

Do you feel like you can practically hear the hum of GPUs anytime someone mentions "large language models?" There's a reason for that cosmic-level buzz: Transformer architectures. And if we're tracing that phenomenon back to its Big Bang moment, we land squarely on a now-legendary 2017 paper from a group of Google Brain and Google Research engineers: Attention Is All You Need.
At first glance, the phrase might sound like a gentle nudge toward mindfulness, but it heralded a revolution in natural language processing (NLP) and beyond. The Transformer model upended the AI status quo in one swift stroke: no more inch-by-inch progression of RNNs, LSTMs, and convolution-based sequence models. Instead, we got a parallelizable, attention-driven system that trains faster, scales bigger, and—here's the kicker—achieves better results.
1. The Big Idea: All Hail Self-Attention
Before Transformers burst onto the scene, the gold standard for sequence transduction (think language translation, summarization, etc.) involved recurrent neural networks with carefully engineered gating mechanisms or convolutional neural networks with complicated stacking to handle long-range dependencies. Effective? Yes. Slow? Also, yes—especially when you need to analyze truly massive datasets.
In simplest terms, self-attention is a mechanism by which every token in a sequence (e.g., a word or subword) can "look" at every other token simultaneously, discovering contextual relationships without being forced to crawl step-by-step through the data. This approach contrasts with older models, such as RNNs and LSTMs, which had to process the sequence largely sequentially.
Transformers enable far more parallelization by discarding recurrence (and the overhead that comes with it). You can toss a bevy of GPUs at the problem, train on massive datasets, and see results in days rather than weeks.
[caption id="" align="alignnone" width="847"]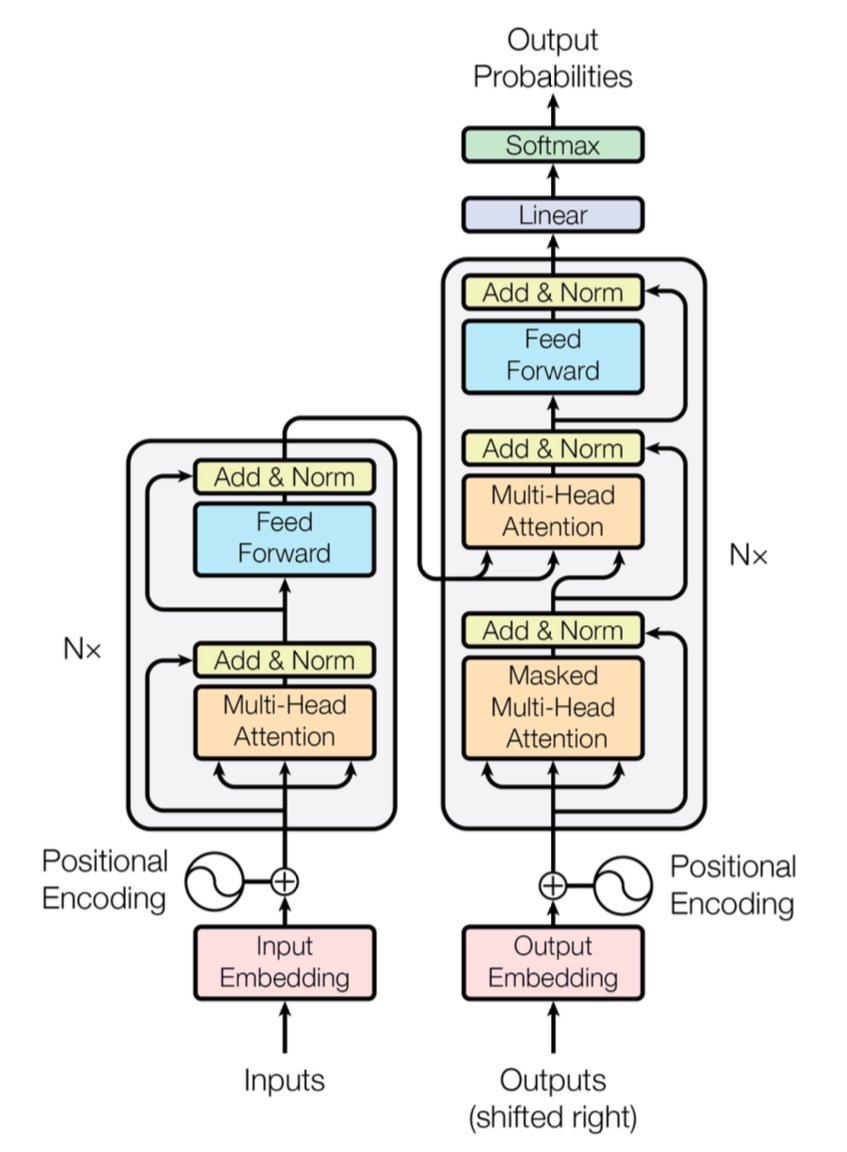 Figure 1: The complete Transformer architecture showing encoder (left) and decoder (right) with multi-head attention layers. Source: Vaswani et al., "Attention Is All You Need" (2017). Image reproduced for educational purposes under fair use. [/caption]
Figure 1: The complete Transformer architecture showing encoder (left) and decoder (right) with multi-head attention layers. Source: Vaswani et al., "Attention Is All You Need" (2017). Image reproduced for educational purposes under fair use. [/caption]
Quick Performance Note: The original Transformer demonstrated a 28.4 BLEU score on the WMT 2014 English-to-German task—a solid leap over prior neural machine translation architectures like CNN-based and RNN-based models, which hovered around 25–26 BLEU at best. These days, improved Transformers (think GPT-4 and its cousins) go even further, handling tasks beyond translation.
2. Under the Hood: Multi-Head Attention and Positional Encodings
Multi-Head Attention
Within the Transformer's self-attention are these magical beasts called multi-head attention modules. They let the network learn different types of relationships in parallel. Think of it as deploying multiple spotlights to illuminate various parts of your data simultaneously. One attention head might track long-distance dependencies (like pronoun-noun references), while another focuses on local context (like the phrase "on the mat" around "cat"). Combining these specialized sub-attentions, the Transformer can better encode nuanced meaning.
[caption id="" align="alignnone" width="1220"]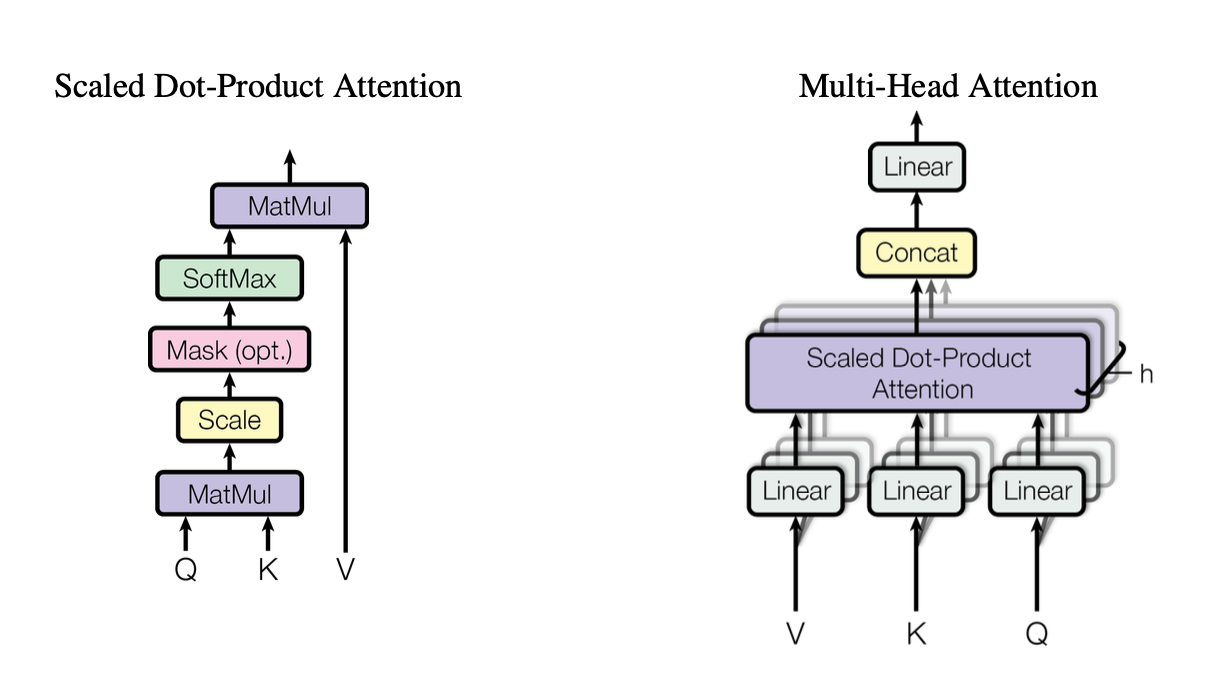 Figure 2: Illustration of the scaled dot-product attention mechanism showing how Query (Q), Key (K), and Value (V) vectors interact. Source: Vaswani et al., "Attention Is All You Need" (2017). Image reproduced for educational purposes under fair use. [/caption]
Figure 2: Illustration of the scaled dot-product attention mechanism showing how Query (Q), Key (K), and Value (V) vectors interact. Source: Vaswani et al., "Attention Is All You Need" (2017). Image reproduced for educational purposes under fair use. [/caption]
These heads use scaled dot-product attention as a standard building block, which we can summarize in code as:
import torchimport math def scaled_dot_product_attention(Q, K, V): # Q, K, V are [batch_size, heads, seq_len, d_k] d_k = Q.size(-1) scores = torch.matmul(Q, K.transpose(-2, -1)) / math.sqrt(d_k) weights = torch.softmax(scores, dim=-1) return torch.matmul(weights, V)
Each head operates on differently projected versions of queries (Q), keys (K), and values (V), then merges the results. This parallelizable design is key to the Transformer's efficiency.
Positional Encodings
No recurrences? That begs the question: How does the model keep track of word order? Enter positional encodings—a sinusoidal or learned pattern added to each token's embedding, helping the Transformer maintain a sense of sequence. It's like giving each word a unique timestamp.
3. Quick Performance Showdown
-
RNNs/LSTMs: Great for sequence tasks but slow for long sequences due to step-by-step processing.
-
CNNs (e.g., ConvS2S): Faster than RNNs but still not fully parallel for long-range dependencies.
-
Transformers:
Higher Throughput: Can process entire sequences in parallel, making training significantly faster.
-
Better Results: Transformers achieved state-of-the-art scores in tasks like machine translation (28.4 BLEU on WMT14 EN-DE) with less training time.
-
Scalable: Throw more GPUs at the data and watch it scale nearly linearly (within hardware and memory limits).
4. The Complexity Consideration: O(n²) and Why It Matters
While Transformers accelerate training through parallelization, self-attention carries an O(n²) complexity concerning sequence length n. In other words, every token attends to every other token, which can be expensive for extremely long sequences. Researchers are actively exploring more efficient attention mechanisms (like sparse or block-wise attention) to mitigate this cost.
Even so, for typical NLP tasks where token counts are in the thousands rather than millions, this O(n²) overhead is often outweighed by the benefits of parallel computation—especially if you have the proper hardware.
5. Why It Matters for Large Language Models (LLMs)
Modern LLMs—like GPT, BERT, and T5—trace their lineage directly to the Transformer. That's because the original paper's focus on parallelism, self-attention, and flexible context windows made it ideally suited for tasks beyond translation, including:
-
Text Generation & Summarization
-
Question-Answering
-
Code Completion
-
Multi-lingual Chatbots
-
And yes, your new AI writing assistant always seems to have a pun up its sleeve.
In short, "Attention Is All You Need" paved the way for these large models that ingest billions of tokens and handle almost any NLP task you throw their way.
6. We’re going to need more compute: Where Introl's Deployments Come In
Here's the catch: Transformers are hungry—very hungry. Training a large language model can mean hoovering up computing resources by the forklift load. To harness all that parallelism, you need robust GPU deployments—sometimes numbering in the thousands (or tens of thousands). That's where high-performance computing (HPC) infrastructure steps in.
At Introl, we've seen firsthand how massive these systems can get. We've worked on builds involving over 100,000 GPUs on tight timelines—talk about logistical prowess. Our bread and butter are deploying GPU servers, racks, and advanced power/cooling setups so everything hums efficiently. When you're simultaneously training a Transformer-based model on thousands of nodes, any hardware bottleneck is an energy vortex for both time and money.
-
Large-Scale GPU Clusters: We've executed deployments that pushed beyond 100K GPUs, meaning we understand the intricacies of rack-and-stack configurations, cabling, and power/cooling strategies to keep everything stable.
-
Rapid Mobilization: Need to add another 2,000 GPU nodes in a few days? Our specialized teams can be on-site and operational within 72 hours.
-
End-to-End Support: From firmware updates and iDRAC configurations to ongoing maintenance and performance checks, we manage the logistics so your data scientists can stay focused on innovation.
7. Looking Ahead: Bigger Models, Bigger Dreams
"Attention Is All You Need" isn't just a milestone—it's the blueprint for future expansions. Researchers are already exploring longer-context Transformers, efficient attention mechanisms, and advanced sparsity to handle enormous corpora (think: entire libraries, not just your local bookstore). Rest assured, the appetite for GPU-accelerated computing will only ramp up.
And that's the beauty of the Transformer era. We have a model that can elegantly scale, provided we match it with the proper hardware strategy. So whether you're building the next generative AI phenomenon or pushing the boundaries of universal translation, having an infrastructure partner adept in massive GPU deployments is more than just a nice-to-have; it's practically your competitive edge.
Final Thought: Transform Your AI Game
The paper Attention Is All You Need was more than a clever title—it was a seismic shift. Transformers have transformed everything from machine translation to code generation and beyond. If you want to harness that power at scale, the key is matching brilliant architecture with equally brilliant infrastructure.
Ready to scale up? Find out how Introl's specialized GPU Infrastructure Deployments can accelerate your next big Transformer project—because the proper hardware can make all the difference in AI.
The visualizations in this article are from the original "Attention Is All You Need" paper (Vaswani et al., 2017) and are included with attribution under fair use for educational purposes. The paper is available at https://arxiv.org/abs/1706.03762 for readers interested in the complete research.


