
Google's Tensor Processing Units voeden de meeste geavanceerde AI-modellen waarmee je dagelijks interacteert, maar toch blijven de meeste engineers verrassend onbekend met hun architectuur. Hoewel NVIDIA GPU's de ontwikkelaarswereld domineren, trainen en serveren TPUs stilletjes Gemini 2.0, Claude en tientallen andere grensverleggende modellen op schalen die de meeste organisaties zouden ruïneren als ze conventionele GPU-infrastructuur zouden gebruiken. Anthropic heeft zich onlangs gecommitteerd aan het inzetten van meer dan een miljoen TPU-chips—wat meer dan een gigawatt aan rekencapaciteit vertegenwoordigt—om toekomstige Claude-modellen te trainen.¹ Google's nieuwste Ironwood-generatie levert 42,5 exaflops aan FP8-berekeningen over 9.216-chip superpods, een schaal die herdefiniëert wat productie-AI-infrastructuur betekent.²
De technische verfijning achter TPUs gaat veel verder dan simpele prestatiemetrieken. Deze processors belichamen een fundamenteel andere ontwerpfilosofie dan GPU's, waarbij algemene flexibiliteit wordt ingeruild voor extreme specialisatie in matrixvermenigvuldiging en tensor-operaties. Engineers die TPU-architectuur begrijpen kunnen 256×256 systolische arrays benutten die 65.536 vermenigvuldig-accumulator-operaties per cyclus verwerken, derdegeneratie SparseCore-accelerators inzetten voor embedding-intensieve workloads, en optische circuitschakelaars programmeren die multi-petabit datacenter-topologieën in minder dan 10 nanoseconden herconfigureren.³ De architectuur beslaat alles van ontwerpbeslissingen op transistorniveau tot supercomputer-orkestratie op gebouwniveau.
De technische inhoud verderop vereist zorgvuldige aandacht. We onderzoeken zeven generaties van TPU-evolutie, ontleden systolische array-wiskunde en dataflow-patronen, verkennen geheugen-hiërarchieën van SRAM-tegels tot HBM3e-kanalen, analyseren XLA-compiler-optimalisaties op het niveau van intermediaire representatie, en onderzoeken waarom collectieve operaties 10× sneller uitvoeren dan equivalente Ethernet-gebaseerde GPU-clusters.⁴ Je zult register-niveau specificaties tegenkomen, cyclus-accurate prestatie-modellering, en de architecturale afwegingen die TPUs tegelijkertijd krachtiger en meer beperkt maken dan GPU's. De diepte hier dient engineers die de volgende generatie AI-infrastructuur bouwen en onderzoekers die de grenzen verleggen van wat huidige accelerators kunnen bereiken.
De Evolutie: Zeven Generaties van Architecturale Innovatie
TPU v1: Uitsluitend Inferentie-Specialisatie (2015)
Google implementeerde de eerste Tensor Processing Unit in 2015 om een kritiek probleem aan te pakken: neural network inferentie-workloads dreigden de datacenter-footprint van het bedrijf te verdubbelen.⁵ Engineers ontwierpen TPU v1 uitsluitend voor inferentie, waarbij trainingsmogelijkheden volledig werden weggelaten om prestaties en energie-efficiëntie voor geïmplementeerde modellen te maximaliseren. De chip beschikt over een 256×256 systolic array van 8-bit integer multiply-accumulate units, die 92 teraops per seconde leveren bij slechts 28-40 watt thermal design power.⁶
De architectuur belichaamde radicaal minimalisme. Een enkele Matrix Multiply Unit verwerkte INT8-operaties via weight-stationary dataflow, waarbij gewichten vast bleven in de systolic array terwijl activaties horizontaal over het grid stroomden. Partiële sommen worden verticaal doorgegeven, waardoor tussenliggende geheugen-writes voor de gehele matrixvermenigvuldiging worden geëlimineerd. De chip, verbonden met hostsystemen via PCIe, vertrouwde op DDR3 DRAM voor extern geheugen en opereerde op 700 MHz—bewust conservatief voor energie-efficiëntie.⁷
Prestatiewinsten verbaasden zelfs Google's engineers. TPU v1 behaalde 30× tot 80× verbeteringen in operaties per watt vergeleken met hedendaagse CPU's en GPU's voor productie-inferentie-workloads.⁸ De chip behandelde Google Search ranking, vertaalservices die 1 miljard dagelijkse verzoeken verwerken, en YouTube-aanbevelingen voor 2 miljard gebruikers. Het succes valideerde een kernarchitecturaal inzicht: doelgebouwde accelerators geoptimaliseerd voor smalle workloads konden orde-van-grootte verbeteringen leveren ten opzichte van algemene processors.
TPU v2: Training op Schaal Mogelijk Maken (2017)
De tweede generatie transformeerde TPU's van inferentie-only accelerators naar complete trainingsplatforms. Google herontwierp de gehele architectuur rond floating-point operaties, waarbij de 256×256 INT8-array werd vervangen door dubbele 128×128 bfloat16 multiply-accumulators per core.⁹ Elke chip bevatte twee TensorCores die 8GB High Bandwidth Memory per core deelden, een enorme upgrade van DDR3 die de bandbreedte bood die neural network training eiste.
Bfloat16-precisie bleek cruciaal voor TPU v2's succes. Het formaat houdt hetzelfde 8-bit exponent bereik aan als FP32 terwijl de mantissa wordt teruggebracht tot 7 bits, waarbij het dynamische bereik voor training behouden blijft terwijl de geheugenbandbreedte-eisen worden gehalveerd.¹⁰ Engineers observeerden dat de verminderde mantissa-precisie daadwerkelijk de generalisatie in veel modellen verbeterde door te fungeren als een vorm van regularisatie, terwijl het volledige FP32-exponent bereik de underflow- en overflow-problemen voorkwam die FP16-training teisterden.
De architecturale innovatie die TPU v2 werkelijk onderscheidde was de Inter-Chip Interconnect (ICI). Eerdere accelerators vereisten Ethernet of InfiniBand voor multi-chip communicatie, wat latency en bandbreedte-knelpunten introduceerde. Google ontwierp aangepaste high-speed bidirectionele links die elke TPU direct verbonden met vier buren in een 2D torus topologie.¹¹ De interconnect maakte TPU v2 "pods" van tot 256 chips mogelijk om te functioneren als een enkele logische accelerator, waarbij collectieve operaties zoals all-reduce veel sneller uitvoerden dan netwerk-gebaseerde alternatieven.
TPU v3: Watergekoelde Prestatieschaling (2018)
Google verhoogde kloksnelheden en core counts agressief in TPU v3, waarbij 420 teraflops per chip werd geleverd—meer dan een verdubbeling van v2's prestaties.¹² De verhoogde vermogensdichtheid forceerde een dramatische architecturale verandering: vloeistofkoeling. Elke TPU v3 pod vereiste waterkoeling-infrastructuur, een afwijking van de luchtgekoelde ontwerpen van eerdere generaties en de meeste datacenter-accelerators.¹³
De chip behield de dubbele 128×128 MXU-architectuur maar verhoogde het totale aantal cores en verbeterde geheugenbandbreedte. Elke TPU v3 bevatte vier chips met elk twee cores, die in totaal 32GB HBM-geheugen deelden tussen de chips.¹⁴ De vectorverwerkingseenheden ontvingen verbeteringen voor activatiefuncties, normalisatie-operaties en gradiëntberekeningen die training op de matrix-units alleen vaak bottleneckten.
Implementaties schaalden naar 2,048-chip pods met dezelfde 2D torus ICI-topologie als v2 maar met verhoogde bandbreedte per link. Google trainde steeds grotere modellen op v3 pods, waarbij werd ontdekt dat de torus-topologie's verminderde netwerkdiameter (maximale afstand tussen twee chips schaalt als N/2 in plaats van N) communicatie-overhead minimaliseerde voor zowel data-parallelle als model-parallelle trainingsstrategieën.¹⁵
TPU v4: Optische Circuit Switching Doorbraak (2021)
De vierde generatie vertegenwoordigde Google's meest significante architecturale sprong sinds de oorspronkelijke TPU. Engineers verhoogden podschaal naar 4,096 chips terwijl optische circuit switching (OCS) voor interconnect werd geïntroduceerd, een technologie geleend van telecommunicatie die datacenter-schaal ML-infrastructuur revolutioneerde.¹⁶
TPU v4's kernarchitectuur bevatte vier 128×128 MXUs per TensorCore naast verbeterde vector- en scalaire eenheden. Elk TensorCore-paar deelde 128MB Common Memory naast per-core Vector Memory, waardoor meer geavanceerde data staging en hergebruikpatronen mogelijk werden.¹⁷ De chiptopologie evolueerde van 2D naar 3D torus, waarbij elke TPU werd verbonden met zes buren in plaats van vier, wat de netwerkdiameter verder verminderde en bisection bandwidth verbeterde.
Het optische circuit switching systeem veranderde alles aan grootschalige implementatie. In plaats van vaste bekabeling tussen TPU's implementeerde Google programmeerbare optische switches die dynamisch konden herconfigureren welke chips met welke verbonden waren. MEMS (microelectromechanical systems) spiegels leiden lichtstralen fysiek om om willekeurige TPU-paren samen te patchen, waarbij praktisch nul latency wordt geïntroduceerd buiten de optische vezeltransmissietijd.¹⁸ De switches herconfigureren in sub-10-nanoseconde vensters, sneller dan de meeste netwerkprotocol-handshakes.
De OCS-architectuur maakte eerder onmogelijke mogelijkheden mogelijk. Google kon "slices" van elke grootte voorzien, van vier chips tot de volledige 4,096-chip pod, door de optische switches gepast te programmeren. Gefaalde chips konden naadloos worden omgeleid zonder hele racks plat te leggen. Het meest opmerkelijk was dat fysiek verafgelegen TPU's in verschillende datacenterlocaties logisch naast elkaar konden zijn in de netwerktopologie, waarbij fysieke en logische layout volledig ontkoppeld werden.¹⁹
TPU v4 introduceerde ook SparseCore, een gespecialiseerde processor voor het behandelen van embedding-operaties die dagelijks gebruikt worden in aanbevelingssystemen, rankingmodellen en large language models met enorme vocabulary embeddings. De SparseCore bevatte vier toegewijde processors per chip, elk met 2,5MB scratchpad-geheugen en geoptimaliseerde dataflow voor sparse geheugentoegangpatronen.²⁰ Modellen met ultra-grote embeddings behaalden 5-7× speedups met slechts 5% van het totale chip die-oppervlak en vermogensbudget.
TPU v5p en v5e: Specialisatie en Schaal (2022-2023)
Google splitste de vijfde generatie op in twee verschillende producten die verschillende use cases targetten. TPU v5p prioriteerde maximale prestaties voor grootschalige training, terwijl v5e optimaliseerde voor kosteneffectieve inferentie en kleinere trainingsjobs.²¹
TPU v5p behaalde ongeveer 4,45 exaflops per seconde over 8,960-chip pods, meer dan een verdubbeling van v4's maximale podgrootte.²² De interconnect-bandbreedte bereikte 4,800 Gbps per chip, en de 3D torus-topologie verbond chips in enorme 16×20×28 superpods. De optische circuit switching fabric beheerde 13,824 optische poorten over 48 OCS-eenheden om een complete v5p superpod te bedraden, wat een van de grootste productie-optische switching implementaties in computergeschiedenis vertegenwoordigde.²³
TPU v5e nam een andere benadering, waarbij core count en kloksnelheid werden verminderd om agressieve vermogen- en kostendoelen te behalen. Inferentie-geoptimaliseerde chips bevatten slechts één TPU-core per chip in plaats van twee, en keerden terug naar de 2D torus-topologie, wat voldoende was voor kleinere podgroottes.²⁴ De architecturale vereenvoudiging stelde Google in staat om v5e competitief te prijzen voor workloads waarbij absolute prestaties minder belangrijk waren dan prestaties per dollar.
TPU v6e Trillium: Verviervoudiging van Matrix-prestaties (2024)
Trillium markeerde nog een architecturaal keerpunt door de Matrix Multiply Unit uit te breiden van 128×128 naar 256×256 multiply-accumulators.²⁵ De grotere array verviervoudigde FLOPs per cyclus bij dezelfde kloksnelheid, waarbij 4,7× de piek compute-prestaties van TPU v5e werd geleverd door een combinatie van de uitgebreide MXU en verhoogde klokfrequenties.
Het geheugensysteem ontving even dramatische upgrades. HBM-capaciteit verdubbelde naar 32GB per chip, met bandbreedte verdubbeld door next-generatie HBM-kanalen.²⁶ De Interchip Interconnect bandbreedte verdubbelde evenzo, waardoor pods van 256 Trillium-chips hogere throughput konden volhouden voor modellen die zowel compute als communicatie benadrukten.²⁷
Trillium bevatte de derde-generatie SparseCore-accelerator, met verbeterde mogelijkheden voor ultra-grote embeddings in ranking- en aanbevelingworkloads. Het bijgewerkte ontwerp verbeterde geheugentoegangspatronen en verhoogde de adequate bandbreedte tussen SparseCores en HBM voor modellen gedomineerd door embedding-lookups in plaats van matrixvermenigvuldigingen.²⁸
Energie-efficiëntie verbeterde met 67% ten opzichte van v5e ondanks substantiële prestatiewinsten.²⁹ Google behaalde de efficiëntiewinsten door geavanceerde procesknooppunten, architecturale optimalisaties die verspild werk verminderden, en zorgvuldige power gating van ongebruikte eenheden tijdens operaties die niet alle delen van de chip tegelijkertijd benadrukten.
TPU v7 Ironwood: Het FP8-tijdperk (2025)
Google's zevende-generatie TPU, codenaam Ironwood, vertegenwoordigt de eerste TPU ontworpen met native FP8-ondersteuning en specifiek geoptimaliseerd voor het "tijdperk van inferentie" terwijl state-of-the-art trainingsprestaties behouden blijven.³⁰ Elke Ironwood-chip levert 4,6 petaFLOPS van dense FP8-compute—iets meer dan NVIDIA's concurrerende B200 op 4,5 petaFLOPS—terwijl 600W thermal design power wordt getrokken.³¹
Het geheugensysteem uitgebreid naar 192GB HBM3e-geheugen per chip, zes keer Trillium's capaciteit, met bandbreedte die 7,4TB/s bereikt.³² De dramatische geheugentoename maakt het serveren van ultra-grote modellen met key-value caches mogelijk die eerder complexe tensor-parallelisme over meerdere accelerators vereisten. Google ontwierp de geheugencapaciteit specifiek om opkomende multi-modale modellen en long-context applicaties te ondersteunen die miljoen-token vensters naderen.
Ironwood's interconnect biedt 9,6 Tbps van geaggregeerde bidirectionele bandbreedte door vier ICI-links, wat zich vertaalt naar 1,2 TB/s van piek per-chip bandbreedte.³³ De architectuur schaalt van 256-chip pods voor kleinere implementaties naar enorme 9,216-chip superpods die 42,5 FP8 exaflops van compute-kracht leveren.³⁴ Google's Jupiter datacenter-netwerktechnologie zou theoretisch tot 43 Ironwood superpods in een enkele cluster kunnen ondersteunen—ongeveer 400,000 accelerators die een bijna onvoorstelbare schaal van compute vertegenwoordigen.³⁵
De FP8-ondersteuning vertegenwoordigt een fundamentele verschuiving in precisiestrategie. Eerdere TPU-generaties emuleerden 8-bit operaties met softwaretechnieken, wat overhead introduceerde. Ironwood implementeert native FP8 multiply-accumulate units die zowel E4M3 (4-bit exponent, 3-bit mantissa) als E5M2 (5-bit exponent, 2-bit mantissa) formaten ondersteunen.³⁶ De dubbele formaat-ondersteuning maakt het mixen van E4M3 mogelijk voor forward passes waar precisie minder uitmaakt en E5M2 voor backward passes waar het behouden van gradiëntgroottes trainingsinstabiliteit voorkomt.
Anthropic's toezegging om meer dan een miljoen Ironwood-chips te implementeren vanaf 2026 toont de productie-gereedheid van de architectuur. Het bedrijf is van plan om ruim meer dan een gigawatt aan TPU-capaciteit te benutten—genoeg om een kleine stad van stroom te voorzien—uitsluitend voor het trainen en serveren van Claude-modellen.³⁷ De schaal overstijgt zelfs de meest significante bekende GPU-implementaties en vertegenwoordigt een fundamentele inzet op TPU-architectuur voor frontier model-ontwikkeling.
Huidige-Generatie Snel Overzicht
De volgende tabellen bieden scanbare specificaties voor de drie huidige-generatie TPU's die het meest relevant zijn voor productie-implementaties in 2025:
Tabel 1: Kern Compute-specificaties
[caption id="" align="alignnone" width="1386"] SpecificatieTPU v5eTPU v5pTPU v6e (Trillium)TPU v7 (Ironwood) MXU Array Grootte 128×128 128×128 256×256 256×256 MACs per Cyclus 16,384 16,384 65,536 65,536 Piek BF16 TFLOPS ~197 ~459 ~918 ~2,300 (schatting) Piek FP8 PFLOPS N/A (geëmuleerd) N/A (geëmuleerd) N/A (geëmuleerd) 4.6 Native Precisie BF16, INT8 BF16, INT8 BF16, INT8 BF16, FP8, INT8 TensorCores/Chip 1 2 1 1 [/caption]
SpecificatieTPU v5eTPU v5pTPU v6e (Trillium)TPU v7 (Ironwood) MXU Array Grootte 128×128 128×128 256×256 256×256 MACs per Cyclus 16,384 16,384 65,536 65,536 Piek BF16 TFLOPS ~197 ~459 ~918 ~2,300 (schatting) Piek FP8 PFLOPS N/A (geëmuleerd) N/A (geëmuleerd) N/A (geëmuleerd) 4.6 Native Precisie BF16, INT8 BF16, INT8 BF16, INT8 BF16, FP8, INT8 TensorCores/Chip 1 2 1 1 [/caption]
Tabel 2: Geheugen en Bandbreedte
[caption id="" align="alignnone" width="1380"]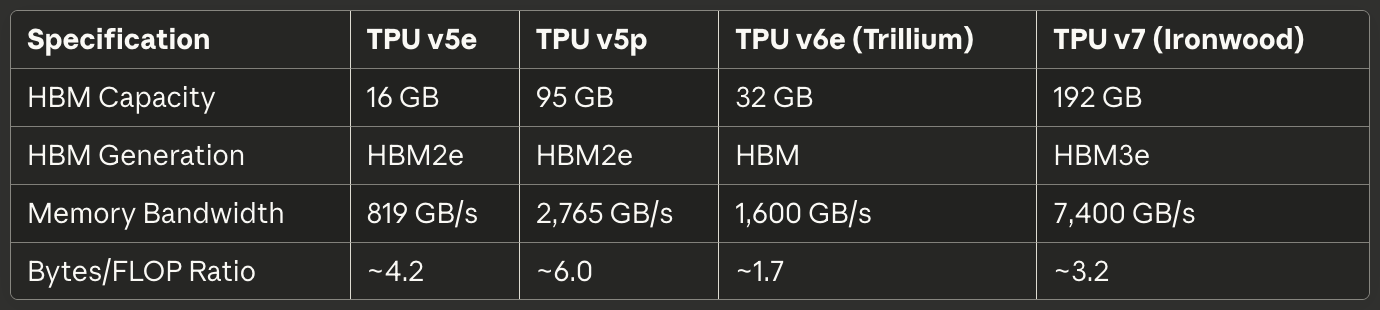 SpecificatieTPU v5eTPU v5pTPU v6e (Trillium)TPU v7 (Ironwood) HBM Capaciteit 16 GB 95 GB 32 GB 192 GB HBM Generatie HBM2e HBM2e HBM HBM3e Geheugenbandbreedte 819 GB/s 2,765 GB/s 1,600 GB/s 7,400 GB/s Bytes/FLOP Ratio ~4.2 ~6.0 ~1.7 ~3.2 [/caption]
SpecificatieTPU v5eTPU v5pTPU v6e (Trillium)TPU v7 (Ironwood) HBM Capaciteit 16 GB 95 GB 32 GB 192 GB HBM Generatie HBM2e HBM2e HBM HBM3e Geheugenbandbreedte 819 GB/s 2,765 GB/s 1,600 GB/s 7,400 GB/s Bytes/FLOP Ratio ~4.2 ~6.0 ~1.7 ~3.2 [/caption]
Tabel 3: Interconnect en Schaling
[caption id="" align="alignnone" width="1384"]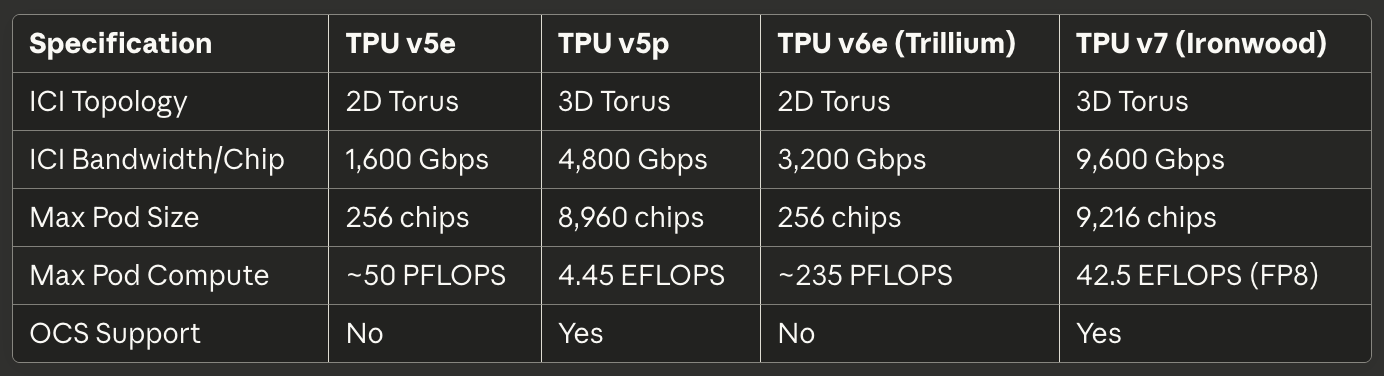 SpecificatieTPU v5eTPU v5pTPU v6e (Trillium)TPU v7 (Ironwood) ICI Topologie 2D Torus 3D Torus 2D Torus 3D Torus ICI Bandbreedte/Chip 1,600 Gbps 4,800 Gbps 3,200 Gbps 9,600 Gbps Max Pod Grootte 256 chips 8,960 chips 256 chips 9,216 chips Max Pod Compute ~50 PFLOPS 4.45 EFLOPS ~235 PFLOPS 42.5 EFLOPS (FP8) OCS Ondersteuning Nee Ja Nee Ja [/caption]
SpecificatieTPU v5eTPU v5pTPU v6e (Trillium)TPU v7 (Ironwood) ICI Topologie 2D Torus 3D Torus 2D Torus 3D Torus ICI Bandbreedte/Chip 1,600 Gbps 4,800 Gbps 3,200 Gbps 9,600 Gbps Max Pod Grootte 256 chips 8,960 chips 256 chips 9,216 chips Max Pod Compute ~50 PFLOPS 4.45 EFLOPS ~235 PFLOPS 42.5 EFLOPS (FP8) OCS Ondersteuning Nee Ja Nee Ja [/caption]
Tabel 4: Vermogen en Efficiëntie
[caption id="" align="alignnone" width="1380"] SpecificatieTPU v5eTPU v5pTPU v6e (Trillium)TPU v7 (Ironwood) TDP ~120-200W ~250-300W ~120-200W 600W Koeling Lucht Vloeistof Lucht Vloeistof TFLOPS/Watt (BF16) ~1.0-1.6 ~1.5-1.8 ~4.6-7.7 ~3.8 Energie vs Vorige Gen Baseline N/A 67% beter dan v5e 2× beter dan Trillium [/caption]
SpecificatieTPU v5eTPU v5pTPU v6e (Trillium)TPU v7 (Ironwood) TDP ~120-200W ~250-300W ~120-200W 600W Koeling Lucht Vloeistof Lucht Vloeistof TFLOPS/Watt (BF16) ~1.0-1.6 ~1.5-1.8 ~4.6-7.7 ~3.8 Energie vs Vorige Gen Baseline N/A 67% beter dan v5e 2× beter dan Trillium [/caption]
Tabel 5: Aanbevolen Use Cases
[caption id="" align="alignnone" width="1382"] Use Case Beste Keuze Rationale Kostengeoptimaliseerde inferentie TPU v5e: Laagste kosten per inferentie-query Grootschalige training (>1000 chips) TPU v5p of Ironwood 3D torus + OCS maakt enorme pods mogelijk Medium trainingsjobs (256 chips) TPU v6e Trillium Beste perf/watt, 4.7× compute vs v5e Memory-bound modellen (>70B params), Ironwood 192GB HBM maakt grotere batchgroottes mogelijk Long-context inferentie (>100K tokens) Ironwood HBM-capaciteit ondersteunt enorme KV-caches Embedding-intensieve workloads TPU v5p of Ironwood SparseCore + grote HBM [/caption]
Use Case Beste Keuze Rationale Kostengeoptimaliseerde inferentie TPU v5e: Laagste kosten per inferentie-query Grootschalige training (>1000 chips) TPU v5p of Ironwood 3D torus + OCS maakt enorme pods mogelijk Medium trainingsjobs (256 chips) TPU v6e Trillium Beste perf/watt, 4.7× compute vs v5e Memory-bound modellen (>70B params), Ironwood 192GB HBM maakt grotere batchgroottes mogelijk Long-context inferentie (>100K tokens) Ironwood HBM-capaciteit ondersteunt enorme KV-caches Embedding-intensieve workloads TPU v5p of Ironwood SparseCore + grote HBM [/caption]
Hardware Architectuur: Binnenkant van het Silicium
Systolic Array Wiskunde en Dataflow
De Matrix Multiply Unit vormt het hart van TPU-architectuur, en het begrijpen van systolic arrays vereist het bevatten van hun fundamenteel verschillende benadering van parallelisme vergeleken met GPU SIMD-lanes. Een systolic array ketent multiply-accumulate units in een grid waar data ritmisch door de structuur stroomt—vandaar "systolic," evoquerend het ritmische pompen van bloed door het hart.³⁸
Beschouw TPU v6e's 256×256 systolic array die de matrixvermenigvuldiging C = A × B uitvoert. Engineers laden de gewichten van matrix B vooraf in de 65,536 individuele multiply-accumulate units gerangschikt in een grid. Matrix A's activatiewaarden betreden van de linkerrand en stromen horizontaal over de array. Elke MAC-unit vermenigvuldigt zijn opgeslagen gewicht met de binnenkomende activatie, telt het resultaat op bij een partiële som die van boven aankomt, en geeft zowel de activatie (horizontaal) als bijgewerkte partiële som (verticaal) door aan naburige units.³⁹
Het dataflow-patroon betekent dat elke activatiewaarde 256 keer wordt hergebruikt terwijl het de horizontale dimensie doorkruist, en elke partiële som bijdragen van 256 vermenigvuldigingen accumuleert terwijl het verticaal stroomt. Cruciaal is dat alle tussenresultaten direct tussen aangrenzende MAC-units passeren via korte draden in plaats van round-trips naar geheugen. De architectuur voert 65,536 multiply-accumulate operaties uit elke klokpuls, en tijdens de gehele matrixvermenigvuldiging met potentieel miljoenen operaties raken nul tussenwaarden DRAM of zelfs on-chip SRAM.⁴⁰
Het weight-stationary dataflow-patroon optimaliseert voor het meest voorkomende geval in neural network inferentie en training: herhaaldelijk vermenigvuldigen van veel verschillende activatiematrices met dezelfde gewichtmatrix. Engineers laden gewichten eenmaal, dan streamen onbegrensde activatiebatches door de array zonder herladen. Het patroon werkt uitzonderlijk goed voor convolutionele lagen, volledig verbonden lagen, en de Q·K^T en attention·V operaties die transformermodellen domineren.⁴¹
Energie-efficiëntie stamt van datahergebruik en ruimtelijke lokaliteit. Het lezen van een waarde uit DRAM verbruikt ongeveer 200× zoveel energie als een enkele multiply-accumulate operatie.⁴² Door elk gewicht 256 keer en elke activatie 256 keer te hergebruiken zonder geheugentoegangen, behaalt de systolic array operaties-per-watt ratio's onmogelijk voor architecturen die data heen en weer shuttlen tussen compute-units en geheugen hiërarchieën.
De zwakte van de systolic array komt naar voren bij dynamische of onregelmatige rekenpatronen. Omdat data door het grid stroomt op een vast schema, heeft de architectuur moeite met conditionele uitvoering, sparse matrices (tenzij SparseCore wordt gebruikt), en operaties die willekeurige toegangspatronen vereisen. De inflexibiliteit ruilt generaliteit in voor extreme efficiëntie op zijn doelworkload: dense matrixvermenigvuldiging met voorspelbare toegangspatronen.
TensorCore Interne Architectuur
Elke TPU-chip bevat een of meer TensorCores—de complete verwerkingseenheid bestaande uit de Matrix Multiply Unit, Vector Processing Unit en Scalar Unit die samenwerken.⁴³ De TensorCore vertegenwoordigt de fundamentele bouwsteen die software target, en het begrijpen van de interactie tussen zijn drie componenten verklaart zowel TPU-prestatiekarakteristieken als programmeerpatronen.
De Matrix Multiply Unit voert 16,000 multiply-accumulate operaties per cyclus uit op bfloat16 of FP8 inputs met FP32 accumulatie.⁴⁴ De mixed-precision benadering behoudt numerieke nauwkeurigheid in de accumulator terwijl geheugenbandbreedte voor inputs wordt verminderd. Engineers observeerden dat het behouden van complete FP32-precisie tijdens accumulatie catastrofale cancellation errors voorkomt bij het sommeren van honderden of duizenden tussenproducten, terwijl verminderde-precisie inputs zelden de uiteindelijke modelkwaliteit beïnvloeden.
De Vector Processing Unit behandelt operaties slecht geschikt voor de MXU's rigide structuur. Activatiefuncties (ReLU, GELU, SiLU), normalisatielagen (batch norm, layer norm), softmax, pooling, dropout en element-wise operaties voeren uit op de VPU's 128-lane SIMD-architectuur.⁴⁵ De VPU opereert op FP32- en INT32-datatypes, waarbij de precisie wordt geboden die vereist is voor numeriek gevoelige operaties zoals softmax, waar exponentials en delingen grote dynamische bereiken kunnen creëren.
De Scalar Unit orkestreert de gehele TensorCore. De single-threaded processor voert control flow uit, berekent geheugen adressen voor complexe indexeringspatronen, en initieert DMA-transfers van High Bandwidth Memory naar Vector Memory.⁴⁶ Omdat de scalar unit single-threaded loopt, kan elke TensorCore slechts één DMA-verzoek per cyclus creëren—een bottleneck voor geheugen-intensieve operaties die MXU- of VPU-compute-throughput niet verzadigen.
De geheugenhiërarchie die de TensorCore voedt bepaalt bereikbare prestaties evenzeer als ruwe compute-capaciteit. Vector Memory (VMEM) fungeert als een software-beheerde scratchpad SRAM exclusief voor elke TensorCore, typisch gedimensioneerd op tientallen megabytes. De XLA-compiler plant expliciet databeweging tussen HBM en VMEM, beslist wat te stage in het snelle lokale geheugen en wanneer resultaten terug te schrijven.⁴⁷
Common Memory (CMEM), aanwezig in TPU v4 en latere generaties, biedt een grotere gedeelde pool toegankelijk voor alle TensorCores op een chip. De TPU v4-architectuur alloceerde 128MB CMEM gedeeld tussen twee TensorCores, waardoor meer geavanceerde producer-consumer patronen mogelijk werden waarbij de outputs van één core de inputs van een andere core voeden zonder round-trips naar HBM.⁴⁸
De programmeermodelimplicaties zijn enorm belangrijk. Omdat de scalar unit single-threads en het vector geheugen expliciete beheer vereist, lijkt TPU-programmering meer op 1990s-era embedded systems ontwikkeling dan moderne GPU-programmering. CUDA abstraheert geheugenbeweging met unified memory en hardware-beheerde caches; TPU-code (of gegenereerd door XLA of handgeschreven in Pallas) moet expliciet elke datatransfer orkestreren. Handmatige controle maakt expertoptimalisatie mogelijk maar verhoogt de drempel voor competente prestaties.
High Bandwidth Memory Architectuur
Moderne TPU's gebruiken HBM (High Bandwidth Memory), of HBM3e, een radicaal verschillende geheugentechnologie van de DDR SDRAM gevonden in CPU's, en de GDDR gebruikt in veel GPU's. HBM stapelt meerdere DRAM-dies verticaal met door-silicium vias (TSVs), plaatst dan de stapel direct naast de processor die op een silicium interposer.⁴⁹ Het korte elektrische pad en brede interface maken dramatisch hogere bandbreedte mogelijk dan conventionele geheugentechnologieën.
TPU v7 Ironwood implementeert 192GB HBM3e met een totale bandbreedte van 7,4 TB/s.⁵⁰ Het geheugensysteem is verdeeld in meerdere kanalen, elk met onafhankelijke toegang tot een apart deel van de totale capaciteit. De XLA-compiler en runtime moeten tensors zorgvuldig verdelen over HBM-kanalen om parallelle toegang te maximaliseren en hotspots te vermijden waar één kanaal verzadigt terwijl anderen ongebruikt zitten.
De geheugeninterface-breedte overstijgt conventioneel DRAM. Waar een DDR5-kanaal 64 bits breedte kan bieden, beslaat een HBM-kanaal typisch 1,024 bits.⁵¹ De extreme breedte maakt hoge bandbreedte mogelijk bij relatief bescheiden kloksnelheden, wat stroomverbruik en signaalintegriteit uitdagingen vermindert vergeleken met het duwen van smalle interfaces naar multi-gigahertz frequenties.
Latency-karakteristieken verschillen substantieel van GPU-geheugensystemen. TPU's missen hardware-beheerde caches buiten kleine lokale buffers, dus de architectuur vertrouwt op software die expliciet data staged in VMEM ruim voordat compute-units het nodig hebben. Het gebrek aan caches betekent dat geheugenlatency direct prestaties beïnvloedt tenzij de compiler succesvol latency verbergt door prefetching en double-buffering.⁵²
Geheugencapaciteit-limieten domineren veel workloads meer dan compute-throughput. Een 175-miljard parameter model met bfloat16 gewichten vereist 350GB om parameters op te slaan—al meer dan Ironwood's 192GB HBM zelfs voor het meenemen van activaties, optimizer states of gradient buffers. Training van dergelijke modellen eist geavanceerde technieken zoals gradient checkpointing, optimizer state sharding over meerdere chips, en zorgvuldige planning van parameter updates om geheugenfootprint te minimaliseren.⁵³
De TPU-runtime forceert specifieke tensor layout-vereisten om MXU-efficiëntie te maximaliseren. Omdat de systolic array data verwerkt in 128×8 tiles, zouden tensors moeten uitlijnen naar deze dimensies om padding waste te vermijden.⁵⁴ Slecht gedimensioneerde matrices forceren de hardware om partiële tiles te verwerken met MACs die stil zitten, wat direct FLOPS-utilizatie vermindert. De compiler probeert tensors automatisch te padden en te reshapen, maar bewuste layout-keuzes in de modelarchitectuur kunnen prestaties substantieel verbeteren.
SparseCore: Gespecialiseerde Embedding-acceleratie
Terwijl de Matrix Multiply Unit excelleert in dense matrix-operaties, vertonen embedding-intensieve workloads radicaal verschillende karakteristieken. Aanbevelingsmodellen, ranking systemen en large language models benaderen vaak enorme embedding-tabellen (vaak honderden gigabytes) door onregelmatige, data-afhankelijke indices. De MXU's gestructureerde dataflow biedt geen voordeel voor deze sparse geheugen-toegangspatronen, wat SparseCore's gespecialiseerde architectuur motiveert.⁵⁵
SparseCore implementeert een tiled dataflow processor fundamenteel verschillend van de MXU's systolic array. TPU v4 bevatte vier SparseCores per chip, elk met 16 compute tiles.⁵⁶ Elke tile opereert als een onafhankelijke dataflow unit met lokaal scratchpad geheugen (SPMEM) en processing elements. De tiles voeren parallel uit, verwerken disjuncte subsets van embedding-operaties gelijktijdig.
De geheugenhiërarchie plaatst hete data in kleine, snelle SPMEM terwijl de volledige embedding-tabellen in HBM blijven. De XLA-compiler analyseert embedding-toegangspatronen om te bepalen welke embedding-vectoren caching in SPMEM verdienen versus on-demand fetchen uit HBM.⁵⁷ De strategie lijkt op traditionele CPU cache-hiërarchieën, maar met software in plaats van hardware die plaatsingsbeslissingen maakt.
SparseCores verbinden direct met HBM-kanalen, omzeilen volledig het TensorCore's geheugenpad. De toegewijde verbinding voorkomt dat embedding-operaties concurreren met dense matrix-operaties voor geheugenbandbreedte, waardoor beide parallel kunnen procederen.⁵⁸ De partitionering werkt uitzonderlijk goed voor modellen zoals Deep Learning Recommendation Models (DLRMs) die dense neural network layers interleave met grote embedding lookups.
De mod-sharding strategie distribueert embeddings over SparseCores door target_sc_id = col_id % num_total_sparse_cores te berekenen.⁵⁹ De simpele sharding-functie verzekert load balancing wanneer embedding IDs uniform gedistribueerd zijn, maar kan hotspots creëren voor skewed toegangspatronen. Engineers die met real-world data werken hebben vaak nodig embedding frequentieverdelingen te analyseren en sharding handmatig te rebalanceren om bottlenecks te vermijden.
Prestatiewinsten van SparseCore bereiken 5-7× vergeleken met het implementeren van identieke operaties op de MXU en VPU, terwijl slechts 5% van chip die-oppervlak en vermogen wordt geconsumeerd.⁶⁰ Het dramatische efficiëntievoordeel stamt van purpose-building de dataflow voor sparse operaties in plaats van ze te forceren door dense matrix-infrastructuur. Het specialisatieprincipe geldt recursief binnen TPU-architectuur: net zoals TPU's specialiseren voorbij GPU's general-purpose ontwerp, specialiseren SparseCores voorbij TPU's matrix-georiënteerde ontwerp.
Trillium's derde-generatie SparseCore introduceerde variabele SIMD-breedte (8 elementen voor FP32, 16 voor bfloat16) en verbeterde geheugen-toegangspatronen, waardoor verspilde bandbreedte van misaligned reads werd verminderd.⁶¹ De architecturale evolutie toont Google's voortgezette investering in embedding-acceleratie terwijl large language models tenderen naar grotere vocabulaires en meer geavanceerde retrieval-augmented generation patronen.
Interconnect-technologie: Het Bedraden van de Supercomputer
Inter-Chip Interconnect (ICI) Architectuur
De Inter-Chip Interconnect is de kritieke technologie die TPUs in staat stelt te functioneren als uniforme supercomputers in plaats van geïsoleerde versnellers. In tegenstelling tot GPU's die communiceren via Ethernet- of InfiniBand-netwerken, implementeert ICI aangepaste hogesnelheids seriële verbindingen die direct naburige TPUs verbinden met latentie op microsecondeschaal en bandbreedte van terabits per seconde.⁶²
Topology-evolutie over TPU-generaties reflecteert veranderende vereisten voor pod-schaling. TPU v2, v3, v5e en v6e implementeren 2D torus-topologieën waarin elke chip verbindt met zijn vier dichtstbijzijnde buren (noord, zuid, oost en west).⁶³ De verbindingen wikkelen rond bij grenzen, wat een donutvormige logische topologie creëert die randchips met minder verbindingen elimineert. Een 16×16 grid van 256 TPUs biedt dus uniforme bandbreedte- en latentiekarakteristieken ongeacht welke twee chips communiceren.
TPU v4 en v5p upgradeden naar 3D torus-topologieën waarbij elke chip verbindt met zes buren.⁶⁴ De extra dimensie reduceert de netwerkdiameter—het maximale aantal hops tussen willekeurige twee chips—van ongeveer 2√N naar 3∛N. Voor een 4.096-chip pod dalen de maximale hops van ongeveer 128 naar 48, wat de worst-case communicatielatentie voor globaal synchroniserende operaties zoals all-reduce substantieel reduceert.
De toroïdale structuur levert een ander kritiek voordeel: gelijke bisectie-bandbreedte ongeacht hoe workloads partitioneren over chips. Elke snede die de torus in tweeën deelt kruist hetzelfde aantal verbindingen, wat pathologische gevallen voorkomt waarbij slechte jobplaatsing netwerkknelpunten creëert.⁶⁵ De uniforme bisectie-bandbreedte vereenvoudigt scheduling en maakt de optical circuit switch herconfigureerbaarheid mogelijk die hieronder besproken wordt.
Bandbreedte-specificaties schalen indrukwekkend over generaties. TPU v6e biedt 13 TB/s ICI-bandbreedte per chip.⁶⁶ TPU v5p bereikte 4.800 Gbps per chip over zes 3D torus-verbindingen.⁶⁷ Ironwood implementeert vier ICI-verbindingen met een 9,6 Tbps geaggregeerde bidirectionele bandbreedte, wat zich vertaalt naar 1,2 TB/s per chip.⁶⁸ Ter vergelijking: een top-tier 400GbE netwerkinterface biedt 50GB/s bidirectionele bandbreedte—een orde van grootte minder dan moderne TPU ICI.
Verbindingstechnologie binnen racks gebruikt direct-attached copper (DAC) kabels voor korte afstanden tussen chips in dezelfde 4×4×4 kubus.⁶⁹ De koperverbindingen minimaliseren kosten en vermogen terwijl ze de vereiste bandbreedte bieden voor nauw gekoppelde chips die gesynchroniseerde operaties uitvoeren. Inter-kubus en pod-schaal verbindingen schakelen over naar optische transceivers, waarbij hogere kosten en vermogen geruild worden voor de afstand en bandbreedte nodig om datacenter-racks te overspannen.
Collectieve operaties benutten ICI's unieke eigenschappen. All-reduce, all-gather en reduce-scatter operaties synchroniseren frequent activaties en gradiënten over chips tijdens training. Op Ethernet-gebaseerde GPU-clusters doorlopen deze collectieven een hiërarchisch netwerk met switches, kabels en netwerkinterfacekaarten, wat latentie introduceert bij elke hop. TPU ICI implementeert geoptimaliseerde collectieve algoritmes direct in hardware, waarbij all-reduce operaties 10× sneller uitgevoerd worden dan equivalente Ethernet-gebaseerde GPU-implementaties.⁷⁰
Optical Circuit Switching: Dynamische Topologie-herconfiguratie
Google's deployment van optical circuit switching (OCS) met TPU v4 vertegenwoordigde een van de meest significante innovaties in datacenternetwerking in decennia. Traditionele packet-switched netwerken—of het nu Ethernet of InfiniBand is—stellen logische verbindingen vast door pakketten hop-voor-hop te routeren door switches die headers onderzoeken en doorsturen naar juiste uitvoerpoorten. OCS gebruikt daarentegen programmeerbare optische elementen om directe fysieke lichtpaden tussen eindpunten te creëren, wat switchinglatentie volledig elimineert.⁷¹
De kerntechnologie berust op MEMS (microelectromechanical systems) spiegels die fysiek roteren om lichtstralen om te leiden. Een zender op TPU A stuurt licht naar de OCS. Kleine spiegels in de OCS roteren om die lichtstraal te reflecteren naar een ontvanger op TPU B. De verbinding wordt een direct optisch pad van A naar B met essentieel nul toegevoegde latentie behalve lichtpropagatie door de vezel.⁷²
Herconfiguratieснelheid bepaalt de praktische bruikbaarheid van OCS in productiesystemen. Google's deployment bereikt sub-10-nanoseconde switchingtijden—sneller dan typische netwerkprotocol round-trip times.⁷³ De herconfiguratiesenlheid maakt dynamische topologiewijzigingen mogelijk die overeenkomen met workloadvereisten zonder lopende jobs te verstoren of zorgvuldig gecoördineerde traffic engineering te vereisen.
TPU v5p demonstreerde OCS op massieve schaal. De architectuur gebruikt optical circuit switches die vier petabits per seconde geaggregeerde bandbreedte leveren over de switching fabric.⁷⁴ Een enkele v5p superpod vereist 48 OCS-eenheden die 13.824 optische poorten beheren om 8.960 chips te bedraden in de 16×20×28 3D torus-configuratie.⁷⁵ Het switchingsysteem vertegenwoordigt een van de grootste optische netwerkdeployments in welke computeromgeving dan ook.
OCS biedt mogelijkheden die onmogelijk zijn met traditionele netwerken. Fysieke topologie en logische topologie ontkoppelen volledig—twee TPUs in tegenovergestelde hoeken van het datacenter verschijnen als aangrenzende buren als de OCS directe optische paden creëert. Gefaalde chips of verbindingen worden omgeleid door spiegels te herprogrammeren om defecte componenten uit te sluiten en de logische torus-structuur te behouden. Nieuwe jobs ontvangen "slices" van elke grootte door de OCS te programmeren om juiste podconfiguraties te creëren zonder fysiek racks opnieuw te bekabelen.⁷⁶
De architectuur integreert met Google's Jupiter datacenternetwerk om verder te schalen dan een enkele pod. Jupiter levert multi-petabit-per-seconde bisectie-bandbreedte over hele datacenters met Google's aangepaste silicium switches en control plane.⁷⁷ Meerdere TPU superpods verbinden via Jupiter fabric, wat theoretisch clusters van tot 400.000 versnellers ondersteunt als netwerkcapaciteit het toestaat.⁷⁸
Vermogensconsumptie en betrouwbaarheidskarakteristieken favoriset optical circuit switching voor TPU-schaal deployments. Traditionele packet switches consumeren substantieel vermogen bij het verwerken en doorsturen van pakketten op terabit-per-seconde snelheden. OCS switches consumeren alleen vermogen om MEMS-spiegels te bedienen tijdens herconfiguratiegebeurtenissen, zitten dan stil en laten licht door met minimaal verlies terwijl verbindingen stabiel blijven.⁷⁹ De eenvoud van de architectuur verbetert betrouwbaarheid door complexe pakketverwerking en buffering logica te elimineren die gevoelig is voor bugs en prestatie-anomalieën.
Pod-architectuur en Schaalkarakteristieken
TPU-pods vertegenwoordigen de grootste enkele eenheid van TPUs verbonden via ICI, wat een uniforme versneller vormt. De fysieke structuur bouwt hiërarchisch op van individuele chips naar trays naar kubussen naar racks naar complete pods.⁸⁰ Het begrijpen van de hiërarchie is belangrijk voor het redeneren over geheugencapaciteit, communicatiebandbreedte en fouttolerantie op verschillende schalen.
De fundamentele bouwsteen bestaat uit vier chips op een enkele tray verbonden met een host-CPU via PCIe.⁸¹ De PCIe-verbinding handelt control plane operaties af, initiële programma-loading en infeed/outfeed voor trainingsdata en inferentieresultaten. De werkelijke inter-chip communicatie voor gedistribueerde training stroomt door ICI in plaats van PCIe, wat PCIe-bandbreedteknelpunten vermijdt.
Zestien trays (64 chips) vormen een enkele 4×4×4 kubus—de basiseenheid voor podconstructie. Binnen een kubus gebruiken alle ICI-verbindingen direct-attached koperkabels omdat chips zich in dezelfde rack bevinden met korte fysieke afstanden.⁸² De kubus implementeert een complete 3D torus met wrap-around verbindingen, wat een zelfstandige 64-chip eenheid creëert die theoretisch onafhankelijk zou kunnen opereren.
TPU v4 pods schalen naar 64 kubussen met in totaal 4.096 chips.⁸³ De inter-kubus verbindingen schakelen over naar optische verbindingen beheerd door de optical circuit switching fabric. De OCS kan deze 4.096 chips provisioneren als een enkele enorme pod, meerdere kleinere onafhankelijke pods, of dynamisch herconfigureren mid-job indien vereist. De flexibiliteit stelt datacenteroperators in staat om gebruik te balanceren over verschillende jobgroottes en prioriteiten.
TPU v5p duwde podschaal naar 8.960 chips in een 16×20×28 3D torus.⁸⁴ De specifieke dimensies reflecteren zorgvuldige bandbreedte- en diameter-optimalisatie—priemfactorisaties zijn belangrijk voor netwerktopologie! De pod levert 4,45 exaflops compute en vertegenwoordigt een van de grootste single-pod configuraties gedeployed in productie.
Ironwood ondersteunt zowel 256-chip pods voor kleinere deployments als 9.216-chip superpods voor massieve frontier model training.⁸⁵ De 9.216-chip configuratie levert 42,5 FP8 exaflops—meer compute dan de hele Top500-lijst van supercomputers bevatte slechts vijf jaar eerder.⁸⁶ De schaal herdefinieert wat organisaties kunnen bereiken met synchrone training in plaats van pipelined of asynchrone benaderingen.
Schaalefficiëntie bepaalt of grotere pods daadwerkelijk helpen. Communicatie-overhead neemt toe met podgrootte omdat chips meer tijd besteden aan synchroniseren in plaats van berekenen. Google Research publiceerde resultaten die 95% schaalefficiëntie demonstreerden bij 32.768 TPUs voor specifieke workloads, wat betekent dat 32.768 TPUs 95% van de prestatie leverden die perfecte lineaire schaling zou voorspellen.⁸⁷ De efficiëntie komt voort uit hardware-versnelde collectieven, geoptimaliseerde compiler-transformaties en slimme algoritmische benaderingen om gradiëntsynchronisatiefrequentie te reduceren.
Fouttolerantie op podschaal vereist geavanceerde afhandeling. Statistische waarschijnlijkheid garandeert componentfalen in elk systeem met duizenden chips die continu draaien. De optical circuit switch maakt graceful degradation mogelijk door te herconfigureren rondom gefaalde componenten. Training checkpointing vindt plaats op reguliere intervallen (typisch elke paar minuten), dus jobfalen vereist alleen herstart vanaf de laatste checkpoint in plaats van vanaf scratch.⁸⁸
Software Stack: Compilers, Frameworks en Programmeermodellen
XLA Compiler: Optimalisatie van Computation Graphs
XLA (Accelerated Linear Algebra) vormt de basis van TPU's software stack en compileert high-level framework operaties naar geoptimaliseerde machinecode voor uitvoering op de TPU.⁸⁹ De compiler implementeert agressieve optimalisaties die onmogelijk zijn in general-purpose compilers omdat het domeinkennis over machine learning workloads en TPU architectuurkenmerken exploiteert.
Fusion vertegenwoordigt XLA's meest impactvolle optimalisatie. De compiler analyseert computation graphs om sequenties van operaties te identificeren die kunnen worden uitgevoerd zonder tussentijdse tensors te materialiseren. Een eenvoudig voorbeeld: element-wise operaties zoals relu(batch_norm(conv(x))) vereisen normaal gesproken het schrijven van de convolutie output naar het geheugen, het lezen ervan voor batch normalisatie, het schrijven van dat resultaat naar het geheugen, en opnieuw lezen voor ReLU. XLA fuseert deze operaties tot een enkele kernel die de uiteindelijke ReLU output produceert zonder tussentijds geheugenverkeer.⁹⁰
Fusion's impact schaalt met TPU's architectuur. Geheugenbandbreedte beperkt veel workloads meer dan compute throughput—de MXU kan matrixvermenigvuldigingen sneller uitvoeren dan het geheugensysteem het data kan voeden. Het elimineren van tussentijdse geheugen writes en reads door fusion vertaalt zich direct naar prestatieverbeteringen, vaak resulterend in 2× of meer speedup voor activatiefunctie-intensieve netwerken.⁹¹
Geheugenlay-out transformaties optimaliseren tensoropslag voor hardwarevereisten. Neurale netwerken representeren tensors vaak in het NHWC formaat (batch, height, width, channels) voor intuïtieve indexering, maar TPU MXU's presteren het best met lay-outs die aansluiten bij 128×8 tiles.⁹² XLA transposeert, hervormt en vult automatisch tensors aan om te matchen met hardwarevoorkeuren, waarbij lay-out transformaties alleen waar nodig worden ingevoegd en soms preferred lay-outs backward door de graph worden gepropageerd om totale transformatie overhead te minimaliseren.
De compiler implementeert geavanceerde constant folding en dead code elimination. ML graphs bevatten vaak subgraphs waarvan de outputs alleen afhangen van constanten—batch normalisatie parameters, inference dropout rates, en shape berekeningen die eenmaal kunnen worden uitgevoerd in plaats van per batch. XLA evalueert deze subgraphs tijdens compile time en vervangt ze met constante tensors, waardoor runtime werk wordt gereduceerd.⁹³
Cross-replica optimalisatie exploiteert kennis over gedistribueerde uitvoering. Bij training across meerdere TPU cores vereisen bepaalde operaties (zoals batch normalisatie statistieken) aggregatie across alle replica's. XLA identificeert deze patronen en genereert geoptimaliseerde collective operaties die ICI's hardware-accelerated all-reduce exploiteren in plaats van aggregatie te implementeren door expliciete message passing.⁹⁴
De compiler target een intermediate representation, Mosaic, specifiek voor TPU's. Mosaic opereert op een hoger abstractieniveau dan assembly language maar lager dan de input computation graph. De taal stelt TPU architecturale features bloot, zoals systolic arrays, vector memory, en VMEM staging, terwijl low-level details zoals instruction scheduling en register allocation worden verborgen.⁹⁵
Auto-tuning capabilities selecteren optimale tile sizes en operatie parameters door empirisch zoeken. Het XLA Auto-Tuning (XTAT) systeem probeert verschillende fusion strategieën, geheugenlay-outs, en tile dimensies, profileert de prestaties van elke variant, en selecteert de snelste configuratie.⁹⁶ De zoektocht kan aanzienlijke compile time vereisen voor complexe modellen, maar produceert dramatische runtime speedups door contra-intuïtieve optimalisaties te ontdekken die mensen zelden handmatig identificeren.
JAX: Composable Transformations en SPMD
JAX biedt een NumPy-compatibele interface voor numerieke berekening met automatische differentiatie, JIT compilatie naar XLA, en first-class ondersteuning voor programmatransformatie.⁹⁷ Het framework's functionele programmeerparadigma en composable transformation model sluiten natuurlijk aan bij TPU execution models en gedistribueerde parallelisme patronen.
De kern JAX abstractie past wiskundige transformaties toe op functies. Grad(f) berekent f's gradient. Jit(f) JIT-compileert f naar XLA. vmap(f) vectoriseert f over een nieuwe dimensie. Cruciaal is dat transformaties componeren: jit(grad(vmap(f))) werkt precies zoals verwacht, compilerend een gevectoriseerde gradient functie.⁹⁸ Het compositionele model maakt het mogelijk complexe gedistribueerde training loops te bouwen uit eenvoudige, testbare componenten.
SPMD (Single Program, Multiple Data) vertegenwoordigt JAX's gedistribueerde execution model. Programmeurs schrijven code alsof ze een enkel apparaat targeten, voegen dan sharding annotations toe die aangeven hoe tensors te partitioneren across meerdere TPU cores. De XLA compiler en GSPMD (General SPMD) subsysteem voegen automatisch communicatie operaties in om programma semantiek te behouden terwijl ze uitvoeren across gedistribueerde apparaten.⁹⁹
Sharding annotations gebruiken PartitionSpec om distributiestrategieën te declareren. PartitionSpec('batch', None) shardet de eerste dimensie van een tensor across de 'batch' as van de device mesh terwijl de tweede dimensie wordt gerepliceerd. PartitionSpec(None, 'model') implementeert tensor parallelisme door de tweede dimensie te partitioneren. De annotations kunnen worden gecomponeerd met willekeurige tensor ranks en device mesh dimensies.¹⁰⁰
GSPMD's automatische parallelisatie elimineert grote hoeveelheden boilerplate code. Traditionele gedistribueerde training vereist handmatig invoegen van een all-gather voor operaties die volledige tensors nodig hebben, een reduce-scatter na het berekenen van gedistribueerde gradiënten, en een all-reduce voor globale reducties. GSPMD analyseert sharding specificaties en voegt automatisch geschikte collectives in, waardoor programmeurs zich kunnen richten op het algoritme in plaats van communicatie engineering.¹⁰¹
De compiler propageert sharding beslissingen door de computation graph met behulp van constraint solving. Als operatie A een sharded tensor output die wordt geconsumeerd door operatie B, infereert GSPMD B's optimale sharding op basis van hoe de output wordt gebruikt, mogelijk alleen resharding operaties invoegend waar wiskundig noodzakelijk.¹⁰² De geautomatiseerde inferentie voorkomt de "sharding spaghetti" die handgeschreven gedistribueerde code plaagt.
JAX biedt fijnmazige controle wanneer automatisering tekortschiet. with_sharding_constraint forceert specifieke sharding op graph locaties, waarbij automatische inferentie wordt overschreven. Aangepaste PJIT (parallel JIT) annotations specificeren exacte device placement en sharding strategieën voor prestatiekritieke code paths. Het gelaagde model maakt snelle prototyping mogelijk met automatische sharding terwijl expert optimalisatie wordt ondersteund waar vereist.¹⁰³
Shardy ontstond als GSPMD's opvolger in 2025, implementerend verbeterde constraint propagatie algoritmes en betere behandeling van dynamische shapes.¹⁰⁴ Het nieuwe systeem stelt aanvullende optimalisatie mogelijkheden bloot door te redeneren over sharding keuzes gezamenlijk across grotere graph regio's in plaats van operatie-voor-operatie.
PyTorch/XLA: PyTorch naar TPU's brengen
PyTorch/XLA maakt het mogelijk PyTorch modellen op TPU's uit te voeren met minimale codewijzigingen, waardoor de kloof wordt overbrugd tussen PyTorch's imperatieve programmeermodel en XLA's graph-based compilatie.¹⁰⁵ De integratie balanceert het behouden van PyTorch's developer experience met het blootstellen van TPU-specifieke optimalisaties.
De fundamentele uitdaging komt voort uit PyTorch's eager execution filosofie. PyTorch voert operaties onmiddellijk uit wanneer Python statements worden uitgevoerd, waardoor debugging met standaard tools en natuurlijke control flow mogelijk wordt. XLA vereist het vastleggen van volledige computation graphs voor compilatie, waardoor spanning ontstaat tussen eager execution en de prestatievoordeelvan graph compilatie.¹⁰⁶
PyTorch/XLA 2.4 introduceerde eager mode ondersteuning, waarmee de impedance mismatch werd aangepakt. De implementatie traced dynamisch PyTorch operaties naar XLA graphs, waardoor ontwikkelaars standaard PyTorch code kunnen schrijven terwijl ze nog steeds profiteren van XLA compilatie.¹⁰⁷ De modus ruilt enkele compilatie optimalisatie mogelijkheden in voor ontwikkelingssnelheid en debugging eenvoud.
Graph mode blijft het primaire pad voor productie deployments. Ontwikkelaars markeren expliciet functies voor XLA compilatie met behulp van decorators of compilatie API's. De expliciete annotations maken agressieve optimalisatie mogelijk maar vereisen begrip van welke operaties moeten worden gefuseerd in een enkele XLA graph versus onafhankelijk uitgevoerd.¹⁰⁸
Pallas integratie brengt aangepaste kernel ontwikkeling naar PyTorch/XLA. Pallas biedt een low-level taal voor het schrijven van TPU kernels wanneer XLA's automatische fusion tekortschiet of gespecialiseerde operaties hand-optimalisatie vereisen.¹⁰⁹ De taal stelt TPU geheugenhiërarchie (VMEM, CMEM, HBM) en compute units (MXU, VPU) bloot terwijl het hoger-level blijft dan ruwe assembly.
Ingebouwde Pallas kernels implementeren prestatiekritieke operaties zoals FlashAttention en PagedAttention. FlashAttention's tiled attention berekening reduceert geheugenbandbreedtevereisten van O(n²) naar O(n) voor sequence lengte n, waardoor modellen veel langere sequenties kunnen verwerken binnen vaste geheugenbudgetten.¹¹⁰ PagedAttention optimaliseert key-value cache management voor serving, waarbij 5× speedup wordt behaald vergeleken met padded implementaties.¹¹¹
De PyTorch/XLA bridge bleek kritiek voor vLLM TPU—een high-performance serving framework oorspronkelijk ontworpen voor GPU's. De implementatie gebruikt daadwerkelijk JAX als een intermediate lowering pad zelfs voor PyTorch modellen, exploiterend JAX's superieure parallelisme ondersteuning terwijl PyTorch frontend compatibiliteit behouden blijft.¹¹² De architectuur bereikte 2-5× prestatieverbeteringen gedurende 2025 vergeleken met initiële prototypes.
Model compatibiliteitsuitdagingen blijven bestaan ondanks verbeteringen. Sommige PyTorch operaties missen XLA equivalenten, waardoor fallback naar CPU uitvoering wordt geforceerd die prestaties verslechtert. Dynamische control flow wordt slecht ondersteund door graph compilatie, waardoor vaak architecturale wijzigingen nodig zijn om dynamisch gedrag te vervangen door statische, compileerbare alternatieven. De PyTorch/XLA repository documenteert compatibiliteit en biedt migratie gidsen voor veelvoorkomende problematische patronen.¹¹³
Precision Formats: BFloat16, FP8, en Quantisatie
TPU's ondersteuning voor reduced-precision rekenkundige berekeningen maakt dramatische prestatie- en geheugenverbeteringen mogelijk terwijl acceptabele modelkwaliteit behouden blijft. Het begrijpen van de numerieke eigenschappen van verschillende formaten en wanneer elk toe te passen blijkt kritiek voor het bereiken van optimale prestaties.¹¹⁴
BFloat16 vertegenwoordigt Google's vroege inzet op reduced-precision training, eerst verschijnend in TPU v2. Het formaat behoudt FP32's 8-bit exponent terwijl de mantisse wordt afgekapt tot 7 bits (plus sign bit).¹¹⁵ Het volledige exponent bereik voorkomt de underflow en overflow die vroege FP16 training plaagden, waar gradiënten vaak buiten FP16's representeerbare bereik vielen.
De gereduceerde mantisse introduceert quantisatie fout maar heeft zelden impact op uiteindelijke modelkwaliteit. Engineers observeerden dat modellen getraind in bfloat16 typisch FP32-getrainde baselines matchen binnen statistische ruis, waarschijnlijk omdat de quantisatie werkt als een vorm van regularisatie, waardoor overfitting op kleine numerieke details wordt voorkomen.¹¹⁶ Het formaat halveert geheugenbandbreedte en capaciteitsvereisten vergeleken met FP32, direct vertaald naar prestatiewinst op geheugen-gebonden workloads.
FP8 neemt reduced precision verder, comprimeerend weights en activaties naar 8 bits. Twee standaard encodings bestaan: E4M3 (4-bit exponent, 3-bit mantisse) prioriteert precisie voor forward passes, terwijl E5M2 (5-bit exponent, 2-bit mantisse) bereik prioriteert voor backward passes waar gradient magnitudes breed variëren.¹¹⁷ Ironwood implementeert native FP8 ondersteuning voor beide formaten, terwijl eerdere TPU's FP8 emuleerden door software transformaties.¹¹⁸
Quantisatie bewustzijn tijdens training maakt FP8's numerieke succes mogelijk. Modellen getraind from scratch met FP8 of fine-getuned met FP8-aware technieken leren weight distributies die het formaat's beperkte precisie tolereren. Post-training quantisatie (converteren van FP32 modellen naar FP8 na training) verslechtert vaak kwaliteit zonder zorgvuldige kalibratie.¹¹⁹
INT8 quantisatie levert nog grotere geheugenbesparingen en inference speedups. Google's Accurate Quantized Training (AQT) maakt INT8 training op TPU's mogelijk met minimaal kwaliteitsverlies vergeleken met bfloat16 baselines.¹²⁰ De techniek past quantisatie-aware training toe from scratch, waardoor modellen kunnen aanpassen aan INT8's beperkingen tijdens leren in plaats van door post-training benadering.
Mixed-precision strategieën combineren formaten strategisch. Forward passes kunnen FP8 gebruiken voor activaties en weights, backward passes gebruiken FP8 E5M2 of bfloat16 voor gradiënten, en optimizer states blijven in FP32 voor numerieke stabiliteit tijdens weight updates.¹²¹ De gemixte aanpak balanceert snelheid, geheugen, en nauwkeurigheid, vaak bereiking 90%+ van FP32 kwaliteit terwijl 4× sneller draait.
Precision tradeoffs strekken zich uit voorbij snelheid en geheugen tot numerieke stabiliteitsoverwegingen. Batch normalisatie, layer normalisatie, en softmax vereisen zorgvuldige numerieke behandeling in reduced precision. Grote exponentials in softmax kunnen FP8 of bfloat16 bereiken overflow; het aftrekken van de maximum logit voor exponentiation voorkomt overflow terwijl wiskundige equivalentie behouden blijft.¹²² De XLA compiler implementeert deze transformaties automatisch wanneer veilig, maar aangepaste operaties vereisen soms handmatige numerieke engineering.
Programmeermodellen en Parallellismestrategieën
SPMD en Automatische Partitionering
Het Single Program, Multiple Data (SPMD) paradigma vormt fundamenteel hoe programmeurs denken over TPU-uitvoering. In plaats van expliciete message-passing code te schrijven om meerdere processen te coördineren, schrijven ontwikkelaars een enkel programma en annoteren hoe data gepartitioneerd moet worden over apparaten.¹²³ De compiler handelt de mechanische details van distributie, communicatie en synchronisatie af.
GSPMD (General SPMD) implementeert de automatische partitioneringslogica in XLA. Het systeem analyseert tensor sharding annotaties en de computationele grafiekstructuur om te bepalen waar operaties uitvoeren op welke apparaten en welke communicatie vereist is om correcte semantiek te behouden.¹²⁴ De automatisering elimineert hele klassen van bugs die voorkomen in handgeschreven gedistribueerde code—niet-overeenkomende tensor vormen, incorrecte collectieve operatieordeningen, en deadlocks door onjuiste synchronisatie.
De constraint propagatie-engine van de compiler leidt sharding beslissingen af van minimale annotaties. Het annoteren van alleen de input en output sharding van een model volstaat vaak; GSPMD propageert constraints door tussenliggende operaties en selecteert automatisch efficiënte distributies.¹²⁵ Wanneer meerdere geldige shardings bestaan voor een operatie, schat de compiler de communicatiekosten van alternatieven en selecteert de optie met de laagste kosten.
Geavanceerde optimalisaties overlappen communicatie met computatie. All-reduce operaties die gradiënten synchroniseren over replica's kunnen starten zodra de gradiënten van de eerste laag voltooid zijn, uitvoerend parallel met backward passes voor daaropvolgende lagen.¹²⁶ De compiler plant automatisch collectieven om overlap te maximaliseren, waarbij adequate communicatietijd met 2× of meer gereduceerd wordt vergeleken met sequentiële uitvoering.
Rematerialisatie wisselt computatie in voor geheugen. In plaats van alle forward pass activaties op te slaan voor gradiëntcomputation, herrekent de compiler selectief activaties tijdens backward passes wanneer geheugendruk drempels overschrijdt.¹²⁷ De afweging werkt bijzonder goed op TPU's waar compute vaak geheugenbandbreedte overtreft, waardoor herrekening goedkoper is dan geheugenverkeer.
Data Parallellisme, Tensor Parallellisme, en Pipeline Parallellisme
Data parallellisme vertegenwoordigt de meest eenvoudige gedistribueerde trainingsstrategie: repliceer het complete model over N apparaten en verwerk verschillende data batches op elke replica. Na het lokaal berekenen van gradiënten, aggregeert een all-reduce gradiënten over replica's, en alle apparaten passen identieke gewichtupdates toe.¹²⁸ De benadering schaalt lineair totdat communicatietijd computatietijd domineert—typisch rond 1.000 GPU's met Ethernet-netwerken maar 10.000+ TPU's met ICI.¹²⁹
Tensor parallellisme (ook wel model parallellisme genoemd) partitioneert individuele operaties over apparaten. Een matrixvermenigvuldiging Y = W @ X splitst de gewichtenmatrix W over apparaten, waarbij elk een deel van de output berekent.¹³⁰ De strategie maakt het trainen van modellen mogelijk die het geheugen van één apparaat overschrijden door parameter opslag en computatie te distribueren.
Het communicatiepatroon voor tensor parallellisme verschilt aanzienlijk van dat voor data parallellisme. In plaats van all-reduce na elke laag, vereist tensor parallellisme een all-gather vóór operaties die volledige tensoren vereisen en een reduce-scatter na gedistribueerde computaties.¹³¹ Het communicatievolume schaalt met model activatiegrootte in plaats van parametergrootte, waardoor verschillende knelpunten ontstaan dan bij data parallellisme.
Pipeline parallellisme partitioneert sequentiële modellagen over apparaten, waarbij verschillende micro-batches op verschillende stadia simultaan verwerkt worden. GPipe introduceerde de strategie met zorgvuldige planning om pipeline-benutting te maximaliseren terwijl geheugengebruik begrensd wordt.¹³² Elk apparaat verwerkt de forward pass van één micro-batch, stuurt activaties naar de volgende fase, verwerkt dan de volgende micro-batch—waardoor een pipeline ontstaat waar alle apparaten continu werken na de initiële opstartfase.
Gradiëntveroudering compliceert pipeline parallellisme. Apparaten updaten gewichten met gradiënten berekend van activaties die potentieel tientallen micro-batches oud zijn, waardoor veroudering ontstaat die convergentie kan schaden.¹³³ Geavanceerde planningsalgoritmen zoals PipeDream minimaliseren veroudering terwijl hoge doorvoer behouden blijft, en empirische resultaten tonen aan dat de meeste modellen matige veroudering tolereren zonder kwaliteitsdegradatie.
3D parallellisme combineert alle drie strategieën. Data parallellisme distribueert over de "data" dimensie, tensor parallellisme over de "model" dimensie, en pipeline parallellisme over de "pipeline" dimensie.¹³⁴ Het zorgvuldig balanceren van dimensies gebaseerd op modelarchitectuur, hardware topologie en communicatiekosten maximaliseert doorvoer. GPT-3-schaal modellen gebruiken gewoonlijk 3D parallellisme met data parallellisme over 8-16 replica's, tensor parallellisme over 4-8 GPU's, en pipeline parallellisme over 4-16 stadia.
Sharding Strategieën en Optimalisatie
Het selecteren van sharding strategieën vereist begrip van de mathematische operaties en hun data-afhankelijkheden. Matrixvermenigvuldiging C = A @ B staat meerdere geldige shardings toe: repliceer zowel A als B en bereken gedeeltelijke resultaten (communicatie vóór computatie), shard B kolomsgewijs en verzamel resultaten (communicatie na computatie), of shard A rijsgewijs en B kolomsgewijs zonder communicatie maar kleinere per-apparaat matrices.¹³⁵
Collectieve operatiekosten bepalen optimale strategieën. All-reduce kosten schalen lineair met tensorgrootte maar sublineair met apparaataantal met tree-gebaseerde of ring-gebaseerde reductiealgoritmen:¹³⁶ All-gather en reduce-scatter vertonen verschillende schaalingseigenschappen. De compiler modelleert deze kosten en selecteert sharding strategieën die totale communicatietijd minimaliseren.
Sequentie parallellisme ontstaat als kritiek voor grote taalmodellen. Attention mechanismen creëren geheugenknelpunten omdat key-value caches groeien met sequentielengte en batch grootte. Partitionering langs de sequentiedimensie distribueert de geheugenlast over apparaten terwijl communicatie alleen geïntroduceerd wordt voor attention computatie zelf.¹³⁷
Expert parallellisme handelt Mixture-of-Experts (MoE) modellen af waar verschillende experts verschillende tokens verwerken. De sharding strategie repliceert gedeelde lagen over alle apparaten maar partitioneert experts, waarbij elk token gerouteerd wordt naar zijn aangewezen expert apparaat.¹³⁸ De dynamische routing creëert onregelmatige communicatiepatronen die traditionele collectieve operaties uitdagen, waardoor geavanceerde runtime systemen vereist zijn om latentie en load onbalans te minimaliseren.
Optimizer state sharding reduceert geheugenoverhead voor grote modellen. Optimizers zoals Adam slaan momentum en variantiestatistieken op voor elke parameter, wat geheugenvereisten verdrievoudigt bovenop die voor parameters alleen. Het sharden van optimizer states over apparaten terwijl parameters gerepliceerd blijven, maakt het trainen van grotere modellen mogelijk binnen vaste geheugenbudgetten.¹³⁹ De strategie vereist het verzamelen van optimizer state updates tijdens gewichtcomputaties maar reduceert substantieel de per-apparaat geheugenvoetafdruk.
Prestatie-analyse en Benchmarking
MLPerf Resultaten en Concurrentiepositie
MLPerf biedt industriestandaard benchmarks die de prestaties van AI-accelerators meten voor training- en inference-werklasten. Google dient regelmatig TPU-resultaten in die concurrerende prestaties aantonen, en de evolutie tussen generaties toont duidelijke architectuurverbeteringen.¹⁴⁰
TPU v5e behaalde leidende resultaten in 8 van de 9 MLPerf training-categorieën.¹⁴¹ De breedte toont architecturale veelzijdigheid voorbij alleen grote taalmodellen—concurrerende prestaties voor computer vision, aanbevelingssystemen en wetenschappelijke computingwerklasten. BERT-training werd 2.8× sneller voltooid dan NVIDIA A100 GPU's, wat de transformer-geoptimaliseerde architectuur valideert.¹⁴²
MLPerf Training v5.0, aangekondigd in juni 2025, introduceerde een Llama 3.1 405B benchmark die het grootste model in de suite vertegenwoordigt.¹⁴³ De benchmark belast multi-node scaling, communicatie-overhead en geheugenkapaciteit meer dan eerdere tests. Google Cloud participeerde met TPU-inzendingen, hoewel gedetailleerde prestatievergelijkingen nog onder embargo staan in afwachting van publicatie van officiële resultaten.
MLPerf Inference v5.0 bevatte vier nieuwe benchmarks: Llama 3.1 405B, Llama 2 70B voor lage-latentie applicaties, RGAT graph neural networks, en PointPainting voor 3D objectdetectie.¹⁴⁴ De diversiteit duwt accelerators voorbij conventionele transformer-werklasten naar opkomende applicatiedomeinen waar architectuurassumpties kunnen verschillen.
Inference-benchmarks bevoordelen vooral TPU's architecturale sterktes. Batch inference-werklasten benutten de MXU's massale parallelisme, waarbij 4× hogere doorvoer wordt behaald dan concurrerende accelerators voor transformer serving.¹⁴⁵ Single-query latency profiteert van TPU's deterministische uitvoering en afwezigheid van thermal throttling, wat consistente latency levert zonder de prestatievariatie die sommige GPU-implementaties plaagt.
Energie-efficiëntiemetrieken tonen dat TPU-voordelen uitbreiden over generaties. TPU v4 demonstreerde 2.7× betere prestaties per watt dan TPU v3, en Trillium verbeterde 67% ten opzichte van v5e.¹⁴⁶ Ironwood claimt 2× betere prestaties per watt dan Trillium ondanks significant hogere absolute prestaties.¹⁴⁷ De efficiëntieverbeteringen stapelen zich op over duizenden-chip pods, wat zich vertaalt naar miljoenen dollars aan operationele datacenterkosten.
Werkelijke Training- en Inference-prestaties
Productiewerklasten onthullen prestatiekenmerken die afwezig zijn in synthetische benchmarks. Google publiceert resultaten van interne services die TPU-gedrag aantonen onder echte gebruikspatronen en schaalvereisten.¹⁴⁸
ResNet-50 ImageNet training wordt voltooid in 28 minuten op TPU pods, een veelgeciteerde benchmark voor computer vision werklastprestaties.¹⁴⁹ De time-to-accuracy metriek vangt het complete trainingsproces, inclusief data loading, augmentatie, gedistribueerde gradiënt synchronisatie, en checkpoint opslaan—niet alleen theoretische FLOPs.
T5-3B taalmodel training toont TPU-voordelen op transformer-architecturen. Het 3-miljard-parameter model traint in 12 uur op TPU pods, vergeleken met 31 uur op equivalente GPU-configuraties.¹⁵⁰ De 2.6× versnelling komt voort uit hardware-versnelde attention-operaties, efficiënt geheugenbandbreedte gebruik, en geoptimaliseerde collectieve communicaties.
GPT-3 schaal werklasten (175B parameters) bereiken 1.7× snellere time-to-accuracy op TPUs dan op hedendaagse GPU's.¹⁵¹ De prestatieafstand wordt groter voor nog grotere modellen, waar geheugenkapaciteit en bandbreedte kritieke beperkingen worden. Ironwood's 192GB HBM3e maakt het serveren van modellen mogelijk die complexe tensor parallelisme vereisen op alternatieven met lager geheugen.
Schaalefficiëntie metingen tonen bijna lineaire speedup tot enorme schalen. Google Research rapporteerde 95% schaalefficiëntie bij 32,768 TPUs voor specifieke transformer training-werklasten.¹⁵² De metriek betekent dat 32,768 TPUs 95% van de prestatie leverden die perfecte lineaire schaling zou voorspellen—opmerkelijk gezien communicatie-overhead toeneemt met schaal.
FLOPS-utilizatiemetrieken onthullen hoe effectief werklasten beschikbare compute benutten. Transformer-modellen bereiken typisch 90% FLOPS-utilization op TPUs, wat betekent dat 90% van de theoretische piekprestatie wordt omgezet in werkelijk werk.¹⁵³ Hoge utilization komt voort uit operatiefusie die geheugenknelpunten elimineert, systolic-array efficiëntie in grote-matrix vermenigvuldigingen, en compiler-optimalisaties die verspilde cycli minimaliseren.
Productie inference-services tonen volgehouden prestaties over miljarden queries per dag. Google Translate verwerkt 1 miljard verzoeken dagelijks op TPUs.¹⁵⁴ YouTube-aanbevelingen bedienen 2 miljard gebruikers met TPU-versnelde modellen.¹⁵⁵ Google Photos analyseert 28 miljard afbeeldingen maandelijks voor zoek- en organisatiefuncties.¹⁵⁶ De operationele schaal valideert betrouwbaarheid en kostenefficiëntie voorbij onderzoeksprototype-implementaties.
Energie-efficiëntie en Total Cost of Ownership
Stroomverbruik beïnvloedt direct datacenter operationele kosten en milieuduurzaamheid. TPU's energie-efficiëntieverbeteringen over generaties reduceren zowel operationele uitgaven als koolstofemissies op schaal.¹⁵⁷
TPU v4 had gemiddeld slechts 200W stroomverbruik in productiewerklasten ondanks een 250W TDP-specificatie.¹⁵⁸ De ruimte tussen gemiddeld en piekstroom maakt flexibel thermisch ontwerp en provisioning mogelijk. Contrast met GPU's, waar volgehouden werklasten vaak TDP-limieten raken, wat conservatieve rack-stroombudgetten vereist.
Ironwood's 600W TDP vertegenwoordigt hoger absoluut stroomverbruik dan eerdere generaties maar levert dramatisch meer compute per watt.¹⁵⁹ De 4.6 PFLOPS FP8-prestatie per chip geeft ongeveer 7.7 TFLOPS per watt—concurrerend met of beter dan hedendaagse GPU-efficiëntie op equivalente werklasten.
Datacenter power usage effectiveness (PUE) versterkt chip-niveau efficiëntie. Google's TPU datacenters bereiken een PUE van 1.1, wat slechts 10% stroomoverhead betekent voorbij chipverbruik voor koeling, stroomconversie, en networking.¹⁶⁰ Industriegemiddelde PUE varieert van 1.5 tot 2.0, waar 50-100% extra stroom gaat naar infrastructuuroverhead. De lage PUE komt voort uit geavanceerde koelsystemen, efficiënte stroomlevering, en doelbewust datacenterontwerp geoptimaliseerd voor ML-werklasten.
Koolstofintensiteit overwegingen strekken zich uit voorbij stroom tot energiebronnen. Google opereert TPU-datacenters op koolstofneutrale stroom door hernieuwbare energie inkoop en koolstofcompensatieprogramma's.¹⁶¹ De koolstofboekhouding wordt steeds belangrijker voor organisaties die Scope 2-emissies van cloud computing volgen.
Total cost of ownership (TCO) analyse moet rekening houden met aanschafkosten, stroomverbruik, koelingvereisten, en onderhoudsuitgaven. TPU-implementaties tonen gewoonlijk 20-30% TCO-reducties vergeleken met equivalente GPU-installaties, hoofdzakelijk gedreven door superieure prestaties per watt en verminderde koelcomplexiteit.¹⁶²
Koelinfrastructuurkosten schalen niet-lineair met stroomdichtheid. Luchtgekoelde racks toppen typisch uit bij 15-20kW per rack voordat exotische koeloplossingen nodig zijn. Hoge-stroom GPU's duwen deze limieten, soms vloeistofkoeling infrastructuur necessiterend met substantieel hogere kapitaal- en operationele kosten. TPU's efficiëntie houdt meer implementaties binnen het luchtkoeling bereik, wat datacenterontwerp vereenvoudigt.¹⁶³
Technische Voordelen: Waar TPUs Uitblinken
Hardware-Versnelde Collectieve Operaties
De gespecialiseerde ondersteuning voor collectieve operaties in TPU ICI levert een van de meest significante voordelen op ten opzichte van traditionele genetwerkte versnellers. All-reduce, de werkpaard-operatie voor het synchroniseren van gradiënten tijdens gedistribueerde training, voert 10× sneller uit op TPU ICI dan gelijkwaardige Ethernet-gebaseerde GPU implementaties.¹⁶⁴
Het prestatieverschil komt voort uit architecturale integratie. Ethernet-gebaseerde collectieve operaties doorlopen meerdere lagen: applicatiecode roept de collectieve bibliotheek aan (NCCL, Horovod, etc.), die pakketten genereert die worden doorgegeven aan de netwerkstack, die data overdraagt naar de NIC, die serialiseert naar de draad, switches doorloopt, deserialiseert bij ontvangende NICs, en het proces omkeert. Elke laag voegt latentie toe, kopieert data door geheugenhiërarchieën, en verbruikt CPU-cycli voor protocolverwerking.¹⁶⁵
TPU ICI implementeert collectieve operaties in hardware zonder de softwarelaag te doorlopen. De operatie start direct vanuit de TensorCore, streamt data over toegewijde ICI-links, en voltooit zonder de host-CPU te betrekken. Het directe hardwarepad elimineert de overhead die traditionele implementaties domineert.¹⁶⁶
De optische circuit-switch topologie maakt optimale collectieve algoritmen mogelijk. De ring-gebaseerde all-reduce vereist slechts 2(N-1) berichten voor N apparaten, en de torus-topologie biedt kortste-pad routing, wat latentie minimaliseert.¹⁶⁷ De uniforme bisectiebandbreedte voorkomt hotspots waar slecht geroutede collectieve operaties netwerklinks verstoppen.
Unified Memory Space en Vereenvoudigde Programmering
TPU's unified memory model vereenvoudigt programmering vergeleken met GPU's complexe geheugenhiërarchieën. Programmeurs redeneren over een enkele HBM-pool in plaats van overdrachten te beheren tussen host-RAM, GPU globaal geheugen, gedeeld geheugen, en registerbestanden. Het vereenvoudigde model vermindert bugs en maakt snellere ontwikkelingssnelheid mogelijk.¹⁶⁸
Geheugenfragmentatie verdwijnt als zorgpunt. GPU's wijzen geheugen toe van een gefragmenteerde heap, waar toewijzingen en deallocaties over tijd gaten creëren die compactie vereisen. TPU-geheugenbeheer via de compiler's statische analyse vermijdt runtime fragmentatie volledig—tensors krijgen vooraf bepaalde locaties toegewezen gebaseerd op de computatiegrafiek.¹⁶⁹
Het programmeermodel elimineert hele klassen van CUDA-fouten. Geen "illegal memory access" meer door incorrecte pointer-rekenkunde, geen cache coherentie bugs tussen CPU en GPU, geen synchronisatiefouten door ontbrekende cudaDeviceSynchronize() calls. De hogere-niveau abstractie voorkomt de gebruikelijke valkuilen in CUDA-programmering.¹⁷⁰
Deterministische Uitvoering en Reproduceerbaarheid
Floating-point non-associativiteit creëert reproduceerbaarheidsuitdagingen in parallel computing. De uitdrukking (a + b) + c kan verschillende resultaten opleveren dan a + (b + c) door afrondingsfouten, en parallelle reducties kunnen in verschillende volgordes optellen tussen runs afhankelijk van race-condities.¹⁷¹
TPU-uitvoering vertoont sterkere determinisme dan typische GPU-implementaties. Het vaste dataflow-patroon van de systolic array zorgt voor identieke operatievolgorde tussen runs. Collectieve operaties volgen deterministische reductiebomen in plaats van opportunistische aggregatie gebaseerd op aankomstvolgorde. De voorspelbaarheid maakt reproduceerbare training mogelijk waar identieke hyperparameters en data bit-identieke modelgewichten produceren.¹⁷²
Debugging profiteert enorm van determinisme. Non-deterministische training maakt het root-causen van failures bijna onmogelijk—komt de NaN van een echte algoritmische bug of willekeurige race-conditie? Deterministische uitvoering betekent dat failures betrouwbaar reproduceren, waardoor systematische debugging-benaderingen mogelijk worden.¹⁷³
Wetenschappelijke computing-applicaties waarderen reproduceerbaarheid bijzonder. Klimaatmodellen, medicijnontdekkingssimulaties, en natuurkundeonderzoek vereisen verifieerbare resultaten die verschillende onderzoekers in staat stellen identieke uitkomsten te reproduceren. TPU's determinisme ondersteunt de wetenschappelijke methode beter dan racende non-deterministische alternatieven.¹⁷⁴
Compiler-Optimalisaties en Ontwikkelaarproductiviteit
XLA's agressieve optimalisatie levert substantiële prestatieverbeteringen "out of the box" zonder handmatige tuning. Onderzoekers rapporteren 40% verbeteringen in modeldoorvoer door compilatie alleen vergeleken met eager execution frameworks.¹⁷⁵ De prestatie komt gratis—geen kernel engineering vereist.
Fusion-optimalisatie komt ontwikkelaars bijzonder ten goede. Het handmatig fuseren van operaties in CUDA vereist het schrijven van aangepaste kernels, correctheidstesten, en onderhoud van de code over frameworkversies. XLA fuseert automatisch operaties en updates, en past fusiestrategieën aan naarmate modellen evolueren, wat de onderhoudsbelasting elimineert.¹⁷⁶
Layout-transformatie automatisering bespaart weken van handmatige optimalisatie. Het bepalen van optimale tensor-layouts voor GPU vereist het profileren van verschillende arrangementen, handmatig invoegen van transposes, en zorgvuldig beheren van geheugentoewijzingspatronen. XLA probeert layouts automatisch en selecteert de snelste, waardoor ontwikkelaars zich kunnen richten op modelarchitectuur in plaats van low-level performance engineering.¹⁷⁷
De productiviteitswinst versterkt zich voor onderzoeksteams. Tijd bespaard op infrastructuuroptimalisatie versnelt wetenschappelijke vooruitgang, waardoor meer experimenten en snellere iteratiecycli mogelijk worden. Organisaties rapporteren 3× ontwikkelingssnelheidsverbeteringen bij de overgang van GPU CUDA-programmering naar TPU JAX-gebaseerde workflows.¹⁷⁸
## Technische Beperkingen en Nadelen
Platform Lock-In en On-Premises Beperkingen
TPU-toegang is uitsluitend beschikbaar via Google Cloud Platform, wat on-premises implementatie verhindert en zorgen over vendor lock-in oproept.¹⁷⁹ Organisaties met data sovereignty-vereisten, air-gapped netwerken, of beleid tegen publieke cloud kunnen geen gebruik maken van TPU, ongeacht technische superioriteit.
Deze beperking wordt steeds belangrijker nu AI kritieke infrastructuur wordt. Afhankelijkheid van één cloud provider creëert bedrijfscontinuïteitsrisico's—prijswijzigingen, beschikbaarheidsstoringen, of stopzetting van services kunnen kostbare migraties forceren.¹⁸⁰ GPU's beschikbaarheid van meerdere leveranciers (NVIDIA hardware draaiend op AWS, Azure, GCP, en on-prem) biedt optionaliteit die TPU architecturaal uitsluit.
Multi-cloud strategieën ondervinden wrijving. Organisaties die standaardiseren op TPU kunnen niet eenvoudig uitbreiden naar andere clouds of multi-cloud redundantie implementeren zonder modellen opnieuw te trainen of aparte codebases te onderhouden voor verschillende accelerator architecturen.¹⁸¹ De operationele complexiteit van hybride GPU/TPU implementaties weegt vaak zwaarder dan kostenbesparing door optimale accelerator selectie.
CUDA Ecosysteem Volwassenheidskloof
NVIDIA's CUDA platform heeft 15+ jaar aan ecosysteem ontwikkeling, bibliotheken, documentatie, en community kennis geaccumuleerd die TPU niet kan evenaren.¹⁸² De volwassenheidskloof manifesteert zich in talloze pijnpunten voor TPU adoptie.
Bibliotheek beschikbaarheid bevoordeelt CUDA overweldigend. Gespecialiseerde domeinen zoals computer graphics, moleculaire dynamica, computational fluid dynamics, en genomica hebben duizenden CUDA-geoptimaliseerde bibliotheken geaccumuleerd over de afgelopen decennia. TPU equivalenten bestaan vaak niet, wat ofwel CPU fallback vereist (wat prestaties vernietigt) of maanden aan porting inspanning.¹⁸³
Community ondersteuning verschilt met ordes van grootte. Stack Overflow bevat honderdduizenden CUDA vragen met gedetailleerde antwoorden—GitHub repositories tellen in de miljoenen. Conferentie presentaties, academische papers, en blog posts focussen voornamelijk op CUDA programmering. TPU programmeurs ondervinden relatief schaarse bronnen, langere debugging cycli, en minder experts om te raadplegen.¹⁸⁴
Educatief materiaal en tutorials richten zich overweldigend op CUDA. Universiteitscursussen onderwijzen GPU programmering met CUDA. Online cursussen focussen op CUDA. De talent pipeline produceert veel meer CUDA-ervaren engineers dan TPU experts, wat uitdagingen creëert bij het werven en trainen van personeel.¹⁸⁵
Custom kernel ontwikkeling illustreert de ecosysteem kloof. Het schrijven van geoptimaliseerde CUDA kernels blijft niet triviaal maar profiteert van uitgebreide documentatie, profiling tools, en voorbeeldcode. Pallas maakt custom TPU kernels mogelijk, maar met minder volwassen tooling en een kleinere kennisbasis. De leercurve ontmoedigt alles behalve de meest prestatie-kritieke optimalisaties.¹⁸⁶
Workload Specialisatie en Flexibiliteitsbeperkingen
TPU's architectuur optimaliseert voor specifieke workload patronen—primair dense matrix multiplicatie met reguliere toegangspatronen en grote batch sizes. Operaties buiten de sweet spot ondervinden prestatie afgronden.¹⁸⁷
Dynamische shapes dagen TPU uitvoeringsmodellen uit. De XLA compiler veronderstelt vaste tensor dimensies voor optimalisatie en code generatie. Modellen met variabele sequence lengtes, dynamische control flow, of data-afhankelijke shapes vereisen padding naar maximum groottes (verspilling van compute en geheugen) of recompilatie voor elke afzonderlijke shape (wat prestaties vernietigt).¹⁸⁸
Sparse operaties krijgen beperkte ondersteuning ondanks SparseCore. Sparse matrix-matrix multiplicatie, een workload veelvoorkomend in scientific computing en graph neural networks, mist efficiënte implementaties op MXU of VPU. De gespecialiseerde SparseCore handelt embedding tables af maar niet algemene sparse linear algebra.¹⁸⁹
Small batch inference onderbenut TPU's parallelle bronnen. De 256×256 systolic array gedijt op grote matrices die het grid vullen met productief werk. Single-query inference laat de meeste MACs inactief, wat per-query latency en kosten oplevert die slechter zijn dan GPU alternatieven geoptimaliseerd voor low-batch scenario's.¹⁹⁰
Onregelmatige berekening patronen verslaan systolic array efficiëntie. Algoritmes met onvoorspelbare vertakking, recursieve structuren, of pointer-chasing geheugen toegang vertonen slechte TPU prestatie omdat de vaste dataflow zich niet kan aanpassen aan runtime-afhankelijk gedrag.¹⁹¹
Non-ML workloads profiteren zelden van TPU acceleratie. Wetenschappelijke simulaties, video encoding, blockchain verificatie, en rendering draaien allemaal sneller op GPU's meer algemene architectuur ondanks TPU's hogere piek FLOPs voor matrix operaties.¹⁹²
Debugging en Development Tooling Kloven
NVIDIA's ecosysteem omvat volwassen profiling tools (Nsight Systems, Nsight Compute, nvprof), debuggers (cuda-gdb), en analyse frameworks die over decennia zijn verfijnd. TPU tooling bestaat, maar loopt substantieel achter in verfijning.¹⁹³
XProf biedt basis profiling door TensorBoard integratie maar mist de granulaire hardware counter toegang die NVIDIA tools blootleggen. Begrip van cache miss rates, occupancy, warp divergence, of memory bank conflicts—allemaal kritieke GPU optimalisatie metrieken—heeft geen TPU equivalent omdat de architectuur fundamenteel verschilt.¹⁹⁴
Foutmeldingen verbergen vaak de hoofdoorzaken. XLA compilatie fouten produceren cryptische berichten over shape mismatches of niet-ondersteunde operaties, zonder duidelijke begeleiding naar oplossing. CUDA fouten, hoewel berucht om hun onbehulpzaamheid, profiteren van vijftien jaar StackOverflow uitleg en tribale kennis.¹⁹⁵
Debugging van gedistribueerde training op multi-chip pods benadert onmogelijkheid zonder gespecialiseerde tools. Race conditions, gradient synchronisatie bugs, en collective operation failures manifesteren zich als non-deterministische fouten (ironisch, ondanks TPU's determinisme voordelen) die inconsistent reproduceren en systematische diagnose weerstaan.¹⁹⁶
De iteratie loop strekt zich pijnlijk uit voor complexe modellen. Recompilatie voor shape wijzigingen of architectuur modificaties kan minuten vereisen, wat ontwikkeling bevriest terwijl de compiler malen. CUDA's eager execution model maakt snellere iteratie mogelijk ondanks lagere piekprestatie.¹⁹⁷
Real-World Deployments: Productie op Schaal
Anthropic Claude: Multi-Platform Strategie
Anthropic's aankondiging in oktober 2025 over de uitrol van meer dan een miljoen TPU chips vertegenwoordigt de grootste publiekelijk bekendgemaakte AI accelerator commitment in de geschiedenis.¹⁹⁸ Het bedrijf is van plan toegang te krijgen tot ruim een gigawatt aan rekencapaciteit die in 2026 online komt, exclusief voor het trainen en bedienen van toekomstige Claude modellen.
De schaal overstijgt eerdere uitrollingsprojecten met ordes van grootte. Een miljoen chips, geconfigureerd als Ironwood TPUs, zouden ongeveer 4,6 exaflops aan FP8 rekenkracht leveren—meer dan 40× de totale prestaties van de gehele Top500 supercomputer lijst van slechts vijf jaar geleden.¹⁹⁹ De toezegging signaleert vertrouwen in TPU architectuur voor frontier model ontwikkeling op schalen die eerder als sciencefiction werden beschouwd.
Anthropic hanteert een doelbewuste multi-platform hardware strategie verspreid over Google's TPUs, Amazon's Trainium, en NVIDIA GPUs.²⁰⁰ De diversificatie biedt capaciteitsverzekering, prijsonderhandelingskracht, en geografische spreiding. Claude wordt wereldwijd bediend vanuit uitrollingsprojecten op alle drie platforms, met request routing gebaseerd op capaciteitsbeschikbaarheid en regionale latency vereisten.
Het technische postmortem van het bedrijf uit augustus 2025 onthulde uitrolcomplexiteiten op schaal. Een misconfiguratie op de Claude API TPU servers veroorzaakte token-generatie fouten, waarbij af en toe onverwacht hoge kansen werden toegekend aan Thai of Chinese karakters in Engelse prompts.²⁰¹ Het incident toonde aan dat zelfs eenvoudige fouten onvoorspelbaar escaleren door systemen die dagelijks miljarden tokens verwerken.
Een aparte uitrol veroorzaakte een latente bug in de XLA: TPU compiler die Claude Haiku 3.5 beïnvloedde. De bug had maandenlang onopgemerkt bestaan totdat een specifieke combinatie van model architectuur en compiler flag het defect blootlegde.²⁰² De ontdekking benadrukt dat productie-uitrol randgevallen vindt die afwezig zijn in ontwikkelings- en staging omgevingen.
Anthropic engineers noemden TPU's prijs-prestatie verhouding en efficiëntie als primaire selectiecriteria. De overtuigende economie versnelt ontwikkeling door grotere experimenten binnen vaste budgetten mogelijk te maken.²⁰³ Het trainen van grotere modellen, het verkennen van meer hyperparameter configuraties, en sneller itereren vloeien allemaal voort uit het verlagen van kosten per FLOP.
Google Gemini: Ontworpen voor TPU Vanaf het Begin
Google's Gemini modellen trainen en bedienen exclusief op TPUs, met architectuur en trainingsprocedures die vanaf het begin zijn meegeconstrueerd voor TPU karakteristieken.²⁰⁴ De strakke koppeling maakt het mogelijk om TPU-specifieke optimalisaties te benutten die cross-platform modellen niet kunnen gebruiken.
Gemini uitrol gebruikt naar verluidt 50.000 TPU v6e chips voor het trainen en bedienen van de meest significante model varianten.²⁰⁵ De enorme pod schalen vereisen geavanceerde orkestratie—job scheduling over duizenden chips, checkpoint coördinatie om knelpunten te voorkomen, failure recovery om verloren werk te minimaliseren, en real-time monitoring om gedegradeerde nodes te identificeren voordat failures zich verspreiden.
Google trainde Gemini 2.0 op Trillium TPUs, waarbij de zesde-generatie architectuur werd gevalideerd voor frontier model ontwikkeling.²⁰⁶ De trainingsrun demonstreerde schaalefficiëntie naar ongekende chip aantallen, met sterke schaling voorbij typische plateaus waar communicatie overhead domineert.
Model serving infrastructuur benut specifiek TPU inference optimalisaties. Batch processing aggregeert meerdere gebruikersverzoeken om MXU benutting te maximaliseren. Key-value cache management benut HBM capaciteit, waardoor langdurige context verwerking mogelijk is zonder disk swapping. De architectuur levert sub-seconde responstijden voor complexe queries terwijl massale globale request volumes worden afgehandeld.²⁰⁷
Productie monitoring systemen volgen continu 50.000+ TPUs, waarbij afwijkingen worden gedetecteerd die model kwaliteit of beschikbaarheid zouden kunnen verslechteren.²⁰⁸ De telemetrie legt error rates, latency percentielen, throughput, geheugendruk, en thermische karakteristieken vast van elke chip. Machine learning modellen analyseren de telemetrie streams zelf, waarbij failures worden voorspeld voordat ze optreden en preventief onderhoud wordt geactiveerd.
Aanvullende Productie Uitrollingsprojecten
Midjourney migreerde van GPU naar TPU infrastructuur, waarbij een 65% kostenbesparing en 40% latency verbetering werd behaald voor image-generatie workloads.²⁰⁹ De kunst generatie service verwerkt 300.000 afbeeldingen per minuut bij piekbelasting, wat massale compute throughput en consistente prestaties vereist onder wisselende verkeerspatronen.
Cohere's taalmodellen op TPU behaalden 3× de throughput van eerdere GPU uitrollingsprojecten.²¹⁰ De versnelling maakte het mogelijk om meer klanten te bedienen vanaf dezelfde infrastructuur footprint, wat direct de bedrijfseconomie verbeterde. Het bedrijf gebruikte JAX's SPMD capaciteiten om modellen efficiënt te paralleliseren over TPU pods.
Snap verzekerde capaciteit voor 10.000 TPU v6e chips ter ondersteuning van augmented reality functies, aanbevelingssystemen, en creatieve AI tools.²¹¹ De uitrol overspant meerdere geografische regio's, wat lage latency voor Snapchat's wereldwijde gebruikersbestand verzekert terwijl model consistentie over regio's wordt gehandhaafd.
Academische instellingen adopteren TPU steeds meer voor onderzoek. Het TPU Research Cloud (TRC) programma biedt gratis TPU toegang aan onderzoekers, wat experimenten mogelijk maakt op schalen die eerder alleen toegankelijk waren voor goed gefinancierde corporate labs.²¹² De democratisering versnelt wetenschappelijke vooruitgang door hardware barrières weg te nemen voor academici die fundamentele vragen over AI capaciteiten en beperkingen onderzoeken.
Debugging, Profiling en Performance Optimalisatie
XProf en TensorBoard Integratie
XProf vormt de primaire profiling tool voor TPU workloads en biedt performance analyse voor JAX, PyTorch/XLA en TensorFlow programma's op CPUs, GPUs en TPUs.²¹³ De tool integreert met TensorBoard voor visualisatie en presenteert profiling data via vertrouwde interfaces die ML engineers al kennen.
Installatie vereist de TensorBoard plugin: pip install tensorboard_plugin_profile tensorboard. Dit maakt de complete toolchain mogelijk.²¹⁴ Het uitvoeren van profiling op TPU VMs houdt in dat traces worden vastgelegd tijdens training of inferentie, de resultaten naar TensorBoard worden geüpload en de visualisatie wordt geanalyseerd om bottlenecks te identificeren.
De Overview Page biedt high-level performance samenvatting metrics, inclusief step time breakdown, device utilization en top-level bottleneck identificatie.²¹⁵ De pagina toont direct of workloads compute-bound zijn (MXU draait continu), memory-bound (wachten op HBM transfers) of communication-bound (geblokkeerd op collective operations).
Trace Viewer en Timeline Analyse
De Trace Viewer toont gedetailleerde timeline visualisaties die exact laten zien wanneer operaties uitvoeren, wanneer data transfers plaatsvinden en waar idle time zich ophoopt.²¹⁶ De Chrome-gebaseerde interface maakt zoomen tot microseconde resolutie mogelijk, wat precieze scheduling behavior onthult die geaggregeerde metrics verbergen.
Het begrijpen van de trace vereist herkenning van gangbare patronen. Lange gaten tussen operaties duiden op compilation overhead, data-loading bottlenecks of Python overhead door slecht geoptimaliseerde data pipelines. Herhaalde kleine operaties suggereren onvoldoende fusie. Collective operations die milliseconden beslaan wijzen op communicatie inefficiënties of slechte sharding strategieën.²¹⁷
Kleurcodering onderscheidt operatie types: groen voor compute, blauw voor memory transfers, oranje voor communicatie en rood voor idle time. Geoptimaliseerde workloads tonen dicht opeengepakte gekleurde blokken met minimale rode gaten. Slecht geoptimaliseerde code vertoont sparse timelines met lange rode stukken die verspilde resources aangeven.²¹⁸
Geavanceerd gebruik houdt correleren van timeline behavior met broncode in. PyTorch/XLA ondersteunt user annotations die in code worden ingevoegd en in traces verschijnen, waardoor mapping van performance behavior naar specifieke model componenten mogelijk wordt.²¹⁹ De annotaties transformeren ondoorzichtige traces naar actionable insights over welke layers of operaties optimalisatie focus nodig hebben.
Memory Profile Tool en OOM Debugging
Out-of-memory (OOM) errors teisteren large model development. De Memory Profile Tool monitort device memory gebruik tijdens uitvoering en vangt peak utilization en allocation patterns die tot OOM failures leiden.²²⁰
De tool visualiseert memory consumption over tijd en toont welke tensors de meeste capaciteit consumeren en wanneer peak usage optreedt. De visualisatie onthult vaak verrassende allocations—gradient buffers groter dan verwacht, activation memory die zou moeten checkpointen of tijdelijke tensors die XLA er niet uit kon elimineren.²²¹
De debugging strategie houdt iteratief reduceren van de memory footprint via meerdere technieken in. Gradient checkpointing herberekent activations tijdens backward passes in plaats van ze op te slaan. Optimizer state sharding distribueert Adam momentum en variance over devices. Mixed precision reduceert memory met 2× vergeleken met FP32. Microbatching verwerkt kleinere batches sequentieel in plaats van één grote batch.²²²
Geavanceerde memory optimalisatie vereist begrip van compiler beslissingen. De xla_dump_to flag exporteert intermediate representations die tonen hoe XLA de computation graph transformeerde. Het analyseren van de IR onthult of fusie succesvol was, waar onnodige copies optreden en welke operaties meer memory alloceren dan verwacht.²²³
Input Pipeline Analyzer
CPU preprocessing vormt frequent een bottleneck voor TPU training. De Input Pipeline Analyzer identificeert of data loading gelijke tred houdt met accelerator consumption of dat TPUs idle zitten te wachten op batches.²²⁴
De tool scheidt host-side analyse (CPU preprocessing, data augmentation, batch assembly) van device-side execution (eigenlijke TPU computation). Input-bound workloads tonen device utilization die daalt tijdens data loading terwijl CPU utilization piekt. Compute-bound workloads behouden hoge device utilization met CPU die comfortabel gelijke tred houdt.²²⁵
Optimalisatie strategieën hangen af van de bottleneck locatie. Langzame host preprocessing profiteert van paralleliseren van data loading over meer CPU cores, reduceren van per-sample augmentation complexiteit of prefetching van batches voorafgaand aan consumption. Device-side bottlenecks vereisen veranderingen aan de model architectuur, betere fusie of sharding aanpassingen in plaats van data pipeline tuning.²²⁶
## De Toekomst van Tensor Processing Units
Google's architecturale evolutie over zeven generaties toont voortdurende innovatie in gespecialiseerde AI accelerators. Ironwood's FP8-ondersteuning, massale geheugencapaciteit en 9.216-chip superpod scaling suggereren trajecten voor toekomstige ontwikkeling.²²⁷
Precisie-reductie zal waarschijnlijk doorgaan richting FP4 of zelfs lager voor specifieke operaties. Opkomend onderzoek toont aan dat veel neural network operaties extreme quantisatie tolereren met zorgvuldige trainingsprocedures. Toekomstige TPUs zouden mixed-precision systemen kunnen implementeren met FP4 forward passes, FP8 backward passes, en FP32 optimizer updates.²²⁸
Geheugencapaciteit wedijvert tegen de groei van modelgrootte. Huidige frontier models belasten accelerator geheugen al zwaar, wat geavanceerde parallelisme strategieën vereist. Volgende-generatie TPUs zouden non-volatile geheugentechnologieën zoals 3D XPoint of resistive RAM kunnen integreren, wat terabyte-schaal on-package geheugen mogelijk maakt zonder DRAM's stroomverbruik.²²⁹
Optische interconnects zouden verder kunnen gaan dan circuit switching en optische computing elementen kunnen omvatten. Onderzoek verkent photonic matrix vermenigvuldiging uitgevoerd met lichtsnelheid en minimaal vermogen, wat elektronische systolic arrays mogelijk kan aanvullen met optische co-processors voor specifieke operaties.²³⁰
Sparsity ondersteuning zal waarschijnlijk uitbreiden voorbij embeddings naar algemene sparse lineaire algebra. Neural network pruning technieken tonen aan dat 90%+ van gewichten op nul kunnen worden gezet zonder kwaliteitsverlies. Toekomstige architecturen zouden nul-waarde berekeningen natively kunnen overslaan in plaats van ze expliciet te berekenen en weg te gooien.²³¹
De architecturale principes die ten grondslag liggen aan TPU-succes—domein specialisatie, custom interconnect, co-designed software stacks, en building-scale orchestratie—wijzen naar een toekomst van steeds meer gespecialiseerde accelerators. In plaats van one-size-fits-all processors, zouden we accelerators kunnen zien die geoptimaliseerd zijn voor training versus inference, convolutional networks versus transformers, dense versus sparse modellen, en korte versus lange sequenties.²³²
Engineers die vandaag AI infrastructure bouwen zouden TPU architectuur diep moeten begrijpen. Of ze nu deployen op Google Cloud, concurreren met Google in de accelerator markt, of volgende-generatie ML systemen ontwerpen, de design principes en trade-offs belichaamd in TPU onthullen fundamentele waarheden over wat AI workloads van hardware vragen. De systolic array wiskunde, memory hierarchy design, interconnect topologie, en compiler optimalisatie strategieën vertegenwoordigen decennia van geaccumuleerde wijsheid toepasbaar ver voorbij TPU zelf.
De spanning tussen specialisatie en generaliteit die TPU versus GPU definieert zal voor onbepaalde tijd aanhouden. TPUs offeren flexibiliteit op voor extreme efficiëntie op smalle workloads. GPUs offeren piekefficiëntie op voor bredere toepasbaarheid. Geen van beide benaderingen domineert—optimale keuze hangt volledig af van workload karakteristieken, schaal, kostenbeperkingen, en operationele vereisten. Organisaties die slagen met AI op schaal adopteren steeds meer heterogene strategieën, waarbij accelerator architecturen worden gematcht aan workload eisen in plaats van standaardiseren op een enkel platform.
Anthropic's miljoen-chip commitment aan TPU toont aan dat de architectuur productie-rijpheid heeft bereikt op de hoogste schalen. De multi-gigawatt deployments die online komen in 2026 zullen modellen trainen die de grenzen van wat AI kan bereiken oprekken, en de infrastructuur die deze modellen mogelijk maakt belichaamt engineering sophisticatie die weinig organisaties hebben geëvenaard. Begrijpen hoe 65.536 multiply-accumulate units in een systolic array samenwerken om frontier modellen te trainen is belangrijk voor iedereen die serieus is over AI's toekomst.
Referenties
-
Google Cloud Press Corner, "Anthropic to Expand Use of Google Cloud TPUs and Services," 23 oktober 2025, https://www.googlecloudpresscorner.com/2025-10-23-Anthropic-to-Expand-Use-of-Google-Cloud-TPUs-and-Services.
-
TrendForce, "Google Unveils 7th-Gen TPU Ironwood with 9,216-Chip Superpod, Taking Aim at NVIDIA," 7 november 2025, https://www.trendforce.com/news/2025/11/07/news-google-unveils-7th-gen-tpu-ironwood-with-9216-chip-superpod-taking-aim-at-nvidia/.
-
Norman P. Jouppi et al., "TPU v4: An Optically Reconfigurable Supercomputer for Machine Learning with Hardware Support for Embeddings," in Proceedings of the 50th Annual International Symposium on Computer Architecture (2023), arXiv:2304.01433.
-
Anthropic, "Expanding our use of Google Cloud TPUs and Services," Anthropic News, oktober 2025, https://www.anthropic.com/news/expanding-our-use-of-google-cloud-tpus-and-services.
-
Google Cloud Blog, "Quantifying the performance of the TPU, our first machine learning chip," april 2017, https://cloud.google.com/blog/products/gcp/quantifying-the-performance-of-the-tpu-our-first-machine-learning-chip.
-
Norman P. Jouppi et al., "In-Datacenter Performance Analysis of a Tensor Processing Unit," Proceedings of the 44th Annual International Symposium on Computer Architecture (2017), arXiv:1704.04760.
-
Jouppi et al., "In-Datacenter Performance Analysis."
-
Jouppi et al., "In-Datacenter Performance Analysis."
-
Jonathan Hui, "AI Chips: Google TPU," Medium, geraadpleegd december 2025, https://jonathan-hui.medium.com/ai-chips-tpu-3fa0b2451a2d.
-
Wikipedia, "Bfloat16 floating-point format," geraadpleegd december 2025, https://en.wikipedia.org/wiki/Bfloat16_floating-point_format.
-
Henry Ko, "TPU Deep Dive," persoonlijke blog, geraadpleegd december 2025, https://henryhmko.github.io/posts/tpu/tpu.html.
-
Wikipedia, "Tensor Processing Unit," geraadpleegd december 2025, https://en.wikipedia.org/wiki/Tensor_Processing_Unit.
-
Wikipedia, "Tensor Processing Unit."
-
Wikipedia, "Tensor Processing Unit."
-
Ko, "TPU Deep Dive."
-
Jouppi et al., "TPU v4: An Optically Reconfigurable Supercomputer."
-
Jouppi et al., "TPU v4: An Optically Reconfigurable Supercomputer."
-
Jouppi et al., "TPU v4: An Optically Reconfigurable Supercomputer."
-
Jouppi et al., "TPU v4: An Optically Reconfigurable Supercomputer."
-
OpenXLA Project, "A deep dive into SparseCore for Large Embedding Models (LEM)," geraadpleegd december 2025, https://openxla.org/xla/sparsecore.
-
JAX Scaling Guide, "How to Think About TPUs," geraadpleegd december 2025, https://jax-ml.github.io/scaling-book/tpus/.
-
JAX Scaling Guide, "How to Think About TPUs."
-
Ko, "TPU Deep Dive."
-
JAX Scaling Guide, "How to Think About TPUs."
-
Google Cloud Blog, "Introducing Trillium, sixth-generation TPUs," mei 2024, https://cloud.google.com/blog/products/compute/introducing-trillium-6th-gen-tpus.
-
Google Cloud Blog, "Introducing Trillium."
-
Google Cloud Blog, "Introducing Trillium."
-
Google Cloud Blog, "Introducing Trillium."
-
Google Cloud Blog, "Introducing Trillium."
-
Google Blog, "Ironwood: The first Google TPU for the age of inference," november 2025, https://blog.google/products/google-cloud/ironwood-tpu-age-of-inference/.
-
XPU.pub, "Google Adds FP8 to Ironwood TPU; Can It Beat Blackwell?" 16 april 2025, https://xpu.pub/2025/04/16/google-ironwood/.
-
TrendForce, "Google Unveils 7th-Gen TPU Ironwood."
-
The Register, "Google's 7th-gen Ironwood TPUs promise 42 AI exaFLOPS pods," 10 april 2025, https://www.theregister.com/2025/04/10/googles_7thgen_ironwood_tpus_debut/.
-
TrendForce, "Google Unveils 7th-Gen TPU Ironwood."
-
Ko, "TPU Deep Dive."
-
XPU.pub, "Google Adds FP8 to Ironwood TPU."
-
Google Cloud Press Corner, "Anthropic to Expand Use."
-
Telesens, "Understanding Matrix Multiplication on a Weight-Stationary Systolic Architecture," 30 juli 2018, https://telesens.co/2018/07/30/systolic-architectures/.
-
Telesens, "Understanding Matrix Multiplication."
-
Jouppi et al., "In-Datacenter Performance Analysis."
-
Telesens, "Understanding Matrix Multiplication."
-
CP Lu, "Should We All Embrace Systolic Arrays?" Medium, geraadpleegd december 2025, https://cplu.medium.com/should-we-all-embrace-systolic-array-df3830f193dc.
-
Google Cloud Documentatie, "TPU architecture," geraadpleegd december 2025, https://docs.cloud.google.com/tpu/docs/system-architecture-tpu-vm.
-
Google Cloud Documentatie, "TPU architecture."
-
Hui, "AI Chips: Google TPU."
-
Telnyx, "Architecture insights: MXU and TPU components," geraadpleegd december 2025, https://telnyx.com/learn-ai/mxu-tpu.
-
Ko, "TPU Deep Dive."
-
Jouppi et al., "TPU v4: An Optically Reconfigurable Supercomputer."
-
SemiEngineering, "Tensor Processing Unit (TPU)," geraadpleegd december 2025, https://semiengineering.com/knowledge_centers/integrated-circuit/ic-types/processors/tensor-processing-unit-tpu/.
-
TrendForce, "Google Unveils 7th-Gen TPU Ironwood."
-
SemiEngineering, "Tensor Processing Unit (TPU)."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Google Cloud Documentatie, "Cloud TPU performance guide," geraadpleegd december 2025, https://cloud.google.com/tpu/docs/performance-guide.
-
OpenXLA Project, "A deep dive into SparseCore."
-
OpenXLA Project, "A deep dive into SparseCore."
-
OpenXLA Project, "A deep dive into SparseCore."
-
Jouppi et al., "TPU v4: An Optically Reconfigurable Supercomputer."
-
OpenXLA Project, "A deep dive into SparseCore."
-
Jouppi et al., "TPU v4: An Optically Reconfigurable Supercomputer."
-
OpenXLA Project, "A deep dive into SparseCore."
-
JAX Scaling Guide, "How to Think About TPUs."
-
JAX Scaling Guide, "How to Think About TPUs."
-
JAX Scaling Guide, "How to Think About TPUs."
-
Ko, "TPU Deep Dive."
-
JAX Scaling Guide, "How to Think About TPUs."
-
JAX Scaling Guide, "How to Think About TPUs."
-
TrendForce, "Google Unveils 7th-Gen TPU Ironwood."
-
Ko, "TPU Deep Dive."
-
Anthropic, "Expanding our use of Google Cloud TPUs."
-
Jouppi et al., "TPU v4: An Optically Reconfigurable Supercomputer."
-
Jouppi et al., "TPU v4: An Optically Reconfigurable Supercomputer."
-
Jouppi et al., "TPU v4: An Optically Reconfigurable Supercomputer."
-
Jouppi et al., "TPU v4: An Optically Reconfigurable Supercomputer."
-
Ko, "TPU Deep Dive."
-
Jouppi et al., "TPU v4: An Optically Reconfigurable Supercomputer."
-
Leon Poutievski, "Mission Apollo: Landing Optical Circuit Switching at Datacenter Scale," LinkedIn, juni 2022, https://www.linkedin.com/posts/leon-poutievski-8910a851_mission-apollo-landing-optical-circuit-switching-activity-6968472071534235649-cB4l.
-
Ko, "TPU Deep Dive."
-
Jouppi et al., "TPU v4: An Optically Reconfigurable Supercomputer."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Jouppi et al., "TPU v4: An Optically Reconfigurable Supercomputer."
-
JAX Scaling Guide, "How to Think About TPUs."
-
TrendForce, "Google Unveils 7th-Gen TPU Ironwood."
-
TrendForce, "Google Unveils 7th-Gen TPU Ironwood."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
OpenXLA Project, "XLA: Optimizing Compiler for Machine Learning," geraadpleegd december 2025, https://openxla.org/xla.
-
Daniel Snider en Ruofan Liang, "Operator Fusion in XLA: Analysis and Evaluation," academisch paper, geraadpleegd december 2025, https://danielsnider.ca/papers/Operator_Fusion_in_XLA_Analysis_and_Evaluation.pdf.
-
Snider en Liang, "Operator Fusion in XLA."
-
APXML, "Memory-Aware Data Layout Transformations (NCHW/NHWC)," geraadpleegd december 2025, https://apxml.com/courses/compiler-runtime-optimization-ml/chapter-3-advanced-graph-level-optimizations/memory-aware-layout-transformations.
-
OpenXLA Project, "XLA."
-
PyTorch Documentatie, "Pytorch/XLA Overview," geraadpleegd december 2025, https://docs.pytorch.org/xla/master/learn/xla-overview.html.
-
OpenXLA Project, "A deep dive into SparseCore."
-
Mangpo Phothilimthana et al., "A Flexible Approach to Autotuning Multi-Pass Machine Learning Compilers," PACT 2021, geraadpleegd december 2025, https://mangpo.net/papers/xla-autotuning-pact2021.pdf.
-
JAX Documentatie, "Introduction to parallel programming," geraadpleegd december 2025, https://docs.jax.dev/en/latest/sharded-computation.html.
-
GitHub, "jax-ml/jax: Composable transformations of Python+NumPy programs," geraadpleegd december 2025, https://github.com/jax-ml/jax.
-
OpenXLA Project, "Shardy Guide for JAX Users," geraadpleegd december 2025, https://openxla.org/shardy/getting_started_jax.
-
JAX Documentatie, "Introduction to parallel programming."
-
OpenXLA Project, "Shardy Guide for JAX Users."
-
OpenXLA Project, "Shardy Guide for JAX Users."
-
JAX Documentatie, "Introduction to parallel programming."
-
OpenXLA Project, "Shardy Guide for JAX Users."
-
PyTorch Documentatie, "Pytorch/XLA Overview."
-
GitHub, "RFC: Evolving PyTorch/XLA for a more native experience on TPU," Issue #9684, geraadpleegd december 2025, https://github.com/pytorch/xla/issues/9684.
-
Google Cloud Blog, "PyTorch/XLA 2.4 improves Pallas and adds 'eager mode,'" geraadpleegd december 2025, https://cloud.google.com/blog/products/ai-machine-learning/pytorch-xla-2-4-improves-pallas-and-adds-eager-mode/.
-
PyTorch Documentatie, "Pytorch/XLA Overview."
-
PyTorch Documentatie, "Custom Kernels via Pallas," geraadpleegd december 2025, https://docs.pytorch.org/xla/master/features/pallas.html.
-
PyTorch Documentatie, "Custom Kernels via Pallas."
-
PyTorch Documentatie, "Custom Kernels via Pallas."
-
vLLM Blog, "vLLM TPU: A New Unified Backend Supporting PyTorch and JAX on TPU," 16 oktober 2025, https://blog.vllm.ai/2025/10/16/vllm-tpu.html.
-
GitHub, "pytorch/xla," geraadpleegd december 2025, https://github.com/pytorch/xla.
-
StackGpu, "FP8, BF16, and INT8: How Low-Precision Formats Are Revolutionizing Deep Learning Throughput," Medium, geraadpleegd december 2025, https://medium.com/@StackGpu/fp8-bf16-and-int8-how-low-precision-formats-are-revolutionizing-deep-learning-throughput-e6c1f3adabc2.
-
Wikipedia, "Bfloat16 floating-point format."
-
Wikipedia, "Bfloat16 floating-point format."
-
Paulius Micikevicius et al., "FP8 Formats for Deep Learning," arXiv:2209.05433, september 2022.
-
XPU.pub, "Google Adds FP8 to Ironwood TPU."
-
Micikevicius et al., "FP8 Formats for Deep Learning."
-
Google Cloud Blog, "Accurate Quantized Training (AQT) for TPU v5e," geraadpleegd december 2025, https://cloud.google.com/blog/products/compute/accurate-quantized-training-aqt-for-tpu-v5e.
-
StackGpu, "FP8, BF16, and INT8."
-
Jeffrey Tse, "Understanding the FP64, FP32, FP16, BFLOAT16, TF32, FP8 Formats," persoonlijke blog, 9 december 2024, https://jeffreytse.net/computer/2024/12/09/understanding-the-fp64-fp32-fp16-bfloat16-tf32-fp8-formats.html.
-
PyTorch Blog, "PyTorch/XLA SPMD: Scale Up Model Training and Serving with Automatic Parallelization," geraadpleegd december 2025, https://pytorch.org/blog/pytorch-xla-spmd/.
-
OpenXLA Project, "Shardy Guide for JAX Users."
-
JAX Documentatie, "Introduction to parallel programming."
-
OpenXLA Project, "Shardy Guide for JAX Users."
-
Ko, "TPU Deep Dive."
-
JAX Documentatie, "Introduction to parallel programming."
-
Anthropic, "Expanding our use of Google Cloud TPUs."
-
JAX Documentatie, "Introduction to parallel programming."
-
JAX Documentatie, "Introduction to parallel programming."
-
Adam Roberts et al., "Scaling Up Models and Data with t5x and seqio," arXiv:2203.17189, maart 2022.
-
Roberts et al., "Scaling Up Models and Data."
-
JAX Documentatie, "Introduction to parallel programming."
-
JAX Documentatie, "Introduction to parallel programming."
-
OpenXLA Project, "Shardy Guide for JAX Users."
-
Roberts et al., "Scaling Up Models and Data."
-
Roberts et al., "Scaling Up Models and Data."
-
Ko, "TPU Deep Dive."
-
MLCommons, "Benchmark MLPerf Training," geraadpleegd december 2025, https://mlcommons.org/benchmarks/training/.
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
HPCwire, "MLPerf Training v5.0 Benchmark Results Reflect Rapid Growth in the Field of AI," juni 2025, https://www.hpcwire.com/off-the-wire/mlperf-training-v5-0-benchmark-results-reflect-rapid-growth-in-the-field-of-ai/.
-
MLCommons, "MLCommons Releases New MLPerf Inference v5.0 Benchmark Results," april 2025, https://mlcommons.org/2025/04/mlperf-inference-v5-0-results/.
-
Ko, "TPU Deep Dive."
-
Google Cloud Blog, "TPU v4 enables performance, energy and CO2e efficiency gains," geraadpleegd december 2025, https://cloud.google.com/blog/topics/systems/tpu-v4-enables-performance-energy-and-co2e-efficiency-gains.
-
TrendForce, "Google Unveils 7th-Gen TPU Ironwood."
-
Google Cloud Blog, "Quantifying the performance of the TPU."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Artech Digital, "Energy-Efficient GPU vs. TPU Allocation," geraadpleegd december 2025, https://www.artech-digital.com/blog/energy-efficient-gpu-vs-tpu-allocation.
-
Wikipedia, "Tensor Processing Unit."
-
XPU.pub, "Google Adds FP8 to Ironwood TPU."
-
Ko, "TPU Deep Dive."
-
Google Cloud Blog, "TPU v4 enables performance, energy and CO2e efficiency gains."
-
ByteBridge, "GPU and TPU Comparative Analysis Report," Medium, geraadpleegd december 2025, https://bytebridge.medium.com/gpu-and-tpu-comparative-analysis-report-a5268e4f0d2a.
-
ByteBridge, "GPU and TPU Comparative Analysis Report."
-
Anthropic, "Expanding our use of Google Cloud TPUs."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
DataCamp, "Understanding TPUs vs GPUs in AI: A Comprehensive Guide," geraadpleegd december 2025, https://www.datacamp.com/blog/tpu-vs-gpu-ai.
-
Ko, "TPU Deep Dive."
-
DataCamp, "Understanding TPUs vs GPUs in AI."
-
Grigory Sapunov, "FP64, FP32, FP16, BFLOAT16, TF32, and other members of the ZOO," Medium, geraadpleegd december 2025, https://moocaholic.medium.com/fp64-fp32-fp16-bfloat16-tf32-and-other-members-of-the-zoo-a1ca7897d407.
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Snider en Liang, "Operator Fusion in XLA."
-
APXML, "Memory-Aware Data Layout Transformations."
-
Google Cloud Blog, "How Lightricks trains video diffusion models at scale with JAX on TPU," geraadpleegd december 2025, https://cloud.google.com/blog/products/media-entertainment/how-lightricks-trains-video-diffusion-models-at-scale-with-jax-on-tpu.
-
CloudOptimo, "TPU vs GPU: What's the Difference in 2025?" geraadpleegd december 2025, https://www.cloudoptimo.com/blog/tpu-vs-gpu-what-is-the-difference-in-2025/.
-
Phoenix NAP, "TPU vs. GPU: Differences Explained," geraadpleegd december 2025, https://phoenixnap.com/kb/tpu-vs-gpu.
-
CloudOptimo, "TPU vs GPU."
-
DataCamp, "Understanding TPUs vs GPUs in AI."
-
Tailscale, "TPU vs GPU: Which Is Better for AI Infrastructure in 2025?" geraadpleegd december 2025, https://tailscale.com/learn/what-is-tpu-vs-gpu.
-
DataCamp, "Understanding TPUs vs GPUs in AI."
-
DataCamp, "Understanding TPUs vs GPUs in AI."
-
PyTorch Documentatie, "Custom Kernels via Pallas."
-
Phoenix NAP, "TPU vs. GPU: Differences Explained."
-
Ko, "TPU Deep Dive."
-
OpenMetal, "TPU vs GPU: Pros and Cons," geraadpleegd december 2025, https://openmetal.io/docs/product-guides/private-cloud/tpu-vs-gpu-pros-and-cons/.
-
OpenMetal, "TPU vs GPU: Pros and Cons."
-
Phoenix NAP, "TPU vs. GPU: Differences Explained."
-
PRIMO.ai, "Processing Units - CPU, GPU, APU, TPU, VPU, FPGA, QPU," geraadpleegd december 2025, https://primo.ai/index.php?title=Processing_Units_-_CPU%2C_GPU%2C_APU%2C_TPU%2C_VPU%2C_FPGA%2C_QPU.
-
DataCamp, "Understanding TPUs vs GPUs in AI."
-
Google Cloud Documentatie, "Profile your model on Cloud TPU VMs," geraadpleegd december 2025, https://cloud.google.com/tpu/docs/cloud-tpu-tools.
-
DataCamp, "Understanding TPUs vs GPUs in AI."
-
Ko, "TPU Deep Dive."
-
GitHub, "RFC: Evolving PyTorch/XLA."
-
Google Cloud Press Corner, "Anthropic to Expand Use."
-
TrendForce, "Google Unveils 7th-Gen TPU Ironwood."
-
Maginative, "Anthropic Secures 1M Google TPUs While Keeping Amazon as Primary Training Partner," geraadpleegd december 2025, https://www.maginative.com/article/anthropic-secures-1m-google-tpus-while-keeping-amazon-as-primary-training-partner/.
-
Anthropic, "A postmortem of three recent issues," Engineering Blog, augustus 2025, https://www.anthropic.com/engineering/a-postmortem-of-three-recent-issues.
-
Anthropic, "A postmortem of three recent issues."
-
AI Magazine, "Why Anthropic Uses Google Cloud TPUs for AI Infrastructure," geraadpleegd december 2025, https://aimagazine.com/news/why-anthropic-uses-google-cloud-tpus-for-ai-infrastructure.
-
Google Cloud Blog, "Ironwood TPUs and new Axion-based VMs for your AI workloads," november 2025, https://cloud.google.com/blog/products/compute/ironwood-tpus-and-new-axion-based-vms-for-your-ai-workloads.
-
Ko, "TPU Deep Dive."
-
TrendForce, "Google Unveils 7th-Gen TPU Ironwood."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Google Cloud, "Tensor Processing Units (TPUs)," geraadpleegd december 2025, https://cloud.google.com/tpu.
-
TensorFlow Documentatie, "Optimize TensorFlow performance using the Profiler," geraadpleegd december 2025, https://www.tensorflow.org/guide/profiler.
-
Google Cloud Documentatie, "Profile your model on Cloud TPU VMs."
-
TensorFlow Documentatie, "TensorFlow Profiler: Profile model performance," geraadpleegd december 2025, https://www.tensorflow.org/tensorboard/tensorboard_profiling_keras.
-
Google Cloud Documentatie, "Profile your model on Cloud TPU VMs."
-
Google Cloud Blog, "PyTorch/XLA: Performance debugging on Cloud TPU VM: Part III," geraadpleegd december 2025, https://cloud.google.com/blog/topics/developers-practitioners/pytorchxla-performance-debugging-cloud-tpu-vm-part-iii.
-
Google Cloud Blog, "PyTorch/XLA: Performance debugging Part III."
-
Google Cloud Documentatie, "Profile PyTorch XLA workloads," geraadpleegd december 2025, https://docs.cloud.google.com/tpu/docs/pytorch-xla-performance-profiling-tpu-vm.
-
TensorFlow Documentatie, "Optimize TensorFlow performance using the Profiler."
-
TensorFlow Documentatie, "Optimize TensorFlow performance using the Profiler."
-
Ko, "TPU Deep Dive."
-
Google Cloud Documentatie, "Cloud TPU performance guide."
-
TensorFlow Documentatie, "Optimize TensorFlow performance using the Profiler."
-
TensorFlow Documentatie, "Optimize TensorFlow performance using the Profiler."
-
TensorFlow Documentatie, "Optimize TensorFlow performance using the Profiler."
-
TrendForce, "Google Unveils 7th-Gen TPU Ironwood."
-
Tse, "Understanding the FP64, FP32, FP16, BFLOAT16, TF32, FP8 Formats."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."


