
Googles Tensor Processing Units betreiben die Mehrheit der hochmodernen AI-Modelle, mit denen Sie täglich interagieren, dennoch bleiben die meisten Ingenieure überraschend unvertraut mit ihrer Architektur. Während NVIDIA GPUs die Aufmerksamkeit der Entwickler dominieren, trainieren und bedienen TPUs stillschweigend Gemini 2.0, Claude und Dutzende andere Spitzenmodelle in Größenordnungen, die die meisten Organisationen bei Verwendung herkömmlicher GPU-Infrastruktur in den Bankrott treiben würden. Anthropic hat sich kürzlich dazu verpflichtet, über eine Million TPU-Chips einzusetzen—was mehr als ein Gigawatt Rechenkapazität darstellt—um zukünftige Claude-Modelle zu trainieren.¹ Googles neueste Ironwood-Generation liefert 42,5 Exaflops FP8-Rechenleistung über 9.216-Chip-Superpods, ein Maßstab, der neu definiert, was produktive AI-Infrastruktur bedeutet.²
Die technische Raffinesse hinter TPUs geht weit über einfache Leistungsmetriken hinaus. Diese Prozessoren verkörpern eine grundlegend andere Designphilosophie als GPUs und tauschen universelle Flexibilität gegen extreme Spezialisierung bei Matrixmultiplikation und Tensoroperationen ein. Ingenieure, die die TPU-Architektur verstehen, können 256×256 systolische Arrays nutzen, die 65.536 Multiplikations-Akkumulations-Operationen pro Zyklus verarbeiten, SparseCore-Beschleuniger der dritten Generation für Embedding-intensive Arbeitslasten einsetzen und optische Schaltkreise programmieren, die Multi-Petabit-Rechenzentrum-Topologien in unter 10 Nanosekunden rekonfigurieren.³ Die Architektur umfasst alles von Designentscheidungen auf Transistorebene bis zur Orchestrierung von Supercomputern auf Gebäudeebene.
Der technische Inhalt, der folgt, erfordert sorgfältige Aufmerksamkeit. Wir untersuchen sieben Generationen der TPU-Evolution, sezieren systolische Array-Mathematik und Datenflussmuster, erkunden Speicherhierarchien von SRAM-Kacheln bis zu HBM3e-Kanälen, analysieren XLA-Compiler-Optimierungen auf der Ebene der Zwischendarstellung und untersuchen, warum kollektive Operationen 10× schneller ausführen als äquivalente Ethernet-basierte GPU-Cluster.⁴ Sie werden auf Spezifikationen auf Registerebene, zyklusgenaue Leistungsmodellierung und die architektonischen Kompromisse stoßen, die TPUs gleichzeitig leistungsfähiger und eingeschränkter als GPUs machen. Die Tiefe hier dient Ingenieuren, die die nächste Generation der AI-Infrastruktur entwickeln, und Forschern, die die Grenzen dessen erweitern, was aktuelle Beschleuniger erreichen können.
Die Evolution: Sieben Generationen architektonischer Innovation
TPU v1: Nur-Inferenz-Spezialisierung (2015)
Google setzte die erste Tensor Processing Unit 2015 ein, um ein kritisches Problem zu lösen: Neuronale Netzwerk-Inferenz-Arbeitslasten drohten den Rechenzentrumsverbrauch des Unternehmens zu verdoppeln.⁵ Ingenieure entwickelten TPU v1 ausschließlich für Inferenz und entfernten Trainingsmöglichkeiten vollständig, um Leistung und Energieeffizienz für eingesetzte Modelle zu maximieren. Der Chip verfügte über ein 256×256 systolisches Array von 8-Bit-Integer-Multiplikations-Akkumulationseinheiten, die 92 Teraops pro Sekunde bei nur 28-40 Watt Wärmeentwicklungsleistung lieferten.⁶
Die Architektur verkörperte radikalen Minimalismus. Eine einzelne Matrix-Multiplikationseinheit verarbeitete INT8-Operationen durch gewichtsstatischen Datenfluss, bei dem Gewichte im systolischen Array fixiert blieben, während Aktivierungen horizontal über das Gitter strömten. Teilsummen werden vertikal propagiert und eliminieren zwischenzeitliche Speicherschreibvorgänge für die gesamte Matrixmultiplikation. Der Chip, der über PCIe an Hostsysteme angeschlossen war, verließ sich auf DDR3 DRAM für externen Speicher und operierte bei 700 MHz—bewusst konservativ für Energieeffizienz.⁷
Leistungsgewinne verblüfften sogar Googles Ingenieure. TPU v1 erreichte 30× bis 80× Verbesserungen bei Operationen pro Watt im Vergleich zu zeitgenössischen CPUs und GPUs für Produktions-Inferenz-Arbeitslasten.⁸ Der Chip handhabte Google Search-Ranking, Übersetzungsservices mit 1 Milliarde täglichen Anfragen und YouTube-Empfehlungen für 2 Milliarden Nutzer. Der Erfolg validierte eine zentrale architektonische Erkenntnis: zweckgebaute Beschleuniger, die für enge Arbeitslasten optimiert sind, konnten größenordnungsmäßige Verbesserungen gegenüber allgemeinen Prozessoren liefern.
TPU v2: Training im großen Maßstab ermöglichen (2017)
Die zweite Generation transformierte TPUs von Nur-Inferenz-Beschleunigern zu vollständigen Trainingsplattformen. Google überarbeitete die gesamte Architektur um Gleitkomma-Operationen und ersetzte das 256×256 INT8-Array mit dualen 128×128 bfloat16-Multiplikatoren pro Kern.⁹ Jeder Chip enthielt zwei TensorCores, die sich 8GB High Bandwidth Memory pro Kern teilten, ein massives Upgrade von DDR3, das die Bandbreite bereitstellte, die neuronales Netzwerk-Training verlangte.
Bfloat16-Präzision erwies sich als kritisch für TPU v2s Erfolg. Das Format behält denselben 8-Bit-Exponenten-Bereich wie FP32 bei, während die Mantisse auf 7 Bits reduziert wird, wodurch der dynamische Bereich für das Training erhalten bleibt, während die Speicherbandbreitenanforderungen halbiert werden.¹⁰ Ingenieure beobachteten, dass die reduzierte Mantissen-Präzision tatsächlich die Generalisierung in vielen Modellen verbesserte, indem sie als eine Form der Regularisierung wirkte, während der vollständige FP32-Exponenten-Bereich die Underflow- und Overflow-Probleme verhinderte, die FP16-Training plagten.
Die architektonische Innovation, die TPU v2 wirklich differenzierte, war der Inter-Chip Interconnect (ICI). Vorherige Beschleuniger erforderten Ethernet oder InfiniBand für Multi-Chip-Kommunikation, was Latenz- und Bandbreiten-Engpässe einführte. Google entwickelte maßgeschneiderte Hochgeschwindigkeits-bidirektionale Verbindungen, die jeden TPU direkt mit vier Nachbarn in einer 2D-Torus-Topologie verbanden.¹¹ Der Interconnect ermöglichte TPU v2 "Pods" mit bis zu 256 Chips, als ein einzelner logischer Beschleuniger zu funktionieren, wobei kollektive Operationen wie All-Reduce deutlich schneller als netzwerkbasierte Alternativen ausgeführt wurden.
TPU v3: Wassergekühlte Leistungsskalierung (2018)
Google trieb Taktfrequenzen und Kernanzahl bei TPU v3 aggressiv voran und lieferte 420 Teraflops pro Chip—mehr als die Verdopplung der v2-Leistung.¹² Die erhöhte Leistungsdichte erzwang eine dramatische architektonische Änderung: Flüssigkeitskühlung. Jeder TPU v3 Pod erforderte Wasserkühlungsinfrastruktur, eine Abweichung von den luftgekühlten Designs vorheriger Generationen und den meisten Rechenzentrumsbeschleunigern.¹³
Der Chip behielt die duale 128×128 MXU-Architektur bei, erhöhte aber die Gesamtzahl der Kerne und verbesserte die Speicherbandbreite. Jeder TPU v3 enthielt vier Chips mit jeweils zwei Kernen, die sich insgesamt 32GB HBM-Speicher über alle Chips teilten.¹⁴ Die Vektorverarbeitungseinheiten erhielten Verbesserungen für Aktivierungsfunktionen, Normalisierungsoperationen und Gradientenberechnungen, die häufig das Training nur auf den Matrixeinheiten verlangsamten.
Einsätze skalierten auf 2.048-Chip-Pods mit derselben 2D-Torus-ICI-Topologie wie v2, aber mit erhöhter Bandbreite pro Verbindung. Google trainierte zunehmend größere Modelle auf v3-Pods und entdeckte, dass die Torus-Topologiens reduzierter Netzwerkdurchmesser (maximale Distanz zwischen zwei Chips skaliert als N/2 statt N) den Kommunikationsoverhead sowohl für datenparallele als auch modellparallele Trainingsstrategien minimierte.¹⁵
TPU v4: Optisches Circuit-Switching-Durchbruch (2021)
Die vierte Generation stellte Googles bedeutendsten architektonischen Sprung seit der ursprünglichen TPU dar. Ingenieure erhöhten die Pod-Größe auf 4.096 Chips und führten optisches Circuit Switching (OCS) für Interconnect ein, eine von der Telekommunikation entlehnte Technologie, die die rechenzentrumsweite ML-Infrastruktur revolutionierte.¹⁶
TPU v4s Kern-Architektur verfügte über vier 128×128 MXUs pro TensorCore neben verbesserten Vektor- und Skalar-Einheiten. Jedes TensorCore-Paar teilte sich 128MB Common Memory zusätzlich zu pro-Kern Vector Memory, was anspruchsvollere Datenstufen- und Wiederverwendungsmuster ermöglichte.¹⁷ Die Chip-Topologie entwickelte sich von 2D zu 3D-Torus und verband jeden TPU mit sechs statt vier Nachbarn, wodurch der Netzwerkdurchmesser weiter reduziert und die Bisektionsbandbreite verbessert wurde.
Das optische Circuit-Switching-System veränderte alles bei groß angelegten Einsätzen. Anstatt fixer Verkabelung zwischen TPUs setzte Google programmierbare optische Switches ein, die dynamisch rekonfigurieren konnten, welche Chips mit welchen verbunden waren. MEMS (mikroelektromechanische Systeme)-Spiegel leiten Lichtstrahlen physisch um, um beliebige TPU-Paare miteinander zu verbinden, was im Wesentlichen null Latenz über die optische Faserübertragungszeit hinaus einführt.¹⁸ Die Switches rekonfigurieren in unter-10-Nanosekunden-Fenstern, schneller als die meisten Netzwerkprotokoll-Handshakes.
Die OCS-Architektur ermöglichte zuvor unmögliche Fähigkeiten. Google konnte "Slices" jeder Größe bereitstellen, von vier Chips bis zum vollständigen 4.096-Chip-Pod, durch entsprechende Programmierung der optischen Switches. Ausgefallene Chips konnten nahtlos umgangen werden, ohne ganze Racks stillzulegen. Am bemerkenswertesten konnten physisch entfernte TPUs in verschiedenen Rechenzentrumsstandorten logisch benachbart in der Netzwerktopologie sein, wodurch physisches und logisches Layout vollständig entkoppelt wurden.¹⁹
TPU v4 führte auch SparseCore ein, einen spezialisierten Prozessor für Embedding-Operationen, die täglich in Empfehlungssystemen, Ranking-Modellen und großen Sprachmodellen mit massiven Vokabular-Embeddings verwendet werden. Der SparseCore verfügte über vier dedizierte Prozessoren pro Chip, jeweils mit 2,5MB Scratchpad-Speicher und optimiertem Datenfluss für spärliche Speicherzugriffsmuster.²⁰ Modelle mit ultra-großen Embeddings erreichten 5-7× Beschleunigungen bei nur 5% der gesamten Chip-Die-Fläche und des Energiebudgets.
TPU v5p und v5e: Spezialisierung und Skalierung (2022-2023)
Google teilte die fünfte Generation in zwei unterschiedliche Produkte auf, die verschiedene Anwendungsfälle adressieren. TPU v5p priorisierte maximale Leistung für großangelegtes Training, während v5e für kosteneffektive Inferenz und kleinere Trainingsjobs optimierte.²¹
TPU v5p erreichte etwa 4,45 Exaflops pro Sekunde über 8.960-Chip-Pods und verdoppelte mehr als die maximale Pod-Größe von v4.²² Die Interconnect-Bandbreite erreichte 4.800 Gbps pro Chip, und die 3D-Torus-Topologie verband Chips in massiven 16×20×28 Superpods. Das optische Circuit-Switching-Fabric verwaltete 13.824 optische Ports über 48 OCS-Einheiten, um einen vollständigen v5p-Superpod zu verdrahten, was eine der größten produktiven optischen Switching-Implementierungen in der Computing-Geschichte darstellt.²³
TPU v5e verfolgte einen anderen Ansatz und reduzierte Kernanzahl und Taktfrequenz, um aggressive Energie- und Kostenziele zu erreichen. Inferenz-optimierte Chips enthielten nur einen TPU-Kern pro Chip statt zwei und kehrten zur 2D-Torus-Topologie zurück, die für kleinere Pod-Größen ausreichte.²⁴ Die architektonische Vereinfachung ermöglichte es Google, v5e wettbewerbsfähig für Arbeitslasten zu bepreisen, bei denen absolute Leistung weniger wichtig war als Leistung pro Dollar.
TPU v6e Trillium: Vervierfachung der Matrix-Leistung (2024)
Trillium markierte einen weiteren architektonischen Wendepunkt durch Erweiterung der Matrix Multiply Unit von 128×128 auf 256×256 Multiplikatoren.²⁵ Das größere Array vervierfachte FLOPs pro Zyklus bei derselben Taktfrequenz und lieferte 4,7× die Spitzen-Rechenleistung von TPU v5e durch eine Kombination aus der erweiterten MXU und erhöhten Taktfrequenzen.
Das Speichersubsystem erhielt ebenso dramatische Upgrades. Die HBM-Kapazität verdoppelte sich auf 32GB pro Chip, mit durch HBM-Kanäle der nächsten Generation verdoppelter Bandbreite.²⁶ Die Interchip-Interconnect-Bandbreite verdoppelte sich ebenfalls und ermöglichte Pods aus 256 Trillium-Chips, höheren Durchsatz für Modelle zu erhalten, die sowohl Compute als auch Kommunikation belasteten.²⁷
Trillium verfügte über den SparseCore-Beschleuniger der dritten Generation mit verbesserten Fähigkeiten für ultra-große Embeddings in Ranking- und Empfehlungsarbeitslasten. Das aktualisierte Design verbesserte Speicherzugriffsmuster und erhöhte die angemessene Bandbreite zwischen SparseCores und HBM für Modelle, die von Embedding-Lookups statt Matrixmultiplikationen dominiert werden.²⁸
Die Energieeffizienz verbesserte sich um 67% gegenüber v5e trotz erheblicher Leistungssteigerungen.²⁹ Google erreichte die Effizienzgewinne durch fortgeschrittene Prozesstechnologien, architektonische Optimierungen, die verschwendete Arbeit reduzierten, und sorgfältiges Power-Gating ungenutzter Einheiten während Operationen, die nicht alle Teile des Chips gleichzeitig belasteten.
TPU v7 Ironwood: Die FP8-Ära (2025)
Googles TPU der siebten Generation, Codename Ironwood, stellt die erste TPU dar, die mit nativer FP8-Unterstützung entwickelt und speziell für das "Zeitalter der Inferenz" optimiert wurde, während sie state-of-the-art Trainingsleistung beibehält.³⁰ Jeder Ironwood-Chip liefert 4,6 PetaFLOPS dichte FP8-Rechenleistung—leicht über NVIDIAs konkurrierendem B200 mit 4,5 PetaFLOPS—während er 600W Wärmeentwicklungsleistung zieht.³¹
Das Speichersystem erweiterte sich auf 192GB HBM3e-Speicher pro Chip, sechsmal Trilliums Kapazität, mit Bandbreite von 7,4TB/s.³² Die dramatische Speichererhöhung ermöglicht das Serving ultra-großer Modelle mit Key-Value-Caches, die zuvor komplexe Tensor-Parallelisierung über mehrere Beschleuniger erforderten. Google entwickelte die Speicherkapazität speziell zur Unterstützung aufkommender multimodaler Modelle und langer Kontext-Anwendungen, die sich Million-Token-Fenstern nähern.
Ironwoods Interconnect bietet 9,6 Tbps aggregierte bidirektionale Bandbreite durch vier ICI-Verbindungen, was sich in 1,2 TB/s Spitzen-pro-Chip-Bandbreite übersetzt.³³ Die Architektur skaliert von 256-Chip-Pods für kleinere Einsätze bis zu massiven 9.216-Chip-Superpods, die 42,5 FP8 Exaflops Rechenleistung liefern.³⁴ Googles Jupiter-Rechenzentrums-Netzwerktechnologie könnte theoretisch bis zu 43 Ironwood-Superpods in einem einzelnen Cluster unterstützen—etwa 400.000 Beschleuniger, die einen fast unvorstellbaren Rechenmaßstab darstellen.³⁵
Die FP8-Unterstützung stellt einen fundamentalen Wandel in der Präzisionsstrategie dar. Vorherige TPU-Generationen emulierten 8-Bit-Operationen mit Software-Techniken, was Overhead einführte. Ironwood implementiert native FP8-Multiplikations-Akkumulations-Einheiten, die sowohl E4M3 (4-Bit-Exponent, 3-Bit-Mantisse) als auch E5M2 (5-Bit-Exponent, 2-Bit-Mantisse) Formate unterstützen.³⁶ Die Dual-Format-Unterstützung ermöglicht das Mischen von E4M3 für Vorwärtsdurchläufe, wo Präzision weniger wichtig ist, und E5M2 für Rückwärtsdurchläufe, wo die Beibehaltung von Gradientenmagnitudes Trainingsinstabilität verhindert.
Anthropics Verpflichtung, über eine Million Ironwood-Chips ab 2026 einzusetzen, demonstriert die Produktionsreife der Architektur. Das Unternehmen plant, weit über ein Gigawatt TPU-Kapazität zu nutzen—genug, um eine kleine Stadt zu versorgen—ausschließlich für das Training und Serving von Claude-Modellen.³⁷ Der Maßstab übertrifft selbst die bedeutendsten bekannten GPU-Einsätze und stellt eine fundamentale Wette auf TPU-Architektur für Frontier-Modellentwicklung dar.
Aktuelle-Generation Schnellreferenz
Die folgenden Tabellen bieten scannbare Spezifikationen für die drei aktuellen TPU-Generationen, die für Produktionseinsätze 2025 am relevantesten sind:
Tabelle 1: Kern-Rechenspezifikationen
[caption id="" align="alignnone" width="1386"] SpezifikationTPU v5eTPU v5pTPU v6e (Trillium)TPU v7 (Ironwood) MXU Array-Größe 128×128 128×128 256×256 256×256 MACs pro Zyklus 16.384 16.384 65.536 65.536 Peak BF16 TFLOPS ~197 ~459 ~918 ~2.300 (geschätzt) Peak FP8 PFLOPS N/A (emuliert) N/A (emuliert) N/A (emuliert) 4,6 Native Präzision BF16, INT8 BF16, INT8 BF16, INT8 BF16, FP8, INT8 TensorCores/Chip 1 2 1 1 [/caption]
SpezifikationTPU v5eTPU v5pTPU v6e (Trillium)TPU v7 (Ironwood) MXU Array-Größe 128×128 128×128 256×256 256×256 MACs pro Zyklus 16.384 16.384 65.536 65.536 Peak BF16 TFLOPS ~197 ~459 ~918 ~2.300 (geschätzt) Peak FP8 PFLOPS N/A (emuliert) N/A (emuliert) N/A (emuliert) 4,6 Native Präzision BF16, INT8 BF16, INT8 BF16, INT8 BF16, FP8, INT8 TensorCores/Chip 1 2 1 1 [/caption]
Tabelle 2: Speicher und Bandbreite
[caption id="" align="alignnone" width="1380"]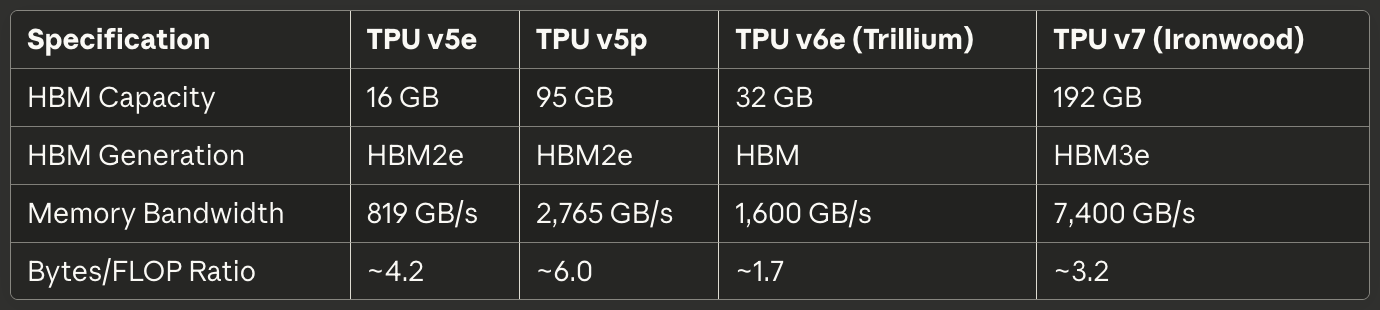 SpezifikationTPU v5eTPU v5pTPU v6e (Trillium)TPU v7 (Ironwood) HBM-Kapazität 16 GB 95 GB 32 GB 192 GB HBM-Generation HBM2e HBM2e HBM HBM3e Speicherbandbreite 819 GB/s 2.765 GB/s 1.600 GB/s 7.400 GB/s Bytes/FLOP-Verhältnis ~4,2 ~6,0 ~1,7 ~3,2 [/caption]
SpezifikationTPU v5eTPU v5pTPU v6e (Trillium)TPU v7 (Ironwood) HBM-Kapazität 16 GB 95 GB 32 GB 192 GB HBM-Generation HBM2e HBM2e HBM HBM3e Speicherbandbreite 819 GB/s 2.765 GB/s 1.600 GB/s 7.400 GB/s Bytes/FLOP-Verhältnis ~4,2 ~6,0 ~1,7 ~3,2 [/caption]
Tabelle 3: Interconnect und Skalierung
[caption id="" align="alignnone" width="1384"]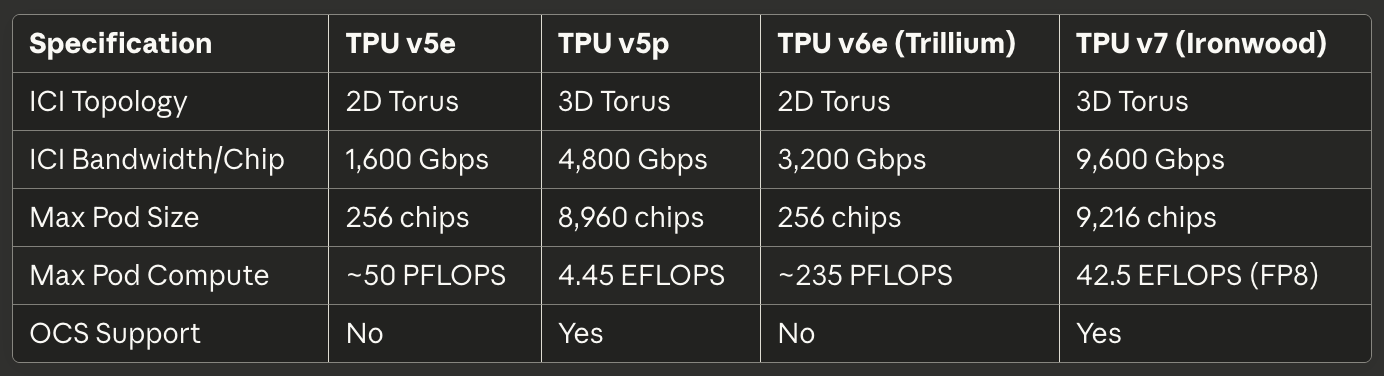 SpezifikationTPU v5eTPU v5pTPU v6e (Trillium)TPU v7 (Ironwood) ICI-Topologie 2D Torus 3D Torus 2D Torus 3D Torus ICI-Bandbreite/Chip 1.600 Gbps 4.800 Gbps 3.200 Gbps 9.600 Gbps Max Pod-Größe 256 Chips 8.960 Chips 256 Chips 9.216 Chips Max Pod-Rechenleistung ~50 PFLOPS 4,45 EFLOPS ~235 PFLOPS 42,5 EFLOPS (FP8) OCS-Unterstützung Nein Ja Nein Ja [/caption]
SpezifikationTPU v5eTPU v5pTPU v6e (Trillium)TPU v7 (Ironwood) ICI-Topologie 2D Torus 3D Torus 2D Torus 3D Torus ICI-Bandbreite/Chip 1.600 Gbps 4.800 Gbps 3.200 Gbps 9.600 Gbps Max Pod-Größe 256 Chips 8.960 Chips 256 Chips 9.216 Chips Max Pod-Rechenleistung ~50 PFLOPS 4,45 EFLOPS ~235 PFLOPS 42,5 EFLOPS (FP8) OCS-Unterstützung Nein Ja Nein Ja [/caption]
Tabelle 4: Leistung und Effizienz
[caption id="" align="alignnone" width="1380"] SpezifikationTPU v5eTPU v5pTPU v6e (Trillium)TPU v7 (Ironwood) TDP ~120-200W ~250-300W ~120-200W 600W Kühlung Luft Flüssig Luft Flüssig TFLOPS/Watt (BF16) ~1,0-1,6 ~1,5-1,8 ~4,6-7,7 ~3,8 Energie vs. vorherige Gen Baseline N/A 67% besser als v5e 2× besser als Trillium [/caption]
SpezifikationTPU v5eTPU v5pTPU v6e (Trillium)TPU v7 (Ironwood) TDP ~120-200W ~250-300W ~120-200W 600W Kühlung Luft Flüssig Luft Flüssig TFLOPS/Watt (BF16) ~1,0-1,6 ~1,5-1,8 ~4,6-7,7 ~3,8 Energie vs. vorherige Gen Baseline N/A 67% besser als v5e 2× besser als Trillium [/caption]
Tabelle 5: Empfohlene Anwendungsfälle
[caption id="" align="alignnone" width="1382"] Anwendungsfall Beste Wahl Begründung Kostenoptimierte Inferenz TPU v5e: Niedrigste Kosten pro Inferenz-Anfrage Groß angelegtes Training (>1000 Chips) TPU v5p oder Ironwood 3D Torus + OCS ermöglicht massive Pods Mittlere Trainingsjobs (256 Chips) TPU v6e Trillium Beste Leistung/Watt, 4,7× Rechenleistung vs v5e Speicherlastige Modelle (>70B Parameter), Ironwood 192GB HBM ermöglicht größere Batch-Größen Lange-Kontext-Inferenz (>100K Token) Ironwood HBM-Kapazität unterstützt massive KV-Caches Embedding-lastige Arbeitslasten TPU v5p oder Ironwood SparseCore + großer HBM [/caption]
Anwendungsfall Beste Wahl Begründung Kostenoptimierte Inferenz TPU v5e: Niedrigste Kosten pro Inferenz-Anfrage Groß angelegtes Training (>1000 Chips) TPU v5p oder Ironwood 3D Torus + OCS ermöglicht massive Pods Mittlere Trainingsjobs (256 Chips) TPU v6e Trillium Beste Leistung/Watt, 4,7× Rechenleistung vs v5e Speicherlastige Modelle (>70B Parameter), Ironwood 192GB HBM ermöglicht größere Batch-Größen Lange-Kontext-Inferenz (>100K Token) Ironwood HBM-Kapazität unterstützt massive KV-Caches Embedding-lastige Arbeitslasten TPU v5p oder Ironwood SparseCore + großer HBM [/caption]
Hardware-Architektur: Im Inneren des Siliziums
Systolische Array-Mathematik und Datenfluss
Die Matrix Multiply Unit bildet das Herzstück der TPU-Architektur, und das Verständnis systolischer Arrays erfordert das Begreifen ihres fundamental unterschiedlichen Ansatzes zur Parallelisierung im Vergleich zu GPU-SIMD-Lanes. Ein systolisches Array verkettet Multiplikations-Akkumulations-Einheiten in einem Gitter, wo Daten rhythmisch durch die Struktur fließen—daher "systolisch", was das rhythmische Pumpen von Blut durch das Herz evoziert.³⁸
Betrachten Sie TPU v6es 256×256 systolisches Array, das die Matrixmultiplikation C = A × B durchführt. Ingenieure laden die Gewichte von Matrix B in die 65.536 individuellen Multiplikations-Akkumulations-Einheiten vor, die in einem Gitter angeordnet sind. Matrix As Aktivierungswerte treten vom linken Rand ein und fließen horizontal über das Array. Jede MAC-Einheit multipliziert ihr gespeichertes Gewicht mit der eingehenden Aktivierung, addiert das Ergebnis zu einer Teilsumme, die von oben ankommt, und übergibt sowohl die Aktivierung (horizontal) als auch die aktualisierte Teilsumme (vertikal) an benachbarte Einheiten.³⁹
Das Datenflussmuster bedeutet, dass jeder Aktivierungswert 256-mal wiederverwendet wird, während er die horizontale Dimension durchquert, und jede Teilsumme Beiträge von 256 Multiplikationen akkumuliert, während sie vertikal fließt. Kritisch ist, dass alle Zwischenergebnisse direkt zwischen benachbarten MAC-Einheiten über kurze Drähte weitergegeben werden, anstatt zum Speicher hin- und herzugehen. Die Architektur führt 65.536 Multiplikations-Akkumulations-Operationen jeden Taktzyklus durch, und während der gesamten Matrixmultiplikation, die potenziell Millionen von Operationen beinhaltet, berühren null Zwischenwerte DRAM oder sogar On-Chip-SRAM.⁴⁰
Das gewichtsstatische Datenflussmuster optimiert für den häufigsten Fall bei neuronaler Netzwerk-Inferenz und -Training: wiederholte Multiplikation vieler verschiedener Aktivierungsmatrizen mit derselben Gewichtsmatrix. Ingenieure laden Gewichte einmal und streamen dann unbegrenzte Aktivierungs-Batches durch das Array, ohne neu zu laden. Das Muster funktioniert außergewöhnlich gut für Faltungsschichten, vollständig verbundene Schichten und die Q·K^T- und Aufmerksamkeit·V-Operationen, die Transformer-Modelle dominieren.⁴¹
Energieeffizienz stammt aus Datenwiederverwendung und räumlicher Lokalität. Das Lesen eines Werts aus DRAM verbraucht etwa 200× so viel Energie wie eine einzelne Multiplikations-Akkumulations-Operation.⁴² Durch 256-maliges Wiederverwenden jedes Gewichts und jeder Aktivierung ohne Speicherzugriffe erreicht das systolische Array Operationen-pro-Watt-Verhältnisse, die für Architekturen unmöglich sind, die Daten zwischen Recheneinheiten und Speicherhierarchien hin- und herbewegen.
Die Schwäche des systolischen Arrays tritt bei dynamischen oder unregelmäßigen Berechnungsmustern auf. Da Daten nach einem festen Zeitplan durch das Gitter fließen, kämpft die Architektur mit bedingter Ausführung, spärlichen Matrizen (außer bei Verwendung von SparseCore) und Operationen, die zufällige Zugriffsmuster erfordern. Die Unflexibilität tauscht Allgemeinheit gegen extreme Effizienz bei ihrer Zielarbeitslast: dichte Matrixmultiplikation mit vorhersagbaren Zugriffsmustern.
TensorCore Interne Architektur
Jeder TPU-Chip enthält einen oder mehrere TensorCores—die vollständige Verarbeitungseinheit, die die Matrix Multiply Unit, Vector Processing Unit und Scalar Unit in Konzert umfasst.⁴³ Der TensorCore stellt den fundamentalen Baustein dar, auf den Software abzielt, und das Verständnis der Interaktion zwischen seinen drei Komponenten erklärt sowohl TPU-Leistungscharakteristika als auch Programmiermuster.
Die Matrix Multiply Unit führt 16.000 Multiplikations-Akkumulations-Operationen pro Zyklus mit bfloat16- oder FP8-Eingaben mit FP32-Akkumulation aus.⁴⁴ Der gemischte Präzisionsansatz bewahrt numerische Genauigkeit im Akkumulator, während er die Speicherbandbreite für Eingaben reduziert. Ingenieure beobachteten, dass die Beibehaltung vollständiger FP32-Präzision während der Akkumulation katastrophale Auslöschungsfehler beim Summieren von Hunderten oder Tausenden von Zwischenprodukten verhindert, während reduzierte Präzision der Eingaben selten die finale Modellqualität beeinflusst.
Die Vector Processing Unit handhabt Operationen, die für die starre Struktur der MXU schlecht geeignet sind. Aktivierungsfunktionen (ReLU, GELU, SiLU), Normalisierungsschichten (Batch Norm, Layer Norm), Softmax, Pooling, Dropout und elementweise Operationen werden auf der 128-Lane-SIMD-Architektur der VPU ausgeführt.⁴⁵ Die VPU operiert mit FP32- und INT32-Datentypen und bietet die für numerisch sensible Operationen wie Softmax erforderliche Präzision, wo Exponentialfunktionen und Divisionen große dynamische Bereiche schaffen können.
Die Scalar Unit orchestriert den gesamten TensorCore. Der single-threaded Prozessor führt Kontrollfluss aus, berechnet Speicheradressen für komplexe Indexierungsmuster und initiiert DMA-Übertragungen von High Bandwidth Memory zu Vector Memory.⁴⁶ Da die Skalar-Einheit single-threaded läuft, kann jeder TensorCore nur eine DMA-Anfrage pro Zyklus erstellen—ein Engpass für speicherintensive Operationen, die MXU- oder VPU-Rechendurchsatz nicht auslasten.
Die Speicherhierarchie, die den TensorCore speist, bestimmt erreichbare Leistung ebenso wie rohe Rechenkapazität. Vector Memory (VMEM) fungiert als software-verwalteter Scratchpad-SRAM exklusiv für jeden TensorCore, typischerweise dimensioniert auf Dutzende Megabytes. Der XLA-Compiler plant explizit Datenbewegung zwischen HBM und VMEM und entscheidet, was in den schnellen lokalen Speicher gestellt und wann Ergebnisse zurückgeschrieben werden.⁴⁷
Common Memory (CMEM), vorhanden in TPU v4 und späteren Generationen, bietet einen größeren geteilten Pool, der für alle TensorCores auf einem Chip zugänglich ist. Die TPU v4-Architektur ordnete 128MB CMEM zu, geteilt zwischen zwei TensorCores, was anspruchsvollere Produzent-Konsument-Muster ermöglichte, bei denen die Ausgaben eines Kerns die Eingaben eines anderen Kerns speisen, ohne zu HBM zurückzugehen.⁴⁸
Die Programmiermodell-Implikationen sind enorm wichtig. Da die Skalar-Einheit single-threaded ist und der Vektorspeicher explizite Verwaltung erfordert, ähnelt TPU-Programmierung der Entwicklung eingebetteter Systeme der 1990er Jahre mehr als moderner GPU-Programmierung. CUDA abstrahiert Speicherbewegung mit unified Memory und hardware-verwalteten Caches; TPU-Code (ob von XLA generiert oder handgeschrieben in Pallas) muss jede Datenübertragung explizit orchestrieren. Manuelle Kontrolle ermöglicht Expertenoptimierung, erhöht aber die Schwelle für kompetente Leistung.
High Bandwidth Memory-Architektur
Moderne TPUs verwenden HBM (High Bandwidth Memory) oder HBM3e, eine radikal andere Speichertechnologie als das in CPUs gefundene DDR SDRAM und das in vielen GPUs verwendete GDDR. HBM stapelt mehrere DRAM-Dies vertikal unter Verwendung von Through-Silicon Vias (TSVs) und platziert dann den Stapel direkt neben dem Prozessor-Die auf einem Silizium-Interposer.⁴⁹ Der kurze elektrische Pfad und die breite Schnittstelle ermöglichen dramatisch höhere Bandbreite als konventionelle Speichertechnologien.
TPU v7 Ironwood implementiert 192GB HBM3e mit einer Gesamtbandbreite von 7,4 TB/s.⁵⁰ Das Speichersystem ist in mehrere Kanäle unterteilt, die jeweils unabhängigen Zugriff auf einen separaten Teil der Gesamtkapazität bieten. Der XLA-Compiler und die Runtime müssen Tensoren sorgfältig über HBM-Kanäle partitionieren, um parallelen Zugriff zu maximieren und Hotspots zu vermeiden, wo ein Kanal sättigt, während andere untätig sind.
Die Speicherschnittstellenbreite übertrifft konventionelles DRAM bei weitem. Während ein DDR5-Kanal 64 Bits Breite bieten könnte, umfasst ein HBM-Kanal typischerweise 1.024 Bits.⁵¹ Die extreme Breite ermöglicht hohe Bandbreite bei relativ bescheidenen Taktfrequenzen, wodurch Stromverbrauch und Signalintegritätsprobleme im Vergleich zum Antrieb schmaler Schnittstellen zu Multi-Gigahertz-Frequenzen reduziert werden.
Latenzcharakteristika unterscheiden sich erheblich von GPU-Speichersystemen. TPUs fehlen hardware-verwaltete Caches jenseits kleiner lokaler Puffer, so dass die Architektur darauf angewiesen ist, dass Software Daten explizit in VMEM lange vor dem Bedarf der Recheneinheiten stellt. Das Fehlen von Caches bedeutet, dass Speicherlatenz die Leistung direkt beeinflusst, es sei denn, der Compiler verbirgt erfolgreich Latenz durch Prefetching und Double-Buffering.⁵²
Speicherkapazitätslimits dominieren viele Arbeitslasten mehr als Rechendurchsatz. Ein 175-Milliarden-Parameter-Modell mit bfloat16-Gewichten erfordert 350GB zur Speicherung der Parameter—bereits Ironwoods 192GB HBM überschreitend, selbst vor der Berücksichtigung von Aktivierungen, Optimizer-Zuständen oder Gradientenpuffern. Training solcher Modelle erfordert anspruchsvolle Techniken wie Gradient Checkpointing, Optimizer-Zustand-Sharding über mehrere Chips und sorgfältige Planung von Parameter-Updates zur Minimierung des Speicher-Footprints.⁵³
Die TPU-Runtime erzwingt spezifische Tensor-Layout-Anforderungen zur Maximierung der MXU-Effizienz. Da das systolische Array Daten in 128×8-Kacheln verarbeitet, sollten Tensoren an diesen Dimensionen ausgerichtet werden, um Padding-Verschwendung zu vermeiden.⁵⁴ Schlecht dimensionierte Matrizen zwingen die Hardware, partielle Kacheln zu verarbeiten, wobei MACs untätig sind, was direkt die FLOPS-Auslastung reduziert. Der Compiler versucht, Tensoren automatisch zu padden und umzuformen, aber bewusste Layout-Entscheidungen in der Modellarchitektur können die Leistung erheblich verbessern.
SparseCore: Spezialisierte Embedding-Beschleunigung
Während die Matrix Multiply Unit bei dichten Matrixoperationen exzelliert, zeigen embedding-intensive Arbeitslasten radikal unterschiedliche Charakteristika. Empfehlungsmodelle, Ranking-Systeme und große Sprachmodelle greifen häufig über unregelmäßige, datenabhängige Indizes auf massive Embedding-Tabellen (oft Hunderte von Gigabytes) zu. Das strukturierte Datenfluss der MXU bietet keinen Vorteil für diese spärlichen Speicherzugriffsmuster, was SparseCore's spezialisierte Architektur motiviert.⁵⁵
SparseCore implementiert einen gekachelten Datenfluss-Prozessor, der sich fundamental vom systolischen Array der MXU unterscheidet. TPU v4 verfügte über vier SparseCores pro Chip, jeder mit 16 Rechen-Kacheln.⁵⁶ Jede Kachel operiert als unabhängige Datenfluss-Einheit mit lokalem Scratchpad-Speicher (SPMEM) und Verarbeitungselementen. Die Kacheln führen parallel aus und verarbeiten disjunkte Teilmengen von Embedding-Operationen gleichzeitig.
Die Speicherhierarchie platziert heiße Daten in kleinem, schnellem SPMEM, während die vollständigen Embedding-Tabellen in HBM gehalten werden. Der XLA-Compiler analysiert Embedding-Zugriffsmuster, um zu bestimmen, welche Embedding-Vektoren Caching in SPMEM verdienen versus on-demand Abrufen aus HBM.⁵⁷ Die Strategie ähnelt traditionellen CPU-Cache-Hierarchien, aber mit Software statt Hardware, die Platzierungsentscheidungen trifft.
SparseCores verbinden sich direkt mit HBM-Kanälen und umgehen den Speicherpfad des TensorCore vollständig. Die dedizierte Verbindung verhindert, dass Embedding-Operationen mit dichten Matrixoperationen um Speicherbandbreite konkurrieren, wodurch beide parallel ablaufen können.⁵⁸ Die Partitionierung funktioniert außergewöhnlich gut für Modelle wie Deep Learning Recommendation Models (DLRMs), die dichte neuronale Netzwerkschichten mit großen Embedding-Lookups verschachteln.
Die Mod-Sharding-Strategie verteilt Embeddings über SparseCores durch Berechnung von target_sc_id = col_id % num_total_sparse_cores.⁵⁹ Die einfache Sharding-Funktion gewährleistet Lastausgleich, wenn Embedding-IDs gleichmäßig verteilt sind, kann aber Hotspots für schiefe Zugriffsmuster schaffen. Ingenieure, die mit realen Daten arbeiten, müssen oft Embedding-Häufigkeitsverteilungen analysieren und Sharding manuell neu ausbalancieren, um Engpässe zu vermeiden.
Leistungsgewinne von SparseCore erreichen 5-7× im Vergleich zur Implementierung identischer Operationen auf MXU und VPU, während nur 5% der Chip-Die-Fläche und Energie verbraucht werden.⁶⁰ Der dramatische Effizienzvorteil stammt aus dem zweckgerichteten Aufbau des Datenflusses für spärliche Operationen statt sie durch dichte Matrix-Infrastruktur zu zwingen. Das Spezialisierungsprinzip wendet sich rekursiv innerhalb der TPU-Architektur an: genau wie TPUs über GPUs allgemeinen Design spezialisieren, spezialisieren SparseCores über TPUs matrix-orientiertes Design.
Trilliums SparseCore der dritten Generation führte variable SIMD-Breite (8 Elemente für FP32, 16 für bfloat16) und verbesserte Speicherzugriffsmuster ein, wodurch verschwendete Bandbreite durch fehlausgerichtete Reads reduziert wurde.⁶¹ Die architektonische Evolution demonstriert Googles anhaltende Investition in Embedding-Beschleunigung, da große Sprachmodelle zu größeren Vokabularen und anspruchsvolleren Retrieval-Augmented-Generation-Mustern tendieren.
Interconnect-Technologie: Die Verkabelung des Supercomputers
Inter-Chip Interconnect (ICI) Architektur
Der Inter-Chip Interconnect ist die kritische Technologie, die es TPUs ermöglicht, als vereinheitlichte Supercomputer zu funktionieren und nicht als isolierte Beschleuniger. Im Gegensatz zu GPUs, die über Ethernet- oder InfiniBand-Netzwerke kommunizieren, implementiert ICI maßgeschneiderte Hochgeschwindigkeits-Seriellverbindungen, die benachbarte TPUs direkt mit Latenzzeiten im Mikrosekundenbereich und Terabit-pro-Sekunde-Bandbreite verbinden.⁶²
Die Topologie-Evolution über TPU-Generationen hinweg spiegelt sich ändernde Anforderungen für Pod-Skalierung wider. TPU v2, v3, v5e und v6e implementieren 2D-Torus-Topologien, bei denen jeder Chip mit seinen vier nächsten Nachbarn (Norden, Süden, Osten und Westen) verbunden ist.⁶³ Die Verbindungen umhüllen an den Grenzen und schaffen eine donutförmige logische Topologie, die Randchips mit weniger Verbindungen eliminiert. Ein 16×16-Gitter von 256 TPUs bietet somit einheitliche Bandbreiten- und Latenzcharakteristika, unabhängig davon, welche zwei Chips kommunizieren.
TPU v4 und v5p wurden auf 3D-Torus-Topologien aufgerüstet, wobei jeder Chip mit sechs Nachbarn verbunden ist.⁶⁴ Die zusätzliche Dimension reduziert den Netzwerkdurchmesser—die maximale Hop-Anzahl zwischen zwei beliebigen Chips—von ungefähr 2√N auf 3∛N. Für einen 4.096-Chip-Pod sinken die maximalen Hops von etwa 128 auf 48, was die Worst-Case-Kommunikationslatenz für global synchronisierende Operationen wie All-Reduce erheblich reduziert.
Die torusförmige Struktur bietet einen weiteren kritischen Vorteil: gleiche Bisektionsbandbreite unabhängig davon, wie Workloads über Chips partitioniert werden. Jeder Schnitt, der den Torus halbiert, durchkreuzt die gleiche Anzahl von Verbindungen und verhindert pathologische Fälle, bei denen schlechte Job-Platzierung Netzwerk-Engpässe erzeugt.⁶⁵ Die einheitliche Bisektionsbandbreite vereinfacht die Planung und ermöglicht die unten diskutierte Rekonfigurierbarkeit von optischen Schaltkreis-Switches.
Bandbreitenspezifikationen skalieren beeindruckend über Generationen hinweg. TPU v6e bietet 13 TB/s ICI-Bandbreite pro Chip.⁶⁶ TPU v5p erreichte 4.800 Gbps pro Chip über sechs 3D-Torus-Verbindungen.⁶⁷ Ironwood implementiert vier ICI-Verbindungen mit einer aggregierten bidirektionalen 9,6-Tbps-Bandbreite, was 1,2 TB/s pro Chip entspricht.⁶⁸ Zum Vergleich: Eine erstklassige 400GbE-Netzwerkschnittstelle bietet 50GB/s bidirektionale Bandbreite—eine Größenordnung weniger als moderne TPU ICI.
Link-Technologie innerhalb von Racks verwendet direkt angeschlossene Kupferkabel (DAC) für kurze Distanzen zwischen Chips im selben 4×4×4-Würfel.⁶⁹ Die Kupferverbindungen minimieren Kosten und Strom und bieten gleichzeitig die erforderliche Bandbreite für eng gekoppelte Chips, die synchronisierte Operationen ausführen. Inter-Würfel- und Pod-Scale-Verbindungen wechseln zu optischen Transceivern und tauschen höhere Kosten und Strom gegen die Distanz und Bandbreite, die benötigt wird, um Datacenter-Racks zu überspannen.
Kollektive Operationen nutzen ICIs einzigartige Eigenschaften. All-Reduce-, All-Gather- und Reduce-Scatter-Operationen synchronisieren häufig Aktivierungen und Gradienten über Chips hinweg während des Trainings. Auf Ethernet-basierten GPU-Clustern durchlaufen diese Kollektive ein hierarchisches Netzwerk mit Switches, Kabeln und Netzwerkschnittstellenkarten, was Latenz bei jedem Hop einführt. TPU ICI implementiert optimierte kollektive Algorithmen direkt in Hardware und führt All-Reduce-Operationen 10× schneller aus als äquivalente Ethernet-basierte GPU-Implementierungen.⁷⁰
Optisches Circuit Switching: Dynamische Topologie-Rekonfiguration
Googles Einsatz von optischem Circuit Switching (OCS) mit TPU v4 stellte eine der bedeutendsten Innovationen im Datacenter-Networking seit Jahrzehnten dar. Traditionelle paketvermittelte Netzwerke—ob Ethernet oder InfiniBand—etablieren logische Verbindungen durch Routing von Paketen Hop-für-Hop durch Switches, die Header untersuchen und zu entsprechenden Ausgabeports weiterleiten. OCS verwendet stattdessen programmierbare optische Elemente, um direkte physische Lichtpfade zwischen Endpunkten zu schaffen und Switching-Latenz vollständig zu eliminieren.⁷¹
Die Kerntechnologie basiert auf MEMS (mikroelektromechanischen Systemen) Spiegeln, die sich physisch drehen, um Lichtstrahlen umzuleiten. Ein Sender auf TPU A sendet Licht in den OCS. Winzige Spiegel im OCS drehen sich, um diesen Lichtstrahl zu einem Empfänger auf TPU B zu reflektieren. Die Verbindung wird zu einem direkten optischen Pfad von A zu B mit im Wesentlichen null zusätzlicher Latenz über die Lichtausbreitung durch die Faser hinaus.⁷²
Die Rekonfigurationsgeschwindigkeit bestimmt die Praktikabilität von OCS in Produktionssystemen. Googles Deployment erreicht Sub-10-Nanosekunden-Switching-Zeiten—schneller als typische Netzwerkprotokoll-Round-Trip-Zeiten.⁷³ Die Rekonfigurationsgeschwindigkeit ermöglicht dynamische Topologieänderungen, die Workload-Anforderungen entsprechen, ohne laufende Jobs zu stören oder sorgfältig koordiniertes Traffic Engineering zu erfordern.
TPU v5p demonstrierte OCS in massivem Maßstab. Die Architektur verwendet optische Circuit Switches, die vier Petabits pro Sekunde aggregierte Bandbreite über das Switching-Fabric liefern.⁷⁴ Ein einzelner v5p-Superpod erfordert 48 OCS-Einheiten, die 13.824 optische Ports verwalten, um 8.960 Chips in der 16×20×28-3D-Torus-Konfiguration zu verkabeln.⁷⁵ Das Switching-System stellt eines der größten optischen Networking-Deployments in jeder Computing-Umgebung dar.
OCS bietet Fähigkeiten, die mit traditionellen Netzwerken unmöglich sind. Physische Topologie und logische Topologie entkoppeln vollständig—zwei TPUs in gegenüberliegenden Ecken des Datacenters erscheinen als benachbarte Nachbarn, wenn der OCS direkte optische Pfade erstellt. Ausgefallene Chips oder Links werden umgeleitet, indem Spiegel umprogrammiert werden, um fehlerhafte Komponenten auszuschließen und die logische Torus-Struktur aufrechtzuerhalten. Neue Jobs erhalten „Slices" beliebiger Größe durch Programmierung des OCS, um geeignete Pod-Konfigurationen zu erstellen, ohne physisch Racks neu zu verkabeln.⁷⁶
Die Architektur integriert sich mit Googles Jupiter Datacenter-Netzwerk, um über einen einzelnen Pod hinaus zu skalieren. Jupiter liefert Multi-Petabit-pro-Sekunde-Bisektionsbandbreite über ganze Datacenter unter Verwendung von Googles maßgeschneiderten Silizium-Switches und Control Plane.⁷⁷ Mehrere TPU-Superpods verbinden sich über Jupiter-Fabric und unterstützen theoretisch Cluster von bis zu 400.000 Beschleunigern, wenn die Netzwerkkapazität es erlaubt.⁷⁸
Stromverbrauch und Zuverlässigkeitscharakteristika begünstigen optisches Circuit Switching für TPU-Scale-Deployments. Traditionelle Paket-Switches verbrauchen erheblichen Strom beim Verarbeiten und Weiterleiten von Paketen bei Terabit-pro-Sekunde-Raten. OCS-Switches verbrauchen nur Strom zum Betrieb von MEMS-Spiegeln während Rekonfigurationsereignissen, dann bleiben sie untätig und leiten Licht mit minimalem Verlust weiter, während Verbindungen stabil bleiben.⁷⁹ Die Einfachheit der Architektur verbessert die Zuverlässigkeit durch Eliminierung komplexer Paketverarbeitung und Pufferlogik, die anfällig für Bugs und Performance-Anomalien ist.
Pod-Architektur und Skalierungscharakteristika
TPU-Pods stellen die größte Einzeleinheit von TPUs dar, die durch ICI verbunden sind und einen vereinheitlichten Beschleuniger bilden. Die physische Struktur baut hierarchisch von einzelnen Chips zu Trays zu Würfeln zu Racks zu kompletten Pods auf.⁸⁰ Das Verständnis der Hierarchie ist wichtig für das Reasoning über Speicherkapazität, Kommunikationsbandbreite und Fehlertoleranz auf verschiedenen Skalen.
Der fundamentale Baustein besteht aus vier Chips auf einem einzelnen Tray, die über PCIe mit einer Host-CPU verbunden sind.⁸¹ Die PCIe-Verbindung handhabt Control-Plane-Operationen, initial Programmladen und Infeed/Outfeed für Trainingsdaten und Inferenzergebnisse. Die tatsächliche Inter-Chip-Kommunikation für verteiltes Training fließt durch ICI statt PCIe und vermeidet PCIe-Bandbreiten-Engpässe.
Sechzehn Trays (64 Chips) bilden einen einzelnen 4×4×4-Würfel—die Grundeinheit für Pod-Konstruktion. Innerhalb eines Würfels verwenden alle ICI-Verbindungen direkt angeschlossene Kupferkabel, da Chips im selben Rack mit kurzen physischen Distanzen residieren.⁸² Der Würfel implementiert einen kompletten 3D-Torus mit Wrap-Around-Verbindungen und schafft eine eigenständige 64-Chip-Einheit, die theoretisch unabhängig operieren könnte.
TPU v4-Pods skalieren auf 64 Würfel mit insgesamt 4.096 Chips.⁸³ Die Inter-Würfel-Verbindungen wechseln zu optischen Links, die vom optischen Circuit-Switching-Fabric verwaltet werden. Der OCS kann diese 4.096 Chips als einen einzelnen enormen Pod, mehrere kleinere unabhängige Pods bereitstellen oder dynamisch mid-job rekonfigurieren, falls erforderlich. Die Flexibilität ermöglicht es Datacenter-Betreibern, die Auslastung über verschiedene Job-Größen und Prioritäten hinweg auszubalancieren.
TPU v5p trieb Pod-Scale auf 8.960 Chips in einem 16×20×28-3D-Torus.⁸⁴ Die spezifischen Dimensionen spiegeln sorgfältige Bandbreiten- und Durchmesseroptimierung wider—Primfaktorisierungen sind wichtig für Netzwerktopologie! Der Pod liefert 4,45 Exaflops an Compute und stellt eine der größten Einzel-Pod-Konfigurationen dar, die in der Produktion eingesetzt wurden.
Ironwood unterstützt sowohl 256-Chip-Pods für kleinere Deployments als auch 9.216-Chip-Superpods für massives Frontier-Model-Training.⁸⁵ Die 9.216-Chip-Konfiguration liefert 42,5 FP8-Exaflops—mehr Compute als die gesamte Top500-Liste von Supercomputern nur fünf Jahre früher enthielt.⁸⁶ Die Skala redefiniert, was Organisationen mit synchronem Training anstatt pipelined oder asynchronen Ansätzen erreichen können.
Skalierungseffizienz bestimmt, ob größere Pods tatsächlich helfen. Kommunikations-Overhead steigt mit Pod-Größe, da Chips mehr Zeit mit Synchronisierung als mit Computing verbringen. Google Research veröffentlichte Ergebnisse, die 95% Skalierungseffizienz bei 32.768 TPUs für spezifische Workloads demonstrieren, was bedeutet, dass 32.768 TPUs 95% der Performance lieferten, die perfekte lineare Skalierung vorhersagen würde.⁸⁷ Die Effizienz stammt von hardware-beschleunigten Kollektiven, optimierten Compiler-Transformationen und cleveren algorithmischen Ansätzen zur Reduzierung der Gradienten-Synchronisationsfrequenz.
Fehlertoleranz auf Pod-Scale erfordert ausgeklügelte Handhabung. Statistische Wahrscheinlichkeit garantiert Komponentenausfälle in jedem System mit tausenden von Chips, die kontinuierlich laufen. Der optische Circuit Switch ermöglicht graceful degradation durch Rekonfiguration um ausgefallene Komponenten herum. Training-Checkpointing erfolgt in regelmäßigen Intervallen (typischerweise alle paar Minuten), sodass Job-Failure nur einen Neustart vom letzten Checkpoint erfordert und nicht von Anfang an.⁸⁸
Software Stack: Compiler, Frameworks und Programmiermodelle
XLA Compiler: Optimierung von Computation Graphs
XLA (Accelerated Linear Algebra) bildet das Fundament des TPU Software Stacks und kompiliert High-Level Framework-Operationen in optimierten Maschinencode für die Ausführung auf der TPU.⁸⁹ Der Compiler implementiert aggressive Optimierungen, die in universellen Compilern unmöglich sind, da er Domänenwissen über Machine Learning Workloads und TPU-Architektur-Eigenschaften ausnutzt.
Fusion stellt XLAs wirkungsvollste Optimierung dar. Der Compiler analysiert Computation Graphs, um Sequenzen von Operationen zu identifizieren, die ohne Materialisierung von Zwischentensoren ausgeführt werden können. Ein einfaches Beispiel: Element-weise Operationen wie relu(batch_norm(conv(x))) erfordern normalerweise das Schreiben der Convolution-Ausgabe in den Speicher, das Lesen für Batch-Normalization, das Schreiben dieses Ergebnisses in den Speicher und erneutes Lesen für ReLU. XLA fusioniert diese Operationen zu einem einzigen Kernel, der die finale ReLU-Ausgabe ohne zwischenzeitlichen Speicher-Traffic produziert.⁹⁰
Fusions Einfluss skaliert mit der TPU-Architektur. Speicherbandbreite limitiert viele Workloads stärker als Compute-Durchsatz—die MXU kann Matrizenmultiplikationen schneller ausführen, als das Speichersystem sie mit Daten versorgen kann. Die Eliminierung von zwischenzeitlichen Speicherschreibvorgängen und -lesevorgängen durch Fusion übersetzt sich direkt in Leistungsverbesserungen und liefert oft 2× oder mehr Speedup für aktivierungsfunktionsreiche Netzwerke.⁹¹
Memory Layout Transformationen optimieren Tensor-Speicherung für Hardware-Anforderungen. Neuronale Netzwerke repräsentieren Tensoren oft im NHWC-Format (Batch, Höhe, Breite, Kanäle) für intuitive Indizierung, aber TPU MXUs funktionieren am besten mit Layouts, die mit 128×8-Kacheln ausgerichtet sind.⁹² XLA transponiert, formt um und polstert Tensoren automatisch entsprechend Hardware-Präferenzen, fügt Layout-Transformationen nur dort ein, wo nötig, und propagiert manchmal bevorzugte Layouts rückwärts durch den Graph, um den gesamten Transformations-Overhead zu minimieren.
Der Compiler implementiert ausgeklügelte Constant Folding und Dead Code Elimination. ML-Graphs enthalten häufig Subgraphs, deren Ausgaben nur von Konstanten abhängen—Batch-Normalization-Parameter, Inference-Dropout-Raten und Form-Berechnungen, die einmal statt pro Batch ausgeführt werden können. XLA evaluiert diese Subgraphs zur Compile-Zeit und ersetzt sie durch konstante Tensoren, wodurch Runtime-Arbeit reduziert wird.⁹³
Cross-Replica-Optimierung nutzt Wissen über verteilte Ausführung aus. Beim Training über mehrere TPU-Kerne hinweg erfordern bestimmte Operationen (wie Batch-Normalization-Statistiken) Aggregation über alle Replikas. XLA identifiziert diese Muster und generiert optimierte kollektive Operationen, die ICIs hardware-beschleunigte All-Reduce ausnutzen, anstatt Aggregation durch explizites Message Passing zu implementieren.⁹⁴
Der Compiler zielt auf eine Zwischendarstellung, Mosaic, spezifisch für TPUs ab. Mosaic operiert auf einem höheren Abstraktionslevel als Assemblersprache, aber niedriger als der Input Computation Graph. Die Sprache exponiert TPU-Architektur-Features wie systolische Arrays, Vector Memory und VMEM-Staging, während sie Low-Level-Details wie Instruction Scheduling und Register Allocation verbirgt.⁹⁵
Auto-Tuning-Fähigkeiten wählen optimale Kachelgrößen und Operations-Parameter durch empirische Suche aus. Das XLA Auto-Tuning (XTAT) System probiert verschiedene Fusion-Strategien, Memory Layouts und Kacheldimensionen aus, profiliert die Performance jeder Variante und wählt die schnellste Konfiguration.⁹⁶ Die Suche kann erhebliche Compile-Zeit für komplexe Modelle erfordern, produziert aber dramatische Runtime-Speedups durch das Entdecken kontraintuitiver Optimierungen, die Menschen selten manuell identifizieren.
JAX: Composable Transformations und SPMD
JAX bietet eine NumPy-kompatible Schnittstelle für numerische Berechnungen mit automatischer Differenzierung, JIT-Kompilierung zu XLA und First-Class-Unterstützung für Programmtransformation.⁹⁷ Das funktionale Programmierparadigma des Frameworks und das komponierbare Transformationsmodell passen natürlich zu TPU-Ausführungsmodellen und verteilten Parallelismusmustern.
Die zentrale JAX-Abstraktion wendet mathematische Transformationen auf Funktionen an. Grad(f) berechnet f's Gradient. Jit(f) JIT-kompiliert f zu XLA. vmap(f) vektorisiert f über eine neue Dimension. Entscheidend ist, dass Transformationen komponieren: jit(grad(vmap(f))) funktioniert genau wie erwartet und kompiliert eine vektorisierte Gradientenfunktion.⁹⁸ Das Kompositionsmodell ermöglicht das Erstellen komplexer verteilter Trainingsschleifen aus einfachen, testbaren Komponenten.
SPMD (Single Program, Multiple Data) repräsentiert JAXs verteiltes Ausführungsmodell. Programmierer schreiben Code, als würden sie ein einzelnes Gerät ansprechen, fügen dann Sharding-Annotationen hinzu, die angeben, wie Tensoren über mehrere TPU-Kerne partitioniert werden sollen. Der XLA Compiler und das GSPMD (General SPMD) Subsystem fügen automatisch Kommunikationsoperationen ein, um Programmsemantik zu erhalten, während sie über verteilte Geräte ausführen.⁹⁹
Sharding-Annotationen verwenden PartitionSpec, um Verteilungsstrategien zu deklarieren. PartitionSpec('batch', None) teilt die erste Dimension eines Tensors über die 'batch'-Achse des Device Mesh, während die zweite Dimension repliziert wird. PartitionSpec(None, 'model') implementiert Tensorparallelismus durch Partitionierung der zweiten Dimension. Die Annotationen können mit beliebigen Tensor-Rängen und Device Mesh Dimensionen komponiert werden.¹⁰⁰
GSPMDs automatische Parallelisierung eliminiert riesige Mengen Boilerplate-Code. Traditionelles verteiltes Training erfordert manuelles Einfügen eines All-Gather vor Operationen, die vollständige Tensoren benötigen, eines Reduce-Scatter nach der Berechnung verteilter Gradienten und eines All-Reduce für globale Reduktionen. GSPMD analysiert Sharding-Spezifikationen und fügt automatisch geeignete Kollektive ein, wodurch Programmierer sich auf den Algorithmus statt auf Communication Engineering konzentrieren können.¹⁰¹
Der Compiler propagiert Sharding-Entscheidungen durch den Computation Graph mittels Constraint Solving. Wenn Operation A einen geteilten Tensor ausgibt, der von Operation B konsumiert wird, inferiert GSPMD Bs optimales Sharding basierend darauf, wie die Ausgabe verwendet wird, und fügt möglicherweise Resharding-Operationen nur dort ein, wo mathematisch notwendig.¹⁰² Die automatisierte Inferenz verhindert das "Sharding Spaghetti", das handgeschriebenen verteilten Code plagt.
JAX bietet feinkörnige Kontrolle, wenn Automatisierung zu kurz greift. with_sharding_constraint erzwingt spezifisches Sharding an Graph-Lokationen und überschreibt automatische Inferenz. Benutzerdefinierte PJIT (parallel JIT) Annotationen spezifizieren exakte Geräteplatzierung und Sharding-Strategien für performance-kritische Code-Pfade. Das geschichtete Modell ermöglicht schnelles Prototyping mit automatischem Sharding und unterstützt gleichzeitig Expertenoptimierung wo erforderlich.¹⁰³
Shardy entstand als GSPMDs Nachfolger im Jahr 2025 und implementiert verbesserte Constraint-Propagation-Algorithmen und bessere Behandlung dynamischer Formen.¹⁰⁴ Das neue System exponiert zusätzliche Optimierungsmöglichkeiten, indem es Sharding-Entscheidungen gemeinsam über größere Graph-Regionen hinweg durchdenkt, anstatt Operation für Operation.
PyTorch/XLA: PyTorch zu TPUs bringen
PyTorch/XLA ermöglicht das Ausführen von PyTorch-Modellen auf TPUs mit minimalen Code-Änderungen und überbrückt die Kluft zwischen PyTorchs imperativem Programmiermodell und XLAs graph-basierter Kompilierung.¹⁰⁵ Die Integration balanciert die Bewahrung von PyTorchs Entwicklererfahrung mit der Exposition TPU-spezifischer Optimierungen.
Die fundamentale Herausforderung entstammt PyTorchs Eager Execution Philosophie. PyTorch führt Operationen sofort aus, während Python-Statements ausgeführt werden, wodurch Debugging mit Standardwerkzeugen und natürlicher Kontrollfluss ermöglicht wird. XLA erfordert das Erfassen vollständiger Computation Graphs vor der Kompilierung, wodurch Spannung zwischen Eager Execution und den Performance-Vorteilen der Graph-Kompilierung entsteht.¹⁰⁶
PyTorch/XLA 2.4 führte Eager Mode Unterstützung ein und adressierte das Impedance Mismatch. Die Implementierung verfolgt PyTorch-Operationen dynamisch in XLA-Graphs und ermöglicht Entwicklern, Standard-PyTorch-Code zu schreiben, während sie trotzdem von XLA-Kompilierung profitieren.¹⁰⁷ Der Mode tauscht einige Kompilierungsoptimierungsmöglichkeiten gegen Entwicklungsgeschwindigkeit und Debugging-Einfachheit.
Graph Mode bleibt der primäre Pfad für Produktionsdeployments. Entwickler markieren Funktionen explizit für XLA-Kompilierung mittels Decorators oder Compilation APIs. Die expliziten Annotationen ermöglichen aggressive Optimierung, erfordern aber das Verständnis, welche Operationen zu einem einzigen XLA-Graph fusioniert werden sollen versus unabhängig ausgeführt.¹⁰⁸
Pallas-Integration bringt Custom Kernel Development zu PyTorch/XLA. Pallas bietet eine Low-Level-Sprache zum Schreiben von TPU-Kernels, wenn XLAs automatische Fusion zu kurz greift oder spezialisierte Operationen Handoptimierung erfordern.¹⁰⁹ Die Sprache exponiert TPU-Speicherhierarchie (VMEM, CMEM, HBM) und Compute Units (MXU, VPU), während sie höheres Level als roher Assembly bleibt.
Eingebaute Pallas-Kernel implementieren performance-kritische Operationen wie FlashAttention und PagedAttention. FlashAttentions gekachelte Attention-Berechnung reduziert Memory Bandwidth Anforderungen von O(n²) zu O(n) für Sequenzlänge n und ermöglicht Modellen, viel längere Sequenzen innerhalb fester Memory Budgets zu verarbeiten.¹¹⁰ PagedAttention optimiert Key-Value-Cache-Management für Serving und erreicht 5× Speedup verglichen mit gepolsterten Implementierungen.¹¹¹
Die PyTorch/XLA-Brücke erwies sich als kritisch für vLLM TPU—ein High-Performance-Serving-Framework, ursprünglich für GPUs konzipiert. Die Implementierung verwendet tatsächlich JAX als intermediären Lowering-Pfad sogar für PyTorch-Modelle und nutzt JAXs überlegene Parallelismus-Unterstützung aus, während PyTorch-Frontend-Kompatibilität erhalten bleibt.¹¹² Die Architektur erreichte 2-5× Performance-Verbesserungen während 2025 verglichen mit anfänglichen Prototypen.
Modellkompatibilitäts-Herausforderungen bestehen trotz Verbesserungen fort. Einige PyTorch-Operationen haben keine XLA-Äquivalente und erzwingen einen Fallback zur CPU-Ausführung, der Performance degradiert. Dynamischer Kontrollfluss wird schlecht von Graph-Kompilierung unterstützt und erfordert oft architektonische Änderungen, um dynamisches Verhalten durch statische, kompilierbare Alternativen zu ersetzen. Das PyTorch/XLA Repository dokumentiert Kompatibilität und bietet Migrationshandbücher für häufige problematische Muster.¹¹³
Precision Formats: BFloat16, FP8 und Quantization
TPUs Unterstützung für reduzierte Präzisions-Arithmetik ermöglicht dramatische Performance- und Memory-Verbesserungen bei Aufrechterhaltung akzeptabler Modellqualität. Das Verstehen der numerischen Eigenschaften verschiedener Formate und wann jedes anzuwenden ist, erweist sich als kritisch für optimale Performance.¹¹⁴
BFloat16 repräsentiert Googles frühen Einsatz auf reduzierte Präzisions-Training, erstmals in TPU v2 erschienen. Das Format behält FP32s 8-Bit-Exponent bei, während die Mantissa auf 7 Bits (plus Vorzeichen-Bit) gekürzt wird.¹¹⁵ Der volle Exponentenbereich verhindert Underflow und Overflow, die frühes FP16-Training plagten, wo Gradienten häufig FP16s darstellbaren Bereich verließen.
Die reduzierte Mantissa führt Quantisierungsfehler ein, beeinflusst aber selten finale Modellqualität. Ingenieure beobachteten, dass in bfloat16 trainierte Modelle typischerweise FP32-trainierte Baselines innerhalb statistischen Rauschens erreichen, wahrscheinlich weil die Quantisierung als Form der Regularisierung wirkt und Overfitting auf winzige numerische Details verhindert.¹¹⁶ Das Format halbiert Memory Bandwidth und Kapazitätsanforderungen verglichen mit FP32 und übersetzt sich direkt in Performance-Gewinne bei memory-bound Workloads.
FP8 treibt reduzierte Präzision weiter und komprimiert Weights und Aktivierungen auf 8 Bits. Zwei Standard-Encodings existieren: E4M3 (4-Bit-Exponent, 3-Bit-Mantissa) priorisiert Präzision für Forward Passes, während E5M2 (5-Bit-Exponent, 2-Bit-Mantissa) Range für Backward Passes priorisiert, wo Gradienten-Magnitudes stark variieren.¹¹⁷ Ironwood implementiert native FP8-Unterstützung für beide Formate, während frühere TPUs FP8 durch Software-Transformationen emulierten.¹¹⁸
Quantization Awareness während des Trainings ermöglicht FP8s numerischen Erfolg. Von Grund auf mit FP8 trainierte oder mit FP8-aware-Techniken fine-getunete Modelle lernen Weight-Verteilungen, die das Formats limitierte Präzision tolerieren. Post-Training-Quantization (Konvertierung von FP32-Modellen zu FP8 nach Training) degradiert oft Qualität ohne sorgfältige Kalibrierung.¹¹⁹
INT8-Quantization liefert noch größere Memory-Einsparungen und Inference-Speedups. Googles Accurate Quantized Training (AQT) ermöglicht INT8-Training auf TPUs mit minimalem Qualitätsverlust verglichen mit bfloat16-Baselines.¹²⁰ Die Technik wendet Quantization-aware Training von Grund auf an und ermöglicht Modellen, sich an INT8s Beschränkungen während des Lernens anzupassen, anstatt durch Post-Training-Approximation.
Mixed-Precision-Strategien kombinieren Formate strategisch. Forward Passes könnten FP8 für Aktivierungen und Weights verwenden, Backward Passes FP8 E5M2 oder bfloat16 für Gradienten und Optimizer States bleiben in FP32 für numerische Stabilität während Weight Updates.¹²¹ Der gemischte Ansatz balanciert Speed, Memory und Accuracy und erreicht oft 90%+ von FP32-Qualität, während er 4× schneller läuft.
Präzisions-Tradeoffs erstrecken sich über Speed und Memory hinaus auf numerische Stabilitätsüberlegungen. Batch Normalization, Layer Normalization und Softmax erfordern sorgfältige numerische Behandlung in reduzierter Präzision. Große Exponentiellen in Softmax können FP8- oder bfloat16-Bereiche überlaufen; das Subtrahieren des maximalen Logits vor Exponentiation verhindert Overflow bei Aufrechterhaltung mathematischer Äquivalenz.¹²² Der XLA Compiler implementiert diese Transformationen automatisch wenn sicher, aber Custom Operations erfordern manchmal manuelles numerisches Engineering.
## Programmiermodelle und Parallelisierungsstrategien
SPMD und automatische Partitionierung
Das Single Program, Multiple Data (SPMD) Paradigma prägt grundlegend, wie Programmierer über TPU-Ausführung denken. Anstatt expliziten Message-Passing-Code zu schreiben, um mehrere Prozesse zu koordinieren, schreiben Entwickler ein einziges Programm und annotieren, wie Daten über Geräte hinweg partitioniert werden sollen.¹²³ Der Compiler übernimmt die mechanischen Details von Verteilung, Kommunikation und Synchronisation.
GSPMD (General SPMD) implementiert die automatische Partitionierungslogik in XLA. Das System analysiert Tensor-Sharding-Annotationen und die Struktur des Berechnungsgraphen, um zu bestimmen, wo Operationen auf welchen Geräten ausgeführt werden und welche Kommunikation erforderlich ist, um korrekte Semantik zu gewährleisten.¹²⁴ Die Automatisierung eliminiert ganze Klassen von Fehlern, die in handgeschriebenem verteiltem Code häufig auftreten—falsch übereinstimmende Tensor-Formen, inkorrekte Collective-Operation-Reihenfolgen und Deadlocks durch unsachgemäße Synchronisation.
Die Constraint-Propagation-Engine des Compilers leitet Sharding-Entscheidungen aus minimalen Annotationen ab. Oft genügt es, nur die Input- und Output-Sharding-Annotationen eines Modells zu setzen; GSPMD propagiert Constraints durch Zwischenoperationen und wählt automatisch effiziente Verteilungen aus.¹²⁵ Wenn mehrere gültige Shardings für eine Operation existieren, schätzt der Compiler die Kommunikationskosten der Alternativen und wählt die kostengünstigste Option.
Erweiterte Optimierungen überlappen Kommunikation mit Berechnung. All-reduce-Operationen, die Gradienten über Replikas hinweg synchronisieren, können starten, sobald die Gradienten der ersten Schicht abgeschlossen sind, und parallel zu Rückwärtsdurchläufen für nachfolgende Schichten ausgeführt werden.¹²⁶ Der Compiler plant Collectives automatisch, um Überlappung zu maximieren und die effektive Kommunikationszeit um den Faktor 2× oder mehr im Vergleich zur sequenziellen Ausführung zu reduzieren.
Rematerialisierung tauscht Berechnung gegen Speicher. Anstatt alle Aktivierungen des Vorwärtsdurchlaufs für die Gradientenberechnung zu speichern, berechnet der Compiler Aktivierungen während Rückwärtsdurchläufen selektiv neu, wenn der Speicherdruck Schwellenwerte überschreitet.¹²⁷ Der Kompromiss funktioniert besonders gut auf TPUs, wo Berechnung oft die Speicherbandbreite übertrifft und Neuberechnung günstiger macht als Speicherverkehr.
Datenparallelität, Tensorparallelität und Pipeline-Parallelität
Datenparallelität stellt die einfachste verteilte Trainingsstrategie dar: Das komplette Modell wird über N Geräte repliziert und verschiedene Daten-Batches auf jeder Replika verarbeitet. Nach der lokalen Gradientenberechnung aggregiert ein All-reduce die Gradienten über Replikas hinweg, und alle Geräte wenden identische Gewichtsupdates an.¹²⁸ Der Ansatz skaliert linear, bis die Kommunikationszeit die Berechnungszeit dominiert—typischerweise um 1.000 GPUs mit Ethernet-Netzwerk, aber 10.000+ TPUs mit ICI.¹²⁹
Tensorparallelität (auch Modellparallelität genannt) partitioniert einzelne Operationen über Geräte hinweg. Eine Matrixmultiplikation Y = W @ X teilt die Gewichtsmatrix W auf Geräte auf, wobei jedes einen Teil der Ausgabe berechnet.¹³⁰ Die Strategie ermöglicht das Training von Modellen, die den Speicher einzelner Geräte überschreiten, durch Verteilung von Parameterspeicherung und Berechnung.
Das Kommunikationsmuster für Tensorparallelität unterscheidet sich erheblich von dem der Datenparallelität. Anstatt All-reduce nach jeder Schicht erfordert Tensorparallelität ein All-gather vor Operationen, die vollständige Tensoren benötigen, und ein Reduce-scatter nach verteilten Berechnungen.¹³¹ Das Kommunikationsvolumen skaliert mit der Modell-Aktivierungsgröße statt mit der Parametergröße und erzeugt andere Engpässe als Datenparallelität.
Pipeline-Parallelität partitioniert sequenzielle Modellschichten über Geräte hinweg und verarbeitet verschiedene Mikro-Batches auf verschiedenen Stufen gleichzeitig. GPipe führte die Strategie mit sorgfältigem Scheduling ein, um Pipeline-Auslastung zu maximieren und gleichzeitig Speicherverbrauch zu begrenzen.¹³² Jedes Gerät verarbeitet den Vorwärtsdurchlauf eines Mikro-Batches, sendet Aktivierungen zur nächsten Stufe und verarbeitet dann den nächsten Mikro-Batch—wodurch eine Pipeline entsteht, in der alle Geräte nach der anfänglichen Anlaufphase kontinuierlich arbeiten.
Gradientenstagnation verkompliziert Pipeline-Parallelität. Geräte aktualisieren Gewichte mit Gradienten, die aus Aktivierungen berechnet wurden, die potenziell dutzende von Mikro-Batches alt sind, was Stagnation erzeugt, die der Konvergenz schaden kann.¹³³ Ausgeklügelte Scheduling-Algorithmen wie PipeDream minimieren Stagnation bei Aufrechterhaltung hohen Durchsatzes, und empirische Ergebnisse zeigen, dass die meisten Modelle moderate Stagnation ohne Qualitätsverschlechterung tolerieren.
3D-Parallelität kombiniert alle drei Strategien. Datenparallelität verteilt über die "Daten"-Dimension, Tensorparallelität über die "Modell"-Dimension und Pipeline-Parallelität über die "Pipeline"-Dimension.¹³⁴ Sorgfältiges Ausbalancieren der Dimensionen basierend auf Modellarchitektur, Hardware-Topologie und Kommunikationskosten maximiert den Durchsatz. GPT-3-skalige Modelle verwenden häufig 3D-Parallelität mit Datenparallelität über 8-16 Replikas, Tensorparallelität über 4-8 GPUs und Pipeline-Parallelität über 4-16 Stufen.
Sharding-Strategien und Optimierung
Die Auswahl von Sharding-Strategien erfordert das Verständnis der mathematischen Operationen und ihrer Datenabhängigkeiten. Matrixmultiplikation C = A @ B erlaubt mehrere gültige Shardings: beide A und B replizieren und partielle Ergebnisse berechnen (Kommunikation vor Berechnung), B spaltenweise sharden und Ergebnisse sammeln (Kommunikation nach Berechnung), oder A zeilenweise und B spaltenweise sharden ohne Kommunikation, aber mit kleineren Pro-Gerät-Matrizen.¹³⁵
Collective-Operation-Kosten bestimmen optimale Strategien. All-reduce-Kosten skalieren linear mit Tensorgröße, aber sublinear mit Geräteanzahl unter Verwendung baumbasierter oder ringbasierter Reduktionsalgorithmen:¹³⁶ All-gather und Reduce-scatter zeigen unterschiedliche Skalierungseigenschaften. Der Compiler modelliert diese Kosten und wählt Sharding-Strategien, die die gesamte Kommunikationszeit minimieren.
Sequenz-Parallelität erweist sich als kritisch für große Sprachmodelle. Attention-Mechanismen erzeugen Speicherengpässe, weil Key-Value-Caches mit Sequenzlänge und Batch-Größe wachsen. Partitionierung entlang der Sequenzdimension verteilt die Speicherlast über Geräte hinweg und führt Kommunikation nur für die Attention-Berechnung selbst ein.¹³⁷
Expert-Parallelität behandelt Mixture-of-Experts (MoE) Modelle, bei denen verschiedene Experten verschiedene Tokens verarbeiten. Die Sharding-Strategie repliziert geteilte Schichten über alle Geräte, partitioniert aber Experten und leitet jeden Token zum designierten Expertengerät.¹³⁸ Das dynamische Routing erzeugt unregelmäßige Kommunikationsmuster, die traditionelle Collective-Operationen herausfordern und ausgeklügelte Laufzeitsysteme erfordern, um Latenz und Lastungleichgewicht zu minimieren.
Optimizer-State-Sharding reduziert Speicher-Overhead für große Modelle. Optimierer wie Adam speichern Momentum- und Varianzstatistiken für jeden Parameter, was die Speicheranforderungen über die für Parameter allein verdreifacht. Das Sharden von Optimizer-Zuständen über Geräte hinweg bei Replikation der Parameter ermöglicht das Training größerer Modelle innerhalb fester Speicherbudgets.¹³⁹ Die Strategie erfordert das Sammeln von Optimizer-State-Updates während Gewichtsberechnungen, reduziert aber den Pro-Gerät-Speicher-Footprint erheblich.
Leistungsanalyse und Benchmarking
MLPerf Ergebnisse und Wettbewerbspositionierung
MLPerf bietet branchenübliche Benchmarks zur Messung der Leistung von AI-Beschleunigern bei Training- und Inferenz-Workloads. Google reicht regelmäßig TPU-Ergebnisse ein, die wettbewerbsfähige Leistung demonstrieren, und die Entwicklung über Generationen hinweg zeigt deutliche architektonische Verbesserungen.¹⁴⁰
TPU v5e erzielte führende Ergebnisse in 8 von 9 MLPerf Training-Kategorien.¹⁴¹ Diese Breite demonstriert architektonische Vielseitigkeit jenseits nur großer Sprachmodelle—wettbewerbsfähige Leistung bei Computer Vision, Empfehlungssystemen und wissenschaftlichen Computing-Workloads. BERT Training wurde 2,8× schneller als bei NVIDIA A100 GPUs abgeschlossen, was die transformer-optimierte Architektur validiert.¹⁴²
MLPerf Training v5.0, angekündigt im Juni 2025, führte einen Llama 3.1 405B Benchmark ein, der das größte Modell in der Suite repräsentiert.¹⁴³ Der Benchmark belastet Multi-Node Skalierung, Kommunikations-Overhead und Speicherkapazität stärker als frühere Tests. Google Cloud beteiligte sich mit TPU-Einreichungen, obwohl detaillierte Leistungsvergleiche unter Embargo bleiben bis zur Veröffentlichung der offiziellen Ergebnisse.
MLPerf Inference v5.0 enthielt vier neue Benchmarks: Llama 3.1 405B, Llama 2 70B für niedrig-latenz Anwendungen, RGAT Graph Neural Networks und PointPainting für 3D-Objekterkennung.¹⁴⁴ Die Vielfalt treibt Beschleuniger über konventionelle Transformer-Workloads hinaus in neue Anwendungsdomänen, wo architektonische Annahmen sich unterscheiden können.
Inferenz-Benchmarks begünstigen besonders die architektonischen Stärken der TPU. Batch-Inferenz-Workloads nutzen die massive Parallelität der MXU und erreichen 4× höheren Durchsatz als konkurrierende Beschleuniger beim Transformer-Serving.¹⁴⁵ Single-Query-Latenz profitiert von der deterministischen Ausführung der TPU und dem Fehlen von Thermal Throttling, was konsistente Latenz ohne die Leistungsschwankungen liefert, die manche GPU-Deployments plagen.
Energieeffizienz-Metriken zeigen TPU-Vorteile, die sich über Generationen hinweg vergrößern. TPU v4 demonstrierte 2,7× bessere Leistung pro Watt als TPU v3, und Trillium verbesserte sich um 67% gegenüber v5e.¹⁴⁶ Ironwood beansprucht 2× bessere Leistung pro Watt als Trillium trotz signifikant höherer absoluter Leistung.¹⁴⁷ Die Effizienzgewinne verstärken sich in Tausend-Chip-Pods und übersetzen sich in Millionen von Dollar bei Rechenzentrum-Betriebskosten.
Reale Training- und Inferenz-Leistung
Produktions-Workloads offenbaren Leistungscharakteristika, die bei synthetischen Benchmarks fehlen. Google veröffentlicht Ergebnisse von internen Services, die TPU-Verhalten unter realen Nutzungsmustern und Skalierungsanforderungen demonstrieren.¹⁴⁸
ResNet-50 ImageNet Training wird in 28 Minuten auf TPU-Pods abgeschlossen, ein weithin zitierter Benchmark für Computer Vision Workload-Leistung.¹⁴⁹ Die Time-to-Accuracy-Metrik erfasst den kompletten Trainingsprozess, einschließlich Datenladen, Augmentierung, verteilter Gradienten-Synchronisation und Checkpoint-Speicherung—nicht nur theoretische FLOPs.
T5-3B Sprachmodell-Training demonstriert TPU-Vorteile bei Transformer-Architekturen. Das 3-Milliarden-Parameter-Modell trainiert in 12 Stunden auf TPU-Pods, verglichen mit 31 Stunden bei äquivalenten GPU-Konfigurationen.¹⁵⁰ Die 2,6× Beschleunigung stammt von hardware-beschleunigten Attention-Operationen, effizienter Speicherbandbreiten-Nutzung und optimierten kollektiven Kommunikationen.
GPT-3 Maßstabs-Workloads (175B Parameter) erreichen 1,7× schnellere Time-to-Accuracy auf TPUs als bei zeitgenössischen GPUs.¹⁵¹ Die Leistungslücke vergrößert sich bei noch größeren Modellen, wo Speicherkapazität und Bandbreite zu kritischen Beschränkungen werden. Ironwoods 192GB HBM3e ermöglicht das Serving von Modellen, die komplexe Tensor-Parallelität bei Alternativen mit geringerem Speicher erfordern.
Skalierungs-Effizienz-Messungen demonstrieren nahezu lineare Beschleunigung bis zu enormen Maßstäben. Google Research berichtete 95% Skalierungs-Effizienz bei 32.768 TPUs für spezifische Transformer-Training-Workloads.¹⁵² Die Metrik bedeutet, dass 32.768 TPUs 95% der Leistung lieferten, die perfekte lineare Skalierung vorhersagen würde—bemerkenswert angesichts steigender Kommunikations-Overheads mit dem Maßstab.
FLOPS-Nutzungs-Metriken zeigen, wie effektiv Workloads verfügbare Rechenleistung nutzen. Transformer-Modelle erreichen typischerweise 90% FLOPS-Nutzung auf TPUs, was bedeutet, dass 90% der theoretischen Spitzenleistung in tatsächliche Arbeit übersetzt werden.¹⁵³ Hohe Nutzung stammt von Operations-Fusion, die Speicher-Engpässe eliminiert, Systolic-Array-Effizienz bei großen Matrix-Multiplikationen und Compiler-Optimierungen, die verschwendete Zyklen minimieren.
Produktions-Inferenz-Services demonstrieren nachhaltige Leistung über Milliarden von Anfragen pro Tag. Google Translate verarbeitet täglich 1 Milliarde Anfragen auf TPUs.¹⁵⁴ YouTube-Empfehlungen bedienen 2 Milliarden Nutzer mit TPU-beschleunigten Modellen.¹⁵⁵ Google Photos analysiert monatlich 28 Milliarden Bilder für Such- und Organisationsfunktionen.¹⁵⁶ Der operative Maßstab validiert Zuverlässigkeit und Kosteneffizienz jenseits von Forschungsprototyp-Deployments.
Energieeffizienz und Total Cost of Ownership
Stromverbrauch beeinflusst direkt Rechenzentrum-Betriebskosten und Umweltnachhaltigkeit. TPUs Energieeffizienz-Verbesserungen über Generationen hinweg reduzieren sowohl Betriebsausgaben als auch CO2-Emissionen in großem Maßstab.¹⁵⁷
TPU v4 verzeichnete nur 200W durchschnittliche Leistungsaufnahme in Produktions-Workloads trotz einer 250W TDP-Spezifikation.¹⁵⁸ Der Spielraum zwischen durchschnittlicher und Spitzenleistung ermöglicht flexibles thermisches Design und Bereitstellung. Im Gegensatz zu GPUs, wo andauernde Workloads oft TDP-Limits erreichen, was konservative Rack-Leistungsbudgets erfordert.
Ironwoods 600W TDP repräsentiert höhere absolute Leistung als frühere Generationen, liefert aber dramatisch mehr Rechenleistung pro Watt.¹⁵⁹ Die 4,6 PFLOPS FP8-Leistung pro Chip ergibt etwa 7,7 TFLOPS pro Watt—wettbewerbsfähig oder überlegen zur zeitgenössischen GPU-Effizienz bei äquivalenten Workloads.
Rechenzentrum-Energienutzungseffektivität (PUE) verstärkt Chip-Level-Effizienz. Googles TPU-Rechenzentren erreichen eine PUE von 1,1, was nur 10% Leistungs-Overhead jenseits des Chip-Verbrauchs für Kühlung, Stromumwandlung und Vernetzung bedeutet.¹⁶⁰ Industriedurchschnitt-PUE reicht von 1,5 bis 2,0, wo 50-100% zusätzliche Leistung an Infrastruktur-Overhead geht. Die niedrige PUE stammt von fortschrittlichen Kühlsystemen, effizienter Stromversorgung und bewusstem Rechenzentrum-Design, das für ML-Workloads optimiert ist.
CO2-Intensitäts-Betrachtungen erstrecken sich über Strom hinaus und umfassen Energiequellen. Google betreibt TPU-Rechenzentren mit CO2-neutralem Strom durch Beschaffung erneuerbarer Energien und CO2-Ausgleichsprogramme.¹⁶¹ Die CO2-Bilanzierung wird zunehmend wichtig für Organisationen, die Scope-2-Emissionen aus Cloud-Computing verfolgen.
Total-Cost-of-Ownership (TCO)-Analyse muss Anschaffungskosten, Stromverbrauch, Kühlungsanforderungen und Wartungsausgaben berücksichtigen. TPU-Deployments zeigen häufig 20-30% TCO-Reduktionen verglichen mit äquivalenten GPU-Installationen, primär angetrieben durch überlegene Leistung pro Watt und reduzierte Kühlungskomplexität.¹⁶²
Kühlungsinfrastruktur-Kosten skalieren nicht-linear mit Leistungsdichte. Luftgekühlte Racks erreichen typischerweise 15-20kW pro Rack bevor sie exotische Kühlungslösungen erfordern. Hochleistungs-GPUs drängen diese Grenzen, manchmal mit der Notwendigkeit flüssiger Kühlungsinfrastruktur mit wesentlich höheren Kapital- und Betriebskosten. TPUs Effizienz hält mehr Deployments im luftgekühlten Bereich und vereinfacht Rechenzentrum-Design.¹⁶³
Technische Vorteile: Wo TPUs Exzellieren
Hardware-Beschleunigte Kollektive Operationen
Die spezialisierte Unterstützung für kollektive Operationen in TPU ICI bietet einen der bedeutendsten Vorteile gegenüber herkömmlichen vernetzten Beschleunigern. All-reduce, die zentrale Operation für die Synchronisierung von Gradienten beim verteilten Training, wird auf TPU ICI 10× schneller ausgeführt als vergleichbare Ethernet-basierte GPU-Implementierungen.¹⁶⁴
Die Leistungslücke ergibt sich aus der architektonischen Integration. Ethernet-basierte Kollektive durchlaufen mehrere Schichten: Anwendungscode ruft die Kollektiv-Bibliothek auf (NCCL, Horovod, etc.), die Pakete generiert, die an den Netzwerk-Stack übergeben werden, der Daten zur NIC überträgt, die auf die Leitung serialisiert, Switches durchläuft, an empfangenden NICs deserialisiert und den Prozess umkehrt. Jede Schicht fügt Latenz hinzu, kopiert Daten durch Speicherhierarchien und verbraucht CPU-Zyklen für die Protokollverarbeitung.¹⁶⁵
TPU ICI implementiert Kollektive in Hardware ohne Durchlaufen der Software-Schicht. Die Operation startet direkt vom TensorCore, streamt Daten über dedizierte ICI-Links und wird abgeschlossen, ohne die Host-CPU zu involvieren. Der direkte Hardware-Pfad eliminiert den Overhead, der traditionelle Implementierungen dominiert.¹⁶⁶
Die optische Circuit-Switch-Topologie ermöglicht optimale kollektive Algorithmen. Das ring-basierte All-reduce benötigt nur 2(N-1) Nachrichten für N Geräte, und die Torus-Topologie bietet kürzeste-Pfad-Routing, wodurch Latenz minimiert wird.¹⁶⁷ Die einheitliche Bisektions-Bandbreite verhindert Hotspots, wo schlecht geroutete Kollektive Netzwerk-Links verstopfen.
Einheitlicher Speicherbereich und Vereinfachte Programmierung
TPUs einheitliches Speichermodell vereinfacht die Programmierung im Vergleich zu GPUs' komplexen Speicherhierarchien. Programmierer denken über einen einzigen HBM-Pool nach, anstatt Übertragungen zwischen Host-RAM, GPU-Global-Speicher, Shared Memory und Register-Files zu verwalten. Das vereinfachte Modell reduziert Bugs und ermöglicht schnellere Entwicklungsgeschwindigkeit.¹⁶⁸
Speicherfragmentierung verschwindet als Problem. GPUs allokieren Speicher aus einem fragmentierten Heap, wo Allokationen und Deallokationen über Zeit Löcher schaffen, die Kompaktierung erfordern. TPU-Speicherverwaltung über die statische Analyse des Compilers vermeidet Runtime-Fragmentierung vollständig—Tensoren werden vorbestimmten Standorten basierend auf dem Berechnungsgraph zugewiesen.¹⁶⁹
Das Programmiermodell eliminiert ganze Klassen von CUDA-Fehlern. Keine "illegal memory access"-Fehler mehr durch inkorrekte Zeiger-Arithmetik, keine Cache-Kohärenz-Bugs zwischen CPU und GPU, keine Synchronisationsfehler durch fehlende cudaDeviceSynchronize()-Aufrufe. Die höhere Abstraktionsebene verhindert die häufigen Fallstricke in der CUDA-Programmierung.¹⁷⁰
Deterministische Ausführung und Reproduzierbarkeit
Gleitkomma-Nicht-Assoziativität schafft Reproduzierbarkeitsprobleme im parallelen Computing. Der Ausdruck (a + b) + c kann aufgrund von Rundungsfehlern andere Ergebnisse liefern als a + (b + c), und parallele Reduktionen können in verschiedenen Reihenfolgen über Durchläufe hinweg summieren, abhängig von Race Conditions.¹⁷¹
TPU-Ausführung zeigt stärkeren Determinismus als typische GPU-Implementierungen. Das feste Datenfluss-Muster des systolischen Arrays gewährleistet identische Operationsreihenfolge über Durchläufe hinweg. Kollektive Operationen folgen deterministischen Reduktionsbäumen anstatt opportunistischer Aggregation basierend auf Ankunftsreihenfolge. Die Vorhersagbarkeit ermöglicht reproduzierbares Training, wo identische Hyperparameter und Daten bit-identische Modellgewichte produzieren.¹⁷²
Debugging profitiert enorm vom Determinismus. Nicht-deterministisches Training macht die Ursachenanalyse von Fehlern nahezu unmöglich—stammt das NaN von einem echten algorithmischen Bug oder einer zufälligen Race Condition? Deterministische Ausführung bedeutet, dass Fehler zuverlässig reproduziert werden, was systematische Debugging-Ansätze ermöglicht.¹⁷³
Scientific Computing-Anwendungen schätzen Reproduzierbarkeit besonders. Klimamodelle, Arzneimittelentdeckungs-Simulationen und Physikforschung erfordern verifizierbare Ergebnisse, die verschiedenen Forschern ermöglichen, identische Ergebnisse zu reproduzieren. TPUs Determinismus unterstützt die wissenschaftliche Methode besser als konkurrierende nicht-deterministische Alternativen.¹⁷⁴
Compiler-Optimierungen und Entwicklerproduktivität
XLAs aggressive Optimierung liefert substanzielle Leistungsverbesserungen "out of the box" ohne manuelles Tuning. Forscher berichten von 40% Verbesserungen im Modell-Durchsatz durch Kompilierung allein im Vergleich zu Eager-Execution-Frameworks.¹⁷⁵ Die Leistung kommt kostenlos—keine Kernel-Entwicklung erforderlich.
Fusion-Optimierung kommt Entwicklern besonders zugute. Manuelles Fusionieren von Operationen in CUDA erfordert das Schreiben benutzerdefinierter Kernel, das Testen der Korrektheit und die Wartung des Codes über Framework-Versionen hinweg. XLA fusioniert automatisch Operationen und Updates und passt Fusion-Strategien an, während sich Modelle entwickeln, wodurch die Wartungsbelastung eliminiert wird.¹⁷⁶
Layout-Transformations-Automatisierung spart Wochen manueller Optimierung. Die Bestimmung optimaler Tensor-Layouts für GPU erfordert das Profiling verschiedener Anordnungen, manuelles Einfügen von Transposen und sorgfältiges Verwalten von Speicherallokationsmustern. XLA probiert Layouts automatisch aus und wählt das schnellste, wodurch Entwickler sich auf Modellarchitektur statt auf Low-Level-Performance-Engineering konzentrieren können.¹⁷⁷
Der Produktivitätsgewinn potenziert sich für Forschungsteams. Zeit, die bei Infrastruktur-Optimierung gespart wird, beschleunigt wissenschaftlichen Fortschritt und ermöglicht mehr Experimente und schnellere Iterationszyklen. Organisationen berichten von 3× Entwicklungsgeschwindigkeitsverbesserungen beim Wechsel von GPU-CUDA-Programmierung zu TPU-JAX-basierten Workflows.¹⁷⁸
Technische Einschränkungen und Nachteile
Platform Lock-In und On-Premises-Beschränkungen
TPU-Zugang ist ausschließlich über die Google Cloud Platform verfügbar, was On-Premises-Deployment verhindert und Vendor Lock-In-Bedenken aufwirft.¹⁷⁹ Organisationen mit Datensouveränitätsanforderungen, air-gapped Netzwerken oder Richtlinien gegen Public Cloud können TPU unabhängig von der technischen Überlegenheit nicht nutzen.
Diese Einschränkung wird zunehmend relevant, da AI zur kritischen Infrastruktur wird. Die Abhängigkeit von einem einzigen Cloud-Anbieter schafft Risiken für die Geschäftskontinuität—Preisänderungen, Verfügbarkeitsstörungen oder Serviceeinstellungen könnten kostspielige Migrationen erzwingen.¹⁸⁰ Die Verfügbarkeit von GPUs von mehreren Anbietern (NVIDIA-Hardware auf AWS, Azure, GCP und on-prem) bietet Optionen, die TPU architektonisch ausschließt.
Multi-Cloud-Strategien stoßen auf Widerstand. Organisationen, die auf TPU standardisieren, können nicht einfach auf andere Clouds ausweichen oder Multi-Cloud-Redundanz implementieren, ohne Modelle neu zu trainieren oder separate Codebasen für verschiedene Accelerator-Architekturen zu unterhalten.¹⁸¹ Die operative Komplexität hybrider GPU/TPU-Deployments überwiegt oft die Kosteneinsparungen durch optimale Accelerator-Auswahl.
Reifegrad-Lücke des CUDA-Ökosystems
NVIDIAs CUDA-Plattform hat über 15 Jahre Ökosystem-Entwicklung, Bibliotheken, Dokumentation und Community-Wissen angesammelt, das TPU nicht erreichen kann.¹⁸² Die Reifegrad-Lücke zeigt sich in zahlreichen Schmerzpunkten bei der TPU-Einführung.
Die Bibliotheksverfügbarkeit begünstigt CUDA überwältigend. Spezialisierte Bereiche wie Computergrafik, Molekulardynamik, Computational Fluid Dynamics und Genomik haben über die vergangenen Jahrzehnte Tausende CUDA-optimierter Bibliotheken angesammelt. TPU-Äquivalente existieren oft nicht und erfordern entweder CPU-Fallback (was die Performance zerstört) oder monatelange Portierungsarbeit.¹⁸³
Community-Support unterscheidet sich um Größenordnungen. Stack Overflow enthält Hunderttausende CUDA-Fragen mit detaillierten Antworten—GitHub-Repositories zählen in die Millionen. Konferenzvorträge, wissenschaftliche Arbeiten und Blog-Posts fokussieren überwiegend auf CUDA-Programmierung. TPU-Programmierer stehen vergleichsweise spärlichen Ressourcen, längeren Debugging-Zyklen und weniger Experten zum Konsultieren gegenüber.¹⁸⁴
Lernmaterialien und Tutorials zielen überwiegend auf CUDA ab. Universitätskurse lehren GPU-Programmierung mit CUDA. Online-Kurse fokussieren auf CUDA. Die Talent-Pipeline produziert weitaus mehr CUDA-erfahrene Ingenieure als TPU-Experten, was Einstellungs- und Trainingsherausforderungen schafft.¹⁸⁵
Custom Kernel Development veranschaulicht die Ökosystem-Lücke. Das Schreiben optimierter CUDA-Kernel bleibt nicht trivial, profitiert aber von umfangreicher Dokumentation, Profiling-Tools und Beispielcode. Pallas ermöglicht custom TPU-Kernel, aber mit weniger reifen Tools und einer kleineren Wissensbasis. Die Lernkurve schreckt alle bis auf die leistungskritischsten Optimierungen ab.¹⁸⁶
Workload-Spezialisierung und Flexibilitätsbeschränkungen
TPUs Architektur optimiert für spezifische Workload-Muster—primär dichte Matrixmultiplikation mit regulären Zugriffsmustern und großen Batch-Größen. Operationen außerhalb des Sweet Spots begegnen Performance-Klippen.¹⁸⁷
Dynamische Shapes fordern TPU-Ausführungsmodelle heraus. Der XLA-Compiler nimmt feste Tensor-Dimensionen für Optimierung und Code-Generierung an. Modelle mit variablen Sequenzlängen, dynamischem Control Flow oder datenabhängigen Shapes erfordern Padding auf maximale Größen (was Compute und Memory verschwendet) oder Rekompilierung für jede distinkte Shape (was Performance zerstört).¹⁸⁸
Sparse Operations erhalten trotz SparseCore begrenzte Unterstützung. Sparse Matrix-Matrix-Multiplikation, eine in Scientific Computing und Graph Neural Networks übliche Workload, fehlen effiziente Implementierungen auf MXU oder VPU. Der spezialisierte SparseCore behandelt Embedding-Tabellen, aber nicht allgemeine sparse lineare Algebra.¹⁸⁹
Small Batch Inference unternutzt TPUs parallele Ressourcen. Das 256×256 Systolic Array gedeiht bei großen Matrizen, die das Gitter mit produktiver Arbeit füllen. Single-Query-Inference lässt die meisten MACs idle, was per-Query-Latenz und Kosten schlechter als GPU-Alternativen ergibt, die für Low-Batch-Szenarien optimiert sind.¹⁹⁰
Irreguläre Berechnungsmuster vereiteln Systolic Array-Effizienz. Algorithmen mit unvorhersagbarem Branching, rekursiven Strukturen oder Pointer-Chasing Memory Access zeigen schlechte TPU-Performance, weil der feste Dataflow sich nicht an laufzeitabhängiges Verhalten anpassen kann.¹⁹¹
Non-ML-Workloads profitieren selten von TPU-Beschleunigung. Wissenschaftliche Simulationen, Video-Encoding, Blockchain-Verifikation und Rendering laufen alle schneller auf GPUs' allgemeinerer Architektur trotz TPUs höherer Peak-FLOPs für Matrix-Operationen.¹⁹²
Debugging- und Development-Tooling-Lücken
NVIDIAs Ökosystem umfasst reife Profiling-Tools (Nsight Systems, Nsight Compute, nvprof), Debugger (cuda-gdb) und Analyse-Frameworks, die über Jahrzehnte verfeinert wurden. TPU-Tooling existiert, hinkt aber substanziell in der Sophistikation hinterher.¹⁹³
XProf bietet grundlegendes Profiling durch TensorBoard-Integration, fehlt aber der granulare Hardware-Counter-Zugang, den NVIDIA-Tools bieten. Das Verstehen von Cache-Miss-Raten, Occupancy, Warp Divergence oder Memory Bank Conflicts—alle kritische GPU-Optimierungsmetriken—hat kein TPU-Äquivalent, weil die Architektur sich fundamental unterscheidet.¹⁹⁴
Error Messages verschleiern oft die Grundursachen. XLA-Kompilierungsfehler produzieren kryptische Nachrichten über Shape-Mismatches oder nicht unterstützte Operationen, ohne klare Anleitung zur Auflösung. CUDA-Fehler, obwohl berüchtigt für Unhilfsamkeit, profitieren von fünfzehn Jahren StackOverflow-Erklärungen und Tribal Knowledge.¹⁹⁵
Debugging von Distributed Training auf Multi-Chip-Pods nähert sich der Unmöglichkeit ohne spezialisierte Tools. Race Conditions, Gradient-Synchronization-Bugs und Collective Operation Failures manifestieren sich als non-deterministische Fehler (ironischerweise trotz TPUs Determinismus-Vorteilen), die inkonsistent reproduzieren und systematischer Diagnose widerstehen.¹⁹⁶
Die Iterationsschleife verlängert sich schmerzhaft für komplexe Modelle. Rekompilierung für Shape-Änderungen oder Architekturmodifikationen kann Minuten erfordern und die Entwicklung einfrieren, während der Compiler arbeitet. CUDAs Eager Execution Model ermöglicht schnellere Iteration trotz niedrigerer Peak-Performance.¹⁹⁷
Real-World-Deployments: Produktion im großen Maßstab
Anthropic Claude: Multi-Plattform-Strategie
Anthropics Ankündigung im Oktober 2025, über eine Million TPU-Chips zu deployieren, stellt das größte öffentlich bekannte AI-Accelerator-Engagement in der Geschichte dar.¹⁹⁸ Das Unternehmen plant, deutlich über ein Gigawatt Rechenkapazität zu nutzen, die 2026 exklusiv für das Training und Serving zukünftiger Claude-Modelle online geht.
Der Umfang übertrifft vorherige Deployments um Größenordnungen. Eine Million Chips, konfiguriert als Ironwood TPUs, würde etwa 4,6 Exaflops FP8-Rechenleistung liefern—mehr als das 40-fache der Gesamtleistung der gesamten Top500-Supercomputer-Liste von vor nur fünf Jahren.¹⁹⁹ Das Engagement signalisiert Vertrauen in die TPU-Architektur für die Entwicklung von Frontier-Modellen in Größenordnungen, die zuvor als Science Fiction galten.
Anthropic verfolgt eine bewusste Multi-Plattform-Hardware-Strategie über Google's TPUs, Amazon's Trainium und NVIDIA GPUs.²⁰⁰ Die Diversifizierung bietet Kapazitätsversicherung, Preisverhandlungsspielraum und geografische Verteilung. Claude dient global von Deployments auf allen drei Plattformen, mit Request-Routing basierend auf Kapazitätsverfügbarkeit und regionalen Latenzanforderungen.
Das technische Postmortem des Unternehmens vom August 2025 offenbarte Deployment-Komplexitäten im großen Maßstab. Eine Fehlkonfiguration auf den Claude API TPU-Servern verursachte Token-Generierungsfehler, die gelegentlich unerwartet hohe Wahrscheinlichkeiten für Thai- oder chinesische Zeichen in englischen Prompts zuwiesen.²⁰¹ Der Vorfall demonstrierte, dass selbst einfache Fehler unvorhersagbar durch Systeme kaskadieren, die täglich Milliarden von Token verarbeiten.
Ein separates Deployment löste einen latenten Bug im XLA: TPU-Compiler aus, der Claude Haiku 3.5 betraf. Der Bug existierte monatelang unentdeckt, bis eine spezifische Kombination aus Modellarchitektur und Compiler-Flag den Defekt aufdeckte.²⁰² Die Entdeckung betont, dass Produktions-Deployment Grenzfälle findet, die in Entwicklungs- und Staging-Umgebungen fehlen.
Anthropic-Ingenieure nannten TPUs Preis-Leistung und Effizienz als primäre Auswahlkriterien. Die überzeugende Wirtschaftlichkeit beschleunigt die Entwicklung, indem sie größere Experimente innerhalb fixer Budgets ermöglicht.²⁰³ Training größerer Modelle, Erkunden von mehr Hyperparameter-Konfigurationen und schnelleres Iterieren resultieren alle aus reduzierten Kosten pro FLOP.
Google Gemini: Von Beginn an für TPU entwickelt
Google's Gemini-Modelle trainieren und dienen ausschließlich auf TPUs, mit Architektur und Trainingsverfahren, die von Anfang an für TPU-Charakteristika co-designed wurden.²⁰⁴ Die enge Kopplung ermöglicht die Nutzung TPU-spezifischer Optimierungen, die plattformübergreifende Modelle nicht nutzen können.
Gemini-Deployment nutzt berichten zufolge 50.000 TPU v6e-Chips für das Training und Serving der wichtigsten Modellvarianten.²⁰⁵ Die enormen Pod-Größen erfordern ausgeklügelte Orchestrierung—Job-Scheduling über Tausende von Chips, Checkpoint-Koordination zur Vermeidung von Engpässen, Failure-Recovery zur Minimierung verlorener Arbeit und Echtzeit-Monitoring zur Identifizierung degradierter Nodes bevor Ausfälle sich ausbreiten.
Google trainierte Gemini 2.0 auf Trillium TPUs und validierte damit die sechste Generation der Architektur für die Entwicklung von Frontier-Modellen.²⁰⁶ Der Trainingslauf demonstrierte Skalierungseffizienz zu beispiellosen Chip-Anzahlen und erreichte Strong Scaling jenseits typischer Plateaus, wo Communication Overhead dominiert.
Die Model-Serving-Infrastruktur nutzt spezifisch TPU-Inferenz-Optimierungen. Batch Processing aggregiert mehrere Nutzeranfragen zur Maximierung der MXU-Auslastung. Key-Value Cache Management nutzt HBM-Kapazität und ermöglicht langlebige Kontextverarbeitung ohne Disk-Swapping. Die Architektur liefert sub-sekündliche Antwortzeiten für komplexe Anfragen bei gleichzeitiger Bewältigung massiver globaler Request-Volumina.²⁰⁷
Produktions-Monitoring-Systeme überwachen kontinuierlich 50.000+ TPUs und erkennen Anomalien, die Modellqualität oder -verfügbarkeit beeinträchtigen könnten.²⁰⁸ Die Telemetrie erfasst Fehlerquoten, Latenz-Perzentile, Durchsatz, Memory-Pressure und thermische Charakteristika für jeden Chip. Machine Learning-Modelle analysieren die Telemetrie-Streams selbst, sagen Ausfälle vorher bevor sie auftreten und lösen präventive Wartung aus.
Weitere Produktions-Deployments
Midjourney migrierte von GPU- zu TPU-Infrastruktur und erreichte 65% Kosteneinsparung und 40% Latenz-Verbesserung für Bildgenerierungs-Workloads.²⁰⁹ Der Kunstgenerierungsdienst verarbeitet bei Spitzenlast 300.000 Bilder pro Minute und benötigt massiven Rechendurchsatz und konsistente Performance bei stoßweisen Verkehrsmustern.
Coheres Sprachmodelle auf TPU erreichten das 3-fache des Durchsatzes vorheriger GPU-Deployments.²¹⁰ Die Beschleunigung ermöglichte es, mehr Kunden mit derselben Infrastruktur-Footprint zu bedienen, was direkt die Geschäftsökonomie verbesserte. Das Unternehmen nutzte JAX's SPMD-Fähigkeiten zur effizienten Parallelisierung von Modellen über TPU-Pods.
Snap sicherte sich Kapazität für 10.000 TPU v6e-Chips zur Unterstützung von Augmented Reality-Features, Empfehlungssystemen und kreativen AI-Tools.²¹¹ Das Deployment erstreckt sich über mehrere geografische Regionen und gewährleistet niedrige Latenz für Snapchats globale Nutzerbasis bei gleichzeitiger Modellkonsistenz über Regionen hinweg.
Akademische Institutionen adoptieren zunehmend TPU für Forschung. Das TPU Research Cloud (TRC)-Programm bietet Forschern kostenlosen TPU-Zugang und ermöglicht Experimente in Größenordnungen, die zuvor nur gut finanzierten Unternehmenslabors zugänglich waren.²¹² Die Demokratisierung beschleunigt wissenschaftlichen Fortschritt durch Beseitigung von Hardware-Barrieren für Akademiker, die grundlegende Fragen zu AI-Fähigkeiten und -Grenzen untersuchen.
Debugging, Profiling und Performance-Optimierung
XProf und TensorBoard Integration
XProf bildet das primäre Profiling-Tool für TPU-Workloads und bietet Leistungsanalyse für JAX-, PyTorch/XLA- und TensorFlow-Programme über CPUs, GPUs und TPUs hinweg.²¹³ Das Tool integriert sich mit TensorBoard für die Visualisierung und präsentiert Profiling-Daten über vertraute Schnittstellen, die ML-Engineers bereits verstehen.
Die Installation erfordert das TensorBoard-Plugin: pip install tensorboard_plugin_profile tensorboard. Dies ermöglicht die vollständige Toolchain.²¹⁴ Das Ausführen von Profiling auf TPU VMs umfasst das Erfassen von Traces während Training oder Inferenz, das Hochladen der Ergebnisse zu TensorBoard und die Analyse der Visualisierung zur Identifizierung von Engpässen.
Die Overview Page bietet High-Level-Performance-Summary-Metriken, einschließlich Step-Time-Aufschlüsselung, Device-Utilization und Top-Level-Engpass-Identifizierung.²¹⁵ Die Seite hebt sofort hervor, ob Workloads compute-bound (MXU läuft kontinuierlich), memory-bound (wartet auf HBM-Transfers) oder communication-bound (blockiert bei collective operations) sind.
Trace Viewer und Timeline-Analyse
Der Trace Viewer zeigt detaillierte Timeline-Visualisierungen, die genau anzeigen, wann Operationen ausgeführt werden, wann Datentransfers auftreten und wo sich Idle-Zeit ansammelt.²¹⁶ Die Chrome-basierte Schnittstelle ermöglicht das Zoomen auf Mikrosekunden-Auflösung und enthüllt präzises Scheduling-Verhalten, das aggregierte Metriken verschleiern.
Das Verstehen des Trace erfordert das Erkennen häufiger Muster. Lange Lücken zwischen Operationen deuten auf Compilation-Overhead, Data-Loading-Engpässe oder Python-Overhead aufgrund schlecht optimierter Data-Pipelines hin. Wiederholte kleine Operationen lassen unzureichende Fusion vermuten. Collective Operations, die sich über Millisekunden erstrecken, weisen auf Kommunikationsineffizienzen oder schlechte Sharding-Strategien hin.²¹⁷
Farbcodierung unterscheidet Operationstypen: Grün für Compute, Blau für Memory-Transfers, Orange für Kommunikation und Rot für Idle-Zeit. Optimierte Workloads zeigen dicht gepackte farbige Blöcke mit minimalen roten Lücken. Schlecht optimierter Code weist spärliche Timelines mit langen roten Abschnitten auf, die verschwendete Ressourcen anzeigen.²¹⁸
Die erweiterte Nutzung umfasst die Korrelation von Timeline-Verhalten mit Quellcode. PyTorch/XLA unterstützt Benutzerannotationen, die in Code eingefügt werden und in Traces erscheinen, wodurch die Zuordnung von Performance-Verhalten zu spezifischen Modellkomponenten ermöglicht wird.²¹⁹ Die Annotationen verwandeln opake Traces in umsetzbare Erkenntnisse darüber, welche Layer oder Operationen Optimierungsfokus benötigen.
Memory Profile Tool und OOM-Debugging
Out-of-memory (OOM)-Fehler plagen die Entwicklung großer Modelle. Das Memory Profile Tool überwacht die Device-Memory-Nutzung während der Ausführung und erfasst Peak-Utilization und Allocation-Muster, die zu OOM-Fehlern führen.²²⁰
Das Tool visualisiert den Memory-Verbrauch über die Zeit und zeigt, welche Tensoren die meiste Kapazität verbrauchen und wann Peak-Usage auftritt. Die Visualisierung enthüllt oft überraschende Allokationen—Gradient-Buffer größer als erwartet, Activation-Memory, das checkpointen sollte, oder temporäre Tensoren, die XLA nicht eliminieren konnte.²²¹
Die Debugging-Strategie umfasst die iterative Reduzierung des Memory-Footprints durch mehrere Techniken. Gradient Checkpointing berechnet Aktivierungen während Backward Passes neu, anstatt sie zu speichern. Optimizer State Sharding verteilt Adam Momentum und Varianz über Devices. Mixed Precision reduziert Memory um 2× im Vergleich zu FP32. Microbatching verarbeitet kleinere Batches sequenziell anstatt eines großen Batches.²²²
Erweiterte Memory-Optimierung erfordert das Verstehen von Compiler-Entscheidungen. Das xla_dump_to Flag exportiert Intermediate Representations, die zeigen, wie XLA den Computation Graph transformiert hat. Die Analyse des IR enthüllt, ob Fusion erfolgreich war, wo unnötige Kopien auftreten und welche Operationen mehr Memory allokieren als erwartet.²²³
Input Pipeline Analyzer
CPU-Preprocessing erzeugt häufig Engpässe beim TPU-Training. Der Input Pipeline Analyzer identifiziert, ob Data Loading mit dem Accelerator-Verbrauch Schritt hält oder ob TPUs idle warten auf Batches.²²⁴
Das Tool trennt Host-seitige Analyse (CPU-Preprocessing, Data Augmentation, Batch Assembly) von Device-seitiger Ausführung (tatsächliche TPU-Computation). Input-bound Workloads zeigen Device Utilization, die während Data Loading sinkt, während CPU Utilization Spitzenwerte erreicht. Compute-bound Workloads halten hohe Device Utilization aufrecht, wobei die CPU komfortabel Schritt hält.²²⁵
Optimierungsstrategien hängen von der Engpass-Location ab. Langsames Host-Preprocessing profitiert von der Parallelisierung des Data Loading über mehr CPU-Cores, der Reduzierung der Per-Sample-Augmentation-Komplexität oder dem Prefetching von Batches vor dem Verbrauch. Device-seitige Engpässe erfordern Änderungen an der Modellarchitektur, bessere Fusion oder Sharding-Anpassungen anstatt Data Pipeline Tuning.²²⁶
Die Zukunft der Tensor Processing Units
Googles sieben Generationen umfassende Architekturentwicklung demonstriert kontinuierliche Innovation bei spezialisierten AI-Beschleunigern. Ironwoods FP8-Unterstützung, massive Speicherkapazität und 9.216-Chip-Superpod-Skalierung deuten auf Entwicklungsrichtungen für die Zukunft hin.²²⁷
Die Präzisionsreduktion wird wahrscheinlich in Richtung FP4 oder sogar niedriger für spezifische Operationen weitergehen. Aktuelle Forschung zeigt, dass viele neuronale Netzwerkoperationen extreme Quantisierung mit sorgfältigen Trainingsverfahren tolerieren. Zukünftige TPUs könnten Mixed-Precision-Systeme mit FP4-Forward-Passes, FP8-Backward-Passes und FP32-Optimizer-Updates implementieren.²²⁸
Die Speicherkapazität konkurriert mit dem Wachstum der Modellgröße. Aktuelle Frontier-Modelle strapazieren bereits den Accelerator-Speicher und erfordern ausgeklügelte Parallelismus-Strategien. TPUs der nächsten Generation könnten nichtflüchtige Speichertechnologien wie 3D XPoint oder resistive RAM integrieren, was terabyte-große On-Package-Speicher ohne den Stromverbrauch von DRAM ermöglicht.²²⁹
Optische Interconnects könnten über Circuit Switching hinaus auch optische Computing-Elemente umfassen. Die Forschung erkundet photonische Matrixmultiplikation, die mit Lichtgeschwindigkeit und minimaler Leistung ausgeführt wird und möglicherweise elektronische systolische Arrays mit optischen Co-Prozessoren für spezifische Operationen ergänzt.²³⁰
Die Sparsity-Unterstützung wird wahrscheinlich über Embeddings hinaus auf allgemeine sparse lineare Algebra ausgeweitet. Pruning-Techniken für neuronale Netzwerke zeigen, dass 90%+ der Gewichte auf null gesetzt werden können, ohne Qualitätsverlust. Zukünftige Architekturen könnten null-wertige Berechnungen nativ überspringen, anstatt sie explizit zu berechnen und zu verwerfen.²³¹
Die architektonischen Prinzipien, die dem TPU-Erfolg zugrunde liegen—Domänenspezialisierung, maßgeschneiderte Interconnects, co-designte Software-Stacks und gebäudeweite Orchestrierung—weisen auf eine Zukunft zunehmend spezialisierter Acceleratoren hin. Anstelle von Universal-Prozessoren könnten wir Acceleratoren sehen, die für Training versus Inferenz, Convolutional Networks versus Transformers, dense versus sparse Modelle und kurze versus lange Sequenzen optimiert sind.²³²
Ingenieure, die heute AI-Infrastruktur aufbauen, sollten die TPU-Architektur tiefgreifend verstehen. Ob bei der Bereitstellung auf Google Cloud, im Wettbewerb mit Google auf dem Accelerator-Markt oder beim Design von ML-Systemen der nächsten Generation—die Design-Prinzipien und Trade-offs, die in TPU verkörpert sind, offenbaren fundamentale Wahrheiten darüber, was AI-Workloads von Hardware verlangen. Die systolische Array-Mathematik, das Memory-Hierarchy-Design, die Interconnect-Topologie und Compiler-Optimierungsstrategien repräsentieren Jahrzehnte akkumulierter Weisheit, die weit über TPU selbst hinaus anwendbar ist.
Die Spannung zwischen Spezialisierung und Generalität, die TPU versus GPU definiert, wird dauerhaft bestehen bleiben. TPUs opfern Flexibilität für extreme Effizienz bei engen Workloads. GPUs opfern Spitzeneffizienz für breitere Anwendbarkeit. Kein Ansatz dominiert—die optimale Wahl hängt vollständig von Workload-Charakteristiken, Skalierung, Kostenbeschränkungen und operationellen Anforderungen ab. Organisationen, die erfolgreich AI im großen Maßstab einsetzen, verfolgen zunehmend heterogene Strategien und passen Accelerator-Architekturen an Workload-Anforderungen an, anstatt auf eine einzige Plattform zu standardisieren.
Anthropics Million-Chip-Commitment für TPU demonstriert, dass die Architektur Produktionsreife in höchsten Maßstäben erreicht hat. Die Multi-Gigawatt-Deployments, die 2026 online gehen, werden Modelle trainieren, die die Grenzen dessen verschieben, was AI erreichen kann, und die Infrastruktur, die diese Modelle ermöglicht, verkörpert engineering-technische Raffinesse, die wenige Organisationen erreicht haben. Zu verstehen, wie 65.536 Multiply-Accumulate-Units in einem systolischen Array zusammenarbeiten, um Frontier-Modelle zu trainieren, ist wichtig für jeden, dem die Zukunft der AI ernst ist.
Referenzen
-
Google Cloud Press Corner, "Anthropic to Expand Use of Google Cloud TPUs and Services," 23. Oktober 2025, https://www.googlecloudpresscorner.com/2025-10-23-Anthropic-to-Expand-Use-of-Google-Cloud-TPUs-and-Services.
-
TrendForce, "Google Unveils 7th-Gen TPU Ironwood with 9,216-Chip Superpod, Taking Aim at NVIDIA," 7. November 2025, https://www.trendforce.com/news/2025/11/07/news-google-unveils-7th-gen-tpu-ironwood-with-9216-chip-superpod-taking-aim-at-nvidia/.
-
Norman P. Jouppi et al., "TPU v4: An Optically Reconfigurable Supercomputer for Machine Learning with Hardware Support for Embeddings," in Proceedings of the 50th Annual International Symposium on Computer Architecture (2023), arXiv:2304.01433.
-
Anthropic, "Expanding our use of Google Cloud TPUs and Services," Anthropic News, Oktober 2025, https://www.anthropic.com/news/expanding-our-use-of-google-cloud-tpus-and-services.
-
Google Cloud Blog, "Quantifying the performance of the TPU, our first machine learning chip," April 2017, https://cloud.google.com/blog/products/gcp/quantifying-the-performance-of-the-tpu-our-first-machine-learning-chip.
-
Norman P. Jouppi et al., "In-Datacenter Performance Analysis of a Tensor Processing Unit," Proceedings of the 44th Annual International Symposium on Computer Architecture (2017), arXiv:1704.04760.
-
Jouppi et al., "In-Datacenter Performance Analysis."
-
Jouppi et al., "In-Datacenter Performance Analysis."
-
Jonathan Hui, "AI Chips: Google TPU," Medium, abgerufen Dezember 2025, https://jonathan-hui.medium.com/ai-chips-tpu-3fa0b2451a2d.
-
Wikipedia, "Bfloat16 floating-point format," abgerufen Dezember 2025, https://en.wikipedia.org/wiki/Bfloat16_floating-point_format.
-
Henry Ko, "TPU Deep Dive," persönlicher Blog, abgerufen Dezember 2025, https://henryhmko.github.io/posts/tpu/tpu.html.
-
Wikipedia, "Tensor Processing Unit," abgerufen Dezember 2025, https://en.wikipedia.org/wiki/Tensor_Processing_Unit.
-
Wikipedia, "Tensor Processing Unit."
-
Wikipedia, "Tensor Processing Unit."
-
Ko, "TPU Deep Dive."
-
Jouppi et al., "TPU v4: An Optically Reconfigurable Supercomputer."
-
Jouppi et al., "TPU v4: An Optically Reconfigurable Supercomputer."
-
Jouppi et al., "TPU v4: An Optically Reconfigurable Supercomputer."
-
Jouppi et al., "TPU v4: An Optically Reconfigurable Supercomputer."
-
OpenXLA Project, "A deep dive into SparseCore for Large Embedding Models (LEM)," abgerufen Dezember 2025, https://openxla.org/xla/sparsecore.
-
JAX Scaling Guide, "How to Think About TPUs," abgerufen Dezember 2025, https://jax-ml.github.io/scaling-book/tpus/.
-
JAX Scaling Guide, "How to Think About TPUs."
-
Ko, "TPU Deep Dive."
-
JAX Scaling Guide, "How to Think About TPUs."
-
Google Cloud Blog, "Introducing Trillium, sixth-generation TPUs," Mai 2024, https://cloud.google.com/blog/products/compute/introducing-trillium-6th-gen-tpus.
-
Google Cloud Blog, "Introducing Trillium."
-
Google Cloud Blog, "Introducing Trillium."
-
Google Cloud Blog, "Introducing Trillium."
-
Google Cloud Blog, "Introducing Trillium."
-
Google Blog, "Ironwood: The first Google TPU for the age of inference," November 2025, https://blog.google/products/google-cloud/ironwood-tpu-age-of-inference/.
-
XPU.pub, "Google Adds FP8 to Ironwood TPU; Can It Beat Blackwell?" 16. April 2025, https://xpu.pub/2025/04/16/google-ironwood/.
-
TrendForce, "Google Unveils 7th-Gen TPU Ironwood."
-
The Register, "Google's 7th-gen Ironwood TPUs promise 42 AI exaFLOPS pods," 10. April 2025, https://www.theregister.com/2025/04/10/googles_7thgen_ironwood_tpus_debut/.
-
TrendForce, "Google Unveils 7th-Gen TPU Ironwood."
-
Ko, "TPU Deep Dive."
-
XPU.pub, "Google Adds FP8 to Ironwood TPU."
-
Google Cloud Press Corner, "Anthropic to Expand Use."
-
Telesens, "Understanding Matrix Multiplication on a Weight-Stationary Systolic Architecture," 30. Juli 2018, https://telesens.co/2018/07/30/systolic-architectures/.
-
Telesens, "Understanding Matrix Multiplication."
-
Jouppi et al., "In-Datacenter Performance Analysis."
-
Telesens, "Understanding Matrix Multiplication."
-
CP Lu, "Should We All Embrace Systolic Arrays?" Medium, abgerufen Dezember 2025, https://cplu.medium.com/should-we-all-embrace-systolic-array-df3830f193dc.
-
Google Cloud Documentation, "TPU architecture," abgerufen Dezember 2025, https://docs.cloud.google.com/tpu/docs/system-architecture-tpu-vm.
-
Google Cloud Documentation, "TPU architecture."
-
Hui, "AI Chips: Google TPU."
-
Telnyx, "Architecture insights: MXU and TPU components," abgerufen Dezember 2025, https://telnyx.com/learn-ai/mxu-tpu.
-
Ko, "TPU Deep Dive."
-
Jouppi et al., "TPU v4: An Optically Reconfigurable Supercomputer."
-
SemiEngineering, "Tensor Processing Unit (TPU)," abgerufen Dezember 2025, https://semiengineering.com/knowledge_centers/integrated-circuit/ic-types/processors/tensor-processing-unit-tpu/.
-
TrendForce, "Google Unveils 7th-Gen TPU Ironwood."
-
SemiEngineering, "Tensor Processing Unit (TPU)."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Google Cloud Documentation, "Cloud TPU performance guide," abgerufen Dezember 2025, https://cloud.google.com/tpu/docs/performance-guide.
-
OpenXLA Project, "A deep dive into SparseCore."
-
OpenXLA Project, "A deep dive into SparseCore."
-
OpenXLA Project, "A deep dive into SparseCore."
-
Jouppi et al., "TPU v4: An Optically Reconfigurable Supercomputer."
-
OpenXLA Project, "A deep dive into SparseCore."
-
Jouppi et al., "TPU v4: An Optically Reconfigurable Supercomputer."
-
OpenXLA Project, "A deep dive into SparseCore."
-
JAX Scaling Guide, "How to Think About TPUs."
-
JAX Scaling Guide, "How to Think About TPUs."
-
JAX Scaling Guide, "How to Think About TPUs."
-
Ko, "TPU Deep Dive."
-
JAX Scaling Guide, "How to Think About TPUs."
-
JAX Scaling Guide, "How to Think About TPUs."
-
TrendForce, "Google Unveils 7th-Gen TPU Ironwood."
-
Ko, "TPU Deep Dive."
-
Anthropic, "Expanding our use of Google Cloud TPUs."
-
Jouppi et al., "TPU v4: An Optically Reconfigurable Supercomputer."
-
Jouppi et al., "TPU v4: An Optically Reconfigurable Supercomputer."
-
Jouppi et al., "TPU v4: An Optically Reconfigurable Supercomputer."
-
Jouppi et al., "TPU v4: An Optically Reconfigurable Supercomputer."
-
Ko, "TPU Deep Dive."
-
Jouppi et al., "TPU v4: An Optically Reconfigurable Supercomputer."
-
Leon Poutievski, "Mission Apollo: Landing Optical Circuit Switching at Datacenter Scale," LinkedIn, Juni 2022, https://www.linkedin.com/posts/leon-poutievski-8910a851_mission-apollo-landing-optical-circuit-switching-activity-6968472071534235649-cB4l.
-
Ko, "TPU Deep Dive."
-
Jouppi et al., "TPU v4: An Optically Reconfigurable Supercomputer."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Jouppi et al., "TPU v4: An Optically Reconfigurable Supercomputer."
-
JAX Scaling Guide, "How to Think About TPUs."
-
TrendForce, "Google Unveils 7th-Gen TPU Ironwood."
-
TrendForce, "Google Unveils 7th-Gen TPU Ironwood."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
OpenXLA Project, "XLA: Optimizing Compiler for Machine Learning," abgerufen Dezember 2025, https://openxla.org/xla.
-
Daniel Snider und Ruofan Liang, "Operator Fusion in XLA: Analysis and Evaluation," akademische Abhandlung, abgerufen Dezember 2025, https://danielsnider.ca/papers/Operator_Fusion_in_XLA_Analysis_and_Evaluation.pdf.
-
Snider und Liang, "Operator Fusion in XLA."
-
APXML, "Memory-Aware Data Layout Transformations (NCHW/NHWC)," abgerufen Dezember 2025, https://apxml.com/courses/compiler-runtime-optimization-ml/chapter-3-advanced-graph-level-optimizations/memory-aware-layout-transformations.
-
OpenXLA Project, "XLA."
-
PyTorch Documentation, "Pytorch/XLA Overview," abgerufen Dezember 2025, https://docs.pytorch.org/xla/master/learn/xla-overview.html.
-
OpenXLA Project, "A deep dive into SparseCore."
-
Mangpo Phothilimthana et al., "A Flexible Approach to Autotuning Multi-Pass Machine Learning Compilers," PACT 2021, abgerufen Dezember 2025, https://mangpo.net/papers/xla-autotuning-pact2021.pdf.
-
JAX Documentation, "Introduction to parallel programming," abgerufen Dezember 2025, https://docs.jax.dev/en/latest/sharded-computation.html.
-
GitHub, "jax-ml/jax: Composable transformations of Python+NumPy programs," abgerufen Dezember 2025, https://github.com/jax-ml/jax.
-
OpenXLA Project, "Shardy Guide for JAX Users," abgerufen Dezember 2025, https://openxla.org/shardy/getting_started_jax.
-
JAX Documentation, "Introduction to parallel programming."
-
OpenXLA Project, "Shardy Guide for JAX Users."
-
OpenXLA Project, "Shardy Guide for JAX Users."
-
JAX Documentation, "Introduction to parallel programming."
-
OpenXLA Project, "Shardy Guide for JAX Users."
-
PyTorch Documentation, "Pytorch/XLA Overview."
-
GitHub, "RFC: Evolving PyTorch/XLA for a more native experience on TPU," Issue #9684, abgerufen Dezember 2025, https://github.com/pytorch/xla/issues/9684.
-
Google Cloud Blog, "PyTorch/XLA 2.4 improves Pallas and adds 'eager mode,'" abgerufen Dezember 2025, https://cloud.google.com/blog/products/ai-machine-learning/pytorch-xla-2-4-improves-pallas-and-adds-eager-mode/.
-
PyTorch Documentation, "Pytorch/XLA Overview."
-
PyTorch Documentation, "Custom Kernels via Pallas," abgerufen Dezember 2025, https://docs.pytorch.org/xla/master/features/pallas.html.
-
PyTorch Documentation, "Custom Kernels via Pallas."
-
PyTorch Documentation, "Custom Kernels via Pallas."
-
vLLM Blog, "vLLM TPU: A New Unified Backend Supporting PyTorch and JAX on TPU," 16. Oktober 2025, https://blog.vllm.ai/2025/10/16/vllm-tpu.html.
-
GitHub, "pytorch/xla," abgerufen Dezember 2025, https://github.com/pytorch/xla.
-
StackGpu, "FP8, BF16, and INT8: How Low-Precision Formats Are Revolutionizing Deep Learning Throughput," Medium, abgerufen Dezember 2025, https://medium.com/@StackGpu/fp8-bf16-and-int8-how-low-precision-formats-are-revolutionizing-deep-learning-throughput-e6c1f3adabc2.
-
Wikipedia, "Bfloat16 floating-point format."
-
Wikipedia, "Bfloat16 floating-point format."
-
Paulius Micikevicius et al., "FP8 Formats for Deep Learning," arXiv:2209.05433, September 2022.
-
XPU.pub, "Google Adds FP8 to Ironwood TPU."
-
Micikevicius et al., "FP8 Formats for Deep Learning."
-
Google Cloud Blog, "Accurate Quantized Training (AQT) for TPU v5e," abgerufen Dezember 2025, https://cloud.google.com/blog/products/compute/accurate-quantized-training-aqt-for-tpu-v5e.
-
StackGpu, "FP8, BF16, and INT8."
-
Jeffrey Tse, "Understanding the FP64, FP32, FP16, BFLOAT16, TF32, FP8 Formats," persönlicher Blog, 9. Dezember 2024, https://jeffreytse.net/computer/2024/12/09/understanding-the-fp64-fp32-fp16-bfloat16-tf32-fp8-formats.html.
-
PyTorch Blog, "PyTorch/XLA SPMD: Scale Up Model Training and Serving with Automatic Parallelization," abgerufen Dezember 2025, https://pytorch.org/blog/pytorch-xla-spmd/.
-
OpenXLA Project, "Shardy Guide for JAX Users."
-
JAX Documentation, "Introduction to parallel programming."
-
OpenXLA Project, "Shardy Guide for JAX Users."
-
Ko, "TPU Deep Dive."
-
JAX Documentation, "Introduction to parallel programming."
-
Anthropic, "Expanding our use of Google Cloud TPUs."
-
JAX Documentation, "Introduction to parallel programming."
-
JAX Documentation, "Introduction to parallel programming."
-
Adam Roberts et al., "Scaling Up Models and Data with t5x and seqio," arXiv:2203.17189, März 2022.
-
Roberts et al., "Scaling Up Models and Data."
-
JAX Documentation, "Introduction to parallel programming."
-
JAX Documentation, "Introduction to parallel programming."
-
OpenXLA Project, "Shardy Guide for JAX Users."
-
Roberts et al., "Scaling Up Models and Data."
-
Roberts et al., "Scaling Up Models and Data."
-
Ko, "TPU Deep Dive."
-
MLCommons, "Benchmark MLPerf Training," abgerufen Dezember 2025, https://mlcommons.org/benchmarks/training/.
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
HPCwire, "MLPerf Training v5.0 Benchmark Results Reflect Rapid Growth in the Field of AI," Juni 2025, https://www.hpcwire.com/off-the-wire/mlperf-training-v5-0-benchmark-results-reflect-rapid-growth-in-the-field-of-ai/.
-
MLCommons, "MLCommons Releases New MLPerf Inference v5.0 Benchmark Results," April 2025, https://mlcommons.org/2025/04/mlperf-inference-v5-0-results/.
-
Ko, "TPU Deep Dive."
-
Google Cloud Blog, "TPU v4 enables performance, energy and CO2e efficiency gains," abgerufen Dezember 2025, https://cloud.google.com/blog/topics/systems/tpu-v4-enables-performance-energy-and-co2e-efficiency-gains.
-
TrendForce, "Google Unveils 7th-Gen TPU Ironwood."
-
Google Cloud Blog, "Quantifying the performance of the TPU."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Artech Digital, "Energy-Efficient GPU vs. TPU Allocation," abgerufen Dezember 2025, https://www.artech-digital.com/blog/energy-efficient-gpu-vs-tpu-allocation.
-
Wikipedia, "Tensor Processing Unit."
-
XPU.pub, "Google Adds FP8 to Ironwood TPU."
-
Ko, "TPU Deep Dive."
-
Google Cloud Blog, "TPU v4 enables performance, energy and CO2e efficiency gains."
-
ByteBridge, "GPU and TPU Comparative Analysis Report," Medium, abgerufen Dezember 2025, https://bytebridge.medium.com/gpu-and-tpu-comparative-analysis-report-a5268e4f0d2a.
-
ByteBridge, "GPU and TPU Comparative Analysis Report."
-
Anthropic, "Expanding our use of Google Cloud TPUs."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
DataCamp, "Understanding TPUs vs GPUs in AI: A Comprehensive Guide," abgerufen Dezember 2025, https://www.datacamp.com/blog/tpu-vs-gpu-ai.
-
Ko, "TPU Deep Dive."
-
DataCamp, "Understanding TPUs vs GPUs in AI."
-
Grigory Sapunov, "FP64, FP32, FP16, BFLOAT16, TF32, and other members of the ZOO," Medium, abgerufen Dezember 2025, https://moocaholic.medium.com/fp64-fp32-fp16-bfloat16-tf32-and-other-members-of-the-zoo-a1ca7897d407.
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Snider und Liang, "Operator Fusion in XLA."
-
APXML, "Memory-Aware Data Layout Transformations."
-
Google Cloud Blog, "How Lightricks trains video diffusion models at scale with JAX on TPU," abgerufen Dezember 2025, https://cloud.google.com/blog/products/media-entertainment/how-lightricks-trains-video-diffusion-models-at-scale-with-jax-on-tpu.
-
CloudOptimo, "TPU vs GPU: What's the Difference in 2025?" abgerufen Dezember 2025, https://www.cloudoptimo.com/blog/tpu-vs-gpu-what-is-the-difference-in-2025/.
-
Phoenix NAP, "TPU vs. GPU: Differences Explained," abgerufen Dezember 2025, https://phoenixnap.com/kb/tpu-vs-gpu.
-
CloudOptimo, "TPU vs GPU."
-
DataCamp, "Understanding TPUs vs GPUs in AI."
-
Tailscale, "TPU vs GPU: Which Is Better for AI Infrastructure in 2025?" abgerufen Dezember 2025, https://tailscale.com/learn/what-is-tpu-vs-gpu.
-
DataCamp, "Understanding TPUs vs GPUs in AI."
-
DataCamp, "Understanding TPUs vs GPUs in AI."
-
PyTorch Documentation, "Custom Kernels via Pallas."
-
Phoenix NAP, "TPU vs. GPU: Differences Explained."
-
Ko, "TPU Deep Dive."
-
OpenMetal, "TPU vs GPU: Pros and Cons," abgerufen Dezember 2025, https://openmetal.io/docs/product-guides/private-cloud/tpu-vs-gpu-pros-and-cons/.
-
OpenMetal, "TPU vs GPU: Pros and Cons."
-
Phoenix NAP, "TPU vs. GPU: Differences Explained."
-
PRIMO.ai, "Processing Units - CPU, GPU, APU, TPU, VPU, FPGA, QPU," abgerufen Dezember 2025, https://primo.ai/index.php?title=Processing_Units_-_CPU%2C_GPU%2C_APU%2C_TPU%2C_VPU%2C_FPGA%2C_QPU.
-
DataCamp, "Understanding TPUs vs GPUs in AI."
-
Google Cloud Documentation, "Profile your model on Cloud TPU VMs," abgerufen Dezember 2025, https://cloud.google.com/tpu/docs/cloud-tpu-tools.
-
DataCamp, "Understanding TPUs vs GPUs in AI."
-
Ko, "TPU Deep Dive."
-
GitHub, "RFC: Evolving PyTorch/XLA."
-
Google Cloud Press Corner, "Anthropic to Expand Use."
-
TrendForce, "Google Unveils 7th-Gen TPU Ironwood."
-
Maginative, "Anthropic Secures 1M Google TPUs While Keeping Amazon as Primary Training Partner," abgerufen Dezember 2025, https://www.maginative.com/article/anthropic-secures-1m-google-tpus-while-keeping-amazon-as-primary-training-partner/.
-
Anthropic, "A postmortem of three recent issues," Engineering Blog, August 2025, https://www.anthropic.com/engineering/a-postmortem-of-three-recent-issues.
-
Anthropic, "A postmortem of three recent issues."
-
AI Magazine, "Why Anthropic Uses Google Cloud TPUs for AI Infrastructure," abgerufen Dezember 2025, https://aimagazine.com/news/why-anthropic-uses-google-cloud-tpus-for-ai-infrastructure.
-
Google Cloud Blog, "Ironwood TPUs and new Axion-based VMs for your AI workloads," November 2025, https://cloud.google.com/blog/products/compute/ironwood-tpus-and-new-axion-based-vms-for-your-ai-workloads.
-
Ko, "TPU Deep Dive."
-
TrendForce, "Google Unveils 7th-Gen TPU Ironwood."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Google Cloud, "Tensor Processing Units (TPUs)," abgerufen Dezember 2025, https://cloud.google.com/tpu.
-
TensorFlow Documentation, "Optimize TensorFlow performance using the Profiler," abgerufen Dezember 2025, https://www.tensorflow.org/guide/profiler.
-
Google Cloud Documentation, "Profile your model on Cloud TPU VMs."
-
TensorFlow Documentation, "TensorFlow Profiler: Profile model performance," abgerufen Dezember 2025, https://www.tensorflow.org/tensorboard/tensorboard_profiling_keras.
-
Google Cloud Documentation, "Profile your model on Cloud TPU VMs."
-
Google Cloud Blog, "PyTorch/XLA: Performance debugging on Cloud TPU VM: Part III," abgerufen Dezember 2025, https://cloud.google.com/blog/topics/developers-practitioners/pytorchxla-performance-debugging-cloud-tpu-vm-part-iii.
-
Google Cloud Blog, "PyTorch/XLA: Performance debugging Part III."
-
Google Cloud Documentation, "Profile PyTorch XLA workloads," abgerufen Dezember 2025, https://docs.cloud.google.com/tpu/docs/pytorch-xla-performance-profiling-tpu-vm.
-
TensorFlow Documentation, "Optimize TensorFlow performance using the Profiler."
-
TensorFlow Documentation, "Optimize TensorFlow performance using the Profiler."
-
Ko, "TPU Deep Dive."
-
Google Cloud Documentation, "Cloud TPU performance guide."
-
TensorFlow Documentation, "Optimize TensorFlow performance using the Profiler."
-
TensorFlow Documentation, "Optimize TensorFlow performance using the Profiler."
-
TensorFlow Documentation, "Optimize TensorFlow performance using the Profiler."
-
TrendForce, "Google Unveils 7th-Gen TPU Ironwood."
-
Tse, "Understanding the FP64, FP32, FP16, BFLOAT16, TF32, FP8 Formats."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."


