
Les unités de traitement Tensor de Google alimentent la majorité des modèles d'IA de pointe avec lesquels vous interagissez quotidiennement, pourtant la plupart des ingénieurs restent étonnamment peu familiers avec leur architecture. Alors que les GPU NVIDIA dominent l'attention des développeurs, les TPU entraînent et servent discrètement Gemini 2.0, Claude, et des dizaines d'autres modèles de pointe à des échelles qui mettraient en faillite la plupart des organisations utilisant une infrastructure GPU conventionnelle. Anthropic s'est récemment engagé à déployer plus d'un million de puces TPU—représentant plus d'un gigawatt de capacité de calcul—pour entraîner les futurs modèles Claude.¹ La dernière génération Ironwood de Google délivre 42,5 exaflops de calcul FP8 à travers des superpods de 9 216 puces, une échelle qui redéfinit ce que signifie l'infrastructure AI de production.²
La sophistication technique derrière les TPU s'étend bien au-delà de simples métriques de performance. Ces processeurs incarnent une philosophie de conception fondamentalement différente des GPU, échangeant la flexibilité généraliste contre une spécialisation extrême dans la multiplication matricielle et les opérations tensorielles. Les ingénieurs qui comprennent l'architecture TPU peuvent exploiter des arrays systoliques 256×256 qui traitent 65 536 opérations de multiplication-accumulation par cycle, tirer parti des accélérateurs SparseCore de troisième génération pour les charges de travail intensives en embedding, et programmer des commutateurs de circuits optiques qui reconfigurent les topologies datacenter multi-petabit en moins de 10 nanosecondes.³ L'architecture s'étend de tout, des décisions de conception au niveau transistor à l'orchestration de superordinateurs à l'échelle du bâtiment.
Le contenu technique qui suit demande une attention particulière. Nous examinons sept générations d'évolution TPU, disséquons les mathématiques des arrays systoliques et les modèles de flux de données, explorons les hiérarchies mémoire des tuiles SRAM aux canaux HBM3e, analysons les optimisations du compilateur XLA au niveau de la représentation intermédiaire, et étudions pourquoi les opérations collectives s'exécutent 10× plus rapidement que les clusters GPU équivalents basés sur Ethernet.⁴ Vous rencontrerez des spécifications au niveau registre, la modélisation de performance cycle-précise, et les compromis architecturaux qui rendent les TPU simultanément plus puissants et plus contraints que les GPU. La profondeur ici sert les ingénieurs construisant la prochaine génération d'infrastructure AI et les chercheurs repoussant les limites de ce que les accélérateurs actuels peuvent accomplir.
L'Évolution : Sept Générations d'Innovation Architecturale
TPU v1 : Spécialisation Inférence Uniquement (2015)
Google a déployé la première Tensor Processing Unit en 2015 pour résoudre un problème critique : les charges de travail d'inférence de réseaux de neurones menaçaient de doubler l'empreinte datacenter de l'entreprise.⁵ Les ingénieurs ont conçu le TPU v1 exclusivement pour l'inférence, supprimant entièrement les capacités d'entraînement pour maximiser les performances et l'efficacité énergétique des modèles déployés. La puce comportait un réseau systolique 256×256 d'unités de multiplication-accumulation entières 8-bit, délivrant 92 téraops par seconde avec seulement 28-40 watts de puissance thermique nominale.⁶
L'architecture incarnait un minimalisme radical. Une seule Unité de Multiplication Matricielle traitait les opérations INT8 via un flux de données stationnaire en poids, où les poids restaient fixes dans le réseau systolique tandis que les activations circulaient horizontalement à travers la grille. Les sommes partielles se propagent verticalement, éliminant les écritures mémoire intermédiaires pour toute la multiplication matricielle. La puce, connectée aux systèmes hôtes via PCIe, s'appuyait sur la DRAM DDR3 pour la mémoire externe et fonctionnait à 700 MHz—délibérément conservateur pour l'efficacité énergétique.⁷
Les gains de performance ont étonné même les ingénieurs de Google. Le TPU v1 a atteint des améliorations de 30× à 80× en opérations par watt comparé aux CPU et GPU contemporains pour les charges de travail d'inférence en production.⁸ La puce gérait le classement Google Search, les services de traduction traitant 1 milliard de requêtes quotidiennes, et les recommandations YouTube pour 2 milliards d'utilisateurs. Le succès a validé une intuition architecturale fondamentale : les accélérateurs spécialisés optimisés pour des charges de travail étroites pouvaient délivrer des améliorations d'ordre de grandeur par rapport aux processeurs généralistes.
TPU v2 : Permettre l'Entraînement à Grande Échelle (2017)
La deuxième génération a transformé les TPU d'accélérateurs d'inférence uniquement en plateformes d'entraînement complètes. Google a reconçu toute l'architecture autour des opérations en virgule flottante, remplaçant le réseau INT8 256×256 par des multiplicateurs-accumulateurs bfloat16 128×128 doubles par cœur.⁹ Chaque puce contenait deux TensorCores partageant 8 GB de Mémoire Haute Bande Passante par cœur, une mise à niveau massive par rapport à la DDR3 qui fournissait la bande passante que demandait l'entraînement de réseaux de neurones.
La précision bfloat16 s'est révélée critique pour le succès du TPU v2. Le format maintient la même plage d'exposant 8-bit que FP32 tout en réduisant la mantisse à 7 bits, préservant la plage dynamique pour l'entraînement tout en divisant par deux les besoins de bande passante mémoire.¹⁰ Les ingénieurs ont observé que la précision réduite de mantisse améliorait en fait la généralisation dans de nombreux modèles en agissant comme une forme de régularisation, tandis que la plage complète d'exposant FP32 prévenait les problèmes de sous-dépassement et de dépassement qui affligeaient l'entraînement FP16.
L'innovation architecturale qui a vraiment différencié le TPU v2 était l'Interconnexion Inter-Puces (ICI). Les accélérateurs précédents nécessitaient Ethernet ou InfiniBand pour la communication multi-puces, introduisant des goulots d'étranglement de latence et de bande passante. Google a conçu des liens bidirectionnels haute vitesse personnalisés qui connectaient chaque TPU directement à quatre voisins dans une topologie tore 2D.¹¹ L'interconnexion a permis aux "pods" TPU v2 de jusqu'à 256 puces de fonctionner comme un seul accélérateur logique, avec des opérations collectives comme all-reduce s'exécutant bien plus rapidement que les alternatives basées réseau.
TPU v3 : Montée en Performance Refroidie à l'Eau (2018)
Google a poussé agressivement les fréquences d'horloge et le nombre de cœurs dans le TPU v3, délivrant 420 téraflops par puce—plus que doubler les performances du v2.¹² La densité de puissance accrue a forcé un changement architecturel dramatique : le refroidissement liquide. Chaque pod TPU v3 nécessitait une infrastructure de refroidissement à eau, un écart par rapport aux conceptions refroidies à l'air des générations précédentes et de la plupart des accélérateurs datacenter.¹³
La puce maintenait l'architecture MXU double 128×128 mais augmentait le nombre total de cœurs et améliorait la bande passante mémoire. Chaque TPU v3 contenait quatre puces avec deux cœurs chacune, partageant 32 GB de mémoire HBM au total entre les puces.¹⁴ Les unités de traitement vectoriel ont reçu des améliorations pour les fonctions d'activation, les opérations de normalisation, et les calculs de gradient qui créaient fréquemment des goulots d'étranglement d'entraînement sur les unités matricielles seules.
Les déploiements ont évolué vers des pods de 2 048 puces utilisant la même topologie tore 2D ICI que le v2 mais avec une bande passante par lien augmentée. Google a entraîné des modèles de plus en plus larges sur des pods v3, découvrant que le diamètre réseau réduit de la topologie tore (distance maximale entre deux puces quelconques évolue comme N/2 plutôt que N) minimisait les frais généraux de communication pour les stratégies d'entraînement parallèle en données et parallèle en modèle.¹⁵
TPU v4 : Percée de Commutation de Circuit Optique (2021)
La quatrième génération représentait le bond architectural le plus significatif de Google depuis le TPU original. Les ingénieurs ont augmenté l'échelle des pods à 4 096 puces tout en introduisant la commutation de circuit optique (OCS) pour l'interconnexion, une technologie empruntée aux télécommunications qui a révolutionné l'infrastructure ML à l'échelle datacenter.¹⁶
L'architecture de cœur du TPU v4 comportait quatre MXU 128×128 par TensorCore aux côtés d'unités vectorielles et scalaires améliorées. Chaque paire TensorCore partageait 128 MB de Mémoire Commune en plus de la Mémoire Vectorielle par cœur, permettant des motifs de mise en scène et de réutilisation de données plus sophistiqués.¹⁷ La topologie de puce a évolué du tore 2D au 3D, connectant chaque TPU à six voisins plutôt qu'à quatre, réduisant davantage le diamètre réseau et améliorant la bande passante de bisection.
Le système de commutation de circuit optique a tout changé aux déploiements à grande échelle. Plutôt qu'un câblage fixe entre TPU, Google a déployé des commutateurs optiques programmables qui pouvaient reconfigurer dynamiquement quelles puces se connectaient à quelles. Les miroirs MEMS (systèmes microélectromécaniques) redirigent physiquement les faisceaux lumineux pour relier ensemble des paires de TPU arbitraires, introduisant essentiellement zéro latence au-delà du temps de transmission fibre optique.¹⁸ Les commutateurs se reconfigurent en fenêtres sub-10-nanosecondes, plus rapides que la plupart des poignées de main de protocole réseau.
L'architecture OCS a permis des capacités précédemment impossibles. Google pouvait provisionner des "tranches" de toute taille, de quatre puces au pod complet de 4 096 puces, en programmant les commutateurs optiques de manière appropriée. Les puces défaillantes pouvaient être contournées de façon transparente sans faire tomber des racks entiers. Plus remarquablement, des TPU physiquement distants dans différents emplacements datacenter pouvaient être logiquement adjacents dans la topologie réseau, découplant entièrement la disposition physique et logique.¹⁹
Le TPU v4 a aussi introduit SparseCore, un processeur spécialisé pour gérer les opérations d'embedding utilisées quotidiennement dans les systèmes de recommandation, les modèles de classement, et les grands modèles de langage avec des embeddings de vocabulaire massifs. Le SparseCore comportait quatre processeurs dédiés par puce, chacun avec 2,5 MB de mémoire scratch et un flux de données optimisé pour les motifs d'accès mémoire éparses.²⁰ Les modèles avec des embeddings ultra-larges ont atteint des accélérations de 5-7× en utilisant seulement 5% de la surface de die totale de puce et du budget énergétique.
TPU v5p et v5e : Spécialisation et Échelle (2022-2023)
Google a divisé la cinquième génération en deux produits distincts ciblant différents cas d'usage. Le TPU v5p priorisait les performances maximales pour l'entraînement à grande échelle, tandis que le v5e optimisait pour l'inférence rentable et les travaux d'entraînement plus petits.²¹
Le TPU v5p a atteint approximativement 4,45 exaflops par seconde à travers des pods de 8 960 puces, plus que doubler la taille maximale de pod du v4.²² La bande passante d'interconnexion a atteint 4 800 Gbps par puce, et la topologie tore 3D connectait les puces dans des superpods massifs 16×20×28. Le tissu de commutation de circuit optique gérait 13 824 ports optiques à travers 48 unités OCS pour câbler un superpod v5p complet, représentant l'un des plus grands déploiements de commutation optique de production dans l'histoire de l'informatique.²³
Le TPU v5e a pris une approche différente, réduisant le nombre de cœurs et la fréquence d'horloge pour atteindre des cibles agressives de puissance et de coût. Les puces optimisées pour l'inférence ne contenaient qu'un seul cœur TPU par puce plutôt que deux, et sont revenues à la topologie tore 2D, qui était suffisante pour les tailles de pods plus petites.²⁴ La simplification architecturale a permis à Google de tarifer le v5e de façon compétitive pour les charges de travail où la performance absolue importait moins que la performance par dollar.
TPU v6e Trillium : Quadrupler les Performances Matricielles (2024)
Trillium a marqué un autre point d'inflexion architectural en étendant l'Unité de Multiplication Matricielle de 128×128 à 256×256 multiplicateurs-accumulateurs.²⁵ Le réseau plus large a quadruplé les FLOPS par cycle à la même fréquence d'horloge, délivrant 4,7× la performance de calcul de pointe du TPU v5e grâce à une combinaison du MXU étendu et des fréquences d'horloge accrues.
Le sous-système mémoire a reçu des mises à niveau également dramatiques. La capacité HBM a doublé à 32 GB par puce, avec la bande passante doublée par les canaux HBM de nouvelle génération.²⁶ La bande passante d'Interconnexion Interpuces a similairement doublé, permettant aux pods de 256 puces Trillium de maintenir un débit plus élevé pour les modèles qui sollicitaient à la fois le calcul et la communication.²⁷
Trillium comportait l'accélérateur SparseCore de troisième génération, avec des capacités améliorées pour les embeddings ultra-larges dans les charges de travail de classement et de recommandation. La conception mise à jour améliorait les motifs d'accès mémoire et augmentait la bande passante adéquate entre SparseCores et HBM pour les modèles dominés par les recherches d'embedding plutôt que les multiplications matricielles.²⁸
L'efficacité énergétique s'est améliorée de 67% par rapport au v5e malgré des gains de performance substantiels.²⁹ Google a atteint les gains d'efficacité grâce à des nœuds de processus avancés, des optimisations architecturales qui réduisaient le travail gaspillé, et une mise en veille soigneuse des unités inutilisées pendant les opérations qui ne sollicitaient pas simultanément toutes les parties de la puce.
TPU v7 Ironwood : L'Ère FP8 (2025)
Le TPU de septième génération de Google, nom de code Ironwood, représente le premier TPU conçu avec support FP8 natif et optimisé spécifiquement pour "l'âge de l'inférence" tout en maintenant des performances d'entraînement de pointe.³⁰ Chaque puce Ironwood délivre 4,6 pétaFLOPS de calcul FP8 dense—dépassant légèrement le B200 concurrent de NVIDIA à 4,5 pétaFLOPS—tout en tirant 600W de puissance thermique nominale.³¹
Le système mémoire s'est étendu à 192 GB de mémoire HBM3e par puce, six fois la capacité de Trillium, avec une bande passante atteignant 7,4 TB/s.³² L'augmentation mémoire dramatique permet de servir des modèles ultra-larges avec des caches clé-valeur qui nécessitaient précédemment un parallélisme tensoriel complexe à travers plusieurs accélérateurs. Google a spécifiquement conçu la capacité mémoire pour supporter les modèles multi-modaux émergents et les applications de contexte long approchant des fenêtres d'un million de tokens.
L'interconnexion d'Ironwood fournit 9,6 Tbps de bande passante bidirectionnelle agrégée à travers quatre liens ICI, se traduisant par 1,2 TB/s de bande passante de pointe par puce.³³ L'architecture évolue de pods de 256 puces pour les déploiements plus petits à des superpods massifs de 9 216 puces délivrant 42,5 FP8 exaflops de puissance de calcul.³⁴ La technologie de réseau datacenter Jupiter de Google pourrait théoriquement supporter jusqu'à 43 superpods Ironwood dans un seul cluster—approximativement 400 000 accélérateurs représentant une échelle de calcul presque incompréhensible.³⁵
Le support FP8 représente un changement fondamental dans la stratégie de précision. Les générations TPU précédentes émulaient les opérations 8-bit utilisant des techniques logicielles, ce qui introduisait des frais généraux. Ironwood implémente des unités de multiplication-accumulation FP8 natives supportant les formats E4M3 (exposant 4-bit, mantisse 3-bit) et E5M2 (exposant 5-bit, mantisse 2-bit).³⁶ Le support de format double permet de mélanger E4M3 pour les passes avant où la précision importe moins et E5M2 pour les passes arrière où maintenir les magnitudes de gradient prévient l'instabilité d'entraînement.
L'engagement d'Anthropic à déployer plus d'un million de puces Ironwood à partir de 2026 démontre la préparation production de l'architecture. L'entreprise prévoit d'exploiter bien plus d'un gigawatt de capacité TPU—suffisant pour alimenter une petite ville—exclusivement pour l'entraînement et le service des modèles Claude.³⁷ L'échelle éclipse même les plus importants déploiements GPU connus et représente un pari fondamental sur l'architecture TPU pour le développement de modèles frontière.
Référence Rapide Génération Actuelle
Les tableaux suivants fournissent des spécifications scannables pour les trois TPU de génération actuelle les plus pertinents pour les déploiements en production en 2025 :
Tableau 1 : Spécifications de Calcul de Cœur
[caption id="" align="alignnone" width="1386"] SpécificationTPU v5eTPU v5pTPU v6e (Trillium)TPU v7 (Ironwood) Taille Réseau MXU 128×128 128×128 256×256 256×256 MACs par Cycle 16,384 16,384 65,536 65,536 TFLOPS BF16 de Pointe ~197 ~459 ~918 ~2,300 (est.) PFLOPS FP8 de Pointe N/A (émulé) N/A (émulé) N/A (émulé) 4.6 Précision Native BF16, INT8 BF16, INT8 BF16, INT8 BF16, FP8, INT8 TensorCores/Puce 1 2 1 1 [/caption]
SpécificationTPU v5eTPU v5pTPU v6e (Trillium)TPU v7 (Ironwood) Taille Réseau MXU 128×128 128×128 256×256 256×256 MACs par Cycle 16,384 16,384 65,536 65,536 TFLOPS BF16 de Pointe ~197 ~459 ~918 ~2,300 (est.) PFLOPS FP8 de Pointe N/A (émulé) N/A (émulé) N/A (émulé) 4.6 Précision Native BF16, INT8 BF16, INT8 BF16, INT8 BF16, FP8, INT8 TensorCores/Puce 1 2 1 1 [/caption]
Tableau 2 : Mémoire et Bande Passante
[caption id="" align="alignnone" width="1380"]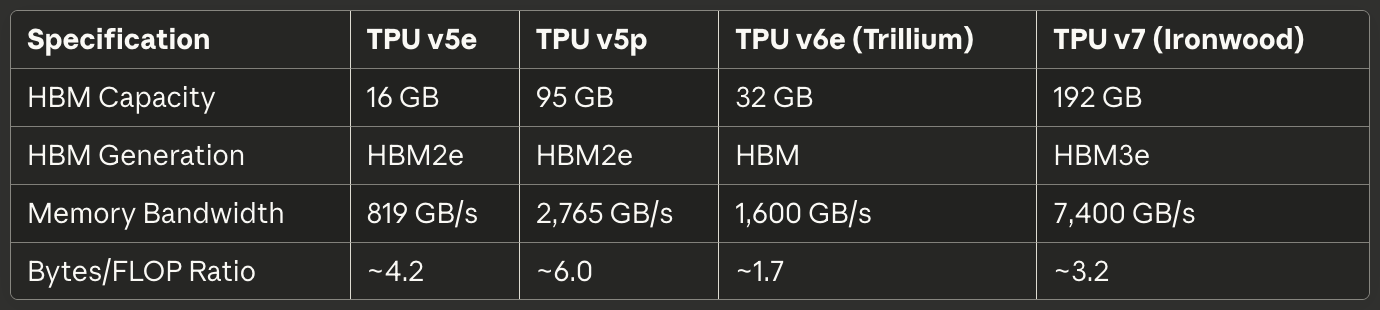 SpécificationTPU v5eTPU v5pTPU v6e (Trillium)TPU v7 (Ironwood) Capacité HBM 16 GB 95 GB 32 GB 192 GB Génération HBM HBM2e HBM2e HBM HBM3e Bande Passante Mémoire 819 GB/s 2,765 GB/s 1,600 GB/s 7,400 GB/s Ratio Octets/FLOP ~4.2 ~6.0 ~1.7 ~3.2 [/caption]
SpécificationTPU v5eTPU v5pTPU v6e (Trillium)TPU v7 (Ironwood) Capacité HBM 16 GB 95 GB 32 GB 192 GB Génération HBM HBM2e HBM2e HBM HBM3e Bande Passante Mémoire 819 GB/s 2,765 GB/s 1,600 GB/s 7,400 GB/s Ratio Octets/FLOP ~4.2 ~6.0 ~1.7 ~3.2 [/caption]
Tableau 3 : Interconnexion et Montée en Charge
[caption id="" align="alignnone" width="1384"]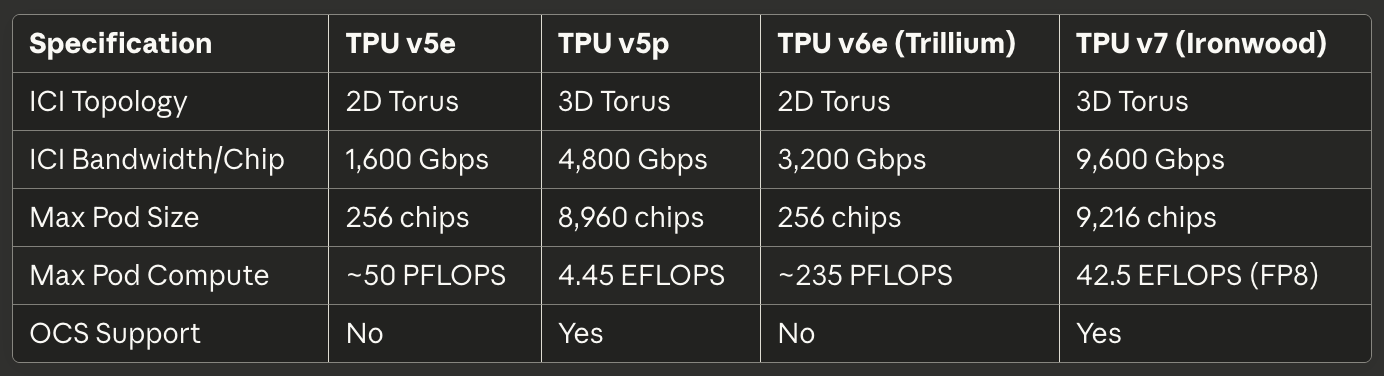 SpécificationTPU v5eTPU v5pTPU v6e (Trillium)TPU v7 (Ironwood) Topologie ICI Tore 2D Tore 3D Tore 2D Tore 3D Bande Passante ICI/Puce 1,600 Gbps 4,800 Gbps 3,200 Gbps 9,600 Gbps Taille Pod Max 256 puces 8,960 puces 256 puces 9,216 puces Calcul Pod Max ~50 PFLOPS 4.45 EFLOPS ~235 PFLOPS 42.5 EFLOPS (FP8) Support OCS Non Oui Non Oui [/caption]
SpécificationTPU v5eTPU v5pTPU v6e (Trillium)TPU v7 (Ironwood) Topologie ICI Tore 2D Tore 3D Tore 2D Tore 3D Bande Passante ICI/Puce 1,600 Gbps 4,800 Gbps 3,200 Gbps 9,600 Gbps Taille Pod Max 256 puces 8,960 puces 256 puces 9,216 puces Calcul Pod Max ~50 PFLOPS 4.45 EFLOPS ~235 PFLOPS 42.5 EFLOPS (FP8) Support OCS Non Oui Non Oui [/caption]
Tableau 4 : Puissance et Efficacité
[caption id="" align="alignnone" width="1380"] SpécificationTPU v5eTPU v5pTPU v6e (Trillium)TPU v7 (Ironwood) TDP ~120-200W ~250-300W ~120-200W 600W Refroidissement Air Liquide Air Liquide TFLOPS/Watt (BF16) ~1.0-1.6 ~1.5-1.8 ~4.6-7.7 ~3.8 Énergie vs Gen Précédente Baseline N/A 67% mieux que v5e 2× mieux que Trillium [/caption]
SpécificationTPU v5eTPU v5pTPU v6e (Trillium)TPU v7 (Ironwood) TDP ~120-200W ~250-300W ~120-200W 600W Refroidissement Air Liquide Air Liquide TFLOPS/Watt (BF16) ~1.0-1.6 ~1.5-1.8 ~4.6-7.7 ~3.8 Énergie vs Gen Précédente Baseline N/A 67% mieux que v5e 2× mieux que Trillium [/caption]
Tableau 5 : Cas d'Usage Recommandés
[caption id="" align="alignnone" width="1382"] Cas d'Usage Meilleur Choix Justification Inférence optimisée coût TPU v5e : Coût le plus bas par requête d'inférence Entraînement à grande échelle (>1000 puces) TPU v5p ou Ironwood Tore 3D + OCS permet pods massifs Travaux d'entraînement moyens (256 puces) TPU v6e Trillium Meilleur perf/watt, 4.7× calcul vs v5e Modèles limités mémoire (>70B params), Ironwood HBM 192GB permet tailles batch plus grandes Inférence contexte long (>100K tokens) Ironwood Capacité HBM supporte caches KV massifs Charges embedding-intensives TPU v5p ou Ironwood SparseCore + HBM large [/caption]
Cas d'Usage Meilleur Choix Justification Inférence optimisée coût TPU v5e : Coût le plus bas par requête d'inférence Entraînement à grande échelle (>1000 puces) TPU v5p ou Ironwood Tore 3D + OCS permet pods massifs Travaux d'entraînement moyens (256 puces) TPU v6e Trillium Meilleur perf/watt, 4.7× calcul vs v5e Modèles limités mémoire (>70B params), Ironwood HBM 192GB permet tailles batch plus grandes Inférence contexte long (>100K tokens) Ironwood Capacité HBM supporte caches KV massifs Charges embedding-intensives TPU v5p ou Ironwood SparseCore + HBM large [/caption]
Architecture Matérielle : À l'Intérieur du Silicium
Mathématiques et Flux de Données des Réseaux Systoliques
L'Unité de Multiplication Matricielle forme le cœur de l'architecture TPU, et comprendre les réseaux systoliques nécessite de saisir leur approche fondamentalement différente du parallélisme comparé aux voies SIMD GPU. Un réseau systolique chaîne les unités de multiplication-accumulation dans une grille où les données circulent rythmiquement à travers la structure—d'où "systolique", évoquant le pompage rythmique du sang à travers le cœur.³⁸
Considérons le réseau systolique 256×256 du TPU v6e exécutant la multiplication matricielle C = A × B. Les ingénieurs préchargent les poids de la matrice B dans les 65 536 unités individuelles de multiplication-accumulation arrangées dans une grille. Les valeurs d'activation de la matrice A entrent depuis le bord gauche et circulent horizontalement à travers le réseau. Chaque unité MAC multiplie son poids stocké par l'activation entrante, ajoute le résultat à une somme partielle arrivant d'en haut, et passe à la fois l'activation (horizontalement) et la somme partielle mise à jour (verticalement) aux unités voisines.³⁹
Le motif de flux de données signifie que chaque valeur d'activation est réutilisée 256 fois en traversant la dimension horizontale, et chaque somme partielle accumule des contributions de 256 multiplications en coulant verticalement. Crucialement, tous les résultats intermédiaires passent directement entre unités MAC adjacentes via de courts fils plutôt que d'aller-retour vers la mémoire. L'architecture exécute 65 536 opérations de multiplication-accumulation à chaque cycle d'horloge, et pendant toute la multiplication matricielle impliquant potentiellement des millions d'opérations, zéro valeurs intermédiaires touchent la DRAM ou même la SRAM sur puce.⁴⁰
Le motif de flux de données stationnaire en poids optimise pour le cas le plus commun dans l'inférence et l'entraînement de réseaux de neurones : multiplier répétitivement de nombreuses matrices d'activation différentes par la même matrice de poids. Les ingénieurs chargent les poids une fois, puis font circuler des lots d'activation illimités à travers le réseau sans rechargement. Le motif fonctionne exceptionnellement bien pour les couches convolutionnelles, les couches entièrement connectées, et les opérations Q·K^T et attention·V qui dominent les modèles transformer.⁴¹
L'efficacité énergétique provient de la réutilisation de données et de la localité spatiale. Lire une valeur de la DRAM consomme approximativement 200× plus d'énergie qu'une seule opération de multiplication-accumulation.⁴² En réutilisant chaque poids 256 fois et chaque activation 256 fois sans accès mémoire, le réseau systolique atteint des ratios opérations-par-watt impossibles pour les architectures qui navettent des données entre unités de calcul et hiérarchies mémoire.
La faiblesse du réseau systolique émerge avec les motifs de calcul dynamiques ou irréguliers. Parce que les données circulent à travers la grille selon un planning fixe, l'architecture peine avec l'exécution conditionnelle, les matrices éparses (sauf en utilisant SparseCore), et les opérations qui nécessitent des motifs d'accès aléatoires. L'inflexibilité échange la généralité pour une efficacité extrême sur sa charge de travail cible : la multiplication matricielle dense avec des motifs d'accès prévisibles.
Architecture Interne TensorCore
Chaque puce TPU contient un ou plusieurs TensorCores—l'unité de traitement complète comprenant l'Unité de Multiplication Matricielle, l'Unité de Traitement Vectoriel, et l'Unité Scalaire travaillant de concert.⁴³ Le TensorCore représente le bloc de construction fondamental que cible le logiciel, et comprendre l'interaction entre ses trois composants explique à la fois les caractéristiques de performance TPU et les motifs de programmation.
L'Unité de Multiplication Matricielle exécute 16 000 opérations de multiplication-accumulation par cycle sur des entrées bfloat16 ou FP8 avec accumulation FP32.⁴⁴ L'approche de précision mixte préserve l'exactitude numérique dans l'accumulateur tout en réduisant la bande passante mémoire pour les entrées. Les ingénieurs ont observé que maintenir une précision FP32 complète pendant l'accumulation prévient les erreurs de cancellation catastrophique lors de la somme de centaines ou milliers de produits intermédiaires, tandis que les entrées à précision réduite affectent rarement la qualité finale du modèle.
L'Unité de Traitement Vectoriel gère les opérations mal adaptées à la structure rigide du MXU. Les fonctions d'activation (ReLU, GELU, SiLU), les couches de normalisation (batch norm, layer norm), softmax, pooling, dropout, et les opérations élément par élément s'exécutent sur l'architecture SIMD 128 voies du VPU.⁴⁵ Le VPU opère sur les types de données FP32 et INT32, fournissant la précision requise pour les opérations numériquement sensibles comme softmax, où les exponentielles et divisions peuvent créer de larges plages dynamiques.
L'Unité Scalaire orchestre tout le TensorCore. Le processeur à fil unique exécute le flux de contrôle, calcule les adresses mémoire pour les motifs d'indexation complexes, et initie les transferts DMA de la Mémoire Haute Bande Passante vers la Mémoire Vectorielle.⁴⁶ Parce que l'unité scalaire fonctionne à fil unique, chaque TensorCore ne peut créer qu'une seule requête DMA par cycle—un goulot d'étranglement pour les opérations intensives en mémoire qui ne saturent pas le débit de calcul MXU ou VPU.
La hiérarchie mémoire alimentant le TensorCore détermine la performance réalisable autant que la capacité de calcul brute. La Mémoire Vectorielle (VMEM) agit comme une SRAM scratch gérée par logiciel exclusive à chaque TensorCore, typiquement dimensionnée à des dizaines de mégaoctets. Le compilateur XLA programme explicitement le mouvement de données entre HBM et VMEM, décidant quoi mettre en scène dans la mémoire locale rapide et quand réécrire les résultats.⁴⁷
La Mémoire Commune (CMEM), présente dans les générations TPU v4 et ultérieures, fournit un pool partagé plus large accessible à tous les TensorCores sur une puce. L'architecture TPU v4 allouait 128 MB de CMEM partagée entre deux TensorCores, permettant des motifs producteur-consommateur plus sophistiqués dans lesquels les sorties d'un cœur alimentent les entrées d'un autre cœur sans aller-retour vers HBM.⁴⁸
Les implications du modèle de programmation importent énormément. Parce que l'unité scalaire à fil unique et la mémoire vectorielle nécessitent une gestion explicite, la programmation TPU ressemble au développement de systèmes embarqués des années 1990 plus qu'à la programmation GPU moderne. CUDA abstrait le mouvement mémoire avec la mémoire unifiée et les caches gérés matériellement ; le code TPU (qu'il soit généré par XLA ou écrit manuellement en Pallas) doit explicitement orchestrer chaque transfert de données. Le contrôle manuel permet l'optimisation experte mais élève la barre pour une performance compétente.
Architecture Mémoire Haute Bande Passante
Les TPU modernes utilisent HBM (Mémoire Haute Bande Passante), ou HBM3e, une technologie mémoire radicalement différente de la SDRAM DDR trouvée dans les CPU, et la GDDR utilisée dans de nombreux GPU. HBM empile plusieurs dies DRAM verticalement utilisant des vias traversant le silicium (TSVs), puis place la pile directement adjacente au die processeur sur un interposeur silicium.⁴⁹ Le chemin électrique court et l'interface large permettent une bande passante dramatiquement plus élevée que les technologies mémoire conventionnelles.
Le TPU v7 Ironwood implémente 192 GB de HBM3e avec une bande passante totale de 7,4 TB/s.⁵⁰ Le système mémoire est divisé en multiples canaux, chacun fournissant un accès indépendant à une portion séparée de la capacité totale. Le compilateur XLA et le runtime doivent soigneusement partitionner les tenseurs à travers les canaux HBM pour maximiser l'accès parallèle et éviter les points chauds où un canal sature tandis que d'autres restent inactifs.
La largeur d'interface mémoire éclipse la DRAM conventionnelle. Où un canal DDR5 pourrait fournir 64 bits de largeur, un canal HBM s'étend typiquement sur 1 024 bits.⁵¹ La largeur extrême permet une haute bande passante à des fréquences d'horloge relativement modestes, réduisant la consommation électrique et les défis d'intégrité de signal comparé à pousser des interfaces étroites à des fréquences multi-gigahertz.
Les caractéristiques de latence diffèrent substantiellement des systèmes mémoire GPU. Les TPU manquent de caches gérés matériellement au-delà de petits tampons locaux, donc l'architecture s'appuie sur le logiciel mettant explicitement en scène les données dans VMEM bien avant que les unités de calcul en aient besoin. L'absence de caches signifie que la latence mémoire impacte directement les performances sauf si le compilateur cache avec succès la latence via la prélecture et le double tampon.⁵²
Les limites de capacité mémoire dominent de nombreuses charges de travail plus que le débit de calcul. Un modèle de 175 milliards de paramètres avec des poids bfloat16 nécessite 350 GB pour stocker les paramètres—dépassant déjà les 192 GB HBM d'Ironwood même avant de compter les activations, états d'optimiseur, ou tampons de gradient. Entraîner de tels modèles demande des techniques sophistiquées comme le checkpointing de gradient, le sharding d'état d'optimiseur à travers plusieurs puces, et la programmation soigneuse des mises à jour de paramètres pour minimiser l'empreinte mémoire.⁵³
Le runtime TPU impose des exigences spécifiques de disposition de tenseur pour maximiser l'efficacité MXU. Parce que le réseau systolique traite les données en tuiles 128×8, les tenseurs devraient s'aligner sur ces dimensions pour éviter le gaspillage de padding.⁵⁴ Les matrices mal dimensionnées forcent le matériel à traiter des tuiles partielles avec des MACs inactifs, réduisant directement l'utilisation FLOPS. Le compilateur tente de padder et reshaper les tenseurs automatiquement, mais des choix conscients de disposition dans l'architecture de modèle peuvent substantiellement améliorer les performances.
SparseCore : Accélération d'Embedding Spécialisée
Tandis que l'Unité de Multiplication Matricielle excelle aux opérations matricielles denses, les charges de travail intensives en embedding présentent des caractéristiques radicalement différentes. Les modèles de recommandation, systèmes de classement, et grands modèles de langage accèdent fréquemment à des tables d'embedding massives (souvent des centaines de gigaoctets) via des indices irréguliers, dépendants des données. Le flux de données structuré du MXU ne fournit aucun avantage pour ces motifs d'accès mémoire éparses, motivant l'architecture spécialisée de SparseCore.⁵⁵
SparseCore implémente un processeur de flux de données tuilé fondamentalement différent du réseau systolique du MXU. Le TPU v4 comportait quatre SparseCores par puce, chacun contenant 16 tuiles de calcul.⁵⁶ Chaque tuile opère comme une unité de flux de données indépendante avec mémoire scratch locale (SPMEM) et éléments de traitement. Les tuiles s'exécutent en parallèle, traitant simultanément des sous-ensembles disjoints d'opérations d'embedding.
La hiérarchie mémoire place les données chaudes dans la petite SPMEM rapide tout en gardant les tables d'embedding complètes en HBM. Le compilateur XLA analyse les motifs d'accès d'embedding pour déterminer quels vecteurs d'embedding méritent la mise en cache dans SPMEM versus la récupération à la demande depuis HBM.⁵⁷ La stratégie ressemble aux hiérarchies de cache CPU traditionnelles, mais avec le logiciel plutôt que le matériel prenant les décisions de placement.
Les SparseCores se connectent directement aux canaux HBM, contournant entièrement le chemin mémoire du TensorCore. La connexion dédiée empêche les opérations d'embedding de concurrencer les opérations matricielles denses pour la bande passante mémoire, permettant aux deux de procéder en parallèle.⁵⁸ Le partitionnement fonctionne exceptionnellement bien pour les modèles comme les Modèles de Recommandation d'Apprentissage Profond (DLRMs) qui entrelacent des couches de réseaux de neurones denses avec de larges recherches d'embedding.
La stratégie de sharding modulo distribue les embeddings à travers les SparseCores en calculant target_sc_id = col_id % num_total_sparse_cores.⁵⁹ La fonction de sharding simple assure l'équilibrage de charge quand les IDs d'embedding sont distribués uniformément, mais peut créer des points chauds pour les motifs d'accès biaisés. Les ingénieurs travaillant avec des données du monde réel ont souvent besoin d'analyser les distributions de fréquence d'embedding et de rééquilibrer manuellement le sharding pour éviter les goulots d'étranglement.
Les gains de performance de SparseCore atteignent 5-7× comparé à l'implémentation d'opérations identiques sur le MXU et VPU, tout en consommant seulement 5% de la surface de die de puce et de l'alimentation.⁶⁰ L'avantage d'efficacité dramatique provient de la construction sur mesure du flux de données pour les opérations éparses plutôt que de les forcer à travers l'infrastructure matricielle dense. Le principe de spécialisation s'applique récursivement dans l'architecture TPU : tout comme les TPU se spécialisent au-delà de la conception généraliste des GPU, les SparseCores se spécialisent au-delà de la conception orientée matrice des TPU.
Le SparseCore de troisième génération de Trillium a introduit une largeur SIMD variable (8 éléments pour FP32, 16 pour bfloat16) et des motifs d'accès mémoire améliorés, réduisant la bande passante gaspillée des lectures mal alignées.⁶¹ L'évolution architecturale démontre l'investissement continu de Google dans l'accélération d'embedding alors que les grands modèles de langage tendent vers des vocabulaires plus larges et des motifs de génération augmentée par récupération plus sophistiqués.
Technologie d'interconnexion : Câbler le supercalculateur
Architecture d'interconnexion inter-puces (ICI)
L'interconnexion inter-puces est la technologie critique qui permet aux TPU de fonctionner comme des supercalculateurs unifiés plutôt que comme des accélérateurs isolés. Contrairement aux GPU qui communiquent via des réseaux Ethernet ou InfiniBand, l'ICI implémente des liaisons série haute vitesse personnalisées connectant directement les TPU voisins avec une latence à l'échelle de la microseconde et une bande passante de térabits par seconde.⁶²
L'évolution de la topologie à travers les générations de TPU reflète les exigences changeantes pour la montée en charge des pods. Les TPU v2, v3, v5e et v6e implémentent des topologies en tore 2D dans lesquelles chaque puce se connecte à ses quatre voisins les plus proches (nord, sud, est et ouest).⁶³ Les liaisons se bouclent aux limites, créant une topologie logique en forme de donut qui élimine les puces de bordure avec moins de connexions. Une grille 16×16 de 256 TPU fournit ainsi des caractéristiques uniformes de bande passante et de latence, peu importe quelles deux puces communiquent.
Les TPU v4 et v5p ont été mis à niveau vers des topologies en tore 3D avec chaque puce se connectant à six voisins.⁶⁴ La dimension supplémentaire réduit le diamètre du réseau—le nombre maximum de sauts entre deux puces quelconques—d'environ 2√N à 3∛N. Pour un pod de 4 096 puces, le maximum de sauts chute d'environ 128 à 48, réduisant substantiellement la latence de communication dans le pire cas pour les opérations de synchronisation globale telles que all-reduce.
La structure toroïdale offre un autre avantage critique : une bande passante de bisection égale indépendamment de la façon dont les charges de travail se partitionnent entre les puces. Toute coupe qui divise le tore en deux traverse le même nombre de liaisons, empêchant les cas pathologiques où un mauvais placement de tâche crée des goulots d'étranglement réseau.⁶⁵ La bande passante de bisection uniforme simplifie la planification et permet la reconfigurabilité du commutateur de circuit optique discutée ci-dessous.
Les spécifications de bande passante évoluent de manière impressionnante à travers les générations. Le TPU v6e fournit 13 TB/s de bande passante ICI par puce.⁶⁶ Le TPU v5p a atteint 4 800 Gbps par puce à travers six liaisons de tore 3D.⁶⁷ Ironwood implémente quatre liaisons ICI avec une bande passante bidirectionnelle agrégée de 9,6 Tbps, se traduisant par 1,2 TB/s par puce.⁶⁸ En comparaison, une interface réseau 400GbE haut de gamme fournit 50 GB/s de bande passante bidirectionnelle—un ordre de grandeur de moins que l'ICI des TPU modernes.
La technologie de liaison à l'intérieur des racks utilise des câbles cuivre à connexion directe (DAC) pour les courtes distances entre puces dans le même cube 4×4×4.⁶⁹ Les connexions cuivre minimisent le coût et la consommation tout en fournissant la bande passante requise pour les puces étroitement couplées exécutant des opérations synchronisées. Les liaisons inter-cubes et à l'échelle du pod passent aux transceivers optiques, échangeant un coût et une consommation plus élevés contre la distance et la bande passante nécessaires pour couvrir les racks du datacenter.
Les opérations collectives exploitent les propriétés uniques de l'ICI. Les opérations all-reduce, all-gather et reduce-scatter synchronisent fréquemment les activations et gradients entre les puces pendant l'entraînement. Sur les clusters GPU basés Ethernet, ces collectifs traversent un réseau hiérarchique avec des commutateurs, câbles et cartes d'interface réseau, introduisant une latence à chaque saut. L'ICI des TPU implémente des algorithmes collectifs optimisés directement en matériel, exécutant les opérations all-reduce 10× plus rapidement que les implémentations GPU équivalentes basées Ethernet.⁷⁰
Commutation de circuit optique : Reconfiguration dynamique de topologie
Le déploiement par Google de la commutation de circuit optique (OCS) avec le TPU v4 a représenté l'une des innovations les plus significatives dans les réseaux de datacenter en décennies. Les réseaux traditionnels à commutation de paquets—qu'il s'agisse d'Ethernet ou d'InfiniBand—établissent des connexions logiques en routant les paquets saut par saut à travers des commutateurs qui examinent les en-têtes et transmettent vers les ports de sortie appropriés. L'OCS utilise plutôt des éléments optiques programmables pour créer des chemins lumineux physiques directs entre les points terminaux, éliminant entièrement la latence de commutation.⁷¹
La technologie centrale repose sur des miroirs MEMS (systèmes microélectromécaniques) qui pivotent physiquement pour rediriger les faisceaux lumineux. Un émetteur sur le TPU A envoie la lumière dans l'OCS. De minuscules miroirs à l'intérieur de l'OCS pivotent pour réfléchir ce faisceau lumineux vers un récepteur sur le TPU B. La connexion devient un chemin optique direct de A vers B avec essentiellement zéro latence ajoutée au-delà de la propagation de la lumière à travers la fibre.⁷²
La vitesse de reconfiguration détermine la praticité de l'OCS dans les systèmes de production. Le déploiement de Google atteint des temps de commutation inférieurs à 10 nanosecondes—plus rapides que les temps d'aller-retour typiques des protocoles réseau.⁷³ La vitesse de reconfiguration permet des changements de topologie dynamiques correspondant aux exigences des charges de travail sans perturber les tâches en cours ou nécessiter une ingénierie de trafic soigneusement coordonnée.
Le TPU v5p a démontré l'OCS à une échelle massive. L'architecture utilise des commutateurs de circuit optique qui délivrent quatre pétabits par seconde de bande passante agrégée à travers le fabric de commutation.⁷⁴ Un seul superpod v5p nécessite 48 unités OCS gérant 13 824 ports optiques pour câbler 8 960 puces dans la configuration de tore 3D 16×20×28.⁷⁵ Le système de commutation représente l'un des plus grands déploiements de réseau optique dans tout environnement informatique.
L'OCS fournit des capacités impossibles avec les réseaux traditionnels. La topologie physique et la topologie logique se découplent entièrement—deux TPU dans des coins opposés du datacenter apparaissent comme des voisins adjacents si l'OCS crée des chemins optiques directs. Les puces ou liaisons défaillantes sont contournées en reprogrammant les miroirs pour exclure les composants défaillants et maintenir la structure de tore logique. Les nouvelles tâches reçoivent des "tranches" de toute taille en programmant l'OCS pour créer des configurations de pod appropriées sans recâbler physiquement les racks.⁷⁶
L'architecture s'intègre avec le réseau de datacenter Jupiter de Google pour évoluer au-delà d'un seul pod. Jupiter délivre une bande passante de bisection multi-pétabits par seconde à travers des datacenters entiers en utilisant les commutateurs silicium personnalisés et le plan de contrôle de Google.⁷⁷ Plusieurs superpods TPU se connectent via le fabric Jupiter, supportant théoriquement des clusters jusqu'à 400 000 accélérateurs si la capacité réseau le permet.⁷⁸
Les caractéristiques de consommation électrique et de fiabilité favorisent la commutation de circuit optique pour les déploiements à l'échelle TPU. Les commutateurs de paquets traditionnels consomment une puissance substantielle pour traiter et transmettre les paquets à des débits de térabits par seconde. Les commutateurs OCS ne consomment de la puissance que pour faire fonctionner les miroirs MEMS pendant les événements de reconfiguration, puis restent inactifs, faisant passer la lumière avec une perte minimale tant que les connexions restent stables.⁷⁹ La simplicité de l'architecture améliore la fiabilité en éliminant le traitement complexe de paquets et la logique de mise en tampon sujette aux bogues et anomalies de performance.
Architecture de pod et caractéristiques de montée en charge
Les pods TPU représentent la plus grande unité unique de TPU connectés via ICI, formant un accélérateur unifié. La structure physique se construit hiérarchiquement des puces individuelles aux plateaux aux cubes aux racks aux pods complets.⁸⁰ Comprendre la hiérarchie importe pour raisonner sur la capacité mémoire, la bande passante de communication et la tolérance aux pannes à différentes échelles.
Le bloc de construction fondamental consiste en quatre puces sur un seul plateau connecté à un CPU hôte via PCIe.⁸¹ La connexion PCIe gère les opérations du plan de contrôle, le chargement initial de programme et l'entrée/sortie pour les données d'entraînement et les résultats d'inférence. La communication inter-puces réelle pour l'entraînement distribué passe par l'ICI plutôt que PCIe, évitant les goulots d'étranglement de bande passante PCIe.
Seize plateaux (64 puces) forment un seul cube 4×4×4—l'unité de base pour la construction de pod. À l'intérieur d'un cube, toutes les connexions ICI utilisent des câbles cuivre à connexion directe puisque les puces résident dans le même rack avec de courtes distances physiques.⁸² Le cube implémente un tore 3D complet avec des connexions de bouclage, créant une unité autonome de 64 puces qui pourrait théoriquement fonctionner indépendamment.
Les pods TPU v4 évoluent jusqu'à 64 cubes totalisant 4 096 puces.⁸³ Les connexions inter-cubes passent aux liaisons optiques gérées par le fabric de commutation de circuit optique. L'OCS peut provisionner ces 4 096 puces comme un seul pod énorme, plusieurs pods indépendants plus petits, ou se reconfigurer dynamiquement en cours de tâche si nécessaire. La flexibilité permet aux opérateurs de datacenter d'équilibrer l'utilisation entre différentes tailles et priorités de tâches.
Le TPU v5p a poussé l'échelle de pod à 8 960 puces dans un tore 3D 16×20×28.⁸⁴ Les dimensions spécifiques reflètent une optimisation soigneuse de la bande passante et du diamètre—les factorisations premières importent pour la topologie réseau ! Le pod délivre 4,45 exaflops de calcul et représente l'une des plus grandes configurations de pod unique déployées en production.
Ironwood supporte à la fois des pods de 256 puces pour les déploiements plus petits et des superpods de 9 216 puces pour l'entraînement de modèles frontière massifs.⁸⁵ La configuration 9 216 puces délivre 42,5 exaflops FP8—plus de calcul que la liste entière Top500 des supercalculateurs ne contenait il y a seulement cinq ans.⁸⁶ L'échelle redéfinit ce que les organisations peuvent accomplir avec l'entraînement synchrone plutôt que des approches en pipeline ou asynchrones.
L'efficacité de montée en charge détermine si les pods plus grands aident réellement. La surcharge de communication augmente avec la taille du pod car les puces passent plus de temps à se synchroniser plutôt qu'à calculer. Google Research a publié des résultats démontrant 95% d'efficacité de montée en charge à 32 768 TPU pour des charges de travail spécifiques, signifiant que 32 768 TPU ont délivré 95% de la performance qu'une montée en charge linéaire parfaite aurait prédit.⁸⁷ L'efficacité provient des collectifs accélérés matériellement, des transformations de compilateur optimisées et des approches algorithmiques astucieuses pour réduire la fréquence de synchronisation des gradients.
La tolérance aux pannes à l'échelle du pod nécessite une gestion sophistiquée. La probabilité statistique garantit des défaillances de composants dans tout système avec des milliers de puces fonctionnant en continu. Le commutateur de circuit optique permet une dégradation gracieuse en se reconfigurant autour des composants défaillants. La création de points de contrôle d'entraînement se produit à intervalles réguliers (typiquement toutes les quelques minutes), donc l'échec de tâche nécessite de redémarrer seulement depuis le dernier point de contrôle plutôt que depuis le début.⁸⁸
Stack logiciel : Compilateurs, frameworks et modèles de programmation
Compilateur XLA : Optimisation des graphes de calcul
XLA (Accelerated Linear Algebra) constitue la fondation du stack logiciel des TPU, compilant les opérations de frameworks de haut niveau en code machine optimisé pour l'exécution sur TPU.⁸⁹ Le compilateur implémente des optimisations agressives impossibles dans les compilateurs généralistes car il exploite la connaissance du domaine des charges de travail d'apprentissage automatique et les caractéristiques de l'architecture TPU.
La fusion représente l'optimisation la plus impactante d'XLA. Le compilateur analyse les graphes de calcul pour identifier les séquences d'opérations qui peuvent s'exécuter sans matérialiser les tenseurs intermédiaires. Un exemple simple : les opérations élément par élément comme relu(batch_norm(conv(x))) nécessitent normalement d'écrire la sortie de convolution en mémoire, de la lire pour la normalisation par lot, d'écrire ce résultat en mémoire, et de lire à nouveau pour ReLU. XLA fusionne ces opérations en un seul kernel qui produit la sortie ReLU finale sans trafic mémoire intermédiaire.⁹⁰
L'impact de la fusion s'adapte à l'architecture TPU. La bande passante mémoire contraint de nombreuses charges de travail plus que le débit de calcul—la MXU peut effectuer des multiplications matricielles plus rapidement que le système mémoire ne peut l'alimenter en données. Éliminer les écritures et lectures mémoire intermédiaires grâce à la fusion se traduit directement par des améliorations de performance, offrant souvent une accélération de 2× ou plus pour les réseaux riches en fonctions d'activation.⁹¹
Les transformations de disposition mémoire optimisent le stockage des tenseurs pour les exigences matérielles. Les réseaux de neurones représentent souvent les tenseurs au format NHWC (batch, height, width, channels) pour un indexage intuitif, mais les MXU TPU performent mieux avec des dispositions qui s'alignent sur les tuiles 128×8.⁹² XLA transpose, remodèle et complète automatiquement les tenseurs pour correspondre aux préférences matérielles, insérant les transformations de disposition seulement lorsque nécessaire et propageant parfois les dispositions préférées vers l'arrière à travers le graphe pour minimiser la surcharge totale de transformation.
Le compilateur implémente un pliage de constantes sophistiqué et une élimination de code mort. Les graphes ML contiennent fréquemment des sous-graphes dont les sorties dépendent uniquement de constantes—paramètres de normalisation par lot, taux de dropout d'inférence, et calculs de forme qui peuvent être exécutés une fois plutôt qu'à chaque lot. XLA évalue ces sous-graphes au moment de la compilation et les remplace par des tenseurs constants, réduisant le travail d'exécution.⁹³
L'optimisation cross-replica exploite la connaissance de l'exécution distribuée. Lors de l'entraînement sur plusieurs cœurs TPU, certaines opérations (comme les statistiques de normalisation par lot) nécessitent une agrégation à travers toutes les repliques. XLA identifie ces motifs et génère des opérations collectives optimisées qui exploitent l'all-reduce accéléré matériellement d'ICI plutôt que d'implémenter l'agrégation via le passage de messages explicite.⁹⁴
Le compilateur cible une représentation intermédiaire, Mosaic, spécifiquement pour les TPU. Mosaic opère à un niveau d'abstraction plus élevé que le langage assembleur mais plus bas que le graphe de calcul d'entrée. Le langage expose les fonctionnalités architecturales TPU, telles que les tableaux systoliques, la mémoire vectorielle et la mise en scène VMEM, tout en cachant les détails de bas niveau, tels que l'ordonnancement d'instructions et l'allocation de registres.⁹⁵
Les capacités d'auto-tuning sélectionnent les tailles de tuiles optimales et les paramètres d'opération par recherche empirique. Le système XLA Auto-Tuning (XTAT) teste différentes stratégies de fusion, dispositions mémoire et dimensions de tuiles, profile les performances de chaque variante, et sélectionne la configuration la plus rapide.⁹⁶ La recherche peut nécessiter un temps de compilation substantiel pour les modèles complexes, mais produit des accélérations d'exécution spectaculaires en découvrant des optimisations contre-intuitives que les humains identifient rarement manuellement.
JAX : Transformations composables et SPMD
JAX fournit une interface compatible NumPy pour le calcul numérique avec différentiation automatique, compilation JIT vers XLA, et support de première classe pour la transformation de programmes.⁹⁷ Le paradigme de programmation fonctionnelle du framework et le modèle de transformation composable s'alignent naturellement avec les modèles d'exécution TPU et les motifs de parallélisme distribué.
L'abstraction JAX centrale applique des transformations mathématiques aux fonctions. grad(f) calcule le gradient de f. jit(f) compile f vers XLA en JIT. vmap(f) vectorise f sur une nouvelle dimension. Crucialement, les transformations se composent : jit(grad(vmap(f))) fonctionne exactement comme attendu, compilant une fonction de gradient vectorisée.⁹⁸ Le modèle compositionnel permet de construire des boucles d'entraînement distribuées complexes à partir de composants simples et testables.
SPMD (Single Program, Multiple Data) représente le modèle d'exécution distribuée de JAX. Les programmeurs écrivent du code comme s'ils ciblaient un seul appareil, puis ajoutent des annotations de sharding indiquant comment partitionner les tenseurs à travers plusieurs cœurs TPU. Le compilateur XLA et le sous-système GSPMD (General SPMD) insèrent automatiquement des opérations de communication pour maintenir la sémantique du programme tout en s'exécutant sur des appareils distribués.⁹⁹
Les annotations de sharding utilisent PartitionSpec pour déclarer les stratégies de distribution. PartitionSpec('batch', None) partage la première dimension d'un tenseur à travers l'axe 'batch' du maillage d'appareils tout en répliquant la seconde dimension. PartitionSpec(None, 'model') implémente le parallélisme tensoriel en partitionnant la seconde dimension. Les annotations peuvent être composées avec des rangs de tenseurs arbitraires et des dimensions de maillage d'appareils.¹⁰⁰
La parallélisation automatique de GSPMD élimine de vastes quantités de code passe-partout. L'entraînement distribué traditionnel nécessite l'insertion manuelle d'un all-gather avant les opérations qui ont besoin de tenseurs complets, un reduce-scatter après avoir calculé les gradients distribués, et un all-reduce pour les réductions globales. GSPMD analyse les spécifications de sharding et insère automatiquement les collectifs appropriés, libérant les programmeurs pour se concentrer sur l'algorithme plutôt que sur l'ingénierie de communication.¹⁰¹
Le compilateur propage les décisions de sharding à travers le graphe de calcul en utilisant la résolution de contraintes. Si l'opération A sort un tenseur partagé consommé par l'opération B, GSPMD infère le sharding optimal de B basé sur la façon dont la sortie est utilisée, insérant potentiellement des opérations de resharding seulement où mathématiquement nécessaire.¹⁰² L'inférence automatisée prévient les "spaghettis de sharding" qui affligent le code distribué écrit à la main.
JAX fournit un contrôle fin quand l'automatisation échoue. with_sharding_constraint force un sharding spécifique aux emplacements du graphe, surpassant l'inférence automatique. Les annotations PJIT (parallel JIT) personnalisées spécifient le placement exact des appareils et les stratégies de sharding pour les chemins de code critiques en performance. Le modèle en couches permet un prototypage rapide avec sharding automatique tout en supportant l'optimisation experte où requise.¹⁰³
Shardy a émergé comme successeur de GSPMD en 2025, implémentant des algorithmes de propagation de contraintes améliorés et une meilleure gestion des formes dynamiques.¹⁰⁴ Le nouveau système expose des opportunités d'optimisation supplémentaires en raisonnant sur les choix de sharding conjointement à travers de plus grandes régions de graphe plutôt qu'opération par opération.
PyTorch/XLA : Amener PyTorch aux TPU
PyTorch/XLA permet d'exécuter des modèles PyTorch sur TPU avec des changements de code minimaux, comblant le fossé entre le modèle de programmation impératif de PyTorch et la compilation basée graphe d'XLA.¹⁰⁵ L'intégration équilibre la préservation de l'expérience développeur PyTorch avec l'exposition d'optimisations spécifiques aux TPU.
Le défi fondamental découle de la philosophie d'exécution eager de PyTorch. PyTorch exécute les opérations immédiatement lors de l'exécution des instructions Python, permettant le débogage avec des outils standards et un flux de contrôle naturel. XLA nécessite de capturer des graphes de calcul complets avant compilation, créant une tension entre l'exécution eager et les bénéfices de performance de la compilation de graphe.¹⁰⁶
PyTorch/XLA 2.4 a introduit le support du mode eager, abordant la discordance d'impédance. L'implémentation trace dynamiquement les opérations PyTorch en graphes XLA, permettant aux développeurs d'écrire du code PyTorch standard tout en bénéficiant encore de la compilation XLA.¹⁰⁷ Le mode échange certaines opportunités d'optimisation de compilation contre la vélocité de développement et la simplicité de débogage.
Le mode graphe reste le chemin principal pour les déploiements de production. Les développeurs marquent explicitement les fonctions pour la compilation XLA en utilisant des décorateurs ou des API de compilation. Les annotations explicites permettent une optimisation agressive mais nécessitent de comprendre quelles opérations doivent être fusionnées en un seul graphe XLA versus exécutées indépendamment.¹⁰⁸
L'intégration Pallas apporte le développement de kernels personnalisés à PyTorch/XLA. Pallas fournit un langage de bas niveau pour écrire des kernels TPU quand la fusion automatique d'XLA échoue ou que des opérations spécialisées nécessitent une optimisation manuelle.¹⁰⁹ Le langage expose la hiérarchie mémoire TPU (VMEM, CMEM, HBM) et les unités de calcul (MXU, VPU) tout en restant de plus haut niveau que l'assembleur brut.
Les kernels Pallas intégrés implémentent des opérations critiques en performance comme FlashAttention et PagedAttention. Le calcul d'attention tuilé de FlashAttention réduit les exigences de bande passante mémoire de O(n²) à O(n) pour une longueur de séquence n, permettant aux modèles de traiter des séquences beaucoup plus longues dans des budgets mémoire fixes.¹¹⁰ PagedAttention optimise la gestion du cache clé-valeur pour le service, atteignant une accélération de 5× par rapport aux implémentations complétées.¹¹¹
Le pont PyTorch/XLA s'est avéré critique pour vLLM TPU—un framework de service haute performance conçu initialement pour GPU. L'implémentation utilise en fait JAX comme chemin de lowering intermédiaire même pour les modèles PyTorch, exploitant le support de parallélisme supérieur de JAX tout en maintenant la compatibilité frontend PyTorch.¹¹² L'architecture a atteint des améliorations de performance de 2-5× tout au long de 2025 par rapport aux prototypes initiaux.
Les défis de compatibilité de modèles persistent malgré les améliorations. Certaines opérations PyTorch manquent d'équivalents XLA, forçant un fallback vers l'exécution CPU qui dégrade les performances. Le flux de contrôle dynamique est mal supporté par la compilation de graphe, nécessitant souvent des changements architecturaux pour remplacer le comportement dynamique par des alternatives statiques et compilables. Le dépôt PyTorch/XLA documente la compatibilité et fournit des guides de migration pour les motifs problématiques courants.¹¹³
Formats de précision : BFloat16, FP8 et quantification
Le support TPU pour l'arithmétique à précision réduite permet des améliorations spectaculaires de performance et mémoire tout en maintenant une qualité de modèle acceptable. Comprendre les propriétés numériques des différents formats et quand appliquer chacun s'avère critique pour atteindre des performances optimales.¹¹⁴
BFloat16 représente le pari précoce de Google sur l'entraînement à précision réduite, apparaissant d'abord dans TPU v2. Le format maintient l'exposant 8-bit de FP32 tout en tronquant la mantisse à 7 bits (plus bit de signe).¹¹⁵ La plage d'exposant complète prévient le sous-débordement et le débordement qui affligeaient l'entraînement FP16 précoce, où les gradients échappaient fréquemment à la plage représentable de FP16.
La mantisse réduite introduit une erreur de quantification mais impacte rarement la qualité finale du modèle. Les ingénieurs ont observé que les modèles entraînés en bfloat16 correspondent typiquement aux baselines entraînées FP32 dans le bruit statistique, probablement parce que la quantification agit comme une forme de régularisation, prévenant le surapprentissage aux détails numériques minuscules.¹¹⁶ Le format divise par deux les exigences de bande passante et capacité mémoire par rapport à FP32, se traduisant directement par des gains de performance sur les charges de travail limitées par la mémoire.
FP8 pousse la précision réduite plus loin, compressant les poids et activations à 8 bits. Deux encodages standard existent : E4M3 (exposant 4-bit, mantisse 3-bit) privilégie la précision pour les passes avant, tandis que E5M2 (exposant 5-bit, mantisse 2-bit) privilégie la plage pour les passes arrière où les magnitudes de gradient varient largement.¹¹⁷ Ironwood implémente le support FP8 natif pour les deux formats, tandis que les TPU antérieurs émulaient FP8 par des transformations logicielles.¹¹⁸
La conscience de quantification pendant l'entraînement permet le succès numérique de FP8. Les modèles entraînés depuis zéro avec FP8 ou affinés avec des techniques conscientes de FP8 apprennent des distributions de poids qui tolèrent la précision limitée du format. La quantification post-entraînement (convertir les modèles FP32 en FP8 après entraînement) dégrade souvent la qualité sans calibration soigneuse.¹¹⁹
La quantification INT8 livre des économies mémoire encore plus grandes et des accélérations d'inférence. L'Accurate Quantized Training (AQT) de Google permet l'entraînement INT8 sur TPU avec une perte de qualité minimale par rapport aux baselines bfloat16.¹²⁰ La technique applique l'entraînement conscient de la quantification depuis zéro, permettant aux modèles de s'adapter aux contraintes INT8 pendant l'apprentissage plutôt que par approximation post-entraînement.
Les stratégies de précision mixte combinent les formats stratégiquement. Les passes avant peuvent utiliser FP8 pour les activations et poids, les passes arrière utilisent FP8 E5M2 ou bfloat16 pour les gradients, et les états optimiseurs restent en FP32 pour la stabilité numérique pendant les mises à jour de poids.¹²¹ L'approche mixte équilibre vitesse, mémoire et précision, atteignant souvent 90%+ de la qualité FP32 tout en fonctionnant 4× plus vite.
Les compromis de précision s'étendent au-delà de la vitesse et mémoire pour inclure des considérations de stabilité numérique. La normalisation par lot, la normalisation de couche et softmax nécessitent une gestion numérique soigneuse en précision réduite. Les grandes exponentielles dans softmax peuvent déborder les plages FP8 ou bfloat16 ; soustraire le logit maximum avant exponentiation prévient le débordement tout en maintenant l'équivalence mathématique.¹²² Le compilateur XLA implémente ces transformations automatiquement quand sûr, mais les opérations personnalisées nécessitent parfois une ingénierie numérique manuelle.
Modèles de Programmation et Stratégies de Parallélisme
SPMD et Partitionnement Automatique
Le paradigme Single Program, Multiple Data (SPMD) façonne fondamentalement la façon dont les programmeurs conçoivent l'exécution sur TPU. Plutôt que d'écrire du code explicite de passage de messages pour coordonner plusieurs processus, les développeurs écrivent un seul programme et annotent comment les données doivent être partitionnées entre les appareils.¹²³ Le compilateur gère les détails mécaniques de distribution, communication et synchronisation.
GSPMD (General SPMD) implémente la logique de partitionnement automatique dans XLA. Le système analyse les annotations de sharding des tenseurs et la structure du graphe de calcul pour déterminer où les opérations s'exécutent sur quels appareils et quelle communication est requise pour maintenir une sémantique correcte.¹²⁴ L'automatisation élimine des classes entières de bugs communes dans le code distribué écrit à la main—formes de tenseurs incompatibles, ordonnancement incorrect des opérations collectives, et interblocages dus à une synchronisation inappropriée.
Le moteur de propagation de contraintes du compilateur infère les décisions de sharding à partir d'annotations minimales. Annoter uniquement le sharding d'entrée et de sortie d'un modèle suffit souvent ; GSPMD propage les contraintes à travers les opérations intermédiaires et sélectionne automatiquement des distributions efficaces.¹²⁵ Quand plusieurs shardings valides existent pour une opération, le compilateur estime les coûts de communication des alternatives et sélectionne l'option la moins coûteuse.
Les optimisations avancées chevauchent communication et calcul. Les opérations all-reduce qui synchronisent les gradients entre les répliques peuvent commencer dès que les gradients de la première couche sont terminés, s'exécutant en parallèle avec les passes arrière des couches suivantes.¹²⁶ Le compilateur planifie automatiquement les collectives pour maximiser le chevauchement, réduisant le temps de communication adéquat de 2× ou plus comparé à l'exécution séquentielle.
La rematérialisation échange calcul contre mémoire. Plutôt que de stocker toutes les activations de passe avant pour le calcul des gradients, le compilateur recalcule sélectivement les activations pendant les passes arrière quand la pression mémoire dépasse les seuils.¹²⁷ Ce compromis fonctionne particulièrement bien sur TPU où le calcul dépasse souvent la bande passante mémoire, rendant le recalcul moins cher que le trafic mémoire.
Parallélisme de Données, Parallélisme de Tenseur, et Parallélisme Pipeline
Le parallélisme de données représente la stratégie d'entraînement distribuée la plus directe : répliquer le modèle complet sur N appareils et traiter différents lots de données sur chaque réplique. Après avoir calculé les gradients localement, un all-reduce agrège les gradients entre les répliques, et tous les appareils appliquent des mises à jour de poids identiques.¹²⁸ L'approche s'adapte linéairement jusqu'à ce que le temps de communication domine le temps de calcul—typiquement autour de 1 000 GPU avec un réseau Ethernet mais 10 000+ TPU avec ICI.¹²⁹
Le parallélisme de tenseur (aussi appelé parallélisme de modèle) partitionne les opérations individuelles entre les appareils. Une multiplication matricielle Y = W @ X divise la matrice de poids W entre les appareils, chacun calculant une portion de la sortie.¹³⁰ La stratégie permet d'entraîner des modèles dépassant la mémoire d'un seul appareil en distribuant le stockage des paramètres et le calcul.
Le modèle de communication pour le parallélisme de tenseur diffère significativement de celui du parallélisme de données. Plutôt qu'un all-reduce après chaque couche, le parallélisme de tenseur requiert un all-gather avant les opérations qui nécessitent des tenseurs complets et un reduce-scatter après les calculs distribués.¹³¹ Le volume de communication s'adapte à la taille d'activation du modèle plutôt qu'à la taille des paramètres, créant des goulots d'étranglement différents du parallélisme de données.
Le parallélisme pipeline partitionne les couches séquentielles du modèle entre les appareils, traitant différents micro-lots sur différentes étapes simultanément. GPipe a introduit la stratégie avec une planification soigneuse pour maximiser l'utilisation du pipeline tout en limitant l'usage mémoire.¹³² Chaque appareil traite la passe avant d'un micro-lot, envoie les activations à l'étape suivante, puis traite le micro-lot suivant—créant un pipeline où tous les appareils travaillent continuellement après la montée en charge initiale.
L'obsolescence des gradients complique le parallélisme pipeline. Les appareils mettent à jour les poids en utilisant des gradients calculés à partir d'activations potentiellement anciennes de dizaines de micro-lots, créant une obsolescence qui peut nuire à la convergence.¹³³ Des algorithmes de planification sophistiqués comme PipeDream minimisent l'obsolescence tout en maintenant un débit élevé, et les résultats empiriques démontrent que la plupart des modèles tolèrent une obsolescence modérée sans dégradation de qualité.
Le parallélisme 3D combine les trois stratégies. Le parallélisme de données distribue selon la dimension "données", le parallélisme de tenseur selon la dimension "modèle", et le parallélisme pipeline selon la dimension "pipeline".¹³⁴ Équilibrer soigneusement les dimensions basé sur l'architecture du modèle, la topologie matérielle, et les coûts de communication maximise le débit. Les modèles à l'échelle de GPT-3 utilisent couramment le parallélisme 3D avec parallélisme de données sur 8-16 répliques, parallélisme de tenseur sur 4-8 GPU, et parallélisme pipeline sur 4-16 étapes.
Stratégies de Sharding et Optimisation
Sélectionner les stratégies de sharding requiert de comprendre les opérations mathématiques et leurs dépendances de données. La multiplication matricielle C = A @ B permet plusieurs shardings valides : répliquer A et B et calculer des résultats partiels (communication avant calcul), sharding de B par colonnes et rassemblement des résultats (communication après calcul), ou sharding de A par lignes et B par colonnes sans communication mais avec des matrices plus petites par appareil.¹³⁵
Les coûts d'opérations collectives déterminent les stratégies optimales. Les coûts all-reduce s'adaptent linéairement à la taille des tenseurs mais sous-linéairement au nombre d'appareils utilisant des algorithmes de réduction basés sur arbre ou anneau :¹³⁶ All-gather et reduce-scatter présentent différentes propriétés d'adaptation. Le compilateur modélise ces coûts et sélectionne les stratégies de sharding minimisant le temps total de communication.
Le parallélisme de séquence émerge comme critique pour les grands modèles de langage. Les mécanismes d'attention créent des goulots d'étranglement mémoire car les caches clé-valeur croissent avec la longueur de séquence et la taille de lot. Partitionner selon la dimension séquence distribue la charge mémoire entre les appareils tout en introduisant de la communication seulement pour le calcul d'attention lui-même.¹³⁷
Le parallélisme d'expert gère les modèles Mixture-of-Experts (MoE) où différents experts traitent différents jetons. La stratégie de sharding réplique les couches partagées sur tous les appareils mais partitionne les experts, routant chaque jeton vers son appareil expert désigné.¹³⁸ Le routage dynamique crée des modèles de communication irréguliers qui défient les opérations collectives traditionnelles, nécessitant des systèmes d'exécution sophistiqués pour minimiser la latence et le déséquilibre de charge.
Le sharding d'état d'optimiseur réduit la surcharge mémoire pour les grands modèles. Les optimiseurs comme Adam stockent des statistiques de momentum et variance pour chaque paramètre, ce qui triple les exigences mémoire au-delà de celles des paramètres seuls. Sharding des états d'optimiseur entre appareils tout en gardant les paramètres répliqués permet d'entraîner des modèles plus grands dans des budgets mémoire fixes.¹³⁹ La stratégie requiert de rassembler les mises à jour d'état d'optimiseur pendant les calculs de poids mais réduit substantiellement l'empreinte mémoire par appareil.
Analyse de performance et benchmarking
Résultats MLPerf et positionnement concurrentiel
MLPerf fournit des benchmarks standard de l'industrie mesurant les performances des accélérateurs AI sur les charges de travail d'entraînement et d'inférence. Google soumet régulièrement les résultats TPU démontrant des performances compétitives, et l'évolution à travers les générations montre des améliorations architecturales claires.¹⁴⁰
TPU v5e a obtenu des résultats leader dans 8 des 9 catégories d'entraînement MLPerf.¹⁴¹ Cette étendue démontre la versatilité architecturale au-delà des seuls grands modèles de langage—des performances compétitives à travers la vision par ordinateur, les systèmes de recommandation et les charges de travail de calcul scientifique. L'entraînement BERT s'est terminé 2,8× plus rapidement que les GPU NVIDIA A100, validant l'architecture optimisée pour les transformers.¹⁴²
MLPerf Training v5.0, annoncé en juin 2025, a introduit un benchmark Llama 3.1 405B représentant le plus grand modèle de la suite.¹⁴³ Le benchmark stresse la montée en charge multi-nœuds, la surcharge de communication et la capacité mémoire plus que les tests précédents. Google Cloud a participé avec des soumissions TPU, bien que les comparaisons de performance détaillées restent sous embargo en attendant la publication des résultats officiels.
MLPerf Inference v5.0 incluait quatre nouveaux benchmarks : Llama 3.1 405B, Llama 2 70B pour les applications à faible latence, les réseaux de neurones graphiques RGAT, et PointPainting pour la détection d'objets 3D.¹⁴⁴ La diversité pousse les accélérateurs au-delà des charges de travail transformer conventionnelles vers des domaines d'application émergents où les hypothèses architecturales peuvent différer.
Les benchmarks d'inférence favorisent particulièrement les forces architecturales du TPU. Les charges de travail d'inférence par lots exploitent le parallélisme massif de la MXU, atteignant un débit 4× plus élevé que les accélérateurs concurrents pour le serving de transformers.¹⁴⁵ La latence de requête unique bénéficie de l'exécution déterministe du TPU et de l'absence de limitation thermique, offrant une latence cohérente sans la variance de performance qui affecte certains déploiements GPU.
Les métriques d'efficacité énergétique montrent les avantages TPU s'étendant à travers les générations. TPU v4 a démontré 2,7× de meilleures performances par watt que TPU v3, et Trillium s'est amélioré de 67% par rapport à v5e.¹⁴⁶ Ironwood revendique 2× de meilleures performances par watt que Trillium malgré des performances absolues significativement plus élevées.¹⁴⁷ Les gains d'efficacité se composent à travers des pods de milliers de puces, se traduisant par des millions de dollars de coûts opérationnels de datacenter.
Performances d'entraînement et d'inférence en conditions réelles
Les charges de travail de production révèlent des caractéristiques de performance absentes des benchmarks synthétiques. Google publie des résultats de services internes démontrant le comportement TPU sous des modèles d'usage réels et des exigences de montée en charge.¹⁴⁸
L'entraînement ResNet-50 ImageNet se termine en 28 minutes sur les pods TPU, un benchmark largement cité pour les performances des charges de travail de vision par ordinateur.¹⁴⁹ La métrique temps-vers-précision capture le processus d'entraînement complet, incluant le chargement des données, l'augmentation, la synchronisation de gradient distribuée et la sauvegarde de checkpoints—pas seulement les FLOPS théoriques.
L'entraînement du modèle de langage T5-3B démontre les avantages TPU sur les architectures transformer. Le modèle à 3 milliards de paramètres s'entraîne en 12 heures sur les pods TPU, comparé à 31 heures sur des configurations GPU équivalentes.¹⁵⁰ L'accélération de 2,6× provient des opérations d'attention accélérées matériellement, de l'utilisation efficace de la bande passante mémoire et des communications collectives optimisées.
Les charges de travail à l'échelle GPT-3 (175B paramètres) atteignent un temps-vers-précision 1,7× plus rapide sur les TPU que sur les GPU contemporains.¹⁵¹ L'écart de performance se creuse pour des modèles encore plus grands, où la capacité et la bande passante mémoire deviennent des contraintes critiques. La HBM3e de 192GB d'Ironwood permet de servir des modèles qui nécessitent un parallélisme tensoriel complexe sur les alternatives à mémoire plus faible.
Les mesures d'efficacité de montée en charge démontrent une accélération quasi-linéaire à des échelles énormes. Google Research a rapporté une efficacité de montée en charge de 95% à 32 768 TPU pour des charges de travail spécifiques d'entraînement de transformers.¹⁵² La métrique signifie que 32 768 TPU ont livré 95% de la performance qu'une montée en charge linéaire parfaite aurait prédit—remarquable étant donné que la surcharge de communication augmente avec l'échelle.
Les métriques d'utilisation FLOPS révèlent à quel point les charges de travail exploitent efficacement le calcul disponible. Les modèles transformer atteignent typiquement 90% d'utilisation FLOPS sur les TPU, signifiant que 90% de la performance théorique maximale est traduite en travail réel.¹⁵³ La haute utilisation provient de la fusion d'opérations éliminant les goulots d'étranglement mémoire, de l'efficacité des arrays systoliques dans les multiplications de grandes matrices, et des optimisations de compilateur qui minimisent les cycles gaspillés.
Les services d'inférence de production démontrent des performances soutenues à travers des milliards de requêtes par jour. Google Translate traite 1 milliard de requêtes quotidiennes sur les TPU.¹⁵⁴ Les recommandations YouTube servent 2 milliards d'utilisateurs en utilisant des modèles accélérés par TPU.¹⁵⁵ Google Photos analyse 28 milliards d'images mensuellement pour les fonctionnalités de recherche et d'organisation.¹⁵⁶ L'échelle opérationnelle valide la fiabilité et la rentabilité au-delà des déploiements de prototypes de recherche.
Efficacité énergétique et coût total de possession
La consommation électrique impacte directement les coûts opérationnels des datacenters et la durabilité environnementale. Les améliorations d'efficacité énergétique du TPU à travers les générations réduisent à la fois les dépenses opérationnelles et les émissions carbone à l'échelle.¹⁵⁷
TPU v4 affichait en moyenne seulement 200W de consommation dans les charges de travail de production malgré une spécification TDP de 250W.¹⁵⁸ La marge entre consommation moyenne et maximale permet une conception thermique et un provisionnement flexibles. Contraste avec les GPU, où les charges de travail soutenues atteignent souvent les limites TDP, nécessitant des budgets d'alimentation rack conservateurs.
Le TDP de 600W d'Ironwood représente une puissance absolue plus élevée que les générations précédentes mais offre dramatiquement plus de calcul par watt.¹⁵⁹ La performance FP8 de 4,6 PFLOPS par puce donne environ 7,7 TFLOPS par watt—compétitive ou dépassant l'efficacité GPU contemporaine sur des charges de travail équivalentes.
L'efficacité d'utilisation d'énergie du datacenter (PUE) amplifie l'efficacité au niveau puce. Les datacenters TPU de Google atteignent un PUE de 1,1, signifiant seulement 10% de surcharge d'alimentation au-delà de la consommation des puces pour le refroidissement, la conversion d'énergie et le réseau.¹⁶⁰ La moyenne industrielle PUE varie de 1,5 à 2,0, où 50-100% d'énergie additionnelle va à la surcharge d'infrastructure. Le faible PUE provient des systèmes de refroidissement avancés, de la distribution d'énergie efficace, et de la conception délibérée de datacenter optimisant pour les charges de travail ML.
Les considérations d'intensité carbone s'étendent au-delà de l'énergie pour inclure les sources d'énergie. Google opère des datacenters TPU sur énergie neutre en carbone via l'approvisionnement en énergie renouvelable et les programmes de compensation carbone.¹⁶¹ La comptabilité carbone importe de plus en plus pour les organisations suivant les émissions Scope 2 du cloud computing.
L'analyse du coût total de possession (TCO) doit tenir compte des coûts d'acquisition, de la consommation électrique, des exigences de refroidissement et des dépenses de maintenance. Les déploiements TPU montrent communément des réductions TCO de 20-30% comparés aux installations GPU équivalentes, principalement dues à la performance par watt supérieure et à la complexité de refroidissement réduite.¹⁶²
Les coûts d'infrastructure de refroidissement évoluent de manière non-linéaire avec la densité de puissance. Les racks refroidis par air plafonnent typiquement à 15-20kW par rack avant de nécessiter des solutions de refroidissement exotiques. Les GPU haute puissance poussent ces limites, nécessitant parfois une infrastructure de refroidissement liquide avec des coûts d'investissement et opérationnels substantiellement plus élevés. L'efficacité du TPU maintient plus de déploiements dans la plage de refroidissement par air, simplifiant la conception de datacenter.¹⁶³
Avantages techniques : Où les TPU excellent
Opérations collectives accélérées par le matériel
Le support spécialisé des opérations collectives dans TPU ICI offre l'un des avantages les plus significatifs par rapport aux accélérateurs en réseau traditionnels. All-reduce, l'opération principale pour synchroniser les gradients lors de l'entraînement distribué, s'exécute 10× plus rapidement sur TPU ICI que les implémentations GPU équivalentes basées sur Ethernet.¹⁶⁴
L'écart de performance provient de l'intégration architecturale. Les collectifs basés sur Ethernet traversent plusieurs couches : le code applicatif invoque la bibliothèque collective (NCCL, Horovod, etc.), qui génère des paquets transmis à la pile réseau, qui transfère les données vers la NIC, qui sérialise sur le fil, traverse les commutateurs, désérialise au niveau des NIC de réception, et inverse le processus. Chaque couche ajoute de la latence, copie les données à travers les hiérarchies mémoire, et consomme des cycles CPU pour le traitement des protocoles.¹⁶⁵
TPU ICI implémente les collectifs en matériel sans traverser la couche logicielle. L'opération s'initie directement depuis le TensorCore, diffuse les données sur des liens ICI dédiés, et se termine sans impliquer le CPU hôte. Le chemin matériel direct élimine la surcharge qui domine les implémentations traditionnelles.¹⁶⁶
La topologie du commutateur de circuit optique permet des algorithmes collectifs optimaux. L'all-reduce basé sur un anneau ne nécessite que 2(N-1) messages pour N dispositifs, et la topologie tore fournit un routage par le chemin le plus court, minimisant la latence.¹⁶⁷ La bande passante de bisection uniforme prévient les points chauds où les collectifs mal routés congestionnent les liens réseau.
Espace mémoire unifié et programmation simplifiée
Le modèle mémoire unifié du TPU simplifie la programmation par rapport aux hiérarchies mémoire complexes des GPU. Les programmeurs raisonnent sur un seul pool HBM plutôt que de gérer les transferts entre la RAM hôte, la mémoire globale GPU, la mémoire partagée et les fichiers de registres. Le modèle simplifié réduit les bogues et permet une vélocité de développement plus rapide.¹⁶⁸
La fragmentation mémoire disparaît en tant que préoccupation. Les GPU allouent la mémoire depuis un tas fragmenté, où les allocations et désallocations au fil du temps créent des trous qui nécessitent un compactage. La gestion mémoire du TPU via l'analyse statique du compilateur évite entièrement la fragmentation à l'exécution—les tenseurs se voient assigner des emplacements prédéterminés basés sur le graphe de calcul.¹⁶⁹
Le modèle de programmation élimine des classes entières d'erreurs CUDA. Plus d'"accès mémoire illégal" dû à une arithmétique de pointeur incorrecte, plus de bogues de cohérence de cache entre CPU et GPU, plus d'erreurs de synchronisation dues à des appels cudaDeviceSynchronize() manqués. L'abstraction de plus haut niveau prévient les pièges courants de la programmation CUDA.¹⁷⁰
Exécution déterministe et reproductibilité
La non-associativité des nombres flottants crée des défis de reproductibilité en calcul parallèle. L'expression (a + b) + c peut donner des résultats différents de a + (b + c) à cause d'erreurs d'arrondi, et les réductions parallèles peuvent sommer dans des ordres différents selon les exécutions en fonction des conditions de course.¹⁷¹
L'exécution TPU présente un déterminisme plus fort que les implémentations GPU typiques. Le motif de flux de données fixe du réseau systolique assure un ordonnancement d'opérations identique à travers les exécutions. Les opérations collectives suivent des arbres de réduction déterministes plutôt qu'une agrégation opportuniste basée sur l'ordre d'arrivée. La prévisibilité permet un entraînement reproductible où des hyperparamètres et données identiques produisent des poids de modèle bit-identiques.¹⁷²
Le débogage bénéficie énormément du déterminisme. L'entraînement non-déterministe rend la recherche des causes racines des échecs quasi impossible—le NaN provient-il d'un véritable bogue algorithmique ou d'une condition de course aléatoire ? L'exécution déterministe signifie que les échecs se reproduisent de manière fiable, permettant des approches de débogage systématiques.¹⁷³
Les applications de calcul scientifique valorisent particulièrement la reproductibilité. Les modèles climatiques, les simulations de découverte de médicaments, et la recherche en physique nécessitent des résultats vérifiables qui permettent à différents chercheurs de reproduire des résultats identiques. Le déterminisme du TPU soutient mieux la méthode scientifique que les alternatives non-déterministes concurrentes.¹⁷⁴
Optimisations du compilateur et productivité des développeurs
L'optimisation agressive de XLA offre des améliorations de performance substantielles "prêtes à l'emploi" sans réglage manuel. Les chercheurs rapportent des améliorations de 40% du débit des modèles grâce à la compilation seule par rapport aux frameworks d'exécution immédiate.¹⁷⁵ La performance est gratuite—aucune ingénierie de noyau requise.
L'optimisation de fusion bénéficie particulièrement aux développeurs. La fusion manuelle d'opérations en CUDA nécessite d'écrire des noyaux personnalisés, de tester la correction, et de maintenir le code à travers les versions de framework. XLA fusionne automatiquement les opérations et les mises à jour, et adapte les stratégies de fusion à mesure que les modèles évoluent, éliminant le fardeau de maintenance.¹⁷⁶
L'automatisation de transformation de disposition économise des semaines d'optimisation manuelle. Déterminer les dispositions de tenseur optimales pour GPU nécessite de profiler différents arrangements, d'insérer manuellement des transposées, et de gérer soigneusement les motifs d'allocation mémoire. XLA essaie les dispositions automatiquement et sélectionne la plus rapide, libérant les développeurs pour se concentrer sur l'architecture du modèle plutôt que sur l'ingénierie de performance de bas niveau.¹⁷⁷
Le gain de productivité se compose pour les équipes de recherche. Le temps économisé sur l'optimisation d'infrastructure accélère le progrès scientifique, permettant plus d'expériences et des cycles d'itération plus rapides. Les organisations rapportent des améliorations de vélocité de développement de 3× lors du passage de la programmation GPU CUDA aux flux de travail TPU basés sur JAX.¹⁷⁸
Limitations techniques et inconvénients
Enfermement propriétaire et contraintes on-premises
L'accès aux TPU est disponible exclusivement via Google Cloud Platform, empêchant le déploiement on-premises et soulevant des préoccupations d'enfermement propriétaire.¹⁷⁹ Les organisations avec des exigences de souveraineté des données, des réseaux isolés, ou des politiques contre le cloud public ne peuvent pas exploiter les TPU indépendamment de leur supériorité technique.
Cette contrainte devient de plus en plus importante alors que l'AI devient une infrastructure critique. La dépendance à un seul fournisseur cloud crée des risques de continuité d'activité—les changements de tarification, les interruptions de disponibilité, ou l'arrêt de service pourraient forcer des migrations coûteuses.¹⁸⁰ La disponibilité des GPU auprès de multiples fournisseurs (matériel NVIDIA fonctionnant sur AWS, Azure, GCP, et on-prem) offre une optionalité que l'architecture TPU exclut structurellement.
Les stratégies multi-cloud rencontrent des frictions. Les organisations standardisant sur TPU ne peuvent pas facilement déborder sur d'autres clouds ou implémenter une redondance multi-cloud sans réentraîner les modèles ou maintenir des bases de code séparées pour différentes architectures d'accélérateurs.¹⁸¹ La complexité opérationnelle des déploiements hybrides GPU/TPU dépasse souvent les économies de coûts liées à la sélection optimale d'accélérateurs.
Écart de maturité de l'écosystème CUDA
La plateforme CUDA de NVIDIA a accumulé plus de 15 ans de développement d'écosystème, de bibliothèques, de documentation, et de connaissances communautaires que les TPU ne peuvent égaler.¹⁸² L'écart de maturité se manifeste par de nombreux points de friction pour l'adoption des TPU.
La disponibilité des bibliothèques favorise CUDA de manière écrasante. Les domaines spécialisés comme l'infographie, la dynamique moléculaire, la mécanique des fluides numérique, et la génomique ont accumulé des milliers de bibliothèques optimisées CUDA au cours des dernières décennies. Les équivalents TPU n'existent souvent pas, nécessitant soit un repli sur CPU (qui détruit les performances) soit des mois d'effort de portage.¹⁸³
Le support communautaire diffère de plusieurs ordres de grandeur. Stack Overflow contient des centaines de milliers de questions CUDA avec des réponses détaillées—les dépôts GitHub se comptent par millions. Les conférences, articles académiques, et articles de blog se concentrent principalement sur la programmation CUDA. Les programmeurs TPU font face à des ressources comparativement éparses, des cycles de débogage plus longs, et moins d'experts à consulter.¹⁸⁴
Les matériaux éducatifs et tutoriels ciblent massivement CUDA. Les cours universitaires enseignent la programmation GPU en utilisant CUDA. Les cours en ligne se concentrent sur CUDA. Le pipeline de talents produit beaucoup plus d'ingénieurs expérimentés en CUDA que d'experts TPU, créant des défis d'embauche et de formation.¹⁸⁵
Le développement de noyaux personnalisés illustre l'écart d'écosystème. Écrire des noyaux CUDA optimisés reste non trivial mais bénéficie d'une documentation étendue, d'outils de profilage, et de code d'exemple. Pallas permet des noyaux TPU personnalisés, mais avec des outils moins matures et une base de connaissances plus petite. La courbe d'apprentissage décourage toutes optimisations sauf les plus critiques en performance.¹⁸⁶
Spécialisation de charge de travail et contraintes de flexibilité
L'architecture TPU optimise pour des modèles de charge de travail spécifiques—principalement la multiplication de matrices denses avec des modèles d'accès réguliers et de grandes tailles de lot. Les opérations en dehors de cette zone optimale rencontrent des chutes de performance.¹⁸⁷
Les formes dynamiques défient les modèles d'exécution TPU. Le compilateur XLA assume des dimensions de tenseur fixes pour l'optimisation et la génération de code. Les modèles avec des longueurs de séquence variables, un flux de contrôle dynamique, ou des formes dépendantes des données nécessitent un remplissage aux tailles maximales (gaspillant calcul et mémoire) ou une recompilation pour chaque forme distincte (détruisant les performances).¹⁸⁸
Les opérations éparses reçoivent un support limité malgré SparseCore. La multiplication matrice-matrice éparse, une charge de travail commune en calcul scientifique et réseaux de neurones de graphe, manque d'implémentations efficaces sur MXU ou VPU. Le SparseCore spécialisé gère les tables d'embedding mais pas l'algèbre linéaire éparse générale.¹⁸⁹
L'inférence par petits lots sous-utilise les ressources parallèles du TPU. Le réseau systolique 256×256 prospère sur de grandes matrices qui remplissent la grille de travail productif. L'inférence à requête unique laisse la plupart des MAC inactifs, produisant une latence par requête et un coût pires que les alternatives GPU optimisées pour les scénarios à faible lot.¹⁹⁰
Les modèles de calcul irréguliers défont l'efficacité du réseau systolique. Les algorithmes avec un branchement imprévisible, des structures récursives, ou un accès mémoire de poursuite de pointeur exhibent de mauvaises performances TPU car le flux de données fixe ne peut s'adapter au comportement dépendant de l'exécution.¹⁹¹
Les charges de travail non-ML bénéficient rarement de l'accélération TPU. Les simulations scientifiques, l'encodage vidéo, la vérification blockchain, et le rendu fonctionnent tous plus rapidement sur l'architecture plus générale des GPU malgré les FLOPS de crête plus élevés du TPU pour les opérations matricielles.¹⁹²
Écarts d'outillage de débogage et développement
L'écosystème de NVIDIA inclut des outils de profilage matures (Nsight Systems, Nsight Compute, nvprof), des débogueurs (cuda-gdb), et des frameworks d'analyse qui ont été affinés sur des décennies. L'outillage TPU existe, mais il est substantiellement en retard en sophistication.¹⁹³
XProf fournit un profilage basique via l'intégration TensorBoard mais manque l'accès granulaire aux compteurs matériels que les outils NVIDIA exposent. Comprendre les taux de défaut de cache, l'occupation, la divergence de warp, ou les conflits de banques mémoire—toutes métriques d'optimisation GPU critiques—n'a pas d'équivalent TPU car l'architecture diffère fondamentalement.¹⁹⁴
Les messages d'erreur obscurcissent souvent les causes racines. Les échecs de compilation XLA produisent des messages cryptiques sur les incompatibilités de forme ou les opérations non supportées, sans guidance claire sur la résolution. Les erreurs CUDA, bien qu'infâmes pour leur inutilité, bénéficient de quinze ans d'explications StackOverflow et de connaissances tribales.¹⁹⁵
Déboguer l'entraînement distribué sur des pods multi-chip approche l'impossibilité sans outils spécialisés. Les conditions de course, bugs de synchronisation de gradient, et échecs d'opérations collectives se manifestent comme des erreurs non-déterministes (ironiquement, malgré les avantages de déterminisme du TPU) qui se reproduisent de manière inconsistante et résistent au diagnostic systématique.¹⁹⁶
La boucle d'itération s'étend douloureusement pour les modèles complexes. La recompilation pour les changements de forme ou modifications d'architecture peut nécessiter des minutes, figeant le développement pendant que le compilateur turbine. Le modèle d'exécution eager de CUDA permet une itération plus rapide malgré des performances de crête inférieures.¹⁹⁷
Déploiements en Conditions Réelles : Production à Grande Échelle
Anthropic Claude : Stratégie Multi-Plateforme
L'annonce d'Anthropic en octobre 2025 concernant le déploiement de plus d'un million de puces TPU représente le plus grand engagement d'accélérateurs IA divulgué publiquement de l'histoire.¹⁹⁸ L'entreprise prévoit d'accéder à bien plus d'un gigawatt de capacité de calcul qui sera mise en ligne en 2026 exclusivement pour l'entraînement et le service des futurs modèles Claude.
L'échelle éclipse les déploiements précédents par plusieurs ordres de grandeur. Un million de puces, configurées en TPU Ironwood, fournirait environ 4,6 exaflops de calcul FP8—plus de 40× la performance totale de l'ensemble de la liste Top500 des supercalculateurs d'il y a seulement cinq ans.¹⁹⁹ Cet engagement signale la confiance dans l'architecture TPU pour le développement de modèles de pointe à des échelles précédemment considérées comme de la science-fiction.
Anthropic poursuit une stratégie matérielle multi-plateforme délibérée à travers les TPU de Google, les Trainium d'Amazon, et les GPU NVIDIA.²⁰⁰ La diversification fournit une assurance de capacité, un effet de levier sur les prix, et une distribution géographique. Claude sert globalement depuis des déploiements sur les trois plateformes, avec un routage des requêtes basé sur la disponibilité de capacité et les exigences de latence régionales.
Le rapport technique post-mortem de l'entreprise d'août 2025 a révélé les complexités de déploiement à grande échelle. Une erreur de configuration sur les serveurs TPU de l'API Claude a causé des erreurs de génération de tokens, attribuant parfois des probabilités anormalement élevées aux caractères thaïlandais ou chinois dans les prompts anglais.²⁰¹ L'incident a démontré que même les erreurs simples se propagent de manière imprévisible à travers les systèmes traitant des milliards de tokens quotidiennement.
Un déploiement séparé a déclenché un bug latent dans le compilateur XLA: TPU affectant Claude Haiku 3.5. Le bug avait existé non détecté pendant des mois jusqu'à ce qu'une combinaison spécifique d'architecture de modèle et de drapeaux de compilateur expose le défaut.²⁰² La découverte souligne que le déploiement en production trouve des cas limites absents des environnements de développement et de staging.
Les ingénieurs d'Anthropic ont cité le rapport prix-performance et l'efficacité des TPU comme critères de sélection principaux. L'économie convaincante accélère le développement en permettant des expériences plus importantes avec des budgets fixes.²⁰³ L'entraînement de modèles plus grands, l'exploration de plus de configurations d'hyperparamètres, et l'itération plus rapide découlent tous de la réduction des coûts par FLOP.
Google Gemini : Conçu pour TPU Dès l'Origine
Les modèles Gemini de Google s'entraînent et servent exclusivement sur TPU, avec une architecture et des procédures d'entraînement co-conçues pour les caractéristiques TPU dès le début.²⁰⁴ Le couplage étroit permet d'exploiter les optimisations spécifiques TPU que les modèles multi-plateformes ne peuvent pas tirer parti.
Le déploiement de Gemini utilise prétendument 50 000 puces TPU v6e pour l'entraînement et le service des variantes de modèles les plus importantes.²⁰⁵ Les énormes pods à cette échelle requièrent une orchestration sophistiquée—planification de tâches à travers des milliers de puces, coordination de points de contrôle pour prévenir les goulots d'étranglement, récupération d'échec pour minimiser le travail perdu, et surveillance en temps réel pour identifier les nœuds dégradés avant que les échecs se propagent.
Google a entraîné Gemini 2.0 sur des TPU Trillium, validant l'architecture de sixième génération pour le développement de modèles de pointe.²⁰⁶ L'exécution d'entraînement a démontré l'efficacité de mise à l'échelle à des nombres de puces sans précédent, atteignant une mise à l'échelle forte au-delà des plateaux typiques où la surcharge de communication domine.
L'infrastructure de service de modèles tire spécifiquement parti des optimisations d'inférence TPU. Le traitement par lots agrège plusieurs requêtes utilisateur pour maximiser l'utilisation MXU. La gestion du cache clé-valeur tire parti de la capacité HBM, permettant le traitement de contexte de longue durée sans échange disque. L'architecture livre des temps de réponse sous la seconde pour des requêtes complexes tout en gérant un volume de requêtes global massif.²⁰⁷
Les systèmes de surveillance de production suivent continuellement 50 000+ TPU, détectant les anomalies qui pourraient dégrader la qualité du modèle ou la disponibilité.²⁰⁸ La télémétrie capture les taux d'erreur, les percentiles de latence, le débit, la pression mémoire, et les caractéristiques thermiques à travers chaque puce. Les modèles d'apprentissage automatique analysent les flux de télémétrie eux-mêmes, prédisant les échecs avant qu'ils se produisent et déclenchant une maintenance préventive.
Déploiements de Production Supplémentaires
Midjourney a migré d'une infrastructure GPU vers TPU, atteignant une réduction de coût de 65% et une amélioration de latence de 40% pour les charges de travail de génération d'images.²⁰⁹ Le service de génération artistique traite 300 000 images par minute au pic de charge, nécessitant un débit de calcul massif et des performances cohérentes sous des modèles de trafic en rafales.
Les modèles de langage de Cohere sur TPU ont atteint 3× le débit des déploiements GPU précédents.²¹⁰ L'accélération a permis de servir plus de clients depuis la même empreinte d'infrastructure, améliorant directement l'économie commerciale. L'entreprise a tiré parti des capacités SPMD de JAX pour paralléliser efficacement les modèles à travers les pods TPU.
Snap a sécurisé la capacité pour 10 000 puces TPU v6e supportant les fonctionnalités de réalité augmentée, les systèmes de recommandation, et les outils d'IA créative.²¹¹ Le déploiement s'étend sur plusieurs régions géographiques, assurant une faible latence pour la base d'utilisateurs globale de Snapchat tout en maintenant la cohérence du modèle à travers les régions.
Les institutions académiques adoptent de plus en plus les TPU pour la recherche. Le programme TPU Research Cloud (TRC) fournit un accès TPU gratuit aux chercheurs, permettant des expériences à des échelles précédemment accessibles seulement aux laboratoires corporatifs bien financés.²¹² La démocratisation accélère le progrès scientifique en supprimant les barrières matérielles pour les académiques enquêtant sur les questions fondamentales concernant les capacités et limitations de l'IA.
Débogage, Profilage et Optimisation des Performances
XProf et Intégration TensorBoard
XProf constitue l'outil de profilage principal pour les charges de travail TPU, fournissant une analyse des performances pour les programmes JAX, PyTorch/XLA et TensorFlow sur CPU, GPU et TPU.²¹³ L'outil s'intègre avec TensorBoard pour la visualisation, présentant les données de profilage à travers des interfaces familières que les ingénieurs ML comprennent déjà.
L'installation nécessite le plugin TensorBoard : pip install tensorboard_plugin_profile tensorboard. Ceci active la chaîne d'outils complète.²¹⁴ Exécuter le profilage sur les VM TPU implique de capturer des traces pendant l'entraînement ou l'inférence, de télécharger les résultats vers TensorBoard, et d'analyser la visualisation pour identifier les goulots d'étranglement.
La Page Vue d'ensemble fournit des métriques de synthèse de performance de haut niveau, incluant la décomposition du temps par étape, l'utilisation des dispositifs, et l'identification des goulots d'étranglement principaux.²¹⁵ La page met immédiatement en évidence si les charges de travail sont limitées par le calcul (MXU fonctionnant en continu), limitées par la mémoire (en attente de transferts HBM), ou limitées par la communication (bloquées sur les opérations collectives).
Visualiseur de Traces et Analyse de Chronologie
Le Visualiseur de Traces affiche des visualisations détaillées de chronologie montrant exactement quand les opérations s'exécutent, quand les transferts de données se produisent, et où le temps d'inactivité s'accumule.²¹⁶ L'interface basée sur Chrome permet de zoomer à la résolution microseconde, révélant un comportement de planification précis que les métriques agrégées obscurcissent.
Comprendre la trace nécessite de reconnaître des motifs courants. De longs intervalles entre les opérations indiquent une surcharge de compilation, des goulots d'étranglement de chargement de données, ou une surcharge Python due à des pipelines de données mal optimisés. Des opérations petites répétées suggèrent une fusion insuffisante. Les opérations collectives s'étendant sur des millisecondes pointent vers des inefficacités de communication ou de mauvaises stratégies de sharding.²¹⁷
Le codage couleur distingue les types d'opérations : vert pour le calcul, bleu pour les transferts mémoire, orange pour la communication, et rouge pour le temps d'inactivité. Les charges de travail optimisées montrent des blocs colorés densément compactés avec des intervalles rouges minimaux. Le code mal optimisé présente des chronologies éparses avec de longs étirements rouges indiquant des ressources gaspillées.²¹⁸
L'utilisation avancée implique de corréler le comportement de la chronologie avec le code source. PyTorch/XLA supporte des annotations utilisateur insérées dans le code qui apparaissent dans les traces, permettant de mapper le comportement des performances à des composants spécifiques du modèle.²¹⁹ Les annotations transforment des traces opaques en insights actionnables sur quelles couches ou opérations nécessitent un focus d'optimisation.
Outil de Profil Mémoire et Débogage OOM
Les erreurs de mémoire insuffisante (OOM) affligent le développement de modèles volumineux. L'Outil de Profil Mémoire surveille l'utilisation de la mémoire du dispositif pendant l'exécution, capturant l'utilisation de pointe et les motifs d'allocation qui mènent aux échecs OOM.²²⁰
L'outil visualise la consommation mémoire dans le temps, montrant quels tenseurs consomment le plus de capacité et quand l'utilisation de pointe se produit. La visualisation révèle souvent des allocations surprenantes—des tampons de gradient plus grands que prévu, de la mémoire d'activation qui devrait être checkpointée, ou des tenseurs temporaires que XLA a échoué à éliminer.²²¹
La stratégie de débogage implique de réduire itérativement l'empreinte mémoire à travers plusieurs techniques. Le checkpointing de gradient recalcule les activations pendant les passes arrière plutôt que de les stocker. Le sharding de l'état de l'optimiseur distribue la momentum et la variance d'Adam entre les dispositifs. La précision mixte réduit la mémoire de 2× comparé à FP32. Le microbatching traite des lots plus petits séquentiellement plutôt qu'un grand lot.²²²
L'optimisation mémoire avancée nécessite de comprendre les décisions du compilateur. Le flag xla_dump_to exporte des représentations intermédiaires montrant comment XLA a transformé le graphe de calcul. Analyser l'IR révèle si la fusion a réussi, où des copies inutiles se produisent, et quelles opérations allouent plus de mémoire que prévu.²²³
Analyseur de Pipeline d'Entrée
Le préprocessing CPU goulote fréquemment l'entraînement TPU. L'Analyseur de Pipeline d'Entrée identifie si le chargement de données suit le rythme de la consommation de l'accélérateur ou si les TPU restent inactifs en attendant les lots.²²⁴
L'outil sépare l'analyse côté hôte (préprocessing CPU, augmentation de données, assemblage de lots) de l'exécution côté dispositif (calcul TPU réel). Les charges de travail limitées par l'entrée montrent l'utilisation du dispositif chutant pendant le chargement de données tandis que l'utilisation CPU atteint un pic. Les charges de travail limitées par le calcul maintiennent une utilisation élevée du dispositif avec le CPU suivant confortablement le rythme.²²⁵
Les stratégies d'optimisation dépendent de l'emplacement du goulot d'étranglement. Un préprocessing hôte lent bénéficie de la parallélisation du chargement de données sur plus de cœurs CPU, de la réduction de la complexité d'augmentation par échantillon, ou du préchargement des lots avant la consommation. Les goulots d'étranglement côté dispositif nécessitent des changements à l'architecture du modèle, une meilleure fusion, ou des ajustements de sharding plutôt qu'un réglage du pipeline de données.²²⁶
L'Avenir des Tensor Processing Units
L'évolution architecturale sur sept générations de Google démontre une innovation continue dans les accélérateurs IA spécialisés. Le support FP8 d'Ironwood, sa capacité mémoire massive et la mise à l'échelle des superpods de 9 216 puces suggèrent des trajectoires pour le développement futur.²²⁷
La réduction de précision continuera probablement vers FP4 ou encore plus bas pour des opérations spécifiques. Les recherches émergentes démontrent que de nombreuses opérations de réseaux de neurones tolèrent une quantification extrême avec des procédures d'entraînement soigneuses. Les futurs TPU pourraient implémenter des systèmes de précision mixte avec des passes avant FP4, des passes arrière FP8, et des mises à jour d'optimiseur FP32.²²⁸
La capacité mémoire rivalise avec la croissance de la taille des modèles. Les modèles de pointe actuels sollicitent déjà la mémoire des accélérateurs, nécessitant des stratégies de parallélisme sophistiquées. Les TPU de nouvelle génération pourraient intégrer des technologies de mémoire non-volatile comme 3D XPoint ou RAM résistive, permettant une mémoire sur package à l'échelle du téraoctet sans la consommation énergétique de la DRAM.²²⁹
Les interconnexions optiques pourraient s'étendre au-delà de la commutation de circuits pour inclure des éléments de calcul optique. La recherche explore la multiplication matricielle photonique exécutée à la vitesse de la lumière avec une puissance minimale, augmentant potentiellement les réseaux systoliques électroniques avec des co-processeurs optiques pour des opérations spécifiques.²³⁰
Le support de la sparsité s'étendra probablement au-delà des embeddings vers l'algèbre linéaire sparse générale. Les techniques d'élagage de réseaux de neurones démontrent que 90%+ des poids peuvent être mis à zéro sans perte de qualité. Les architectures futures pourraient nativement ignorer les calculs à valeur nulle plutôt que de les calculer explicitement puis les rejeter.²³¹
Les principes architecturaux sous-jacents au succès des TPU—spécialisation de domaine, interconnexion personnalisée, piles logicielles co-conçues, et orchestration à l'échelle du bâtiment—pointent vers un avenir d'accélérateurs de plus en plus spécialisés. Plutôt que des processeurs universels, nous pourrions voir des accélérateurs optimisés pour l'entraînement versus l'inférence, les réseaux convolutionnels versus les transformers, les modèles denses versus sparse, et les séquences courtes versus longues.²³²
Les ingénieurs construisant l'infrastructure IA aujourd'hui devraient comprendre profondément l'architecture TPU. Qu'ils déploient sur Google Cloud, concurrencent Google sur le marché des accélérateurs, ou conçoivent des systèmes ML de nouvelle génération, les principes de conception et les compromis incarnés dans les TPU révèlent des vérités fondamentales sur ce que les charges de travail IA exigent du matériel. Les mathématiques de réseau systolique, la conception de hiérarchie mémoire, la topologie d'interconnexion, et les stratégies d'optimisation de compilateur représentent des décennies de sagesse accumulée applicable bien au-delà du TPU lui-même.
La tension entre spécialisation et généralité qui définit TPU versus GPU persistera indéfiniment. Les TPU sacrifient la flexibilité pour une efficacité extrême sur des charges de travail étroites. Les GPU sacrifient l'efficacité de pointe pour une applicabilité plus large. Aucune approche ne domine—le choix optimal dépend entièrement des caractéristiques de la charge de travail, de l'échelle, des contraintes de coût, et des exigences opérationnelles. Les organisations réussissant avec l'IA à grande échelle adoptent de plus en plus des stratégies hétérogènes, adaptant les architectures d'accélérateurs aux demandes des charges de travail plutôt que de standardiser sur une plateforme unique.
L'engagement d'Anthropic d'un million de puces vers les TPU démontre que l'architecture a atteint la maturité de production aux plus hautes échelles. Les déploiements multi-gigawatt qui vont en ligne en 2026 entraîneront des modèles repoussant les limites de ce que l'IA peut accomplir, et l'infrastructure permettant ces modèles incarne une sophistication d'ingénierie que peu d'organisations ont égalée. Comprendre comment 65 536 unités de multiplication-accumulation dans un réseau systolique collaborent pour entraîner des modèles de pointe importe pour quiconque est sérieux au sujet de l'avenir de l'IA.
Références
-
Google Cloud Press Corner, "Anthropic to Expand Use of Google Cloud TPUs and Services," 23 octobre 2025, https://www.googlecloudpresscorner.com/2025-10-23-Anthropic-to-Expand-Use-of-Google-Cloud-TPUs-and-Services.
-
TrendForce, "Google Unveils 7th-Gen TPU Ironwood with 9,216-Chip Superpod, Taking Aim at NVIDIA," 7 novembre 2025, https://www.trendforce.com/news/2025/11/07/news-google-unveils-7th-gen-tpu-ironwood-with-9216-chip-superpod-taking-aim-at-nvidia/.
-
Norman P. Jouppi et al., "TPU v4: An Optically Reconfigurable Supercomputer for Machine Learning with Hardware Support for Embeddings," dans Proceedings of the 50th Annual International Symposium on Computer Architecture (2023), arXiv:2304.01433.
-
Anthropic, "Expanding our use of Google Cloud TPUs and Services," Anthropic News, octobre 2025, https://www.anthropic.com/news/expanding-our-use-of-google-cloud-tpus-and-services.
-
Google Cloud Blog, "Quantifying the performance of the TPU, our first machine learning chip," avril 2017, https://cloud.google.com/blog/products/gcp/quantifying-the-performance-of-the-tpu-our-first-machine-learning-chip.
-
Norman P. Jouppi et al., "In-Datacenter Performance Analysis of a Tensor Processing Unit," Proceedings of the 44th Annual International Symposium on Computer Architecture (2017), arXiv:1704.04760.
-
Jouppi et al., "In-Datacenter Performance Analysis."
-
Jouppi et al., "In-Datacenter Performance Analysis."
-
Jonathan Hui, "AI Chips: Google TPU," Medium, consulté en décembre 2025, https://jonathan-hui.medium.com/ai-chips-tpu-3fa0b2451a2d.
-
Wikipedia, "Bfloat16 floating-point format," consulté en décembre 2025, https://en.wikipedia.org/wiki/Bfloat16_floating-point_format.
-
Henry Ko, "TPU Deep Dive," blog personnel, consulté en décembre 2025, https://henryhmko.github.io/posts/tpu/tpu.html.
-
Wikipedia, "Tensor Processing Unit," consulté en décembre 2025, https://en.wikipedia.org/wiki/Tensor_Processing_Unit.
-
Wikipedia, "Tensor Processing Unit."
-
Wikipedia, "Tensor Processing Unit."
-
Ko, "TPU Deep Dive."
-
Jouppi et al., "TPU v4: An Optically Reconfigurable Supercomputer."
-
Jouppi et al., "TPU v4: An Optically Reconfigurable Supercomputer."
-
Jouppi et al., "TPU v4: An Optically Reconfigurable Supercomputer."
-
Jouppi et al., "TPU v4: An Optically Reconfigurable Supercomputer."
-
OpenXLA Project, "A deep dive into SparseCore for Large Embedding Models (LEM)," consulté en décembre 2025, https://openxla.org/xla/sparsecore.
-
JAX Scaling Guide, "How to Think About TPUs," consulté en décembre 2025, https://jax-ml.github.io/scaling-book/tpus/.
-
JAX Scaling Guide, "How to Think About TPUs."
-
Ko, "TPU Deep Dive."
-
JAX Scaling Guide, "How to Think About TPUs."
-
Google Cloud Blog, "Introducing Trillium, sixth-generation TPUs," mai 2024, https://cloud.google.com/blog/products/compute/introducing-trillium-6th-gen-tpus.
-
Google Cloud Blog, "Introducing Trillium."
-
Google Cloud Blog, "Introducing Trillium."
-
Google Cloud Blog, "Introducing Trillium."
-
Google Cloud Blog, "Introducing Trillium."
-
Google Blog, "Ironwood: The first Google TPU for the age of inference," novembre 2025, https://blog.google/products/google-cloud/ironwood-tpu-age-of-inference/.
-
XPU.pub, "Google Adds FP8 to Ironwood TPU; Can It Beat Blackwell?" 16 avril 2025, https://xpu.pub/2025/04/16/google-ironwood/.
-
TrendForce, "Google Unveils 7th-Gen TPU Ironwood."
-
The Register, "Google's 7th-gen Ironwood TPUs promise 42 AI exaFLOPS pods," 10 avril 2025, https://www.theregister.com/2025/04/10/googles_7thgen_ironwood_tpus_debut/.
-
TrendForce, "Google Unveils 7th-Gen TPU Ironwood."
-
Ko, "TPU Deep Dive."
-
XPU.pub, "Google Adds FP8 to Ironwood TPU."
-
Google Cloud Press Corner, "Anthropic to Expand Use."
-
Telesens, "Understanding Matrix Multiplication on a Weight-Stationary Systolic Architecture," 30 juillet 2018, https://telesens.co/2018/07/30/systolic-architectures/.
-
Telesens, "Understanding Matrix Multiplication."
-
Jouppi et al., "In-Datacenter Performance Analysis."
-
Telesens, "Understanding Matrix Multiplication."
-
CP Lu, "Should We All Embrace Systolic Arrays?" Medium, consulté en décembre 2025, https://cplu.medium.com/should-we-all-embrace-systolic-array-df3830f193dc.
-
Google Cloud Documentation, "TPU architecture," consulté en décembre 2025, https://docs.cloud.google.com/tpu/docs/system-architecture-tpu-vm.
-
Google Cloud Documentation, "TPU architecture."
-
Hui, "AI Chips: Google TPU."
-
Telnyx, "Architecture insights: MXU and TPU components," consulté en décembre 2025, https://telnyx.com/learn-ai/mxu-tpu.
-
Ko, "TPU Deep Dive."
-
Jouppi et al., "TPU v4: An Optically Reconfigurable Supercomputer."
-
SemiEngineering, "Tensor Processing Unit (TPU)," consulté en décembre 2025, https://semiengineering.com/knowledge_centers/integrated-circuit/ic-types/processors/tensor-processing-unit-tpu/.
-
TrendForce, "Google Unveils 7th-Gen TPU Ironwood."
-
SemiEngineering, "Tensor Processing Unit (TPU)."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Google Cloud Documentation, "Cloud TPU performance guide," consulté en décembre 2025, https://cloud.google.com/tpu/docs/performance-guide.
-
OpenXLA Project, "A deep dive into SparseCore."
-
OpenXLA Project, "A deep dive into SparseCore."
-
OpenXLA Project, "A deep dive into SparseCore."
-
Jouppi et al., "TPU v4: An Optically Reconfigurable Supercomputer."
-
OpenXLA Project, "A deep dive into SparseCore."
-
Jouppi et al., "TPU v4: An Optically Reconfigurable Supercomputer."
-
OpenXLA Project, "A deep dive into SparseCore."
-
JAX Scaling Guide, "How to Think About TPUs."
-
JAX Scaling Guide, "How to Think About TPUs."
-
JAX Scaling Guide, "How to Think About TPUs."
-
Ko, "TPU Deep Dive."
-
JAX Scaling Guide, "How to Think About TPUs."
-
JAX Scaling Guide, "How to Think About TPUs."
-
TrendForce, "Google Unveils 7th-Gen TPU Ironwood."
-
Ko, "TPU Deep Dive."
-
Anthropic, "Expanding our use of Google Cloud TPUs."
-
Jouppi et al., "TPU v4: An Optically Reconfigurable Supercomputer."
-
Jouppi et al., "TPU v4: An Optically Reconfigurable Supercomputer."
-
Jouppi et al., "TPU v4: An Optically Reconfigurable Supercomputer."
-
Jouppi et al., "TPU v4: An Optically Reconfigurable Supercomputer."
-
Ko, "TPU Deep Dive."
-
Jouppi et al., "TPU v4: An Optically Reconfigurable Supercomputer."
-
Leon Poutievski, "Mission Apollo: Landing Optical Circuit Switching at Datacenter Scale," LinkedIn, juin 2022, https://www.linkedin.com/posts/leon-poutievski-8910a851_mission-apollo-landing-optical-circuit-switching-activity-6968472071534235649-cB4l.
-
Ko, "TPU Deep Dive."
-
Jouppi et al., "TPU v4: An Optically Reconfigurable Supercomputer."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Jouppi et al., "TPU v4: An Optically Reconfigurable Supercomputer."
-
JAX Scaling Guide, "How to Think About TPUs."
-
TrendForce, "Google Unveils 7th-Gen TPU Ironwood."
-
TrendForce, "Google Unveils 7th-Gen TPU Ironwood."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
OpenXLA Project, "XLA: Optimizing Compiler for Machine Learning," consulté en décembre 2025, https://openxla.org/xla.
-
Daniel Snider et Ruofan Liang, "Operator Fusion in XLA: Analysis and Evaluation," article académique, consulté en décembre 2025, https://danielsnider.ca/papers/Operator_Fusion_in_XLA_Analysis_and_Evaluation.pdf.
-
Snider et Liang, "Operator Fusion in XLA."
-
APXML, "Memory-Aware Data Layout Transformations (NCHW/NHWC)," consulté en décembre 2025, https://apxml.com/courses/compiler-runtime-optimization-ml/chapter-3-advanced-graph-level-optimizations/memory-aware-layout-transformations.
-
OpenXLA Project, "XLA."
-
PyTorch Documentation, "Pytorch/XLA Overview," consulté en décembre 2025, https://docs.pytorch.org/xla/master/learn/xla-overview.html.
-
OpenXLA Project, "A deep dive into SparseCore."
-
Mangpo Phothilimthana et al., "A Flexible Approach to Autotuning Multi-Pass Machine Learning Compilers," PACT 2021, consulté en décembre 2025, https://mangpo.net/papers/xla-autotuning-pact2021.pdf.
-
JAX Documentation, "Introduction to parallel programming," consulté en décembre 2025, https://docs.jax.dev/en/latest/sharded-computation.html.
-
GitHub, "jax-ml/jax: Composable transformations of Python+NumPy programs," consulté en décembre 2025, https://github.com/jax-ml/jax.
-
OpenXLA Project, "Shardy Guide for JAX Users," consulté en décembre 2025, https://openxla.org/shardy/getting_started_jax.
-
JAX Documentation, "Introduction to parallel programming."
-
OpenXLA Project, "Shardy Guide for JAX Users."
-
OpenXLA Project, "Shardy Guide for JAX Users."
-
JAX Documentation, "Introduction to parallel programming."
-
OpenXLA Project, "Shardy Guide for JAX Users."
-
PyTorch Documentation, "Pytorch/XLA Overview."
-
GitHub, "RFC: Evolving PyTorch/XLA for a more native experience on TPU," Issue #9684, consulté en décembre 2025, https://github.com/pytorch/xla/issues/9684.
-
Google Cloud Blog, "PyTorch/XLA 2.4 improves Pallas and adds 'eager mode,'" consulté en décembre 2025, https://cloud.google.com/blog/products/ai-machine-learning/pytorch-xla-2-4-improves-pallas-and-adds-eager-mode/.
-
PyTorch Documentation, "Pytorch/XLA Overview."
-
PyTorch Documentation, "Custom Kernels via Pallas," consulté en décembre 2025, https://docs.pytorch.org/xla/master/features/pallas.html.
-
PyTorch Documentation, "Custom Kernels via Pallas."
-
PyTorch Documentation, "Custom Kernels via Pallas."
-
vLLM Blog, "vLLM TPU: A New Unified Backend Supporting PyTorch and JAX on TPU," 16 octobre 2025, https://blog.vllm.ai/2025/10/16/vllm-tpu.html.
-
GitHub, "pytorch/xla," consulté en décembre 2025, https://github.com/pytorch/xla.
-
StackGpu, "FP8, BF16, and INT8: How Low-Precision Formats Are Revolutionizing Deep Learning Throughput," Medium, consulté en décembre 2025, https://medium.com/@StackGpu/fp8-bf16-and-int8-how-low-precision-formats-are-revolutionizing-deep-learning-throughput-e6c1f3adabc2.
-
Wikipedia, "Bfloat16 floating-point format."
-
Wikipedia, "Bfloat16 floating-point format."
-
Paulius Micikevicius et al., "FP8 Formats for Deep Learning," arXiv:2209.05433, septembre 2022.
-
XPU.pub, "Google Adds FP8 to Ironwood TPU."
-
Micikevicius et al., "FP8 Formats for Deep Learning."
-
Google Cloud Blog, "Accurate Quantized Training (AQT) for TPU v5e," consulté en décembre 2025, https://cloud.google.com/blog/products/compute/accurate-quantized-training-aqt-for-tpu-v5e.
-
StackGpu, "FP8, BF16, and INT8."
-
Jeffrey Tse, "Understanding the FP64, FP32, FP16, BFLOAT16, TF32, FP8 Formats," blog personnel, 9 décembre 2024, https://jeffreytse.net/computer/2024/12/09/understanding-the-fp64-fp32-fp16-bfloat16-tf32-fp8-formats.html.
-
PyTorch Blog, "PyTorch/XLA SPMD: Scale Up Model Training and Serving with Automatic Parallelization," consulté en décembre 2025, https://pytorch.org/blog/pytorch-xla-spmd/.
-
OpenXLA Project, "Shardy Guide for JAX Users."
-
JAX Documentation, "Introduction to parallel programming."
-
OpenXLA Project, "Shardy Guide for JAX Users."
-
Ko, "TPU Deep Dive."
-
JAX Documentation, "Introduction to parallel programming."
-
Anthropic, "Expanding our use of Google Cloud TPUs."
-
JAX Documentation, "Introduction to parallel programming."
-
JAX Documentation, "Introduction to parallel programming."
-
Adam Roberts et al., "Scaling Up Models and Data with t5x and seqio," arXiv:2203.17189, mars 2022.
-
Roberts et al., "Scaling Up Models and Data."
-
JAX Documentation, "Introduction to parallel programming."
-
JAX Documentation, "Introduction to parallel programming."
-
OpenXLA Project, "Shardy Guide for JAX Users."
-
Roberts et al., "Scaling Up Models and Data."
-
Roberts et al., "Scaling Up Models and Data."
-
Ko, "TPU Deep Dive."
-
MLCommons, "Benchmark MLPerf Training," consulté en décembre 2025, https://mlcommons.org/benchmarks/training/.
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
HPCwire, "MLPerf Training v5.0 Benchmark Results Reflect Rapid Growth in the Field of AI," juin 2025, https://www.hpcwire.com/off-the-wire/mlperf-training-v5-0-benchmark-results-reflect-rapid-growth-in-the-field-of-ai/.
-
MLCommons, "MLCommons Releases New MLPerf Inference v5.0 Benchmark Results," avril 2025, https://mlcommons.org/2025/04/mlperf-inference-v5-0-results/.
-
Ko, "TPU Deep Dive."
-
Google Cloud Blog, "TPU v4 enables performance, energy and CO2e efficiency gains," consulté en décembre 2025, https://cloud.google.com/blog/topics/systems/tpu-v4-enables-performance-energy-and-co2e-efficiency-gains.
-
TrendForce, "Google Unveils 7th-Gen TPU Ironwood."
-
Google Cloud Blog, "Quantifying the performance of the TPU."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Artech Digital, "Energy-Efficient GPU vs. TPU Allocation," consulté en décembre 2025, https://www.artech-digital.com/blog/energy-efficient-gpu-vs-tpu-allocation.
-
Wikipedia, "Tensor Processing Unit."
-
XPU.pub, "Google Adds FP8 to Ironwood TPU."
-
Ko, "TPU Deep Dive."
-
Google Cloud Blog, "TPU v4 enables performance, energy and CO2e efficiency gains."
-
ByteBridge, "GPU and TPU Comparative Analysis Report," Medium, consulté en décembre 2025, https://bytebridge.medium.com/gpu-and-tpu-comparative-analysis-report-a5268e4f0d2a.
-
ByteBridge, "GPU and TPU Comparative Analysis Report."
-
Anthropic, "Expanding our use of Google Cloud TPUs."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
DataCamp, "Understanding TPUs vs GPUs in AI: A Comprehensive Guide," consulté en décembre 2025, https://www.datacamp.com/blog/tpu-vs-gpu-ai.
-
Ko, "TPU Deep Dive."
-
DataCamp, "Understanding TPUs vs GPUs in AI."
-
Grigory Sapunov, "FP64, FP32, FP16, BFLOAT16, TF32, and other members of the ZOO," Medium, consulté en décembre 2025, https://moocaholic.medium.com/fp64-fp32-fp16-bfloat16-tf32-and-other-members-of-the-zoo-a1ca7897d407.
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Snider et Liang, "Operator Fusion in XLA."
-
APXML, "Memory-Aware Data Layout Transformations."
-
Google Cloud Blog, "How Lightricks trains video diffusion models at scale with JAX on TPU," consulté en décembre 2025, https://cloud.google.com/blog/products/media-entertainment/how-lightricks-trains-video-diffusion-models-at-scale-with-jax-on-tpu.
-
CloudOptimo, "TPU vs GPU: What's the Difference in 2025?" consulté en décembre 2025, https://www.cloudoptimo.com/blog/tpu-vs-gpu-what-is-the-difference-in-2025/.
-
Phoenix NAP, "TPU vs. GPU: Differences Explained," consulté en décembre 2025, https://phoenixnap.com/kb/tpu-vs-gpu.
-
CloudOptimo, "TPU vs GPU."
-
DataCamp, "Understanding TPUs vs GPUs in AI."
-
Tailscale, "TPU vs GPU: Which Is Better for AI Infrastructure in 2025?" consulté en décembre 2025, https://tailscale.com/learn/what-is-tpu-vs-gpu.
-
DataCamp, "Understanding TPUs vs GPUs in AI."
-
DataCamp, "Understanding TPUs vs GPUs in AI."
-
PyTorch Documentation, "Custom Kernels via Pallas."
-
Phoenix NAP, "TPU vs. GPU: Differences Explained."
-
Ko, "TPU Deep Dive."
-
OpenMetal, "TPU vs GPU: Pros and Cons," consulté en décembre 2025, https://openmetal.io/docs/product-guides/private-cloud/tpu-vs-gpu-pros-and-cons/.
-
OpenMetal, "TPU vs GPU: Pros and Cons."
-
Phoenix NAP, "TPU vs. GPU: Differences Explained."
-
PRIMO.ai, "Processing Units - CPU, GPU, APU, TPU, VPU, FPGA, QPU," consulté en décembre 2025, https://primo.ai/index.php?title=Processing_Units_-_CPU%2C_GPU%2C_APU%2C_TPU%2C_VPU%2C_FPGA%2C_QPU.
-
DataCamp, "Understanding TPUs vs GPUs in AI."
-
Google Cloud Documentation, "Profile your model on Cloud TPU VMs," consulté en décembre 2025, https://cloud.google.com/tpu/docs/cloud-tpu-tools.
-
DataCamp, "Understanding TPUs vs GPUs in AI."
-
Ko, "TPU Deep Dive."
-
GitHub, "RFC: Evolving PyTorch/XLA."
-
Google Cloud Press Corner, "Anthropic to Expand Use."
-
TrendForce, "Google Unveils 7th-Gen TPU Ironwood."
-
Maginative, "Anthropic Secures 1M Google TPUs While Keeping Amazon as Primary Training Partner," consulté en décembre 2025, https://www.maginative.com/article/anthropic-secures-1m-google-tpus-while-keeping-amazon-as-primary-training-partner/.
-
Anthropic, "A postmortem of three recent issues," Engineering Blog, août 2025, https://www.anthropic.com/engineering/a-postmortem-of-three-recent-issues.
-
Anthropic, "A postmortem of three recent issues."
-
AI Magazine, "Why Anthropic Uses Google Cloud TPUs for AI Infrastructure," consulté en décembre 2025, https://aimagazine.com/news/why-anthropic-uses-google-cloud-tpus-for-ai-infrastructure.
-
Google Cloud Blog, "Ironwood TPUs and new Axion-based VMs for your AI workloads," novembre 2025, https://cloud.google.com/blog/products/compute/ironwood-tpus-and-new-axion-based-vms-for-your-ai-workloads.
-
Ko, "TPU Deep Dive."
-
TrendForce, "Google Unveils 7th-Gen TPU Ironwood."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Google Cloud, "Tensor Processing Units (TPUs)," consulté en décembre 2025, https://cloud.google.com/tpu.
-
TensorFlow Documentation, "Optimize TensorFlow performance using the Profiler," consulté en décembre 2025, https://www.tensorflow.org/guide/profiler.
-
Google Cloud Documentation, "Profile your model on Cloud TPU VMs."
-
TensorFlow Documentation, "TensorFlow Profiler: Profile model performance," consulté en décembre 2025, https://www.tensorflow.org/tensorboard/tensorboard_profiling_keras.
-
Google Cloud Documentation, "Profile your model on Cloud TPU VMs."
-
Google Cloud Blog, "PyTorch/XLA: Performance debugging on Cloud TPU VM: Part III," consulté en décembre 2025, https://cloud.google.com/blog/topics/developers-practitioners/pytorchxla-performance-debugging-cloud-tpu-vm-part-iii.
-
Google Cloud Blog, "PyTorch/XLA: Performance debugging Part III."
-
Google Cloud Documentation, "Profile PyTorch XLA workloads," consulté en décembre 2025, https://docs.cloud.google.com/tpu/docs/pytorch-xla-performance-profiling-tpu-vm.
-
TensorFlow Documentation, "Optimize TensorFlow performance using the Profiler."
-
TensorFlow Documentation, "Optimize TensorFlow performance using the Profiler."
-
Ko, "TPU Deep Dive."
-
Google Cloud Documentation, "Cloud TPU performance guide."
-
TensorFlow Documentation, "Optimize TensorFlow performance using the Profiler."
-
TensorFlow Documentation, "Optimize TensorFlow performance using the Profiler."
-
TensorFlow Documentation, "Optimize TensorFlow performance using the Profiler."
-
TrendForce, "Google Unveils 7th-Gen TPU Ironwood."
-
Tse, "Understanding the FP64, FP32, FP16, BFLOAT16, TF32, FP8 Formats."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."


