
Googleの Tensor Processing Units は、あなたが日常的に操作する最先端AIモデルの大部分を支えているにも関わらず、ほとんどのエンジニアはそのアーキテクチャについて驚くほど馴染みがない。NVIDIA GPUが開発者の関心を独占している一方で、TPUは静かにGemini 2.0、Claude、その他数十の最前線モデルを、従来のGPUインフラを使用すれば多くの組織を破綻させるような規模でトレーニングし、サービス提供している。Anthropicは最近、将来のClaudeモデルをトレーニングするために100万チップ以上のTPU(1ギガワット以上のコンピュート容量に相当)の配備を約束した。¹ Googleの最新Ironwood世代は、9,216チップのスーパーポッドにわたって42.5エクサフロップスのFP8コンピュートを提供し、プロダクションAIインフラの意味を再定義する規模を実現している。²
TPUの背後にある技術的洗練さは、単純なパフォーマンス指標をはるかに超えている。これらのプロセッサは、GPUとは根本的に異なる設計哲学を体現し、汎用的な柔軟性を行列乗算とテンソル演算における極度の特化と引き換えにしている。TPUアーキテクチャを理解するエンジニアは、サイクルあたり65,536回の積和演算を処理する256×256シストリックアレイを活用し、埋め込み集約ワークロード向けの第3世代SpareCore アクセラレータを利用し、10ナノ秒未満でマルチペタビットデータセンタートポロジを再構成する光回路スイッチをプログラムできる。³ アーキテクチャはトランジスタレベルの設計決定から建物規模のスーパーコンピュータオーケストレーションまで、あらゆるものにわたっている。
これから述べる技術的内容は注意深い検討を要求する。我々は7世代にわたるTPUの進化を検証し、シストリックアレイの数学とデータフローパターンを解剖し、SRAMタイルからHBM3eチャネルまでのメモリ階層を探求し、中間表現レベルでのXLAコンパイラ最適化を分析し、なぜ集合演算が同等のEthernetベースGPUクラスタより10倍高速に実行されるのかを調査する。⁴ あなたはレジスタレベルの仕様、サイクル精度のパフォーマンスモデリング、そしてTPUをGPUより同時により強力かつより制約のあるものにするアーキテクチャトレードオフに遭遇するだろう。ここでの深さは、次世代AIインフラを構築するエンジニアと、現在のアクセラレータが達成可能な境界を押し広げる研究者に役立つ。
進化:7世代にわたるアーキテクチャイノベーション
TPU v1: 推論専用の特化(2015年)
Googleは2015年に初代Tensor Processing Unitを導入し、重要な問題に対処した:ニューラルネットワーク推論ワークロードが同社のデータセンター設置面積を倍増させる脅威となっていた。⁵ エンジニアは、デプロイされたモデルの性能と電力効率を最大化するため、学習機能を完全に削除してTPU v1を推論専用に設計した。このチップは256×256のシストリックアレイと8ビット整数の乗算累積ユニットを特徴とし、わずか28-40ワットの熱設計電力で92テラオペレーション/秒を実現した。⁶
アーキテクチャは根本的なミニマリズムを体現していた。単一のMatrix Multiply Unitが重み固定データフローを通じてINT8演算を処理し、重みはシストリックアレイに固定されたまま、活性化がグリッドを水平に流れる。部分和は垂直に伝播され、行列乗算全体の中間メモリ書き込みを排除した。PCIe経由でホストシステムに接続されたこのチップは、外部メモリにDDR3 DRAMを使用し、電力効率のために意図的に保守的な700MHzで動作した。⁷
性能向上はGoogleのエンジニアでさえも驚かせた。TPU v1は本番推論ワークロードにおいて、同世代のCPUやGPUと比較してワット当たり演算数で30倍から80倍の改善を達成した。⁸ このチップはGoogle検索ランキング、1日10億リクエストを処理する翻訳サービス、20億ユーザー向けのYouTubeレコメンデーションを処理した。この成功により、狭いワークロードに最適化された専用アクセラレータが汎用プロセッサに対して桁違いの改善を提供できるという核となるアーキテクチャの洞察が実証された。
TPU v2: 大規模学習の実現(2017年)
第2世代はTPUを推論専用アクセラレータから完全な学習プラットフォームに変革した。Googleは浮動小数点演算を中心にアーキテクチャ全体を再設計し、256×256のINT8アレイをコア当たりデュアル128×128のbfloat16乗算累積器に置き換えた。⁹ 各チップは2つのTensorCoreを含み、コア当たり8GBのHigh Bandwidth Memoryを共有した。これはDDR3からの大幅なアップグレードで、ニューラルネットワーク学習が要求する帯域幅を提供した。
bfloat16精度はTPU v2の成功に不可欠だった。この形式はFP32と同じ8ビット指数範囲を維持しながら、仮数を7ビットに削減し、メモリ帯域幅要件を半減させつつ学習の動的範囲を保持した。¹⁰ エンジニアは、削減された仮数精度が実際に正則化の一形態として作用し、多くのモデルで汎化を改善する一方で、完全なFP32指数範囲がFP16学習を悩ませていたアンダーフローとオーバーフローの問題を防いだことを観察した。
TPU v2を真に差別化したアーキテクチャイノベーションはInter-Chip Interconnect(ICI)だった。従来のアクセラレータはマルチチップ通信にEthernetやInfiniBandを必要とし、レイテンシと帯域幅のボトルネックが発生していた。Googleは各TPUを2Dトーラストポロジで4つの隣接チップに直接接続するカスタム高速双方向リンクを設計した。¹¹ この相互接続により、最大256チップのTPU v2「ポッド」が単一の論理アクセラレータとして機能し、all-reduceなどの集合演算がネットワークベースの代替案よりもはるかに高速に実行できるようになった。
TPU v3: 水冷式性能スケーリング(2018年)
GoogleはTPU v3でクロック速度とコア数を積極的に押し上げ、チップ当たり420テラフロップスを実現し、v2の性能を倍以上に向上させた。¹² 電力密度の増加により劇的なアーキテクチャ変更が必要となった:液体冷却である。各TPU v3ポッドは水冷インフラを必要とし、従来世代や大部分のデータセンターアクセラレータの空冷設計からの転換となった。¹³
チップはデュアル128×128 MXUアーキテクチャを維持したが、総コア数を増加させ、メモリ帯域幅を改善した。各TPU v3は2コアずつの4つのチップを含み、チップ全体で合計32GBのHBMメモリを共有した。¹⁴ ベクトル処理ユニットは、行列ユニットだけでは学習のボトルネックとなることの多い活性化関数、正規化演算、勾配計算の機能強化を受けた。
デプロイメントは、v2と同じ2DトーラスICIトポロジを使用して2,048チップポッドまでスケールしたが、リンクあたりの帯域幅が増加した。Googleはv3ポッドでますます大きなモデルを学習し、トーラストポロジの削減されたネットワーク直径(任意の2つのチップ間の最大距離がNではなくN/2にスケール)がデータ並列と模型並列の両学習戦略の通信オーバーヘッドを最小化することを発見した。¹⁵
TPU v4: 光回路交換のブレークスルー(2021年)
第4世代は初代TPU以来Googleの最も重要なアーキテクチャの飛躍を表した。エンジニアはポッドスケールを4,096チップまで増加させ、データセンタースケールのMLインフラを革新した電気通信から借用した技術である光回路交換(OCS)を相互接続に導入した。¹⁶
TPU v4のコアアーキテクチャは、TensorCore当たり4つの128×128 MXUと強化されたベクトルおよびスカラユニットを特徴とした。各TensorCoreペアは、コア別Vector Memoryに加えて128MBのCommon Memoryを共有し、より洗練されたデータステージングと再利用パターンを可能にした。¹⁷ チップトポロジは2Dから3Dトーラスに進化し、各TPUを4つではなく6つの隣接チップに接続し、ネットワーク直径をさらに削減し、バイセクション帯域幅を改善した。
光回路交換システムは大規模デプロイに関するすべてを変えた。TPU間の固定配線ではなく、Googleはどのチップがどれに接続するかを動的に再構成できるプログラマブル光スイッチを展開した。MEMS(微小電気機械システム)ミラーが物理的に光ビームを再方向付けして任意のTPUペアを接続し、光ファイバ伝送時間を超えて本質的にゼロレイテンシを導入した。¹⁸ スイッチは10ナノ秒未満のウィンドウで再構成し、ほとんどのネットワークプロトコルハンドシェイクより高速である。
OCSアーキテクチャは以前は不可能だった機能を可能にした。Googleは光スイッチを適切にプログラミングすることで、4チップから完全な4,096チップポッドまで、任意のサイズの「スライス」をプロビジョニングできた。故障したチップは、ラック全体をダウンさせることなくシームレスに迂回できた。最も注目すべきは、異なるデータセンター場所にある物理的に離れたTPUがネットワークトポロジで論理的に隣接可能で、物理的と論理的レイアウトを完全に分離できることだった。¹⁹
TPU v4はまた、レコメンデーションシステム、ランキングモデル、大規模語彙埋め込みを持つ大型言語モデルで日常的に使用される埋め込み演算を処理するための専用プロセッサSparseCore を導入した。SparseCoreはチップ当たり4つの専用プロセッサを特徴とし、それぞれ2.5MBのスクラッチパッドメモリとスパース メモリアクセスパターンに最適化されたデータフローを持った。²⁰ 超大型埋め込みを持つモデルは、総チップダイ面積と電力予算のわずか5%を使用して5-7倍の速度向上を達成した。
TPU v5pとv5e: 特化とスケール(2022-2023年)
Googleは第5世代を異なる使用事例をターゲットとする2つの異なる製品に分割した。TPU v5pは大規模学習の最大性能を優先し、v5eはコスト効率的な推論と小規模学習ジョブに最適化した。²¹
TPU v5pは8,960チップポッド全体で約4.45エクサフロップス/秒を達成し、v4の最大ポッドサイズを倍以上にした。²² 相互接続帯域幅はチップ当たり4,800Gbpsに到達し、3Dトーラストポロジが大規模な16×20×28スーパーポッドでチップを接続した。光回路交換ファブリックは、完全なv5pスーパーポッドを配線するために48のOCSユニット全体で13,824の光ポートを管理し、コンピューティング史上最大の本番光交換デプロイの一つを表した。²³
TPU v5eは異なるアプローチを取り、積極的な電力とコスト目標を達成するためにコア数とクロック速度を削減した。推論最適化チップは、2つではなくチップ当たり1つのTPUコアのみを含み、小さなポッドサイズに十分な2Dトーラストポロジに戻った。²⁴ アーキテクチャの簡素化により、絶対性能よりもドル当たり性能が重要なワークロードでGoogleがv5eを競争力のある価格で提供することが可能になった。
TPU v6e Trillium: 行列性能の4倍化(2024年)
TrilliumはMatrix Multiply Unitを128×128から256×256乗算累積器に拡張することで、別のアーキテクチャ変曲点を示した。²⁵ より大きなアレイは同じクロック速度でサイクル当たりFLOPsを4倍にし、拡張されたMXUと増加したクロック周波数の組み合わせを通じてTPU v5eの4.7倍のピーク計算性能を実現した。
メモリサブシステムは同様に劇的なアップグレードを受けた。HBM容量はチップ当たり32GBに倍増し、次世代HBMチャネルにより帯域幅が倍増した。²⁶ Interchip Interconnect帯域幅も同様に倍増し、256のTrilliumチップのポッドが計算と通信の両方にストレスをかけるモデルに対してより高いスループットを維持することを可能にした。²⁷
Trilliumは第3世代SparseCore アクセラレータを特徴とし、ランキングとレコメンデーションワークロードの超大型埋め込みに対する機能強化を持った。更新された設計はメモリアクセスパターンを改善し、行列乗算ではなく埋め込みルックアップが支配的なモデルのためのSparseCoreとHBM間の適切な帯域幅を増加させた。²⁸
大幅な性能向上にもかかわらず、エネルギー効率はv5eより67%改善した。²⁹ Googleは先進プロセスノード、無駄な作業を削減するアーキテクチャ最適化、チップの全部分に同時にストレスをかけない演算中の未使用ユニットの注意深い電力ゲーティングを通じて効率向上を達成した。
TPU v7 Ironwood: FP8時代(2025年)
コードネームIronwoodのGoogleの第7世代TPUは、ネイティブFP8サポートで設計され、最先端の学習性能を維持しながら「推論の時代」に特化して最適化された初のTPUを表す。³⁰ 各IronwoodチップはNVIDIAの競合するB200の4.5ペタフロップスをわずかに上回る4.6ペタフロップスの密FP8計算を実現し、600Wの熱設計電力を消費する。³¹
メモリシステムはチップ当たり192GBのHBM3eメモリに拡張され、Trilliumの容量の6倍、帯域幅は7.4TB/sに達した。³² 劇的なメモリ増加により、以前は複数のアクセラレータ間で複雑なテンソル並列性を必要としていたキー値キャッシュを持つ超大型モデルのサービングが可能になった。Googleは、100万トークンウィンドウに近づく新興マルチモーダルモデルと長文脈アプリケーションをサポートするために、特にメモリ容量を設計した。
Ironwoodの相互接続は4つのICIリンクを通じて9.6Tbpsの集約双方向帯域幅を提供し、チップ当たり1.2TB/sのピーク帯域幅に変換される。³³ アーキテクチャは小規模デプロイメント用の256チップポッドから42.5 FP8エクサフロップスの計算能力を提供する大規模な9,216チップスーパーポッドまでスケールする。³⁴ GoogleのJupiterデータセンターネットワーク技術は理論的に単一クラスターで最大43のIronwoodスーパーポッドをサポートできる―約400,000のアクセラレータで、ほぼ理解不可能な計算規模を表す。³⁵
FP8サポートは精度戦略の根本的な転換を表す。以前のTPU世代はソフトウェア技術を使用して8ビット演算をエミュレートし、オーバーヘッドが発生していた。IronwoodはE4M3(4ビット指数、3ビット仮数)とE5M2(5ビット指数、2ビット仮数)形式の両方をサポートするネイティブFP8乗算累積ユニットを実装する。³⁶ デュアル形式サポートにより、精度がそれほど重要でない前方パスにはE4M3を、勾配の大きさを維持して学習不安定性を防ぐ後方パスにはE5M2を混合使用できる。
Anthropicの2026年から始まる100万を超えるIronwoodチップのデプロイメントコミットメントは、アーキテクチャの本番準備を実証している。同社は1ギガワットをはるかに超えるTPU容量―小都市を電力供給するのに十分―をClaude モデルの学習とサービングのためだけに活用する計画である。³⁷ この規模は最も重要な既知のGPUデプロイメントを矮小化し、フロンティアモデル開発のためのTPUアーキテクチャへの根本的な賭けを表している。
現世代クイックリファレンス
以下の表は2025年の本番デプロイメントに最も関連性の高い3つの現世代TPUのスキャン可能な仕様を提供する:
表1: コアコンピュート仕様
[caption id="" align="alignnone" width="1386"] [/caption]
[/caption]
表2: メモリと帯域幅
[caption id="" align="alignnone" width="1380"]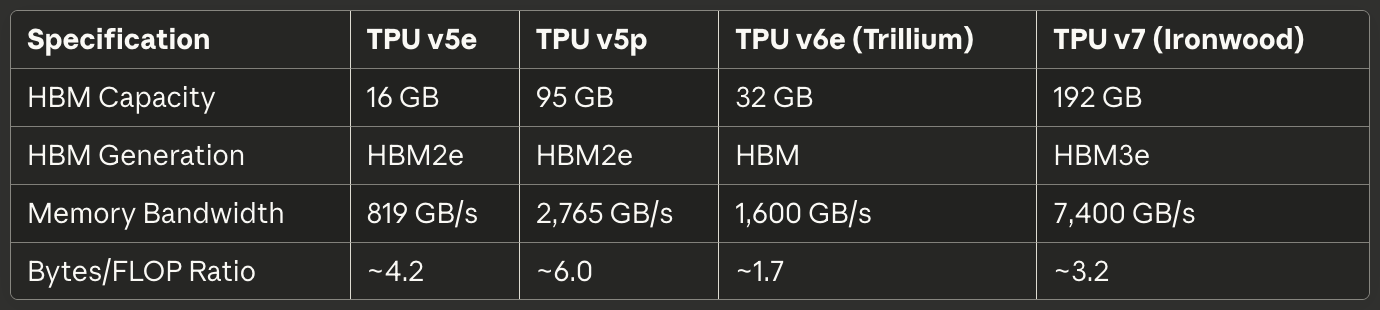 [/caption]
[/caption]
表3: 相互接続とスケーリング
[caption id="" align="alignnone" width="1384"]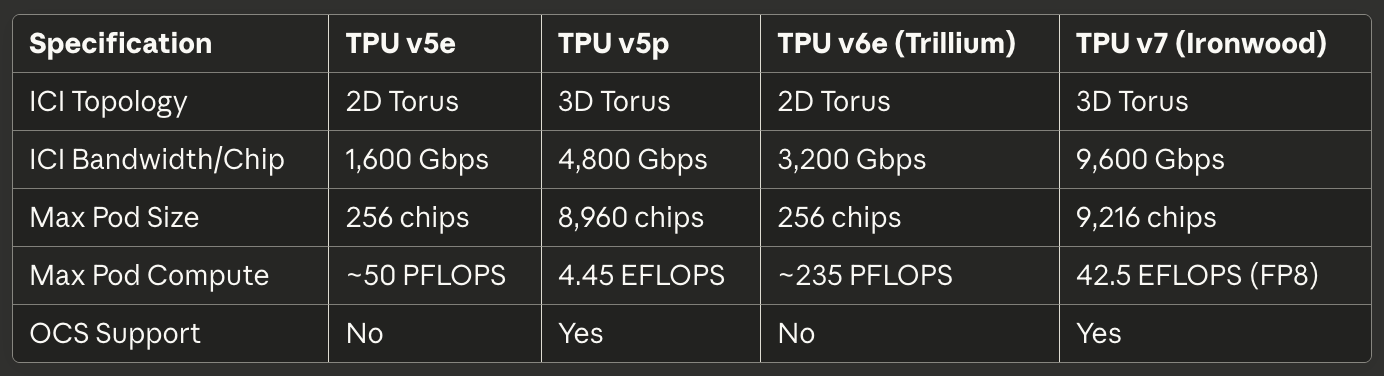 [/caption]
[/caption]
表4: 電力と効率
[caption id="" align="alignnone" width="1380"] [/caption]
[/caption]
表5: 推奨使用事例
[caption id="" align="alignnone" width="1382"] [/caption]
[/caption]
ハードウェアアーキテクチャ: シリコンの内部
シストリックアレイ数学とデータフロー
Matrix Multiply UnitはTPUアーキテクチャの心臓部を形成し、シストリックアレイの理解にはGPU SIMDレーンと比較した並列性への根本的に異なるアプローチを把握する必要がある。シストリックアレイは乗算累積ユニットをグリッドに連鎖し、データが構造を通ってリズミカルに流れる―それゆえ「シストリック」で、心臓を通る血液のリズミカルなポンピングを想起させる。³⁸
TPU v6eの256×256シストリックアレイが行列乗算C = A × Bを実行することを考える。エンジニアは行列Bの重みをグリッドに配列された65,536個の個別乗算累積ユニットに事前ロードする。行列Aの活性化値は左端から入り、アレイを水平に流れる。各MACユニットは格納された重みを入力活性化で乗算し、上から到着する部分和に結果を加算し、活性化(水平)と更新された部分和(垂直)の両方を隣接ユニットに渡す。³⁹
データフローパターンは、各活性化値が水平次元を横切る際に256回再利用され、各部分和が垂直に流れる際に256の乗算からの寄与を累積することを意味する。重要なことに、すべての中間結果はメモリへの往復ではなく短いワイヤを介して隣接MACユニット間を直接通過する。アーキテクチャは毎クロックサイクルで65,536の乗算累積演算を実行し、潜在的に数百万の演算を含む行列乗算全体で、ゼロの中間値がDRAMやオンチップSRAMにさえ触れない。⁴⁰
重み固定データフローパターンは、ニューラルネットワーク推論と学習で最も一般的なケース:同じ重み行列に多くの異なる活性化行列を繰り返し乗算することに最適化されている。エンジニアは重みを一度ロードし、再ロードなしで無制限の活性化バッチをアレイを通してストリーミングする。このパターンは畳み込み層、完全結合層、そしてtransformerモデルを支配するQ·K^Tとattention·V演算で非常によく機能する。⁴¹
エネルギー効率はデータ再利用と空間局所性に由来する。DRAMから値を読み取ることは、単一の乗算累積演算の約200倍のエネルギーを消費する。⁴² 各重みを256回、各活性化を256回メモリアクセスなしで再利用することで、シストリックアレイは計算ユニットとメモリ階層間でデータをやり取りするアーキテクチャでは不可能な演算/ワット比を達成する。
シストリックアレイの弱点は動的または不規則な計算パターンで現れる。データが固定スケジュールでグリッドを流れるため、アーキテクチャは条件実行、スパース行列(SparseCoreを使用しない限り)、ランダムアクセスパターンを必要とする演算で苦労する。柔軟性の欠如は汎用性をターゲットワークロードでの極限効率:予測可能なアクセスパターンを持つ密行列乗算と交換する。
TensorCore内部アーキテクチャ
各TPUチップは1つ以上のTensorCore―Matrix Multiply Unit、Vector Processing Unit、Scalar Unitが連携して動作する完全な処理ユニット―を含む。⁴³ TensorCoreはソフトウェアがターゲットとする基本的な構成要素を表し、3つのコンポーネント間の相互作用を理解することで、TPU性能特性とプログラミングパターンの両方が説明される。
Matrix Multiply UnitはFP32累積でbfloat16またはFP8入力に対してサイクル当たり16,000の乗算累積演算を実行する。⁴⁴ 混合精度アプローチは入力のメモリ帯域幅を削減しながら累積器で数値精度を保持する。エンジニアは、累積中に完全なFP32精度を維持することで、数百または数千の中間積を合計する際の破滅的キャンセレーションエラーを防ぐ一方で、削減精度入力が最終モデル品質に影響することはまれであることを観察した。
Vector Processing UnitはMXUの硬直した構造に適さない演算を処理する。活性化関数(ReLU、GELU、SiLU)、正規化層(バッチノルム、レイヤーノルム)、softmax、プーリング、ドロップアウト、要素単位演算は128レーンのSIMDアーキテクチャのVPUで実行される。⁴⁵ VPUはFP32とINT32データ型で動作し、指数と除算が大きな動的範囲を作り出すsoftmaxなどの数値的に敏感な演算に必要な精度を提供する。
Scalar UnitはTensorCore全体を統制する。単一スレッドプロセッサは制御フロー、複雑なインデックスパターンのメモリアドレス計算を実行し、High Bandwidth MemoryからVector MemoryへのDMA転送を開始する。⁴⁶ スカラユニットが単一スレッドで実行されるため、各TensorCoreはサイクル当たり1つのDMA要求のみを作成できる―MXUまたはVPU計算スループットを飽和させないメモリ集約的演算のボトルネックである。
TensorCoreに供給するメモリ階層は、生の計算能力と同程度に達成可能性能を決定する。Vector Memory(VMEM)は各TensorCore専用のソフトウェア管理スクラッチパッドSRAMとして機能し、通常数十メガバイトのサイズである。XLAコンパイラはHBMとVMEM間のデータ移動を明示的にスケジューリングし、高速ローカルメモリに何をステージするか、結果をいつ書き戻すかを決定する。⁴⁷
TPU v4以降の世代に存在するCommon Memory(CMEM)は、チップ上のすべてのTensorCoreがアクセス可能なより大きな共有プールを提供する。TPU v4アーキテクチャは2つのTensorCore間で共有される128MBのCMEMを割り当て、一方のコアの出力が他方のコアの入力に供給される、HBMへの往復なしのより洗練されたプロデューサ-コンシューマパターンを可能にした。⁴⁸
プログラミングモデルの影響は非常に重要である。スカラユニットが単一スレッドでベクトルメモリが明示的管理を必要とするため、TPUプログラミングは現代のGPUプログラミングよりも1990年代の組み込みシステム開発に似ている。CUDAは統一メモリとハードウェア管理キャッシュでメモリ移動を抽象化する;TPUコード(XLAによって生成されるかPallasで手書きされるかに関わらず)はすべてのデータ転送を明示的に統制しなければならない。手動制御は専門的最適化を可能にするが、有能な性能のハードルを上げる。
High Bandwidth Memoryアーキテクチャ
現代のTPUはHBM(High Bandwidth Memory)、またはHBM3eを使用し、CPUで見つかるDDR SDRAMや多くのGPUで使用されるGDDRとは根本的に異なるメモリ技術である。HBMはシリコン貫通ビア(TSV)を使用して複数のDRAMダイを垂直にスタックし、シリコンインターポーザー上でプロセッサダイに直接隣接してスタックを配置する。⁴⁹ 短い電気パスと広いインターフェースにより、従来のメモリ技術よりも劇的に高い帯域幅が可能になる。
TPU v7 Ironwoodは合計帯域幅7.4TB/sで192GBのHBM3eを実装する。⁵⁰ メモリシステムは複数のチャネルに分割され、それぞれが総容量の別の部分への独立アクセスを提供する。XLAコンパイラとランタイムは、並列アクセスを最大化し、1つのチャネルが飽和して他が遊んでいるホットスポットを避けるために、HBMチャネル全体にテンソルを慎重に分割しなければならない。
メモリインターフェース幅は従来のDRAMを圧倒する。DDR5チャネルが64ビット幅を提供する場合、HBMチャネルは通常1,024ビットにまたがる。⁵¹ 極端な幅により、狭いインターフェースを複数ギガヘルツ周波数に押し上げることと比較して、比較的控えめなクロック速度で高帯域幅が可能になり、電力消費と信号完全性の課題が削減される。
レイテンシ特性はGPUメモリシステムと大幅に異なる。TPUは小さなローカルバッファを超えるハードウェア管理キャッシュを欠き、そのためアーキテクチャは計算ユニットが必要とするずっと前にソフトウェアが明示的にデータをVMEMにステージングすることに依存する。キャッシュの欠如はコンパイラがプリフェッチとダブルバッファリングを通じてレイテンシを隠すことに成功しない限り、メモリレイテンシが性能に直接影響することを意味する。⁵²
メモリ容量制限は計算スループットよりも多くのワークロードを支配する。bfloat16重みを持つ1750億パラメータモデルはパラメータを格納するために350GBを必要とし―活性化、オプティマイザ状態、勾配バッファを考慮する前にすでにIronwoodの192GB HBMを超える。そのようなモデルの学習には、勾配チェックポインティング、複数チップ間のオプティマイザ状態シャーディング、メモリフットプリントを最小化するパラメータ更新の慎重なスケジューリングなどの洗練された技術が必要である。⁵³
TPUランタイムはMXU効率を最大化するための特定のテンソルレイアウト要件を強制する。シストリックアレイが128×8タイルでデータを処理するため、テンソルはパディング無駄を避けるためにこれらの次元に整列すべきである。⁵⁴ 不適切なサイズの行列はMACがアイドル状態で部分タイルを処理することを強制し、FLOPS利用率を直接削減する。コンパイラはテンソルを自動的にパッドおよび再形成しようとするが、モデルアーキテクチャでの意識的なレイアウト選択は性能を大幅に改善できる。
SparseCore: 専用埋め込み加速
Matrix Multiply Unitは密行列演算で優れているが、埋め込み集約的ワークロードは根本的に異なる特性を示す。レコメンデーションモデル、ランキングシステム、大型言語モデルは頻繁に不規則でデータ依存のインデックスを通じて大規模埋め込みテーブル(しばしば数百ギガバイト)にアクセスする。MXUの構造化データフローはこれらのスパースメモリアクセスパターンに利点を提供せず、SparseCoreの専用アーキテクチャを動機づける。⁵⁵
SparseCoreはMXUのシストリックアレイとは根本的に異なるタイル化データフロープロセッサを実装する。TPU v4はチップ当たり4つのSparseCore を特徴とし、それぞれ16の計算タイルを含んだ。⁵⁶ 各タイルはローカルスクラッチパッドメモリ(SPMEM)と処理要素を持つ独立データフローユニットとして動作する。タイルは並列実行し、埋め込み演算の分離されたサブセットを同時に処理する。
メモリ階層は完全な埋め込みテーブルをHBMに保持しながら、小さく高速なSPMEMにホットデータを配置する。XLAコンパイラは埋め込みアクセスパターンを分析して、どの埋め込みベクトルがSPMEMでのキャッシングに値するかHBMからオンデマンド取得するかを決定する。⁵⁷ 戦略は従来のCPUキャッシュ階層に似ているが、ハードウェアではなくソフトウェアが配置決定を行う。
SparseCoreはTensorCoreのメモリパスを完全にバイパスしてHBMチャネルに直接接続する。専用接続により、埋め込み演算が密行列演算とメモリ帯域幅を競合することを防ぎ、両方が並列に進行できる。⁵⁸ 分割は、大規模埋め込みルックアップと密ニューラルネットワーク層をインターリーブするDeep Learning Recommendation Models(DLRM)などのモデルで非常によく機能する。
mod-シャーディング戦略は、target_sc_id = col_id % num_total_sparse_coresを計算することでSparseCore全体に埋め込みを分散する。⁵⁹ 単純なシャーディング関数は埋め込みIDが均一に分散されている場合の負荷バランシングを保証するが、偏ったアクセスパターンでホットスポットを作る可能性がある。実世界データを扱うエンジニアは多くの場合、埋め込み頻度分布を分析し、ボトルネックを避けるために手動でシャーディングを再バランスする必要がある。
SparseCoreからの性能向上は、チップダイ面積と電力のわずか5%を消費しながら、MXUとVPUで同一演算を実装することと比較して5-7倍に達する。⁶⁰ 劇的な効率優位性は、密行列インフラを通じて強制するのではなく、スパース演算専用にデータフローを構築することに由来する。特化原理はTPUアーキテクチャ内で再帰的に適用される:TPUがGPUの汎用設計を超えて特化するように、SparseCoreはTPUの行列指向設計を超えて特化する。
Trilliumの第3世代SparseCoreは可変SIMD幅(FP32で8要素、bfloat16で16)と改善されたメモリアクセスパターンを導入し、位置ずれ読み取りからの無駄帯域幅を削減した。⁶¹ アーキテクチャ進化は、大型言語モデルがより大きな語彙とより洗練された検索強化生成パターンに向かう傾向として、埋め込み加速へのGoogleの継続的投資を実証している。
相互接続技術:スーパーコンピューターの配線
チップ間相互接続(ICI)アーキテクチャ
チップ間相互接続は、TPUを独立したアクセラレーターではなく統合されたスーパーコンピューターとして機能させる重要な技術です。EthernetやInfiniBandネットワーク経由で通信するGPUとは異なり、ICIは隣接するTPUを直接接続するカスタム高速シリアルリンクを実装し、マイクロ秒規模のレイテンシとテラビット/秒の帯域幅を実現します。⁶²
TPU世代全体にわたるトポロジーの進化は、ポッドスケーリングの要件の変化を反映しています。TPU v2、v3、v5e、v6eは2Dトーラストポロジーを実装し、各チップは4つの最近傍(北、南、東、西)に接続します。⁶³ リンクは境界で折り返し、接続数の少ないエッジチップを排除するドーナツ状の論理トポロジーを作成します。256個のTPUからなる16×16グリッドは、通信する2つのチップに関係なく均一な帯域幅とレイテンシ特性を提供します。
TPU v4とv5pは3Dトーラストポロジーにアップグレードし、各チップが6つの隣接チップに接続します。⁶⁴ 追加の次元により、ネットワーク直径(任意の2つのチップ間の最大ホップ数)が約2√Nから3∛Nに削減されます。4,096チップのポッドでは、最大ホップ数が約128から48に削減され、全削減などのグローバル同期操作の最悪ケース通信レイテンシが大幅に削減されます。
トロイダル構造は、もう一つの重要な利点を提供します:ワークロードがチップ間でどのように分割されても等しいバイセクション帯域幅です。トーラスを半分に分割する任意のカットは同じ数のリンクを横断し、ジョブ配置の不備がネットワークボトルネックを作成する病的なケースを防ぎます。⁶⁵ 均一なバイセクション帯域幅により、スケジューリングが簡素化され、以下で説明する光回路スイッチの再構成可能性が実現されます。
帯域幅仕様は世代を重ねるごとに印象的にスケールしています。TPU v6eは、チップあたり13 TB/sのICI帯域幅を提供します。⁶⁶ TPU v5pは6つの3Dトーラスリンクを介してチップあたり4,800 Gbpsに達しました。⁶⁷ Ironwoodは4つのICIリンクを実装し、9.6 Tbpsの総双方向帯域幅を実現し、チップあたり1.2 TB/sに相当します。⁶⁸ 比較として、最高級の400GbEネットワークインターフェースは50GB/sの双方向帯域幅を提供しますが、これは現代のTPU ICIより一桁少ないです。
ラック内のリンク技術では、同じ4×4×4キューブ内のチップ間の短距離接続に直接接続銅(DAC)ケーブルを使用します。⁶⁹ 銅接続は、同期操作を実行する密結合チップに必要な帯域幅を提供しながら、コストと電力を最小化します。キューブ間およびポッドスケールのリンクは光トランシーバーに移行し、より高いコストと電力と引き換えに、データセンターラックに跨るのに必要な距離と帯域幅を実現します。
コレクティブ操作は、ICIの独自の特性を活用します。全削減、全収集、削減散布操作は、トレーニング中にチップ間でアクティベーションと勾配を頻繁に同期します。EthernetベースのGPUクラスターでは、これらのコレクティブはスイッチ、ケーブル、ネットワークインターフェースカードを含む階層ネットワークを通過し、各ホップでレイテンシが発生します。TPU ICIは最適化されたコレクティブアルゴリズムを直接ハードウェアに実装し、等価なEthernetベースのGPU実装より10倍高速に全削減操作を実行します。⁷⁰
光回路スイッチング:動的トポロジー再構成
GoogleのTPU v4による光回路スイッチング(OCS)の展開は、数十年におけるデータセンターネットワーキングの最も重要な革新の一つでした。EthernetやInfiniBandなどの従来のパケット交換ネットワークは、ヘッダーを検査し適切な出力ポートに転送するスイッチを通じてパケットをホップバイホップでルーティングすることで論理接続を確立します。OCSは代わりにプログラム可能な光素子を使用してエンドポイント間に直接的な物理光パスを作成し、スイッチングレイテンシを完全に排除します。⁷¹
コア技術は、光ビームをリダイレクトするために物理的に回転するMEMS(微小電気機械システム)ミラーに依存しています。TPU Aの送信機が光をOCSに送信します。OCS内の小さなミラーが回転し、その光ビームをTPU Bの受信機に反射します。接続は、ファイバー内の光伝播以外に本質的にゼロの追加レイテンシでAからBへの直接光パスになります。⁷²
再構成速度は、生産システムにおけるOCSの実用性を決定します。Googleの展開は10ナノ秒未満のスイッチング時間を実現し、これは典型的なネットワークプロトコルのラウンドトリップ時間よりも高速です。⁷³ 再構成速度により、実行中のジョブを中断したり慎重に調整されたトラフィックエンジニアリングを必要とすることなく、ワークロード要件に合致する動的トポロジー変更が可能になります。
TPU v5pは大規模スケールでOCSを実証しました。アーキテクチャは、スイッチングファブリック全体で毎秒4ペタビットの総帯域幅を提供する光回路スイッチを使用します。⁷⁴ 単一のv5pスーパーポッドには、16×20×28の3Dトーラス構成で8,960チップを配線するために13,824の光ポートを管理する48のOCSユニットが必要です。⁷⁵ このスイッチングシステムは、あらゆるコンピューティング環境における最大の光ネットワーキング展開の一つです。
OCSは従来のネットワークでは不可能な機能を提供します。物理トポロジーと論理トポロジーが完全に分離され、OCSが直接光パスを作成すれば、データセンターの反対の角にある2つのTPUが隣接する隣接チップとして現れます。故障したチップやリンクは、故障コンポーネントを除外し論理トーラス構造を維持するようにミラーを再プログラミングすることで回避されます。新しいジョブは、ラックを物理的に再配線することなく適切なポッド構成を作成するようにOCSをプログラミングすることで、任意のサイズの「スライス」を受け取ります。⁷⁶
このアーキテクチャはGoogleのJupiterデータセンターネットワークと統合され、単一ポッドを超えてスケールします。JupiterはGoogleのカスタムシリコンスイッチと制御プレーンを使用して、データセンター全体にわたってマルチペタビット/秒のバイセクション帯域幅を提供します。⁷⁷ 複数のTPUスーパーポッドがJupiterファブリック経由で接続され、ネットワーク容量が許せば理論的に最大400,000アクセラレーターのクラスターをサポートします。⁷⁸
消費電力と信頼性特性は、TPUスケール展開において光回路スイッチングを有利にします。従来のパケットスイッチは、テラビット/秒レートでパケットを処理・転送するのに大きな電力を消費します。OCSスイッチは再構成イベント中にMEMSミラーを動作させるためだけに電力を消費し、その後はアイドル状態となり、接続が安定している間は最小限の損失で光を通過させます。⁷⁹ アーキテクチャのシンプルさは、バグやパフォーマンス異常の原因となりやすい複雑なパケット処理とバッファリングロジックを排除することで信頼性を向上させます。
ポッドアーキテクチャとスケーリング特性
TPUポッドは、ICI経由で接続されたTPUの最大単一ユニットを表し、統合されたアクセラレーターを形成します。物理構造は、個別のチップからトレイ、キューブ、ラック、完全なポッドまで階層的に構築されます。⁸⁰ この階層を理解することは、異なるスケールでのメモリ容量、通信帯域幅、耐障害性について推論するために重要です。
基本的な構成要素は、PCIe経由でホストCPUに接続された単一トレイ上の4つのチップから構成されます。⁸¹ PCIe接続は制御プレーン操作、初期プログラムロード、トレーニングデータと推論結果のインフィード/アウトフィードを処理します。分散トレーニングのための実際のチップ間通信は、PCIeの帯域幅ボトルネックを回避してPCIeではなくICI経由で流れます。
16のトレイ(64チップ)で単一の4×4×4キューブを形成し、これがポッド構築の基本単位です。キューブ内では、チップが同じラック内にあり物理的距離が短いため、すべてのICI接続は直接接続銅ケーブルを使用します。⁸² キューブはラップアラウンド接続を持つ完全な3Dトーラスを実装し、理論的に独立して動作可能な自己完結型の64チップユニットを作成します。
TPU v4ポッドは64キューブまでスケールし、総計4,096チップになります。⁸³ キューブ間接続は光回路スイッチングファブリックによって管理される光リンクに移行します。OCSは、これらの4,096チップを単一の巨大なポッド、複数の小さな独立ポッド、または必要に応じてジョブ中動的に再構成することができます。この柔軟性により、データセンターオペレーターは異なるジョブサイズと優先度にわたって利用率のバランスを取ることができます。
TPU v5pはポッドスケールを16×20×28の3Dトーラスで8,960チップまで押し上げました。⁸⁴ 具体的な次元は慎重な帯域幅と直径の最適化を反映しています—素因数分解がネットワークトポロジーにとって重要です! ポッドは4.45エクサフロップスの計算能力を提供し、生産環境で展開された最大の単一ポッド構成の一つです。
Ironwoodは小規模展開用の256チップポッドと大規模フロンティアモデルトレーニング用の9,216チップスーパーポッドの両方をサポートします。⁸⁵ 9,216チップ構成は42.5 FP8エクサフロップスを提供し、これはわずか5年前のTop500スーパーコンピューターリスト全体の計算能力を上回ります。⁸⁶ このスケールは、パイプライン化や非同期アプローチではなく同期トレーニングで組織が達成できることを再定義しています。
スケーリング効率は、より大きなポッドが実際に役立つかどうかを決定します。チップが計算よりも同期により多くの時間を費やすため、通信オーバーヘッドはポッドサイズと共に増加します。Google Researchは、特定のワークロードで32,768 TPUにおいて95%のスケーリング効率を実証した結果を発表しました。これは32,768 TPUが完全な線形スケーリングが予測するパフォーマンスの95%を実現したことを意味します。⁸⁷ この効率は、ハードウェア加速コレクティブ、最適化されたコンパイラー変換、勾配同期頻度を削減する巧妙なアルゴリズムアプローチに由来します。
ポッドスケールでの耐障害性には洗練された処理が必要です。統計的確率は、数千のチップを継続的に実行する任意のシステムでコンポーネント障害を保証します。光回路スイッチは、故障したコンポーネントを回避して再構成することで、優雅な劣化を可能にします。トレーニングチェックポイントは定期的間隔(通常数分ごと)で発生するため、ジョブ障害は最初からではなく最後のチェックポイントから再開するだけで済みます。⁸⁸
ソフトウェアスタック:コンパイラ、フレームワーク、プログラミングモデル
XLAコンパイラ:計算グラフの最適化
XLA(Accelerated Linear Algebra)はTPUのソフトウェアスタックの基盤を形成し、高レベルフレームワークの演算をTPU上で実行するための最適化された機械語コードにコンパイルします。⁸⁹このコンパイラは、機械学習ワークロードとTPUアーキテクチャの特性に関するドメイン知識を活用するため、汎用コンパイラでは不可能な積極的な最適化を実装しています。
Fusionは、XLAの最も影響力のある最適化手法です。コンパイラは計算グラフを分析して、中間テンソルを実体化せずに実行できる演算シーケンスを特定します。単純な例として、relu(batch_norm(conv(x)))のような要素単位演算では、通常、畳み込み出力をメモリに書き込み、それをバッチ正規化のために読み出し、その結果をメモリに書き込み、ReLUのために再度読み出す必要があります。XLAはこれらの演算を単一のカーネルに融合し、中間的なメモリトラフィックなしで最終的なReLU出力を生成します。⁹⁰
Fusionの影響は、TPUのアーキテクチャとともにスケールします。多くのワークロードでは、計算スループットよりもメモリ帯域幅が制約となります—MXUは、メモリシステムがデータを供給できる速度よりも高速に行列乗算を実行できます。Fusionによる中間メモリ書き込みと読み出しの削除は、パフォーマンス改善に直接的に寄与し、活性化関数を多用するネットワークにおいて、しばしば2倍以上の高速化を実現します。⁹¹
メモリレイアウト変換は、ハードウェア要件に合わせてテンソルストレージを最適化します。ニューラルネットワークでは、直感的なインデックス付けのためにテンソルをNHWC形式(バッチ、高さ、幅、チャンネル)で表現することが多いですが、TPU MXUは128×8タイルに整列したレイアウトで最高のパフォーマンスを発揮します。⁹²XLAは自動的にテンソルを転置、変形、パディングしてハードウェアの設定に合わせ、必要な場合にのみレイアウト変換を挿入し、時には全体の変換オーバーヘッドを最小化するために好ましいレイアウトをグラフ内で逆向きに伝播させます。
コンパイラは、高度な定数畳み込みと無用コード削除を実装しています。MLグラフには、出力が定数のみに依存するサブグラフが頻繁に含まれます—バッチ正規化パラメータ、推論ドロップアウト率、バッチごとではなく一度だけ実行できる形状計算などです。XLAは、これらのサブグラフをコンパイル時に評価し、定数テンソルに置き換えることで、ランタイムの作業を削減します。⁹³
クロスレプリカ最適化は、分散実行に関する知識を活用します。複数のTPUコアにわたってトレーニングを行う場合、特定の演算(バッチ正規化統計など)はすべてのレプリカにわたって集約を必要とします。XLAはこれらのパターンを識別し、明示的なメッセージパッシングによる集約実装ではなく、ICIのハードウェア加速all-reduceを活用する最適化された集合演算を生成します。⁹⁴
コンパイラは、TPU専用の中間表現であるMosaicをターゲットとします。Mosaicは、アセンブリ言語よりも高い抽象レベルで動作しますが、入力計算グラフよりも低レベルです。この言語は、命令スケジューリングやレジスタ割り当てなどの低レベル詳細を隠しながら、システィックアレイ、ベクトルメモリ、VMEM ステージングなどのTPUアーキテクチャ機能を公開します。⁹⁵
自動調整機能は、経験的検索により最適なタイルサイズと演算パラメータを選択します。XLA Auto-Tuning(XTAT)システムは、異なるfusion戦略、メモリレイアウト、タイル寸法を試行し、各バリアントのパフォーマンスをプロファイルして、最速の設定を選択します。⁹⁶検索は複雑なモデルに対して相当なコンパイル時間を要求することがありますが、人間が手動で特定することがほとんどない直感に反する最適化を発見することで、劇的なランタイム高速化を生成します。
JAX:組み合わせ可能な変換とSPMD
JAXは、自動微分、XLAへのJITコンパイル、プログラム変換のファーストクラスサポートを備えたNumPy互換の数値計算インターフェースを提供します。⁹⁷このフレームワークの関数型プログラミングパラダイムと組み合わせ可能な変換モデルは、TPU実行モデルと分散並列パターンと自然に整合します。
JAXの中核抽象化は、関数に数学的変換を適用します。grad(f)はfの勾配を計算します。jit(f)はfをXLAにJITコンパイルします。vmap(f)は新しい次元でfをベクトル化します。重要なことは、変換が組み合わせ可能であることです:jit(grad(vmap(f)))は期待通りに機能し、ベクトル化された勾配関数をコンパイルします。⁹⁸組み合わせモデルは、シンプルでテスト可能なコンポーネントから複雑な分散トレーニングループを構築することを可能にします。
SPMD(Single Program, Multiple Data)はJAXの分散実行モデルを表します。プログラマは単一デバイスをターゲットとするかのようにコードを書き、複数のTPUコアにわたってテンソルを分割する方法を示すシャーディングアノテーションを追加します。XLAコンパイラとGSPMD(General SPMD)サブシステムは、分散デバイス間での実行中にプログラムセマンティクスを維持しながら、通信演算を自動的に挿入します。⁹⁹
シャーディングアノテーションは、PartitionSpecを使用して分散戦略を宣言します。PartitionSpec('batch', None)は、テンソルの第1次元をデバイスメッシュの'batch'軸にわたってシャードし、第2次元を複製します。PartitionSpec(None, 'model')は、第2次元を分割することでテンソル並列を実装します。アノテーションは、任意のテンソルランクとデバイスメッシュ次元で組み合わせることができます。¹⁰⁰
GSPMDの自動並列化は、膨大な量の定型コードを削除します。従来の分散トレーニングでは、完全なテンソルを必要とする演算の前にall-gatherを手動で挿入し、分散勾配の計算後にreduce-scatterを、グローバルリダクションにall-reduceを手動で挿入する必要がありました。GSPMDはシャーディング仕様を分析し、適切な集合演算を自動的に挿入することで、プログラマが通信エンジニアリングではなくアルゴリズムに集中できるようにします。¹⁰¹
コンパイラは、制約解決を使用して計算グラフを通じてシャーディング決定を伝播します。演算Aが、演算Bによって消費されるシャードテンソルを出力する場合、GSPMDは出力の使用方法に基づいてBの最適なシャーディングを推論し、数学的に必要な場合のみリシャーディング演算を挿入する可能性があります。¹⁰²自動推論は、手書きの分散コードを悩ませる「シャーディングスパゲッティ」を防ぎます。
JAXは、自動化が不十分な場合の細かい制御を提供します。with_sharding_constraintは、グラフ位置で特定のシャーディングを強制し、自動推論を上書きします。カスタムPJIT(parallel JIT)アノテーションは、パフォーマンス重要なコードパスの正確なデバイス配置とシャーディング戦略を指定します。階層モデルは、自動シャーディングによる迅速なプロトタイピングを可能にしながら、必要に応じて専門家の最適化をサポートします。¹⁰³
Shardyは、2025年にGSPMDの後継として登場し、改良された制約伝播アルゴリズムと動的形状のより良い処理を実装しました。¹⁰⁴新しいシステムは、演算ごとではなく、より大きなグラフ領域にわたって共同でシャーディング選択について推論することで、追加の最適化機会を公開します。
PyTorch/XLA:PyTorchをTPUへ
PyTorch/XLAは、最小限のコード変更でTPU上でPyTorchモデルを実行することを可能にし、PyTorchの命令型プログラミングモデルとXLAのグラフベースコンパイルの間のギャップを埋めます。¹⁰⁵この統合は、PyTorchの開発者体験を維持することと、TPU固有の最適化を公開することのバランスを取ります。
根本的な課題は、PyTorchの即座実行哲学に起因します。PyTorchは、Python文が実行されるとすぐに演算を実行し、標準ツールでのデバッグと自然な制御フローを可能にします。XLAはコンパイル前に完全な計算グラフをキャプチャする必要があり、即座実行とグラフコンパイルのパフォーマンス利点との間に緊張を生み出します。¹⁰⁶
PyTorch/XLA 2.4は、eager modeサポートを導入し、インピーダンスミスマッチに対処しました。実装は、PyTorch演算をXLAグラフに動的にトレースし、開発者がXLAコンパイルの恩恵を受けながら標準PyTorchコードを書くことを可能にします。¹⁰⁷このモードは、一部のコンパイル最適化機会を開発速度とデバッグの簡単さのためにトレードオフします。
グラフモードは、本番デプロイメントの主要なパスのままです。開発者は、デコレータまたはコンパイルAPIを使用してXLAコンパイル用の関数を明示的にマークします。明示的なアノテーションは積極的な最適化を可能にしますが、どの演算を単一のXLAグラフに融合すべきか、独立して実行すべきかを理解する必要があります。¹⁰⁸
Pallas統合は、PyTorch/XLAにカスタムカーネル開発をもたらします。PallasはXLAの自動fusionが不十分な場合や、特殊化された演算が手動最適化を必要とする場合に、TPUカーネルを書くための低レベル言語を提供します。¹⁰⁹この言語は、生のアセンブリよりも高レベルを保ちながら、TPUメモリ階層(VMEM、CMEM、HBM)と計算ユニット(MXU、VPU)を公開します。
組み込みのPallasカーネルは、FlashAttentionやPagedAttentionなどのパフォーマンス重要な演算を実装します。FlashAttentionのタイル化された注意計算は、メモリ帯域幅要件を系列長nに対してO(n²)からO(n)に削減し、モデルが固定メモリ予算内ではるかに長い系列を処理できるようにします。¹¹⁰PagedAttentionは、サービング用のキー・値キャッシュ管理を最適化し、パディング実装と比較して5倍の高速化を実現します。¹¹¹
PyTorch/XLAブリッジは、当初GPU用に設計された高性能サービングフレームワークであるvLLM TPUにとって重要であることが証明されました。実装は、実際にはPyTorchモデルに対してもJAXを中間的な低レベル化パスとして使用し、PyTorchフロントエンド互換性を維持しながらJAXの優れた並列サポートを活用しています。¹¹²このアーキテクチャは、初期プロトタイプと比較して2025年を通じて2-5倍のパフォーマンス改善を実現しました。
改善にもかかわらず、モデル互換性の課題は続いています。一部のPyTorch演算にはXLA等価物が欠けており、パフォーマンスを低下させるCPU実行へのフォールバックを強制します。動的制御フローはグラフコンパイルによってサポートが不十分で、しばしば動的動作を静的でコンパイル可能な代替案に置き換えるアーキテクチャ変更を必要とします。PyTorch/XLAリポジトリは互換性を文書化し、一般的な問題のあるパターンの移行ガイドを提供しています。¹¹³
精度フォーマット:BFloat16、FP8、量子化
TPUの減精度演算サポートは、許容可能なモデル品質を維持しながら劇的なパフォーマンスとメモリ改善を可能にします。異なるフォーマットの数値特性と、それぞれをいつ適用するかを理解することは、最適なパフォーマンスを実現するために重要であることが証明されます。¹¹⁴
BFloat16は、TPU v2で最初に登場したGoogleの減精度トレーニングに対する初期の賭けを表します。このフォーマットは、仮数を7ビット(符号ビット付き)に切り詰めながら、FP32の8ビット指数を維持します。¹¹⁵完全な指数範囲は、勾配が頻繁にFP16の表現可能範囲から外れる初期のFP16トレーニングを悩ませたアンダーフローとオーバーフローを防ぎます。
削減された仮数は量子化誤差を導入しますが、最終的なモデル品質に影響を与えることはまれです。エンジニアは、bfloat16でトレーニングされたモデルが通常、統計的ノイズ内でFP32トレーニングベースラインと一致することを観察しました。これは量子化が正則化の一形態として機能し、微小な数値詳細への過学習を防ぐためと考えられます。¹¹⁶このフォーマットは、FP32と比較してメモリ帯域幅と容量要件を半分にし、メモリバウンドワークロードでのパフォーマンス向上に直接的に寄与します。
FP8は減精度をさらに進め、重みと活性化を8ビットに圧縮します。2つの標準エンコーディングが存在します:E4M3(4ビット指数、3ビット仮数)は前方パスの精度を優先し、E5M2(5ビット指数、2ビット仮数)は勾配の大きさが大きく変動する後方パスの範囲を優先します。¹¹⁷Ironwoodは両フォーマットのネイティブFP8サポートを実装しているのに対し、以前のTPUはソフトウェア変換によってFP8をエミュレートしていました。¹¹⁸
トレーニング中の量子化認識は、FP8の数値的成功を可能にします。FP8でゼロからトレーニングされたモデル、またはFP8認識技術で微調整されたモデルは、フォーマットの限られた精度に耐える重み分布を学習します。ポストトレーニング量子化(トレーニング後にFP32モデルをFP8に変換)は、注意深いキャリブレーションなしでしばしば品質を劣化させます。¹¹⁹
INT8量子化は、さらに大きなメモリ節約と推論高速化を実現します。GoogleのAccurate Quantized Training(AQT)は、bfloat16ベースラインと比較して最小限の品質損失でTPU上でのINT8トレーニングを可能にします。¹²⁰この技術は、ポストトレーニング近似ではなく、学習中にモデルがINT8の制約に適応できるように、ゼロから量子化認識トレーニングを適用します。
混合精度戦略は、フォーマットを戦略的に組み合わせます。前方パスは活性化と重みにFP8を使用し、後方パスは勾配にFP8 E5M2またはbfloat16を使用し、オプティマイザ状態は重み更新中の数値安定性のためにFP32のまま残ります。¹²¹混合アプローチは速度、メモリ、精度のバランスを取り、しばしば4倍高速で実行しながらFP32品質の90%以上を実現します。
精度トレードオフは、速度とメモリを超えて数値安定性の考慮事項まで拡張されます。バッチ正規化、層正規化、softmaxは、減精度において注意深い数値処理を必要とします。softmaxでの大きな指数はFP8またはbfloat16範囲をオーバーフローする可能性があります;指数化前に最大ロジットを減算することで、数学的等価性を維持しながらオーバーフローを防ぎます。¹²²XLAコンパイラは、安全な場合にこれらの変換を自動的に実装しますが、カスタム演算は時々手動の数値エンジニアリングを必要とします。
プログラミングモデルと並列化戦略
SPMDと自動分割
Single Program, Multiple Data (SPMD) パラダイムは、プログラマーがTPU実行について考える方法を根本的に形成します。複数のプロセスを調整するための明示的なメッセージパッシングコードを書くのではなく、開発者は単一のプログラムを書き、データをデバイス間でどのように分割すべきかを注釈付けします。¹²³ コンパイラは分散、通信、同期の機械的な詳細を処理します。
GSPMD (General SPMD) は、XLAで自動分割ロジックを実装します。このシステムはテンソルシャーディング注釈と計算グラフ構造を分析し、どの操作がどのデバイスで実行され、正しいセマンティクスを維持するためにどのような通信が必要かを決定します。¹²⁴ この自動化により、手動で書かれた分散コードに共通するバグのカテゴリ全体が排除されます—テンソル形状の不一致、不正なcollective操作の順序付け、不適切な同期によるデッドロックなど。
コンパイラの制約伝播エンジンは、最小限の注釈からシャーディング決定を推論します。モデルの入力と出力のシャーディングのみを注釈付けることで多くの場合十分です;GSPMDは中間操作を通じて制約を伝播し、効率的な分散を自動的に選択します。¹²⁵ 操作に対して複数の有効なシャーディングが存在する場合、コンパイラは代替案の通信コストを見積もり、最も低コストのオプションを選択します。
高度な最適化では、通信と計算をオーバーラップさせます。レプリカ間で勾配を同期するall-reduce操作は、最初の層の勾配が完了するとすぐに開始でき、後続の層のバックワードパスと並行して実行できます。¹²⁶ コンパイラは自動的にcollectiveをスケジュールしてオーバーラップを最大化し、逐次実行と比較して適切な通信時間を2倍以上削減します。
再計算はメモリと引き換えに計算を行います。勾配計算のためにすべてのフォワードパス活性化を保存するのではなく、コンパイラはメモリ圧迫が閾値を超えた際にバックワードパス中に選択的に活性化を再計算します。¹²⁷ このトレードオフは、計算がメモリ帯域幅を上回ることが多いTPUで特によく機能し、再計算をメモリトラフィックよりも安価にします。
データ並列性、テンソル並列性、パイプライン並列性
データ並列性は最も分かりやすい分散訓練戦略を表しています:完全なモデルをN個のデバイスに複製し、各レプリカで異なるデータバッチを処理します。局所的に勾配を計算した後、all-reduceがレプリカ間で勾配を集約し、すべてのデバイスが同一の重み更新を適用します。¹²⁸ このアプローチは、通信時間が計算時間を支配するまで線形にスケールします—通常、イーサネットネットワーキングでは約1,000 GPU、ICIを使用したTPUでは10,000+です。¹²⁹
テンソル並列性(モデル並列性とも呼ばれる)は、個々の操作をデバイス間で分割します。行列乗算Y = W @ Xでは、重み行列Wをデバイス間で分割し、それぞれが出力の一部を計算します。¹³⁰ この戦略により、パラメータストレージと計算を分散することで、単一デバイスメモリを超えるモデルの訓練が可能になります。
テンソル並列性の通信パターンはデータ並列性と大幅に異なります。各層後のall-reduceではなく、テンソル並列性では完全なテンソルを必要とする操作前のall-gatherと、分散計算後のreduce-scatterが必要です。¹³¹ 通信量はパラメータサイズではなくモデル活性化サイズとともにスケールし、データ並列性とは異なるボトルネックを作成します。
パイプライン並列性は、モデルの逐次層をデバイス間で分割し、異なるマイクロバッチを異なるステージで同時に処理します。GPipeは、メモリ使用量を制限しながらパイプライン利用率を最大化する慎重なスケジューリングでこの戦略を導入しました。¹³² 各デバイスは1つのマイクロバッチのフォワードパスを処理し、活性化を次のステージに送信し、次のマイクロバッチを処理します—初期立ち上げ後にすべてのデバイスが連続的に動作するパイプラインを作成します。
勾配の古さがパイプライン並列性を複雑にします。デバイスは数十マイクロバッチも古い可能性のある活性化から計算された勾配を使用して重みを更新し、収束に害を与える古さを作り出します。¹³³ PipeDreamのような洗練されたスケジューリングアルゴリズムは、高スループットを維持しながら古さを最小化し、経験的結果では、ほとんどのモデルが品質劣化なしに適度な古さを許容することが実証されています。
3D並列性は3つの戦略すべてを組み合わせます。データ並列性は「データ」次元で分散し、テンソル並列性は「モデル」次元で、パイプライン並列性は「パイプライン」次元で分散します。¹³⁴ モデルアーキテクチャ、ハードウェアトポロジ、通信コストに基づいて次元を慎重にバランスさせることで、スループットを最大化します。GPT-3スケールのモデルは一般的に、8-16レプリカでのデータ並列性、4-8 GPUでのテンソル並列性、4-16ステージでのパイプライン並列性を使用した3D並列性を使用します。
シャーディング戦略と最適化
シャーディング戦略の選択には、数学的操作とそのデータ依存関係の理解が必要です。行列乗算C = A @ Bは複数の有効なシャーディングを許可します:AとBの両方を複製して部分結果を計算する(計算前の通信)、Bを列方向にシャードして結果を収集する(計算後の通信)、またはAを行方向、Bを列方向にシャードして通信なしだがデバイス当たりの行列は小さくなる。¹³⁵
collective操作コストが最適戦略を決定します。All-reduceコストはテンソルサイズと線形にスケールしますが、ツリーベースまたはリングベースの削減アルゴリズムを使用してデバイス数とは準線形にスケールします:¹³⁶ All-gatherとreduce-scatterは異なるスケーリング特性を示します。コンパイラはこれらのコストをモデル化し、総通信時間を最小化するシャーディング戦略を選択します。
シーケンス並列性は大規模言語モデルにとって重要として浮上しています。アテンション機構は、キー・バリューキャッシュがシーケンス長とバッチサイズとともに増大するため、メモリボトルネックを作り出します。シーケンス次元に沿った分割は、アテンション計算自体にのみ通信を導入しながら、デバイス間でメモリ負担を分散します。¹³⁷
エキスパート並列性は、異なるエキスパートが異なるトークンを処理するMixture-of-Experts (MoE) モデルを処理します。シャーディング戦略は、すべてのデバイスで共有層を複製しますが、エキスパートを分割し、各トークンを指定されたエキスパートデバイスにルーティングします。¹³⁸ 動的ルーティングは、従来のcollective操作に挑戦する不規則な通信パターンを作り出し、レイテンシと負荷不均衡を最小化するための洗練されたランタイムシステムを必要とします。
オプティマイザー状態シャーディングは、大規模モデルのメモリオーバーヘッドを削減します。Adamのようなオプティマイザーは、すべてのパラメータに対してモメンタムと分散統計を保存し、パラメータ単体を超えてメモリ要件を3倍にします。パラメータを複製したままオプティマイザー状態をデバイス間でシャーディングすることで、固定メモリ予算内でより大きなモデルの訓練が可能になります。¹³⁹ この戦略は重み計算中にオプティマイザー状態更新を収集する必要がありますが、デバイス当たりのメモリフットプリントを大幅に削減します。
パフォーマンス分析とベンチマーキング
MLPerfの結果と競合他社との位置づけ
MLPerfは、トレーニングと推論のワークロードにおけるAIアクセラレータのパフォーマンスを測定する業界標準ベンチマークを提供しています。Googleは定期的にTPUの結果を提出し、競合他社に対抗するパフォーマンスを実証しており、世代を重ねるごとの進化により明確なアーキテクチャの改善が示されています。¹⁴⁰
TPU v5eは、MLPerfトレーニングの9カテゴリのうち8カテゴリで最高の結果を達成しました。¹⁴¹この幅広い成果は、大規模言語モデルを超えたアーキテクチャの汎用性を実証しており、コンピュータビジョン、推薦システム、科学計算ワークロードにおいて競争力のあるパフォーマンスを発揮しています。BERTトレーニングはNVIDIA A100 GPUより2.8倍高速に完了し、transformer最適化アーキテクチャの有効性を検証しました。¹⁴²
2025年6月に発表されたMLPerf Training v5.0では、スイート内で最大のモデルとなるLlama 3.1 405Bベンチマークが導入されました。¹⁴³このベンチマークは、これまでのテストよりもマルチノードスケーリング、通信オーバーヘッド、メモリ容量により大きな負荷をかけます。Google CloudはTPUによる提出で参加しましたが、詳細なパフォーマンス比較は公式結果の発表まで公開禁止となっています。
MLPerf Inference v5.0には4つの新しいベンチマークが含まれました:Llama 3.1 405B、低レイテンシアプリケーション用のLlama 2 70B、RGATグラフニューラルネットワーク、3Dオブジェクト検出用のPointPaintingです。¹⁴⁴この多様性により、アクセラレータは従来のtransformerワークロードを超えて、アーキテクチャの前提が異なる可能性のある新興アプリケーション領域へと押し進められています。
推論ベンチマークは特にTPUのアーキテクチャ上の強みを活用しています。バッチ推論ワークロードはMXUの大規模並列処理を活用し、transformer提供において競合アクセラレータより4倍高いスループットを実現しています。¹⁴⁵シングルクエリレイテンシは、TPUの決定論的実行とサーマルスロットリングの不存在により、一部のGPUデプロイメントを悩ませるパフォーマンスのばらつきなしに一貫したレイテンシを提供します。
エネルギー効率指標は、世代を重ねるごとにTPUの優位性が拡大していることを示しています。TPU v4はTPU v3より2.7倍優れたワットあたりパフォーマンスを実証し、Trilliumはv5eより67%改善しました。¹⁴⁶Ironwoodは絶対パフォーマンスが大幅に向上しているにもかかわらず、Trilliumより2倍優れたワットあたりパフォーマンスを主張しています。¹⁴⁷効率の向上は数千チップのポッド全体で複合的に作用し、データセンターの運用コストで数百万ドルの削減につながります。
実際のトレーニングと推論パフォーマンス
本番ワークロードは、合成ベンチマークでは見られないパフォーマンス特性を明らかにします。Googleは実際の使用パターンとスケーリング要件下でのTPUの動作を実証する社内サービスの結果を公開しています。¹⁴⁸
ResNet-50 ImageNetトレーニングはTPUポッドで28分で完了し、これはコンピュータビジョンワークロードパフォーマンスの広く引用されるベンチマークです。¹⁴⁹この時間対精度指標は、データロード、拡張、分散勾配同期、チェックポイント保存を含む完全なトレーニングプロセスをキャプチャします—単なる理論的なFLOPsではありません。
T5-3B言語モデルトレーニングは、transformerアーキテクチャにおけるTPUの優位性を実証しています。30億パラメータモデルはTPUポッドで12時間でトレーニングが完了し、同等のGPU構成の31時間と比較されます。¹⁵⁰この2.6倍の高速化は、ハードウェア加速アテンション演算、効率的なメモリ帯域幅利用、最適化された集合通信に由来します。
GPT-3スケールのワークロード(1750億パラメータ)は、同世代のGPUと比較してTPUで1.7倍高速な時間対精度を実現します。¹⁵¹このパフォーマンス格差は、メモリ容量と帯域幅が重要な制約となるさらに大きなモデルで広がります。Ironwoodの192GB HBM3eにより、低メモリの代替案では複雑なテンソル並列処理を必要とするモデルの提供が可能になります。
スケーリング効率の測定では、巨大なスケールまでほぼ線形な高速化が実証されています。Google Researchは、特定のtransformerトレーニングワークロードで32,768 TPUにおいて95%のスケーリング効率を報告しました。¹⁵²この指標は、32,768 TPUが完全な線形スケーリングが予測するパフォーマンスの95%を提供したことを意味します—スケールとともに通信オーバーヘッドが増加することを考慮すると驚くべきことです。
FLOPS利用率指標は、ワークロードが利用可能な計算をどの程度効果的に活用するかを明らかにします。Transformerモデルは通常TPUで90%のFLOPS利用率を実現し、これは理論的ピークパフォーマンスの90%が実際の作業に変換されることを意味します。¹⁵³高い利用率は、メモリボトルネックを排除する演算融合、大行列乗算におけるシストリックアレイ効率、無駄なサイクルを最小化するコンパイラ最適化に由来します。
本番推論サービスは、1日数十億クエリにわたって持続的なパフォーマンスを実証しています。Google TranslateはTPUで1日10億リクエストを処理しています。¹⁵⁴YouTubeの推薦システムはTPU加速モデルを使用して20億ユーザーにサービスを提供しています。¹⁵⁵Google Photosは検索と整理機能のために月間280億の画像を分析しています。¹⁵⁶この運用規模は、研究プロトタイプデプロイメントを超えた信頼性とコスト効率を検証しています。
エネルギー効率と総所有コスト
消費電力はデータセンターの運用コストと環境持続可能性に直接影響します。TPUの世代を重ねるエネルギー効率改善により、運用費用と大規模な炭素排出の両方が削減されます。¹⁵⁷
TPU v4は250W TDP仕様にもかかわらず、本番ワークロードで平均200Wの消費電力でした。¹⁵⁸平均と最大電力の間の余裕により、柔軟な熱設計とプロビジョニングが可能になります。継続ワークロードがしばしばTDP制限に達し、保守的なラック電力予算を必要とするGPUと対照的です。
Ironwoodの600W TDPは以前の世代より高い絶対電力を表しますが、ワットあたり劇的に多くの計算を提供します。¹⁵⁹チップあたり4.6 PFLOPS FP8パフォーマンスは約7.7 TFLOPSパーワットをもたらし—同等ワークロードにおいて現代のGPU効率と競合または上回ります。
データセンターの電力使用効率(PUE)は、チップレベルの効率を増幅します。GoogleのTPUデータセンターは1.1のPUEを実現し、冷却、電力変換、ネットワーキングのためのチップ消費を超える電力オーバーヘッドはわずか10%です。¹⁶⁰業界平均PUEは1.5から2.0の範囲で、インフラストラクチャオーバーヘッドに50-100%の追加電力が必要です。低PUEは、先進的な冷却システム、効率的な電力供給、MLワークロード用に最適化された意図的なデータセンター設計に由来します。
炭素強度の考慮は、電力を超えてエネルギー源を含みます。Googleは再生可能エネルギー調達と炭素オフセットプログラムを通じてカーボンニュートラル電力でTPUデータセンターを運営しています。¹⁶¹炭素会計は、クラウドコンピューティングからのScope 2排出を追跡する組織にとってますます重要になっています。
総所有コスト(TCO)分析は、取得コスト、消費電力、冷却要件、メンテナンス費用を考慮する必要があります。TPUデプロイメントは、主に優れたワットあたりパフォーマンスと冷却複雑性の軽減により、同等のGPUインストレーションと比較して通常20-30%のTCO削減を示します。¹⁶²
冷却インフラストラクチャコストは電力密度に対して非線形にスケールします。空冷ラックは通常、特殊冷却ソリューションが必要になる前に15-20kWパーラックでトップアウトします。高電力GPUはこれらの制限を押し上げ、時には大幅に高い資本・運用コストを持つ液冷インフラストラクチャを必要とします。TPUの効率により、より多くのデプロイメントが空冷範囲内に留まり、データセンター設計が簡素化されます。¹⁶³
技術的優位性:TPUが優れている分野
ハードウェア・アクセラレーテッド・コレクティブ・オペレーション
TPU ICIの専用コレクティブ・オペレーション・サポートは、従来のネットワーク・アクセラレーターに対する最も重要な優位性の一つを提供している。分散トレーニングにおいて勾配を同期するワークホース・オペレーションであるall-reduceは、同等のEthernet基盤のGPU実装よりもTPU ICIで10倍高速に実行される。¹⁶⁴
性能ギャップはアーキテクチャ統合に起因している。Ethernet基盤のコレクティブは複数レイヤーを通過する:アプリケーション・コードがコレクティブ・ライブラリ(NCCL、Horovodなど)を呼び出し、ネットワーク・スタックに渡されるパケットを生成し、データをNICに転送し、回線上でシリアル化し、スイッチを通過し、受信側NICでデシリアル化し、そのプロセスを逆転させる。各レイヤーがレイテンシを追加し、メモリ階層を通じてデータをコピーし、プロトコル処理のためのCPUサイクルを消費する。¹⁶⁵
TPU ICIはソフトウェア・レイヤーを通過せずにハードウェアでコレクティブを実装している。オペレーションはTensorCoreから直接開始し、専用のICIリンク経由でデータをストリーミングし、ホストCPUを介在させずに完了する。直接ハードウェア・パスは、従来の実装を支配するオーバーヘッドを排除する。¹⁶⁶
光回路スイッチ・トポロジーは最適なコレクティブ・アルゴリズムを可能にする。リングベースのall-reduceはNデバイスに対してわずか2(N-1)メッセージしか必要とせず、トーラス・トポロジーは最短パス・ルーティングを提供し、レイテンシを最小化する。¹⁶⁷ 均一な二分帯域幅は、不適切にルーティングされたコレクティブがネットワーク・リンクを輻輳させるホットスポットを防ぐ。
統合メモリ空間と簡素化されたプログラミング
TPUの統合メモリ・モデルは、GPUの複雑なメモリ階層と比較してプログラミングを簡素化する。プログラマーはホストRAM、GPUグローバル・メモリ、共有メモリ、レジスタ・ファイル間の転送を管理するのではなく、単一のHBMプールについて考えるだけで済む。簡素化されたモデルはバグを削減し、開発速度を向上させる。¹⁶⁸
メモリ・フラグメンテーションは懸念事項として消失する。GPUは断片化されたヒープからメモリを割り当て、時間の経過とともに割り当てと解放がコンパクションを必要とする穴を作成する。コンパイラーの静的解析によるTPUメモリ管理は、ランタイム・フラグメンテーションを完全に回避する—テンソルは計算グラフに基づいて事前に決定された場所に割り当てられる。¹⁶⁹
プログラミング・モデルはCUDAエラーのクラス全体を排除する。不正なポインタ演算による「illegal memory access」、CPUとGPU間のキャッシュ・コヒーレンシ・バグ、cudaDeviceSynchronize()呼び出しの欠如による同期エラーがもはや発生しない。高レベル抽象化はCUDAプログラミングにおける一般的なフットガンを防ぐ。¹⁷⁰
決定論的実行と再現性
浮動小数点の非結合性は、並列コンピューティングにおいて再現性の課題を作成する。式(a + b) + cは、丸め誤差により、a + (b + c)とは異なる結果を生成する可能性があり、並列リダクションは競合状態に依存して実行間で異なる順序で合計する場合がある。¹⁷¹
TPU実行は典型的なGPU実装よりも強い決定論を示す。シストリック・アレイの固定データフロー・パターンは、実行間で同一のオペレーション順序を保証する。コレクティブ・オペレーションは、到着順序に基づく日和見的集約ではなく、決定論的リダクション・ツリーに従う。予測可能性により、同一のハイパーパラメータとデータがビット同一のモデル重みを生成する再現可能なトレーニングが可能になる。¹⁷²
決定論からのデバッギングの恩恵は非常に大きい。非決定論的トレーニングは失敗の根本原因究明をほぼ不可能にする—NaNは本物のアルゴリズム・バグによるものなのか、ランダムな競合状態によるものなのか?決定論的実行は失敗が確実に再現されることを意味し、体系的なデバッギング・アプローチを可能にする。¹⁷³
科学計算アプリケーションは特に再現性を重視する。気候モデル、創薬シミュレーション、物理研究は、異なる研究者が同一の結果を再現できる検証可能な結果を必要とする。TPUの決定論は、競合する非決定論的代替案よりも科学的方法をよりよくサポートする。¹⁷⁴
コンパイラー最適化と開発者生産性
XLAのアグレッシブな最適化は、手動チューニングなしに「すぐに使える」状態で大幅な性能改善を提供する。研究者は、eager実行フレームワークと比較して、コンパイルだけでモデル・スループットが40%改善されると報告している。¹⁷⁵ 性能は無料で得られる—カーネル・エンジニアリングは不要である。
融合最適化は特に開発者に利益をもたらす。CUDAでのオペレーションの手動融合は、カスタム・カーネルの記述、正確性のテスト、フレームワーク・バージョン間でのコード保守を要求する。XLAは自動的にオペレーションを融合し、更新し、モデルの進化に応じて融合戦略を適応させ、保守負荷を排除する。¹⁷⁶
レイアウト変換自動化は数週間の手動最適化を節約する。GPUに対する最適テンソル・レイアウトの決定は、異なる配置のプロファイリング、転置の手動挿入、メモリ割り当てパターンの慎重な管理を要求する。XLAは自動的にレイアウトを試行し、最高速を選択し、開発者が低レベル性能エンジニアリングではなくモデル・アーキテクチャに集中できるようにする。¹⁷⁷
生産性向上は研究チームに対して複合的な効果をもたらす。インフラストラクチャ最適化で節約された時間は科学的進歩を加速し、より多くの実験とより高速な反復サイクルを可能にする。組織は、GPU CUDAプログラミングからTPU JAXベース・ワークフローに移行する際に3倍の開発速度改善を報告している。¹⁷⁸
技術的制限とデメリット
プラットフォームロックインとオンプレミス制約
TPUアクセスはGoogle Cloud Platformを通してのみ利用可能で、オンプレミスデプロイメントを妨げ、ベンダーロックインの懸念を引き起こしている。¹⁷⁹ データ主権要件、エアギャップネットワーク、またはパブリッククラウドに対するポリシーを持つ組織は、技術的優位性に関係なくTPUを活用できない。
AIが重要なインフラとなるにつれて、この制約はますます重要になっている。単一のクラウドプロバイダーへの依存は事業継続リスクを生み出す—価格変更、可用性の中断、またはサービス終了により、コストのかかる移行を余儀なくされる可能性がある。¹⁸⁰ GPU(NVIDIA ハードウェアがAWS、Azure、GCP、およびオンプレミスで動作)の複数ベンダーからの利用可能性は、TPUアーキテクチャが構造的に排除する選択肢を提供する。
マルチクラウド戦略は摩擦に遭遇する。TPUを標準化する組織は、モデルの再トレーニングや異なるアクセラレータアーキテクチャ用の別々のコードベースを維持することなく、他のクラウドに簡単にバーストしたり、マルチクラウド冗長性を実装したりできない。¹⁸¹ GPU/TPUハイブリッドデプロイメントの運用複雑性は、最適なアクセラレータ選択によるコスト削減を上回ることが多い。
CUDAエコシステム成熟度のギャップ
NVIDIAのCUDAプラットフォームは、15年以上のエコシステム開発、ライブラリ、ドキュメント、およびコミュニティ知識を蓄積しており、TPUは匹敵できない。¹⁸² この成熟度ギャップは、TPU採用における数多くの問題点として現れている。
ライブラリの利用可能性は圧倒的にCUDAに有利である。コンピュータグラフィックス、分子動力学、計算流体力学、ゲノミクスなどの専門分野は、過去数十年にわたって数千のCUDA最適化ライブラリを蓄積してきた。TPU相当品はしばしば存在せず、CPU フォールバック(パフォーマンスを破壊する)または数ヶ月の移植作業が必要となる。¹⁸³
コミュニティサポートは桁違いに異なる。Stack OverflowにはCUDAに関する何十万もの詳細な回答を含む質問がある—GitHubリポジトリは数百万に及ぶ。カンファレンストーク、学術論文、ブログ投稿は主にCUDAプログラミングに焦点を当てている。TPUプログラマーは比較的希少なリソース、長いデバッグサイクル、相談できる専門家の少なさに直面している。¹⁸⁴
教育資料とチュートリアルは圧倒的にCUDAをターゲットとしている。大学のコースはCUDAを使用してGPUプログラミングを教える。オンラインコースはCUDAに焦点を当てている。人材パイプラインはTPUエキスパートよりもはるかに多くのCUDA経験エンジニアを生み出し、採用とトレーニングの課題を生み出している。¹⁸⁵
カスタムカーネル開発はエコシステムギャップの典型例である。最適化されたCUDAカーネルの記述は依然として簡単ではないが、豊富なドキュメント、プロファイリングツール、サンプルコードの恩恵を受けている。PallasはカスタムTPUカーネルを可能にするが、ツールの成熟度が低く、知識ベースが小さい。学習曲線は最もパフォーマンス重視の最適化以外を躊躇させる。¹⁸⁶
ワークロード専門化と柔軟性制約
TPUのアーキテクチャは特定のワークロードパターン—主に正規アクセスパターンと大きなバッチサイズを持つ密な行列乗算—に最適化されている。スイートスポット外の操作はパフォーマンスの断崖に遭遇する。¹⁸⁷
動的形状はTPU実行モデルに挑戦する。XLAコンパイラは最適化とコード生成のために固定テンソル次元を仮定する。可変シーケンス長、動的制御フロー、またはデータ依存形状を持つモデルは、最大サイズへのパディング(計算とメモリの無駄)または各異なる形状の再コンパイル(パフォーマンスの破壊)を必要とする。¹⁸⁸
スパース操作はSparseCoreにもかかわらず限定的なサポートを受ける。科学計算とグラフニューラルネットワークで一般的なワークロードであるスパース行列-行列乗算は、MXUまたはVPUでの効率的な実装を欠いている。特化されたSparseCoreは埋め込みテーブルを処理するが、一般的なスパース線形代数は処理しない。¹⁸⁹
小バッチ推論はTPUの並列リソースを十分活用しない。256×256シストリックアレイは、グリッドを生産的作業で満たす大きな行列で威力を発揮する。単一クエリ推論は大部分のMACをアイドル状態にし、低バッチシナリオ用に最適化されたGPU代替品よりもクエリあたりのレイテンシとコストが悪化する。¹⁹⁰
不規則な計算パターンはシストリックアレイ効率を破る。予測不可能な分岐、再帰構造、またはポインタチェイシングメモリアクセスを持つアルゴリズムは、固定データフローがランタイム依存動作に適応できないため、TPUパフォーマンスが低下する。¹⁹¹
非MLワークロードがTPUアクセラレーションの恩恵を受けることは稀である。科学シミュレーション、ビデオエンコーディング、ブロックチェーン検証、レンダリングはすべて、TPUが行列操作でより高いピークFLOPsを持つにもかかわらず、GPUのより汎用的なアーキテクチャでより高速に動作する。¹⁹²
デバッグと開発ツールのギャップ
NVIDIAのエコシステムには、数十年にわたって洗練された成熟したプロファイリングツール(Nsight Systems、Nsight Compute、nvprof)、デバッガー(cuda-gdb)、分析フレームワークが含まれている。TPUツールは存在するが、洗練度において大幅に遅れている。¹⁹³
XProfはTensorBoard統合を通じて基本的なプロファイリングを提供するが、NVIDIAツールが公開する粒度の細かいハードウェアカウンタアクセスを欠いている。キャッシュミス率、占有率、ワープダイバージェンス、またはメモリバンク競合の理解—すべて重要なGPU最適化メトリクス—は、アーキテクチャが根本的に異なるため、TPU相当品が存在しない。¹⁹⁴
エラーメッセージはしばしば根本原因を曖昧にする。XLAコンパイル失敗は形状の不一致またはサポートされていない操作について暗号的なメッセージを生成し、解決への明確なガイダンスがない。CUDAエラーは不親切さで悪名高いが、15年のStackOverflow説明と部族知識の恩恵を受けている。¹⁹⁵
マルチチップポッドでの分散トレーニングのデバッグは、特殊ツールなしには不可能に近づく。競合状態、勾配同期バグ、集合操作失敗は、一貫性なく再現し、系統的診断に抵抗する非決定論的エラー(皮肉にも、TPUの決定論的利点にもかかわらず)として現れる。¹⁹⁶
複雑なモデルでは反復ループが痛々しく拡張される。形状変更またはアーキテクチャ変更の再コンパイルに数分を要することがあり、コンパイラが処理している間開発を凍結する。CUDAのイーガー実行モデルは、ピークパフォーマンスが低いにもかかわらず、より高速な反復を可能にする。¹⁹⁷
実用的な展開:本格的なプロダクション規模
Anthropic Claude:マルチプラットフォーム戦略
Anthropicが2025年10月に発表した100万個を超えるTPUチップの展開は、AI向けアクセラレータとして公開された史上最大のコミットメントを表している。¹⁹⁸同社は、将来のClaudeモデルの学習と提供専用として、2026年にオンライン化予定の1ギガワットを大幅に超える計算能力にアクセスすることを計画している。
その規模は、過去の展開を桁違いに凌駕している。100万個のチップをIronwood TPUとして構成した場合、約4.6エクサフロップスのFP8計算を提供することになり、これは5年前のTop500スーパーコンピュータリスト全体の合計性能の40倍以上である。¹⁹⁹このコミットメントは、これまでSF小説のような規模と考えられていたフロンティアモデル開発におけるTPUアーキテクチャへの信頼を示している。
Anthropicは、Google TPU、Amazon Trainium、NVIDIA GPUを横断する意図的なマルチプラットフォームハードウェア戦略を追求している。²⁰⁰この多様化により、容量保険、価格交渉力、地理的分散が提供される。Claudeは3つのプラットフォーム全てからの展開によりグローバルに提供され、リクエストルーティングは容量の可用性と地域の遅延要件に基づいて行われる。
同社の2025年8月の技術事後検証では、大規模展開における複雑さが明らかになった。Claude API TPUサーバーの設定ミスにより、トークン生成エラーが発生し、英語プロンプトにおいてタイ語や中国語の文字に予期せず高い確率を割り当てることが時々あった。²⁰¹この事件は、単純なエラーでさえ、1日数十億のトークンを処理するシステム全体で予測不能に波及することを実証した。
別の展開では、Claude Haiku 3.5に影響するXLA: TPUコンパイラの潜在的なバグが引き起こされた。このバグは、特定のモデルアーキテクチャとコンパイラフラグの組み合わせが欠陥を露呈するまで、数ヶ月間検出されずに存在していた。²⁰²この発見は、本番環境での展開が開発環境やステージング環境では見つからないコーナーケースを発見することを強調している。
Anthropicのエンジニアは、主要な選択基準としてTPUの価格性能と効率性を挙げた。説得力のある経済性により、固定予算内でより大規模な実験を可能にすることで開発を加速している。²⁰³より大きなモデルの学習、より多くのハイパーパラメータ設定の探索、より高速な反復はすべて、FLOP当たりのコストを削減することから生まれている。
Google Gemini:創設時からTPU向けに設計
GoogleのGeminiモデルは、TPU上でのみ学習と提供を行い、アーキテクチャと学習手順は最初からTPUの特性に合わせて共同設計されている。²⁰⁴この密結合により、クロスプラットフォームモデルでは活用できないTPU固有の最適化を利用することが可能になっている。
Geminiの展開では、最も重要なモデルバリアントの学習と提供に50,000個のTPU v6eチップを使用していると報告されている。²⁰⁵この巨大なPod規模には高度なオーケストレーションが必要である—数千のチップ間でのジョブスケジューリング、ボトルネックを防ぐためのチェックポイント調整、失われた作業を最小限に抑える障害復旧、障害が拡散する前に劣化したノードを特定するリアルタイム監視。
GoogleはTrillium TPU上でGemini 2.0を学習し、フロンティアモデル開発における第6世代アーキテクチャを検証した。²⁰⁶この学習実行では、前例のないチップ数への拡張効率性を実証し、通信オーバーヘッドが支配的になる典型的な停滞点を超えて強力なスケーリングを達成した。
モデル提供インフラストラクチャは、TPU推論最適化を特に活用している。バッチ処理により複数のユーザーリクエストを集約し、MXU利用率を最大化している。キーバリューキャッシュ管理はHBM容量を活用し、ディスクスワッピングなしで長期間のコンテキスト処理を可能にしている。このアーキテクチャは、大規模なグローバルリクエスト量を処理しながら、複雑なクエリに対してサブ秒の応答時間を提供している。²⁰⁷
本番監視システムは、50,000個以上のTPUを継続的に追跡し、モデル品質や可用性を低下させる可能性のある異常を検出している。²⁰⁸テレメトリは、エラー率、遅延パーセンタイル、スループット、メモリ圧迫、すべてのチップの熱特性をキャプチャしている。機械学習モデルがテレメトリストリーム自体を分析し、障害が発生する前に予測して予防的メンテナンスをトリガーしている。
その他の本番環境での展開
MidjourneyはGPUからTPUインフラストラクチャに移行し、画像生成ワークロードにおいて65%のコスト削減と40%の遅延改善を達成した。²⁰⁹このアート生成サービスは、ピーク負荷時に1分間に300,000枚の画像を処理し、大規模な計算スループットと急激なトラフィックパターン下での一貫したパフォーマンスを必要としている。
CohereのTPU上での言語モデルは、従来のGPU展開の3倍のスループットを達成した。²¹⁰この高速化により、同じインフラストラクチャフットプリントからより多くの顧客にサービスを提供することが可能になり、ビジネス経済性を直接的に改善した。同社はJAXのSPMD機能を活用して、TPU Pod全体でモデルを効率的に並列化した。
Snapは、拡張現実機能、推薦システム、創造的AIツールをサポートする10,000個のTPU v6eチップの容量を確保した。²¹¹この展開は複数の地理的地域にまたがり、Snapchatのグローバルユーザーベースに対する低遅延を確保しながら、地域間でのモデル一貫性を維持している。
学術機関はますますTPUを研究に採用している。TPU Research Cloud(TRC)プログラムは研究者に無料のTPUアクセスを提供し、以前は資金豊富な企業研究所のみがアクセス可能だった規模での実験を可能にしている。²¹²この民主化により、AIの能力と限界に関する基本的な問題を調査する学術研究者のハードウェア障壁が取り除かれ、科学的進歩が加速されている。
デバッグ、プロファイリング、パフォーマンス最適化
XProfとTensorBoard統合
XProfはTPUワークロードの主要なプロファイリングツールであり、CPU、GPU、TPU全体でJAX、PyTorch/XLA、TensorFlowプログラムのパフォーマンス解析を提供します。²¹³このツールはTensorBoardと統合して可視化を行い、MLエンジニアが既に理解している馴染みのあるインターフェースでプロファイリングデータを提示します。
インストールにはTensorBoardプラグインが必要です:pip install tensorboard_plugin_profile tensorboard。これにより完全なツールチェーンが有効になります。²¹⁴TPU VMでのプロファイリング実行には、トレーニングや推論中にトレースをキャプチャし、結果をTensorBoardにアップロードし、可視化を解析してボトルネックを特定することが含まれます。
Overview Pageは高レベルのパフォーマンスサマリメトリクスを提供し、ステップ時間の内訳、デバイス利用率、トップレベルのボトルネック識別が含まれます。²¹⁵このページは、ワークロードが計算律速(MXUが継続的に動作)、メモリ律速(HBM転送を待機)、通信律速(集約操作でブロック)のいずれかを即座に強調表示します。
Trace ViewerとTimeline解析
Trace Viewerは詳細なタイムライン可視化を表示し、操作がいつ実行されるか、データ転送がいつ発生するか、アイドル時間がどこに蓄積されるかを正確に示します。²¹⁶Chrome ベースのインターフェースにより、マイクロ秒解像度までズームが可能で、集計メトリクスでは隠れてしまう正確なスケジューリング動作を明らかにします。
トレースを理解するには、一般的なパターンを認識する必要があります。操作間の長いギャップは、コンパイルオーバーヘッド、データロードのボトルネック、または最適化が不十分なデータパイプラインによるPythonオーバーヘッドを示します。小さな操作の繰り返しは融合が不十分であることを示唆します。数ミリ秒にわたる集約操作は、通信の非効率性や不適切なシャーディング戦略を指しています。²¹⁷
色分けにより操作タイプが区別されます:計算は緑、メモリ転送は青、通信はオレンジ、アイドル時間は赤です。最適化されたワークロードは、赤いギャップが最小の密にパックされた色付きブロックを表示します。最適化が不十分なコードは、リソースの無駄を示す長い赤いストレッチを持つ疎なタイムラインを示します。²¹⁸
高度な使用方法では、タイムライン動作をソースコードと関連付けます。PyTorch/XLAは、トレースに表示されるコードに挿入されたユーザーアノテーションをサポートし、パフォーマンス動作を特定のモデルコンポーネントにマッピングできます。²¹⁹アノテーションは、不透明なトレースを、どのレイヤーや操作に最適化の焦点を当てるべきかについてのアクショナブルな洞察に変換します。
Memory Profile ToolとOOMデバッグ
Out-of-memory(OOM)エラーは大型モデル開発を悩ませます。Memory Profile Toolは実行中のデバイスメモリ使用量を監視し、OOM障害につながるピーク利用率と割り当てパターンをキャプチャします。²²⁰
このツールは時間経過とともにメモリ消費を可視化し、どのテンソルが最も容量を消費し、ピーク使用量がいつ発生するかを示します。この可視化はしばしば驚くべき割り当てを明らかにします—予想より大きい勾配バッファ、チェックポイントすべき活性化メモリ、またはXLAが除去に失敗した一時テンソルです。²²¹
デバッグ戦略には、複数の技術を通じてメモリフットプリントを反復的に削減することが含まれます。勾配チェックポイントは、活性化を保存するのではなく、逆方向パス中に再計算します。オプティマイザ状態シャーディングは、Adamモメンタムと分散をデバイス間で分散します。混合精度はFP32と比較してメモリを2倍削減します。マイクロバッチングは、1つの大きなバッチではなく、小さなバッチを順次処理します。²²²
高度なメモリ最適化には、コンパイラの決定を理解することが必要です。xla_dump_toフラグは、XLAが計算グラフをどのように変換したかを示す中間表現をエクスポートします。IRを解析することで、融合が成功したかどうか、不要なコピーがどこで発生するか、どの操作が予想より多くのメモリを割り当てるかが明らかになります。²²³
Input Pipeline Analyzer
CPU前処理は頻繁にTPUトレーニングのボトルネックとなります。Input Pipeline Analyzerは、データロードがアクセラレータの消費に追いついているか、またはTPUがバッチを待ってアイドル状態になっているかを特定します。²²⁴
このツールは、ホスト側の解析(CPU前処理、データ拡張、バッチアセンブリ)をデバイス側の実行(実際のTPU計算)から分離します。入力律速のワークロードは、データロード中にデバイス利用率が低下し、CPU利用率がピークに達することを示します。計算律速のワークロードは、CPUが快適に追いつきながら高いデバイス利用率を維持します。²²⁵
最適化戦略はボトルネックの位置に依存します。遅いホスト前処理は、より多くのCPUコア間でのデータロードの並列化、サンプルあたりの拡張複雑性の削減、または消費に先立つバッチのプリフェッチから恩恵を受けます。デバイス側のボトルネックには、データパイプラインの調整ではなく、モデルアーキテクチャの変更、より良い融合、またはシャーディング調整が必要です。²²⁶
## Tensor Processing Unitの未来
Googleの7世代にわたるアーキテクチャの進化は、専用AI アクセラレータにおける継続的な革新を実証している。IronwoodのFP8サポート、大容量メモリ、そして9,216チップのスーパーポッドスケーリングは、将来の開発軌道を示唆している。²²⁷
精度の削減は、特定の操作において FP4 またはさらに低い精度へと継続される可能性が高い。新たな研究では、多くのニューラルネットワーク操作が注意深い学習手順により極端な量子化に耐えられることが実証されている。将来の TPU は、FP4 フォワードパス、FP8 バックワードパス、および FP32 オプティマイザーアップデートを持つ混合精度システムを実装する可能性がある。²²⁸
メモリ容量はモデルサイズの成長と競争状態にある。現在の最先端モデルはすでにアクセラレータメモリを圧迫しており、高度な並列化戦略を必要としている。次世代 TPU は、3D XPoint や抵抗変化メモリなどの不揮発性メモリ技術を統合し、DRAM の消費電力なしにテラバイト規模のオンパッケージメモリを可能にするかもしれない。²²⁹
光インターコネクトは、回路スイッチングを超えて光コンピューティング要素を含むまでに拡張される可能性がある。研究では、最小限の電力で光速で実行される フォトニック行列乗算が探求されており、特定の操作において電子システム アレイを光コプロセッサで補強する可能性がある。²³⁰
スパース性サポートは、埋め込みを超えて一般的なスパース線形代数まで拡張される可能性が高い。ニューラルネットワークプルーニング技術は、品質を損なうことなく90%以上の重みをゼロにできることを実証している。将来のアーキテクチャは、明示的に計算して破棄するのではなく、ゼロ値の計算をネイティブにスキップする可能性がある。²³¹
TPU の成功の根底にあるアーキテクチャ原則—ドメイン特化、カスタムインターコネクト、共設計ソフトウェアスタック、ビルディング規模のオーケストレーション—は、ますます特化されたアクセラレータの未来を指し示している。万能プロセッサではなく、学習対推論、畳み込みネットワーク対トランスフォーマー、密対疎モデル、短対長シーケンス用に最適化されたアクセラレータが見られるかもしれない。²³²
今日 AI インフラストラクチャを構築するエンジニアは、TPU アーキテクチャを深く理解すべきである。Google Cloud へのデプロイ、アクセラレータ市場での Google との競争、次世代 ML システムの設計のいずれにおいても、TPU に体現された設計原則とトレードオフは、AI ワークロードがハードウェアに求める根本的な真実を明らかにしている。システムアレイ数学、メモリ階層設計、インターコネクトトポロジー、コンパイラ最適化戦略は、TPU 自体を遥かに超えて適用可能な数十年にわたる蓄積された知恵を表している。
TPU 対 GPU を定義する特化と汎用性の間の緊張は、無期限に持続するだろう。TPU は狭いワークロードでの極度の効率のために柔軟性を犠牲にしている。GPU はより広い適用性のためにピーク効率を犠牲にしている。どちらのアプローチも支配的ではない—最適な選択は、ワークロードの特性、規模、コスト制約、および運用要件に完全に依存している。大規模で AI を成功させる組織は、単一プラットフォームに標準化するのではなく、アクセラレータアーキテクチャをワークロード要求に合わせる異種戦略をますます採用している。
Anthropic の TPU への100万チップのコミットメントは、このアーキテクチャが最高規模で本格運用の成熟度を達成したことを実証している。2026年にオンラインになる数ギガワットの展開は、AI が達成できることの境界を押し広げるモデルを学習し、それらのモデルを可能にするインフラストラクチャは、少数の組織しか匹敵していないエンジニアリングの洗練を体現している。システムアレイ内の65,536個の積和演算ユニットが最先端モデルの学習でどのように協力するかを理解することは、AI の未来について真剣に考える人にとって重要である。
参考文献
-
Google Cloud Press Corner, "Anthropic to Expand Use of Google Cloud TPUs and Services," October 23, 2025, https://www.googlecloudpresscorner.com/2025-10-23-Anthropic-to-Expand-Use-of-Google-Cloud-TPUs-and-Services.
-
TrendForce, "Google Unveils 7th-Gen TPU Ironwood with 9,216-Chip Superpod, Taking Aim at NVIDIA," November 7, 2025, https://www.trendforce.com/news/2025/11/07/news-google-unveils-7th-gen-tpu-ironwood-with-9216-chip-superpod-taking-aim-at-nvidia/.
-
Norman P. Jouppi et al., "TPU v4: An Optically Reconfigurable Supercomputer for Machine Learning with Hardware Support for Embeddings," in Proceedings of the 50th Annual International Symposium on Computer Architecture (2023), arXiv:2304.01433.
-
Anthropic, "Expanding our use of Google Cloud TPUs and Services," Anthropic News, October 2025, https://www.anthropic.com/news/expanding-our-use-of-google-cloud-tpus-and-services.
-
Google Cloud Blog, "Quantifying the performance of the TPU, our first machine learning chip," April 2017, https://cloud.google.com/blog/products/gcp/quantifying-the-performance-of-the-tpu-our-first-machine-learning-chip.
-
Norman P. Jouppi et al., "In-Datacenter Performance Analysis of a Tensor Processing Unit," Proceedings of the 44th Annual International Symposium on Computer Architecture (2017), arXiv:1704.04760.
-
Jouppi et al., "In-Datacenter Performance Analysis."
-
Jouppi et al., "In-Datacenter Performance Analysis."
-
Jonathan Hui, "AI Chips: Google TPU," Medium, accessed December 2025, https://jonathan-hui.medium.com/ai-chips-tpu-3fa0b2451a2d.
-
Wikipedia, "Bfloat16 floating-point format," accessed December 2025, https://en.wikipedia.org/wiki/Bfloat16_floating-point_format.
-
Henry Ko, "TPU Deep Dive," personal blog, accessed December 2025, https://henryhmko.github.io/posts/tpu/tpu.html.
-
Wikipedia, "Tensor Processing Unit," accessed December 2025, https://en.wikipedia.org/wiki/Tensor_Processing_Unit.
-
Wikipedia, "Tensor Processing Unit."
-
Wikipedia, "Tensor Processing Unit."
-
Ko, "TPU Deep Dive."
-
Jouppi et al., "TPU v4: An Optically Reconfigurable Supercomputer."
-
Jouppi et al., "TPU v4: An Optically Reconfigurable Supercomputer."
-
Jouppi et al., "TPU v4: An Optically Reconfigurable Supercomputer."
-
Jouppi et al., "TPU v4: An Optically Reconfigurable Supercomputer."
-
OpenXLA Project, "A deep dive into SparseCore for Large Embedding Models (LEM)," accessed December 2025, https://openxla.org/xla/sparsecore.
-
JAX Scaling Guide, "How to Think About TPUs," accessed December 2025, https://jax-ml.github.io/scaling-book/tpus/.
-
JAX Scaling Guide, "How to Think About TPUs."
-
Ko, "TPU Deep Dive."
-
JAX Scaling Guide, "How to Think About TPUs."
-
Google Cloud Blog, "Introducing Trillium, sixth-generation TPUs," May 2024, https://cloud.google.com/blog/products/compute/introducing-trillium-6th-gen-tpus.
-
Google Cloud Blog, "Introducing Trillium."
-
Google Cloud Blog, "Introducing Trillium."
-
Google Cloud Blog, "Introducing Trillium."
-
Google Cloud Blog, "Introducing Trillium."
-
Google Blog, "Ironwood: The first Google TPU for the age of inference," November 2025, https://blog.google/products/google-cloud/ironwood-tpu-age-of-inference/.
-
XPU.pub, "Google Adds FP8 to Ironwood TPU; Can It Beat Blackwell?" April 16, 2025, https://xpu.pub/2025/04/16/google-ironwood/.
-
TrendForce, "Google Unveils 7th-Gen TPU Ironwood."
-
The Register, "Google's 7th-gen Ironwood TPUs promise 42 AI exaFLOPS pods," April 10, 2025, https://www.theregister.com/2025/04/10/googles_7thgen_ironwood_tpus_debut/.
-
TrendForce, "Google Unveils 7th-Gen TPU Ironwood."
-
Ko, "TPU Deep Dive."
-
XPU.pub, "Google Adds FP8 to Ironwood TPU."
-
Google Cloud Press Corner, "Anthropic to Expand Use."
-
Telesens, "Understanding Matrix Multiplication on a Weight-Stationary Systolic Architecture," July 30, 2018, https://telesens.co/2018/07/30/systolic-architectures/.
-
Telesens, "Understanding Matrix Multiplication."
-
Jouppi et al., "In-Datacenter Performance Analysis."
-
Telesens, "Understanding Matrix Multiplication."
-
CP Lu, "Should We All Embrace Systolic Arrays?" Medium, accessed December 2025, https://cplu.medium.com/should-we-all-embrace-systolic-array-df3830f193dc.
-
Google Cloud Documentation, "TPU architecture," accessed December 2025, https://docs.cloud.google.com/tpu/docs/system-architecture-tpu-vm.
-
Google Cloud Documentation, "TPU architecture."
-
Hui, "AI Chips: Google TPU."
-
Telnyx, "Architecture insights: MXU and TPU components," accessed December 2025, https://telnyx.com/learn-ai/mxu-tpu.
-
Ko, "TPU Deep Dive."
-
Jouppi et al., "TPU v4: An Optically Reconfigurable Supercomputer."
-
SemiEngineering, "Tensor Processing Unit (TPU)," accessed December 2025, https://semiengineering.com/knowledge_centers/integrated-circuit/ic-types/processors/tensor-processing-unit-tpu/.
-
TrendForce, "Google Unveils 7th-Gen TPU Ironwood."
-
SemiEngineering, "Tensor Processing Unit (TPU)."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Google Cloud Documentation, "Cloud TPU performance guide," accessed December 2025, https://cloud.google.com/tpu/docs/performance-guide.
-
OpenXLA Project, "A deep dive into SparseCore."
-
OpenXLA Project, "A deep dive into SparseCore."
-
OpenXLA Project, "A deep dive into SparseCore."
-
Jouppi et al., "TPU v4: An Optically Reconfigurable Supercomputer."
-
OpenXLA Project, "A deep dive into SparseCore."
-
Jouppi et al., "TPU v4: An Optically Reconfigurable Supercomputer."
-
OpenXLA Project, "A deep dive into SparseCore."
-
JAX Scaling Guide, "How to Think About TPUs."
-
JAX Scaling Guide, "How to Think About TPUs."
-
JAX Scaling Guide, "How to Think About TPUs."
-
Ko, "TPU Deep Dive."
-
JAX Scaling Guide, "How to Think About TPUs."
-
JAX Scaling Guide, "How to Think About TPUs."
-
TrendForce, "Google Unveils 7th-Gen TPU Ironwood."
-
Ko, "TPU Deep Dive."
-
Anthropic, "Expanding our use of Google Cloud TPUs."
-
Jouppi et al., "TPU v4: An Optically Reconfigurable Supercomputer."
-
Jouppi et al., "TPU v4: An Optically Reconfigurable Supercomputer."
-
Jouppi et al., "TPU v4: An Optically Reconfigurable Supercomputer."
-
Jouppi et al., "TPU v4: An Optically Reconfigurable Supercomputer."
-
Ko, "TPU Deep Dive."
-
Jouppi et al., "TPU v4: An Optically Reconfigurable Supercomputer."
-
Leon Poutievski, "Mission Apollo: Landing Optical Circuit Switching at Datacenter Scale," LinkedIn, June 2022, https://www.linkedin.com/posts/leon-poutievski-8910a851_mission-apollo-landing-optical-circuit-switching-activity-6968472071534235649-cB4l.
-
Ko, "TPU Deep Dive."
-
Jouppi et al., "TPU v4: An Optically Reconfigurable Supercomputer."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Jouppi et al., "TPU v4: An Optically Reconfigurable Supercomputer."
-
JAX Scaling Guide, "How to Think About TPUs."
-
TrendForce, "Google Unveils 7th-Gen TPU Ironwood."
-
TrendForce, "Google Unveils 7th-Gen TPU Ironwood."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
OpenXLA Project, "XLA: Optimizing Compiler for Machine Learning," accessed December 2025, https://openxla.org/xla.
-
Daniel Snider and Ruofan Liang, "Operator Fusion in XLA: Analysis and Evaluation," academic paper, accessed December 2025, https://danielsnider.ca/papers/Operator_Fusion_in_XLA_Analysis_and_Evaluation.pdf.
-
Snider and Liang, "Operator Fusion in XLA."
-
APXML, "Memory-Aware Data Layout Transformations (NCHW/NHWC)," accessed December 2025, https://apxml.com/courses/compiler-runtime-optimization-ml/chapter-3-advanced-graph-level-optimizations/memory-aware-layout-transformations.
-
OpenXLA Project, "XLA."
-
PyTorch Documentation, "Pytorch/XLA Overview," accessed December 2025, https://docs.pytorch.org/xla/master/learn/xla-overview.html.
-
OpenXLA Project, "A deep dive into SparseCore."
-
Mangpo Phothilimthana et al., "A Flexible Approach to Autotuning Multi-Pass Machine Learning Compilers," PACT 2021, accessed December 2025, https://mangpo.net/papers/xla-autotuning-pact2021.pdf.
-
JAX Documentation, "Introduction to parallel programming," accessed December 2025, https://docs.jax.dev/en/latest/sharded-computation.html.
-
GitHub, "jax-ml/jax: Composable transformations of Python+NumPy programs," accessed December 2025, https://github.com/jax-ml/jax.
-
OpenXLA Project, "Shardy Guide for JAX Users," accessed December 2025, https://openxla.org/shardy/getting_started_jax.
-
JAX Documentation, "Introduction to parallel programming."
-
OpenXLA Project, "Shardy Guide for JAX Users."
-
OpenXLA Project, "Shardy Guide for JAX Users."
-
JAX Documentation, "Introduction to parallel programming."
-
OpenXLA Project, "Shardy Guide for JAX Users."
-
PyTorch Documentation, "Pytorch/XLA Overview."
-
GitHub, "RFC: Evolving PyTorch/XLA for a more native experience on TPU," Issue #9684, accessed December 2025, https://github.com/pytorch/xla/issues/9684.
-
Google Cloud Blog, "PyTorch/XLA 2.4 improves Pallas and adds 'eager mode,'" accessed December 2025, https://cloud.google.com/blog/products/ai-machine-learning/pytorch-xla-2-4-improves-pallas-and-adds-eager-mode/.
-
PyTorch Documentation, "Pytorch/XLA Overview."
-
PyTorch Documentation, "Custom Kernels via Pallas," accessed December 2025, https://docs.pytorch.org/xla/master/features/pallas.html.
-
PyTorch Documentation, "Custom Kernels via Pallas."
-
PyTorch Documentation, "Custom Kernels via Pallas."
-
vLLM Blog, "vLLM TPU: A New Unified Backend Supporting PyTorch and JAX on TPU," October 16, 2025, https://blog.vllm.ai/2025/10/16/vllm-tpu.html.
-
GitHub, "pytorch/xla," accessed December 2025, https://github.com/pytorch/xla.
-
StackGpu, "FP8, BF16, and INT8: How Low-Precision Formats Are Revolutionizing Deep Learning Throughput," Medium, accessed December 2025, https://medium.com/@StackGpu/fp8-bf16-and-int8-how-low-precision-formats-are-revolutionizing-deep-learning-throughput-e6c1f3adabc2.
-
Wikipedia, "Bfloat16 floating-point format."
-
Wikipedia, "Bfloat16 floating-point format."
-
Paulius Micikevicius et al., "FP8 Formats for Deep Learning," arXiv:2209.05433, September 2022.
-
XPU.pub, "Google Adds FP8 to Ironwood TPU."
-
Micikevicius et al., "FP8 Formats for Deep Learning."
-
Google Cloud Blog, "Accurate Quantized Training (AQT) for TPU v5e," accessed December 2025, https://cloud.google.com/blog/products/compute/accurate-quantized-training-aqt-for-tpu-v5e.
-
StackGpu, "FP8, BF16, and INT8."
-
Jeffrey Tse, "Understanding the FP64, FP32, FP16, BFLOAT16, TF32, FP8 Formats," personal blog, December 9, 2024, https://jeffreytse.net/computer/2024/12/09/understanding-the-fp64-fp32-fp16-bfloat16-tf32-fp8-formats.html.
-
PyTorch Blog, "PyTorch/XLA SPMD: Scale Up Model Training and Serving with Automatic Parallelization," accessed December 2025, https://pytorch.org/blog/pytorch-xla-spmd/.
-
OpenXLA Project, "Shardy Guide for JAX Users."
-
JAX Documentation, "Introduction to parallel programming."
-
OpenXLA Project, "Shardy Guide for JAX Users."
-
Ko, "TPU Deep Dive."
-
JAX Documentation, "Introduction to parallel programming."
-
Anthropic, "Expanding our use of Google Cloud TPUs."
-
JAX Documentation, "Introduction to parallel programming."
-
JAX Documentation, "Introduction to parallel programming."
-
Adam Roberts et al., "Scaling Up Models and Data with t5x and seqio," arXiv:2203.17189, March 2022.
-
Roberts et al., "Scaling Up Models and Data."
-
JAX Documentation, "Introduction to parallel programming."
-
JAX Documentation, "Introduction to parallel programming."
-
OpenXLA Project, "Shardy Guide for JAX Users."
-
Roberts et al., "Scaling Up Models and Data."
-
Roberts et al., "Scaling Up Models and Data."
-
Ko, "TPU Deep Dive."
-
MLCommons, "Benchmark MLPerf Training," accessed December 2025, https://mlcommons.org/benchmarks/training/.
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
HPCwire, "MLPerf Training v5.0 Benchmark Results Reflect Rapid Growth in the Field of AI," June 2025, https://www.hpcwire.com/off-the-wire/mlperf-training-v5-0-benchmark-results-reflect-rapid-growth-in-the-field-of-ai/.
-
MLCommons, "MLCommons Releases New MLPerf Inference v5.0 Benchmark Results," April 2025, https://mlcommons.org/2025/04/mlperf-inference-v5-0-results/.
-
Ko, "TPU Deep Dive."
-
Google Cloud Blog, "TPU v4 enables performance, energy and CO2e efficiency gains," accessed December 2025, https://cloud.google.com/blog/topics/systems/tpu-v4-enables-performance-energy-and-co2e-efficiency-gains.
-
TrendForce, "Google Unveils 7th-Gen TPU Ironwood."
-
Google Cloud Blog, "Quantifying the performance of the TPU."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Artech Digital, "Energy-Efficient GPU vs. TPU Allocation," accessed December 2025, https://www.artech-digital.com/blog/energy-efficient-gpu-vs-tpu-allocation.
-
Wikipedia, "Tensor Processing Unit."
-
XPU.pub, "Google Adds FP8 to Ironwood TPU."
-
Ko, "TPU Deep Dive."
-
Google Cloud Blog, "TPU v4 enables performance, energy and CO2e efficiency gains."
-
ByteBridge, "GPU and TPU Comparative Analysis Report," Medium, accessed December 2025, https://bytebridge.medium.com/gpu-and-tpu-comparative-analysis-report-a5268e4f0d2a.
-
ByteBridge, "GPU and TPU Comparative Analysis Report."
-
Anthropic, "Expanding our use of Google Cloud TPUs."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
DataCamp, "Understanding TPUs vs GPUs in AI: A Comprehensive Guide," accessed December 2025, https://www.datacamp.com/blog/tpu-vs-gpu-ai.
-
Ko, "TPU Deep Dive."
-
DataCamp, "Understanding TPUs vs GPUs in AI."
-
Grigory Sapunov, "FP64, FP32, FP16, BFLOAT16, TF32, and other members of the ZOO," Medium, accessed December 2025, https://moocaholic.medium.com/fp64-fp32-fp16-bfloat16-tf32-and-other-members-of-the-zoo-a1ca7897d407.
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Snider and Liang, "Operator Fusion in XLA."
-
APXML, "Memory-Aware Data Layout Transformations."
-
Google Cloud Blog, "How Lightricks trains video diffusion models at scale with JAX on TPU," accessed December 2025, https://cloud.google.com/blog/products/media-entertainment/how-lightricks-trains-video-diffusion-models-at-scale-with-jax-on-tpu.
-
CloudOptimo, "TPU vs GPU: What's the Difference in 2025?" accessed December 2025, https://www.cloudoptimo.com/blog/tpu-vs-gpu-what-is-the-difference-in-2025/.
-
Phoenix NAP, "TPU vs. GPU: Differences Explained," accessed December 2025, https://phoenixnap.com/kb/tpu-vs-gpu.
-
CloudOptimo, "TPU vs GPU."
-
DataCamp, "Understanding TPUs vs GPUs in AI."
-
Tailscale, "TPU vs GPU: Which Is Better for AI Infrastructure in 2025?" accessed December 2025, https://tailscale.com/learn/what-is-tpu-vs-gpu.
-
DataCamp, "Understanding TPUs vs GPUs in AI."
-
DataCamp, "Understanding TPUs vs GPUs in AI."
-
PyTorch Documentation, "Custom Kernels via Pallas."
-
Phoenix NAP, "TPU vs. GPU: Differences Explained."
-
Ko, "TPU Deep Dive."
-
OpenMetal, "TPU vs GPU: Pros and Cons," accessed December 2025, https://openmetal.io/docs/product-guides/private-cloud/tpu-vs-gpu-pros-and-cons/.
-
OpenMetal, "TPU vs GPU: Pros and Cons."
-
Phoenix NAP, "TPU vs. GPU: Differences Explained."
-
PRIMO.ai, "Processing Units - CPU, GPU, APU, TPU, VPU, FPGA, QPU," accessed December 2025, https://primo.ai/index.php?title=Processing_Units_-_CPU%2C_GPU%2C_APU%2C_TPU%2C_VPU%2C_FPGA%2C_QPU.
-
DataCamp, "Understanding TPUs vs GPUs in AI."
-
Google Cloud Documentation, "Profile your model on Cloud TPU VMs," accessed December 2025, https://cloud.google.com/tpu/docs/cloud-tpu-tools.
-
DataCamp, "Understanding TPUs vs GPUs in AI."
-
Ko, "TPU Deep Dive."
-
GitHub, "RFC: Evolving PyTorch/XLA."
-
Google Cloud Press Corner, "Anthropic to Expand Use."
-
TrendForce, "Google Unveils 7th-Gen TPU Ironwood."
-
Maginative, "Anthropic Secures 1M Google TPUs While Keeping Amazon as Primary Training Partner," accessed December 2025, https://www.maginative.com/article/anthropic-secures-1m-google-tpus-while-keeping-amazon-as-primary-training-partner/.
-
Anthropic, "A postmortem of three recent issues," Engineering Blog, August 2025, https://www.anthropic.com/engineering/a-postmortem-of-three-recent-issues.
-
Anthropic, "A postmortem of three recent issues."
-
AI Magazine, "Why Anthropic Uses Google Cloud TPUs for AI Infrastructure," accessed December 2025, https://aimagazine.com/news/why-anthropic-uses-google-cloud-tpus-for-ai-infrastructure.
-
Google Cloud Blog, "Ironwood TPUs and new Axion-based VMs for your AI workloads," November 2025, https://cloud.google.com/blog/products/compute/ironwood-tpus-and-new-axion-based-vms-for-your-ai-workloads.
-
Ko, "TPU Deep Dive."
-
TrendForce, "Google Unveils 7th-Gen TPU Ironwood."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Google Cloud, "Tensor Processing Units (TPUs)," accessed December 2025, https://cloud.google.com/tpu.
-
TensorFlow Documentation, "Optimize TensorFlow performance using the Profiler," accessed December 2025, https://www.tensorflow.org/guide/profiler.
-
Google Cloud Documentation, "Profile your model on Cloud TPU VMs."
-
TensorFlow Documentation, "TensorFlow Profiler: Profile model performance," accessed December 2025, https://www.tensorflow.org/tensorboard/tensorboard_profiling_keras.
-
Google Cloud Documentation, "Profile your model on Cloud TPU VMs."
-
Google Cloud Blog, "PyTorch/XLA: Performance debugging on Cloud TPU VM: Part III," accessed December 2025, https://cloud.google.com/blog/topics/developers-practitioners/pytorchxla-performance-debugging-cloud-tpu-vm-part-iii.
-
Google Cloud Blog, "PyTorch/XLA: Performance debugging Part III."
-
Google Cloud Documentation, "Profile PyTorch XLA workloads," accessed December 2025, https://docs.cloud.google.com/tpu/docs/pytorch-xla-performance-profiling-tpu-vm.
-
TensorFlow Documentation, "Optimize TensorFlow performance using the Profiler."
-
TensorFlow Documentation, "Optimize TensorFlow performance using the Profiler."
-
Ko, "TPU Deep Dive."
-
Google Cloud Documentation, "Cloud TPU performance guide."
-
TensorFlow Documentation, "Optimize TensorFlow performance using the Profiler."
-
TensorFlow Documentation, "Optimize TensorFlow performance using the Profiler."
-
TensorFlow Documentation, "Optimize TensorFlow performance using the Profiler."
-
TrendForce, "Google Unveils 7th-Gen TPU Ironwood."
-
Tse, "Understanding the FP64, FP32, FP16, BFLOAT16, TF32, FP8 Formats."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."


