
Tensor Processing Units від Google забезпечують роботу більшості передових AI-моделей, з якими ви взаємодієте щодня, проте більшість інженерів залишаються напрочуд незнайомими з їхньою архітектурою. Хоча GPU від NVIDIA домінують у свідомості розробників, TPU тихо тренують і обслуговують Gemini 2.0, Claude та десятки інших найсучасніших моделей у масштабах, які збанкрутили б більшість організацій при використанні звичайної GPU-інфраструктури. Anthropic нещодавно взяла зобов'язання розгорнути понад мільйон TPU-чіпів—що становить понад гігават обчислювальної потужності—для тренування майбутніх моделей Claude.¹ Найновіше покоління Ironwood від Google забезпечує 42.5 екзафлопс FP8-обчислень на суперподах з 9,216 чіпів, масштаб, який переосмислює поняття виробничої AI-інфраструктури.²
Технічна складність TPU виходить далеко за межі простих метрик продуктивності. Ці процесори втілюють принципово іншу філософію дизайну порівняно з GPU, жертвуючи універсальною гнучкістю заради екстремальної спеціалізації в матричному множенні та операціях з тензорами. Інженери, які розуміють архітектуру TPU, можуть використовувати систолічні масиви 256×256, які обробляють 65,536 операцій множення-накопичення за цикл, задіювати прискорювачі третього покоління SparseCore для робочих навантажень, інтенсивних на ембединги, та програмувати оптичні комутатори схем, які реконфігурують багатопетабітні топології дата-центрів менш ніж за 10 наносекунд.³ Архітектура охоплює все від рішень дизайну на рівні транзисторів до оркестрації суперкомп'ютерів масштабу будівель.
Технічний контент далі вимагає ретельної уваги. Ми розглянемо сім поколінь еволюції TPU, розберемо математику систолічних масивів та паттерни потоків даних, дослідимо ієрархії пам'яті від SRAM-тайлів до каналів HBM3e, проаналізуємо оптимізації компілятора XLA на рівні проміжного представлення та з'ясуємо, чому колективні операції виконуються в 10× швидше, ніж еквівалентні GPU-кластери на базі Ethernet.⁴ Ви зустрінете специфікації на рівні регістрів, моделювання продуктивності з точністю до циклів та архітектурні компроміси, які роблять TPU одночасно потужнішими та більш обмеженими, ніж GPU. Така глибина служить інженерам, які будують наступне покоління AI-інфраструктури, та дослідникам, які розширюють межі того, що можуть досягти поточні прискорювачі.
Еволюція: Сім поколінь архітектурних інновацій
TPU v1: Спеціалізація для інференсу (2015)
Google розгорнув перший Tensor Processing Unit у 2015 році для вирішення критичної проблеми: робочі навантаження інференсу нейронних мереж загрожували подвоїти площу дата-центрів компанії.⁵ Інженери розробили TPU v1 виключно для інференсу, повністю виключивши можливості тренування, щоб максимізувати продуктивність і енергоефективність для розгорнутих моделей. Чіп містив систолічний масив 256×256 з 8-бітними цілочисельними одиницями множення-накопичення, забезпечуючи 92 терафлопс на секунду при лише 28-40 ватах розрахункової теплової потужності.⁶
Архітектура втілювала радикальний мінімалізм. Єдиний Matrix Multiply Unit обробляв INT8 операції через потік даних зі стаціонарними вагами, де ваги залишалися фіксованими в систолічному масиві, поки активації протікали горизонтально через сітку. Часткові суми поширювалися вертикально, усуваючи проміжні записи в пам'ять для всього матричного множення. Чіп, підключений до хост-систем через PCIe, покладався на DDR3 DRAM для зовнішньої пам'яті та працював на частоті 700 МГц—навмисно консервативно для енергоефективності.⁷
Покращення продуктивності вразили навіть інженерів Google. TPU v1 досяг покращення у 30-80 разів в операціях на ват порівняно з сучасними CPU і GPU для продуктивних робочих навантажень інференсу.⁸ Чіп обробляв ранжування Google Search, служби перекладу, що обробляли 1 мільярд щоденних запитів, і рекомендації YouTube для 2 мільярдів користувачів. Успіх підтвердив ключове архітектурне розуміння: спеціально створені прискорювачі, оптимізовані для вузьких робочих навантажень, могли забезпечити покращення на порядки величин порівняно з процесорами загального призначення.
TPU v2: Забезпечення тренування у масштабі (2017)
Друге покоління перетворило TPU з прискорювачів лише для інференсу на повноцінні платформи для тренування. Google повністю переробив архітектуру навколо операцій з плаваючою комою, замінивши масив 256×256 INT8 на подвійні 128×128 bfloat16 множники-накопичувачі на ядро.⁹ Кожен чіп містив два TensorCores, що ділили 8GB High Bandwidth Memory на ядро, масивне оновлення з DDR3, яке забезпечило пропускну здатність, яку вимагало тренування нейронних мереж.
Точність bfloat16 виявилася критичною для успіху TPU v2. Формат зберігає той же 8-бітний діапазон експоненти, що й FP32, зменшуючи мантису до 7 біт, зберігаючи динамічний діапазон для тренування, одночасно зменшуючи вдвічі вимоги до пропускної здатності пам'яті.¹⁰ Інженери помітили, що знижена точність мантиси фактично покращила узагальнення в багатьох моделях, діючи як форма регуляризації, тоді як повний діапазон експонент FP32 запобіг проблемам недопливу та переповнення, які переслідували тренування FP16.
Архітектурною інновацією, яка справді відрізнила TPU v2, був Inter-Chip Interconnect (ICI). Попередні прискорювачі потребували Ethernet або InfiniBand для міжчіпового зв'язку, вводячи вузькі місця затримки та пропускної здатності. Google розробив спеціальні високошвидкісні двонаправлені зв'язки, які з'єднували кожен TPU безпосередньо з чотирма сусідами в 2D торусовій топології.¹¹ Interconnect дозволив "подам" TPU v2 з до 256 чіпів функціонувати як єдиний логічний прискорювач, з колективними операціями як all-reduce, які виконувалися набагато швидше за альтернативи на основі мережі.
TPU v3: Масштабування продуктивності з водяним охолодженням (2018)
Google агресивно підвищив тактові частоти та кількість ядер у TPU v3, забезпечивши 420 терафлопс на чіп—більш ніж подвоївши продуктивність v2.¹² Збільшена щільність потужності вимагала драматичної архітектурної зміни: рідинного охолодження. Кожен под TPU v3 вимагав інфраструктури водяного охолодження, відхід від повітряно-охолоджуваних конструкцій попередніх поколінь і більшості прискорювачів дата-центрів.¹³
Чіп зберіг архітектуру подвійних 128×128 MXU, але збільшив загальну кількість ядер і покращив пропускну здатність пам'яті. Кожен TPU v3 містив чотири чіпи з двома ядрами кожен, загалом діливши 32GB HBM пам'яті між чіпами.¹⁴ Векторні обробляючі одиниці отримали покращення для функцій активації, операцій нормалізації та обчислень градієнтів, які часто створювали вузькі місця при тренуванні лише на матричних одиницях.
Розгортання масштабувалося до подів з 2,048 чіпів, використовуючи ту ж 2D торусову топологію ICI, що й v2, але зі збільшеною пропускною здатністю на зв'язок. Google тренував усе більші моделі на подах v3, виявляючи, що зменшений діаметр мережі торусової топології (максимальна відстань між будь-якими двома чіпами масштабується як N/2 замість N) мінімізував накладні витрати на комунікацію як для стратегій паралелізму даних, так і модельного паралелізму.¹⁵
TPU v4: Прорив оптичної комутації каналів (2021)
Четверте покоління представило найбільший архітектурний стрибок Google з часів оригінального TPU. Інженери збільшили масштаб подів до 4,096 чіпів, одночасно впроваджуючи оптичну комутацію каналів (OCS) для interconnect—технологію, запозичену з телекомунікацій, яка революціонізувала ML інфраструктуру масштабу дата-центру.¹⁶
Основна архітектура TPU v4 містила чотири 128×128 MXU на TensorCore разом з покращеними векторними та скалярними одиницями. Кожна пара TensorCore ділила 128MB Common Memory на додаток до Vector Memory кожного ядра, дозволяючи більш складні паттерни розміщення даних та повторного використання.¹⁷ Топологія чіпа еволюціонувала з 2D до 3D торуса, з'єднуючи кожен TPU з шістьма сусідами замість чотирьох, далі зменшуючи діаметр мережі та покращуючи пропускну здатність розрізу.
Система оптичної комутації каналів змінила все в крупномасштабному розгортанні. Замість фіксованої кабельної прокладки між TPU, Google розгорнув програмовані оптичні комутатори, які могли динамічно переконфігурувати, які чіпи з'єднувалися з якими. MEMS (мікроелектромеханічні системи) дзеркала фізично перенаправляють світлові промені для з'єднання довільних пар TPU, вводячи практично нульову затримку понад час передачі оптичного волокна.¹⁸ Комутатори переконфігуруються у вікнах менше 10 наносекунд, швидше за більшість рукостискань мережевих протоколів.
Архітектура OCS дозволила можливості, які раніше були неможливими. Google міг виділяти "зрізи" будь-якого розміру, від чотирьох чіпів до повного поду з 4,096 чіпів, відповідно програмуючи оптичні комутатори. Несправні чіпи могли бути безшовно оминуті без виходу з ладу цілих стійок. Найбільш примітно, фізично віддалені TPU в різних локаціях дата-центрів могли бути логічно сусідніми в топології мережі, повністю розв'язуючи фізичне та логічне розташування.¹⁹
TPU v4 також представив SparseCore, спеціалізований процесор для обробки операцій вбудовування, які використовуються щодня в системах рекомендацій, моделях ранжування та великих мовних моделях з масивними вбудовуваннями словника. SparseCore містив чотири спеціалізовані процесори на чіп, кожен з 2.5MB тимчасової пам'яті та оптимізованим потоком даних для розріджених паттернів доступу до пам'яті.²⁰ Моделі з ультравеликими вбудовуваннями досягли прискорення у 5-7 разів, використовуючи лише 5% від загальної площі кристала чіпа та енергетичного бюджету.
TPU v5p і v5e: Спеціалізація та масштаб (2022-2023)
Google розділив п'яте покоління на два різні продукти, орієнтовані на різні випадки використання. TPU v5p надавав пріоритет максимальній продуктивності для крупномасштабного тренування, тоді як v5e оптимізувався для економічно ефективного інференсу та менших завдань тренування.²¹
TPU v5p досяг приблизно 4.45 ексафлопс на секунду у подах з 8,960 чіпів, більш ніж подвоївши максимальний розмір поду v4.²² Пропускна здатність interconnect досягла 4,800 Гбіт/с на чіп, а 3D торусова топологія з'єднувала чіпи в масивних суперподах 16×20×28. Оптична структура комутації каналів керувала 13,824 оптичними портами через 48 OCS одиниць для з'єднання повного суперподу v5p, представляючи одне з найбільших виробничих розгортань оптичної комутації в історії обчислень.²³
TPU v5e обрав інший підхід, зменшивши кількість ядер та тактову частоту для досягнення агресивних цілей потужності та вартості. Оптимізовані для інференсу чіпи містили лише одне TPU ядро на чіп замість двох та повернулися до 2D торусової топології, яка була достатньою для менших розмірів подів.²⁴ Архітектурне спрощення дозволило Google конкурентно оцінювати v5e для робочих навантажень, де абсолютна продуктивність мала менше значення, ніж продуктивність за долар.
TPU v6e Trillium: Четириразове збільшення матричної продуктивності (2024)
Trillium позначив ще один архітектурний переломний момент, розширивши Matrix Multiply Unit зі 128×128 до 256×256 множників-накопичувачів.²⁵ Більший масив учетверив FLOPS на цикл при тій же тактовій частоті, забезпечивши продуктивність обчислень у 4.7 рази вище піку TPU v5e завдяки комбінації розширеного MXU та збільшених тактових частот.
Підсистема пам'яті отримала однаково драматичні покращення. Ємність HBM подвоїлася до 32GB на чіп, з пропускною здатністю, подвоєною каналами HBM наступного покоління.²⁶ Пропускна здатність Interchip Interconnect також подвоїлася, дозволяючи подам з 256 чіпів Trillium підтримувати вищу пропускну здатність для моделей, які навантажували як обчислення, так і комунікацію.²⁷
Trillium містив прискорювач SparseCore третього покоління з покращеними можливостями для ультравеликих вбудовувань в робочих навантаженнях ранжування та рекомендацій. Оновлена конструкція покращила паттерни доступу до пам'яті та збільшила адекватну пропускну здатність між SparseCores та HBM для моделей, в яких домінували пошуки вбудовувань, а не матричні множення.²⁸
Енергоефективність покращилася на 67% порівняно з v5e незважаючи на суттєві покращення продуктивності.²⁹ Google досяг покращення ефективності через передові процесні вузли, архітектурні оптимізації, що зменшили марну роботу, та ретельне відключення живлення невикористаних одиниць під час операцій, які не навантажували всі частини чіпа одночасно.
TPU v7 Ironwood: Ера FP8 (2025)
TPU сьомого покоління Google, кодова назва Ironwood, представляє перший TPU, розроблений з нативною підтримкою FP8 та оптимізований спеціально для "ери інференсу", зберігаючи передову продуктивність тренування.³⁰ Кожен чіп Ironwood забезпечує 4.6 петафлопс щільних обчислень FP8—трохи перевершуючи конкуруючий B200 від NVIDIA з 4.5 петафлопс—споживаючи 600W розрахункової теплової потужності.³¹
Система пам'яті розширилася до 192GB пам'яті HBM3e на чіп, у шість разів більше ємності Trillium, з пропускною здатністю, що досягає 7.4TB/s.³² Драматичне збільшення пам'яті дозволяє обслуговувати ультравеликі моделі з кешами ключ-значення, які раніше вимагали складного тензорного паралелізму на декількох прискорювачах. Google спеціально розробив ємність пам'яті для підтримки нових мультимодальних моделей та додатків довгого контексту, що наближаються до вікон з мільйона токенів.
Interconnect Ironwood забезпечує 9.6 Тбіт/с агрегованої двонаправленої пропускної здатності через чотири ICI зв'язки, що перекладається в 1.2 TB/s пікової пропускної здатності на чіп.³³ Архітектура масштабується від подів з 256 чіпів для менших розгортань до масивних суперподів з 9,216 чіпів, що забезпечують 42.5 FP8 ексафлопс обчислювальної потужності.³⁴ Мережева технологія Jupiter дата-центру Google теоретично могла би підтримувати до 43 суперподів Ironwood в одному кластері—приблизно 400,000 прискорювачів, що представляє майже незрозумілий масштаб обчислень.³⁵
Підтримка FP8 представляє фундаментальний зсув у стратегії точності. Попередні покоління TPU емулювали 8-бітні операції, використовуючи програмні техніки, які вносили накладні витрати. Ironwood реалізує нативні одиниці множення-накопичення FP8, підтримуючи формати E4M3 (4-бітна експонента, 3-бітна мантиса) та E5M2 (5-бітна експонента, 2-бітна мантиса).³⁶ Підтримка подвійного формату дозволяє змішувати E4M3 для прямих проходів, де точність менш важлива, та E5M2 для зворотних проходів, де підтримка магнітуд градієнтів запобігає нестабільності тренування.
Зобов'язання Anthropic розгорнути понад один мільйон чіпів Ironwood, починаючи з 2026 року, демонструє готовність архітектури до виробництва. Компанія планує використовувати понад гігават потужності TPU—достатньо для живлення невеликого міста—виключно для тренування та обслуговування моделей Claude.³⁷ Масштаб затьмарює навіть найзначніші відомі розгортання GPU та представляє фундаментальну ставку на архітектуру TPU для розробки передових моделей.
Швидкий довідник поточного покоління
Наступні таблиці надають сканувальні специфікації для трьох TPU поточного покоління, найбільш релевантних для виробничих розгортань у 2025 році:
Таблиця 1: Специфікації основних обчислень
[caption id="" align="alignnone" width="1386"] SpecificationTPU v5eTPU v5pTPU v6e (Trillium)TPU v7 (Ironwood) MXU Array Size 128×128 128×128 256×256 256×256 MACs per Cycle 16,384 16,384 65,536 65,536 Peak BF16 TFLOPS ~197 ~459 ~918 ~2,300 (est.) Peak FP8 PFLOPS N/A (emulated) N/A (emulated) N/A (emulated) 4.6 Native Precision BF16, INT8 BF16, INT8 BF16, INT8 BF16, FP8, INT8 TensorCores/Chip 1 2 1 1 [/caption]
SpecificationTPU v5eTPU v5pTPU v6e (Trillium)TPU v7 (Ironwood) MXU Array Size 128×128 128×128 256×256 256×256 MACs per Cycle 16,384 16,384 65,536 65,536 Peak BF16 TFLOPS ~197 ~459 ~918 ~2,300 (est.) Peak FP8 PFLOPS N/A (emulated) N/A (emulated) N/A (emulated) 4.6 Native Precision BF16, INT8 BF16, INT8 BF16, INT8 BF16, FP8, INT8 TensorCores/Chip 1 2 1 1 [/caption]
Таблиця 2: Пам'ять і пропускна здатність
[caption id="" align="alignnone" width="1380"]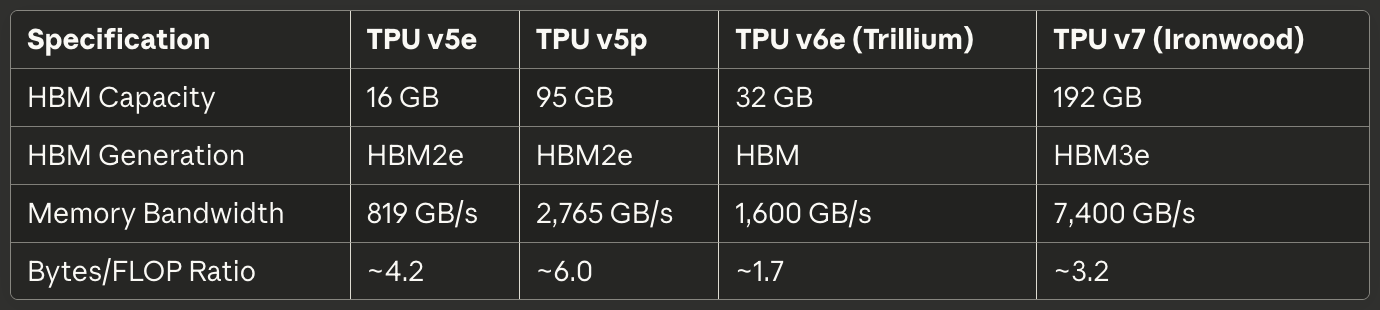 SpecificationTPU v5eTPU v5pTPU v6e (Trillium)TPU v7 (Ironwood) HBM Capacity 16 GB 95 GB 32 GB 192 GB HBM Generation HBM2e HBM2e HBM HBM3e Memory Bandwidth 819 GB/s 2,765 GB/s 1,600 GB/s 7,400 GB/s Bytes/FLOP Ratio ~4.2 ~6.0 ~1.7 ~3.2 [/caption]
SpecificationTPU v5eTPU v5pTPU v6e (Trillium)TPU v7 (Ironwood) HBM Capacity 16 GB 95 GB 32 GB 192 GB HBM Generation HBM2e HBM2e HBM HBM3e Memory Bandwidth 819 GB/s 2,765 GB/s 1,600 GB/s 7,400 GB/s Bytes/FLOP Ratio ~4.2 ~6.0 ~1.7 ~3.2 [/caption]
Таблиця 3: Interconnect і масштабування
[caption id="" align="alignnone" width="1384"]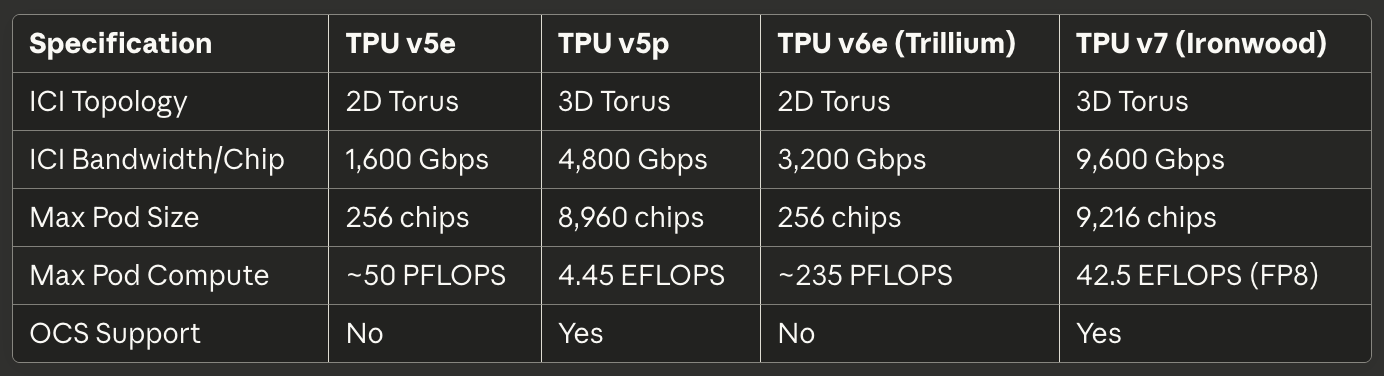 SpecificationTPU v5eTPU v5pTPU v6e (Trillium)TPU v7 (Ironwood) ICI Topology 2D Torus 3D Torus 2D Torus 3D Torus ICI Bandwidth/Chip 1,600 Gbps 4,800 Gbps 3,200 Gbps 9,600 Gbps Max Pod Size 256 chips 8,960 chips 256 chips 9,216 chips Max Pod Compute ~50 PFLOPS 4.45 EFLOPS ~235 PFLOPS 42.5 EFLOPS (FP8) OCS Support No Yes No Yes [/caption]
SpecificationTPU v5eTPU v5pTPU v6e (Trillium)TPU v7 (Ironwood) ICI Topology 2D Torus 3D Torus 2D Torus 3D Torus ICI Bandwidth/Chip 1,600 Gbps 4,800 Gbps 3,200 Gbps 9,600 Gbps Max Pod Size 256 chips 8,960 chips 256 chips 9,216 chips Max Pod Compute ~50 PFLOPS 4.45 EFLOPS ~235 PFLOPS 42.5 EFLOPS (FP8) OCS Support No Yes No Yes [/caption]
Таблиця 4: Потужність і ефективність
[caption id="" align="alignnone" width="1380"] SpecificationTPU v5eTPU v5pTPU v6e (Trillium)TPU v7 (Ironwood) TDP ~120-200W ~250-300W ~120-200W 600W Cooling Air Liquid Air Liquid TFLOPS/Watt (BF16) ~1.0-1.6 ~1.5-1.8 ~4.6-7.7 ~3.8 Energy vs Prior Gen Baseline N/A 67% better than v5e 2× better than Trillium [/caption]
SpecificationTPU v5eTPU v5pTPU v6e (Trillium)TPU v7 (Ironwood) TDP ~120-200W ~250-300W ~120-200W 600W Cooling Air Liquid Air Liquid TFLOPS/Watt (BF16) ~1.0-1.6 ~1.5-1.8 ~4.6-7.7 ~3.8 Energy vs Prior Gen Baseline N/A 67% better than v5e 2× better than Trillium [/caption]
Таблиця 5: Рекомендовані випадки використання
[caption id="" align="alignnone" width="1382"] Use Case Best Choice Rationale Cost-optimized inference TPU v5e: Lowest cost per inference query Large-scale training (>1000 chips) TPU v5p or Ironwood 3D torus + OCS enables massive pods Medium training jobs (256 chips) TPU v6e Trillium Best perf/watt, 4.7× compute vs v5e Memory-bound models (>70B params), Ironwood 192GB HBM enables larger batch sizes Long-context inference (>100K tokens) Ironwood HBM capacity supports massive KV caches Embedding-heavy workloads TPU v5p or Ironwood SparseCore + large HBM [/caption]
Use Case Best Choice Rationale Cost-optimized inference TPU v5e: Lowest cost per inference query Large-scale training (>1000 chips) TPU v5p or Ironwood 3D torus + OCS enables massive pods Medium training jobs (256 chips) TPU v6e Trillium Best perf/watt, 4.7× compute vs v5e Memory-bound models (>70B params), Ironwood 192GB HBM enables larger batch sizes Long-context inference (>100K tokens) Ironwood HBM capacity supports massive KV caches Embedding-heavy workloads TPU v5p or Ironwood SparseCore + large HBM [/caption]
Апаратна архітектура: Всередині кремнію
Математика систолічного масиву та потік даних
Matrix Multiply Unit формує серце архітектури TPU, і розуміння систолічних масивів вимагає осягнення їхнього принципово відмінного підходу до паралелізму порівняно з SIMD лініями GPU. Систолічний масив ланцюжить одиниці множення-накопичення в сітці, де дані ритмічно протікають через структуру—звідси "систолічний", що викликає ритмічне перекачування крові через серце.³⁸
Розглянемо систолічний масив 256×256 TPU v6e, що виконує матричне множення C = A × B. Інженери заздалегідь завантажують ваги матриці B у 65,536 індивідуальних одиниць множення-накопичення, розташованих у сітці. Значення активацій матриці A входять з лівого краю та протікають горизонтально через масив. Кожна MAC одиниця множить свою збережену вагу на вхідну активацію, додає результат до часткової суми, що надходить зверху, та передає як активацію (горизонтально), так і оновлену часткову суму (вертикально) сусіднім одиницям.³⁹
Паттерн потоку даних означає, що кожне значення активації повторно використовується 256 разів, коли воно проходить горизонтальний вимір, і кожна часткова сума накопичує внески від 256 множень, протікаючи вертикально. Критично важливо, що всі проміжні результати передаються безпосередньо між сусідніми MAC одиницями через короткі дроти, а не туди-назад до пам'яті. Архітектура виконує 65,536 операцій множення-накопичення кожен такт, і протягом усього матричного множення, що включає потенційно мільйони операцій, нуль проміжних значень торкається DRAM чи навіть SRAM на чіпі.⁴⁰
Паттерн потоку даних зі стаціонарними вагами оптимізується для найпоширенішого випадку в інференсі та тренуванні нейронних мереж: повторне множення багатьох різних матриць активацій на ту ж матрицю ваг. Інженери завантажують ваги один раз, потім передають необмежені пакети активацій через масив без перезавантаження. Паттерн винятково добре працює для конволюційних шарів, повнозв'язних шарів та операцій Q·K^T і attention·V, які домінують у трансформерних моделях.⁴¹
Енергоефективність випливає з повторного використання даних та просторової локальності. Читання значення з DRAM споживає приблизно в 200 разів більше енергії, ніж одна операція множення-накопичення.⁴² Повторно використовуючи кожну вагу 256 разів та кожну активацію 256 разів без доступу до пам'яті, систолічний масив досягає співвідношень операцій на ват, неможливих для архітектур, які перевозять дані туди-назад між обчислювальними одиницями та ієрархіями пам'яті.
Слабкість систолічного масиву проявляється з динамічними або нерегулярними паттернами обчислень. Оскільки дані протікають через сітку за фіксованим розкладом, архітектура борється з умовним виконанням, розрідженими матрицями (якщо не використовується SparseCore) та операціями, які вимагають паттернів випадкового доступу. Негнучкість обмінює універсальність на екстремальну ефективність на своєму цільовому робочому навантаженні: щільне матричне множення з передбачуваними паттернами доступу.
Внутрішня архітектура TensorCore
Кожен чіп TPU містить один або більше TensorCores—повну обробляючу одиницю, що включає Matrix Multiply Unit, Vector Processing Unit та Scalar Unit, які працюють узгоджено.⁴³ TensorCore представляє фундаментальний будівельний блок, на який орієнтоване програмне забезпечення, і розуміння взаємодії між його трьома компонентами пояснює як характеристики продуктивності TPU, так і паттерни програмування.
Matrix Multiply Unit виконує 16,000 операцій множення-накопичення за цикл на входах bfloat16 або FP8 з накопиченням FP32.⁴⁴ Підхід змішаної точності зберігає числову точність в акумуляторі, зменшуючи пропускну здатність пам'яті для входів. Інженери помітили, що підтримка повної точності FP32 під час накопичення запобігає катастрофічним помилкам скасування при сумуванні сотень або тисяч проміжних добутків, тоді як входи зменшеної точності рідко впливають на якість фінальної моделі.
Vector Processing Unit обробляє операції, погано підходящі для жорсткої структури MXU. Функції активації (ReLU, GELU, SiLU), шари нормалізації (batch norm, layer norm), softmax, pooling, dropout та поелементні операції виконуються на 128-смузькій SIMD архітектурі VPU.⁴⁵ VPU працює з типами даних FP32 та INT32, забезпечуючи точність, необхідну для числово чутливих операцій, як softmax, де експоненти та ділення можуть створювати великі динамічні діапазони.
Scalar Unit координує весь TensorCore. Односереднічний процесор виконує потік управління, обчислює адреси пам'яті для складних паттернів індексації та ініціює DMA передачі з High Bandwidth Memory до Vector Memory.⁴⁶ Оскільки скалярна одиниця працює односеременно, кожен TensorCore може створити лише один DMA запит за цикл—вузьке місце для операцій, інтенсивних за пам'яттю, які не насичують пропускну здатність MXU або VPU.
Ієрархія пам'яті, що живить TensorCore, визначає досяжну продуктивність так само, як і сирі обчислювальні можливості. Vector Memory (VMEM) діє як програмно керована тимчасова пам'ять SRAM, ексклюзивна для кожного TensorCore, зазвичай розміром у десятки мегабайт. Компілятор XLA явно планує переміщення даних між HBM та VMEM, вирішуючи, що поставити в швидку локальну пам'ять і коли записувати результати назад.⁴⁷
Common Memory (CMEM), присутня в TPU v4 і пізніших поколіннях, забезпечує більший спільний пул, доступний для всіх TensorCores на чіпі. Архітектура TPU v4 виділила 128MB CMEM, спільної між двома TensorCores, дозволяючи більш складні паттерни виробник-споживач, в яких виходи одного ядра живлять входи іншого ядра без туди-назад до HBM.⁴⁸
Наслідки моделі програмування надзвычайно важливі. Оскільки скалярна одиниця односеременна, а векторна пам'ять вимагає явного керування, програмування TPU нагадує розробку вбудованих систем 1990-х років більше, ніж сучасне програмування GPU. CUDA абстрагує переміщення пам'яті з уніфікованою пам'яттю та кешами, керованими апаратно; код TPU (чи згенерований XLA, чи написаний вручну в Pallas) повинен явно координувати кожну передачу даних. Ручне керування дозволяє експертну оптимізацію, але підвищує планку для компетентної продуктивності.
Архітектура High Bandwidth Memory
Сучасні TPU використовують HBM (High Bandwidth Memory) або HBM3e—радикально відмінну технологію пам'яті від DDR SDRAM, що знаходиться в CPU, та GDDR, що використовується в багатьох GPU. HBM укладає кілька кристалів DRAM вертикально, використовуючи наскрізні кремнієві переходи (TSV), потім розміщує стек безпосередньо поруч з кристалом процесора на кремнієвому інтерпозері.⁴⁹ Короткий електричний шлях та широкий інтерфейс дозволяють драматично вищу пропускну здатність, ніж традиційні технології пам'яті.
TPU v7 Ironwood реалізує 192GB HBM3e з загальною пропускною здатністю 7.4 TB/s.⁵⁰ Система пам'яті розділена на кілька каналів, кожен з яких забезпечує незалежний доступ до окремої частини загальної ємності. Компілятор XLA та середовище виконання повинні ретельно розподіляти тензори через канали HBM для максимізації паралельного доступу та уникнення гарячих точок, де один канал насичується, поки інші простоюють.
Ширина інтерфейсу пам'яті затьмарює звичайну DRAM. Там де канал DDR5 може забезпечити 64 біти ширини, канал HBM зазвичай охоплює 1,024 біти.⁵¹ Екстремальна ширина дозволяє високу пропускну здатність при відносно помірних тактових частотах, зменшуючи споживання енергії та виклики цілісності сигналу порівняно з підштовхуванням вузьких інтерфейсів до мультигігагерцових частот.
Характеристики затримки суттєво відрізняються від систем пам'яті GPU. TPU не мають апаратно керованих кешів понад невеликі локальні буфери, тому архітектура покладається на програмне забезпечення, яке явно розміщує дані в VMEM задовго до того, як обчислювальні одиниці їх потребують. Відсутність кешів означає, що затримка пам'яті безпосередньо впливає на продуктивність, якщо компілятор не успішно приховує затримку через попереднє завантаження та подвійну буферизацію.⁵²
Обмеження ємності пам'яті домінують у багатьох робочих навантаженнях більше, ніж пропускна здатність обчислень. Модель зі 175 мільярдами параметрів з вагами bfloat16 вимагає 350GB для збереження параметрів—уже перевищуючи 192GB HBM Ironwood навіть до врахування активацій, станів оптимізатора або буферів градієнтів. Тренування таких моделей вимагає складних технік, як перевірка градієнтів, розділення стану оптимізатора через кілька чіпів та ретельне планування оновлень параметрів для мінімізації слід пам'яті.⁵³
Середовище виконання TPU накладає специфічні вимоги до розкладки тензорів для максимізації ефективності MXU. Оскільки систолічний масив обробляє дані в плитках 128×8, тензори повинні вирівнюватися за цими розмірами, щоб уникнути марних відступів.⁵⁴ Погано розмірені матриці примушують апаратуру обробляти часткові плитки з простоюючими MAC, безпосередньо зменшуючи використання FLOPS. Компілятор намагається автоматично додавати відступи та переформовувати тензори, але свідомі вибори розкладки в архітектурі моделі можуть суттєво покращити продуктивність.
SparseCore: Спеціалізоване прискорення вбудовувань
Хоча Matrix Multiply Unit відмінно справляється з щільними матричними операціями, робочі навантаження, інтенсивні за вбудовуваннями, демонструють радикально відмінні характеристики. Моделі рекомендацій, системи ранжування та великі мовні моделі часто звертаються до масивних таблиць вбудовувань (часто сотні гігабайт) через нерегулярні, залежні від даних індекси. Структурований потік даних MXU не надає переваг для цих розріджених паттернів доступу до пам'яті, що мотивує спеціалізовану архітектуру SparseCore.⁵⁵
SparseCore реалізує мозаїчний процесор потоку даних, принципово відмінний від систолічного масиву MXU. TPU v4 містив чотири SparseCores на чіп, кожен з 16 обчислювальними плитками.⁵⁶ Кожна плитка працює як незалежна одиниця потоку даних з локальною тимчасовою пам'яттю (SPMEM) та обробляючими елементами. Плитки виконуються паралельно, обробляючи роз'єднані підмножини операцій вбудовування одночасно.
Ієрархія пам'яті розміщує гарячі дані в невеликій, швидкій SPMEM, зберігаючи повні таблиці вбудовувань в HBM. Компілятор XLA аналізує паттерни доступу до вбудовувань, щоб визначити, які вектори вбудовувань заслуговують кешування в SPMEM проти завантаження на вимогу з HBM.⁵⁷ Стратегія нагадує традиційні ієрархії кешу CPU, але з програмним, а не апаратним прийняттям рішень про розміщення.
SparseCores з'єднуються безпосередньо з каналами HBM, обминаючи шлях пам'яті TensorCore повністю. Виділене з'єднання запобігає конкуренції операцій вбудовування з щільними матричними операціями за пропускну здатність пам'яті, дозволяючи обом продовжуватися паралельно.⁵⁸ Розділення виняткові добре працює для моделей, як Deep Learning Recommendation Models (DLRMs), що чергують щільні шари нейронних мереж з великими пошуками вбудовувань.
Стратегія mod-розділення розподіляє вбудовування через SparseCores, обчислюючи target_sc_id = col_id % num_total_sparse_cores.⁵⁹ Проста функція розділення забезпечує збалансованість навантаження, коли ID вбудовувань розподілені рівномірно, але може створювати гарячі точки для скошених паттернів доступу. Інженери, які працюють з реальними даними, часто потребують аналізу розподілів частоти вбудовувань та ручного перебалансування розділення для уникнення вузьких місць.
Покращення продуктивності від SparseCore досягають 5-7× порівняно з реалізацією ідентичних операцій на MXU та VPU, споживаючи лише 5% від площі кристала чіпа та живлення.⁶⁰ Драматична перевага ефективності випливає з цільового створення потоку даних для розріджених операцій, а не примусового прогону їх через щільну матричну інфраструктуру. Принцип спеціалізації застосовується рекурсивно всередині архітектури TPU: так як TPU спеціалізуються понад універсальний дизайн GPU, SparseCores спеціалізуються понад матрично-орієнтований дизайн TPU.
SparseCore третього покоління Trillium представив змінну SIMD ширину (8 елементів для FP32, 16 для bfloat16) та покращені паттерни доступу до пам'яті, зменшуючи марну пропускну здатність від невирівняних читань.⁶¹ Архітектурна еволюція демонструє продовжені інвестиції Google в прискорення вбудовувань, оскільки великі мовні моделі тяжіють до більших словників та більш складних паттернів генерації, доповненої пошуком.
Технологія взаємозв'язку: З'єднання суперкомп'ютера
Архітектура міжчипового взаємозв'язку (ICI)
Міжчиповий взаємозв'язок є критичною технологією, що дозволяє TPU функціонувати як уніфіковані суперкомп'ютери, а не ізольовані прискорювачі. На відміну від GPU, які спілкуються через мережі Ethernet або InfiniBand, ICI реалізує спеціальні високошвидкісні послідовні з'єднання, що безпосередньо підключають сусідні TPU з затримкою порядку мікросекунд та пропускною здатністю терабіт за секунду.⁶²
Еволюція топології між поколіннями TPU відображає змінні вимоги до масштабування подів. TPU v2, v3, v5e та v6e реалізують 2D-торові топології, де кожен чип з'єднується з чотирма найближчими сусідами (північ, південь, схід та захід).⁶³ З'єднання замикаються на межах, створюючи логічну топологію у формі пончика, що виключає крайні чипи з меншою кількістю з'єднань. Сітка 16×16 з 256 TPU таким чином забезпечує однорідні характеристики пропускної здатності та затримки незалежно від того, які два чипи спілкуються.
TPU v4 та v5p оновилися до 3D-торових топологій, де кожен чип з'єднується з шістьма сусідами.⁶⁴ Додатковий вимір зменшує діаметр мережі — максимальну кількість переходів між будь-якими двома чипами — з приблизно 2√N до 3∛N. Для поду з 4,096 чипів максимальна кількість переходів зменшується з приблизно 128 до 48, істотно знижуючи найгіршу затримку зв'язку для глобально синхронізованих операцій, таких як all-reduce.
Торова структура забезпечує ще одну критичну перевагу: однакову пропускну здатність розрізу незалежно від того, як робочі навантаження розподіляються між чипами. Будь-який розріз, що ділить тор навпіл, перетинає однакову кількість з'єднань, запобігаючи патологічним випадкам, коли поганий розподіл завдань створює вузькі місця в мережі.⁶⁵ Однорідна пропускна здатність розрізу спрощує планування та дозволяє реконфігурованість оптичного комутатора каналів, що обговорюється нижче.
Специфікації пропускної здатності вражаюче масштабуються між поколіннями. TPU v6e забезпечує 13 ТБ/с пропускної здатності ICI на чип.⁶⁶ TPU v5p досяг 4,800 Гбіт/с на чип через шість 3D-торових з'єднань.⁶⁷ Ironwood реалізує чотири ICI-з'єднання з агрегованою двонаправленою пропускною здатністю 9.6 Тбіт/с, що перекладається в 1.2 ТБ/с на чип.⁶⁸ Для порівняння, топовий мережевий інтерфейс 400GbE забезпечує двонаправлену пропускну здатність 50 ГБ/с — на порядок менше, ніж сучасний TPU ICI.
Технологія з'єднань всередині стійок використовує кабелі з прямим під'єднанням міді (DAC) для коротких відстаней між чипами в одному кубі 4×4×4.⁶⁹ Мідні з'єднання мінімізують вартість та споживання енергії, забезпечуючи необхідну пропускну здатність для тісно пов'язаних чипів, що виконують синхронізовані операції. Міжкубові з'єднання та з'єднання масштабу поду переходять на оптичні трансивери, обмінюючи вищу вартість і споживання енергії на відстань та пропускну здатність, необхідні для охоплення стійок центру обробки даних.
Колективні операції експлуатують унікальні властивості ICI. Операції all-reduce, all-gather та reduce-scatter часто синхронізують активації та градієнти між чипами під час навчання. У кластерах GPU на базі Ethernet ці колективні операції проходять через ієрархічну мережу з комутаторами, кабелями та мережевими інтерфейсними картами, вносячи затримку на кожному переході. TPU ICI реалізує оптимізовані колективні алгоритми безпосередньо в апаратному забезпеченні, виконуючи операції all-reduce у 10 разів швидше, ніж еквівалентні реалізації GPU на базі Ethernet.⁷⁰
Оптична комутація каналів: динамічна реконфігурація топології
Розгортання Google оптичної комутації каналів (OCS) з TPU v4 стало однією з найбільш значущих інновацій у мережевих технологіях центрів обробки даних за десятиліття. Традиційні мережі з комутацією пакетів — будь то Ethernet чи InfiniBand — встановлюють логічні з'єднання шляхом маршрутизації пакетів від переходу до переходу через комутатори, що досліджують заголовки та пересилають до відповідних вихідних портів. OCS натомість використовує програмовані оптичні елементи для створення прямих фізичних світлових шляхів між кінцевими точками, повністю виключаючи затримку комутації.⁷¹
Основна технологія спирається на MEMS (мікроелектромеханічні системи) дзеркала, які фізично обертаються для перенаправлення світлових променів. Передавач на TPU A надсилає світло в OCS. Крихітні дзеркала всередині OCS обертаються, щоб відбити цей світловий промінь до приймача на TPU B. З'єднання стає прямим оптичним шляхом від A до B з практично нульовою доданою затримкою, окрім поширення світла через волокно.⁷²
Швидкість реконфігурації визначає практичність OCS у виробничих системах. Розгортання Google досягає часу комутації менше 10 наносекунд — швидше, ніж типові часи кругових поїздок мережевих протоколів.⁷³ Швидкість реконфігурації дозволяє динамічні зміни топології відповідно до вимог робочого навантаження без порушення виконуваних завдань або необхідності ретельно скоординованої інженерії трафіку.
TPU v5p продемонстрував OCS у масивному масштабі. Архітектура використовує оптичні комутатори каналів, що забезпечують чотири петабіти за секунду агрегованої пропускної здатності через комутаційну структуру.⁷⁴ Один суперпод v5p потребує 48 блоків OCS, що керують 13,824 оптичними портами для з'єднання 8,960 чипів у конфігурації 3D-тора 16×20×28.⁷⁵ Система комутації представляє одне з найбільших розгортань оптичних мереж у будь-якому обчислювальному середовищі.
OCS забезпечує можливості, неможливі з традиційними мережами. Фізична топологія та логічна топологія повністю роз'єднуються — два TPU в протилежних кутах центру обробки даних виглядають як сусідні сусіди, якщо OCS створює прямі оптичні шляхи. Несправні чипи або з'єднання обходяться шляхом перепрограмування дзеркал для виключення несправних компонентів та підтримання логічної структури тора. Нові завдання отримують "зрізи" будь-якого розміру шляхом програмування OCS для створення відповідних конфігурацій подів без фізичного перекабелювання стійок.⁷⁶
Архітектура інтегрується з мережею центру обробки даних Google Jupiter для масштабування за межі одного поду. Jupiter забезпечує мультипетабітну пропускну здатність розрізу через цілі центри обробки даних, використовуючи спеціальні кремнієві комутатори Google та площину управління.⁷⁷ Кілька суперподів TPU з'єднуються через структуру Jupiter, теоретично підтримуючи кластери до 400,000 прискорювачів, якщо пропускна здатність мережі дозволяє.⁷⁸
Характеристики споживання енергії та надійності сприяють оптичній комутації каналів для розгортань масштабу TPU. Традиційні комутатори пакетів споживають значну енергію, обробляючи та пересилаючи пакети зі швидкістю терабіт за секунду. Комутатори OCS споживають енергію лише для керування дзеркалами MEMS під час подій реконфігурації, потім залишаються бездіяльними, пропускаючи світло з мінімальними втратами, поки з'єднання залишаються стабільними.⁷⁹ Простота архітектури покращує надійність, виключаючи складну логіку обробки та буферизації пакетів, схильну до помилок та аномалій продуктивності.
Архітектура подів та характеристики масштабування
Поди TPU представляють найбільшу одиничну групу TPU, з'єднаних через ICI, утворюючи уніфікований прискорювач. Фізична структура будується ієрархічно від окремих чипів до лотків до кубів до стійок до повних подів.⁸⁰ Розуміння ієрархії важливе для міркувань про ємність пам'яті, пропускну здатність зв'язку та відмовостійкість на різних масштабах.
Фундаментальний будівельний блок складається з чотирьох чипів на одному лотку, під'єднаних до хост-процесора через PCIe.⁸¹ З'єднання PCIe обробляє операції площини управління, початкове завантаження програм та вхідні/вихідні потоки для навчальних даних та результатів виведення. Фактичний міжчиповий зв'язок для розподіленого навчання проходить через ICI, а не PCIe, уникаючи вузьких місць пропускної здатності PCIe.
Шістнадцять лотків (64 чипи) утворюють один куб 4×4×4 — основну одиницю для побудови подів. Всередині куба всі з'єднання ICI використовують кабелі з прямим під'єднанням міді, оскільки чипи розташовані в одній стійці з короткими фізичними відстанями.⁸² Куб реалізує повний 3D-тор із зворотними з'єднаннями, створюючи самодостатню одиницю з 64 чипів, яка теоретично могла б працювати незалежно.
Поди TPU v4 масштабуються до 64 кубів загалом 4,096 чипів.⁸³ Міжкубові з'єднання переходять на оптичні з'єднання, керовані структурою оптичної комутації каналів. OCS може забезпечити ці 4,096 чипів як один величезний под, кілька менших незалежних подів або динамічно реконфігурувати середину завдання, якщо потрібно. Гнучкість дозволяє операторам центрів обробки даних балансувати використання між різними розмірами завдань та пріоритетами.
TPU v5p довів масштаб поду до 8,960 чипів у 3D-торі 16×20×28.⁸⁴ Конкретні розміри відображають ретельну оптимізацію пропускної здатності та діаметру — просте факторизація має значення для топології мережі! Под забезпечує 4.45 екзафлопс обчислень та представляє одну з найбільших конфігурацій одного поду, розгорнутих у виробництві.
Ironwood підтримує як 256-чипові поди для менших розгортань, так і 9,216-чипові суперподи для масивного навчання граничних моделей.⁸⁵ Конфігурація з 9,216 чипів забезпечує 42.5 FP8 екзафлопс — більше обчислень, ніж містив весь список Top500 суперкомп'ютерів лише п'ять років тому.⁸⁶ Масштаб переосмислює те, чого організації можуть досягти з синхронним навчанням замість конвеєрних або асинхронних підходів.
Ефективність масштабування визначає, чи дійсно допомагають більші поди. Накладні витрати на зв'язок зростають із розміром поду, оскільки чипи витрачають більше часу на синхронізацію, а не на обчислення. Google Research опублікувала результати, що демонструють 95% ефективність масштабування на 32,768 TPU для конкретних робочих навантажень, що означає, що 32,768 TPU забезпечили 95% продуктивності, яку передбачило б ідеальне лінійне масштабування.⁸⁷ Ефективність походить від апаратно-прискорених колективів, оптимізованих трансформацій компілятора та розумних алгоритмічних підходів до зменшення частоти синхронізації градієнтів.
Відмовостійкість на масштабі поду потребує складного обробки. Статистична ймовірність гарантує збої компонентів у будь-якій системі з тисячами чипів, що працюють безперервно. Оптичний комутатор каналів дозволяє витончену деградацію шляхом реконфігурації навколо несправних компонентів. Контрольні точки навчання відбуваються через регулярні інтервали (зазвичай кожні кілька хвилин), тому збій завдання потребує перезапуску лише з останньої контрольної точки, а не з самого початку.⁸⁸
Програмний стек: компілятори, фреймворки та моделі програмування
Компілятор XLA: оптимізація обчислювальних графів
XLA (Accelerated Linear Algebra) є основою програмного стеку TPU, компілюючи операції фреймворків високого рівня в оптимізований машинний код для виконання на TPU.⁸⁹ Компілятор реалізує агресивні оптимізації, неможливі в компіляторах загального призначення, оскільки він використовує знання предметної області про навантаження машинного навчання та характеристики архітектури TPU.
Злиття операцій (fusion) представляє найвпливовішу оптимізацію XLA. Компілятор аналізує обчислювальні графи для ідентифікації послідовностей операцій, які можуть виконуватися без матеріалізації проміжних тензорів. Простий приклад: поелементні операції як relu(batch_norm(conv(x))) зазвичай вимагають запису виходу згортки в пам'ять, зчитування для пакетної нормалізації, запису результату в пам'ять та повторного зчитування для ReLU. XLA об'єднує ці операції в один ядерний код, що виробляє фінальний ReLU вихід без проміжного трафіку пам'яті.⁹⁰
Вплив злиття масштабується з архітектурою TPU. Пропускна здатність пам'яті обмежує багато навантажень більше, ніж обчислювальна пропускна здатність—MXU може виконувати матричні множення швидше, ніж система пам'яті може постачати дані. Усунення проміжних записів та читань пам'яті через злиття безпосередньо перетворюється на покращення продуктивності, часто забезпечуючи прискорення в 2× або більше для мереж з багатьма функціями активації.⁹¹
Трансформації макету пам'яті оптимізують зберігання тензорів для вимог обладнання. Нейронні мережі часто представляють тензори у форматі NHWC (пакет, висота, ширина, канали) для інтуїтивного індексування, але TPU MXU найкраще працюють з макетами, які вирівняні з тайлами 128×8.⁹² XLA автоматично транспонує, змінює форму та доповнює тензори для відповідності апаратним вимогам, вставляючи трансформації макету тільки де необхідно та іноді поширюючи бажані макети назад через граф для мінімізації загального накладу трансформацій.
Компілятор реалізує складну операцію згортання констант та видалення мертвого коду. ML графи часто містять підграфи, виходи яких залежать тільки від констант—параметри пакетної нормалізації, коефіцієнти dropout для висновку та обчислення форм, які можуть виконуватися одного разу замість одного разу на пакет. XLA обчислює ці підграфи під час компіляції та замінює їх константними тензорами, зменшуючи роботу під час виконання.⁹³
Міжрепліційна оптимізація використовує знання про розподілене виконання. При тренуванні на кількох TPU ядрах певні операції (як статистики пакетної нормалізації) вимагають агрегації по всіх репліках. XLA ідентифікує ці патерни та генерує оптимізовані колективні операції, які використовують апаратно-прискорений all-reduce ICI замість реалізації агрегації через явну передачу повідомлень.⁹⁴
Компілятор націлений на проміжне представлення Mosaic, спеціально для TPU. Mosaic працює на вищому рівні абстракції, ніж мова асемблера, але нижчому за вхідний обчислювальний граф. Мова експонує архітектурні особливості TPU, такі як систолічні масиви, векторна пам'ять та проміжне збереження VMEM, приховуючи деталі низького рівня, такі як планування інструкцій та розподіл регістрів.⁹⁵
Можливості авто-налаштування вибирають оптимальні розміри тайлів та параметри операцій через емпіричний пошук. Система XLA Auto-Tuning (XTAT) пробує різні стратегії злиття, макети пам'яті та розміри тайлів, профілює продуктивність кожного варіанта та вибирає найшвидшу конфігурацію.⁹⁶ Пошук може вимагати значного часу компіляції для складних моделей, але забезпечує драматичне прискорення виконання, виявляючи протиінтуїтивні оптимізації, які люди рідко ідентифікують вручну.
JAX: композиційні трансформації та SPMD
JAX забезпечує NumPy-сумісний інтерфейс для чисельних обчислень з автоматичним диференціюванням, JIT компіляцією в XLA та першокласною підтримкою трансформацій програм.⁹⁷ Парадигма функціонального програмування фреймворка та модель композиційних трансформацій природно вирівнюються з моделями виконання TPU та патернами розподіленого паралелізму.
Основна абстракція JAX застосовує математичні трансформації до функцій. grad(f) обчислює градієнт f. jit(f) JIT-компілює f в XLA. vmap(f) векторизує f по новому виміру. Критично, що трансформації компонуються: jit(grad(vmap(f))) працює точно як очікується, компілюючи векторизовану градієнтну функцію.⁹⁸ Композиційна модель дозволяє будувати складні розподілені тренувальні цикли з простих, тестованих компонентів.
SPMD (Single Program, Multiple Data) представляє модель розподіленого виконання JAX. Програмісти пишуть код ніби для одного пристрою, потім додають анотації шардингу, що вказують, як розділити тензори по кількох TPU ядрах. Компілятор XLA та підсистема GSPMD (General SPMD) автоматично вставляють операції комунікації для підтримки семантики програми при виконанні на розподілених пристроях.⁹⁹
Анотації шардингу використовують PartitionSpec для декларування стратегій розподілу. PartitionSpec('batch', None) розділяє перший вимір тензора по осі 'batch' сітки пристроїв, реплікуючи другий вимір. PartitionSpec(None, 'model') реалізує тензорний паралелізм розділенням другого виміру. Анотації можуть компонуватися з довільними рангами тензорів та вимірами сітки пристроїв.¹⁰⁰
Автоматична паралелізація GSPMD усуває величезну кількість шаблонного коду. Традиційне розподілене тренування вимагає ручного вставлення all-gather перед операціями, що потребують повних тензорів, reduce-scatter після обчислення розподілених градієнтів, та all-reduce для глобальних зведень. GSPMD аналізує специфікації шардингу та автоматично вставляє відповідні колективи, звільняючи програмістів зосередитися на алгоритмі замість інжинірингу комунікацій.¹⁰¹
Компілятор поширює рішення шардингу через обчислювальний граф, використовуючи вирішення обмежень. Якщо операція A виводить шардований тензор, що споживається операцією B, GSPMD виводить оптимальний шардинг B на основі того, як використовується вихід, потенційно вставляючи операції решардингу тільки де математично необхідно.¹⁰² Автоматичне виведення запобігає "шардинговим спагеті", які переслідують написаний вручну розподілений код.
JAX забезпечує детальний контроль, коли автоматизація не спрацьовує. with_sharding_constraint примушує специфічний шардинг у розташуваннях графа, перевизначаючи автоматичне виведення. Користувацькі PJIT (parallel JIT) анотації специфікують точне розміщення пристроїв та стратегії шардингу для критичних за продуктивністю шляхів коду. Багаторівнева модель дозволяє швидке прототипування з автоматичним шардингом, підтримуючи експертну оптимізацію де потрібно.¹⁰³
Shardy з'явився як наступник GSPMD у 2025 році, реалізуючи покращені алгоритми поширення обмежень та кращу обробку динамічних форм.¹⁰⁴ Нова система експонує додаткові можливості оптимізації, міркуючи про вибори шардингу спільно по більших регіонах графа замість операція-за-операцією.
PyTorch/XLA: приведення PyTorch до TPU
PyTorch/XLA дозволяє запускати PyTorch моделі на TPU з мінімальними змінами коду, мостячи розрив між імперативною моделлю програмування PyTorch та графовою компіляцією XLA.¹⁰⁵ Інтеграція балансує збереження досвіду розробника PyTorch з експонуванням TPU-специфічних оптимізацій.
Фундаментальний виклик походить від філософії нетерплячого виконання PyTorch. PyTorch виконує операції негайно при виконанні Python інструкцій, дозволяючи відладку стандартними інструментами та природний потік контролю. XLA вимагає захоплення повних обчислювальних графів перед компіляцією, створюючи напругу між нетерплячим виконанням та перевагами продуктивності графової компіляції.¹⁰⁶
PyTorch/XLA 2.4 представив підтримку нетерплячого режиму, вирішуючи невідповідність імпедансу. Реалізація динамічно трасує PyTorch операції в XLA графи, дозволяючи розробникам писати стандартний PyTorch код, все ще отримуючи переваги від XLA компіляції.¹⁰⁷ Режим обмінює деякі можливості оптимізації компіляції на швидкість розробки та простоту відладки.
Графовий режим залишається основним шляхом для виробничих розгортань. Розробники явно позначають функції для XLA компіляції, використовуючи декоратори або API компіляції. Явні анотації дозволяють агресивну оптимізацію, але вимагають розуміння, які операції повинні бути об'єднані в один XLA граф проти виконання незалежно.¹⁰⁸
Інтеграція Pallas приносить розробку користувацьких ядер до PyTorch/XLA. Pallas забезпечує низькорівневу мову для написання TPU ядер, коли автоматичне злиття XLA не спрацьовує або спеціалізовані операції вимагають ручної оптимізації.¹⁰⁹ Мова експонує ієрархію пам'яті TPU (VMEM, CMEM, HBM) та обчислювальні блоки (MXU, VPU), залишаючись вищерівневою за сирий асемблер.
Вбудовані Pallas ядра реалізують критичні за продуктивністю операції як FlashAttention та PagedAttention. Тайлове обчислення уваги FlashAttention зменшує вимоги пропускної здатності пам'яті з O(n²) до O(n) для довжини послідовності n, дозволяючи моделям обробляти набагато довші послідовності в межах фіксованих бюджетів пам'яті.¹¹⁰ PagedAttention оптимізує управління кешем ключ-значення для сервінгу, досягаючи 5× прискорення порівняно з доповненими реалізаціями.¹¹¹
Міст PyTorch/XLA виявився критичним для vLLM TPU—високопродуктивного сервінгового фреймворка, спочатку розробленого для GPU. Реалізація фактично використовує JAX як проміжний шлях зниження навіть для PyTorch моделей, використовуючи кращу підтримку паралелізму JAX при збереженні сумісності з PyTorch frontend.¹¹² Архітектура досягла 2-5× покращення продуктивності протягом 2025 року порівняно з початковими прототипами.
Виклики сумісності моделей залишаються незважаючи на покращення. Деякі PyTorch операції не мають XLA еквівалентів, примушуючи відступ до CPU виконання, що погіршує продуктивність. Динамічний потік контролю погано підтримується графовою компіляцією, часто вимагаючи архітектурних змін для заміни динамічної поведінки статичними, компільованими альтернативами. Репозиторій PyTorch/XLA документує сумісність та надає гіди міграції для поширених проблемних патернів.¹¹³
Формати точності: BFloat16, FP8 та квантизація
Підтримка TPU для арифметики зменшеної точності дозволяє драматичні покращення продуктивності та пам'яті при збереженні прийнятної якості моделі. Розуміння числових властивостей різних форматів та коли застосовувати кожний виявляється критичним для досягнення оптимальної продуктивності.¹¹⁴
BFloat16 представляє ранню ставку Google на тренування зменшеної точності, вперше з'явившись у TPU v2. Формат зберігає 8-бітовий експонент FP32, скорочуючи мантису до 7 біт (плюс знаковий біт).¹¹⁵ Повний діапазон експоненти запобігає недповненню та переповненню, що переслідували раннє FP16 тренування, де градієнти часто виходили за межі представного діапазону FP16.
Зменшена мантиса вводить похибку квантизації, але рідко впливає на фінальну якість моделі. Інженери спостерігали, що моделі, тренувані в bfloat16, зазвичай відповідають FP32-тренованим базовим лініям у межах статистичного шуму, імовірно тому, що квантизація діє як форма регуляризації, запобігаючи перенавчанню на крихітних числових деталях.¹¹⁶ Формат зменшує вдвічі вимоги пропускної здатності та ємності пам'яті порівняно з FP32, безпосередньо перетворюючись на покращення продуктивності на навантаженнях, обмежених пам'яттю.
FP8 веде зменшену точність далі, стискаючи ваги та активації до 8 біт. Існують два стандартні кодування: E4M3 (4-бітовий експонент, 3-бітова мантиса) пріоритизує точність для прямих проходів, тоді як E5M2 (5-бітовий експонент, 2-бітова мантиса) пріоритизує діапазон для зворотних проходів, де величини градієнтів сильно варіюються.¹¹⁷ Ironwood реалізує нативну підтримку FP8 для обох форматів, тоді як попередні TPU емулювали FP8 через програмні трансформації.¹¹⁸
Усвідомлення квантизації під час тренування забезпечує числовий успіх FP8. Моделі, тренувані з нуля з FP8 або тонко налаштовані з FP8-усвідомленими техніками, вивчають розподіли ваг, що толерують обмежену точність формату. Квантизація після тренування (перетворення FP32 моделей у FP8 після тренування) часто погіршує якість без ретельного калібрування.¹¹⁹
Квантизація INT8 забезпечує ще більшу економію пам'яті та прискорення висновку. Accurate Quantized Training (AQT) Google дозволяє INT8 тренування на TPU з мінімальною втратою якості порівняно з bfloat16 базовими лініями.¹²⁰ Техніка застосовує усвідомлене квантизацією тренування з нуля, дозволяючи моделям адаптуватися до обмежень INT8 під час навчання замість після-тренувального наближення.
Стратегії змішаної точності стратегічно комбінують формати. Прямі проходи можуть використовувати FP8 для активацій та ваг, зворотні проходи використовують FP8 E5M2 або bfloat16 для градієнтів, а стани оптимізатора залишаються в FP32 для числової стабільності під час оновлень ваг.¹²¹ Змішаний підхід балансує швидкість, пам'ять та точність, часто досягаючи 90%+ якості FP32 при роботі в 4× швидше.
Компроміси точності поширюються за межі швидкості та пам'яті, включаючи міркування числової стабільності. Пакетна нормалізація, шарова нормалізація та softmax вимагають ретельної числової обробки в зменшеній точності. Великі експоненти в softmax можуть переповнювати діапазони FP8 або bfloat16; віднімання максимального логіта перед експоненціюванням запобігає переповненню при збереженні математичної еквівалентності.¹²² Компілятор XLA реалізує ці трансформації автоматично, коли безпечно, але користувацькі операції іноді вимагають ручного числового інжинірингу.
Моделі програмування та стратегії паралелізму
SPMD та автоматичне розподілення
Парадигма Single Program, Multiple Data (SPMD) фундаментально формує спосіб мислення програмістів про виконання на TPU. Замість написання явного коду передачі повідомлень для координації кількох процесів, розробники пишуть одну програму та анотують, як дані повинні бути розподілені між пристроями.¹²³ Компілятор обробляє механічні деталі розподілу, комунікації та синхронізації.
GSPMD (General SPMD) реалізує логіку автоматичного розподілення в XLA. Система аналізує анотації сегментування тензорів та структуру обчислювального графа, щоб визначити, де операції виконуються на яких пристроях і яка комунікація необхідна для збереження правильної семантики.¹²⁴ Автоматизація усуває цілі класи помилок, поширених у рукописному розподіленому коді—невідповідні форми тензорів, неправильне впорядкування колективних операцій та взаємні блокування від неправильної синхронізації.
Механізм поширення обмежень компілятора виводить рішення щодо сегментування з мінімальних анотацій. Часто достатньо анотувати лише сегментування входу та виходу моделі; GSPMD поширює обмеження через проміжні операції та автоматично вибирає ефективні розподіли.¹²⁵ Коли для операції існує кілька дійсних сегментувань, компілятор оцінює комунікаційні витрати альтернатив та вибирає варіант з найнижчими витратами.
Передові оптимізації перекривають комунікацію з обчисленням. All-reduce операції, що синхронізують градієнти між репліками, можуть початися, як тільки завершуються градієнти першого шару, виконуючись паралельно з зворотними проходами для наступних шарів.¹²⁶ Компілятор автоматично планує колективи для максимізації перекриття, зменшуючи адекватний час комунікації в 2× або більше порівняно з послідовним виконанням.
Ремаtéріалізація обмінює обчислення на пам'ять. Замість збереження всіх активацій прямого проходу для обчислення градієнта, компілятор селективно перераховує активації під час зворотних проходів, коли тиск пам'яті перевищує пороги.¹²⁷ Компроміс особливо добре працює на TPU, де обчислення часто випереджають пропускну здатність пам'яті, що робить перерахунок дешевшим за трафік пам'яті.
Паралелізм даних, тензорний паралелізм та конвеєрний паралелізм
Паралелізм даних представляє найпростішу стратегію розподіленого навчання: реплікувати повну модель на N пристроїв та обробляти різні пакети даних на кожній репліці. Після локального обчислення градієнтів, all-reduce агрегує градієнти між репліками, і всі пристрої застосовують ідентичні оновлення ваг.¹²⁸ Підхід масштабується лінійно, поки час комунікації не починає домінувати над часом обчислення—зазвичай приблизно 1,000 GPU з Ethernet мережею, але 10,000+ TPU з ICI.¹²⁹
Тензорний паралелізм (також називається паралелізмом моделі) розподіляє окремі операції між пристроями. Множення матриць Y = W @ X розділяє матрицю ваг W між пристроями, де кожен обчислює частину виходу.¹³⁰ Стратегія дозволяє навчати моделі, що перевищують пам'ять одного пристрою, розподіляючи зберігання параметрів та обчислення.
Паттерн комунікації для тензорного паралелізму значно відрізняється від паралелізму даних. Замість all-reduce після кожного шару, тензорний паралелізм потребує all-gather перед операціями, що потребують повних тензорів, та reduce-scatter після розподілених обчислень.¹³¹ Обсяг комунікації масштабується з розміром активацій моделі, а не розміром параметрів, створюючи інші вузькі місця, ніж паралелізм даних.
Конвеєрний паралелізм розподіляє послідовні шари моделі між пристроями, одночасно обробляючи різні мікро-пакети на різних етапах. GPipe представив стратегію з ретельним плануванням для максимізації використання конвеєра при обмеженні використання пам'яті.¹³² Кожен пристрій обробляє прямий прохід одного мікро-пакета, надсилає активації на наступний етап, потім обробляє наступний мікро-пакет—створюючи конвеєр, де всі пристрої працюють безперервно після початкового розгону.
Застарілість градієнтів ускладнює конвеєрний паралелізм. Пристрої оновлюють ваги, використовуючи градієнти, обчислені з активацій потенційно десятків мікро-пакетів тому, створюючи застарілість, що може завдати шкоди конвергенції.¹³³ Складні алгоритми планування, як PipeDream, мінімізують застарілість, підтримуючи високу пропускну здатність, а емпіричні результати демонструють, що більшість моделей толерують помірну застарілість без погіршення якості.
3D паралелізм поєднує всі три стратегії. Паралелізм даних розподіляє по "даних" виміру, тензорний паралелізм по "модельному" виміру, а конвеєрний паралелізм по "конвеєрному" виміру.¹³⁴ Ретельне збалансування вимірів на основі архітектури моделі, топології обладнання та комунікаційних витрат максимізує пропускну здатність. Моделі масштабу GPT-3 зазвичай використовують 3D паралелізм з паралелізмом даних по 8-16 репліках, тензорним паралелізмом по 4-8 GPU та конвеєрним паралелізмом по 4-16 етапах.
Стратегії сегментування та оптимізація
Вибір стратегій сегментування потребує розуміння математичних операцій та їх залежностей даних. Множення матриць C = A @ B дозволяє кілька дійсних сегментувань: реплікувати і A, і B та обчислювати часткові результати (комунікація перед обчисленням), сегментувати B по стовпцях та збирати результати (комунікація після обчислення), або сегментувати A по рядках та B по стовпцях без комунікації, але з меншими матрицями на пристрій.¹³⁵
Витрати колективних операцій визначають оптимальні стратегії. All-reduce витрати масштабуються лінійно з розміром тензора, але сублінійно з кількістю пристроїв, використовуючи алгоритми редукції на основі дерева або кільця:¹³⁶ All-gather та reduce-scatter демонструють різні властивості масштабування. Компілятор моделює ці витрати та вибирає стратегії сегментування, що мінімізують загальний час комунікації.
Послідовний паралелізм стає критичним для великих мовних моделей. Механізми уваги створюють вузькі місця пам'яті, оскільки кеші ключ-значення зростають з довжиною послідовності та розміром пакета. Розподіл по виміру послідовності розподіляє навантаження пам'яті між пристроями, вводячи комунікацію лише для самого обчислення уваги.¹³⁷
Паралелізм експертів обробляє моделі Mixture-of-Experts (MoE), де різні експерти обробляють різні токени. Стратегія сегментування реплікує спільні шари на всіх пристроях, але розподіляє експертів, направляючи кожен токен до його призначеного експертного пристрою.¹³⁸ Динамічна маршрутизація створює нерегулярні паттерни комунікації, що кидає виклик традиційним колективним операціям, потребуючи складних систем виконання для мінімізації затримки та дисбалансу навантаження.
Сегментування стану оптимізатора зменшує накладні витрати пам'яті для великих моделей. Оптимізатори, як Adam, зберігають статистику моментуму та варіації для кожного параметра, що потроює вимоги до пам'яті порівняно з лише параметрами. Сегментування станів оптимізатора між пристроями, підтримуючи реплікацію параметрів, дозволяє навчати більші моделі в межах фіксованих бюджетів пам'яті.¹³⁹ Стратегія потребує збирання оновлень стану оптимізатора під час обчислень ваг, але суттєво зменшує слід пам'яті на пристрій.
Аналіз продуктивності та бенчмаркінг
Результати MLPerf та конкурентне позиціонування
MLPerf надає промислові стандартні бенчмарки для вимірювання продуктивності AI-прискорювачів у навчальних та інференсних робочих навантаженнях. Google регулярно подає результати TPU, демонструючи конкурентну продуктивність, а еволюція між поколіннями показує чіткі архітектурні покращення.¹⁴⁰
TPU v5e досяг провідних результатів у 8 з 9 категорій навчання MLPerf.¹⁴¹ Ця широта демонструє архітектурну універсальність поза межами великих мовних моделей—конкурентну продуктивність у комп'ютерному зорі, рекомендаційних системах та обчислювальних навантаженнях для наукових розрахунків. Навчання BERT завершилось у 2.8× разів швидше, ніж GPU NVIDIA A100, підтверджуючи архітектуру, оптимізовану для трансформерів.¹⁴²
MLPerf Training v5.0, оголошений у червні 2025 року, представив бенчмарк Llama 3.1 405B, що є найбільшою моделлю в наборі.¹⁴³ Бенчмарк навантажує багатовузлове масштабування, накладні витрати на комунікацію та ємність пам'яті більше, ніж попередні тести. Google Cloud брав участь із поданнями TPU, хоча детальні порівняння продуктивності залишаються під ембарго до публікації офіційних результатів.
MLPerf Inference v5.0 включав чотири нових бенчмарки: Llama 3.1 405B, Llama 2 70B для застосунків з низькою затримкою, графові нейронні мережі RGAT та PointPainting для 3D детекції об'єктів.¹⁴⁴ Ця різноманітність виводить прискорювачі за межі звичайних робочих навантажень трансформерів у нові прикладні домени, де архітектурні припущення можуть відрізнятися.
Бенчмарки інференсу особливо сприяють архітектурним перевагам TPU. Робочі навантаження пакетного інференсу використовують масовий паралелізм MXU, досягаючи у 4× рази вищої пропускної здатності, ніж конкуруючі прискорювачі для обслуговування трансформерів.¹⁴⁵ Затримка одного запиту виграє від детермінованого виконання TPU та відсутності теплового троттлінгу, забезпечуючи стабільну затримку без варіацій продуктивності, які вражають деякі розгортання GPU.
Метрики енергоефективності показують, що переваги TPU розширюються з поколіннями. TPU v4 продемонстрував у 2.7× рази кращу продуктивність на ват, ніж TPU v3, а Trillium покращив на 67% порівняно з v5e.¹⁴⁶ Ironwood заявляє про у 2× рази кращу продуктивність на ват, ніж Trillium, незважаючи на значно вищу абсолютну продуктивність.¹⁴⁷ Покращення ефективності накопичуються в тисячочіпових подах, що перетворюється на мільйони доларів операційних витрат дата-центрів.
Продуктивність навчання та інференсу в реальних умовах
Виробничі робочі навантаження розкривають характеристики продуктивності, відсутні в синтетичних бенчмарках. Google публікує результати від внутрішніх сервісів, демонструючи поведінку TPU під реальними шаблонами використання та вимогами масштабування.¹⁴⁸
Навчання ResNet-50 ImageNet завершується за 28 хвилин на подах TPU, що є широко цитованим бенчмарком для продуктивності робочих навантажень комп'ютерного зору.¹⁴⁹ Метрика часу до точності охоплює весь процес навчання, включаючи завантаження даних, розширення, синхронізацію розподілених градієнтів та збереження контрольних точок—не лише теоретичні FLOPS.
Навчання мовної моделі T5-3B демонструє переваги TPU на архітектурах трансформерів. Модель з 3 мільярдами параметрів навчається за 12 годин на подах TPU, порівняно з 31 годиною на еквівалентних конфігураціях GPU.¹⁵⁰ Прискорення у 2.6× рази походить від апаратно-прискорених операцій уваги, ефективного використання пропускної здатності пам'яті та оптимізованих колективних комунікацій.
Робочі навантаження масштабу GPT-3 (175B параметрів) досягають у 1.7× рази швидшого часу до точності на TPU, ніж на сучасних GPU.¹⁵¹ Розрив у продуктивності розширюється для ще більших моделей, де ємність пам'яті та пропускна здатність стають критичними обмеженнями. 192GB HBM3e Ironwood дозволяє обслуговувати моделі, які потребують складного тензорного паралелізму на альтернативах з меншою пам'яттю.
Вимірювання ефективності масштабування демонструють майже лінійне прискорення до величезних масштабів. Google Research повідомив про 95% ефективність масштабування на 32,768 TPU для специфічних робочих навантажень навчання трансформерів.¹⁵² Ця метрика означає, що 32,768 TPU забезпечили 95% продуктивності, яку передбачало б ідеальне лінійне масштабування—вражаюче, враховуючи, що накладні витрати на комунікацію збільшуються з масштабом.
Метрики використання FLOPS розкривають, наскільки ефективно робочі навантаження використовують доступні обчислення. Моделі трансформерів зазвичай досягають 90% використання FLOPS на TPU, що означає, що 90% теоретичної пікової продуктивності перетворюється в фактичну роботу.¹⁵³ Високе використання походить від злиття операцій, що усуває вузькі місця пам'яті, ефективності систолічних масивів у великих матричних множеннях та оптимізацій компілятора, які мінімізують втрачені цикли.
Виробничі сервіси інференсу демонструють стабільну продуктивність через мільярди запитів на день. Google Translate обробляє 1 мільярд запитів щодня на TPU.¹⁵⁴ Рекомендації YouTube обслуговують 2 мільярди користувачів, використовуючи моделі з прискоренням TPU.¹⁵⁵ Google Photos аналізує 28 мільярдів зображень щомісяця для функцій пошуку та організації.¹⁵⁶ Операційний масштаб підтверджує надійність та економічну ефективність поза дослідницькими прототипними розгортаннями.
Енергоефективність та загальна вартість володіння
Споживання енергії безпосередньо впливає на операційні витрати дата-центрів та екологічну стійкість. Покращення енергоефективності TPU між поколіннями зменшують як операційні витрати, так і викиди вуглецю у масштабі.¹⁵⁷
TPU v4 у середньому споживав лише 200W потужності у виробничих робочих навантаженнях, незважаючи на специфікацію TDP 250W.¹⁵⁸ Запас між середньою та піковою потужністю дозволяє гнучке тепловодизайн та провізіонінг. На відміну від GPU, де тривалі робочі навантаження часто досягають меж TDP, вимагаючи консервативних бюджетів потужності стійки.
TDP 600W Ironwood представляє вищу абсолютну потужність, ніж попередні покоління, але забезпечує драматично більше обчислень на ват.¹⁵⁹ Продуктивність FP8 4.6 PFLOPS на чіп дає приблизно 7.7 TFLOPS на ват—конкурентоспроможно з або перевищує сучасну ефективність GPU на еквівалентних робочих навантаженнях.
Ефективність використання енергії дата-центру (PUE) посилює ефективність на рівні чіпа. TPU дата-центри Google досягають PUE 1.1, що означає лише 10% накладних витрат потужності понад споживання чіпа для охолодження, перетворення енергії та мережування.¹⁶⁰ Середній промисловий PUE коливається від 1.5 до 2.0, де 50-100% додаткової потужності йде на накладні витрати інфраструктури. Низький PUE походить від передових систем охолодження, ефективної подачі енергії та навмисного дизайну дата-центру, оптимізованого для ML робочих навантажень.
Міркування щодо вуглецевої інтенсивності поширюються за межі потужності, включаючи джерела енергії. Google експлуатує TPU дата-центри на вуглецево-нейтральній енергії через закупівлю відновлюваної енергії та програми компенсації вуглецю.¹⁶¹ Облік вуглецю стає все важливішим для організацій, які відстежують викиди Scope 2 від хмарних обчислень.
Аналіз загальної вартості володіння (TCO) повинен враховувати витрати на придбання, споживання енергії, вимоги охолодження та витрати на обслуговування. Розгортання TPU зазвичай показують зниження TCO на 20-30% порівняно з еквівалентними установками GPU, що обумовлено переважно вищою продуктивністю на ват та зменшеною складністю охолодження.¹⁶²
Витрати на інфраструктуру охолодження масштабуються нелінійно з щільністю потужності. Стійки з повітряним охолодженням зазвичай досягають максимуму 15-20кВт на стійку, перш ніж вимагати екзотичних рішень охолодження. Високопотужні GPU наближаються до цих меж, іноді вимагаючи інфраструктури рідинного охолодження з істотно вищими капітальними та операційними витратами. Ефективність TPU утримує більше розгортань у діапазоні повітряного охолодження, спрощуючи дизайн дата-центру.¹⁶³
Технічні переваги: де TPU перевершують інші рішення
Апаратно-прискорені колективні операції
Спеціалізована підтримка колективних операцій в TPU ICI забезпечує одну з найбільш значних переваг над традиційними мережевими прискорювачами. All-reduce, основна операція для синхронізації градієнтів під час розподіленого навчання, виконується в 10 разів швидше на TPU ICI порівняно з еквівалентними реалізаціями на базі Ethernet для GPU.¹⁶⁴
Різниця в продуктивності пов'язана з архітектурною інтеграцією. Колективні операції на базі Ethernet проходять через кілька рівнів: код програми викликає бібліотеку колективних операцій (NCCL, Horovod тощо), яка генерує пакети, що передаються мережевому стеку, який передає дані на NIC, що серіалізує їх на провід, проходить через комутатори, десеріалізує на приймаючих NIC і повертає процес. Кожен рівень додає затримку, копіює дані через ієрархії пам'яті та споживає цикли CPU для обробки протоколу.¹⁶⁵
TPU ICI реалізує колективні операції в апаратному забезпеченні без проходження через програмний рівень. Операція ініціюється безпосередньо з TensorCore, передає дані через виділені канали ICI і завершується без залучення головного CPU. Прямий апаратний шлях усуває накладні витрати, які домінують у традиційних реалізаціях.¹⁶⁶
Топологія оптичного комутатора з комутацією каналів дозволяє оптимальні алгоритми колективних операцій. Кільцевий all-reduce потребує лише 2(N-1) повідомлень для N пристроїв, а торусна топологія забезпечує маршрутизацію найкоротшим шляхом, мінімізуючи затримку.¹⁶⁷ Рівномірна пропускна здатність бісекції запобігає вузьким місцям, де погано маршрутизовані колективні операції перевантажують мережеві канали.
Уніфікований простір пам'яті та спрощене програмування
Уніфікована модель пам'яті TPU спрощує програмування порівняно зі складними ієрархіями пам'яті GPU. Програмісти міркують про один пул HBM замість управління передачами між RAM хоста, глобальною пам'яттю GPU, спільною пам'яттю та файлами регістрів. Спрощена модель зменшує кількість помилок і дозволяє швидшу швидкість розробки.¹⁶⁸
Фрагментація пам'яті перестає бути проблемою. GPU виділяють пам'ять з фрагментованої купи, де виділення та звільнення з часом створюють дірки, які потребують ущільнення. Управління пам'яттю TPU через статичний аналіз компілятора повністю уникає фрагментації під час виконання — тензори отримують заздалегідь визначені місця на основі обчислювального графа.¹⁶⁹
Модель програмування усуває цілі класи помилок CUDA. Більше немає "незаконного доступу до пам'яті" від неправильної арифметики покажчиків, немає помилок когерентності кешу між CPU та GPU, немає помилок синхронізації від пропущених викликів cudaDeviceSynchronize(). Абстракція вищого рівня запобігає поширеним пасткам у програмуванні CUDA.¹⁷⁰
Детерміністичне виконання та відтворюваність
Неасоціативність чисел з плаваючою комою створює проблеми відтворюваності в паралельних обчисленнях. Вираз (a + b) + c може давати інші результати, ніж a + (b + c) через помилки округлення, а паралельні скорочення можуть сумувати в різному порядку між запусками залежно від умов перегонів.¹⁷¹
Виконання TPU демонструє сильніший детермінізм, ніж типові реалізації GPU. Фіксований шаблон потоку даних систолічного масиву забезпечує ідентичний порядок операцій між запусками. Колективні операції слідують детерміністичним деревам скорочення, а не опортуністичній агрегації на основі порядку прибуття. Передбачуваність дозволяє відтворюване навчання, де ідентичні гіперпараметри та дані створюють побітно ідентичні ваги моделі.¹⁷²
Відлагодження значно виграє від детермінізму. Недетерміністичне навчання робить з'ясування першопричин збоїв майже неможливим — чи NaN від справжньої алгоритмічної помилки або випадкової умови перегонів? Детерміністичне виконання означає, що збої відтворюються надійно, дозволяючи систематичні підходи до відлагодження.¹⁷³
Додатки наукових обчислень особливо цінують відтворюваність. Кліматичні моделі, симуляції відкриття ліків та фізичні дослідження потребують перевірених результатів, які дозволяють різним дослідникам відтворити ідентичні результати. Детермінізм TPU краще підтримує науковий метод, ніж змагальні недетерміністичні альтернативи.¹⁷⁴
Оптимізації компілятора та продуктивність розробників
Агресивна оптимізація XLA забезпечує істотні поліпшення продуктивності "з коробки" без ручного налаштування. Дослідники повідомляють про 40% поліпшення пропускної здатності моделі лише від компіляції порівняно з фреймворками eager execution.¹⁷⁵ Продуктивність надається безкоштовно — не потрібно інженерії ядер.
Оптимізація злиття особливо корисна для розробників. Ручне злиття операцій в CUDA потребує написання користувальницьких ядер, тестування коректності та підтримки коду через версії фреймворків. XLA автоматично зливає операції та оновлення, і адаптує стратегії злиття по мірі еволюції моделей, усуваючи тягар обслуговування.¹⁷⁶
Автоматизація трансформації макетів економить тижні ручної оптимізації. Визначення оптимальних макетів тензорів для GPU потребує профілювання різних схем, ручного вставлення транспонувань та ретельного управління шаблонами виділення пам'яті. XLA автоматично випробовує макети та обирає найшвидший, звільняючи розробників зосередитися на архітектурі моделі, а не на низькорівневій інженерії продуктивності.¹⁷⁷
Приріст продуктивності зростає для дослідницьких команд. Час, заощаджений на оптимізації інфраструктури, прискорює науковий прогрес, дозволяючи більше експериментів та швидші цикли ітерацій. Організації повідомляють про 3× поліпшення швидкості розробки при переході від програмування GPU CUDA до робочих процесів TPU на базі JAX.¹⁷⁸
## Технічні обмеження та недоліки
Прив'язка до платформи та обмеження on-premises
Доступ до TPU надається виключно через Google Cloud Platform, що унеможливлює on-premises розгортання та викликає занепокоення щодо прив'язки до постачальника.¹⁷⁹ Організації з вимогами до суверенітету даних, ізольованими мережами або політикою проти публічних хмар не можуть використовувати TPU незалежно від технічної переваги.
Це обмеження стає все більш важливим, оскільки AI перетворюється на критичну інфраструктуру. Залежність від єдиного хмарного провайдера створює ризики для безперервності бізнесу — зміни цін, перебої в доступності або припинення послуг можуть примусити до дорогих міграцій.¹⁸⁰ Доступність GPU від кількох постачальників (обладнання NVIDIA, що працює на AWS, Azure, GCP та on-prem) надає варіативність, яку TPU архітектурно виключає.
Мультихмарні стратегії зіштовхуються з труднощами. Організації, які стандартизуються на TPU, не можуть легко розширитися на інші хмари або реалізувати мультихмарну надлишковість без перенавчання моделей або підтримки окремих кодових баз для різних архітектур акселераторів.¹⁸¹ Операційна складність гібридних розгортань GPU/TPU часто переважає економію від оптимального вибору акселератора.
Розрив у зрілості екосистеми CUDA
Платформа CUDA від NVIDIA накопичила понад 15 років розвитку екосистеми, бібліотек, документації та знань спільноти, які TPU не може повторити.¹⁸² Розрив у зрілості проявляється у численних проблемах для впровадження TPU.
Доступність бібліотек переважно сприяє CUDA. Спеціалізовані галузі, такі як комп'ютерна графіка, молекулярна динаміка, обчислювальна гідродинаміка та геноміка, накопичили тисячі CUDA-оптимізованих бібліотек протягом останніх десятиліть. TPU еквіваленти часто не існують, що вимагає або повернення до CPU (що руйнує продуктивність) або місяців роботи з портування.¹⁸³
Підтримка спільноти відрізняється на порядки величини. Stack Overflow містить сотні тисяч CUDA питань з детальними відповідями — репозиторії GitHub нараховують мільйони. Доповіді на конференціях, наукові роботи та блоги переважно зосереджені на програмуванні CUDA. Програмісти TPU стикаються з порівняно обмеженими ресурсами, довшими циклами налагодження та меншою кількістю експертів для консультацій.¹⁸⁴
Навчальні матеріали та посібники переважно орієнтовані на CUDA. Університетські курси викладають програмування GPU з використанням CUDA. Онлайн-курси зосереджені на CUDA. Конвеєр талантів виробляє набагато більше інженерів з досвідом CUDA, ніж експертів TPU, створюючи виклики з наймом та навчанням.¹⁸⁵
Розробка кастомних ядер демонструє розрив в екосистемі. Написання оптимізованих CUDA ядер залишається нетривіальним, але користується від обширної документації, інструментів профілювання та прикладного коду. Pallas дозволяє створювати кастомні TPU ядра, але з менш зрілими інструментами та меншою базою знань. Крива навчання відлякує всіх, крім найбільш критичних для продуктивності оптимізацій.¹⁸⁶
Спеціалізація навантажень та обмеження гнучкості
Архітектура TPU оптимізована для специфічних шаблонів навантажень — переважно щільного матричного множення з регулярними шаблонами доступу та великими розмірами пакетів. Операції поза цією оптимальною зоною зіштовхуються з провалами продуктивності.¹⁸⁷
Динамічні форми викликають труднощі в моделях виконання TPU. Компілятор XLA припускає фіксовані розміри тензорів для оптимізації та генерації коду. Моделі з варіативними довжинами послідовностей, динамічним потоком управління або формами, залежними від даних, вимагають заповнення до максимальних розмірів (марно витрачаючи обчислення та пам'ять) або рекомпіляції для кожної окремої форми (руйнуючи продуктивність).¹⁸⁸
Розріджені операції отримують обмежену підтримку, незважаючи на SparseCore. Розріджене матрично-матричне множення, навантаження поширене в наукових обчисленнях та графових нейронних мережах, не має ефективних реалізацій на MXU або VPU. Спеціалізований SparseCore обробляє таблиці вбудовування, але не загальну розріджену лінійну алгебру.¹⁸⁹
Інференс з малими пакетами недовикористовує паралельні ресурси TPU. Систолічний масив 256×256 процвітає на великих матрицях, які заповнюють сітку продуктивною роботою. Інференс одиничних запитів залишає більшість MAC простоюючими, даючи затримку на запит та вартість гіршу за GPU альтернативи, оптимізовані для сценаріїв з малими пакетами.¹⁹⁰
Нерегулярні обчислювальні шаблони руйнують ефективність систолічного масиву. Алгоритми з непередбачуваним розгалуженням, рекурсивними структурами або доступом до пам'яті з переслідуванням вказівників демонструють погану продуктивність TPU, оскільки фіксований потік даних не може адаптуватися до поведінки, залежної від часу виконання.¹⁹¹
Не-ML навантаження рідко отримують користь від TPU прискорення. Наукові симуляції, кодування відео, верифікація blockchain та рендеринг — все це працює швидше на більш загальній архітектурі GPU, незважаючи на вищий піковий FLOPs TPU для матричних операцій.¹⁹²
Прогалини в інструментах налагодження та розробки
Екосистема NVIDIA включає зрілі інструменти профілювання (Nsight Systems, Nsight Compute, nvprof), налагоджувачі (cuda-gdb) та фреймворки аналізу, які вдосконалювалися протягом десятиліть. Інструментарій TPU існує, але суттєво відстає за складністю.¹⁹³
XProf надає базове профілювання через інтеграцію з TensorBoard, але не має детального доступу до апаратних лічильників, який надають інструменти NVIDIA. Розуміння частоти промахів кешу, заповненості, розбіжності warp або конфліктів банків пам'яті — всіх критичних метрик оптимізації GPU — не має TPU еквіваленту через фундаментальну відмінність архітектури.¹⁹⁴
Повідомлення про помилки часто приховують справжні причини. Збої компіляції XLA виводять загадкові повідомлення про невідповідності форм або непідтримувані операції без чітких вказівок щодо вирішення. Помилки CUDA, хоч і відомі своєю безкорисністю, користуються п'ятнадцятьма роками пояснень на StackOverflow та племінних знань.¹⁹⁵
Налагодження розподіленого навчання на мультичіпних pod'ах наближається до неможливого без спеціалізованих інструментів. Умови гонки, помилки синхронізації градієнтів та збої колективних операцій проявляються як недетерміністичні помилки (парадоксально, незважаючи на переваги детермінізму TPU), які відтворюються непослідовно та опираються систематичній діагностиці.¹⁹⁶
Цикл ітерації болісно подовжується для складних моделей. Рекомпіляція для змін форми або модифікацій архітектури може вимагати хвилин, заморожуючи розробку, поки працює компілятор. Модель eager execution CUDA дозволяє швидшу ітерацію, незважаючи на нижчу пікову продуктивність.¹⁹⁷
Реальні розгортання: Виробництво в масштабі
Anthropic Claude: Мультиплатформна стратегія
Оголошення Anthropic в жовтні 2025 року про розгортання понад одного мільйона чіпів TPU представляє найбільше публічно оголошене зобов'язання щодо AI-прискорювачів в історії.¹⁹⁸ Компанія планує отримати доступ до понад гігавата обчислювальної потужності, яка з'явиться онлайн у 2026 році виключно для тренування та обслуговування майбутніх моделей Claude.
Масштаб перевершує попередні розгортання на порядки величини. Один мільйон чіпів, налаштований як Ironwood TPU, забезпечив би приблизно 4.6 ексафлопс обчислень FP8 — більше ніж у 40 разів загальна продуктивність усього списку Top500 суперкомп'ютерів п'ять років тому.¹⁹⁹ Це зобов'язання сигналізує про впевненість в архітектурі TPU для розробки передових моделей у масштабах, які раніше вважалися науковою фантастикою.
Anthropic дотримується обдуманої мультиплатформної апаратної стратегії через TPU Google, Trainium Amazon та GPU NVIDIA.²⁰⁰ Диверсифікація забезпечує страхування потужності, цінове важелювання та географічний розподіл. Claude обслуговує глобально через розгортання на всіх трьох платформах, з маршрутизацією запитів на основі доступності потужності та регіональних вимог до затримки.
Технічний розбір компанії з серпня 2025 року розкрив складності розгортання в масштабі. Неправильна конфігурація на серверах TPU Claude API спричинила помилки генерації токенів, іноді призначаючи несподівано високі ймовірності тайським або китайським символам в англійських промптах.²⁰¹ Інцидент продемонстрував, що навіть прості помилки непередбачувано каскадуються через системи, що обробляють мільярди токенів щоденно.
Окреме розгортання запустило прихований баг в компіляторі XLA: TPU, що вплинув на Claude Haiku 3.5. Баг існував непомічено місяцями, поки конкретна комбінація архітектури моделі та прапорця компілятора не виявила дефект.²⁰² Відкриття підкреслює, що виробниче розгортання знаходить крайні випадки, відсутні в середовищах розробки та тестування.
Інженери Anthropic назвали співвідношення ціна-продуктивність і ефективність TPU основними критеріями вибору. Привабливі економічні показники прискорюють розробку, дозволяючи більші експерименти в рамках фіксованих бюджетів.²⁰³ Тренування більших моделей, дослідження більше конфігурацій гіперпараметрів та швидша ітерація — все це випливає зі зменшення витрат на FLOP.
Google Gemini: Розроблено для TPU з самого початку
Моделі Google Gemini тренуються та обслуговуються виключно на TPU, з архітектурою та процедурами тренування, спільно розробленими для характеристик TPU з самого початку.²⁰⁴ Тісне поєднання дозволяє використовувати оптимізації, специфічні для TPU, які кросплатформні моделі не можуть використовувати.
Розгортання Gemini, як повідомляється, використовує 50,000 чіпів TPU v6e для тренування та обслуговування найбільших варіантів моделі.²⁰⁵ Величезні масштаби поду вимагають складної оркестрації — планування завдань через тисячі чіпів, координації контрольних точок для запобігання вузьких місць, відновлення після збоїв для мінімізації втраченої роботи та моніторингу в реальному часі для виявлення деградованих вузлів до поширення збоїв.
Google тренував Gemini 2.0 на TPU Trillium, валідуючи архітектуру шостого покоління для розробки передових моделей.²⁰⁶ Тренувальний запуск продемонстрував ефективність масштабування до безпрецедентної кількості чіпів, досягаючи сильного масштабування за межами типових плато, де домінує накладні витрати комунікації.
Інфраструктура обслуговування моделей спеціально використовує оптимізації виведення TPU. Пакетна обробка агрегує кілька користувальницьких запитів для максимізації використання MXU. Управління кешем ключ-значення використовує ємність HBM, дозволяючи обробку довготривалого контексту без підкачки диска. Архітектура забезпечує час відповіді менше секунди для складних запитів, обробляючи масивний глобальний обсяг запитів.²⁰⁷
Системи виробничого моніторингу безперервно відстежують 50,000+ TPU, виявляючи аномалії, які можуть погіршити якість моделі або доступність.²⁰⁸ Телеметрія фіксує частоти помилок, процентилі затримки, пропускну здатність, тиск пам'яті та теплові характеристики кожного чіпа. Моделі машинного навчання аналізують самі потоки телеметрії, передбачаючи збої до їх виникнення та запускаючи превентивне обслуговування.
Додаткові виробничі розгортання
Midjourney мігрував з GPU на інфраструктуру TPU, досягнувши 65% зниження витрат і 40% покращення затримки для робочих навантажень генерації зображень.²⁰⁹ Сервіс генерації мистецтва обробляє 300,000 зображень на хвилину при піковому навантаженні, вимагаючи масивної обчислювальної пропускної здатності та стабільної продуктивності при різкозмінних схемах трафіку.
Мовні моделі Cohere на TPU досягли втричі більшої пропускної здатності порівняно з попередніми розгортаннями GPU.²¹⁰ Прискорення дозволило обслуговувати більше клієнтів з тієї ж інфраструктурної площі, безпосередньо покращуючи бізнес-економіку. Компанія використала можливості SPMD JAX для ефективної паралелізації моделей через поди TPU.
Snap забезпечив потужність для 10,000 чіпів TPU v6e, підтримуючи функції доповненої реальності, рекомендаційні системи та інструменти творчого AI.²¹¹ Розгортання охоплює кілька географічних регіонів, забезпечуючи низьку затримку для глобальної бази користувачів Snapchat при збереженні консистентності моделей між регіонами.
Академічні установи все частіше приймають TPU для досліджень. Програма TPU Research Cloud (TRC) надає безкоштовний доступ до TPU для дослідників, дозволяючи експерименти в масштабах, раніше доступних лише добре фінансованим корпоративним лабораторіям.²¹² Демократизація прискорює науковий прогрес, усуваючи апаратні бар'єри для академіків, що досліджують фундаментальні питання про можливості та обмеження AI.
Дебагінг, профілювання та оптимізація продуктивності
Інтеграція XProf та TensorBoard
XProf є основним інструментом профілювання для TPU робочих навантажень, забезпечуючи аналіз продуктивності для JAX, PyTorch/XLA та TensorFlow програм на CPU, GPU та TPU.²¹³ Інструмент інтегрується з TensorBoard для візуалізації, представляючи дані профілювання через знайомі інтерфейси, які ML інженери вже розуміють.
Встановлення вимагає плагін TensorBoard: pip install tensorboard_plugin_profile tensorboard. Це вмикає повний інструментарій.²¹⁴ Запуск профілювання на TPU VM передбачає захоплення трасувань під час навчання або інференції, завантаження результатів до TensorBoard та аналіз візуалізації для виявлення вузьких місць.
Сторінка огляду надає високорівневі метрики підсумку продуктивності, включаючи розбивку часу кроків, використання пристроїв та ідентифікацію вузьких місць верхнього рівня.²¹⁵ Сторінка негайно виділяє, чи обмежені робочі навантаження обчисленнями (MXU працює безперервно), пам'яттю (очікування передач HBM) або комунікацією (заблоковано на колективних операціях).
Переглядач трасувань та аналіз часової шкали
Переглядач трасувань відображає детальні візуалізації часової шкали, показуючи точно коли виконуються операції, коли відбуваються передачі даних та де накопичується час простою.²¹⁶ Інтерфейс на основі Chrome дозволяє масштабування до мікросекундної роздільної здатності, розкриваючи точну поведінку планування, яку приховують агреговані метрики.
Розуміння трасування вимагає розпізнавання загальних шаблонів. Довгі проміжки між операціями вказують на накладні витрати компіляції, вузькі місця завантаження даних або накладні витрати Python через погано оптимізовані конвеєри даних. Повторювані малі операції вказують на недостатнє з'єднання. Колективні операції тривалістю в мілісекунди вказують на неефективність комунікації або погані стратегії шардингу.²¹⁷
Кольорове кодування розрізняє типи операцій: зелений для обчислень, синій для передач пам'яті, оранжевий для комунікації та червоний для часу простою. Оптимізовані робочі навантаження показують щільно упаковані кольорові блоки з мінімальними червоними проміжками. Погано оптимізований код демонструє розріджені часові шкали з довгими червоними ділянками, що вказують на марнування ресурсів.²¹⁸
Розширене використання передбачає кореляцію поведінки часової шкали з вихідним кодом. PyTorch/XLA підтримує користувацькі анотації, вставлені в код, які з'являються в трасуваннях, дозволяючи співставляти поведінку продуктивності з конкретними компонентами моделі.²¹⁹ Анотації перетворюють непрозорі трасування в дієві уявлення про те, які шари або операції потребують фокусу оптимізації.
Інструмент профілю пам'яті та дебагінг OOM
Помилки нестачі пам'яті (OOM) переслідують розробку великих моделей. Інструмент профілю пам'яті відстежує використання пам'яті пристрою під час виконання, захоплюючи пікове використання та шаблони розподілу, які призводять до збоїв OOM.²²⁰
Інструмент візуалізує споживання пам'яті в часі, показуючи які тензори споживають найбільше ємності та коли відбувається пікове використання. Візуалізація часто розкриває несподівані розподіли—буфери градієнтів більші, ніж очікувалося, пам'ять активації, яку слід поставити на контрольну точку, або тимчасові тензори, які XLA не зміг усунути.²²¹
Стратегія дебагінгу передбачає ітеративне зменшення відбитку пам'яті через кілька технік. Контрольні точки градієнта перераховують активації під час зворотних проходів замість їх зберігання. Шардинг стану оптимізатора розподіляє імпульс та варіацію Adam між пристроями. Змішана точність зменшує пам'ять в 2 рази порівняно з FP32. Мікропакетування обробляє менші пакети послідовно, а не один великий пакет.²²²
Розширена оптимізація пам'яті вимагає розуміння рішень компілятора. Прапор xla_dump_to експортує проміжні представлення, показуючи як XLA перетворив обчислювальний граф. Аналіз IR розкриває чи з'єднання вдалося, де відбуваються непотрібні копії та які операції виділяють більше пам'яті, ніж очікувалося.²²³
Аналізатор конвеєра вводу
Попередня обробка CPU часто створює вузькі місця в навчанні TPU. Аналізатор конвеєра вводу визначає чи завантаження даних йде в ногу із споживанням прискорювача або чи TPU простоюють в очікуванні пакетів.²²⁴
Інструмент розділяє аналіз хост-сторони (попередня обробка CPU, розширення даних, збирання пакетів) від виконання пристрою (фактичні обчислення TPU). Робочі навантаження, обмежені вводом, показують падіння використання пристрою під час завантаження даних, поки використання CPU досягає піку. Робочі навантаження, обмежені обчисленнями, підтримують високе використання пристрою з CPU, що комфортно йде в ногу.²²⁵
Стратегії оптимізації залежать від розташування вузького місця. Повільна попередня обробка хоста виграє від паралелізації завантаження даних через більше ядер CPU, зменшення складності розширення на зразок або попереднього завантаження пакетів перед споживанням. Вузькі місця пристрою вимагають змін до архітектури моделі, кращого з'єднання або коригування шардингу, а не налаштування конвеєра даних.²²⁶
## Майбутнє процесорних модулів Tensor
Еволюція сімох поколінь архітектури Google демонструє постійні інновації у спеціалізованих прискорювачах AI. Підтримка FP8 у Ironwood, масштабна ємність пам'яті та масштабування суперподу на 9,216 чипів вказують на траєкторії майбутнього розвитку.²²⁷
Зниження точності, ймовірно, продовжиться до FP4 або навіть нижче для специфічних операцій. Дослідження показують, що багато операцій нейронних мереж толерують екстремальну квантизацію при ретельних процедурах навчання. Майбутні TPU можуть впроваджувати системи змішаної точності з FP4 прямими проходами, FP8 зворотними проходами та FP32 оновленнями оптимізатора.²²⁸
Ємність пам'яті змагається зі зростанням розміру моделей. Поточні передові моделі вже навантажують пам'ять прискорювачів, вимагаючи складних стратегій паралелізму. TPU наступного покоління можуть інтегрувати технології енергонезалежної пам'яті, такі як 3D XPoint або резистивна RAM, забезпечуючи терабайтову пам'ять на пакеті без споживання енергії DRAM.²²⁹
Оптичні з'єднання можуть поширитися за межі комутації ланцюгів, включаючи елементи оптичних обчислень. Дослідження вивчають фотонне матричне множення, що виконується зі швидкістю світла з мінімальним споживанням енергії, потенційно доповнюючи електронні систолічні масиви оптичними співпроцесорами для специфічних операцій.²³⁰
Підтримка розрідженості, ймовірно, розшириться за межі вбудовувань до загальної розрідженої лінійної алгебри. Техніки обрізання нейронних мереж демонструють, що понад 90% ваг можна обнулити без втрати якості. Майбутні архітектури можуть нативно пропускати обчислення з нульовими значеннями замість явного обчислення та відкидання їх.²³¹
Архітектурні принципи, що лежать в основі успіху TPU—доменна спеціалізація, користувацькі з'єднання, співрозроблені програмні стеки та оркестрування масштабу будівлі—вказують на майбутнє все більш спеціалізованих прискорювачів. Замість процесорів універсального призначення ми можемо побачити прискорювачі, оптимізовані для навчання проти виводу, згорткових мереж проти трансформерів, густих проти розріджених моделей, та коротких проти довгих послідовностей.²³²
Інженери, які сьогодні будують AI інфраструктуру, повинні глибоко розуміти архітектуру TPU. Незалежно від того, чи розгортають на Google Cloud, конкурують з Google на ринку прискорювачів, або проектують ML системи наступного покоління, принципи дизайну та компроміси, втілені в TPU, розкривають фундаментальні істини про те, що AI навантаження вимагають від обладнання. Математика систолічних масивів, дизайн ієрархії пам'яті, топологія з'єднань та стратегії оптимізації компілятора представляють десятиліття накопиченої мудрості, застосовної далеко за межами самого TPU.
Напруження між спеціалізацією та універсальністю, що визначає TPU проти GPU, триватиме невизначено довго. TPU жертвують гнучкістю заради екстремальної ефективності на вузьких навантаженнях. GPU жертвують піковою ефективністю заради більшої застосовності. Жодний підхід не домінує—оптимальний вибір повністю залежить від характеристик навантаження, масштабу, обмежень вартості та операційних вимог. Організації, що досягають успіху з AI у великому масштабі, все частіше застосовують гетерогенні стратегії, підбираючи архітектури прискорювачів під вимоги навантаження замість стандартизації на одній платформі.
Зобов'язання Anthropic щодо мільйона чипів TPU демонструє, що архітектура досягла виробничої зрілості на найвищих масштабах. Мультигігаватні розгортання, що вводяться в експлуатацію у 2026 році, навчатимуть моделі, що розширюють межі того, чого може досягти AI, а інфраструктура, що забезпечує ці моделі, втілює інженерну витонченість, якої мало організацій змогли досягти. Розуміння того, як 65,536 блоків множення-накопичення в систолічному масиві співпрацюють для навчання передових моделей, має значення для будь-кого, хто серйозно ставиться до майбутнього AI.
Джерела
-
Google Cloud Press Corner, "Anthropic to Expand Use of Google Cloud TPUs and Services," 23 жовтня 2025 р., https://www.googlecloudpresscorner.com/2025-10-23-Anthropic-to-Expand-Use-of-Google-Cloud-TPUs-and-Services.
-
TrendForce, "Google Unveils 7th-Gen TPU Ironwood with 9,216-Chip Superpod, Taking Aim at NVIDIA," 7 листопада 2025 р., https://www.trendforce.com/news/2025/11/07/news-google-unveils-7th-gen-tpu-ironwood-with-9216-chip-superpod-taking-aim-at-nvidia/.
-
Norman P. Jouppi та ін., "TPU v4: An Optically Reconfigurable Supercomputer for Machine Learning with Hardware Support for Embeddings," в Proceedings of the 50th Annual International Symposium on Computer Architecture (2023), arXiv:2304.01433.
-
Anthropic, "Expanding our use of Google Cloud TPUs and Services," Anthropic News, жовтень 2025 р., https://www.anthropic.com/news/expanding-our-use-of-google-cloud-tpus-and-services.
-
Google Cloud Blog, "Quantifying the performance of the TPU, our first machine learning chip," квітень 2017 р., https://cloud.google.com/blog/products/gcp/quantifying-the-performance-of-the-tpu-our-first-machine-learning-chip.
-
Norman P. Jouppi та ін., "In-Datacenter Performance Analysis of a Tensor Processing Unit," Proceedings of the 44th Annual International Symposium on Computer Architecture (2017), arXiv:1704.04760.
-
Jouppi та ін., "In-Datacenter Performance Analysis."
-
Jouppi та ін., "In-Datacenter Performance Analysis."
-
Jonathan Hui, "AI Chips: Google TPU," Medium, отримано в грудні 2025 р., https://jonathan-hui.medium.com/ai-chips-tpu-3fa0b2451a2d.
-
Wikipedia, "Bfloat16 floating-point format," отримано в грудні 2025 р., https://en.wikipedia.org/wiki/Bfloat16_floating-point_format.
-
Henry Ko, "TPU Deep Dive," особистий блог, отримано в грудні 2025 р., https://henryhmko.github.io/posts/tpu/tpu.html.
-
Wikipedia, "Tensor Processing Unit," отримано в грудні 2025 р., https://en.wikipedia.org/wiki/Tensor_Processing_Unit.
-
Wikipedia, "Tensor Processing Unit."
-
Wikipedia, "Tensor Processing Unit."
-
Ko, "TPU Deep Dive."
-
Jouppi та ін., "TPU v4: An Optically Reconfigurable Supercomputer."
-
Jouppi та ін., "TPU v4: An Optically Reconfigurable Supercomputer."
-
Jouppi та ін., "TPU v4: An Optically Reconfigurable Supercomputer."
-
Jouppi та ін., "TPU v4: An Optically Reconfigurable Supercomputer."
-
OpenXLA Project, "A deep dive into SparseCore for Large Embedding Models (LEM)," отримано в грудні 2025 р., https://openxla.org/xla/sparsecore.
-
JAX Scaling Guide, "How to Think About TPUs," отримано в грудні 2025 р., https://jax-ml.github.io/scaling-book/tpus/.
-
JAX Scaling Guide, "How to Think About TPUs."
-
Ko, "TPU Deep Dive."
-
JAX Scaling Guide, "How to Think About TPUs."
-
Google Cloud Blog, "Introducing Trillium, sixth-generation TPUs," травень 2024 р., https://cloud.google.com/blog/products/compute/introducing-trillium-6th-gen-tpus.
-
Google Cloud Blog, "Introducing Trillium."
-
Google Cloud Blog, "Introducing Trillium."
-
Google Cloud Blog, "Introducing Trillium."
-
Google Cloud Blog, "Introducing Trillium."
-
Google Blog, "Ironwood: The first Google TPU for the age of inference," листопад 2025 р., https://blog.google/products/google-cloud/ironwood-tpu-age-of-inference/.
-
XPU.pub, "Google Adds FP8 to Ironwood TPU; Can It Beat Blackwell?" 16 квітня 2025 р., https://xpu.pub/2025/04/16/google-ironwood/.
-
TrendForce, "Google Unveils 7th-Gen TPU Ironwood."
-
The Register, "Google's 7th-gen Ironwood TPUs promise 42 AI exaFLOPS pods," 10 квітня 2025 р., https://www.theregister.com/2025/04/10/googles_7thgen_ironwood_tpus_debut/.
-
TrendForce, "Google Unveils 7th-Gen TPU Ironwood."
-
Ko, "TPU Deep Dive."
-
XPU.pub, "Google Adds FP8 to Ironwood TPU."
-
Google Cloud Press Corner, "Anthropic to Expand Use."
-
Telesens, "Understanding Matrix Multiplication on a Weight-Stationary Systolic Architecture," 30 липня 2018 р., https://telesens.co/2018/07/30/systolic-architectures/.
-
Telesens, "Understanding Matrix Multiplication."
-
Jouppi та ін., "In-Datacenter Performance Analysis."
-
Telesens, "Understanding Matrix Multiplication."
-
CP Lu, "Should We All Embrace Systolic Arrays?" Medium, отримано в грудні 2025 р., https://cplu.medium.com/should-we-all-embrace-systolic-array-df3830f193dc.
-
Google Cloud Documentation, "TPU architecture," отримано в грудні 2025 р., https://docs.cloud.google.com/tpu/docs/system-architecture-tpu-vm.
-
Google Cloud Documentation, "TPU architecture."
-
Hui, "AI Chips: Google TPU."
-
Telnyx, "Architecture insights: MXU and TPU components," отримано в грудні 2025 р., https://telnyx.com/learn-ai/mxu-tpu.
-
Ko, "TPU Deep Dive."
-
Jouppi та ін., "TPU v4: An Optically Reconfigurable Supercomputer."
-
SemiEngineering, "Tensor Processing Unit (TPU)," отримано в грудні 2025 р., https://semiengineering.com/knowledge_centers/integrated-circuit/ic-types/processors/tensor-processing-unit-tpu/.
-
TrendForce, "Google Unveils 7th-Gen TPU Ironwood."
-
SemiEngineering, "Tensor Processing Unit (TPU)."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Google Cloud Documentation, "Cloud TPU performance guide," отримано в грудні 2025 р., https://cloud.google.com/tpu/docs/performance-guide.
-
OpenXLA Project, "A deep dive into SparseCore."
-
OpenXLA Project, "A deep dive into SparseCore."
-
OpenXLA Project, "A deep dive into SparseCore."
-
Jouppi та ін., "TPU v4: An Optically Reconfigurable Supercomputer."
-
OpenXLA Project, "A deep dive into SparseCore."
-
Jouppi та ін., "TPU v4: An Optically Reconfigurable Supercomputer."
-
OpenXLA Project, "A deep dive into SparseCore."
-
JAX Scaling Guide, "How to Think About TPUs."
-
JAX Scaling Guide, "How to Think About TPUs."
-
JAX Scaling Guide, "How to Think About TPUs."
-
Ko, "TPU Deep Dive."
-
JAX Scaling Guide, "How to Think About TPUs."
-
JAX Scaling Guide, "How to Think About TPUs."
-
TrendForce, "Google Unveils 7th-Gen TPU Ironwood."
-
Ko, "TPU Deep Dive."
-
Anthropic, "Expanding our use of Google Cloud TPUs."
-
Jouppi та ін., "TPU v4: An Optically Reconfigurable Supercomputer."
-
Jouppi та ін., "TPU v4: An Optically Reconfigurable Supercomputer."
-
Jouppi та ін., "TPU v4: An Optically Reconfigurable Supercomputer."
-
Jouppi та ін., "TPU v4: An Optically Reconfigurable Supercomputer."
-
Ko, "TPU Deep Dive."
-
Jouppi та ін., "TPU v4: An Optically Reconfigurable Supercomputer."
-
Leon Poutievski, "Mission Apollo: Landing Optical Circuit Switching at Datacenter Scale," LinkedIn, червень 2022 р., https://www.linkedin.com/posts/leon-poutievski-8910a851_mission-apollo-landing-optical-circuit-switching-activity-6968472071534235649-cB4l.
-
Ko, "TPU Deep Dive."
-
Jouppi та ін., "TPU v4: An Optically Reconfigurable Supercomputer."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Jouppi та ін., "TPU v4: An Optically Reconfigurable Supercomputer."
-
JAX Scaling Guide, "How to Think About TPUs."
-
TrendForce, "Google Unveils 7th-Gen TPU Ironwood."
-
TrendForce, "Google Unveils 7th-Gen TPU Ironwood."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
OpenXLA Project, "XLA: Optimizing Compiler for Machine Learning," отримано в грудні 2025 р., https://openxla.org/xla.
-
Daniel Snider та Ruofan Liang, "Operator Fusion in XLA: Analysis and Evaluation," наукова стаття, отримано в грудні 2025 р., https://danielsnider.ca/papers/Operator_Fusion_in_XLA_Analysis_and_Evaluation.pdf.
-
Snider та Liang, "Operator Fusion in XLA."
-
APXML, "Memory-Aware Data Layout Transformations (NCHW/NHWC)," отримано в грудні 2025 р., https://apxml.com/courses/compiler-runtime-optimization-ml/chapter-3-advanced-graph-level-optimizations/memory-aware-layout-transformations.
-
OpenXLA Project, "XLA."
-
PyTorch Documentation, "Pytorch/XLA Overview," отримано в грудні 2025 р., https://docs.pytorch.org/xla/master/learn/xla-overview.html.
-
OpenXLA Project, "A deep dive into SparseCore."
-
Mangpo Phothilimthana та ін., "A Flexible Approach to Autotuning Multi-Pass Machine Learning Compilers," PACT 2021, отримано в грудні 2025 р., https://mangpo.net/papers/xla-autotuning-pact2021.pdf.
-
JAX Documentation, "Introduction to parallel programming," отримано в грудні 2025 р., https://docs.jax.dev/en/latest/sharded-computation.html.
-
GitHub, "jax-ml/jax: Composable transformations of Python+NumPy programs," отримано в грудні 2025 р., https://github.com/jax-ml/jax.
-
OpenXLA Project, "Shardy Guide for JAX Users," отримано в грудні 2025 р., https://openxla.org/shardy/getting_started_jax.
-
JAX Documentation, "Introduction to parallel programming."
-
OpenXLA Project, "Shardy Guide for JAX Users."
-
OpenXLA Project, "Shardy Guide for JAX Users."
-
JAX Documentation, "Introduction to parallel programming."
-
OpenXLA Project, "Shardy Guide for JAX Users."
-
PyTorch Documentation, "Pytorch/XLA Overview."
-
GitHub, "RFC: Evolving PyTorch/XLA for a more native experience on TPU," Issue #9684, отримано в грудні 2025 р., https://github.com/pytorch/xla/issues/9684.
-
Google Cloud Blog, "PyTorch/XLA 2.4 improves Pallas and adds 'eager mode,'" отримано в грудні 2025 р., https://cloud.google.com/blog/products/ai-machine-learning/pytorch-xla-2-4-improves-pallas-and-adds-eager-mode/.
-
PyTorch Documentation, "Pytorch/XLA Overview."
-
PyTorch Documentation, "Custom Kernels via Pallas," отримано в грудні 2025 р., https://docs.pytorch.org/xla/master/features/pallas.html.
-
PyTorch Documentation, "Custom Kernels via Pallas."
-
PyTorch Documentation, "Custom Kernels via Pallas."
-
vLLM Blog, "vLLM TPU: A New Unified Backend Supporting PyTorch and JAX on TPU," 16 жовтня 2025 р., https://blog.vllm.ai/2025/10/16/vllm-tpu.html.
-
GitHub, "pytorch/xla," отримано в грудні 2025 р., https://github.com/pytorch/xla.
-
StackGpu, "FP8, BF16, and INT8: How Low-Precision Formats Are Revolutionizing Deep Learning Throughput," Medium, отримано в грудні 2025 р., https://medium.com/@StackGpu/fp8-bf16-and-int8-how-low-precision-formats-are-revolutionizing-deep-learning-throughput-e6c1f3adabc2.
-
Wikipedia, "Bfloat16 floating-point format."
-
Wikipedia, "Bfloat16 floating-point format."
-
Paulius Micikevicius та ін., "FP8 Formats for Deep Learning," arXiv:2209.05433, вересень 2022 р.
-
XPU.pub, "Google Adds FP8 to Ironwood TPU."
-
Micikevicius та ін., "FP8 Formats for Deep Learning."
-
Google Cloud Blog, "Accurate Quantized Training (AQT) for TPU v5e," отримано в грудні 2025 р., https://cloud.google.com/blog/products/compute/accurate-quantized-training-aqt-for-tpu-v5e.
-
StackGpu, "FP8, BF16, and INT8."
-
Jeffrey Tse, "Understanding the FP64, FP32, FP16, BFLOAT16, TF32, FP8 Formats," особистий блог, 9 грудня 2024 р., https://jeffreytse.net/computer/2024/12/09/understanding-the-fp64-fp32-fp16-bfloat16-tf32-fp8-formats.html.
-
PyTorch Blog, "PyTorch/XLA SPMD: Scale Up Model Training and Serving with Automatic Parallelization," отримано в грудні 2025 р., https://pytorch.org/blog/pytorch-xla-spmd/.
-
OpenXLA Project, "Shardy Guide for JAX Users."
-
JAX Documentation, "Introduction to parallel programming."
-
OpenXLA Project, "Shardy Guide for JAX Users."
-
Ko, "TPU Deep Dive."
-
JAX Documentation, "Introduction to parallel programming."
-
Anthropic, "Expanding our use of Google Cloud TPUs."
-
JAX Documentation, "Introduction to parallel programming."
-
JAX Documentation, "Introduction to parallel programming."
-
Adam Roberts та ін., "Scaling Up Models and Data with t5x and seqio," arXiv:2203.17189, березень 2022 р.
-
Roberts та ін., "Scaling Up Models and Data."
-
JAX Documentation, "Introduction to parallel programming."
-
JAX Documentation, "Introduction to parallel programming."
-
OpenXLA Project, "Shardy Guide for JAX Users."
-
Roberts та ін., "Scaling Up Models and Data."
-
Roberts та ін., "Scaling Up Models and Data."
-
Ko, "TPU Deep Dive."
-
MLCommons, "Benchmark MLPerf Training," отримано в грудні 2025 р., https://mlcommons.org/benchmarks/training/.
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
HPCwire, "MLPerf Training v5.0 Benchmark Results Reflect Rapid Growth in the Field of AI," червень 2025 р., https://www.hpcwire.com/off-the-wire/mlperf-training-v5-0-benchmark-results-reflect-rapid-growth-in-the-field-of-ai/.
-
MLCommons, "MLCommons Releases New MLPerf Inference v5.0 Benchmark Results," квітень 2025 р., https://mlcommons.org/2025/04/mlperf-inference-v5-0-results/.
-
Ko, "TPU Deep Dive."
-
Google Cloud Blog, "TPU v4 enables performance, energy and CO2e efficiency gains," отримано в грудні 2025 р., https://cloud.google.com/blog/topics/systems/tpu-v4-enables-performance-energy-and-co2e-efficiency-gains.
-
TrendForce, "Google Unveils 7th-Gen TPU Ironwood."
-
Google Cloud Blog, "Quantifying the performance of the TPU."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Artech Digital, "Energy-Efficient GPU vs. TPU Allocation," отримано в грудні 2025 р., https://www.artech-digital.com/blog/energy-efficient-gpu-vs-tpu-allocation.
-
Wikipedia, "Tensor Processing Unit."
-
XPU.pub, "Google Adds FP8 to Ironwood TPU."
-
Ko, "TPU Deep Dive."
-
Google Cloud Blog, "TPU v4 enables performance, energy and CO2e efficiency gains."
-
ByteBridge, "GPU and TPU Comparative Analysis Report," Medium, отримано в грудні 2025 р., https://bytebridge.medium.com/gpu-and-tpu-comparative-analysis-report-a5268e4f0d2a.
-
ByteBridge, "GPU and TPU Comparative Analysis Report."
-
Anthropic, "Expanding our use of Google Cloud TPUs."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
DataCamp, "Understanding TPUs vs GPUs in AI: A Comprehensive Guide," отримано в грудні 2025 р., https://www.datacamp.com/blog/tpu-vs-gpu-ai.
-
Ko, "TPU Deep Dive."
-
DataCamp, "Understanding TPUs vs GPUs in AI."
-
Grigory Sapunov, "FP64, FP32, FP16, BFLOAT16, TF32, and other members of the ZOO," Medium, отримано в грудні 2025 р., https://moocaholic.medium.com/fp64-fp32-fp16-bfloat16-tf32-and-other-members-of-the-zoo-a1ca7897d407.
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Snider та Liang, "Operator Fusion in XLA."
-
APXML, "Memory-Aware Data Layout Transformations."
-
Google Cloud Blog, "How Lightricks trains video diffusion models at scale with JAX on TPU," отримано в грудні 2025 р., https://cloud.google.com/blog/products/media-entertainment/how-lightricks-trains-video-diffusion-models-at-scale-with-jax-on-tpu.
-
CloudOptimo, "TPU vs GPU: What's the Difference in 2025?" отримано в грудні 2025 р., https://www.cloudoptimo.com/blog/tpu-vs-gpu-what-is-the-difference-in-2025/.
-
Phoenix NAP, "TPU vs. GPU: Differences Explained," отримано в грудні 2025 р., https://phoenixnap.com/kb/tpu-vs-gpu.
-
CloudOptimo, "TPU vs GPU."
-
DataCamp, "Understanding TPUs vs GPUs in AI."
-
Tailscale, "TPU vs GPU: Which Is Better for AI Infrastructure in 2025?" отримано в грудні 2025 р., https://tailscale.com/learn/what-is-tpu-vs-gpu.
-
DataCamp, "Understanding TPUs vs GPUs in AI."
-
DataCamp, "Understanding TPUs vs GPUs in AI."
-
PyTorch Documentation, "Custom Kernels via Pallas."
-
Phoenix NAP, "TPU vs. GPU: Differences Explained."
-
Ko, "TPU Deep Dive."
-
OpenMetal, "TPU vs GPU: Pros and Cons," отримано в грудні 2025 р., https://openmetal.io/docs/product-guides/private-cloud/tpu-vs-gpu-pros-and-cons/.
-
OpenMetal, "TPU vs GPU: Pros and Cons."
-
Phoenix NAP, "TPU vs. GPU: Differences Explained."
-
PRIMO.ai, "Processing Units - CPU, GPU, APU, TPU, VPU, FPGA, QPU," отримано в грудні 2025 р., https://primo.ai/index.php?title=Processing_Units_-_CPU%2C_GPU%2C_APU%2C_TPU%2C_VPU%2C_FPGA%2C_QPU.
-
DataCamp, "Understanding TPUs vs GPUs in AI."
-
Google Cloud Documentation, "Profile your model on Cloud TPU VMs," отримано в грудні 2025 р., https://cloud.google.com/tpu/docs/cloud-tpu-tools.
-
DataCamp, "Understanding TPUs vs GPUs in AI."
-
Ko, "TPU Deep Dive."
-
GitHub, "RFC: Evolving PyTorch/XLA."
-
Google Cloud Press Corner, "Anthropic to Expand Use."
-
TrendForce, "Google Unveils 7th-Gen TPU Ironwood."
-
Maginative, "Anthropic Secures 1M Google TPUs While Keeping Amazon as Primary Training Partner," отримано в грудні 2025 р., https://www.maginative.com/article/anthropic-secures-1m-google-tpus-while-keeping-amazon-as-primary-training-partner/.
-
Anthropic, "A postmortem of three recent issues," Engineering Blog, серпень 2025 р., https://www.anthropic.com/engineering/a-postmortem-of-three-recent-issues.
-
Anthropic, "A postmortem of three recent issues."
-
AI Magazine, "Why Anthropic Uses Google Cloud TPUs for AI Infrastructure," отримано в грудні 2025 р., https://aimagazine.com/news/why-anthropic-uses-google-cloud-tpus-for-ai-infrastructure.
-
Google Cloud Blog, "Ironwood TPUs and new Axion-based VMs for your AI workloads," листопад 2025 р., https://cloud.google.com/blog/products/compute/ironwood-tpus-and-new-axion-based-vms-for-your-ai-workloads.
-
Ko, "TPU Deep Dive."
-
TrendForce, "Google Unveils 7th-Gen TPU Ironwood."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Google Cloud, "Tensor Processing Units (TPUs)," отримано в грудні 2025 р., https://cloud.google.com/tpu.
-
TensorFlow Documentation, "Optimize TensorFlow performance using the Profiler," отримано в грудні 2025 р., https://www.tensorflow.org/guide/profiler.
-
Google Cloud Documentation, "Profile your model on Cloud TPU VMs."
-
TensorFlow Documentation, "TensorFlow Profiler: Profile model performance," отримано в грудні 2025 р., https://www.tensorflow.org/tensorboard/tensorboard_profiling_keras.
-
Google Cloud Documentation, "Profile your model on Cloud TPU VMs."
-
Google Cloud Blog, "PyTorch/XLA: Performance debugging on Cloud TPU VM: Part III," отримано в грудні 2025 р., https://cloud.google.com/blog/topics/developers-practitioners/pytorchxla-performance-debugging-cloud-tpu-vm-part-iii.
-
Google Cloud Blog, "PyTorch/XLA: Performance debugging Part III."
-
Google Cloud Documentation, "Profile PyTorch XLA workloads," отримано в грудні 2025 р., https://docs.cloud.google.com/tpu/docs/pytorch-xla-performance-profiling-tpu-vm.
-
TensorFlow Documentation, "Optimize TensorFlow performance using the Profiler."
-
TensorFlow Documentation, "Optimize TensorFlow performance using the Profiler."
-
Ko, "TPU Deep Dive."
-
Google Cloud Documentation, "Cloud TPU performance guide."
-
TensorFlow Documentation, "Optimize TensorFlow performance using the Profiler."
-
TensorFlow Documentation, "Optimize TensorFlow performance using the Profiler."
-
TensorFlow Documentation, "Optimize TensorFlow performance using the Profiler."
-
TrendForce, "Google Unveils 7th-Gen TPU Ironwood."
-
Tse, "Understanding the FP64, FP32, FP16, BFLOAT16, TF32, FP8 Formats."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."


