
Tensor Processing Unit Google menggerakkan mayoritas model AI mutakhir yang berinteraksi dengan Anda setiap hari, namun sebagian besar engineer tetap mengejutkan tidak familiar dengan arsitekturnya. Meskipun GPU NVIDIA mendominasi mindshare developer, TPU secara diam-diam melatih dan melayani Gemini 2.0, Claude, dan puluhan model frontier lainnya pada skala yang akan memangkrutkan sebagian besar organisasi yang menggunakan infrastruktur GPU konvensional. Anthropic baru-baru ini berkomitmen untuk men-deploy lebih dari satu juta chip TPU—mewakili lebih dari satu gigawatt kapasitas komputasi—untuk melatih model Claude masa depan.¹ Generasi Ironwood terbaru Google menghadirkan 42,5 exaflops komputasi FP8 melintasi superpod 9.216-chip, skala yang mendefinisikan ulang apa arti infrastruktur AI produksi.²
Kecanggihan teknis di balik TPU meluas jauh melampaui metrik performa sederhana. Prosesor ini mewujudkan filosofi desain yang fundamentally berbeda dari GPU, menukar fleksibilitas general-purpose untuk spesialisasi ekstrem dalam perkalian matrix dan operasi tensor. Engineer yang memahami arsitektur TPU dapat mengeksploitasi systolic array 256×256 yang memproses 65.536 operasi multiply-accumulate per siklus, memanfaatkan akselerator SparseCore generasi ketiga untuk workload embedding-intensive, dan memprogram optical circuit switch yang mengkonfigurasi ulang topologi datacenter multi-petabit dalam waktu kurang dari 10 nanodetik.³ Arsitekturnya mencakup segala hal dari keputusan desain tingkat transistor hingga orkestrasi superkomputer skala gedung.
Konten teknis di depan menuntut perhatian yang cermat. Kami memeriksa tujuh generasi evolusi TPU, membedah matematika systolic array dan pola dataflow, mengeksplorasi hierarki memori dari tile SRAM hingga channel HBM3e, menganalisis optimisasi compiler XLA pada tingkat intermediate representation, dan menyelidiki mengapa operasi kolektif mengeksekusi 10× lebih cepat dari kluster GPU berbasis Ethernet yang setara.⁴ Anda akan menemui spesifikasi tingkat register, pemodelan performa cycle-accurate, dan tradeoff arsitektural yang membuat TPU secara bersamaan lebih powerful dan lebih terkendala daripada GPU. Kedalaman di sini melayani engineer yang membangun generasi infrastruktur AI berikutnya dan peneliti yang mendorong batas-batas dari apa yang dapat dicapai akselerator saat ini.
Evolusi: Tujuh Generasi Inovasi Arsitektur
TPU v1: Spesialisasi Inference-Only (2015)
Google menerapkan Tensor Processing Unit pertama pada tahun 2015 untuk mengatasi masalah kritis: beban kerja inference neural network terancam menggandakan jejak datacenter perusahaan.⁵ Engineer merancang TPU v1 khusus untuk inference, menghilangkan seluruhnya kemampuan training untuk memaksimalkan performa dan efisiensi daya untuk model yang sudah di-deploy. Chip ini menampilkan systolic array 256×256 dari unit multiply-accumulate integer 8-bit, memberikan 92 teraops per detik hanya dengan thermal design power 28-40 watt.⁶
Arsitekturnya mengusung minimalisme radikal. Satu Matrix Multiply Unit memproses operasi INT8 melalui dataflow weight-stationary, dimana weight tetap fixed di systolic array sementara aktivasi mengalir horizontal melintasi grid. Partial sum dipropagasi secara vertikal, mengeliminasi intermediate memory write untuk keseluruhan matrix multiplication. Chip yang terhubung ke host system via PCIe ini mengandalkan DDR3 DRAM untuk external memory dan beroperasi pada 700 MHz—sengaja konservatif untuk efisiensi daya.⁷
Peningkatan performa mencengangkan bahkan engineer Google sendiri. TPU v1 mencapai peningkatan 30× hingga 80× dalam operations per watt dibandingkan CPU dan GPU kontemporer untuk beban kerja inference produksi.⁸ Chip ini menangani ranking Google Search, layanan translate yang memproses 1 miliar permintaan harian, dan rekomendasi YouTube untuk 2 miliar pengguna. Kesuksesan ini memvalidasi insight arsitektural inti: accelerator yang dibangun khusus untuk beban kerja sempit dapat memberikan peningkatan order-of-magnitude dibanding processor general-purpose.
TPU v2: Mengaktifkan Training dalam Skala Besar (2017)
Generasi kedua mentransformasi TPU dari accelerator inference-only menjadi platform training yang lengkap. Google mendesain ulang seluruh arsitektur di sekitar operasi floating-point, mengganti array INT8 256×256 dengan dual multiply-accumulator bfloat16 128×128 per core.⁹ Setiap chip berisi dua TensorCore yang berbagi 8GB High Bandwidth Memory per core, upgrade masif dari DDR3 yang menyediakan bandwidth yang dibutuhkan neural network training.
Presisi bfloat16 terbukti kritis untuk kesuksesan TPU v2. Format ini mempertahankan exponent range 8-bit yang sama dengan FP32 sambil mengurangi mantissa menjadi 7 bit, mempertahankan dynamic range untuk training sambil memotong setengah kebutuhan memory bandwidth.¹⁰ Engineer mengamati bahwa presisi mantissa yang dikurangi sebenarnya meningkatkan generalisasi pada banyak model dengan bertindak sebagai bentuk regularisasi, sementara exponent range FP32 penuh mencegah masalah underflow dan overflow yang mengganggu training FP16.
Inovasi arsitektural yang benar-benar membedakan TPU v2 adalah Inter-Chip Interconnect (ICI). Accelerator sebelumnya memerlukan Ethernet atau InfiniBand untuk komunikasi multi-chip, memunculkan bottleneck latency dan bandwidth. Google merancang custom high-speed bidirectional link yang menghubungkan setiap TPU langsung ke empat neighbor dalam topologi 2D torus.¹¹ Interconnect ini memungkinkan "pod" TPU v2 hingga 256 chip berfungsi sebagai single logical accelerator, dengan operasi kolektif seperti all-reduce mengeksekusi jauh lebih cepat dibanding alternatif berbasis network.
TPU v3: Water-Cooled Performance Scaling (2018)
Google mendorong clock speed dan core count secara agresif pada TPU v3, memberikan 420 teraflops per chip—lebih dari menggandakan performa v2.¹² Peningkatan power density memaksa perubahan arsitektural dramatis: liquid cooling. Setiap TPU v3 pod memerlukan infrastruktur water cooling, penyimpangan dari desain air-cooled generasi sebelumnya dan sebagian besar datacenter accelerator.¹³
Chip ini mempertahankan arsitektur dual 128×128 MXU namun meningkatkan total jumlah core dan memperbaiki memory bandwidth. Setiap TPU v3 berisi empat chip dengan dua core masing-masing, berbagi total 32GB HBM memory di seluruh chip.¹⁴ Vector processing unit mendapat peningkatan untuk activation function, operasi normalisasi, dan komputasi gradient yang sering membuat bottleneck training hanya pada matrix unit.
Deployment diskalakan ke pod 2.048-chip menggunakan topologi ICI 2D torus yang sama dengan v2 namun dengan bandwidth per-link yang ditingkatkan. Google melatih model yang semakin besar pada pod v3, menemukan bahwa diameter network yang dikurangi topologi torus (jarak maksimum antara dua chip skala sebagai N/2 daripada N) meminimalkan overhead komunikasi untuk strategi training data-parallel dan model-parallel.¹⁵
TPU v4: Optical Circuit Switching Breakthrough (2021)
Generasi keempat mewakili lompatan arsitektural paling signifikan Google sejak TPU original. Engineer meningkatkan skala pod ke 4.096 chip sambil memperkenalkan optical circuit switching (OCS) untuk interconnect, teknologi yang dipinjam dari telekomunikasi yang merevolusi infrastruktur ML skala datacenter.¹⁶
Arsitektur inti TPU v4 menampilkan empat 128×128 MXU per TensorCore bersama enhanced vector dan scalar unit. Setiap pasangan TensorCore berbagi 128MB Common Memory selain per-core Vector Memory, memungkinkan pola staging data dan reuse yang lebih sophisticated.¹⁷ Topologi chip berevolusi dari 2D ke 3D torus, menghubungkan setiap TPU ke enam neighbor daripada empat, lebih jauh mengurangi diameter network dan meningkatkan bisection bandwidth.
Sistem optical circuit switching mengubah segalanya tentang deployment skala besar. Daripada kabel tetap antara TPU, Google men-deploy programmable optical switch yang dapat merekonfigurasi secara dinamis chip mana yang terhubung ke mana. Mirror MEMS (microelectromechanical systems) secara fisik mengarahkan ulang light beam untuk meng-patch pasangan TPU arbitrer bersama-sama, memperkenalkan pada dasarnya zero latency di luar waktu transmisi optical fiber.¹⁸ Switch merekonfigurasi dalam window sub-10-nanosecond, lebih cepat dari sebagian besar handshake protokol network.
Arsitektur OCS memungkinkan kemampuan yang sebelumnya tidak mungkin. Google dapat menyediakan "slice" dari ukuran apa pun, dari empat chip hingga pod penuh 4.096-chip, dengan memprogram optical switch secara tepat. Chip yang failed dapat di-route around dengan mulus tanpa mematikan seluruh rack. Yang paling menakjubkan, TPU yang secara fisik jauh di lokasi datacenter berbeda dapat secara logis bersebelahan dalam topologi network, memisahkan layout fisik dan logis sepenuhnya.¹⁹
TPU v4 juga memperkenalkan SparseCore, processor khusus untuk menangani operasi embedding yang digunakan setiap hari dalam recommendation system, ranking model, dan large language model dengan massive vocabulary embedding. SparseCore menampilkan empat dedicated processor per chip, masing-masing dengan 2.5MB scratchpad memory dan dataflow yang dioptimalkan untuk pola akses memory sparse.²⁰ Model dengan ultra-large embedding mencapai speedup 5-7× menggunakan hanya 5% dari total chip die area dan power budget.
TPU v5p dan v5e: Spesialisasi dan Skala (2022-2023)
Google membagi generasi kelima menjadi dua produk berbeda yang menargetkan use case yang berbeda. TPU v5p memprioritaskan performa maksimum untuk training skala besar, sementara v5e dioptimalkan untuk inference cost-effective dan training job yang lebih kecil.²¹
TPU v5p mencapai sekitar 4.45 exaflops per detik di seluruh pod 8.960-chip, lebih dari menggandakan ukuran pod maksimum v4.²² Bandwidth interconnect mencapai 4.800 Gbps per chip, dan topologi 3D torus menghubungkan chip dalam superpod 16×20×28 yang masif. Fabric optical circuit switching mengelola 13.824 optical port di seluruh 48 unit OCS untuk meng-wire superpod v5p lengkap, mewakili salah satu deployment optical switching produksi terbesar dalam sejarah computing.²³
TPU v5e mengambil pendekatan berbeda, mengurangi core count dan clock speed untuk mencapai target daya dan biaya yang agresif. Chip yang dioptimalkan inference berisi hanya satu TPU core per chip daripada dua, dan kembali ke topologi 2D torus, yang cukup untuk ukuran pod yang lebih kecil.²⁴ Simplifikasi arsitektural memungkinkan Google menetapkan harga v5e secara kompetitif untuk beban kerja dimana performa absolut kurang penting dibanding performa per dolar.
TPU v6e Trillium: Quadrupling Matrix Performance (2024)
Trillium menandai titik balik arsitektural lain dengan memperluas Matrix Multiply Unit dari 128×128 ke 256×256 multiply-accumulator.²⁵ Array yang lebih besar memperkuat empat kali lipat FLOP per cycle pada clock speed yang sama, memberikan 4.7× performa compute puncak TPU v5e melalui kombinasi MXU yang diperluas dan frekuensi clock yang ditingkatkan.
Subsistem memori mendapat upgrade yang sama dramatisnya. Kapasitas HBM digandakan menjadi 32GB per chip, dengan bandwidth digandakan oleh channel HBM generasi berikutnya.²⁶ Bandwidth Interchip Interconnect juga digandakan, memungkinkan pod 256 chip Trillium mempertahankan throughput yang lebih tinggi untuk model yang menekan baik compute maupun komunikasi.²⁷
Trillium menampilkan accelerator SparseCore generasi ketiga, dengan kemampuan yang ditingkatkan untuk ultra-large embedding dalam beban kerja ranking dan rekomendasi. Desain yang diperbarui meningkatkan pola akses memori dan meningkatkan bandwidth yang memadai antara SparseCore dan HBM untuk model yang didominasi oleh embedding lookup daripada matrix multiplication.²⁸
Efisiensi energi meningkat 67% dari v5e meskipun ada peningkatan performa substansial.²⁹ Google mencapai peningkatan efisiensi melalui advanced process node, optimisasi arsitektural yang mengurangi wasted work, dan power gating yang hati-hati dari unit yang tidak terpakai selama operasi yang tidak menekan semua bagian chip secara bersamaan.
TPU v7 Ironwood: Era FP8 (2025)
TPU generasi ketujuh Google, berkode nama Ironwood, mewakili TPU pertama yang dirancang dengan dukungan FP8 native dan dioptimalkan khusus untuk "age of inference" sambil mempertahankan performa training state-of-the-art.³⁰ Setiap chip Ironwood memberikan 4.6 petaFLOPS compute FP8 dense—sedikit melampaui NVIDIA B200 yang bersaing pada 4.5 petaFLOPS—sambil menarik 600W thermal design power.³¹
Sistem memori diperluas ke 192GB HBM3e memory per chip, enam kali kapasitas Trillium, dengan bandwidth mencapai 7.4TB/s.³² Peningkatan memori dramatis memungkinkan serving ultra-large model dengan key-value cache yang sebelumnya memerlukan tensor parallelism yang kompleks di seluruh multiple accelerator. Google secara khusus merancang kapasitas memori untuk mendukung emerging multi-modal model dan aplikasi konteks panjang yang mendekati million-token window.
Interconnect Ironwood menyediakan 9.6 Tbps aggregate bidirectional bandwidth melalui empat ICI link, diterjemahkan ke 1.2 TB/s peak per-chip bandwidth.³³ Arsitektur diskalakan dari pod 256-chip untuk deployment yang lebih kecil ke superpod 9.216-chip masif yang memberikan 42.5 FP8 exaflops compute power.³⁴ Teknologi Jupiter datacenter network Google secara teoritis dapat mendukung hingga 43 superpod Ironwood dalam single cluster—kira-kira 400.000 accelerator yang mewakili skala compute yang hampir tidak terbayangkan.³⁵
Dukungan FP8 mewakili pergeseran fundamental dalam strategi presisi. Generasi TPU sebelumnya mengemulasi operasi 8-bit menggunakan teknik software, yang memperkenalkan overhead. Ironwood mengimplementasikan native FP8 multiply-accumulate unit yang mendukung format E4M3 (4-bit exponent, 3-bit mantissa) dan E5M2 (5-bit exponent, 2-bit mantissa).³⁶ Dukungan dual format memungkinkan pencampuran E4M3 untuk forward pass dimana presisi kurang penting dan E5M2 untuk backward pass dimana mempertahankan magnitude gradient mencegah instabilitas training.
Komitmen Anthropic untuk men-deploy lebih dari satu juta chip Ironwood mulai 2026 mendemonstrasikan kesiapan produksi arsitektur. Perusahaan berencana memanfaatkan lebih dari satu gigawatt kapasitas TPU—cukup untuk memberi daya pada small city—khusus untuk training dan serving model Claude.³⁷ Skala ini mengerdilkan bahkan deployment GPU paling signifikan yang diketahui dan mewakili taruhan fundamental pada arsitektur TPU untuk pengembangan frontier model.
Referensi Cepat Generasi Saat Ini
Tabel berikut menyediakan spesifikasi yang dapat dipindai untuk tiga TPU generasi saat ini yang paling relevan untuk deployment produksi pada tahun 2025:
Tabel 1: Spesifikasi Compute Inti
[caption id="" align="alignnone" width="1386"] SpesifikasiTPU v5eTPU v5pTPU v6e (Trillium)TPU v7 (Ironwood) Ukuran Array MXU 128×128 128×128 256×256 256×256 MAC per Cycle 16.384 16.384 65.536 65.536 Peak BF16 TFLOPS ~197 ~459 ~918 ~2.300 (est.) Peak FP8 PFLOPS N/A (emulated) N/A (emulated) N/A (emulated) 4.6 Native Precision BF16, INT8 BF16, INT8 BF16, INT8 BF16, FP8, INT8 TensorCore/Chip 1 2 1 1 [/caption]
SpesifikasiTPU v5eTPU v5pTPU v6e (Trillium)TPU v7 (Ironwood) Ukuran Array MXU 128×128 128×128 256×256 256×256 MAC per Cycle 16.384 16.384 65.536 65.536 Peak BF16 TFLOPS ~197 ~459 ~918 ~2.300 (est.) Peak FP8 PFLOPS N/A (emulated) N/A (emulated) N/A (emulated) 4.6 Native Precision BF16, INT8 BF16, INT8 BF16, INT8 BF16, FP8, INT8 TensorCore/Chip 1 2 1 1 [/caption]
Tabel 2: Memory dan Bandwidth
[caption id="" align="alignnone" width="1380"]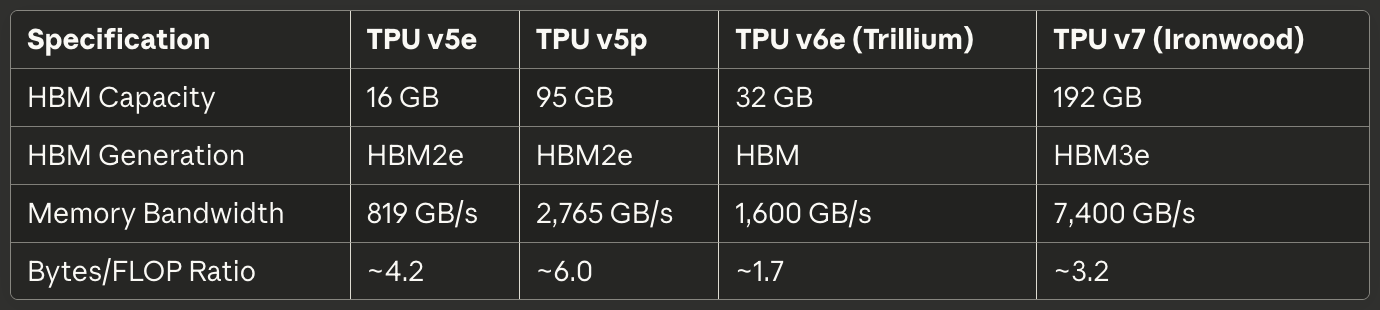 SpesifikasiTPU v5eTPU v5pTPU v6e (Trillium)TPU v7 (Ironwood) Kapasitas HBM 16 GB 95 GB 32 GB 192 GB Generasi HBM HBM2e HBM2e HBM HBM3e Memory Bandwidth 819 GB/s 2.765 GB/s 1.600 GB/s 7.400 GB/s Rasio Bytes/FLOP ~4.2 ~6.0 ~1.7 ~3.2 [/caption]
SpesifikasiTPU v5eTPU v5pTPU v6e (Trillium)TPU v7 (Ironwood) Kapasitas HBM 16 GB 95 GB 32 GB 192 GB Generasi HBM HBM2e HBM2e HBM HBM3e Memory Bandwidth 819 GB/s 2.765 GB/s 1.600 GB/s 7.400 GB/s Rasio Bytes/FLOP ~4.2 ~6.0 ~1.7 ~3.2 [/caption]
Tabel 3: Interconnect dan Scaling
[caption id="" align="alignnone" width="1384"]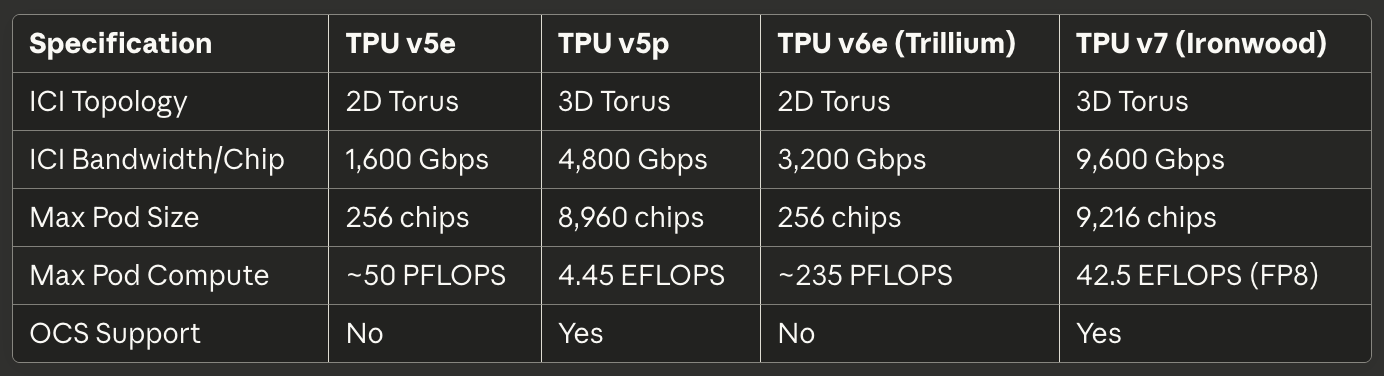 SpesifikasiTPU v5eTPU v5pTPU v6e (Trillium)TPU v7 (Ironwood) Topologi ICI 2D Torus 3D Torus 2D Torus 3D Torus ICI Bandwidth/Chip 1.600 Gbps 4.800 Gbps 3.200 Gbps 9.600 Gbps Ukuran Pod Max 256 chip 8.960 chip 256 chip 9.216 chip Compute Pod Max ~50 PFLOPS 4.45 EFLOPS ~235 PFLOPS 42.5 EFLOPS (FP8) Dukungan OCS Tidak Ya Tidak Ya [/caption]
SpesifikasiTPU v5eTPU v5pTPU v6e (Trillium)TPU v7 (Ironwood) Topologi ICI 2D Torus 3D Torus 2D Torus 3D Torus ICI Bandwidth/Chip 1.600 Gbps 4.800 Gbps 3.200 Gbps 9.600 Gbps Ukuran Pod Max 256 chip 8.960 chip 256 chip 9.216 chip Compute Pod Max ~50 PFLOPS 4.45 EFLOPS ~235 PFLOPS 42.5 EFLOPS (FP8) Dukungan OCS Tidak Ya Tidak Ya [/caption]
Tabel 4: Power dan Efisiensi
[caption id="" align="alignnone" width="1380"] SpesifikasiTPU v5eTPU v5pTPU v6e (Trillium)TPU v7 (Ironwood) TDP ~120-200W ~250-300W ~120-200W 600W Cooling Air Liquid Air Liquid TFLOPS/Watt (BF16) ~1.0-1.6 ~1.5-1.8 ~4.6-7.7 ~3.8 Energi vs Gen Sebelumnya Baseline N/A 67% lebih baik dari v5e 2× lebih baik dari Trillium [/caption]
SpesifikasiTPU v5eTPU v5pTPU v6e (Trillium)TPU v7 (Ironwood) TDP ~120-200W ~250-300W ~120-200W 600W Cooling Air Liquid Air Liquid TFLOPS/Watt (BF16) ~1.0-1.6 ~1.5-1.8 ~4.6-7.7 ~3.8 Energi vs Gen Sebelumnya Baseline N/A 67% lebih baik dari v5e 2× lebih baik dari Trillium [/caption]
Tabel 5: Recommended Use Case
[caption id="" align="alignnone" width="1382"] Use Case Pilihan Terbaik Rasional Inference cost-optimized TPU v5e: Biaya terendah per query inference Training skala besar (>1000 chip) TPU v5p atau Ironwood 3D torus + OCS memungkinkan pod masif Training job menengah (256 chip) TPU v6e Trillium Perf/watt terbaik, 4.7× compute vs v5e Model memory-bound (>70B param) Ironwood 192GB HBM memungkinkan batch size lebih besar Inference konteks panjang (>100K token) Ironwood Kapasitas HBM mendukung massive KV cache Beban kerja embedding-heavy TPU v5p atau Ironwood SparseCore + HBM besar [/caption]
Use Case Pilihan Terbaik Rasional Inference cost-optimized TPU v5e: Biaya terendah per query inference Training skala besar (>1000 chip) TPU v5p atau Ironwood 3D torus + OCS memungkinkan pod masif Training job menengah (256 chip) TPU v6e Trillium Perf/watt terbaik, 4.7× compute vs v5e Model memory-bound (>70B param) Ironwood 192GB HBM memungkinkan batch size lebih besar Inference konteks panjang (>100K token) Ironwood Kapasitas HBM mendukung massive KV cache Beban kerja embedding-heavy TPU v5p atau Ironwood SparseCore + HBM besar [/caption]
Arsitektur Hardware: Di Dalam Silikon
Matematika Systolic Array dan Dataflow
Matrix Multiply Unit membentuk jantung arsitektur TPU, dan memahami systolic array memerlukan pemahaman pendekatan mereka yang secara fundamental berbeda terhadap paralelisme dibandingkan GPU SIMD lane. Systolic array menghubungkan unit multiply-accumulate dalam grid dimana data mengalir secara ritmis melalui struktur—maka "systolic," mengingat pompa darah ritmis melalui jantung.³⁸
Perhatikan systolic array 256×256 TPU v6e yang melakukan matrix multiplication C = A × B. Engineer memuat weight dari matrix B ke dalam 65.536 unit multiply-accumulate individual yang disusun dalam grid. Nilai aktivasi matrix A masuk dari tepi kiri dan mengalir horizontal melintasi array. Setiap unit MAC mengalikan weight yang tersimpan dengan aktivasi yang masuk, menambahkan hasil ke partial sum yang tiba dari atas, dan meneruskan baik aktivasi (horizontal) maupun partial sum yang diperbarui (vertikal) ke unit tetangga.³⁹
Pola dataflow berarti setiap nilai aktivasi digunakan kembali 256 kali saat melintasi dimensi horizontal, dan setiap partial sum mengakumulasi kontribusi dari 256 perkalian saat mengalir vertikal. Yang penting, semua hasil intermediate melewati langsung antara unit MAC yang bersebelahan via kabel pendek daripada round-trip ke memori. Arsitektur melakukan 65.536 operasi multiply-accumulate setiap clock cycle, dan selama keseluruhan matrix multiplication yang melibatkan berpotensi jutaan operasi, zero nilai intermediate menyentuh DRAM atau bahkan on-chip SRAM.⁴⁰
Pola dataflow weight-stationary dioptimalkan untuk kasus paling umum dalam neural network inference dan training: berulang kali mengalikan banyak matrix aktivasi yang berbeda dengan matrix weight yang sama. Engineer memuat weight sekali, lalu mengalirkan batch aktivasi tanpa batas melalui array tanpa reload. Pola ini bekerja sangat baik untuk convolutional layer, fully connected layer, dan operasi Q·K^T dan attention·V yang mendominasi transformer model.⁴¹
Efisiensi energi berasal dari reuse data dan spatial locality. Membaca nilai dari DRAM mengkonsumsi kira-kira 200× energi sebanyak operasi multiply-accumulate tunggal.⁴² Dengan menggunakan kembali setiap weight 256 kali dan setiap aktivasi 256 kali tanpa akses memori, systolic array mencapai rasio operations-per-watt yang tidak mungkin untuk arsitektur yang mengangkut data bolak-balik antara compute unit dan hierarki memori.
Kelemahan systolic array muncul dengan pola komputasi dinamis atau tidak teratur. Karena data mengalir melalui grid pada jadwal tetap, arsitektur kesulitan dengan eksekusi kondisional, sparse matrix (kecuali menggunakan SparseCore), dan operasi yang memerlukan pola akses acak. Ketidakfleksibelan menukar generalitas untuk efisiensi ekstrim pada beban kerja targetnya: dense matrix multiplication dengan pola akses yang dapat diprediksi.
Arsitektur Internal TensorCore
Setiap chip TPU berisi satu atau lebih TensorCore—unit pemrosesan lengkap yang terdiri dari Matrix Multiply Unit, Vector Processing Unit, dan Scalar Unit yang bekerja bersama.⁴³ TensorCore mewakili building block fundamental yang ditargetkan software, dan memahami interaksi antara tiga komponennya menjelaskan baik karakteristik performa TPU maupun pola programming.
Matrix Multiply Unit mengeksekusi 16.000 operasi multiply-accumulate per cycle pada input bfloat16 atau FP8 dengan akumulasi FP32.⁴⁴ Pendekatan mixed-precision mempertahankan akurasi numerik dalam accumulator sambil mengurangi memory bandwidth untuk input. Engineer mengamati bahwa mempertahankan presisi FP32 lengkap selama akumulasi mencegah kesalahan catastrophic cancellation saat menjumlahkan ratusan atau ribuan produk intermediate, sementara input presisi-dikurangi jarang mempengaruhi kualitas model final.
Vector Processing Unit menangani operasi yang tidak cocok untuk struktur rigid MXU. Activation function (ReLU, GELU, SiLU), normalization layer (batch norm, layer norm), softmax, pooling, dropout, dan operasi element-wise dieksekusi pada arsitektur SIMD 128-lane VPU.⁴⁵ VPU beroperasi pada datatype FP32 dan INT32, menyediakan presisi yang diperlukan untuk operasi numerik sensitive seperti softmax, dimana eksponensial dan pembagian dapat menciptakan dynamic range yang besar.
Scalar Unit mengorkestrasi seluruh TensorCore. Processor single-threaded mengeksekusi control flow, menghitung alamat memori untuk pola pengindeksan kompleks, dan memulai transfer DMA dari High Bandwidth Memory ke Vector Memory.⁴⁶ Karena scalar unit berjalan single-threaded, setiap TensorCore dapat membuat hanya satu permintaan DMA per cycle—bottleneck untuk operasi memory-intensive yang tidak jenuh throughput compute MXU atau VPU.
Hierarki memori yang memberi makan TensorCore menentukan performa yang dapat dicapai sebanyak kemampuan compute mentah. Vector Memory (VMEM) bertindak sebagai scratchpad SRAM yang dikelola software eksklusif untuk setiap TensorCore, biasanya berukuran puluhan megabyte. Compiler XLA secara eksplisit menjadwalkan pergerakan data antara HBM dan VMEM, memutuskan apa yang akan di-stage ke dalam fast local memory dan kapan menulis hasil kembali.⁴⁷
Common Memory (CMEM), hadir dalam TPU v4 dan generasi selanjutnya, menyediakan shared pool yang lebih besar yang dapat diakses oleh semua TensorCore pada chip. Arsitektur TPU v4 mengalokasikan 128MB CMEM yang dibagi antara dua TensorCore, memungkinkan pola producer-consumer yang lebih sophisticated dimana output satu core menjadi input core lain tanpa round-trip ke HBM.⁴⁸
Implikasi model programming sangat penting. Karena scalar unit single-thread dan vector memory memerlukan manajemen eksplisit, programming TPU menyerupai pengembangan embedded system era 1990-an lebih dari programming GPU modern. CUDA mengabstraksi pergerakan memori dengan unified memory dan cache yang dikelola hardware; kode TPU (baik yang dihasilkan oleh XLA atau ditulis tangan dalam Pallas) harus secara eksplisit mengorkestrasi setiap transfer data. Kontrol manual memungkinkan optimisasi expert namun meningkatkan bar untuk performa yang kompeten.
Arsitektur High Bandwidth Memory
TPU modern menggunakan HBM (High Bandwidth Memory), atau HBM3e, teknologi memori yang secara radikal berbeda dari DDR SDRAM yang ditemukan dalam CPU, dan GDDR yang digunakan dalam banyak GPU. HBM menumpuk multiple DRAM die secara vertikal menggunakan through-silicon via (TSV), lalu menempatkan stack langsung bersebelahan dengan processor die pada silicon interposer.⁴⁹ Jalur elektrik yang pendek dan interface yang lebar memungkinkan bandwidth yang secara dramatis lebih tinggi dibanding teknologi memori konvensional.
TPU v7 Ironwood mengimplementasikan 192GB HBM3e dengan total bandwidth 7.4 TB/s.⁵⁰ Sistem memori dibagi menjadi multiple channel, masing-masing menyediakan akses independen ke porsi terpisah dari total kapasitas. Compiler XLA dan runtime harus hati-hati mempartisi tensor di seluruh channel HBM untuk memaksimalkan akses paralel dan menghindari hotspot dimana satu channel jenuh sementara yang lain duduk idle.
Lebar interface memori mengerdilkan DRAM konvensional. Dimana channel DDR5 mungkin menyediakan 64 bit lebar, channel HBM biasanya membentang 1.024 bit.⁵¹ Lebar ekstrim memungkinkan bandwidth tinggi pada clock speed yang relatif sederhana, mengurangi konsumsi daya dan tantangan integritas sinyal dibandingkan mendorong interface sempit ke frekuensi multi-gigahertz.
Karakteristik latency berbeda secara substansial dari sistem memori GPU. TPU tidak memiliki cache yang dikelola hardware di luar buffer lokal kecil, jadi arsitektur bergantung pada software yang secara eksplisit men-staging data ke dalam VMEM jauh sebelum compute unit membutuhkannya. Kurangnya cache berarti latency memori secara langsung mempengaruhi performa kecuali compiler berhasil menyembunyikan latency melalui prefetching dan double-buffering.⁵²
Batasan kapasitas memori mendominasi banyak beban kerja lebih dari throughput compute. Model 175 miliar parameter dengan weight bfloat16 memerlukan 350GB untuk menyimpan parameter—sudah melampaui 192GB HBM Ironwood bahkan sebelum memperhitungkan aktivasi, optimizer state, atau gradient buffer. Training model seperti itu menuntut teknik sophisticated seperti gradient checkpointing, optimizer state sharding di seluruh multiple chip, dan penjadwalan update parameter yang hati-hati untuk meminimalkan memory footprint.⁵³
Runtime TPU memberlakukan persyaratan layout tensor spesifik untuk memaksimalkan efisiensi MXU. Karena systolic array memproses data dalam tile 128×8, tensor harus align dengan dimensi ini untuk menghindari padding waste.⁵⁴ Matrix berukuran buruk memaksa hardware memproses tile parsial dengan MAC yang duduk idle, langsung mengurangi utilisasi FLOPS. Compiler mencoba untuk pad dan reshape tensor secara otomatis, namun pilihan layout yang sadar dalam arsitektur model dapat secara substansial meningkatkan performa.
SparseCore: Akselerasi Embedding Spesialis
Sementara Matrix Multiply Unit unggul dalam operasi matrix dense, beban kerja embedding-intensive menunjukkan karakteristik yang secara radikal berbeda. Model rekomendasi, sistem ranking, dan large language model sering mengakses massive embedding table (sering ratusan gigabyte) melalui indeks irregular dan data-dependent. Dataflow terstruktur MXU tidak memberikan keuntungan untuk pola akses memori sparse ini, memotivasi arsitektur khusus SparseCore.⁵⁵
SparseCore mengimplementasikan tiled dataflow processor yang secara fundamental berbeda dari systolic array MXU. TPU v4 menampilkan empat SparseCore per chip, masing-masing berisi 16 compute tile.⁵⁶ Setiap tile beroperasi sebagai unit dataflow independen dengan scratchpad memory lokal (SPMEM) dan elemen pemrosesan. Tile mengeksekusi secara paralel, memproses subset terpisah dari operasi embedding secara bersamaan.
Hierarki memori menempatkan hot data dalam SPMEM kecil dan cepat sambil menyimpan embedding table penuh dalam HBM. Compiler XLA menganalisis pola akses embedding untuk menentukan vektor embedding mana yang layak di-cache dalam SPMEM versus diambil on demand dari HBM.⁵⁷ Strategi menyerupai hierarki cache CPU tradisional, namun dengan software daripada hardware yang membuat keputusan penempatan.
SparseCore terhubung langsung ke channel HBM, mem-bypass jalur memori TensorCore sepenuhnya. Koneksi dedicated mencegah operasi embedding bersaing dengan operasi matrix dense untuk memory bandwidth, memungkinkan keduanya untuk berjalan secara paralel.⁵⁸ Partisi bekerja sangat baik untuk model seperti Deep Learning Recommendation Model (DLRM) yang menyelingi dense neural network layer dengan large embedding lookup.
Strategi mod-sharding mendistribusikan embedding di seluruh SparseCore dengan menghitung target_sc_id = col_id % num_total_sparse_cores.⁵⁹ Fungsi sharding sederhana memastikan load balancing ketika embedding ID didistribusikan secara seragam, namun dapat menciptakan hotspot untuk pola akses skewed. Engineer yang bekerja dengan data dunia nyata sering perlu menganalisis distribusi frekuensi embedding dan secara manual merebalance sharding untuk menghindari bottleneck.
Peningkatan performa dari SparseCore mencapai 5-7× dibandingkan mengimplementasikan operasi identik pada MXU dan VPU, sambil mengkonsumsi hanya 5% chip die area dan power.⁶⁰ Keuntungan efisiensi dramatis berasal dari purpose-building dataflow untuk operasi sparse daripada memaksa mereka melalui infrastruktur matrix dense. Prinsip spesialisasi berlaku secara rekursif dalam arsitektur TPU: sama seperti TPU berspesialisasi di luar desain general-purpose GPU, SparseCore berspesialisasi di luar desain matrix-oriented TPU.
SparseCore generasi ketiga Trillium memperkenalkan lebar SIMD variabel (8 elemen untuk FP32, 16 untuk bfloat16) dan pola akses memori yang diperbaiki, mengurangi bandwidth terbuang dari pembacaan misaligned.⁶¹ Evolusi arsitektural mendemonstrasikan investasi berkelanjutan Google dalam akselerasi embedding karena large language model bertendensi menuju vocabulary yang lebih besar dan pola retrieval-augmented generation yang lebih sophisticated.
## Teknologi Interconnect: Menghubungkan Superkomputer
Arsitektur Inter-Chip Interconnect (ICI)
Inter-Chip Interconnect adalah teknologi kritis yang memungkinkan TPU berfungsi sebagai superkomputer terpadu daripada akselerator yang terisolasi. Berbeda dengan GPU yang berkomunikasi melalui jaringan Ethernet atau InfiniBand, ICI mengimplementasikan tautan serial berkecepatan tinggi khusus yang menghubungkan langsung TPU tetangga dengan latensi skala mikrodetik dan bandwidth terabit per detik.⁶²
Evolusi topologi di seluruh generasi TPU mencerminkan perubahan kebutuhan untuk scaling pod. TPU v2, v3, v5e, dan v6e mengimplementasikan topologi torus 2D di mana setiap chip terhubung ke empat tetangga terdekatnya (utara, selatan, timur, dan barat).⁶³ Tautan melingkar di batas-batas, menciptakan topologi logis berbentuk donat yang menghilangkan chip tepi dengan koneksi lebih sedikit. Grid 16×16 dari 256 TPU dengan demikian memberikan karakteristik bandwidth dan latensi yang seragam terlepas dari dua chip mana yang berkomunikasi.
TPU v4 dan v5p ditingkatkan ke topologi torus 3D dengan setiap chip terhubung ke enam tetangga.⁶⁴ Dimensi tambahan mengurangi diameter jaringan—jumlah hop maksimum antara dua chip mana pun—dari sekitar 2√N ke 3∛N. Untuk pod 4,096 chip, hop maksimum turun dari sekitar 128 ke 48, secara substansial mengurangi latensi komunikasi worst-case untuk operasi sinkronisasi global seperti all-reduce.
Struktur toroidal memberikan keuntungan kritis lainnya: bandwidth bisection yang sama terlepas dari bagaimana workload dipartisi di seluruh chip. Setiap potongan yang membagi torus menjadi dua melintasi jumlah tautan yang sama, mencegah kasus patologis di mana penempatan job yang buruk menciptakan bottleneck jaringan.⁶⁵ Bandwidth bisection yang seragam menyederhanakan penjadwalan dan memungkinkan rekonfigurabilitas optical circuit switch yang dibahas di bawah.
Spesifikasi bandwidth meningkat secara mengesankan di seluruh generasi. TPU v6e menyediakan 13 TB/s bandwidth ICI per chip.⁶⁶ TPU v5p mencapai 4,800 Gbps per chip di seluruh enam tautan torus 3D.⁶⁷ Ironwood mengimplementasikan empat tautan ICI dengan bandwidth bidirectional agregat 9,6 Tbps, diterjemahkan ke 1,2 TB/s per chip.⁶⁸ Sebagai perbandingan, antarmuka jaringan 400GbE tingkat atas menyediakan 50GB/s bandwidth bidirectional—satu orde magnitude lebih rendah dari ICI TPU modern.
Teknologi tautan dalam rak menggunakan kabel direct-attached copper (DAC) untuk jarak pendek antara chip dalam kubus 4×4×4 yang sama.⁶⁹ Koneksi tembaga meminimalkan biaya dan daya sambil menyediakan bandwidth yang diperlukan untuk chip yang terpasang erat yang menjalankan operasi tersinkronisasi. Tautan antar-kubus dan skala pod beralih ke transceiver optik, menukar biaya dan daya yang lebih tinggi untuk jarak dan bandwidth yang diperlukan untuk menjangkau rak datacenter.
Operasi kolektif memanfaatkan properti unik ICI. Operasi all-reduce, all-gather, dan reduce-scatter sering menyinkronkan aktivasi dan gradien di seluruh chip selama training. Pada cluster GPU berbasis Ethernet, kolektif ini melintasi jaringan hierarkis dengan switch, kabel, dan kartu antarmuka jaringan, memperkenalkan latensi di setiap hop. TPU ICI mengimplementasikan algoritma kolektif yang dioptimalkan langsung dalam hardware, menjalankan operasi all-reduce 10× lebih cepat dari implementasi GPU berbasis Ethernet yang setara.⁷⁰
Optical Circuit Switching: Rekonfigurasi Topologi Dinamis
Penerapan optical circuit switching (OCS) Google dengan TPU v4 mewakili salah satu inovasi paling signifikan dalam networking datacenter dalam beberapa dekade. Jaringan packet-switched tradisional—baik Ethernet atau InfiniBand—membentuk koneksi logis dengan merutekan paket hop-by-hop melalui switch yang memeriksa header dan meneruskan ke port output yang sesuai. OCS sebaliknya menggunakan elemen optik yang dapat diprogram untuk menciptakan jalur cahaya fisik langsung antara endpoint, menghilangkan latensi switching sepenuhnya.⁷¹
Teknologi inti mengandalkan cermin MEMS (microelectromechanical systems) yang secara fisik berputar untuk mengarahkan ulang sinar cahaya. Transmitter pada TPU A mengirim cahaya ke dalam OCS. Cermin kecil di dalam OCS berputar untuk memantulkan sinar cahaya tersebut ke receiver pada TPU B. Koneksi menjadi jalur optik langsung dari A ke B dengan pada dasarnya nol latensi tambahan di luar propagasi cahaya melalui serat.⁷²
Kecepatan rekonfigurasi menentukan kepraktisan OCS dalam sistem produksi. Penerapan Google mencapai waktu switching sub-10-nanodetik—lebih cepat dari waktu round-trip protokol jaringan yang khas.⁷³ Kecepatan rekonfigurasi memungkinkan perubahan topologi dinamis yang sesuai dengan kebutuhan workload tanpa mengganggu job yang berjalan atau memerlukan traffic engineering yang dikoordinasikan dengan hati-hati.
TPU v5p mendemonstrasikan OCS pada skala yang masif. Arsitektur menggunakan optical circuit switch yang memberikan empat petabit per detik bandwidth agregat di seluruh switching fabric.⁷⁴ Satu superpod v5p memerlukan 48 unit OCS yang mengelola 13,824 port optik untuk menghubungkan 8,960 chip dalam konfigurasi torus 3D 16×20×28.⁷⁵ Sistem switching mewakili salah satu penerapan optical networking terbesar di lingkungan komputasi mana pun.
OCS menyediakan kemampuan yang tidak mungkin dengan jaringan tradisional. Topologi fisik dan topologi logis sepenuhnya terpisah—dua TPU di sudut berlawanan datacenter tampak sebagai tetangga yang berdekatan jika OCS menciptakan jalur optik langsung. Chip atau tautan yang gagal diarahkan ulang dengan memprogram ulang cermin untuk mengecualikan komponen yang rusak dan mempertahankan struktur torus logis. Job baru menerima "slice" berukuran apa pun dengan memprogram OCS untuk menciptakan konfigurasi pod yang sesuai tanpa secara fisik memasang ulang kabel rak.⁷⁶
Arsitektur terintegrasi dengan jaringan data center Jupiter Google untuk menskalakan melampaui satu pod. Jupiter memberikan bandwidth bisection multi-petabit-per-detik di seluruh datacenter menggunakan switch silikon khusus Google dan control plane.⁷⁷ Beberapa superpod TPU terhubung melalui fabric Jupiter, secara teoretis mendukung cluster hingga 400,000 akselerator jika kapasitas jaringan memungkinkan.⁷⁸
Karakteristik konsumsi daya dan keandalan mendukung optical circuit switching untuk penerapan skala TPU. Switch paket tradisional mengonsumsi daya yang substansial untuk memproses dan meneruskan paket pada tingkat terabit-per-detik. Switch OCS mengonsumsi daya hanya untuk mengoperasikan cermin MEMS selama peristiwa rekonfigurasi, kemudian diam, melewatkan cahaya dengan kehilangan minimal sementara koneksi tetap stabil.⁷⁹ Kesederhanaan arsitektur meningkatkan keandalan dengan menghilangkan pemrosesan paket yang kompleks dan logika buffering yang rentan terhadap bug dan anomali kinerja.
Arsitektur Pod dan Karakteristik Scaling
Pod TPU mewakili unit tunggal terbesar TPU yang terhubung melalui ICI, membentuk akselerator terpadu. Struktur fisik dibangun secara hierarkis dari chip individual ke tray ke kubus ke rak ke pod lengkap.⁸⁰ Memahami hierarki penting untuk bernalar tentang kapasitas memori, bandwidth komunikasi, dan toleransi kesalahan pada skala yang berbeda.
Blok bangunan fundamental terdiri dari empat chip pada satu tray yang terhubung ke CPU host melalui PCIe.⁸¹ Koneksi PCIe menangani operasi control plane, pemuatan program awal, dan infeed/outfeed untuk data training dan hasil inferensi. Komunikasi inter-chip aktual untuk distributed training mengalir melalui ICI daripada PCIe, menghindari bottleneck bandwidth PCIe.
Enam belas tray (64 chip) membentuk satu kubus 4×4×4—unit dasar untuk konstruksi pod. Dalam kubus, semua koneksi ICI menggunakan kabel tembaga direct-attached karena chip berada di rak yang sama dengan jarak fisik yang pendek.⁸² Kubus mengimplementasikan torus 3D lengkap dengan koneksi wrap-around, menciptakan unit 64-chip yang mandiri yang secara teoretis dapat beroperasi secara independen.
Pod TPU v4 menskalakan ke 64 kubus dengan total 4,096 chip.⁸³ Koneksi antar-kubus beralih ke tautan optik yang dikelola oleh fabric optical circuit switching. OCS dapat menyediakan 4,096 chip ini sebagai satu pod yang sangat besar, beberapa pod independen yang lebih kecil, atau secara dinamis merekonfigurasi mid-job jika diperlukan. Fleksibilitas memungkinkan operator datacenter menyeimbangkan utilitas di berbagai ukuran dan prioritas job.
TPU v5p mendorong skala pod ke 8,960 chip dalam torus 3D 16×20×28.⁸⁴ Dimensi spesifik mencerminkan optimasi bandwidth dan diameter yang hati-hati—faktorisasi prima penting untuk topologi jaringan! Pod memberikan 4,45 exaflops komputasi dan mewakili salah satu konfigurasi pod tunggal terbesar yang diterapkan dalam produksi.
Ironwood mendukung baik pod 256-chip untuk penerapan yang lebih kecil dan superpod 9,216-chip untuk training model frontier yang masif.⁸⁵ Konfigurasi 9,216-chip memberikan 42,5 FP8 exaflops—lebih banyak komputasi dari seluruh daftar Top500 superkomputer yang terkandung hanya lima tahun sebelumnya.⁸⁶ Skala ini mendefinisikan ulang apa yang dapat dicapai organisasi dengan training sinkron daripada pendekatan pipelined atau asinkron.
Efisiensi scaling menentukan apakah pod yang lebih besar benar-benar membantu. Overhead komunikasi meningkat dengan ukuran pod karena chip menghabiskan lebih banyak waktu untuk sinkronisasi daripada komputasi. Google Research menerbitkan hasil yang mendemonstrasikan 95% efisiensi scaling pada 32,768 TPU untuk workload spesifik, yang berarti 32,768 TPU memberikan 95% kinerja yang diprediksi scaling linear sempurna.⁸⁷ Efisiensi berasal dari kolektif yang dipercepat hardware, transformasi compiler yang dioptimalkan, dan pendekatan algoritmik yang cerdas untuk mengurangi frekuensi sinkronisasi gradien.
Toleransi kesalahan pada skala pod memerlukan penanganan yang canggih. Probabilitas statistik menjamin kegagalan komponen dalam sistem apa pun dengan ribuan chip yang berjalan terus-menerus. Optical circuit switch memungkinkan degradasi yang anggun dengan merekonfigurasi di sekitar komponen yang gagal. Checkpointing training terjadi pada interval reguler (biasanya setiap beberapa menit), sehingga kegagalan job memerlukan restart hanya dari checkpoint terakhir daripada dari awal.⁸⁸
Stack Software: Compiler, Framework, dan Model Pemrograman
Compiler XLA: Mengoptimalkan Computation Graph
XLA (Accelerated Linear Algebra) membentuk fondasi dari software stack TPU, mengkompilasi operasi framework tingkat tinggi menjadi machine code yang dioptimalkan untuk eksekusi di TPU.⁸⁹ Compiler ini mengimplementasikan optimasi agresif yang tidak mungkin dilakukan di compiler general-purpose karena memanfaatkan domain knowledge tentang machine learning workload dan karakteristik arsitektur TPU.
Fusion merepresentasikan optimasi XLA yang paling berdampak. Compiler menganalisis computation graph untuk mengidentifikasi urutan operasi yang dapat dieksekusi tanpa materialisasi tensor intermediate. Contoh sederhana: operasi element-wise seperti relu(batch_norm(conv(x))) normalnya memerlukan penulisan output konvolusi ke memory, membacanya untuk batch normalization, menulis hasil tersebut ke memory, dan membaca lagi untuk ReLU. XLA menyatukan operasi-operasi ini menjadi satu kernel yang menghasilkan output ReLU final tanpa traffic memory intermediate.⁹⁰
Dampak fusion meningkat seiring dengan arsitektur TPU. Memory bandwidth membatasi banyak workload lebih dari compute throughput—MXU dapat melakukan matrix multiplication lebih cepat daripada sistem memory dapat memberinya data. Menghilangkan intermediate memory write dan read melalui fusion langsung berubah menjadi peningkatan performa, sering memberikan speedup 2× atau lebih untuk network yang heavy activation-function.⁹¹
Memory layout transformation mengoptimalkan penyimpanan tensor untuk persyaratan hardware. Neural network sering merepresentasikan tensor dalam format NHWC (batch, height, width, channels) untuk indexing yang intuitif, namun TPU MXU bekerja paling baik dengan layout yang sejajar dengan tile 128×8.⁹² XLA secara otomatis mentranspose, reshape, dan padding tensor untuk mencocokkan preferensi hardware, menyisipkan layout transformation hanya jika perlu dan terkadang mempropagasi preferred layout mundur melalui graph untuk meminimalkan total transformation overhead.
Compiler mengimplementasikan sophisticated constant folding dan dead code elimination. ML graph sering berisi subgraph yang outputnya hanya bergantung pada konstanta—parameter batch normalization, inference dropout rate, dan perhitungan shape yang dapat dieksekusi sekali daripada per batch. XLA mengevaluasi subgraph ini pada compile time dan menggantinya dengan constant tensor, mengurangi runtime work.⁹³
Cross-replica optimization memanfaatkan pengetahuan tentang eksekusi terdistribusi. Ketika melakukan training di beberapa TPU core, operasi tertentu (seperti statistik batch normalization) memerlukan agregasi di semua replica. XLA mengidentifikasi pola ini dan menghasilkan collective operation yang dioptimalkan yang memanfaatkan all-reduce hardware-accelerated ICI daripada mengimplementasikan agregasi melalui explicit message passing.⁹⁴
Compiler menargetkan intermediate representation, Mosaic, khusus untuk TPU. Mosaic beroperasi pada tingkat abstraksi yang lebih tinggi dari assembly language tapi lebih rendah dari input computation graph. Bahasa ini mengekspos fitur arsitektur TPU, seperti systolic array, vector memory, dan VMEM staging, sambil menyembunyikan detail tingkat rendah, seperti instruction scheduling dan register allocation.⁹⁵
Kemampuan auto-tuning memilih tile size dan parameter operasi optimal melalui empirical search. Sistem XLA Auto-Tuning (XTAT) mencoba berbagai fusion strategy, memory layout, dan tile dimension, memprofil performa setiap varian, dan memilih konfigurasi tercepat.⁹⁶ Search dapat memerlukan compile time yang substansial untuk model kompleks, namun menghasilkan speedup runtime yang dramatis dengan menemukan optimasi counter-intuitive yang jarang diidentifikasi manusia secara manual.
JAX: Composable Transformation dan SPMD
JAX menyediakan interface NumPy-compatible untuk numerical computation dengan automatic differentiation, JIT compilation ke XLA, dan first-class support untuk program transformation.⁹⁷ Paradigma functional programming framework dan model composable transformation selaras secara natural dengan model eksekusi TPU dan pola distributed parallelism.
Abstraksi JAX inti menerapkan mathematical transformation pada function. Grad (f) menghitung gradient f. Jit (f) JIT-compile f ke XLA. vmap(f) memvektorisasi f pada dimensi baru. Yang kritis, transformation dapat dikomposisi: jit(grad(vmap(f))) bekerja persis seperti yang diharapkan, mengkompilasi vectorized gradient function.⁹⁸ Model komposisional memungkinkan membangun distributed training loop kompleks dari komponen sederhana dan dapat ditest.
SPMD (Single Program, Multiple Data) merepresentasikan model eksekusi terdistribusi JAX. Programmer menulis code seolah-olah menargetkan single device, kemudian menambahkan sharding annotation yang menunjukkan bagaimana mempartisi tensor di beberapa TPU core. XLA compiler dan subsistem GSPMD (General SPMD) secara otomatis menyisipkan communication operation untuk mempertahankan semantik program sambil mengeksekusi di distributed device.⁹⁹
Sharding annotation menggunakan PartitionSpec untuk mendeklarasikan distribution strategy. PartitionSpec('batch', None) menshard dimensi pertama tensor di 'batch' axis dari device mesh sambil mereplikasi dimensi kedua. PartitionSpec(None, 'model') mengimplementasikan tensor parallelism dengan mempartisi dimensi kedua. Annotation dapat dikomposisi dengan tensor rank dan device mesh dimension yang arbitrary.¹⁰⁰
Automatic parallelization GSPMD menghilangkan sejumlah besar boilerplate code. Distributed training tradisional memerlukan menyisipkan secara manual all-gather sebelum operasi yang memerlukan tensor penuh, reduce-scatter setelah menghitung distributed gradient, dan all-reduce untuk global reduction. GSPMD menganalisis sharding specification dan secara otomatis menyisipkan collective yang sesuai, membebaskan programmer untuk fokus pada algoritma daripada communication engineering.¹⁰¹
Compiler mempropagasi keputusan sharding melalui computation graph menggunakan constraint solving. Jika operasi A mengoutput sharded tensor yang dikonsumsi oleh operasi B, GSPMD menyimpulkan optimal sharding B berdasarkan bagaimana output digunakan, berpotensi menyisipkan resharding operation hanya di mana secara matematis diperlukan.¹⁰² Automated inference mencegah "sharding spaghetti" yang mengganggu hand-written distributed code.
JAX menyediakan fine-grained control ketika automation kurang memadai. with_sharding_constraint memaksa sharding spesifik pada lokasi graph, mengganti automatic inference. Custom annotation PJIT (parallel JIT) menentukan exact device placement dan sharding strategy untuk performance-critical code path. Model berlapis memungkinkan rapid prototyping dengan automatic sharding sambil mendukung expert optimization di mana diperlukan.¹⁰³
Shardy muncul sebagai penerus GSPMD pada 2025, mengimplementasikan algoritma constraint propagation yang diperbaiki dan penanganan dynamic shape yang lebih baik.¹⁰⁴ Sistem baru mengekspos peluang optimasi tambahan dengan mempertimbangkan sharding choice secara bersama di region graph yang lebih besar daripada operation-by-operation.
PyTorch/XLA: Membawa PyTorch ke TPU
PyTorch/XLA memungkinkan menjalankan model PyTorch di TPU dengan perubahan code minimal, menjembatani kesenjangan antara model pemrograman imperative PyTorch dan kompilasi graph-based XLA.¹⁰⁵ Integrasi menyeimbangkan mempertahankan developer experience PyTorch dengan mengekspos optimasi khusus TPU.
Tantangan fundamental berasal dari filosofi eager execution PyTorch. PyTorch mengeksekusi operasi segera saat statement Python dieksekusi, memungkinkan debugging dengan tool standar dan control flow natural. XLA memerlukan capture computation graph lengkap sebelum kompilasi, menciptakan ketegangan antara eager execution dan manfaat performa graph compilation.¹⁰⁶
PyTorch/XLA 2.4 memperkenalkan dukungan eager mode, mengatasi impedance mismatch. Implementasi secara dinamis trace operasi PyTorch menjadi XLA graph, memungkinkan developer menulis code PyTorch standar sambil tetap mendapat manfaat dari XLA compilation.¹⁰⁷ Mode ini menukar beberapa peluang optimasi kompilasi untuk velocity development dan simplicity debugging.
Graph mode tetap menjadi path utama untuk deployment produksi. Developer secara eksplisit menandai function untuk kompilasi XLA menggunakan decorator atau compilation API. Annotation eksplisit memungkinkan optimasi agresif namun memerlukan pemahaman operasi mana yang harus difuse menjadi single XLA graph versus dieksekusi secara independen.¹⁰⁸
Integrasi Pallas membawa pengembangan custom kernel ke PyTorch/XLA. Pallas menyediakan bahasa tingkat rendah untuk menulis TPU kernel ketika automatic fusion XLA kurang memadai atau operasi khusus memerlukan hand-optimization.¹⁰⁹ Bahasa ini mengekspos hierarki memory TPU (VMEM, CMEM, HBM) dan compute unit (MXU, VPU) sambil tetap higher-level daripada raw assembly.
Built-in Pallas kernel mengimplementasikan operasi performance-critical seperti FlashAttention dan PagedAttention. Tiled attention computation FlashAttention mengurangi memory bandwidth requirement dari O(n²) menjadi O(n) untuk sequence length n, memungkinkan model memproses sequence yang jauh lebih panjang dalam budget memory tetap.¹¹⁰ PagedAttention mengoptimalkan key-value cache management untuk serving, mencapai speedup 5× dibanding implementasi padded.¹¹¹
Bridge PyTorch/XLA terbukti kritis untuk vLLM TPU—framework serving high-performance yang dirancang awalnya untuk GPU. Implementasi sebenarnya menggunakan JAX sebagai intermediate lowering path bahkan untuk model PyTorch, memanfaatkan dukungan parallelism superior JAX sambil mempertahankan kompatibilitas frontend PyTorch.¹¹² Arsitektur mencapai peningkatan performa 2-5× sepanjang 2025 dibanding prototype awal.
Tantangan kompatibilitas model tetap ada meski ada perbaikan. Beberapa operasi PyTorch tidak memiliki equivalent XLA, memaksa fallback ke eksekusi CPU yang menurunkan performa. Dynamic control flow didukung dengan buruk oleh graph compilation, sering memerlukan perubahan arsitektural untuk mengganti behavior dinamis dengan alternatif statis yang dapat dikompilasi. Repository PyTorch/XLA mendokumentasikan kompatibilitas dan menyediakan migration guide untuk pola bermasalah yang umum.¹¹³
Format Precision: BFloat16, FP8, dan Quantization
Dukungan TPU untuk arithmetic reduced-precision memungkinkan peningkatan performa dan memory yang dramatis sambil mempertahankan kualitas model yang dapat diterima. Memahami properti numerical dari format berbeda dan kapan menerapkan masing-masing terbukti kritis untuk mencapai performa optimal.¹¹⁴
BFloat16 merepresentasikan taruhan awal Google pada reduced-precision training, pertama muncul di TPU v2. Format mempertahankan exponent 8-bit FP32 sambil memotong mantissa menjadi 7 bit (plus sign bit).¹¹⁵ Range exponent penuh mencegah underflow dan overflow yang mengganggu training FP16 awal, di mana gradient sering lolos dari range representable FP16.
Mantissa yang dikurangi memperkenalkan quantization error namun jarang berdampak pada kualitas model final. Engineer mengamati bahwa model yang dilatih dalam bfloat16 biasanya mencocokkan baseline yang dilatih FP32 dalam statistical noise, kemungkinan karena quantization bertindak sebagai bentuk regularization, mencegah overfitting pada detail numerical kecil.¹¹⁶ Format mengurangi setengah memory bandwidth dan capacity requirement dibanding FP32, langsung berubah menjadi performance gain pada memory-bound workload.
FP8 mengambil reduced precision lebih jauh, mengompresi weight dan activation menjadi 8 bit. Dua standard encoding ada: E4M3 (4-bit exponent, 3-bit mantissa) memprioritaskan precision untuk forward pass, sedangkan E5M2 (5-bit exponent, 2-bit mantissa) memprioritaskan range untuk backward pass di mana magnitude gradient sangat bervariasi.¹¹⁷ Ironwood mengimplementasikan dukungan FP8 native untuk kedua format, sedangkan TPU sebelumnya mengemulasi FP8 melalui software transformation.¹¹⁸
Quantization awareness selama training memungkinkan kesuksesan numerical FP8. Model yang dilatih dari nol dengan FP8 atau fine-tune dengan teknik FP8-aware mempelajari distribusi weight yang mentoleransi precision terbatas format. Post-training quantization (mengkonversi model FP32 ke FP8 setelah training) sering menurunkan kualitas tanpa kalibrasi yang hati-hati.¹¹⁹
Quantization INT8 memberikan memory saving dan inference speedup yang lebih besar. Accurate Quantized Training (AQT) Google memungkinkan training INT8 di TPU dengan quality loss minimal dibanding baseline bfloat16.¹²⁰ Teknik menerapkan quantization-aware training dari nol, memungkinkan model beradaptasi dengan constraint INT8 selama pembelajaran daripada melalui post-training approximation.
Mixed-precision strategy menggabungkan format secara strategis. Forward pass mungkin menggunakan FP8 untuk activation dan weight, backward pass menggunakan FP8 E5M2 atau bfloat16 untuk gradient, dan optimizer state tetap dalam FP32 untuk numerical stability selama weight update.¹²¹ Pendekatan mixed menyeimbangkan speed, memory, dan accuracy, sering mencapai 90%+ dari kualitas FP32 sambil berjalan 4× lebih cepat.
Tradeoff precision meluas melampaui speed dan memory untuk mencakup pertimbangan numerical stability. Batch normalization, layer normalization, dan softmax memerlukan numerical handling yang hati-hati dalam reduced precision. Exponential besar dalam softmax dapat overflow range FP8 atau bfloat16; mengurangkan maximum logit sebelum exponentiation mencegah overflow sambil mempertahankan equivalence matematis.¹²² XLA compiler mengimplementasikan transformation ini secara otomatis ketika aman, namun operasi custom terkadang memerlukan numerical engineering manual.
Model Pemrograman dan Strategi Paralelisme
SPMD dan Partisi Otomatis
Paradigma Single Program, Multiple Data (SPMD) secara fundamental membentuk cara programmer berpikir tentang eksekusi TPU. Daripada menulis kode message-passing eksplisit untuk mengkoordinasi beberapa proses, developer menulis program tunggal dan memberikan anotasi bagaimana data harus dipartisi di seluruh perangkat.¹²³ Compiler menangani detail mekanis distribusi, komunikasi, dan sinkronisasi.
GSPMD (General SPMD) mengimplementasikan logika partisi otomatis di XLA. Sistem menganalisis anotasi tensor sharding dan struktur computation graph untuk menentukan di mana operasi dieksekusi pada perangkat mana dan komunikasi apa yang diperlukan untuk mempertahankan semantik yang benar.¹²⁴ Otomatisasi ini mengeliminasi seluruh kelas bug yang umum terjadi dalam kode distributed yang ditulis manual—ketidakcocokan bentuk tensor, urutan operasi kolektif yang salah, dan deadlock dari sinkronisasi yang tidak tepat.
Mesin constraint propagation compiler menyimpulkan keputusan sharding dari anotasi minimal. Memberikan anotasi hanya pada input dan output sharding model seringkali sudah cukup; GSPMD mempropagasi constraint melalui operasi intermediate dan secara otomatis memilih distribusi yang efisien.¹²⁵ Ketika beberapa sharding valid ada untuk suatu operasi, compiler memperkirakan biaya komunikasi dari alternatif-alternatif tersebut dan memilih opsi dengan biaya terendah.
Optimisasi lanjutan menumpang-tindihkan komunikasi dengan komputasi. Operasi all-reduce yang menyinkronisasi gradient di seluruh replika dapat dimulai segera setelah gradient layer pertama selesai, dieksekusi secara paralel dengan backward pass untuk layer berikutnya.¹²⁶ Compiler secara otomatis menjadwalkan kolektif untuk memaksimalkan tumpang-tindih, mengurangi waktu komunikasi hingga 2× atau lebih dibandingkan eksekusi sekuensial.
Rematerialization menukar komputasi dengan memori. Daripada menyimpan semua aktivasi forward pass untuk komputasi gradient, compiler secara selektif menghitung ulang aktivasi selama backward pass ketika tekanan memori melampaui threshold.¹²⁷ Trade-off ini bekerja sangat baik pada TPU di mana komputasi seringkali mengungguli bandwidth memori, membuat rekomputasi lebih murah daripada traffic memori.
Data Parallelism, Tensor Parallelism, dan Pipeline Parallelism
Data parallelism merepresentasikan strategi distributed training yang paling mudah: replikasi model lengkap di seluruh N perangkat dan memproses batch data yang berbeda pada setiap replika. Setelah menghitung gradient secara lokal, all-reduce mengagregasi gradient di seluruh replika, dan semua perangkat menerapkan update weight yang identik.¹²⁸ Pendekatan ini berskala secara linier hingga waktu komunikasi mendominasi waktu komputasi—biasanya sekitar 1.000 GPU dengan networking Ethernet tetapi 10.000+ TPU dengan ICI.¹²⁹
Tensor parallelism (juga disebut model parallelism) mempartisi operasi individual di seluruh perangkat. Perkalian matriks Y = W @ X membagi weight matrix W di seluruh perangkat, dengan masing-masing menghitung sebagian dari output.¹³⁰ Strategi ini memungkinkan training model yang melebihi memori perangkat tunggal dengan mendistribusikan penyimpanan parameter dan komputasi.
Pola komunikasi untuk tensor parallelism berbeda signifikan dari data parallelism. Daripada all-reduce setelah setiap layer, tensor parallelism memerlukan all-gather sebelum operasi yang memerlukan tensor penuh dan reduce-scatter setelah komputasi terdistribusi.¹³¹ Volume komunikasi berskala dengan ukuran aktivasi model daripada ukuran parameter, menciptakan bottleneck yang berbeda dari data parallelism.
Pipeline parallelism mempartisi layer model sekuensial di seluruh perangkat, memproses micro-batch yang berbeda pada stage yang berbeda secara bersamaan. GPipe memperkenalkan strategi ini dengan penjadwalan yang cermat untuk memaksimalkan utilisasi pipeline sambil membatasi penggunaan memori.¹³² Setiap perangkat memproses forward pass satu micro-batch, mengirim aktivasi ke stage berikutnya, kemudian memproses micro-batch selanjutnya—menciptakan pipeline di mana semua perangkat bekerja secara kontinu setelah ramp-up awal.
Gradient staleness memperumit pipeline parallelism. Perangkat memperbarui weight menggunakan gradient yang dihitung dari aktivasi yang berpotensi puluhan micro-batch lama, menciptakan staleness yang dapat merusak konvergensi.¹³³ Algoritma penjadwalan canggih seperti PipeDream meminimalkan staleness sambil mempertahankan throughput tinggi, dan hasil empiris menunjukkan bahwa sebagian besar model mentolerir staleness moderat tanpa degradasi kualitas.
3D parallelism menggabungkan ketiga strategi. Data parallelism mendistribusi di seluruh dimensi "data", tensor parallelism di seluruh dimensi "model", dan pipeline parallelism di seluruh dimensi "pipeline".¹³⁴ Menyeimbangkan dimensi dengan cermat berdasarkan arsitektur model, topologi hardware, dan biaya komunikasi memaksimalkan throughput. Model skala GPT-3 umumnya menggunakan 3D parallelism dengan data parallelism di seluruh 8-16 replika, tensor parallelism di seluruh 4-8 GPU, dan pipeline parallelism di seluruh 4-16 stage.
Strategi Sharding dan Optimisasi
Memilih strategi sharding memerlukan pemahaman operasi matematika dan dependensi data mereka. Perkalian matriks C = A @ B memungkinkan beberapa sharding valid: replikasi A dan B dan hitung hasil parsial (komunikasi sebelum komputasi), shard B column-wise dan gather hasil (komunikasi setelah komputasi), atau shard A row-wise dan B column-wise tanpa komunikasi tetapi matriks per-perangkat yang lebih kecil.¹³⁵
Biaya operasi kolektif menentukan strategi optimal. Biaya all-reduce berskala secara linier dengan ukuran tensor tetapi sublinier dengan jumlah perangkat menggunakan algoritma reduksi berbasis tree atau ring:¹³⁶ All-gather dan reduce-scatter menunjukkan properti penskalaan yang berbeda. Compiler memodelkan biaya ini dan memilih strategi sharding yang meminimalkan total waktu komunikasi.
Sequence parallelism muncul sebagai hal yang kritis untuk large language model. Mekanisme attention menciptakan bottleneck memori karena key-value cache tumbuh dengan panjang sequence dan ukuran batch. Partisi sepanjang dimensi sequence mendistribusikan beban memori di seluruh perangkat sambil memperkenalkan komunikasi hanya untuk komputasi attention itu sendiri.¹³⁷
Expert parallelism menangani model Mixture-of-Experts (MoE) di mana expert yang berbeda memproses token yang berbeda. Strategi sharding mereplikasi layer bersama di seluruh semua perangkat tetapi mempartisi expert, merutekan setiap token ke perangkat expert yang ditentukan.¹³⁸ Routing dinamis menciptakan pola komunikasi tidak teratur yang menantang operasi kolektif tradisional, memerlukan sistem runtime yang canggih untuk meminimalkan latensi dan ketidakseimbangan beban.
Optimizer state sharding mengurangi overhead memori untuk model besar. Optimizer seperti Adam menyimpan statistik momentum dan varians untuk setiap parameter, yang melipattigakan kebutuhan memori di luar yang diperlukan untuk parameter saja. Sharding state optimizer di seluruh perangkat sambil menjaga parameter tetap tereplikasi memungkinkan training model yang lebih besar dalam anggaran memori tetap.¹³⁹ Strategi ini memerlukan gathering update optimizer state selama komputasi weight tetapi secara substansial mengurangi jejak memori per-perangkat.
Analisis Performa dan Benchmarking
Hasil MLPerf dan Posisi Kompetitif
MLPerf menyediakan benchmark standar industri yang mengukur performa akselerator AI pada workload training dan inference. Google secara rutin mengirimkan hasil TPU yang menunjukkan performa kompetitif, dan evolusi lintas generasi menampilkan peningkatan arsitektur yang jelas.¹⁴⁰
TPU v5e mencapai hasil terdepan dalam 8 dari 9 kategori training MLPerf.¹⁴¹ Cakupan yang luas ini menunjukkan versatilitas arsitektur di luar model bahasa besar—performa kompetitif di seluruh computer vision, sistem rekomendasi, dan workload scientific computing. Training BERT selesai 2,8× lebih cepat dibandingkan GPU NVIDIA A100, memvalidasi arsitektur yang dioptimalkan untuk transformer.¹⁴²
MLPerf Training v5.0, yang diumumkan pada Juni 2025, memperkenalkan benchmark Llama 3.1 405B yang mewakili model terbesar dalam suite tersebut.¹⁴³ Benchmark ini menekan scaling multi-node, overhead komunikasi, dan kapasitas memori lebih dari test sebelumnya. Google Cloud berpartisipasi dengan submission TPU, meskipun perbandingan performa detail masih dibatasi menunggu publikasi hasil resmi.
MLPerf Inference v5.0 mencakup empat benchmark baru: Llama 3.1 405B, Llama 2 70B untuk aplikasi latensi rendah, RGAT graph neural networks, dan PointPainting untuk deteksi objek 3D.¹⁴⁴ Keragaman ini mendorong akselerator di luar workload transformer konvensional ke domain aplikasi emerging dimana asumsi arsitektur mungkin berbeda.
Benchmark inference secara khusus mendukung kekuatan arsitektur TPU. Workload batch inference memanfaatkan paralelisme masif MXU, mencapai throughput 4× lebih tinggi dibandingkan akselerator kompetitif untuk serving transformer.¹⁴⁵ Latensi single-query diuntungkan dari eksekusi deterministik TPU dan tidak adanya thermal throttling, memberikan latensi konsisten tanpa variance performa yang mengganggu beberapa deployment GPU.
Metrik efisiensi energi menunjukkan keunggulan TPU yang mengembang lintas generasi. TPU v4 mendemonstrasikan 2,7× performa per watt yang lebih baik dibandingkan TPU v3, dan Trillium meningkat 67% dari v5e.¹⁴⁶ Ironwood mengklaim 2× performa per watt yang lebih baik dibandingkan Trillium meskipun performa absolut yang secara signifikan lebih tinggi.¹⁴⁷ Peningkatan efisiensi ini menguat pada pod ribuan chip, diterjemahkan ke jutaan dolar biaya operasional datacenter.
Performa Training dan Inference Dunia Nyata
Workload produksi mengungkap karakteristik performa yang tidak ada pada benchmark sintetis. Google mempublikasikan hasil dari layanan internal yang mendemonstrasikan perilaku TPU di bawah pola penggunaan real dan persyaratan scaling.¹⁴⁸
Training ResNet-50 ImageNet selesai dalam 28 menit pada pod TPU, benchmark yang banyak dikutip untuk performa workload computer vision.¹⁴⁹ Metrik time-to-accuracy menangkap proses training lengkap, termasuk loading data, augmentasi, sinkronisasi gradient terdistribusi, dan penyimpanan checkpoint—bukan hanya FLOP teoritis.
Training model bahasa T5-3B mendemonstrasikan keunggulan TPU pada arsitektur transformer. Model 3-miliar-parameter ini training dalam 12 jam pada pod TPU, dibandingkan dengan 31 jam pada konfigurasi GPU yang setara.¹⁵⁰ Speedup 2,6× berasal dari operasi attention yang dipercepat hardware, utilisasi bandwidth memori yang efisien, dan komunikasi kolektif yang dioptimalkan.
Workload skala GPT-3 (175B parameter) mencapai 1,7× time-to-accuracy yang lebih cepat pada TPU dibandingkan pada GPU kontemporer.¹⁵¹ Gap performa melebar untuk model yang bahkan lebih besar, dimana kapasitas memori dan bandwidth menjadi constraint kritis. HBM3e 192GB Ironwood memungkinkan serving model yang memerlukan tensor parallelism kompleks pada alternatif memori yang lebih rendah.
Pengukuran efisiensi scaling mendemonstrasikan speedup hampir linear hingga skala yang enorm. Google Research melaporkan 95% efisiensi scaling pada 32.768 TPU untuk workload training transformer spesifik.¹⁵² Metrik ini berarti 32.768 TPU memberikan 95% dari performa yang diprediksi scaling linear sempurna—luar biasa mengingat overhead komunikasi meningkat dengan skala.
Metrik utilisasi FLOPS mengungkap seberapa efektif workload memanfaatkan compute yang tersedia. Model transformer biasanya mencapai 90% utilisasi FLOPS pada TPU, berarti 90% dari performa puncak teoritis diterjemahkan ke pekerjaan aktual.¹⁵³ Utilisasi tinggi berasal dari fusion operasi yang menghilangkan bottleneck memori, efisiensi systolic-array dalam perkalian large-matrix, dan optimisasi compiler yang meminimalkan cycle yang terbuang.
Layanan inference produksi mendemonstrasikan performa berkelanjutan di seluruh miliaran query per hari. Google Translate memproses 1 miliar request harian pada TPU.¹⁵⁴ Rekomendasi YouTube melayani 2 miliar pengguna menggunakan model yang dipercepat TPU.¹⁵⁵ Google Photos menganalisis 28 miliar gambar bulanan untuk fitur pencarian dan organisasi.¹⁵⁶ Skala operasional memvalidasi reliabilitas dan cost-efficiency di luar deployment prototipe penelitian.
Efisiensi Energi dan Total Cost of Ownership
Konsumsi daya secara langsung berdampak pada biaya operasional data center dan sustainability lingkungan. Peningkatan efisiensi energi TPU lintas generasi mengurangi baik biaya operasional maupun emisi karbon pada skala.¹⁵⁷
TPU v4 rata-rata hanya konsumsi daya 200W dalam workload produksi meskipun spesifikasi TDP 250W.¹⁵⁸ Headroom antara daya rata-rata dan puncak memungkinkan desain termal yang fleksibel dan provisioning. Kontras dengan GPU, dimana workload berkelanjutan sering mencapai batas TDP, memerlukan budget daya rack yang konservatif.
TDP 600W Ironwood mewakili daya absolut yang lebih tinggi dibandingkan generasi sebelumnya tetapi memberikan compute per watt yang secara dramatis lebih banyak.¹⁵⁹ Performa FP8 4,6 PFLOPS per chip menghasilkan sekitar 7,7 TFLOPS per watt—kompetitif dengan atau melebihi efisiensi GPU kontemporer pada workload setara.
Power usage effectiveness (PUE) datacenter memperkuat efisiensi tingkat chip. Datacenter TPU Google mencapai PUE 1,1, berarti hanya 10% overhead daya di luar konsumsi chip untuk pendinginan, konversi daya, dan networking.¹⁶⁰ Rata-rata industri PUE berkisar dari 1,5 hingga 2,0, dimana 50-100% daya tambahan pergi ke overhead infrastruktur. PUE rendah berasal dari sistem pendinginan canggih, power delivery efisien, dan desain datacenter deliberat yang mengoptimalkan untuk workload ML.
Pertimbangan intensitas karbon meluas di luar daya untuk mencakup sumber energi. Google mengoperasikan datacenter TPU pada daya karbon-netral melalui procurement energi terbarukan dan program offset karbon.¹⁶¹ Akuntansi karbon semakin penting untuk organisasi yang melacak emisi Scope 2 dari cloud computing.
Analisis total cost of ownership (TCO) harus memperhitungkan biaya akuisisi, konsumsi daya, persyaratan pendinginan, dan biaya maintenance. Deployment TPU umumnya menunjukkan pengurangan TCO 20-30% dibandingkan instalasi GPU setara, didorong terutama oleh performa per watt yang superior dan kompleksitas pendinginan yang berkurang.¹⁶²
Biaya infrastruktur pendinginan skala non-linear dengan kepadatan daya. Rack berpendingin udara biasanya mencapai puncak 15-20kW per rack sebelum memerlukan solusi pendinginan eksotis. GPU berdaya tinggi mendorong batas ini, kadang memerlukan infrastruktur liquid cooling dengan biaya kapital dan operasional yang substansial lebih tinggi. Efisiensi TPU menjaga lebih banyak deployment dalam rentang air-cooling, menyederhanakan desain datacenter.¹⁶³
Keunggulan Teknis: Di Mana TPU Unggul
Operasi Kolektif yang Dipercepat Hardware
Dukungan operasi kolektif khusus dalam TPU ICI memberikan salah satu keunggulan paling signifikan dibandingkan akselerator berjaringan tradisional. All-reduce, operasi andalan untuk menyinkronkan gradien di seluruh training terdistribusi, dieksekusi 10× lebih cepat pada TPU ICI dibandingkan implementasi GPU berbasis Ethernet yang setara.¹⁶⁴
Kesenjangan performa berasal dari integrasi arsitektur. Kolektif berbasis Ethernet melewati beberapa lapisan: kode aplikasi memanggil pustaka kolektif (NCCL, Horovod, dll.), yang menghasilkan paket yang diserahkan ke network stack, yang mentransfer data ke NIC, yang melakukan serialisasi ke kabel, melewati switch, deserializing di NIC penerima, dan membalikkan prosesnya. Setiap lapisan menambah latensi, menyalin data melalui hierarki memori, dan mengonsumsi siklus CPU untuk pemrosesan protokol.¹⁶⁵
TPU ICI mengimplementasikan kolektif dalam hardware tanpa melewati lapisan software. Operasi dimulai langsung dari TensorCore, streaming data melalui link ICI khusus, dan selesai tanpa melibatkan host CPU. Jalur hardware langsung menghilangkan overhead yang mendominasi implementasi tradisional.¹⁶⁶
Topologi optical circuit-switch memungkinkan algoritma kolektif optimal. All-reduce berbasis ring hanya memerlukan 2(N-1) pesan untuk N device, dan topologi torus menyediakan routing jalur terpendek, meminimalkan latensi.¹⁶⁷ Bandwidth bisection yang seragam mencegah hotspot di mana kolektif yang di-route dengan buruk menyebabkan kemacetan link jaringan.
Ruang Memori Terpadu dan Pemrograman yang Disederhanakan
Model memori terpadu TPU menyederhanakan pemrograman dibandingkan hierarki memori kompleks GPU. Programmer berpikir tentang satu pool HBM daripada mengelola transfer antara host RAM, GPU global memory, shared memory, dan register file. Model yang disederhanakan mengurangi bug dan memungkinkan kecepatan pengembangan yang lebih tinggi.¹⁶⁸
Fragmentasi memori hilang sebagai kekhawatiran. GPU mengalokasikan memori dari heap yang terfragmentasi, di mana alokasi dan dealokasi dari waktu ke waktu menciptakan lubang yang memerlukan kompaksi. Manajemen memori TPU melalui analisis statis compiler menghindari fragmentasi runtime sepenuhnya—tensor diberi lokasi yang telah ditentukan berdasarkan computation graph.¹⁶⁹
Model pemrograman menghilangkan seluruh kelas error CUDA. Tidak ada lagi "illegal memory access" dari pointer arithmetic yang salah, tidak ada bug cache coherency antara CPU dan GPU, tidak ada error sinkronisasi dari panggilan cudaDeviceSynchronize() yang hilang. Abstraksi tingkat tinggi mencegah footgun umum dalam pemrograman CUDA.¹⁷⁰
Eksekusi Deterministik dan Reproduktibilitas
Non-associativity floating-point menciptakan tantangan reproduktibilitas dalam komputasi paralel. Ekspresi (a + b) + c dapat menghasilkan hasil berbeda dari a + (b + c) karena rounding error, dan reduksi paralel dapat menjumlah dalam urutan berbeda di seluruh run tergantung pada race condition.¹⁷¹
Eksekusi TPU menunjukkan determinisme yang lebih kuat dibandingkan implementasi GPU tipikal. Pola dataflow tetap systolic array memastikan urutan operasi identik di seluruh run. Operasi kolektif mengikuti pohon reduksi deterministik daripada agregasi oportunistik berdasarkan urutan kedatangan. Prediktabilitas memungkinkan training reproducible di mana hyperparameter dan data identik menghasilkan bobot model yang bit-identical.¹⁷²
Debugging sangat diuntungkan dari determinisme. Training non-deterministik membuat root-causing kegagalan hampir tidak mungkin—apakah NaN dari bug algoritmik yang asli atau race condition acak? Eksekusi deterministik berarti kegagalan reproduksi dengan andal, memungkinkan pendekatan debugging sistematis.¹⁷³
Aplikasi scientific computing sangat menghargai reproduktibilitas. Model iklim, simulasi penemuan obat, dan penelitian fisika memerlukan hasil yang dapat diverifikasi yang memungkinkan peneliti berbeda mereproduksi hasil identik. Determinisme TPU mendukung metode ilmiah lebih baik daripada alternatif non-deterministik yang racing.¹⁷⁴
Optimisasi Compiler dan Produktivitas Developer
Optimisasi agresif XLA memberikan peningkatan performa substansial "out of the box" tanpa tuning manual. Peneliti melaporkan peningkatan 40% dalam throughput model dari kompilasi saja dibandingkan framework eksekusi eager.¹⁷⁵ Performa datang gratis—tidak diperlukan kernel engineering.
Optimisasi fusion khususnya menguntungkan developer. Hand-fusing operasi dalam CUDA memerlukan penulisan kernel khusus, pengujian kebenaran, dan pemeliharaan kode di seluruh versi framework. XLA secara otomatis menyatukan operasi dan update, serta mengadaptasi strategi fusion saat model berevolusi, menghilangkan beban pemeliharaan.¹⁷⁶
Otomatisasi transformasi layout menghemat minggu optimisasi manual. Menentukan layout tensor optimal untuk GPU memerlukan profiling berbagai pengaturan, menyisipkan transpos secara manual, dan mengelola pola alokasi memori dengan hati-hati. XLA mencoba layout secara otomatis dan memilih yang tercepat, membebaskan developer untuk fokus pada arsitektur model daripada performance engineering tingkat rendah.¹⁷⁷
Peningkatan produktivitas berkomposisi untuk tim penelitian. Waktu yang dihemat pada optimisasi infrastruktur mempercepat kemajuan ilmiah, memungkinkan lebih banyak eksperimen dan siklus iterasi yang lebih cepat. Organisasi melaporkan peningkatan kecepatan pengembangan 3× saat beralih dari pemrograman GPU CUDA ke workflow berbasis TPU JAX.¹⁷⁸
Keterbatasan Teknis dan Kekurangan
Platform Lock-In dan Kendala On-Premises
Akses TPU tersedia secara eksklusif melalui Google Cloud Platform, mencegah deployment on-premises dan menimbulkan kekhawatiran vendor lock-in.¹⁷⁹ Organisasi dengan persyaratan kedaulatan data, jaringan air-gapped, atau kebijakan yang melarang public cloud tidak dapat memanfaatkan TPU terlepas dari keunggulan teknisnya.
Kendala ini semakin penting seiring AI menjadi infrastruktur kritis. Ketergantungan pada satu cloud provider menciptakan risiko business continuity—perubahan harga, gangguan ketersediaan, atau penghentian layanan dapat memaksa migrasi yang mahal.¹⁸⁰ Ketersediaan GPU dari multiple vendor (hardware NVIDIA yang berjalan di AWS, Azure, GCP, dan on-prem) menyediakan pilihan yang secara arsitektur tidak dimungkinkan oleh TPU.
Strategi multi-cloud menghadapi hambatan. Organisasi yang melakukan standardisasi pada TPU tidak dapat dengan mudah burst ke cloud lain atau mengimplementasikan redundansi multi-cloud tanpa retraining model atau memelihara codebase terpisah untuk arsitektur accelerator yang berbeda.¹⁸¹ Kompleksitas operasional dari deployment hybrid GPU/TPU seringkali melebihi penghematan biaya dari pemilihan accelerator yang optimal.
Gap Kematangan Ekosistem CUDA
Platform CUDA NVIDIA telah mengakumulasi 15+ tahun pengembangan ekosistem, library, dokumentasi, dan pengetahuan komunitas yang tidak dapat disamai oleh TPU.¹⁸² Gap kematangan ini termanifestasi dalam berbagai pain point untuk adopsi TPU.
Ketersediaan library sangat menguntungkan CUDA. Domain khusus seperti computer graphics, molecular dynamics, computational fluid dynamics, dan genomics telah mengakumulasi ribuan library yang dioptimalkan untuk CUDA selama beberapa dekade. Ekuivalen TPU seringkali tidak ada, memerlukan CPU fallback (yang menghancurkan performa) atau upaya porting selama berbulan-bulan.¹⁸³
Dukungan komunitas berbeda secara signifikan. Stack Overflow berisi ratusan ribu pertanyaan CUDA dengan jawaban detail—repository GitHub berjumlah jutaan. Conference talk, paper akademis, dan blog post sebagian besar berfokus pada programming CUDA. Programmer TPU menghadapi resource yang relatif jarang, siklus debugging yang lebih panjang, dan lebih sedikit ahli untuk dikonsultasikan.¹⁸⁴
Materi edukasi dan tutorial sebagian besar menargetkan CUDA. Kursus universitas mengajarkan programming GPU menggunakan CUDA. Kursus online berfokus pada CUDA. Talent pipeline menghasilkan jauh lebih banyak engineer berpengalaman CUDA dibandingkan ahli TPU, menciptakan tantangan hiring dan training.¹⁸⁵
Pengembangan custom kernel mencontohkan gap ekosistem. Menulis kernel CUDA yang dioptimalkan tetap tidak mudah tetapi mendapat keuntungan dari dokumentasi ekstensif, tool profiling, dan contoh kode. Pallas memungkinkan custom kernel TPU, tetapi dengan tooling yang kurang matang dan knowledge base yang lebih kecil. Learning curve ini mencegah semua kecuali optimasi yang paling performance-critical.¹⁸⁶
Spesialisasi Workload dan Kendala Fleksibilitas
Arsitektur TPU mengoptimalkan pola workload tertentu—terutama dense matrix multiplication dengan pola akses reguler dan batch size besar. Operasi di luar sweet spot mengalami performance cliff.¹⁸⁷
Dynamic shape menantang model eksekusi TPU. Compiler XLA mengasumsikan dimensi tensor tetap untuk optimasi dan code generation. Model dengan variable sequence length, dynamic control flow, atau data-dependent shape memerlukan padding ke ukuran maksimum (membuang compute dan memory) atau recompilation untuk setiap shape yang berbeda (menghancurkan performa).¹⁸⁸
Operasi sparse mendapat dukungan terbatas meskipun ada SparseCore. Sparse matrix-matrix multiplication, workload umum dalam scientific computing dan graph neural network, kekurangan implementasi efisien pada MXU atau VPU. SparseCore yang khusus menangani embedding table tetapi bukan general sparse linear algebra.¹⁸⁹
Inferensi batch kecil underutilize resource paralel TPU. Systolic array 256×256 berkembang pada matriks besar yang mengisi grid dengan pekerjaan produktif. Inferensi single-query meninggalkan sebagian besar MAC idle, menghasilkan latency per-query dan biaya yang lebih buruk dibandingkan alternatif GPU yang dioptimalkan untuk skenario low-batch.¹⁹⁰
Pola komputasi irregular mengalahkan efisiensi systolic array. Algoritma dengan branching yang tidak dapat diprediksi, struktur rekursif, atau akses memory pointer-chasing menunjukkan performa TPU yang buruk karena dataflow tetap tidak dapat beradaptasi dengan perilaku yang bergantung pada runtime.¹⁹¹
Workload non-ML jarang mendapat keuntungan dari akselerasi TPU. Simulasi ilmiah, video encoding, verifikasi blockchain, dan rendering semuanya berjalan lebih cepat pada arsitektur GPU yang lebih umum meskipun TPU memiliki peak FLOP yang lebih tinggi untuk operasi matriks.¹⁹²
Gap Debugging dan Development Tooling
Ekosistem NVIDIA mencakup tool profiling yang matang (Nsight Systems, Nsight Compute, nvprof), debugger (cuda-gdb), dan framework analisis yang telah disempurnakan selama beberapa dekade. Tooling TPU ada, tetapi secara substansial tertinggal dalam kecanggihan.¹⁹³
XProf menyediakan profiling dasar melalui integrasi TensorBoard tetapi kekurangan akses hardware counter granular yang diekspos oleh tool NVIDIA. Memahami cache miss rate, occupancy, warp divergence, atau memory bank conflict—semua metrik optimasi GPU yang kritis—tidak memiliki ekuivalen TPU karena arsitekturnya berbeda secara fundamental.¹⁹⁴
Error message seringkali menyamarkan root cause. Kegagalan kompilasi XLA menghasilkan pesan samar tentang shape mismatch atau operasi yang tidak didukung, tanpa panduan yang jelas untuk resolusi. Error CUDA, meskipun terkenal tidak membantu, mendapat keuntungan dari lima belas tahun penjelasan StackOverflow dan tribal knowledge.¹⁹⁵
Debugging distributed training pada multi-chip pod mendekati kemustahilan tanpa tool khusus. Race condition, bug sinkronisasi gradient, dan kegagalan operasi kolektif termanifestasi sebagai error non-deterministik (ironisnya, meskipun ada keuntungan determinisme TPU) yang bereproduksi secara tidak konsisten dan menolak diagnosis sistematis.¹⁹⁶
Iteration loop memperpanjang secara menyakitkan untuk model kompleks. Recompilation untuk perubahan shape atau modifikasi arsitektur dapat memerlukan beberapa menit, membekukan pengembangan sementara compiler bekerja. Model eager execution CUDA memungkinkan iterasi yang lebih cepat meskipun peak performance lebih rendah.¹⁹⁷
Deployment di Dunia Nyata: Produksi dalam Skala Besar
Anthropic Claude: Strategi Multi-Platform
Pengumuman Anthropic pada Oktober 2025 tentang deployment lebih dari satu juta chip TPU mewakili komitmen akselerator AI terbesar yang pernah diungkapkan secara publik dalam sejarah.¹⁹⁸ Perusahaan tersebut berencana mengakses lebih dari satu gigawatt kapasitas komputasi yang akan beroperasi pada 2026 secara eksklusif untuk training dan serving model Claude masa depan.
Skala ini mengerdilkan deployment sebelumnya hingga beberapa orde magnitude. Satu juta chip yang dikonfigurasi sebagai Ironwood TPU akan memberikan sekitar 4,6 exaflops komputasi FP8—lebih dari 40× total performa seluruh daftar superkomputer Top500 dari lima tahun sebelumnya.¹⁹⁹ Komitmen ini menandakan kepercayaan pada arsitektur TPU untuk pengembangan model frontier pada skala yang sebelumnya dianggap fiksi ilmiah.
Anthropic menjalankan strategi hardware multi-platform yang disengaja di seluruh TPU Google, Trainium Amazon, dan GPU NVIDIA.²⁰⁰ Diversifikasi ini menyediakan asuransi kapasitas, leverage harga, dan distribusi geografis. Claude melayani secara global dari deployment di ketiga platform tersebut, dengan routing permintaan berdasarkan ketersediaan kapasitas dan persyaratan latensi regional.
Postmortem teknis perusahaan dari Agustus 2025 mengungkapkan kompleksitas deployment dalam skala besar. Miskonfigurasi pada server TPU Claude API menyebabkan error generasi token, kadang-kadang memberikan probabilitas yang tidak terduga tinggi pada karakter Thai atau Cina dalam prompt bahasa Inggris.²⁰¹ Insiden tersebut menunjukkan bahwa bahkan error sederhana dapat berefek cascade secara tidak terduga melalui sistem yang memproses miliaran token setiap hari.
Deployment terpisah memicu bug laten dalam XLA: TPU compiler yang memengaruhi Claude Haiku 3.5. Bug tersebut telah ada tanpa terdeteksi selama berbulan-bulan hingga kombinasi arsitektur model dan flag compiler tertentu mengekspos cacat tersebut.²⁰² Penemuan ini menekankan bahwa deployment produksi menemukan kasus-kasus corner yang tidak ada di lingkungan development dan staging.
Engineer Anthropic menyebutkan price-performance dan efisiensi TPU sebagai kriteria seleksi utama. Ekonomi yang menarik mempercepat pengembangan dengan memungkinkan eksperimen yang lebih besar dalam anggaran yang tetap.²⁰³ training model yang lebih besar, eksplorasi konfigurasi hyperparameter yang lebih banyak, dan iterasi yang lebih cepat semuanya berasal dari pengurangan biaya per-FLOP.
Google Gemini: Dirancang untuk TPU Sejak Awal
Model Gemini Google melakukan training dan serving secara eksklusif di TPU, dengan arsitektur dan prosedur training yang di-co-design untuk karakteristik TPU sejak awal.²⁰⁴ Coupling yang ketat memungkinkan eksploitasi optimisasi khusus TPU yang tidak dapat dimanfaatkan oleh model cross-platform.
Deployment Gemini dilaporkan menggunakan 50.000 chip TPU v6e untuk training dan serving varian model yang paling signifikan.²⁰⁵ Pod skala besar tersebut memerlukan orkestrasi yang sophisticated—penjadwalan job di ribuan chip, koordinasi checkpoint untuk mencegah bottleneck, pemulihan kegagalan untuk meminimalkan pekerjaan yang hilang, dan monitoring real-time untuk mengidentifikasi node yang terdegradasi sebelum kegagalan menyebar.
Google melatih Gemini 2.0 pada Trillium TPU, memvalidasi arsitektur generasi keenam untuk pengembangan model frontier.²⁰⁶ Training run tersebut mendemonstrasikan efisiensi scaling hingga jumlah chip yang belum pernah ada, mencapai strong scaling melampaui plateau tipikal di mana overhead komunikasi mendominasi.
Infrastruktur serving model secara khusus memanfaatkan optimisasi inference TPU. Batch processing mengagregat beberapa permintaan pengguna untuk memaksimalkan utilisasi MXU. Manajemen key-value cache memanfaatkan kapasitas HBM, memungkinkan pemrosesan konteks yang berumur panjang tanpa disk swapping. Arsitektur ini memberikan waktu respons sub-detik untuk query kompleks sambil menangani volume permintaan global yang masif.²⁰⁷
Sistem monitoring produksi secara kontinu melacak 50.000+ TPU, mendeteksi anomali yang mungkin menurunkan kualitas atau ketersediaan model.²⁰⁸ Telemetri menangkap error rate, persentil latensi, throughput, tekanan memori, dan karakteristik termal di setiap chip. Model machine learning menganalisis stream telemetri itu sendiri, memprediksi kegagalan sebelum terjadi dan memicu pemeliharaan preemptive.
Deployment Produksi Tambahan
Midjourney bermigrasi dari infrastruktur GPU ke TPU, mencapai pengurangan biaya 65% dan peningkatan latensi 40% untuk workload generasi gambar.²⁰⁹ Layanan generasi seni memproses 300.000 gambar per menit pada beban puncak, memerlukan throughput komputasi yang masif dan performa konsisten di bawah pola traffic yang bersifat burst.
Model bahasa Cohere di TPU mencapai 3× throughput dari deployment GPU sebelumnya.²¹⁰ Speedup tersebut memungkinkan melayani lebih banyak pelanggan dari footprint infrastruktur yang sama, secara langsung meningkatkan ekonomi bisnis. Perusahaan memanfaatkan kemampuan SPMD JAX untuk secara efisien memparalelkan model di seluruh pod TPU.
Snap mengamankan kapasitas untuk 10.000 chip TPU v6e yang mendukung fitur augmented reality, sistem rekomendasi, dan tool AI kreatif.²¹¹ Deployment tersebut mencakup beberapa wilayah geografis, memastikan latensi rendah untuk basis pengguna global Snapchat sambil menjaga konsistensi model di seluruh wilayah.
Institusi akademik semakin banyak mengadopsi TPU untuk penelitian. Program TPU Research Cloud (TRC) menyediakan akses TPU gratis untuk peneliti, memungkinkan eksperimen pada skala yang sebelumnya hanya dapat diakses oleh lab korporat yang didanai dengan baik.²¹² Demokratisasi ini mempercepat kemajuan saintifik dengan menghilangkan hambatan hardware bagi akademisi yang menyelidiki pertanyaan fundamental tentang kemampuan dan keterbatasan AI.
Debugging, Profiling, dan Optimisasi Kinerja
Integrasi XProf dan TensorBoard
XProf merupakan tool profiling utama untuk beban kerja TPU, menyediakan analisis kinerja untuk program JAX, PyTorch/XLA, dan TensorFlow di CPU, GPU, dan TPU.²¹³ Tool ini terintegrasi dengan TensorBoard untuk visualisasi, menyajikan data profiling melalui antarmuka yang familiar dan sudah dipahami oleh para ML engineer.
Instalasi memerlukan plugin TensorBoard: pip install tensorboard_plugin_profile tensorboard. Ini mengaktifkan keseluruhan toolchain.²¹⁴ Menjalankan profiling pada TPU VM melibatkan pengambilan trace selama training atau inference, mengupload hasil ke TensorBoard, dan menganalisis visualisasi untuk mengidentifikasi bottleneck.
Overview Page menyediakan metrik ringkasan kinerja tingkat tinggi, termasuk breakdown waktu step, utilisasi device, dan identifikasi bottleneck level atas.²¹⁵ Halaman ini langsung menyoroti apakah beban kerja terbatas pada compute (MXU berjalan terus-menerus), terbatas pada memory (menunggu transfer HBM), atau terbatas pada komunikasi (terblokir pada operasi kolektif).
Trace Viewer dan Analisis Timeline
Trace Viewer menampilkan visualisasi timeline detail yang menunjukkan kapan tepatnya operasi dijalankan, kapan transfer data terjadi, dan di mana idle time terakumulasi.²¹⁶ Antarmuka berbasis Chrome memungkinkan zooming hingga resolusi mikrodetik, mengungkap perilaku penjadwalan yang tepat yang disamarkan oleh metrik agregat.
Memahami trace memerlukan pengenalan pola umum. Celah panjang antara operasi menunjukkan overhead kompilasi, bottleneck data-loading, atau overhead Python karena pipeline data yang kurang optimal. Operasi kecil yang berulang menunjukkan fusion yang tidak memadai. Operasi kolektif yang berlangsung dalam milidetik menunjuk pada inefisiensi komunikasi atau strategi sharding yang buruk.²¹⁷
Color coding membedakan jenis operasi: hijau untuk compute, biru untuk transfer memory, oranye untuk komunikasi, dan merah untuk idle time. Beban kerja yang optimal menunjukkan blok berwarna yang padat dengan celah merah minimal. Kode yang kurang optimal menampilkan timeline yang jarang dengan rentang merah panjang yang menunjukkan pemborosan resource.²¹⁸
Penggunaan lanjutan melibatkan korelasi perilaku timeline dengan source code. PyTorch/XLA mendukung anotasi pengguna yang disisipkan dalam kode yang muncul di trace, memungkinkan pemetaan perilaku kinerja ke komponen model tertentu.²¹⁹ Anotasi tersebut mengubah trace yang tidak jelas menjadi wawasan yang dapat ditindaklanjuti tentang layer atau operasi mana yang membutuhkan fokus optimisasi.
Memory Profile Tool dan OOM Debugging
Error out-of-memory (OOM) mengganggu pengembangan model besar. Memory Profile Tool memantau penggunaan memory device selama eksekusi, menangkap utilisasi puncak dan pola alokasi yang menyebabkan kegagalan OOM.²²⁰
Tool ini memvisualisasikan konsumsi memory dari waktu ke waktu, menunjukkan tensor mana yang mengonsumsi kapasitas paling banyak dan kapan penggunaan puncak terjadi. Visualisasi sering mengungkap alokasi yang mengejutkan—gradient buffer yang lebih besar dari perkiraan, activation memory yang seharusnya di-checkpoint, atau tensor sementara yang gagal dieliminasi oleh XLA.²²¹
Strategi debugging melibatkan pengurangan footprint memory secara iteratif melalui berbagai teknik. Gradient checkpointing menghitung ulang activation selama backward pass alih-alih menyimpannya. Optimizer state sharding mendistribusikan momentum Adam dan variance ke seluruh device. Mixed precision mengurangi memory hingga 2× dibandingkan FP32. Microbatching memproses batch yang lebih kecil secara berurutan daripada satu batch besar.²²²
Optimisasi memory lanjutan memerlukan pemahaman keputusan compiler. Flag xla_dump_to mengekspor representasi intermediate yang menunjukkan bagaimana XLA mentransformasi computation graph. Menganalisis IR mengungkap apakah fusion berhasil, di mana copy yang tidak perlu terjadi, dan operasi mana yang mengalokasikan lebih banyak memory dari yang diperkirakan.²²³
Input Pipeline Analyzer
Preprocessing CPU sering menjadi bottleneck pada training TPU. Input Pipeline Analyzer mengidentifikasi apakah data loading mengikuti konsumsi accelerator atau apakah TPU menganggur menunggu batch.²²⁴
Tool ini memisahkan analisis sisi host (preprocessing CPU, data augmentation, assembly batch) dari eksekusi sisi device (komputasi TPU aktual). Beban kerja yang terbatas input menunjukkan utilisasi device menurun selama data loading sementara utilisasi CPU memuncak. Beban kerja yang terbatas compute mempertahankan utilisasi device yang tinggi dengan CPU yang nyaman mengikuti pace.²²⁵
Strategi optimisasi bergantung pada lokasi bottleneck. Preprocessing host yang lambat mendapat manfaat dari paralelisasi data loading di lebih banyak core CPU, mengurangi kompleksitas augmentation per-sample, atau prefetching batch sebelum konsumsi. Bottleneck sisi device memerlukan perubahan pada arsitektur model, fusion yang lebih baik, atau penyesuaian sharding daripada tuning pipeline data.²²⁶
Masa Depan Tensor Processing Unit
Evolusi arsitektur tujuh generasi Google menunjukkan inovasi berkelanjutan dalam akselerator AI terspesialisasi. Dukungan FP8 Ironwood, kapasitas memori yang masif, dan skala superpod 9,216-chip menunjukkan lintasan untuk pengembangan masa depan.²²⁷
Pengurangan presisi kemungkinan akan berlanjut menuju FP4 atau bahkan lebih rendah untuk operasi-operasi spesifik. Penelitian yang muncul menunjukkan bahwa banyak operasi jaringan neural mentolerir kuantisasi ekstrem dengan prosedur pelatihan yang cermat. TPU masa depan mungkin menerapkan sistem mixed-precision dengan forward pass FP4, backward pass FP8, dan pembaruan optimizer FP32.²²⁸
Kapasitas memori berlomba melawan pertumbuhan ukuran model. Model-model frontier saat ini sudah membebani memori akselerator, memerlukan strategi paralelisme yang canggih. TPU generasi berikutnya mungkin mengintegrasikan teknologi memori non-volatile seperti 3D XPoint atau resistive RAM, memungkinkan memori on-package skala terabyte tanpa konsumsi daya DRAM.²²⁹
Interkoneksi optik dapat diperluas melampaui circuit switching untuk menyertakan elemen komputasi optik. Penelitian mengeksplorasi perkalian matriks fotonik yang dieksekusi dengan kecepatan cahaya dan daya minimal, berpotensi memperkuat systolic array elektronik dengan co-processor optik untuk operasi-operasi spesifik.²³⁰
Dukungan sparsity kemungkinan akan berkembang melampaui embedding ke aljabar linear sparse umum. Teknik pruning jaringan neural menunjukkan bahwa 90%+ dari weight dapat di-zero-kan tanpa kehilangan kualitas. Arsitektur masa depan mungkin secara native melewati komputasi bernilai nol daripada secara eksplisit menghitung dan membuangnya.²³¹
Prinsip-prinsip arsitektural yang mendasari kesuksesan TPU—spesialisasi domain, interkoneksi kustom, stack software yang co-designed, dan orkestrasi skala gedung—mengarah pada masa depan akselerator yang semakin terspesialisasi. Daripada processor satu-ukuran-untuk-semua, kita mungkin melihat akselerator yang dioptimalkan untuk training versus inference, jaringan konvolusional versus transformer, model dense versus sparse, dan sequence pendek versus panjang.²³²
Engineer yang membangun infrastruktur AI saat ini harus memahami secara mendalam arsitektur TPU. Baik saat menerapkan di Google Cloud, bersaing dengan Google di pasar akselerator, atau mendesain sistem ML generasi berikutnya, prinsip desain dan tradeoff yang terwujud dalam TPU mengungkapkan kebenaran fundamental tentang apa yang diminta workload AI dari hardware. Matematika systolic array, desain hierarki memori, topologi interkoneksi, dan strategi optimisasi compiler mewakili kebijaksanaan terakumulasi selama puluhan tahun yang dapat diterapkan jauh melampaui TPU itu sendiri.
Ketegangan antara spesialisasi dan generalitas yang mendefinisikan TPU versus GPU akan bertahan tanpa batas. TPU mengorbankan fleksibilitas untuk efisiensi ekstrem pada workload yang sempit. GPU mengorbankan efisiensi puncak untuk aplikabilitas yang lebih luas. Tidak ada pendekatan yang mendominasi—pilihan optimal sepenuhnya bergantung pada karakteristik workload, skala, batasan biaya, dan kebutuhan operasional. Organisasi yang berhasil dengan AI pada skala besar semakin mengadopsi strategi heterogen, mencocokkan arsitektur akselerator dengan kebutuhan workload daripada melakukan standarisasi pada satu platform.
Komitmen jutaan chip Anthropic terhadap TPU menunjukkan bahwa arsitektur tersebut telah mencapai kematangan produksi pada skala tertinggi. Deployment multi-gigawatt yang akan online pada 2026 akan melatih model-model yang mendorong batas-batas dari apa yang dapat dicapai AI, dan infrastruktur yang memungkinkan model-model tersebut mewujudkan kecanggihan engineering yang jarang ditandingi organisasi lain. Memahami bagaimana 65,536 unit multiply-accumulate dalam systolic array berkolaborasi untuk melatih model-model frontier sangat penting bagi siapa pun yang serius tentang masa depan AI.
Referensi
-
Google Cloud Press Corner, "Anthropic to Expand Use of Google Cloud TPUs and Services," 23 Oktober 2025, https://www.googlecloudpresscorner.com/2025-10-23-Anthropic-to-Expand-Use-of-Google-Cloud-TPUs-and-Services.
-
TrendForce, "Google Unveils 7th-Gen TPU Ironwood with 9,216-Chip Superpod, Taking Aim at NVIDIA," 7 November 2025, https://www.trendforce.com/news/2025/11/07/news-google-unveils-7th-gen-tpu-ironwood-with-9216-chip-superpod-taking-aim-at-nvidia/.
-
Norman P. Jouppi et al., "TPU v4: An Optically Reconfigurable Supercomputer for Machine Learning with Hardware Support for Embeddings," dalam Proceedings of the 50th Annual International Symposium on Computer Architecture (2023), arXiv:2304.01433.
-
Anthropic, "Expanding our use of Google Cloud TPUs and Services," Anthropic News, Oktober 2025, https://www.anthropic.com/news/expanding-our-use-of-google-cloud-tpus-and-services.
-
Google Cloud Blog, "Quantifying the performance of the TPU, our first machine learning chip," April 2017, https://cloud.google.com/blog/products/gcp/quantifying-the-performance-of-the-tpu-our-first-machine-learning-chip.
-
Norman P. Jouppi et al., "In-Datacenter Performance Analysis of a Tensor Processing Unit," Proceedings of the 44th Annual International Symposium on Computer Architecture (2017), arXiv:1704.04760.
-
Jouppi et al., "In-Datacenter Performance Analysis."
-
Jouppi et al., "In-Datacenter Performance Analysis."
-
Jonathan Hui, "AI Chips: Google TPU," Medium, diakses Desember 2025, https://jonathan-hui.medium.com/ai-chips-tpu-3fa0b2451a2d.
-
Wikipedia, "Bfloat16 floating-point format," diakses Desember 2025, https://en.wikipedia.org/wiki/Bfloat16_floating-point_format.
-
Henry Ko, "TPU Deep Dive," blog pribadi, diakses Desember 2025, https://henryhmko.github.io/posts/tpu/tpu.html.
-
Wikipedia, "Tensor Processing Unit," diakses Desember 2025, https://en.wikipedia.org/wiki/Tensor_Processing_Unit.
-
Wikipedia, "Tensor Processing Unit."
-
Wikipedia, "Tensor Processing Unit."
-
Ko, "TPU Deep Dive."
-
Jouppi et al., "TPU v4: An Optically Reconfigurable Supercomputer."
-
Jouppi et al., "TPU v4: An Optically Reconfigurable Supercomputer."
-
Jouppi et al., "TPU v4: An Optically Reconfigurable Supercomputer."
-
Jouppi et al., "TPU v4: An Optically Reconfigurable Supercomputer."
-
OpenXLA Project, "A deep dive into SparseCore for Large Embedding Models (LEM)," diakses Desember 2025, https://openxla.org/xla/sparsecore.
-
JAX Scaling Guide, "How to Think About TPUs," diakses Desember 2025, https://jax-ml.github.io/scaling-book/tpus/.
-
JAX Scaling Guide, "How to Think About TPUs."
-
Ko, "TPU Deep Dive."
-
JAX Scaling Guide, "How to Think About TPUs."
-
Google Cloud Blog, "Introducing Trillium, sixth-generation TPUs," Mei 2024, https://cloud.google.com/blog/products/compute/introducing-trillium-6th-gen-tpus.
-
Google Cloud Blog, "Introducing Trillium."
-
Google Cloud Blog, "Introducing Trillium."
-
Google Cloud Blog, "Introducing Trillium."
-
Google Cloud Blog, "Introducing Trillium."
-
Google Blog, "Ironwood: The first Google TPU for the age of inference," November 2025, https://blog.google/products/google-cloud/ironwood-tpu-age-of-inference/.
-
XPU.pub, "Google Adds FP8 to Ironwood TPU; Can It Beat Blackwell?" 16 April 2025, https://xpu.pub/2025/04/16/google-ironwood/.
-
TrendForce, "Google Unveils 7th-Gen TPU Ironwood."
-
The Register, "Google's 7th-gen Ironwood TPUs promise 42 AI exaFLOPS pods," 10 April 2025, https://www.theregister.com/2025/04/10/googles_7thgen_ironwood_tpus_debut/.
-
TrendForce, "Google Unveils 7th-Gen TPU Ironwood."
-
Ko, "TPU Deep Dive."
-
XPU.pub, "Google Adds FP8 to Ironwood TPU."
-
Google Cloud Press Corner, "Anthropic to Expand Use."
-
Telesens, "Understanding Matrix Multiplication on a Weight-Stationary Systolic Architecture," 30 Juli 2018, https://telesens.co/2018/07/30/systolic-architectures/.
-
Telesens, "Understanding Matrix Multiplication."
-
Jouppi et al., "In-Datacenter Performance Analysis."
-
Telesens, "Understanding Matrix Multiplication."
-
CP Lu, "Should We All Embrace Systolic Arrays?" Medium, diakses Desember 2025, https://cplu.medium.com/should-we-all-embrace-systolic-array-df3830f193dc.
-
Google Cloud Documentation, "TPU architecture," diakses Desember 2025, https://docs.cloud.google.com/tpu/docs/system-architecture-tpu-vm.
-
Google Cloud Documentation, "TPU architecture."
-
Hui, "AI Chips: Google TPU."
-
Telnyx, "Architecture insights: MXU and TPU components," diakses Desember 2025, https://telnyx.com/learn-ai/mxu-tpu.
-
Ko, "TPU Deep Dive."
-
Jouppi et al., "TPU v4: An Optically Reconfigurable Supercomputer."
-
SemiEngineering, "Tensor Processing Unit (TPU)," diakses Desember 2025, https://semiengineering.com/knowledge_centers/integrated-circuit/ic-types/processors/tensor-processing-unit-tpu/.
-
TrendForce, "Google Unveils 7th-Gen TPU Ironwood."
-
SemiEngineering, "Tensor Processing Unit (TPU)."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Google Cloud Documentation, "Cloud TPU performance guide," diakses Desember 2025, https://cloud.google.com/tpu/docs/performance-guide.
-
OpenXLA Project, "A deep dive into SparseCore."
-
OpenXLA Project, "A deep dive into SparseCore."
-
OpenXLA Project, "A deep dive into SparseCore."
-
Jouppi et al., "TPU v4: An Optically Reconfigurable Supercomputer."
-
OpenXLA Project, "A deep dive into SparseCore."
-
Jouppi et al., "TPU v4: An Optically Reconfigurable Supercomputer."
-
OpenXLA Project, "A deep dive into SparseCore."
-
JAX Scaling Guide, "How to Think About TPUs."
-
JAX Scaling Guide, "How to Think About TPUs."
-
JAX Scaling Guide, "How to Think About TPUs."
-
Ko, "TPU Deep Dive."
-
JAX Scaling Guide, "How to Think About TPUs."
-
JAX Scaling Guide, "How to Think About TPUs."
-
TrendForce, "Google Unveils 7th-Gen TPU Ironwood."
-
Ko, "TPU Deep Dive."
-
Anthropic, "Expanding our use of Google Cloud TPUs."
-
Jouppi et al., "TPU v4: An Optically Reconfigurable Supercomputer."
-
Jouppi et al., "TPU v4: An Optically Reconfigurable Supercomputer."
-
Jouppi et al., "TPU v4: An Optically Reconfigurable Supercomputer."
-
Jouppi et al., "TPU v4: An Optically Reconfigurable Supercomputer."
-
Ko, "TPU Deep Dive."
-
Jouppi et al., "TPU v4: An Optically Reconfigurable Supercomputer."
-
Leon Poutievski, "Mission Apollo: Landing Optical Circuit Switching at Datacenter Scale," LinkedIn, Juni 2022, https://www.linkedin.com/posts/leon-poutievski-8910a851_mission-apollo-landing-optical-circuit-switching-activity-6968472071534235649-cB4l.
-
Ko, "TPU Deep Dive."
-
Jouppi et al., "TPU v4: An Optically Reconfigurable Supercomputer."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Jouppi et al., "TPU v4: An Optically Reconfigurable Supercomputer."
-
JAX Scaling Guide, "How to Think About TPUs."
-
TrendForce, "Google Unveils 7th-Gen TPU Ironwood."
-
TrendForce, "Google Unveils 7th-Gen TPU Ironwood."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
OpenXLA Project, "XLA: Optimizing Compiler for Machine Learning," diakses Desember 2025, https://openxla.org/xla.
-
Daniel Snider dan Ruofan Liang, "Operator Fusion in XLA: Analysis and Evaluation," makalah akademis, diakses Desember 2025, https://danielsnider.ca/papers/Operator_Fusion_in_XLA_Analysis_and_Evaluation.pdf.
-
Snider dan Liang, "Operator Fusion in XLA."
-
APXML, "Memory-Aware Data Layout Transformations (NCHW/NHWC)," diakses Desember 2025, https://apxml.com/courses/compiler-runtime-optimization-ml/chapter-3-advanced-graph-level-optimizations/memory-aware-layout-transformations.
-
OpenXLA Project, "XLA."
-
PyTorch Documentation, "Pytorch/XLA Overview," diakses Desember 2025, https://docs.pytorch.org/xla/master/learn/xla-overview.html.
-
OpenXLA Project, "A deep dive into SparseCore."
-
Mangpo Phothilimthana et al., "A Flexible Approach to Autotuning Multi-Pass Machine Learning Compilers," PACT 2021, diakses Desember 2025, https://mangpo.net/papers/xla-autotuning-pact2021.pdf.
-
JAX Documentation, "Introduction to parallel programming," diakses Desember 2025, https://docs.jax.dev/en/latest/sharded-computation.html.
-
GitHub, "jax-ml/jax: Composable transformations of Python+NumPy programs," diakses Desember 2025, https://github.com/jax-ml/jax.
-
OpenXLA Project, "Shardy Guide for JAX Users," diakses Desember 2025, https://openxla.org/shardy/getting_started_jax.
-
JAX Documentation, "Introduction to parallel programming."
-
OpenXLA Project, "Shardy Guide for JAX Users."
-
OpenXLA Project, "Shardy Guide for JAX Users."
-
JAX Documentation, "Introduction to parallel programming."
-
OpenXLA Project, "Shardy Guide for JAX Users."
-
PyTorch Documentation, "Pytorch/XLA Overview."
-
GitHub, "RFC: Evolving PyTorch/XLA for a more native experience on TPU," Issue #9684, diakses Desember 2025, https://github.com/pytorch/xla/issues/9684.
-
Google Cloud Blog, "PyTorch/XLA 2.4 improves Pallas and adds 'eager mode,'" diakses Desember 2025, https://cloud.google.com/blog/products/ai-machine-learning/pytorch-xla-2-4-improves-pallas-and-adds-eager-mode/.
-
PyTorch Documentation, "Pytorch/XLA Overview."
-
PyTorch Documentation, "Custom Kernels via Pallas," diakses Desember 2025, https://docs.pytorch.org/xla/master/features/pallas.html.
-
PyTorch Documentation, "Custom Kernels via Pallas."
-
PyTorch Documentation, "Custom Kernels via Pallas."
-
vLLM Blog, "vLLM TPU: A New Unified Backend Supporting PyTorch and JAX on TPU," 16 Oktober 2025, https://blog.vllm.ai/2025/10/16/vllm-tpu.html.
-
GitHub, "pytorch/xla," diakses Desember 2025, https://github.com/pytorch/xla.
-
StackGpu, "FP8, BF16, and INT8: How Low-Precision Formats Are Revolutionizing Deep Learning Throughput," Medium, diakses Desember 2025, https://medium.com/@StackGpu/fp8-bf16-and-int8-how-low-precision-formats-are-revolutionizing-deep-learning-throughput-e6c1f3adabc2.
-
Wikipedia, "Bfloat16 floating-point format."
-
Wikipedia, "Bfloat16 floating-point format."
-
Paulius Micikevicius et al., "FP8 Formats for Deep Learning," arXiv:2209.05433, September 2022.
-
XPU.pub, "Google Adds FP8 to Ironwood TPU."
-
Micikevicius et al., "FP8 Formats for Deep Learning."
-
Google Cloud Blog, "Accurate Quantized Training (AQT) for TPU v5e," diakses Desember 2025, https://cloud.google.com/blog/products/compute/accurate-quantized-training-aqt-for-tpu-v5e.
-
StackGpu, "FP8, BF16, and INT8."
-
Jeffrey Tse, "Understanding the FP64, FP32, FP16, BFLOAT16, TF32, FP8 Formats," blog pribadi, 9 Desember 2024, https://jeffreytse.net/computer/2024/12/09/understanding-the-fp64-fp32-fp16-bfloat16-tf32-fp8-formats.html.
-
PyTorch Blog, "PyTorch/XLA SPMD: Scale Up Model Training and Serving with Automatic Parallelization," diakses Desember 2025, https://pytorch.org/blog/pytorch-xla-spmd/.
-
OpenXLA Project, "Shardy Guide for JAX Users."
-
JAX Documentation, "Introduction to parallel programming."
-
OpenXLA Project, "Shardy Guide for JAX Users."
-
Ko, "TPU Deep Dive."
-
JAX Documentation, "Introduction to parallel programming."
-
Anthropic, "Expanding our use of Google Cloud TPUs."
-
JAX Documentation, "Introduction to parallel programming."
-
JAX Documentation, "Introduction to parallel programming."
-
Adam Roberts et al., "Scaling Up Models and Data with t5x and seqio," arXiv:2203.17189, Maret 2022.
-
Roberts et al., "Scaling Up Models and Data."
-
JAX Documentation, "Introduction to parallel programming."
-
JAX Documentation, "Introduction to parallel programming."
-
OpenXLA Project, "Shardy Guide for JAX Users."
-
Roberts et al., "Scaling Up Models and Data."
-
Roberts et al., "Scaling Up Models and Data."
-
Ko, "TPU Deep Dive."
-
MLCommons, "Benchmark MLPerf Training," diakses Desember 2025, https://mlcommons.org/benchmarks/training/.
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
HPCwire, "MLPerf Training v5.0 Benchmark Results Reflect Rapid Growth in the Field of AI," Juni 2025, https://www.hpcwire.com/off-the-wire/mlperf-training-v5-0-benchmark-results-reflect-rapid-growth-in-the-field-of-ai/.
-
MLCommons, "MLCommons Releases New MLPerf Inference v5.0 Benchmark Results," April 2025, https://mlcommons.org/2025/04/mlperf-inference-v5-0-results/.
-
Ko, "TPU Deep Dive."
-
Google Cloud Blog, "TPU v4 enables performance, energy and CO2e efficiency gains," diakses Desember 2025, https://cloud.google.com/blog/topics/systems/tpu-v4-enables-performance-energy-and-co2e-efficiency-gains.
-
TrendForce, "Google Unveils 7th-Gen TPU Ironwood."
-
Google Cloud Blog, "Quantifying the performance of the TPU."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Artech Digital, "Energy-Efficient GPU vs. TPU Allocation," diakses Desember 2025, https://www.artech-digital.com/blog/energy-efficient-gpu-vs-tpu-allocation.
-
Wikipedia, "Tensor Processing Unit."
-
XPU.pub, "Google Adds FP8 to Ironwood TPU."
-
Ko, "TPU Deep Dive."
-
Google Cloud Blog, "TPU v4 enables performance, energy and CO2e efficiency gains."
-
ByteBridge, "GPU and TPU Comparative Analysis Report," Medium, diakses Desember 2025, https://bytebridge.medium.com/gpu-and-tpu-comparative-analysis-report-a5268e4f0d2a.
-
ByteBridge, "GPU and TPU Comparative Analysis Report."
-
Anthropic, "Expanding our use of Google Cloud TPUs."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
DataCamp, "Understanding TPUs vs GPUs in AI: A Comprehensive Guide," diakses Desember 2025, https://www.datacamp.com/blog/tpu-vs-gpu-ai.
-
Ko, "TPU Deep Dive."
-
DataCamp, "Understanding TPUs vs GPUs in AI."
-
Grigory Sapunov, "FP64, FP32, FP16, BFLOAT16, TF32, and other members of the ZOO," Medium, diakses Desember 2025, https://moocaholic.medium.com/fp64-fp32-fp16-bfloat16-tf32-and-other-members-of-the-zoo-a1ca7897d407.
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Snider dan Liang, "Operator Fusion in XLA."
-
APXML, "Memory-Aware Data Layout Transformations."
-
Google Cloud Blog, "How Lightricks trains video diffusion models at scale with JAX on TPU," diakses Desember 2025, https://cloud.google.com/blog/products/media-entertainment/how-lightricks-trains-video-diffusion-models-at-scale-with-jax-on-tpu.
-
CloudOptimo, "TPU vs GPU: What's the Difference in 2025?" diakses Desember 2025, https://www.cloudoptimo.com/blog/tpu-vs-gpu-what-is-the-difference-in-2025/.
-
Phoenix NAP, "TPU vs. GPU: Differences Explained," diakses Desember 2025, https://phoenixnap.com/kb/tpu-vs-gpu.
-
CloudOptimo, "TPU vs GPU."
-
DataCamp, "Understanding TPUs vs GPUs in AI."
-
Tailscale, "TPU vs GPU: Which Is Better for AI Infrastructure in 2025?" diakses Desember 2025, https://tailscale.com/learn/what-is-tpu-vs-gpu.
-
DataCamp, "Understanding TPUs vs GPUs in AI."
-
DataCamp, "Understanding TPUs vs GPUs in AI."
-
PyTorch Documentation, "Custom Kernels via Pallas."
-
Phoenix NAP, "TPU vs. GPU: Differences Explained."
-
Ko, "TPU Deep Dive."
-
OpenMetal, "TPU vs GPU: Pros and Cons," diakses Desember 2025, https://openmetal.io/docs/product-guides/private-cloud/tpu-vs-gpu-pros-and-cons/.
-
OpenMetal, "TPU vs GPU: Pros and Cons."
-
Phoenix NAP, "TPU vs. GPU: Differences Explained."
-
PRIMO.ai, "Processing Units - CPU, GPU, APU, TPU, VPU, FPGA, QPU," diakses Desember 2025, https://primo.ai/index.php?title=Processing_Units_-_CPU%2C_GPU%2C_APU%2C_TPU%2C_VPU%2C_FPGA%2C_QPU.
-
DataCamp, "Understanding TPUs vs GPUs in AI."
-
Google Cloud Documentation, "Profile your model on Cloud TPU VMs," diakses Desember 2025, https://cloud.google.com/tpu/docs/cloud-tpu-tools.
-
DataCamp, "Understanding TPUs vs GPUs in AI."
-
Ko, "TPU Deep Dive."
-
GitHub, "RFC: Evolving PyTorch/XLA."
-
Google Cloud Press Corner, "Anthropic to Expand Use."
-
TrendForce, "Google Unveils 7th-Gen TPU Ironwood."
-
Maginative, "Anthropic Secures 1M Google TPUs While Keeping Amazon as Primary Training Partner," diakses Desember 2025, https://www.maginative.com/article/anthropic-secures-1m-google-tpus-while-keeping-amazon-as-primary-training-partner/.
-
Anthropic, "A postmortem of three recent issues," Engineering Blog, Agustus 2025, https://www.anthropic.com/engineering/a-postmortem-of-three-recent-issues.
-
Anthropic, "A postmortem of three recent issues."
-
AI Magazine, "Why Anthropic Uses Google Cloud TPUs for AI Infrastructure," diakses Desember 2025, https://aimagazine.com/news/why-anthropic-uses-google-cloud-tpus-for-ai-infrastructure.
-
Google Cloud Blog, "Ironwood TPUs and new Axion-based VMs for your AI workloads," November 2025, https://cloud.google.com/blog/products/compute/ironwood-tpus-and-new-axion-based-vms-for-your-ai-workloads.
-
Ko, "TPU Deep Dive."
-
TrendForce, "Google Unveils 7th-Gen TPU Ironwood."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Google Cloud, "Tensor Processing Units (TPUs)," diakses Desember 2025, https://cloud.google.com/tpu.
-
TensorFlow Documentation, "Optimize TensorFlow performance using the Profiler," diakses Desember 2025, https://www.tensorflow.org/guide/profiler.
-
Google Cloud Documentation, "Profile your model on Cloud TPU VMs."
-
TensorFlow Documentation, "TensorFlow Profiler: Profile model performance," diakses Desember 2025, https://www.tensorflow.org/tensorboard/tensorboard_profiling_keras.
-
Google Cloud Documentation, "Profile your model on Cloud TPU VMs."
-
Google Cloud Blog, "PyTorch/XLA: Performance debugging on Cloud TPU VM: Part III," diakses Desember 2025, https://cloud.google.com/blog/topics/developers-practitioners/pytorchxla-performance-debugging-cloud-tpu-vm-part-iii.
-
Google Cloud Blog, "PyTorch/XLA: Performance debugging Part III."
-
Google Cloud Documentation, "Profile PyTorch XLA workloads," diakses Desember 2025, https://docs.cloud.google.com/tpu/docs/pytorch-xla-performance-profiling-tpu-vm.
-
TensorFlow Documentation, "Optimize TensorFlow performance using the Profiler."
-
TensorFlow Documentation, "Optimize TensorFlow performance using the Profiler."
-
Ko, "TPU Deep Dive."
-
Google Cloud Documentation, "Cloud TPU performance guide."
-
TensorFlow Documentation, "Optimize TensorFlow performance using the Profiler."
-
TensorFlow Documentation, "Optimize TensorFlow performance using the Profiler."
-
TensorFlow Documentation, "Optimize TensorFlow performance using the Profiler."
-
TrendForce, "Google Unveils 7th-Gen TPU Ironwood."
-
Tse, "Understanding the FP64, FP32, FP16, BFLOAT16, TF32, FP8 Formats."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."


