
Google的Tensor Processing Units为你日常接触的大多数前沿AI模型提供算力支撑,然而大部分工程师对其架构仍然令人惊讶地不熟悉。虽然NVIDIA GPU在开发者心智份额中占据主导地位,但TPU悄然训练和服务着Gemini 2.0、Claude以及数十种其他前沿模型,其规模足以让大多数使用传统GPU基础设施的组织破产。Anthropic最近承诺部署超过一百万颗TPU芯片——代表超过1吉瓦的计算容量——来训练未来的Claude模型。¹ Google最新的Ironwood代在9,216芯片超级集群中提供42.5 exaflops的FP8计算能力,这一规模重新定义了生产级AI基础设施的含义。²
TPU背后的技术复杂性远超简单的性能指标。这些处理器体现了与GPU根本不同的设计理念,以通用灵活性换取矩阵乘法和张量运算的极致专业化。理解TPU架构的工程师可以利用256×256脉动阵列,每周期处理65,536次乘加运算,利用第三代SparseCore加速器处理嵌入密集型工作负载,以及编程光学电路交换机,在10纳秒内重新配置多拍字节数据中心拓扑。³ 该架构涵盖了从晶体管级设计决策到建筑级超级计算机编排的各个层面。
接下来的技术内容需要仔细关注。我们将研究七代TPU演进历程,剖析脉动阵列数学原理和数据流模式,探索从SRAM瓦片到HBM3e通道的存储器层次结构,分析中间表示层面的XLA编译器优化,并调查为什么集体操作的执行速度比等效的基于Ethernet的GPU集群快10倍。⁴ 你将遇到寄存器级规格、周期精确的性能建模,以及使TPU同时比GPU更强大又更受约束的架构权衡。这里的深度内容服务于构建下一代AI基础设施的工程师和推动当前加速器能力边界的研究人员。
发展历程:七代架构创新
TPU v1:专用推理(2015年)
Google在2015年部署了第一代Tensor Processing Unit,旨在解决一个关键问题:神经网络推理工作负载可能会使公司的数据中心占地面积翻倍。⁵工程师专门为推理设计了TPU v1,完全去除了训练能力,以最大化已部署模型的性能和能效。该芯片采用256×256的8位整数乘累加单元脉动阵列,在仅28-40瓦的热设计功耗下实现92 teraops每秒的计算能力。⁶
该架构体现了极简主义的设计理念。单个矩阵乘法单元通过权重静止数据流处理INT8操作,权重在脉动阵列中保持固定,而激活值在网格中水平流动。部分和垂直传播,消除了整个矩阵乘法过程中的中间内存写入。该芯片通过PCIe连接到主机系统,依靠DDR3 DRAM作为外部内存,运行在700 MHz频率——为了能效而刻意保守的设计。⁷
性能提升甚至让Google的工程师感到惊讶。在生产推理工作负载中,TPU v1相比同期的CPU和GPU在每瓦操作数方面实现了30-80倍的改进。⁸该芯片处理Google搜索排名、每日处理10亿请求的翻译服务,以及为20亿用户提供的YouTube推荐。这一成功验证了核心架构洞察:针对窄工作负载优化的专用加速器可以比通用处理器实现数量级的改进。
TPU v2:大规模训练(2017年)
第二代将TPU从推理专用加速器转变为完整的训练平台。Google重新设计了整个架构,围绕浮点操作进行优化,将256×256 INT8阵列替换为每个核心的双128×128 bfloat16乘累加器。⁹每个芯片包含两个TensorCore,每个核心共享8GB High Bandwidth Memory,这是对DDR3的巨大升级,提供了神经网络训练所需的带宽。
Bfloat16精度对TPU v2的成功至关重要。该格式保持与FP32相同的8位指数范围,同时将尾数减少到7位,在训练时保持动态范围的同时将内存带宽需求减半。¹⁰工程师观察到,降低的尾数精度实际上通过充当正则化形式改善了许多模型的泛化能力,而完整的FP32指数范围防止了困扰FP16训练的下溢和上溢问题。
真正区别TPU v2的架构创新是Inter-Chip Interconnect (ICI)。以前的加速器需要以太网或InfiniBand进行多芯片通信,引入了延迟和带宽瓶颈。Google设计了定制的高速双向链路,将每个TPU直接连接到2D环形拓扑中的四个邻居。¹¹互连使多达256个芯片的TPU v2"pod"能够作为单个逻辑加速器运行,all-reduce等集体操作的执行速度远快于基于网络的替代方案。
TPU v3:水冷性能扩展(2018年)
Google在TPU v3中大幅提升了时钟速度和核心数量,每个芯片提供420 teraflops的计算能力——性能比v2提升了一倍多。¹²增加的功率密度迫使了一个重大的架构变化:液体冷却。每个TPU v3 pod都需要水冷基础设施,这与前几代和大多数数据中心加速器的风冷设计有所不同。¹³
该芯片保持了双128×128 MXU架构,但增加了核心总数并改善了内存带宽。每个TPU v3包含四个芯片,每个有两个核心,芯片间共享总计32GB的HBM内存。¹⁴向量处理单元在激活函数、归一化操作和梯度计算方面得到增强,这些操作经常成为仅依靠矩阵单元训练的瓶颈。
部署扩展到使用与v2相同的2D环形ICI拓扑的2,048芯片pod,但增加了每链路带宽。Google在v3 pod上训练越来越大的模型,发现环形拓扑减少的网络直径(任意两个芯片之间的最大距离按N/2而不是N扩展)最小化了数据并行和模型并行训练策略的通信开销。¹⁵
TPU v4:光电路交换突破(2021年)
第四代代表了Google自原始TPU以来最重大的架构飞跃。工程师将pod规模增加到4,096个芯片,同时引入了用于互连的光电路交换(OCS),这是一项从电信借鉴的技术,彻底改变了数据中心规模的ML基础设施。¹⁶
TPU v4的核心架构在每个TensorCore中配备了四个128×128 MXU,以及增强的向量和标量单元。每对TensorCore除了每核心向量内存外,还共享128MB的公共内存,实现了更复杂的数据暂存和重用模式。¹⁷芯片拓扑从2D演进为3D环形,将每个TPU连接到六个邻居而不是四个,进一步减少了网络直径并改善了二分带宽。
光电路交换系统彻底改变了大规模部署。Google部署了可编程光交换机,可以动态重新配置哪些芯片连接到哪些芯片,而不是TPU之间的固定布线。MEMS(微机电系统)镜子物理重定向光束,将任意TPU对连接在一起,除了光纤传输时间外几乎不引入延迟。¹⁸交换机在亚10纳秒窗口内重新配置,比大多数网络协议握手更快。
OCS架构实现了以前不可能的能力。Google可以通过适当编程光交换机来提供任何大小的"切片",从四个芯片到完整的4,096芯片pod。故障芯片可以无缝绕过而不会影响整个机架。最值得注意的是,不同数据中心位置的物理上遥远的TPU可以在网络拓扑中逻辑相邻,完全解耦物理和逻辑布局。¹⁹
TPU v4还引入了SparseCore,这是一个专门处理推荐系统、排名模型和具有大规模词汇嵌入的大语言模型中每天使用的嵌入操作的专用处理器。SparseCore每个芯片配备四个专用处理器,每个都有2.5MB的暂存内存和针对稀疏内存访问模式优化的数据流。²⁰具有超大嵌入的模型使用仅5%的总芯片芯片面积和功耗预算实现了5-7倍的加速。
TPU v5p和v5e:专业化和规模(2022-2023年)
Google将第五代分为两个针对不同用例的不同产品。TPU v5p优先考虑大规模训练的最大性能,而v5e针对成本效益的推理和较小的训练作业进行优化。²¹
TPU v5p在8,960芯片pod中实现了每秒约4.45 exaflops,比v4的最大pod规模增加了一倍多。²²互连带宽达到每芯片4,800 Gbps,3D环形拓扑在大规模16×20×28超级pod中连接芯片。光电路交换结构管理48个OCS单元中的13,824个光端口来连接完整的v5p超级pod,代表了计算历史上最大的生产光交换部署之一。²³
TPU v5e采用了不同的方法,降低核心数量和时钟速度以达到激进的功耗和成本目标。推理优化芯片每个芯片只包含一个TPU核心而不是两个,并返回到2D环形拓扑,这对较小的pod规模来说是足够的。²⁴架构简化使Google能够为绝对性能不如每美元性能重要的工作负载提供有竞争力的v5e定价。
TPU v6e Trillium:矩阵性能翻四倍(2024年)
Trillium通过将矩阵乘法单元从128×128扩展到256×256乘累加器标志着另一个架构拐点。²⁵更大的阵列在相同时钟速度下将每周期FLOPS翻了四倍,通过扩展的MXU和增加的时钟频率的结合,提供了比TPU v5e高4.7倍的峰值计算性能。
内存子系统获得了同样显著的升级。每芯片HBM容量翻倍至32GB,通过下一代HBM通道带宽也翻了一番。²⁶芯片间互连带宽同样翻倍,使256个Trillium芯片的pod能够为那些同时压力计算和通信的模型维持更高的吞吐量。²⁷
Trillium配备了第三代SparseCore加速器,在排名和推荐工作负载中对超大嵌入具有增强的能力。更新的设计改善了内存访问模式,并增加了SparseCores和HBM之间对于由嵌入查找而不是矩阵乘法主导的模型的充足带宽。²⁸
尽管性能大幅提升,能效比v5e提高了67%。²⁹Google通过先进制程节点、减少无用功的架构优化,以及在不同时压力芯片所有部分的操作期间对未使用单元的仔细功率门控来实现能效提升。
TPU v7 Ironwood:FP8时代(2025年)
Google的第七代TPU,代号Ironwood,是第一个设计原生FP8支持的TPU,专门针对"推理时代"进行优化,同时保持最先进的训练性能。³⁰每个Ironwood芯片提供4.6 petaFLOPS的密集FP8计算能力——略超过NVIDIA竞争对手B200的4.5 petaFLOPS——而热设计功耗为600W。³¹
内存系统扩展到每芯片192GB HBM3e内存,是Trillium容量的六倍,带宽达到7.4TB/s。³²巨大的内存增加使得能够服务以前需要跨多个加速器复杂张量并行的超大模型和键值缓存。Google专门设计了内存容量来支持新兴的多模态模型和接近百万token窗口的长上下文应用。
Ironwood的互连通过四个ICI链路提供9.6 Tbps的聚合双向带宽,转换为每芯片1.2 TB/s的峰值带宽。³³该架构从用于较小部署的256芯片pod扩展到提供42.5 FP8 exaflops计算能力的大规模9,216芯片超级pod。³⁴Google的Jupiter数据中心网络技术理论上可以在单个集群中支持多达43个Ironwood超级pod——大约400,000个加速器,代表了几乎难以想象的计算规模。³⁵
FP8支持代表了精度策略的根本转变。之前的TPU代数使用软件技术模拟8位操作,这引入了开销。Ironwood实现了原生FP8乘累加单元,支持E4M3(4位指数,3位尾数)和E5M2(5位指数,2位尾数)格式。³⁶双格式支持能够混合使用E4M3进行精度要求较低的前向传递和E5M2进行需要维持梯度幅度以防止训练不稳定的反向传递。
Anthropic承诺从2026年开始部署超过一百万个Ironwood芯片,展示了该架构的生产就绪性。该公司计划利用超过一千兆瓦的TPU容量——足以为一个小城市供电——专门用于训练和服务Claude模型。³⁷这一规模甚至超过了最重要的已知GPU部署,代表了对TPU架构用于前沿模型开发的根本押注。
当代产品快速参考
以下表格为2025年生产部署中最相关的三个当代TPU提供可扫描的规格:
表1:核心计算规格

表2:内存和带宽
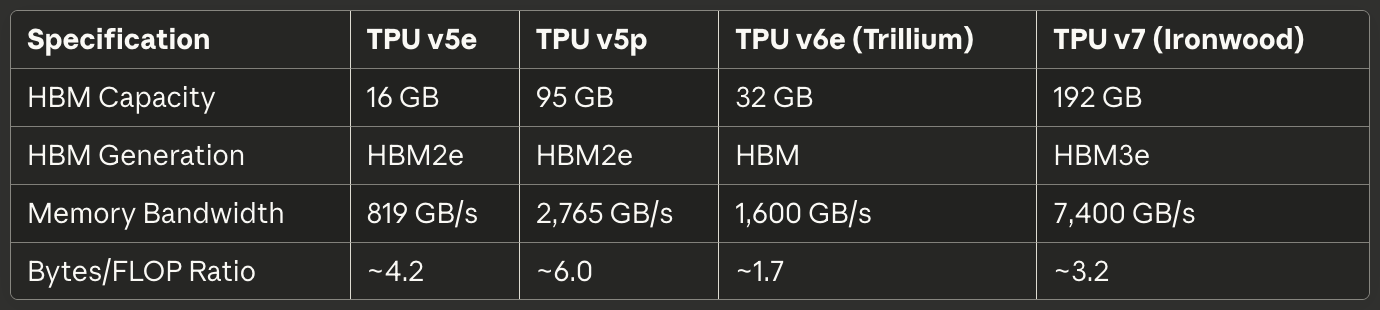
表3:互连和扩展
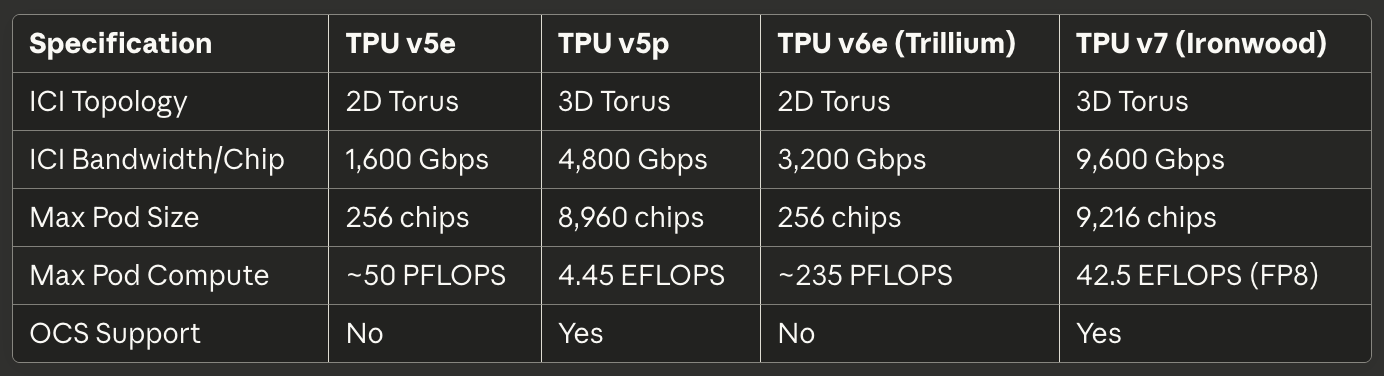
表4:功耗和效率

表5:推荐用例

硬件架构:深入硅芯片
脉动阵列数学和数据流
矩阵乘法单元构成了TPU架构的核心,理解脉动阵列需要掌握它们与GPU SIMD通道相比在并行性方面根本不同的方法。脉动阵列在网格中链接乘累加单元,其中数据有节奏地流经结构——因此称为"脉动",让人联想到心脏的节律性血液泵送。³⁸
考虑TPU v6e的256×256脉动阵列执行矩阵乘法C = A × B。工程师将矩阵B的权重预加载到排列在网格中的65,536个单独的乘累加单元中。矩阵A的激活值从左边缘进入并水平穿过阵列流动。每个MAC单元将其存储的权重与传入的激活相乘,将结果添加到从上方到达的部分和,并将激活(水平)和更新的部分和(垂直)传递给相邻单元。³⁹
数据流模式意味着每个激活值在穿越水平维度时被重用256次,每个部分和在垂直流动时累积来自256次乘法的贡献。关键的是,所有中间结果通过短导线直接在相邻MAC单元之间传递,而不是往返到内存。该架构每个时钟周期执行65,536次乘累加操作,在涉及潜在数百万次操作的整个矩阵乘法期间,零个中间值接触DRAM甚至片上SRAM。⁴⁰
权重静止数据流模式针对神经网络推理和训练中最常见的情况进行优化:用相同的权重矩阵重复乘以许多不同的激活矩阵。工程师加载一次权重,然后通过阵列流式传输无界限的激活批次而无需重新加载。该模式对卷积层、全连接层以及主导transformer模型的Q·K^T和attention·V操作效果特别好。⁴¹
能效源于数据重用和空间局部性。从DRAM读取一个值消耗的能量大约是单次乘累加操作的200倍。⁴²通过在不访问内存的情况下将每个权重重用256次,每个激活重用256次,脉动阵列实现了在计算单元和内存层次结构之间穿梭数据的架构无法实现的每瓦操作比率。
脉动阵列的弱点出现在动态或不规则的计算模式中。由于数据按固定时间表流经网格,该架构在条件执行、稀疏矩阵(除非使用SparseCore)和需要随机访问模式的操作方面存在困难。不灵活性以通用性换取在其目标工作负载上的极高效率:具有可预测访问模式的密集矩阵乘法。
TensorCore内部架构
每个TPU芯片包含一个或多个TensorCore——包含矩阵乘法单元、向量处理单元和标量单元协同工作的完整处理单元。⁴³TensorCore代表软件定位的基本构建块,理解其三个组件之间的交互解释了TPU性能特征和编程模式。
矩阵乘法单元在bfloat16或FP8输入上每周期执行16,000次乘累加操作,使用FP32累积。⁴⁴混合精度方法在累加器中保持数值精度,同时减少输入的内存带宽。工程师观察到,在累积期间保持完整的FP32精度可以防止在对数百或数千个中间乘积求和时出现灾难性抵消错误,而降低精度的输入很少影响最终模型质量。
向量处理单元处理不适合MXU刚性结构的操作。激活函数(ReLU、GELU、SiLU)、归一化层(批归一化、层归一化)、softmax、池化、dropout和逐元素操作在VPU的128通道SIMD架构上执行。⁴⁵VPU操作FP32和INT32数据类型,提供数值敏感操作(如softmax)所需的精度,其中指数和除法可能创建大的动态范围。
标量单元协调整个TensorCore。单线程处理器执行控制流,计算复杂索引模式的内存地址,并启动从高带宽内存到向量内存的DMA传输。⁴⁶由于标量单元单线程运行,每个TensorCore每周期只能创建一个DMA请求——这对于不能饱和MXU或VPU计算吞吐量的内存密集型操作来说是一个瓶颈。
为TensorCore提供数据的内存层次结构决定了可实现的性能,与原始计算能力同样重要。向量内存(VMEM)充当每个TensorCore专用的软件管理暂存SRAM,通常大小为数十兆字节。XLA编译器明确调度HBM和VMEM之间的数据移动,决定在快速本地内存中暂存什么以及何时将结果写回。⁴⁷
公共内存(CMEM)存在于TPU v4及更高代数中,提供所有芯片上TensorCore都可访问的更大共享池。TPU v4架构在两个TensorCore之间分配了128MB的CMEM,使得更复杂的生产者-消费者模式成为可能,其中一个核心的输出为另一个核心的输入提供数据,而无需往返到HBM。⁴⁸
编程模型的含义非常重要。由于标量单元单线程且向量内存需要显式管理,TPU编程更像1990年代的嵌入式系统开发而不是现代GPU编程。CUDA通过统一内存和硬件管理缓存抽象内存移动;TPU代码(无论是由XLA生成还是在Pallas中手写)必须明确协调每次数据传输。手动控制支持专家优化,但提高了胜任性能的门槛。
高带宽内存架构
现代TPU使用HBM(高带宽内存)或HBM3e,这是一种与CPU中的DDR SDRAM和许多GPU中使用的GDDR截然不同的内存技术。HBM使用硅通孔(TSV)垂直堆叠多个DRAM芯片,然后将堆叠直接放在硅中介层上的处理器芯片旁边。⁴⁹短电气路径和宽接口能够实现比传统内存技术显著更高的带宽。
TPU v7 Ironwood实现了192GB HBM3e,总带宽为7.4 TB/s。⁵⁰内存系统分为多个通道,每个通道提供对总容量独立部分的独立访问。XLA编译器和运行时必须仔细在HBM通道间分区张量,以最大化并行访问并避免一个通道饱和而其他通道闲置的热点。
内存接口宽度远超传统DRAM。DDR5通道可能提供64位宽度,而HBM通道通常跨越1,024位。⁵¹极端宽度在相对适度的时钟速度下实现高带宽,与将窄接口推到多千兆赫频率相比,降低了功耗和信号完整性挑战。
延迟特性与GPU内存系统有很大不同。TPU除了小的本地缓冲区外缺乏硬件管理缓存,因此该架构依赖软件在计算单元需要数据之前明确将数据暂存到VMEM中。缺乏缓存意味着内存延迟直接影响性能,除非编译器通过预取和双缓冲成功隐藏延迟。⁵²
内存容量限制在许多工作负载中比计算吞吐量更重要。一个1750亿参数的模型使用bfloat16权重需要350GB来存储参数——甚至在考虑激活、优化器状态或梯度缓冲区之前就已经超过了Ironwood的192GB HBM。训练此类模型需要复杂的技术,如梯度检查点、跨多芯片的优化器状态分片,以及仔细调度参数更新以最小化内存占用。⁵³
TPU运行时强制执行特定的张量布局要求以最大化MXU效率。由于脉动阵列以128×8瓦片处理数据,张量应该对齐到这些维度以避免填充浪费。⁵⁴大小不当的矩阵迫使硬件处理部分瓦片,MAC处于空闲状态,直接降低FLOPS利用率。编译器尝试自动填充和重塑张量,但在模型架构中有意识的布局选择可以大幅改善性能。
SparseCore:专用嵌入加速
虽然矩阵乘法单元在密集矩阵操作方面表现出色,但嵌入密集型工作负载表现出截然不同的特征。推荐模型、排名系统和大语言模型经常通过不规则的、数据依赖的索引访问大规模嵌入表(通常数百GB)。MXU的结构化数据流对这些稀疏内存访问模式没有优势,这促使了SparseCore专用架构的出现。⁵⁵
SparseCore实现了与MXU脉动阵列根本不同的瓦片化数据流处理器。TPU v4每芯片配备四个SparseCore,每个包含16个计算瓦片。⁵⁶每个瓦片作为具有本地暂存内存(SPMEM)和处理元件的独立数据流单元运行。瓦片并行执行,同时处理嵌入操作的不相交子集。
内存层次结构将热数据放在小而快的SPMEM中,同时将完整的嵌入表保持在HBM中。XLA编译器分析嵌入访问模式以确定哪些嵌入向量值得在SPMEM中缓存,哪些从HBM按需获取。⁵⁷该策略类似于传统CPU缓存层次结构,但由软件而不是硬件做出放置决策。
SparseCore直接连接到HBM通道,完全绕过TensorCore的内存路径。专用连接防止嵌入操作与密集矩阵操作竞争内存带宽,使两者能够并行进行。⁵⁸这种分区对于像深度学习推荐模型(DLRM)这样交替进行密集神经网络层和大规模嵌入查找的模型效果特别好。
模块分片策略通过计算target_sc_id = col_id % num_total_sparse_cores在SparseCores间分布嵌入。⁵⁹简单的分片函数在嵌入ID均匀分布时确保负载均衡,但对于倾斜的访问模式可能会产生热点。使用真实世界数据的工程师通常需要分析嵌入频率分布并手动重新平衡分片以避免瓶颈。
SparseCore的性能提升与在MXU和VPU上实现相同操作相比达到5-7倍,同时仅消耗5%的芯片芯片面积和功耗。⁶⁰显著的效率优势源于为稀疏操作专门构建数据流,而不是强制它们通过密集矩阵基础设施。专门化原理在TPU架构中递归应用:正如TPU专门化超越了GPU的通用设计,SparseCore专门化超越了TPU的矩阵导向设计。
Trillium的第三代SparseCore引入了可变SIMD宽度(FP32为8个元素,bfloat16为16个)和改进的内存访问模式,减少了未对齐读取造成的带宽浪费。⁶¹架构演进展示了Google对嵌入加速的持续投资,因为大语言模型趋向于更大的词汇表和更复杂的检索增强生成模式。
互连技术:超级计算机的布线
芯片间互连(ICI)架构
芯片间互连是使TPU能够作为统一超级计算机而非孤立加速器运行的关键技术。与通过以太网或InfiniBand网络通信的GPU不同,ICI实现了定制高速串行链路,直接连接相邻的TPU,具有微秒级延迟和每秒太比特级带宽。⁶²
跨TPU代际的拓扑演进反映了pod扩展的变化需求。TPU v2、v3、v5e和v6e实现了二维环形拓扑,其中每个芯片连接到四个最近的邻居(北、南、东、西)。⁶³ 链路在边界处环绕,创建甜甜圈形的逻辑拓扑,消除了连接较少的边缘芯片。因此,256个TPU的16×16网格无论哪两个芯片通信,都提供统一的带宽和延迟特性。
TPU v4和v5p升级到三维环形拓扑,每个芯片连接到六个邻居。⁶⁴ 额外的维度将网络直径(任意两个芯片之间的最大跳数)从大约2√N减少到3∛N。对于4,096芯片的pod,最大跳数从约128下降到48,大幅降低了全局同步操作(如all-reduce)的最坏情况通信延迟。
环形结构提供了另一个关键优势:无论工作负载如何跨芯片分配,都有相等的二分带宽。任何将环形分成两半的切割都会穿过相同数量的链路,防止因作业放置不当而造成网络瓶颈的病态情况。⁶⁵ 统一的二分带宽简化了调度,并实现了下文讨论的光电路交换机可重构性。
带宽规格在各代中显著扩展。TPU v6e每芯片提供13 TB/s的ICI带宽。⁶⁶ TPU v5p通过六个3D环形链路每芯片达到4,800 Gbps。⁶⁷ Ironwood实现四个ICI链路,聚合双向带宽为9.6 Tbps,转换为每芯片1.2 TB/s。⁶⁸ 相比之下,顶级400GbE网络接口提供50GB/s双向带宽——比现代TPU ICI低一个数量级。
机架内的链路技术使用直连铜缆(DAC)进行同一4×4×4立方体内芯片间的短距离连接。⁶⁹ 铜缆连接在为紧密耦合芯片执行同步操作提供所需带宽的同时,最大限度地降低了成本和功耗。立方体间和pod规模的链路过渡到光收发器,以更高的成本和功耗换取跨越数据中心机架所需的距离和带宽。
集合操作利用了ICI的独特特性。All-reduce、all-gather和reduce-scatter操作在训练期间频繁同步跨芯片的激活值和梯度。在基于以太网的GPU集群上,这些集合操作通过带有交换机、线缆和网络接口卡的分层网络传输,在每一跳引入延迟。TPU ICI直接在硬件中实现优化的集合算法,执行all-reduce操作比等效的基于以太网的GPU实现快10倍。⁷⁰
光电路交换:动态拓扑重构
Google在TPU v4中部署光电路交换(OCS)代表了数十年来数据中心网络领域最重要的创新之一。传统的分组交换网络——无论是以太网还是InfiniBand——通过逐跳路由数据包建立逻辑连接,交换机检查报头并转发到适当的输出端口。OCS使用可编程光学元件在端点之间创建直接的物理光路径,完全消除了交换延迟。⁷¹
核心技术依赖于物理旋转以重定向光束的MEMS(微机电系统)镜。TPU A上的发射器将光发送到OCS。OCS内的微型镜旋转以将光束反射到TPU B上的接收器。连接成为从A到B的直接光路径,除了光通过光纤传播外,基本上没有额外延迟。⁷²
重构速度决定了OCS在生产系统中的实用性。Google的部署实现了亚10纳秒的交换时间——比典型的网络协议往返时间更快。⁷³ 重构速度使动态拓扑变化能够匹配工作负载需求,而无需中断运行中的作业或需要精心协调的流量工程。
TPU v5p展示了大规模的OCS。该架构使用光电路交换机,在交换结构中提供每秒四拍比特的聚合带宽。⁷⁴ 单个v5p superpod需要48个OCS单元管理13,824个光端口,以在16×20×28三维环形配置中连接8,960个芯片。⁷⁵ 该交换系统代表了任何计算环境中最大的光网络部署之一。
OCS提供了传统网络无法实现的能力。物理拓扑和逻辑拓扑完全解耦——如果OCS创建直接光路径,数据中心相对两角的两个TPU看起来像相邻邻居。通过重新编程镜子来排除故障组件并维护逻辑环形结构,可以绕过故障芯片或链路。新作业通过编程OCS创建适当的pod配置而无需物理重新布线机架,从而接收任何大小的"切片"。⁷⁶
该架构与Google的Jupiter数据中心网络集成,以扩展超出单个pod。Jupiter使用Google的定制硅交换机和控制平面在整个数据中心提供每秒多拍比特的二分带宽。⁷⁷ 多个TPU superpod通过Jupiter结构连接,如果网络容量允许,理论上支持多达400,000个加速器的集群。⁷⁸
功耗和可靠性特性有利于TPU规模部署的光电路交换。传统分组交换机在太比特每秒速率下处理和转发数据包消耗大量功率。OCS交换机仅在重构事件期间消耗功率来操作MEMS镜,然后空闲,在连接保持稳定时以最小损耗传递光。⁷⁹ 该架构的简单性通过消除易出错和性能异常的复杂数据包处理和缓冲逻辑提高了可靠性。
Pod架构和扩展特性
TPU pod代表通过ICI连接的TPU的最大单一单元,形成统一的加速器。物理结构从单个芯片到托盘到立方体到机架到完整pod分层构建。⁸⁰ 理解层次结构对于推理不同规模的内存容量、通信带宽和容错性很重要。
基本构建块由单个托盘上的四个芯片组成,通过PCIe连接到主机CPU。⁸¹ PCIe连接处理控制平面操作、初始程序加载以及训练数据和推理结果的输入/输出。分布式训练的实际芯片间通信通过ICI而非PCIe流动,避免了PCIe带宽瓶颈。
16个托盘(64个芯片)形成单个4×4×4立方体——pod构建的基本单元。在立方体内,由于芯片位于同一机架内物理距离较短,所有ICI连接都使用直连铜缆。⁸² 立方体实现完整的带环绕连接的3D环形,创建可以理论上独立运行的自包含64芯片单元。
TPU v4 pod扩展到64个立方体,总计4,096个芯片。⁸³ 立方体间连接过渡到由光电路交换结构管理的光链路。OCS可以将这4,096个芯片配置为单个巨大的pod、多个较小的独立pod,或在需要时动态重新配置任务中。这种灵活性使数据中心运营商能够在不同的作业大小和优先级之间平衡利用率。
TPU v5p将pod规模推至16×20×28三维环形中的8,960个芯片。⁸⁴ 特定维度反映了仔细的带宽和直径优化——质因数分解对网络拓扑很重要!该pod提供4.45 exaflops的计算力,代表生产中部署的最大单pod配置之一。
Ironwood支持用于较小部署的256芯片pod和用于大规模前沿模型训练的9,216芯片superpod。⁸⁵ 9,216芯片配置提供42.5 FP8 exaflops——比仅仅五年前整个Top500超级计算机列表包含的计算力还多。⁸⁶ 这种规模重新定义了组织通过同步训练而非流水线或异步方法能够实现的目标。
扩展效率决定了更大的pod是否真正有帮助。随着pod大小的增加,通信开销增加,因为芯片花费更多时间同步而非计算。Google Research发布的结果表明,对于特定工作负载,32,768个TPU实现95%的扩展效率,意味着32,768个TPU提供了完美线性扩展预测性能的95%。⁸⁷ 效率源于硬件加速集合、优化编译器变换和减少梯度同步频率的巧妙算法方法。
pod规模的容错需要复杂的处理。统计概率保证在任何具有数千个连续运行芯片的系统中都会出现组件故障。光电路交换机通过围绕故障组件重新配置实现优雅降级。训练检查点定期进行(通常每隔几分钟),因此作业故障只需要从最后一个检查点而不是从头重新启动。⁸⁸
软件栈:编译器、框架和编程模型
XLA编译器:优化计算图
XLA(Accelerated Linear Algebra)构成了TPU软件栈的基础,将高级框架操作编译为优化的机器代码在TPU上执行。⁸⁹ 该编译器实施了通用编译器无法实现的激进优化,因为它利用了关于机器学习工作负载和TPU架构特性的领域知识。
融合是XLA最具影响力的优化。编译器分析计算图以识别可以在不物化中间张量的情况下执行的操作序列。一个简单的例子:像relu(batch_norm(conv(x)))这样的逐元素操作通常需要将卷积输出写入内存,读取用于批量归一化,将该结果写入内存,然后再次读取用于ReLU。XLA将这些操作融合为单个内核,产生最终ReLU输出而无需中间内存流量。⁹⁰
融合的影响随着TPU架构而扩大。内存带宽比计算吞吐量更多地约束许多工作负载——MXU执行矩阵乘法的速度比内存系统向其提供数据的速度更快。通过融合消除中间内存写入和读取直接转化为性能改进,通常为激活函数密集的网络提供2倍或更多的加速。⁹¹
内存布局转换针对硬件要求优化张量存储。神经网络通常以NHWC格式(批次、高度、宽度、通道)表示张量以便直观索引,但TPU MXU在与128×8块对齐的布局下表现最佳。⁹² XLA自动转置、重塑和填充张量以匹配硬件偏好,仅在必要时插入布局转换,有时通过图向后传播首选布局以最小化总转换开销。
编译器实现了复杂的常量折叠和死代码消除。ML图经常包含输出仅依赖于常量的子图——批量归一化参数、推理丢弃率和可以执行一次而不是每批次执行的形状计算。XLA在编译时评估这些子图并用常量张量替换它们,减少运行时工作。⁹³
跨副本优化利用关于分布式执行的知识。当跨多个TPU核心训练时,某些操作(如批量归一化统计)需要跨所有副本聚合。XLA识别这些模式并生成优化的集合操作,利用ICI的硬件加速全规约而不是通过显式消息传递实现聚合。⁹⁴
编译器专门针对TPU的中间表示Mosaic。Mosaic在比汇编语言更高但比输入计算图更低的抽象级别上操作。该语言暴露了TPU架构特性,如脉动阵列、向量内存和VMEM暂存,同时隐藏了低级细节,如指令调度和寄存器分配。⁹⁵
自动调优能力通过经验搜索选择最佳块大小和操作参数。XLA自动调优(XTAT)系统尝试不同的融合策略、内存布局和块维度,分析每个变体的性能,并选择最快的配置。⁹⁶ 对于复杂模型,搜索可能需要大量编译时间,但通过发现人类很少手动识别的反直觉优化来产生显著的运行时加速。
JAX:可组合变换和SPMD
JAX为数值计算提供了NumPy兼容的接口,具有自动微分、JIT编译到XLA和对程序变换的一流支持。⁹⁷ 该框架的函数式编程范式和可组合变换模型与TPU执行模型和分布式并行模式自然对齐。
核心JAX抽象将数学变换应用于函数。grad(f)计算f的梯度。jit(f)将f JIT编译到XLA。vmap(f)在新维度上向量化f。关键是,变换可组合:jit(grad(vmap(f)))完全按预期工作,编译向量化梯度函数。⁹⁸ 组合模型能够从简单、可测试的组件构建复杂的分布式训练循环。
SPMD(单程序多数据)表示JAX的分布式执行模型。程序员编写代码就像针对单个设备一样,然后添加分片注释指示如何跨多个TPU核心分区张量。XLA编译器和GSPMD(通用SPMD)子系统自动插入通信操作以在跨分布式设备执行时维护程序语义。⁹⁹
分片注释使用PartitionSpec声明分布策略。PartitionSpec('batch', None)将张量的第一个维度跨设备网格的'batch'轴分片,同时复制第二个维度。PartitionSpec(None, 'model')通过分区第二个维度实现张量并行。注释可以与任意张量级别和设备网格维度组合。¹⁰⁰
GSPMD的自动并行化消除了大量样板代码。传统的分布式训练需要在需要完整张量的操作之前手动插入all-gather,在计算分布式梯度之后插入reduce-scatter,以及为全局归约插入all-reduce。GSPMD分析分片规范并自动插入适当的集合操作,使程序员能够专注于算法而不是通信工程。¹⁰¹
编译器使用约束求解通过计算图传播分片决策。如果操作A输出被操作B消费的分片张量,GSPMD基于输出如何被使用推断B的最优分片,可能仅在数学上必要时插入重分片操作。¹⁰² 自动推理防止了困扰手写分布式代码的"分片意大利面条"。
当自动化不足时,JAX提供细粒度控制。with_sharding_constraint在图位置强制特定分片,覆盖自动推理。自定义PJIT(并行JIT)注释为性能关键代码路径指定精确的设备放置和分片策略。分层模型通过自动分片实现快速原型设计,同时在需要时支持专家优化。¹⁰³
Shardy在2025年作为GSPMD的继任者出现,实现了改进的约束传播算法和对动态形状的更好处理。¹⁰⁴ 新系统通过在更大的图区域而不是逐操作地联合推理分片选择来暴露额外的优化机会。
PyTorch/XLA:将PyTorch带到TPU
PyTorch/XLA能够在TPU上运行PyTorch模型,只需最小的代码更改,在PyTorch的命令式编程模型和XLA的基于图的编译之间建立桥梁。¹⁰⁵ 该集成在保持PyTorch开发者体验和暴露TPU特定优化之间取得平衡。
基本挑战源于PyTorch的急切执行理念。PyTorch在Python语句执行时立即执行操作,支持使用标准工具进行调试和自然的控制流。XLA需要在编译前捕获完整的计算图,在急切执行和图编译的性能优势之间产生张力。¹⁰⁶
PyTorch/XLA 2.4引入了急切模式支持,解决了阻抗不匹配。该实现动态跟踪PyTorch操作到XLA图中,允许开发者编写标准PyTorch代码同时仍然受益于XLA编译。¹⁰⁷ 该模式为开发速度和调试简单性牺牲了一些编译优化机会。
图模式仍然是生产部署的主要路径。开发者使用装饰器或编译API显式标记函数进行XLA编译。显式注释实现激进优化,但需要理解哪些操作应该融合到单个XLA图中而不是独立执行。¹⁰⁸
Pallas集成为PyTorch/XLA带来了自定义内核开发。当XLA的自动融合不足或专门操作需要手工优化时,Pallas提供了编写TPU内核的低级语言。¹⁰⁹ 该语言暴露TPU内存层次结构(VMEM、CMEM、HBM)和计算单元(MXU、VPU),同时保持比原始汇编更高的级别。
内置Pallas内核实现性能关键操作,如FlashAttention和PagedAttention。FlashAttention的分块注意力计算将序列长度n的内存带宽要求从O(n²)减少到O(n),使模型能够在固定内存预算内处理更长的序列。¹¹⁰ PagedAttention为服务优化键值缓存管理,与填充实现相比实现了5倍加速。¹¹¹
PyTorch/XLA桥对于vLLM TPU——一个最初为GPU设计的高性能服务框架——至关重要。该实现实际上甚至为PyTorch模型使用JAX作为中间降级路径,利用JAX卓越的并行支持同时保持PyTorch前端兼容性。¹¹² 该架构在2025年相比初始原型实现了2-5倍的性能改进。
尽管有改进,模型兼容性挑战仍然存在。一些PyTorch操作缺乏XLA等价物,强制回退到降低性能的CPU执行。动态控制流在图编译中支持较差,通常需要架构更改以用静态、可编译的替代方案替换动态行为。PyTorch/XLA存储库记录兼容性并为常见问题模式提供迁移指南。¹¹³
精度格式:BFloat16、FP8和量化
TPU对降低精度算术的支持在保持可接受模型质量的同时实现了显著的性能和内存改进。理解不同格式的数值特性以及何时应用每种格式对于实现最佳性能至关重要。¹¹⁴
BFloat16代表了Google在降低精度训练上的早期投注,首次出现在TPU v2中。该格式保持FP32的8位指数同时将尾数截断为7位(加符号位)。¹¹⁵ 完整的指数范围防止了困扰早期FP16训练的下溢和上溢,其中梯度经常逃脱FP16的可表示范围。
缩减的尾数引入量化误差,但很少影响最终模型质量。工程师观察到在bfloat16中训练的模型通常在统计噪声范围内匹配FP32训练的基线,可能因为量化充当了一种正则化形式,防止对微小数值细节的过拟合。¹¹⁶ 该格式相比FP32将内存带宽和容量需求减半,直接转化为内存受限工作负载的性能提升。
FP8进一步降低精度,将权重和激活压缩到8位。存在两种标准编码:E4M3(4位指数,3位尾数)优先考虑前向传递的精度,而E5M2(5位指数,2位尾数)优先考虑反向传递的范围,其中梯度幅度变化很大。¹¹⁷ Ironwood为两种格式实现原生FP8支持,而早期TPU通过软件变换模拟FP8。¹¹⁸
训练期间的量化感知实现了FP8的数值成功。从头开始用FP8训练或用FP8感知技术微调的模型学习能够容忍该格式有限精度的权重分布。训练后量化(在训练后将FP32模型转换为FP8)在没有仔细校准的情况下经常降低质量。¹¹⁹
INT8量化提供了更大的内存节省和推理加速。Google的准确量化训练(AQT)在TPU上实现INT8训练,相比bfloat16基线质量损失最小。¹²⁰ 该技术从头开始应用量化感知训练,允许模型在学习期间适应INT8的约束,而不是通过训练后近似。
混合精度策略战略性地组合格式。前向传递可能对激活和权重使用FP8,反向传递对梯度使用FP8 E5M2或bfloat16,优化器状态保持FP32以在权重更新期间保持数值稳定性。¹²¹ 混合方法平衡速度、内存和准确性,通常实现FP32质量的90%+同时运行速度快4倍。
精度权衡超出速度和内存,包括数值稳定性考虑。批量归一化、层归一化和softmax在降低精度中需要仔细的数值处理。softmax中的大指数可能溢出FP8或bfloat16范围;在指数化之前减去最大logit防止溢出同时保持数学等价性。¹²² XLA编译器在安全时自动实现这些转换,但自定义操作有时需要手动数值工程。
编程模型和并行化策略
SPMD和自动分区
Single Program, Multiple Data (SPMD) 范式从根本上改变了程序员对TPU执行的思考方式。开发者无需编写显式的消息传递代码来协调多个进程,而是编写单个程序并标注数据应如何在设备间分区。¹²³编译器处理分布、通信和同步的机制细节。
GSPMD (General SPMD) 在XLA中实现了自动分区逻辑。该系统分析tensor分片标注和计算图结构,确定操作在哪些设备上执行以及维持正确语义需要什么通信。¹²⁴这种自动化消除了手写分布式代码中常见的整类bug——tensor形状不匹配、集合操作顺序错误,以及不当同步造成的死锁。
编译器的约束传播引擎从最少的标注推断分片决策。通常只需标注模型的输入和输出分片;GSPMD通过中间操作传播约束并自动选择高效的分布。¹²⁵当某个操作存在多个有效分片时,编译器估算替代方案的通信成本并选择最低成本选项。
高级优化将通信与计算重叠。在副本间同步梯度的all-reduce操作可以在第一层梯度完成后立即开始,与后续层的反向传播并行执行。¹²⁶编译器自动调度集合操作以最大化重叠,与串行执行相比可将适当的通信时间减少2倍或更多。
重新材料化以计算换内存。编译器不储存所有前向传播激活值用于梯度计算,而是在内存压力超过阈值时在反向传播过程中选择性重新计算激活值。¹²⁷这种权衡在TPU上特别有效,因为计算往往超过内存带宽,使得重新计算比内存流量更便宜。
数据并行、Tensor并行和流水线并行
数据并行是最直接的分布式训练策略:在N个设备上复制完整模型,在每个副本上处理不同的数据批次。在本地计算梯度后,all-reduce聚合跨副本的梯度,所有设备应用相同的权重更新。¹²⁸该方法线性扩展直到通信时间主导计算时间——通常在以太网络环境下约1,000个GPU,但在ICI环境下可达10,000+个TPU。¹²⁹
Tensor并行(也称为模型并行)将单个操作分区到多个设备。矩阵乘法Y = W @ X将权重矩阵W分布到各设备,每个设备计算输出的一部分。¹³⁰该策略通过分布参数存储和计算,使训练超过单设备内存的模型成为可能。
Tensor并行的通信模式与数据并行显著不同。Tensor并行不是在每层后进行all-reduce,而是在需要完整tensor的操作前进行all-gather,在分布式计算后进行reduce-scatter。¹³¹通信量随模型激活大小而非参数大小扩展,产生与数据并行不同的瓶颈。
流水线并行将连续的模型层分区到不同设备,同时在不同阶段处理不同的微批次。GPipe引入了该策略,通过精心调度在限制内存使用的同时最大化流水线利用率。¹³²每个设备处理一个微批次的前向传播,将激活值发送到下一阶段,然后处理下一个微批次——创建一个在初始启动后所有设备持续工作的流水线。
梯度过时性使流水线并行复杂化。设备使用可能早于数十个微批次计算的激活值产生的梯度来更新权重,产生可能损害收敛性的过时性。¹³³像PipeDream这样的复杂调度算法在保持高吞吐量的同时最小化过时性,经验结果表明大多数模型在适度过时性下不会出现质量下降。
3D并行结合所有三种策略。数据并行在"数据"维度分布,tensor并行在"模型"维度分布,流水线并行在"流水线"维度分布。¹³⁴基于模型架构、硬件拓扑和通信成本精心平衡各维度可最大化吞吐量。GPT-3规模的模型通常使用3D并行,数据并行跨8-16个副本,tensor并行跨4-8个GPU,流水线并行跨4-16个阶段。
分片策略和优化
选择分片策略需要理解数学操作及其数据依赖性。矩阵乘法C = A @ B允许多种有效分片:复制A和B并计算部分结果(计算前通信),按列分片B并收集结果(计算后通信),或按行分片A、按列分片B且无通信但设备矩阵更小。¹³⁵
集合操作成本决定最优策略。All-reduce成本随tensor大小线性扩展,但使用基于树或基于环的归约算法随设备数量次线性扩展:¹³⁶All-gather和reduce-scatter表现出不同的扩展特性。编译器建模这些成本并选择最小化总通信时间的分片策略。
序列并行在大型语言模型中至关重要。注意力机制产生内存瓶颈,因为key-value缓存随序列长度和批次大小增长。沿序列维度分区将内存负担分布到各设备,同时仅在注意力计算本身引入通信。¹³⁷
专家并行处理Mixture-of-Experts (MoE)模型,其中不同专家处理不同token。分片策略在所有设备上复制共享层但分区专家,将每个token路由到其指定的专家设备。¹³⁸动态路由创建不规则通信模式,挑战传统集合操作,需要复杂的运行时系统来最小化延迟和负载不平衡。
优化器状态分片减少大型模型的内存开销。像Adam这样的优化器为每个参数存储动量和方差统计,使内存需求超过仅参数需求的三倍。在保持参数复制的同时跨设备分片优化器状态,使得在固定内存预算内训练更大模型成为可能。¹³⁹该策略在权重计算期间需要收集优化器状态更新,但显著减少每设备内存占用。
性能分析与基准测试
MLPerf结果与竞争定位
MLPerf提供行业标准基准测试,衡量AI加速器在训练和推理工作负载中的性能表现。Google定期提交TPU结果,展现出有竞争力的性能,各代产品的演进显示出明显的架构改进。¹⁴⁰
TPU v5e在MLPerf的9个训练类别中有8个取得了领先成绩。¹⁴¹这种广泛性展示了架构的多功能性,不仅仅局限于大语言模型——在计算机视觉、推荐系统和科学计算工作负载中都表现出竞争力。BERT训练速度比NVIDIA A100 GPU快2.8倍,验证了transformer优化架构的有效性。¹⁴²
2025年6月发布的MLPerf Training v5.0引入了Llama 3.1 405B基准测试,这是该测试套件中最大的模型。¹⁴³该基准测试比以往测试更注重多节点扩展、通信开销和内存容量。Google Cloud参与了TPU提交,但详细的性能比较仍处于保密阶段,等待官方结果发布。
MLPerf Inference v5.0包含了四个新基准测试:Llama 3.1 405B、用于低延迟应用的Llama 2 70B、RGAT图神经网络,以及用于3D目标检测的PointPainting。¹⁴⁴这种多样性推动加速器超越传统transformer工作负载,进入架构假设可能不同的新兴应用领域。
推理基准测试特别有利于发挥TPU的架构优势。批量推理工作负载充分利用了MXU的大规模并行性,在transformer服务中实现了比竞争加速器高4倍的吞吐量。¹⁴⁵单查询延迟受益于TPU的确定性执行和无热节流特性,提供一致的延迟,避免了一些GPU部署中困扰的性能波动。
能效指标显示TPU的优势在各代产品中不断扩大。TPU v4相比TPU v3展现出2.7倍的每瓦性能提升,Trillium相比v5e提升了67%。¹⁴⁶Ironwood声称相比Trillium具有2倍的每瓦性能提升,尽管绝对性能显著更高。¹⁴⁷效率提升在千芯片pod中复合增长,转化为数据中心运营成本的数百万美元节省。
实际训练和推理性能
生产工作负载揭示了合成基准测试中不存在的性能特征。Google发布了来自内部服务的结果,展示了TPU在实际使用模式和扩展要求下的行为。¹⁴⁸
ResNet-50 ImageNet训练在TPU pod上28分钟完成,这是计算机视觉工作负载性能的广泛引用基准。¹⁴⁹时间精度指标捕获了完整的训练过程,包括数据加载、增强、分布式梯度同步和检查点保存——不仅仅是理论FLOPS。
T5-3B语言模型训练展示了TPU在transformer架构上的优势。这个30亿参数模型在TPU pod上训练12小时,相比之下在等效GPU配置上需要31小时。¹⁵⁰2.6倍的加速来自硬件加速注意力操作、高效的内存带宽利用和优化的集合通信。
GPT-3规模工作负载(1750亿参数)在TPU上比同时代GPU实现1.7倍更快的时间精度。¹⁵¹对于更大的模型,性能差距进一步扩大,此时内存容量和带宽成为关键约束。Ironwood的192GB HBM3e能够服务那些在低内存替代方案上需要复杂张量并行的模型。
扩展效率测量展示了在巨大规模下接近线性的加速。Google Research报告称,对于特定transformer训练工作负载,32,768个TPU的扩展效率达到95%。¹⁵²该指标意味着32,768个TPU提供了完美线性扩展所预测性能的95%——考虑到通信开销随规模增加,这是非常出色的表现。
FLOPS利用率指标揭示了工作负载如何有效地利用可用计算资源。Transformer模型在TPU上通常达到90%的FLOPS利用率,意味着90%的理论峰值性能被转化为实际工作。¹⁵³高利用率源于操作融合消除了内存瓶颈、在大矩阵乘法中的脉动阵列效率,以及最小化浪费周期的编译器优化。
生产推理服务展示了每天数十亿查询的持续性能。Google Translate每天在TPU上处理10亿次请求。¹⁵⁴YouTube推荐使用TPU加速模型为20亿用户提供服务。¹⁵⁵Google Photos每月分析280亿张图像用于搜索和组织功能。¹⁵⁶这种运营规模验证了超越研究原型部署的可靠性和成本效益。
能效和总体拥有成本
功耗直接影响数据中心运营成本和环境可持续性。TPU各代产品的能效改进降低了大规模运营费用和碳排放。¹⁵⁷
TPU v4在生产工作负载中平均功耗仅为200W,尽管TDP规格为250W。¹⁵⁸平均功耗与峰值功耗之间的余量使得灵活的热设计和配置成为可能。对比GPU,持续工作负载经常达到TDP限制,需要保守的机架功率预算。
Ironwood的600W TDP相比之前几代产品代表了更高的绝对功耗,但每瓦提供的计算性能显著提升。¹⁵⁹每芯片4.6 PFLOPS FP8性能产生约7.7 TFLOPS每瓦——在等效工作负载上与当代GPU效率竞争或超越。
数据中心电源使用效率(PUE)放大了芯片级效率。Google的TPU数据中心实现了1.1的PUE,意味着除芯片消耗外,冷却、电源转换和网络的功率开销仅为10%。¹⁶⁰行业平均PUE范围从1.5到2.0,其中50-100%的额外功率用于基础设施开销。低PUE源于先进的冷却系统、高效的电力传输和专门针对ML工作负载优化的数据中心设计。
碳强度考虑超越了功率,还包括能源来源。Google通过可再生能源采购和碳抵消计划在碳中和电力上运营TPU数据中心。¹⁶¹碳核算对于跟踪云计算范围2排放的组织来说越来越重要。
总体拥有成本(TCO)分析必须考虑采购成本、功耗、冷却需求和维护费用。TPU部署相比等效GPU安装通常显示20-30%的TCO降低,主要由卓越的每瓦性能和降低的冷却复杂性驱动。¹⁶²
冷却基础设施成本随功率密度非线性扩展。风冷机架通常在需要特殊冷却解决方案之前上限为每机架15-20kW。高功率GPU推动这些限制,有时需要液体冷却基础设施,资本和运营成本大幅增加。TPU的效率使更多部署保持在风冷范围内,简化了数据中心设计。¹⁶³
技术优势:TPU的突出表现
硬件加速集合操作
TPU ICI中的专用集合操作支持提供了相比传统网络加速器的最重要优势之一。all-reduce作为跨分布式训练同步梯度的核心操作,在TPU ICI上的执行速度比同等基于Ethernet的GPU实现快10倍。¹⁶⁴
性能差距源于架构集成。基于Ethernet的集合操作需要遍历多个层级:应用程序代码调用集合库(NCCL、Horovod等),生成数据包交给网络栈,网络栈将数据传输到NIC,在网线上序列化,遍历交换机,在接收NIC处反序列化,然后逆向执行这个过程。每一层都增加延迟,在内存层次结构中复制数据,并消耗CPU周期进行协议处理。¹⁶⁵
TPU ICI在硬件中实现集合操作而无需遍历软件层。操作直接从TensorCore启动,通过专用ICI链路流式传输数据,完成时不涉及主机CPU。直接的硬件路径消除了传统实现中占主导地位的开销。¹⁶⁶
光学电路交换拓扑结构实现了最优的集合算法。基于环的all-reduce对N个设备只需要2(N-1)条消息,而环形拓扑提供最短路径路由,最小化延迟。¹⁶⁷ 统一的对分带宽防止了路由不当的集合操作阻塞网络链路的热点问题。
统一内存空间和简化编程
TPU的统一内存模型相比GPU的复杂内存层次结构简化了编程。程序员只需考虑单个HBM池,而不是管理主机RAM、GPU全局内存、共享内存和寄存器文件之间的传输。简化的模型减少了错误并提高了开发效率。¹⁶⁸
内存碎片不再是问题。GPU从碎片化堆中分配内存,随着时间推移的分配和释放会创建需要压缩的空洞。TPU通过编译器的静态分析进行内存管理,完全避免了运行时碎片化——张量根据计算图被分配到预定位置。¹⁶⁹
编程模型消除了整类CUDA错误。不再有因指针算术错误导致的"非法内存访问",不再有CPU和GPU之间的缓存一致性错误,不再有因缺少cudaDeviceSynchronize()调用导致的同步错误。更高级的抽象防止了CUDA编程中的常见陷阱。¹⁷⁰
确定性执行和可重现性
浮点数的非结合性在并行计算中带来可重现性挑战。表达式(a + b) + c可能与a + (b + c)由于舍入错误产生不同结果,并行归约可能因竞态条件在不同运行中以不同顺序求和。¹⁷¹
TPU执行比典型GPU实现展现出更强的确定性。脉动阵列的固定数据流模式确保跨运行的相同操作顺序。集合操作遵循确定性归约树,而不是基于到达顺序的机会性聚合。这种可预测性实现了可重现训练,相同的超参数和数据产生位级相同的模型权重。¹⁷²
调试从确定性中获得巨大益处。非确定性训练使得定位故障根因几乎不可能——NaN是来自真正的算法错误还是随机竞态条件?确定性执行意味着故障可靠地重现,实现系统性调试方法。¹⁷³
科学计算应用特别重视可重现性。气候模型、药物发现仿真和物理研究需要可验证的结果,允许不同研究人员重现相同结果。TPU的确定性比竞争的非确定性替代方案更好地支持科学方法。¹⁷⁴
编译器优化和开发者生产力
XLA的激进优化无需手动调优即可"开箱即用"地提供大幅性能改进。研究人员报告仅通过编译相比急切执行框架就实现了40%的模型吞吐量改进。¹⁷⁵ 这种性能是免费的——无需内核工程。
融合优化特别有利于开发者。在CUDA中手动融合操作需要编写自定义内核,测试正确性,并在框架版本间维护代码。XLA自动融合操作并更新,随着模型演进调整融合策略,消除了维护负担。¹⁷⁶
布局变换自动化节省了数周的手动优化。为GPU确定最优张量布局需要分析不同排列,手动插入转置,并仔细管理内存分配模式。XLA自动尝试布局并选择最快的,释放开发者专注于模型架构而非底层性能工程。¹⁷⁷
生产力提升对研究团队产生复合效应。节省的基础设施优化时间加速科学进展,实现更多实验和更快迭代周期。组织报告从GPU CUDA编程转向TPU基于JAX的工作流时开发效率提升3倍。¹⁷⁸
## 技术限制和劣势
平台锁定和本地部署限制
TPU 只能通过 Google Cloud Platform 访问,无法进行本地部署,引发了供应商锁定担忧。¹⁷⁹ 对于有数据主权要求、隔离网络或禁止使用公有云政策的组织,无论技术优势如何,都无法利用 TPU。
随着 AI 成为关键基础设施,这种限制变得越来越重要。对单一云服务提供商的依赖会产生业务连续性风险——定价变化、可用性中断或服务停用都可能导致昂贵的迁移成本。¹⁸⁰ GPU 可从多个供应商获得(NVIDIA 硬件可在 AWS、Azure、GCP 和本地运行),这种可选性是 TPU 架构上无法提供的。
多云策略面临阻力。标准化使用 TPU 的组织无法轻易扩展到其他云平台或实施多云冗余,必须重新训练模型或为不同的加速器架构维护独立的代码库。¹⁸¹ 混合 GPU/TPU 部署的运维复杂性往往超过了最优加速器选择带来的成本节省。
CUDA 生态系统成熟度差距
NVIDIA 的 CUDA 平台经过 15+ 年的生态系统开发,积累了大量库、文档和社区知识,这是 TPU 无法匹敌的。¹⁸² 成熟度差距在 TPU 采用过程中表现为众多痛点。
库的可用性压倒性地偏向 CUDA。计算机图形学、分子动力学、计算流体力学和基因组学等专业领域在过去几十年中积累了数千个 CUDA 优化库。TPU 等效库往往不存在,需要回退到 CPU(这会破坏性能)或花费数月时间进行移植。¹⁸³
社区支持相差几个数量级。Stack Overflow 包含数十万个 CUDA 问题和详细答案——GitHub 仓库数量达到数百万。会议演讲、学术论文和博客文章主要关注 CUDA 编程。TPU 程序员面临相对稀少的资源、更长的调试周期和更少的专家咨询。¹⁸⁴
教育材料和教程压倒性地针对 CUDA。大学课程使用 CUDA 教授 GPU 编程。在线课程专注于 CUDA。人才培养管道产生的 CUDA 经验工程师远多于 TPU 专家,造成招聘和培训挑战。¹⁸⁵
自定义内核开发体现了生态系统差距。编写优化的 CUDA 内核仍然不简单,但受益于广泛的文档、分析工具和示例代码。Pallas 支持自定义 TPU 内核,但工具链不够成熟,知识库较小。学习曲线阻止了除最关键性能优化之外的所有应用。¹⁸⁶
工作负载专业化和灵活性约束
TPU 的架构针对特定工作负载模式进行优化——主要是具有规则访问模式和大批量大小的稠密矩阵乘法。超出最佳范围的操作会遇到性能悬崖。¹⁸⁷
动态形状挑战 TPU 执行模型。XLA 编译器假设固定张量维度以进行优化和代码生成。具有可变序列长度、动态控制流或数据依赖形状的模型需要填充到最大尺寸(浪费计算和内存)或为每个不同形状重新编译(破坏性能)。¹⁸⁸
尽管有 SparseCore,稀疏操作的支持仍然有限。稀疏矩阵-矩阵乘法是科学计算和图神经网络中常见的工作负载,在 MXU 或 VPU 上缺乏高效实现。专用的 SparseCore 处理嵌入表,但不处理通用稀疏线性代数。¹⁸⁹
小批量推理未充分利用 TPU 的并行资源。256×256 脉动阵列在能够用高效工作填满网格的大矩阵上表现出色。单查询推理使大部分 MAC 空闲,导致每查询延迟和成本比针对低批量场景优化的 GPU 替代方案更差。¹⁹⁰
不规则计算模式削弱脉动阵列效率。具有不可预测分支、递归结构或指针追踪内存访问的算法在 TPU 上表现不佳,因为固定数据流无法适应运行时依赖行为。¹⁹¹
非 ML 工作负载很少从 TPU 加速中受益。科学模拟、视频编码、区块链验证和渲染在 GPU 的更通用架构上运行更快,尽管 TPU 在矩阵操作上具有更高的峰值 FLOPs。¹⁹²
调试和开发工具差距
NVIDIA 的生态系统包括成熟的分析工具(Nsight Systems、Nsight Compute、nvprof)、调试器(cuda-gdb)和经过数十年完善的分析框架。TPU 工具确实存在,但在复杂性方面显著落后。¹⁹³
XProf 通过 TensorBoard 集成提供基本分析,但缺乏 NVIDIA 工具暴露的细粒度硬件计数器访问。理解缓存缺失率、占用率、warp 分歧或内存库冲突——所有关键 GPU 优化指标——在 TPU 上没有等效项,因为架构根本不同。¹⁹⁴
错误消息经常掩盖根本原因。XLA 编译失败产生关于形状不匹配或不支持操作的难懂消息,没有明确的解决指导。CUDA 错误虽然因无用而臭名昭著,但受益于十五年的 StackOverflow 解释和部落知识。¹⁹⁵
在多芯片 pod 上调试分布式训练在没有专用工具的情况下几乎不可能。竞态条件、梯度同步错误和集体操作失败表现为非确定性错误(讽刺的是,尽管 TPU 有确定性优势),不一致地重现并抵制系统诊断。¹⁹⁶
对于复杂模型,迭代循环延长得令人痛苦。形状更改或架构修改的重新编译可能需要几分钟,在编译器运转时冻结开发。CUDA 的急切执行模型尽管峰值性能较低,但能够实现更快的迭代。¹⁹⁷
真实部署案例:大规模生产应用
Anthropic Claude:多平台战略
Anthropic在2025年10月宣布部署超过一百万个TPU芯片,这代表了历史上最大的公开披露的AI加速器承诺。¹⁹⁸ 该公司计划在2026年专门用于训练和服务未来Claude模型的计算能力将超过一千兆瓦。
这个规模在数量级上超越了以往的部署。一百万个芯片,配置为Ironwood TPU,将提供大约4.6 exaflops的FP8计算能力——比仅仅五年前整个Top500超级计算机榜单的总性能高出40倍以上。¹⁹⁹ 这一承诺表明了对TPU架构在前沿模型开发中的信心,其规模在以前被认为是科幻小说。
Anthropic采用了深思熟虑的多平台硬件战略,涵盖Google的TPU、Amazon的Trainium和NVIDIA GPU。²⁰⁰ 这种多样化提供了容量保险、定价杠杆和地理分布。Claude通过在所有三个平台上的部署为全球提供服务,请求路由基于容量可用性和区域延迟要求。
该公司2025年8月的技术事后分析揭示了大规模部署的复杂性。Claude API TPU服务器上的配置错误导致了token生成错误,偶尔会在英文提示中为泰文或中文字符分配异常高的概率。²⁰¹ 这一事件表明,即使是简单的错误也会在日处理数十亿token的系统中产生不可预测的连锁反应。
另一个部署触发了XLA: TPU编译器中影响Claude Haiku 3.5的潜在bug。这个bug已经存在数月未被发现,直到特定的模型架构和编译器标志组合暴露了这个缺陷。²⁰² 这一发现强调了生产部署会发现开发和测试环境中不存在的边角案例。
Anthropic工程师将TPU的性价比和效率作为主要选择标准。令人信服的经济性通过在固定预算内实现更大规模的实验来加速开发。²⁰³ 训练更大的模型、探索更多的超参数配置和更快的迭代都源于降低每FLOP成本。
Google Gemini:从设计之初就针对TPU
Google的Gemini模型专门在TPU上训练和服务,其架构和训练过程从一开始就是为TPU特性协同设计的。²⁰⁴ 这种紧密耦合使得能够利用跨平台模型无法使用的TPU特定优化。
据报告,Gemini部署使用50,000个TPU v6e芯片来训练和服务最重要的模型变体。²⁰⁵ 如此庞大的pod规模需要复杂的编排——跨数千个芯片的作业调度、防止瓶颈的检查点协调、最小化工作损失的故障恢复,以及识别故障传播前的降级节点的实时监控。
Google在Trillium TPU上训练了Gemini 2.0,验证了第六代架构在前沿模型开发中的有效性。²⁰⁶ 这次训练运行展示了扩展到前所未有芯片数量的效率,在通信开销占主导地位的典型瓶颈之外实现了强大的扩展。
模型服务基础设施专门利用TPU推理优化。批处理聚合多个用户请求以最大化MXU利用率。键值缓存管理利用HBM容量,实现长期上下文处理而无需磁盘交换。该架构在处理大规模全球请求量的同时,为复杂查询提供亚秒级响应时间。²⁰⁷
生产监控系统持续跟踪50,000多个TPU,检测可能降低模型质量或可用性的异常。²⁰⁸ 遥测数据捕获每个芯片的错误率、延迟百分位数、吞吐量、内存压力和热特性。机器学习模型分析遥测流本身,在故障发生前预测故障并触发预防性维护。
其他生产部署案例
Midjourney从GPU迁移到TPU基础设施,在图像生成工作负载中实现了65%的成本降低和40%的延迟改善。²⁰⁹ 这项艺术生成服务在峰值负载时每分钟处理300,000张图像,需要大规模计算吞吐量和在突发流量模式下的一致性能。
Cohere在TPU上的语言模型实现了比之前GPU部署3倍的吞吐量。²¹⁰ 这种加速使得能够在相同的基础设施占用空间内为更多客户提供服务,直接改善了业务经济性。该公司利用JAX的SPMD功能在TPU pod间高效并行化模型。
Snap获得了10,000个TPU v6e芯片的容量,支持增强现实功能、推荐系统和创意AI工具。²¹¹ 该部署跨越多个地理区域,确保为Snapchat全球用户群提供低延迟,同时保持跨区域的模型一致性。
学术机构越来越多地采用TPU进行研究。TPU Research Cloud (TRC)项目为研究人员提供免费的TPU访问,使得以前只有资金充足的企业实验室才能达到的规模的实验成为可能。²¹² 这种民主化通过消除学者研究AI能力和局限性基本问题的硬件障碍来加速科学进步。
调试、性能分析和性能优化
XProf 和 TensorBoard 集成
XProf 是 TPU 工作负载的主要性能分析工具,为跨 CPU、GPU 和 TPU 的 JAX、PyTorch/XLA 和 TensorFlow 程序提供性能分析。²¹³ 该工具与 TensorBoard 集成用于可视化,通过 ML 工程师已经熟悉的界面呈现性能分析数据。
安装需要 TensorBoard 插件:pip install tensorboard_plugin_profile tensorboard。这样可以启用完整的工具链。²¹⁴ 在 TPU VM 上运行性能分析包括在训练或推理期间捕获跟踪、将结果上传到 TensorBoard,以及分析可视化结果来识别瓶颈。
Overview Page 提供高级性能摘要指标,包括步骤时间分解、设备利用率和顶级瓶颈识别。²¹⁵ 该页面立即突出显示工作负载是计算受限(MXU 持续运行)、内存受限(等待 HBM 传输)还是通信受限(在集合操作上阻塞)。
Trace Viewer 和时间线分析
Trace Viewer 显示详细的时间线可视化,准确显示操作执行时间、数据传输发生时间以及空闲时间累积位置。²¹⁶ 基于 Chrome 的界面支持缩放到微秒分辨率,揭示聚合指标掩盖的精确调度行为。
理解跟踪需要识别常见模式。操作间的长间隙表示编译开销、数据加载瓶颈或由于数据管道优化不当导致的 Python 开销。重复的小操作表明融合不足。跨越毫秒的集合操作指向通信效率低下或分片策略不当。²¹⁷
颜色编码区分操作类型:绿色表示计算,蓝色表示内存传输,橙色表示通信,红色表示空闲时间。优化的工作负载显示密集排列的彩色块,红色间隙最小。优化不良的代码表现为稀疏时间线,长红色段表示资源浪费。²¹⁸
高级用法涉及将时间线行为与源代码关联。PyTorch/XLA 支持在代码中插入用户注释,这些注释出现在跟踪中,使性能行为映射到特定模型组件成为可能。²¹⁹ 注释将不透明的跟踪转换为关于哪些层或操作需要优化焦点的可操作见解。
Memory Profile Tool 和 OOM 调试
内存不足(OOM)错误困扰着大模型开发。Memory Profile Tool 在执行期间监控设备内存使用,捕获导致 OOM 失败的峰值利用率和分配模式。²²⁰
该工具可视化随时间变化的内存消耗,显示哪些张量消耗最多容量以及峰值使用何时发生。可视化通常揭示令人惊讶的分配——比预期更大的梯度缓冲区、应该检查点的激活内存,或 XLA 未能消除的临时张量。²²¹
调试策略涉及通过多种技术迭代减少内存占用。梯度检查点在反向传播期间重新计算激活而不是存储它们。优化器状态分片将 Adam 动量和方差分布到各个设备。混合精度相比 FP32 减少 2× 内存。微批次处理顺序处理更小的批次而不是一个大批次。²²²
高级内存优化需要理解编译器决策。xla_dump_to 标志导出中间表示,显示 XLA 如何转换计算图。分析 IR 揭示融合是否成功、不必要的复制发生在哪里,以及哪些操作分配的内存超出预期。²²³
Input Pipeline Analyzer
CPU 预处理经常成为 TPU 训练的瓶颈。Input Pipeline Analyzer 识别数据加载是否跟上加速器消耗的步伐,或者 TPU 是否因等待批次而空闲。²²⁴
该工具将主机端分析(CPU 预处理、数据增强、批次装配)与设备端执行(实际 TPU 计算)分开。输入受限的工作负载显示在数据加载期间设备利用率下降,而 CPU 利用率达到峰值。计算受限的工作负载保持高设备利用率,CPU 轻松跟上步伐。²²⁵
优化策略取决于瓶颈位置。慢速主机预处理受益于将数据加载并行化到更多 CPU 核心、减少每样本增强复杂性,或在消耗前预取批次。设备端瓶颈需要改变模型架构、更好的融合或分片调整,而不是数据管道调优。²²⁶
## Tensor处理单元的未来
Google的七代架构演进展现了专用AI加速器的持续创新。Ironwood的FP8支持、大规模内存容量和9,216芯片超级集群扩展展示了未来发展的轨迹。²²⁷
精度降低可能会继续朝着FP4甚至更低的特定操作发展。新兴研究表明,许多神经网络操作通过精心的训练程序能够容忍极端量化。未来的TPU可能会实现混合精度系统,采用FP4前向传播、FP8反向传播和FP32优化器更新。²²⁸
内存容量与模型规模增长之间的竞赛持续进行。当前的前沿模型已经让加速器内存承受压力,需要复杂的并行策略。下一代TPU可能会集成3D XPoint或阻变RAM等非易失性内存技术,在不消耗DRAM功耗的情况下实现TB级片上内存。²²⁹
光学互连可能会从电路交换扩展到包含光学计算元件。研究探索以光速执行的光子矩阵乘法,功耗极低,有可能用光学协处理器增强电子脉动阵列来执行特定操作。²³⁰
稀疏性支持可能会从嵌入扩展到通用稀疏线性代数。神经网络剪枝技术证明,90%以上的权重可以被置零而不损失质量。未来的架构可能会原生地跳过零值计算,而不是显式计算然后丢弃它们。²³¹
TPU成功的架构原则——领域专门化、定制互连、协同设计的软件栈和建筑级编排——指向了日益专门化的加速器的未来。我们可能会看到针对训练与推理、卷积网络与transformer、密集与稀疏模型、短序列与长序列优化的加速器,而不是万能处理器。²³²
当今构建AI基础设施的工程师应该深入理解TPU架构。无论是在Google Cloud上部署、在加速器市场与Google竞争,还是设计下一代ML系统,TPU中体现的设计原则和权衡揭示了AI工作负载对硬件需求的基本真理。脉动阵列数学、内存层次设计、互连拓扑和编译器优化策略代表了数十年积累的智慧,适用范围远超TPU本身。
定义TPU与GPU之间专门化与通用性的张力将无限期持续。TPU为了在狭窄工作负载上的极致效率而牺牲灵活性。GPU为了更广泛的适用性而牺牲峰值效率。两种方法都没有占据主导地位——最优选择完全取决于工作负载特性、规模、成本约束和运营要求。在大规模AI方面取得成功的组织越来越多地采用异构策略,将加速器架构与工作负载需求匹配,而不是标准化为单一平台。
Anthropic对TPU的百万芯片承诺表明该架构已在最高规模上达到生产成熟度。2026年即将上线的多千兆瓦部署将训练推动AI能力边界的模型,而支撑这些模型的基础设施体现了少数组织能够匹敌的工程复杂性。对于任何认真对待AI未来的人来说,理解脉动阵列中65,536个乘累加单元如何协作训练前沿模型都很重要。
参考文献
-
Google Cloud Press Corner,"Anthropic to Expand Use of Google Cloud TPUs and Services",2025年10月23日,https://www.googlecloudpresscorner.com/2025-10-23-Anthropic-to-Expand-Use-of-Google-Cloud-TPUs-and-Services。
-
TrendForce,"Google Unveils 7th-Gen TPU Ironwood with 9,216-Chip Superpod, Taking Aim at NVIDIA",2025年11月7日,https://www.trendforce.com/news/2025/11/07/news-google-unveils-7th-gen-tpu-ironwood-with-9216-chip-superpod-taking-aim-at-nvidia/。
-
Norman P. Jouppi等,"TPU v4: An Optically Reconfigurable Supercomputer for Machine Learning with Hardware Support for Embeddings",载于第50届国际计算机架构年会论文集(2023年),arXiv:2304.01433。
-
Anthropic,"Expanding our use of Google Cloud TPUs and Services",Anthropic新闻,2025年10月,https://www.anthropic.com/news/expanding-our-use-of-google-cloud-tpus-and-services。
-
Google Cloud Blog,"Quantifying the performance of the TPU, our first machine learning chip",2017年4月,https://cloud.google.com/blog/products/gcp/quantifying-the-performance-of-the-tpu-our-first-machine-learning-chip。
-
Norman P. Jouppi等,"In-Datacenter Performance Analysis of a Tensor Processing Unit",第44届国际计算机架构年会论文集(2017年),arXiv:1704.04760。
-
Jouppi等,"In-Datacenter Performance Analysis"。
-
Jouppi等,"In-Datacenter Performance Analysis"。
-
Jonathan Hui,"AI Chips: Google TPU",Medium,2025年12月访问,https://jonathan-hui.medium.com/ai-chips-tpu-3fa0b2451a2d。
-
Wikipedia,"Bfloat16 floating-point format",2025年12月访问,https://en.wikipedia.org/wiki/Bfloat16_floating-point_format。
-
Henry Ko,"TPU Deep Dive",个人博客,2025年12月访问,https://henryhmko.github.io/posts/tpu/tpu.html。
-
Wikipedia,"Tensor Processing Unit",2025年12月访问,https://en.wikipedia.org/wiki/Tensor_Processing_Unit。
-
Wikipedia,"Tensor Processing Unit"。
-
Wikipedia,"Tensor Processing Unit"。
-
Ko,"TPU Deep Dive"。
-
Jouppi等,"TPU v4: An Optically Reconfigurable Supercomputer"。
-
Jouppi等,"TPU v4: An Optically Reconfigurable Supercomputer"。
-
Jouppi等,"TPU v4: An Optically Reconfigurable Supercomputer"。
-
Jouppi等,"TPU v4: An Optically Reconfigurable Supercomputer"。
-
OpenXLA Project,"A deep dive into SparseCore for Large Embedding Models (LEM)",2025年12月访问,https://openxla.org/xla/sparsecore。
-
JAX Scaling Guide,"How to Think About TPUs",2025年12月访问,https://jax-ml.github.io/scaling-book/tpus/。
-
JAX Scaling Guide,"How to Think About TPUs"。
-
Ko,"TPU Deep Dive"。
-
JAX Scaling Guide,"How to Think About TPUs"。
-
Google Cloud Blog,"Introducing Trillium, sixth-generation TPUs",2024年5月,https://cloud.google.com/blog/products/compute/introducing-trillium-6th-gen-tpus。
-
Google Cloud Blog,"Introducing Trillium"。
-
Google Cloud Blog,"Introducing Trillium"。
-
Google Cloud Blog,"Introducing Trillium"。
-
Google Cloud Blog,"Introducing Trillium"。
-
Google Blog,"Ironwood: The first Google TPU for the age of inference",2025年11月,https://blog.google/products/google-cloud/ironwood-tpu-age-of-inference/。
-
XPU.pub,"Google Adds FP8 to Ironwood TPU; Can It Beat Blackwell?",2025年4月16日,https://xpu.pub/2025/04/16/google-ironwood/。
-
TrendForce,"Google Unveils 7th-Gen TPU Ironwood"。
-
The Register,"Google's 7th-gen Ironwood TPUs promise 42 AI exaFLOPS pods",2025年4月10日,https://www.theregister.com/2025/04/10/googles_7thgen_ironwood_tpus_debut/。
-
TrendForce,"Google Unveils 7th-Gen TPU Ironwood"。
-
Ko,"TPU Deep Dive"。
-
XPU.pub,"Google Adds FP8 to Ironwood TPU"。
-
Google Cloud Press Corner,"Anthropic to Expand Use"。
-
Telesens,"Understanding Matrix Multiplication on a Weight-Stationary Systolic Architecture",2018年7月30日,https://telesens.co/2018/07/30/systolic-architectures/。
-
Telesens,"Understanding Matrix Multiplication"。
-
Jouppi等,"In-Datacenter Performance Analysis"。
-
Telesens,"Understanding Matrix Multiplication"。
-
CP Lu,"Should We All Embrace Systolic Arrays?",Medium,2025年12月访问,https://cplu.medium.com/should-we-all-embrace-systolic-array-df3830f193dc。
-
Google Cloud文档,"TPU architecture",2025年12月访问,https://docs.cloud.google.com/tpu/docs/system-architecture-tpu-vm。
-
Google Cloud文档,"TPU architecture"。
-
Hui,"AI Chips: Google TPU"。
-
Telnyx,"Architecture insights: MXU and TPU components",2025年12月访问,https://telnyx.com/learn-ai/mxu-tpu。
-
Ko,"TPU Deep Dive"。
-
Jouppi等,"TPU v4: An Optically Reconfigurable Supercomputer"。
-
SemiEngineering,"Tensor Processing Unit (TPU)",2025年12月访问,https://semiengineering.com/knowledge_centers/integrated-circuit/ic-types/processors/tensor-processing-unit-tpu/。
-
TrendForce,"Google Unveils 7th-Gen TPU Ironwood"。
-
SemiEngineering,"Tensor Processing Unit (TPU)"。
-
Ko,"TPU Deep Dive"。
-
Ko,"TPU Deep Dive"。
-
Google Cloud文档,"Cloud TPU performance guide",2025年12月访问,https://cloud.google.com/tpu/docs/performance-guide。
-
OpenXLA Project,"A deep dive into SparseCore"。
-
OpenXLA Project,"A deep dive into SparseCore"。
-
OpenXLA Project,"A deep dive into SparseCore"。
-
Jouppi等,"TPU v4: An Optically Reconfigurable Supercomputer"。
-
OpenXLA Project,"A deep dive into SparseCore"。
-
Jouppi等,"TPU v4: An Optically Reconfigurable Supercomputer"。
-
OpenXLA Project,"A deep dive into SparseCore"。
-
JAX Scaling Guide,"How to Think About TPUs"。
-
JAX Scaling Guide,"How to Think About TPUs"。
-
JAX Scaling Guide,"How to Think About TPUs"。
-
Ko,"TPU Deep Dive"。
-
JAX Scaling Guide,"How to Think About TPUs"。
-
JAX Scaling Guide,"How to Think About TPUs"。
-
TrendForce,"Google Unveils 7th-Gen TPU Ironwood"。
-
Ko,"TPU Deep Dive"。
-
Anthropic,"Expanding our use of Google Cloud TPUs"。
-
Jouppi等,"TPU v4: An Optically Reconfigurable Supercomputer"。
-
Jouppi等,"TPU v4: An Optically Reconfigurable Supercomputer"。
-
Jouppi等,"TPU v4: An Optically Reconfigurable Supercomputer"。
-
Jouppi等,"TPU v4: An Optically Reconfigurable Supercomputer"。
-
Ko,"TPU Deep Dive"。
-
Jouppi等,"TPU v4: An Optically Reconfigurable Supercomputer"。
-
Leon Poutievski,"Mission Apollo: Landing Optical Circuit Switching at Datacenter Scale",LinkedIn,2022年6月,https://www.linkedin.com/posts/leon-poutievski-8910a851_mission-apollo-landing-optical-circuit-switching-activity-6968472071534235649-cB4l。
-
Ko,"TPU Deep Dive"。
-
Jouppi等,"TPU v4: An Optically Reconfigurable Supercomputer"。
-
Ko,"TPU Deep Dive"。
-
Ko,"TPU Deep Dive"。
-
Ko,"TPU Deep Dive"。
-
Jouppi等,"TPU v4: An Optically Reconfigurable Supercomputer"。
-
JAX Scaling Guide,"How to Think About TPUs"。
-
TrendForce,"Google Unveils 7th-Gen TPU Ironwood"。
-
TrendForce,"Google Unveils 7th-Gen TPU Ironwood"。
-
Ko,"TPU Deep Dive"。
-
Ko,"TPU Deep Dive"。
-
OpenXLA Project,"XLA: Optimizing Compiler for Machine Learning",2025年12月访问,https://openxla.org/xla。
-
Daniel Snider和Ruofan Liang,"Operator Fusion in XLA: Analysis and Evaluation",学术论文,2025年12月访问,https://danielsnider.ca/papers/Operator_Fusion_in_XLA_Analysis_and_Evaluation.pdf。
-
Snider和Liang,"Operator Fusion in XLA"。
-
APXML,"Memory-Aware Data Layout Transformations (NCHW/NHWC)",2025年12月访问,https://apxml.com/courses/compiler-runtime-optimization-ml/chapter-3-advanced-graph-level-optimizations/memory-aware-layout-transformations。
-
OpenXLA Project,"XLA"。
-
PyTorch文档,"Pytorch/XLA Overview",2025年12月访问,https://docs.pytorch.org/xla/master/learn/xla-overview.html。
-
OpenXLA Project,"A deep dive into SparseCore"。
-
Mangpo Phothilimthana等,"A Flexible Approach to Autotuning Multi-Pass Machine Learning Compilers",PACT 2021,2025年12月访问,https://mangpo.net/papers/xla-autotuning-pact2021.pdf。
-
JAX文档,"Introduction to parallel programming",2025年12月访问,https://docs.jax.dev/en/latest/sharded-computation.html。
-
GitHub,"jax-ml/jax: Composable transformations of Python+NumPy programs",2025年12月访问,https://github.com/jax-ml/jax。
-
OpenXLA Project,"Shardy Guide for JAX Users",2025年12月访问,https://openxla.org/shardy/getting_started_jax。
-
JAX文档,"Introduction to parallel programming"。
-
OpenXLA Project,"Shardy Guide for JAX Users"。
-
OpenXLA Project,"Shardy Guide for JAX Users"。
-
JAX文档,"Introduction to parallel programming"。
-
OpenXLA Project,"Shardy Guide for JAX Users"。
-
PyTorch文档,"Pytorch/XLA Overview"。
-
GitHub,"RFC: Evolving PyTorch/XLA for a more native experience on TPU",Issue #9684,2025年12月访问,https://github.com/pytorch/xla/issues/9684。
-
Google Cloud Blog,"PyTorch/XLA 2.4 improves Pallas and adds 'eager mode,'",2025年12月访问,https://cloud.google.com/blog/products/ai-machine-learning/pytorch-xla-2-4-improves-pallas-and-adds-eager-mode/。
-
PyTorch文档,"Pytorch/XLA Overview"。
-
PyTorch文档,"Custom Kernels via Pallas",2025年12月访问,https://docs.pytorch.org/xla/master/features/pallas.html。
-
PyTorch文档,"Custom Kernels via Pallas"。
-
PyTorch文档,"Custom Kernels via Pallas"。
-
vLLM Blog,"vLLM TPU: A New Unified Backend Supporting PyTorch and JAX on TPU",2025年10月16日,https://blog.vllm.ai/2025/10/16/vllm-tpu.html。
-
GitHub,"pytorch/xla",2025年12月访问,https://github.com/pytorch/xla。
-
StackGpu,"FP8, BF16, and INT8: How Low-Precision Formats Are Revolutionizing Deep Learning Throughput",Medium,2025年12月访问,https://medium.com/@StackGpu/fp8-bf16-and-int8-how-low-precision-formats-are-revolutionizing-deep-learning-throughput-e6c1f3adabc2。
-
Wikipedia,"Bfloat16 floating-point format"。
-
Wikipedia,"Bfloat16 floating-point format"。
-
Paulius Micikevicius等,"FP8 Formats for Deep Learning",arXiv:2209.05433,2022年9月。
-
XPU.pub,"Google Adds FP8 to Ironwood TPU"。
-
Micikevicius等,"FP8 Formats for Deep Learning"。
-
Google Cloud Blog,"Accurate Quantized Training (AQT) for TPU v5e",2025年12月访问,https://cloud.google.com/blog/products/compute/accurate-quantized-training-aqt-for-tpu-v5e。
-
StackGpu,"FP8, BF16, and INT8"。
-
Jeffrey Tse,"Understanding the FP64, FP32, FP16, BFLOAT16, TF32, FP8 Formats",个人博客,2024年12月9日,https://jeffreytse.net/computer/2024/12/09/understanding-the-fp64-fp32-fp16-bfloat16-tf32-fp8-formats.html。
-
PyTorch Blog,"PyTorch/XLA SPMD: Scale Up Model Training and Serving with Automatic Parallelization",2025年12月访问,https://pytorch.org/blog/pytorch-xla-spmd/。
-
OpenXLA Project,"Shardy Guide for JAX Users"。
-
JAX文档,"Introduction to parallel programming"。
-
OpenXLA Project,"Shardy Guide for JAX Users"。
-
Ko,"TPU Deep Dive"。
-
JAX文档,"Introduction to parallel programming"。
-
Anthropic,"Expanding our use of Google Cloud TPUs"。
-
JAX文档,"Introduction to parallel programming"。
-
JAX文档,"Introduction to parallel programming"。
-
Adam Roberts等,"Scaling Up Models and Data with t5x and seqio",arXiv:2203.17189,2022年3月。
-
Roberts等,"Scaling Up Models and Data"。
-
JAX文档,"Introduction to parallel programming"。
-
JAX文档,"Introduction to parallel programming"。
-
OpenXLA Project,"Shardy Guide for JAX Users"。
-
Roberts等,"Scaling Up Models and Data"。
-
Roberts等,"Scaling Up Models and Data"。
-
Ko,"TPU Deep Dive"。
-
MLCommons,"Benchmark MLPerf Training",2025年12月访问,https://mlcommons.org/benchmarks/training/。
-
Ko,"TPU Deep Dive"。
-
Ko,"TPU Deep Dive"。
-
HPCwire,"MLPerf Training v5.0 Benchmark Results Reflect Rapid Growth in the Field of AI",2025年6月,https://www.hpcwire.com/off-the-wire/mlperf-training-v5-0-benchmark-results-reflect-rapid-growth-in-the-field-of-ai/。
-
MLCommons,"MLCommons Releases New MLPerf Inference v5.0 Benchmark Results",2025年4月,https://mlcommons.org/2025/04/mlperf-inference-v5-0-results/。
-
Ko,"TPU Deep Dive"。
-
Google Cloud Blog,"TPU v4 enables performance, energy and CO2e efficiency gains",2025年12月访问,https://cloud.google.com/blog/topics/systems/tpu-v4-enables-performance-energy-and-co2e-efficiency-gains。
-
TrendForce,"Google Unveils 7th-Gen TPU Ironwood"。
-
Google Cloud Blog,"Quantifying the performance of the TPU"。
-
Ko,"TPU Deep Dive"。
-
Ko,"TPU Deep Dive"。
-
Ko,"TPU Deep Dive"。
-
Ko,"TPU Deep Dive"。
-
Ko,"TPU Deep Dive"。
-
Ko,"TPU Deep Dive"。
-
Ko,"TPU Deep Dive"。
-
Ko,"TPU Deep Dive"。
-
Artech Digital,"Energy-Efficient GPU vs. TPU Allocation",2025年12月访问,https://www.artech-digital.com/blog/energy-efficient-gpu-vs-tpu-allocation。
-
Wikipedia,"Tensor Processing Unit"。
-
XPU.pub,"Google Adds FP8 to Ironwood TPU"。
-
Ko,"TPU Deep Dive"。
-
Google Cloud Blog,"TPU v4 enables performance, energy and CO2e efficiency gains"。
-
ByteBridge,"GPU and TPU Comparative Analysis Report",Medium,2025年12月访问,https://bytebridge.medium.com/gpu-and-tpu-comparative-analysis-report-a5268e4f0d2a。
-
ByteBridge,"GPU and TPU Comparative Analysis Report"。
-
Anthropic,"Expanding our use of Google Cloud TPUs"。
-
Ko,"TPU Deep Dive"。
-
Ko,"TPU Deep Dive"。
-
Ko,"TPU Deep Dive"。
-
DataCamp,"Understanding TPUs vs GPUs in AI: A Comprehensive Guide",2025年12月访问,https://www.datacamp.com/blog/tpu-vs-gpu-ai。
-
Ko,"TPU Deep Dive"。
-
DataCamp,"Understanding TPUs vs GPUs in AI"。
-
Grigory Sapunov,"FP64, FP32, FP16, BFLOAT16, TF32, and other members of the ZOO",Medium,2025年12月访问,https://moocaholic.medium.com/fp64-fp32-fp16-bfloat16-tf32-and-other-members-of-the-zoo-a1ca7897d407。
-
Ko,"TPU Deep Dive"。
-
Ko,"TPU Deep Dive"。
-
Ko,"TPU Deep Dive"。
-
Ko,"TPU Deep Dive"。
-
Snider和Liang,"Operator Fusion in XLA"。
-
APXML,"Memory-Aware Data Layout Transformations"。
-
Google Cloud Blog,"How Lightricks trains video diffusion models at scale with JAX on TPU",2025年12月访问,https://cloud.google.com/blog/products/media-entertainment/how-lightricks-trains-video-diffusion-models-at-scale-with-jax-on-tpu。
-
CloudOptimo,"TPU vs GPU: What's the Difference in 2025?",2025年12月访问,https://www.cloudoptimo.com/blog/tpu-vs-gpu-what-is-the-difference-in-2025/。
-
Phoenix NAP,"TPU vs. GPU: Differences Explained",2025年12月访问,https://phoenixnap.com/kb/tpu-vs-gpu。
-
CloudOptimo,"TPU vs GPU"。
-
DataCamp,"Understanding TPUs vs GPUs in AI"。
-
Tailscale,"TPU vs GPU: Which Is Better for AI Infrastructure in 2025?",2025年12月访问,https://tailscale.com/learn/what-is-tpu-vs-gpu。
-
DataCamp,"Understanding TPUs vs GPUs in AI"。
-
DataCamp,"Understanding TPUs vs GPUs in AI"。
-
PyTorch文档,"Custom Kernels via Pallas"。
-
Phoenix NAP,"TPU vs. GPU: Differences Explained"。
-
Ko,"TPU Deep Dive"。
-
OpenMetal,"TPU vs GPU: Pros and Cons",2025年12月访问,https://openmetal.io/docs/product-guides/private-cloud/tpu-vs-gpu-pros-and-cons/。
-
OpenMetal,"TPU vs GPU: Pros and Cons"。
-
Phoenix NAP,"TPU vs. GPU: Differences Explained"。
-
PRIMO.ai,"Processing Units - CPU, GPU, APU, TPU, VPU, FPGA, QPU",2025年12月访问,https://primo.ai/index.php?title=Processing_Units_-_CPU%2C_GPU%2C_APU%2C_TPU%2C_VPU%2C_FPGA%2C_QPU。
-
DataCamp,"Understanding TPUs vs GPUs in AI"。
-
Google Cloud文档,"Profile your model on Cloud TPU VMs",2025年12月访问,https://cloud.google.com/tpu/docs/cloud-tpu-tools。
-
DataCamp,"Understanding TPUs vs GPUs in AI"。
-
Ko,"TPU Deep Dive"。
-
GitHub,"RFC: Evolving PyTorch/XLA"。
-
Google Cloud Press Corner,"Anthropic to Expand Use"。
-
TrendForce,"Google Unveils 7th-Gen TPU Ironwood"。
-
Maginative,"Anthropic Secures 1M Google TPUs While Keeping Amazon as Primary Training Partner",2025年12月访问,https://www.maginative.com/article/anthropic-secures-1m-google-tpus-while-keeping-amazon-as-primary-training-partner/。
-
Anthropic,"A postmortem of three recent issues",工程博客,2025年8月,https://www.anthropic.com/engineering/a-postmortem-of-three-recent-issues。
-
Anthropic,"A postmortem of three recent issues"。
-
AI Magazine,"Why Anthropic Uses Google Cloud TPUs for AI Infrastructure",2025年12月访问,https://aimagazine.com/news/why-anthropic-uses-google-cloud-tpus-for-ai-infrastructure。
-
Google Cloud Blog,"Ironwood TPUs and new Axion-based VMs for your AI workloads",2025年11月,https://cloud.google.com/blog/products/compute/ironwood-tpus-and-new-axion-based-vms-for-your-ai-workloads。
-
Ko,"TPU Deep Dive"。
-
TrendForce,"Google Unveils 7th-Gen TPU Ironwood"。
-
Ko,"TPU Deep Dive"。
-
Ko,"TPU Deep Dive"。
-
Ko,"TPU Deep Dive"。
-
Ko,"TPU Deep Dive"。
-
Ko,"TPU Deep Dive"。
-
Google Cloud,"Tensor Processing Units (TPUs)",2025年12月访问,https://cloud.google.com/tpu。
-
TensorFlow文档,"Optimize TensorFlow performance using the Profiler",2025年12月访问,https://www.tensorflow.org/guide/profiler。
-
Google Cloud文档,"Profile your model on Cloud TPU VMs"。
-
TensorFlow文档,"TensorFlow Profiler: Profile model performance",2025年12月访问,https://www.tensorflow.org/tensorboard/tensorboard_profiling_keras。
-
Google Cloud文档,"Profile your model on Cloud TPU VMs"。
-
Google Cloud Blog,"PyTorch/XLA: Performance debugging on Cloud TPU VM: Part III",2025年12月访问,https://cloud.google.com/blog/topics/developers-practitioners/pytorchxla-performance-debugging-cloud-tpu-vm-part-iii。
-
Google Cloud Blog,"PyTorch/XLA: Performance debugging Part III"。
-
Google Cloud文档,"Profile PyTorch XLA workloads",2025年12月访问,https://docs.cloud.google.com/tpu/docs/pytorch-xla-performance-profiling-tpu-vm。
-
TensorFlow文档,"Optimize TensorFlow performance using the Profiler"。
-
TensorFlow文档,"Optimize TensorFlow performance using the Profiler"。
-
Ko,"TPU Deep Dive"。
-
Google Cloud文档,"Cloud TPU performance guide"。
-
TensorFlow文档,"Optimize TensorFlow performance using the Profiler"。
-
TensorFlow文档,"Optimize TensorFlow performance using the Profiler"。
-
TensorFlow文档,"Optimize TensorFlow performance using the Profiler"。
-
TrendForce,"Google Unveils 7th-Gen TPU Ironwood"。
-
Tse,"Understanding the FP64, FP32, FP16, BFLOAT16, TF32, FP8 Formats"。
-
Ko,"TPU Deep Dive"。
-
Ko,"TPU Deep Dive"。
-
Ko,"TPU Deep Dive"。
-
Ko,"TPU Deep Dive"。


