
Tensor Processing Units ของ Google เป็นพลังขับเคลื่อนโมเดล AI ล้ำสมัยส่วนใหญ่ที่คุณใช้งานในชีวิตประจำวัน แต่วิศวกรส่วนใหญ่กลับยังไม่คุ้นเคยกับสถาปัตยกรรมของมันอย่างน่าแปลก ในขณะที่ GPU ของ NVIDIA ครองใจนักพัฒนา TPU กลับเงียบๆ ฝึกอบรมและให้บริการ Gemini 2.0, Claude และโมเดล frontier อีกหลายสิบตัวในระดับที่จะทำให้องค์กรส่วนใหญ่ล้มละลายหากใช้โครงสร้างพื้นฐาน GPU แบบเดิม Anthropic เพิ่งประกาศความมุ่งมั่นในการติดตั้ง TPU ชิปมากกว่าหนึ่งล้านชิป ซึ่งแสดงถึงกำลังประมวลผลมากกว่าหนึ่งจิกะวัตต์ เพื่อฝึกอบรมโมเดล Claude รุ่นอนาคต¹ Ironwood generation ล่าสุดของ Google ให้ประสิทธิภาพ 42.5 exaflops ของการประมวลผล FP8 ผ่าน superpods 9,216 ชิป ซึ่งเป็นระดับที่นิยามใหม่ของโครงสร้างพื้นฐาน AI ระดับการผลิต²
ความซับซ้อนทางเทคนิคเบื้องหลัง TPU นั้นขยายไปไกลเกินกว่าตัวชี้วัดประสิทธิภาพธรรมดา โปรเซสเซอร์เหล่านี้รวบรวมปรัชญาการออกแบบที่แตกต่างจาก GPU อย่างพื้นฐาน โดยแลกเปลี่ยนความยืดหยุ่นแบบใช้งานทั่วไปเพื่อความเชี่ยวชาญเฉพาะทางในการคูณเมทริกซ์และการดำเนินการ tensor วิศวกรที่เข้าใจสถาปัตยกรรม TPU สามารถใช้ประโยชน์จาก systolic arrays ขนาด 256×256 ที่ประมวลผลการดำเนินการ multiply-accumulate 65,536 ครั้งต่อรอบ ใช้ประโยชน์จาก SparseCore accelerators รุ่นที่สามสำหรับงานที่ใช้ embedding มาก และเขียนโปรแกรม optical circuit switches ที่ปรับโครงสร้าง datacenter topologies แบบ multi-petabit ในเวลาน้อยกว่า 10 นาโนวินาที³ สถาปัตยกรรมนี้ครอบคลุมทุกอย่างตั้งแต่การตัดสินใจออกแบบในระดับทรานซิสเตอร์ไปจนถึงการประสานงานซูเปอร์คอมพิวเตอร์ในระดับอาคาร
เนื้อหาทางเทคนิคที่จะตามมาต้องการความใส่ใจอย่างรอบคอบ เราจะศึกษาวิวัฒนาการ TPU เจ็ดรุ่น ผ่าสถาปัตยกรรม systolic array คณิตศาสตร์และรูปแบบ dataflow สำรวจลำดับชั้นหน่วยความจำตั้งแต่ SRAM tiles ไปจนถึงช่องสัญญาณ HBM3e วิเคราะห์การเพิ่มประสิทธิภาพคอมไพเลอร์ XLA ในระดับ intermediate representation และสืบสวนว่าทำไมการดำเนินการ collective จึงทำงานเร็วกว่า GPU clusters แบบใช้ Ethernet ถึง 10 เท่า⁴ คุณจะพบกับข้อกำหนดในระดับ register การสร้างแบบจำลองประสิทธิภาพที่แม่นยำจนถึงรอบ และการแลกเปลี่ยนทางสถาปัตยกรรมที่ทำให้ TPU มีทั้งพลังมากขึ้นและข้อจำกัดมากขึ้นกว่า GPU ความลึกที่นี่มีไว้สำหรับวิศวกรที่สร้างโครงสร้างพื้นฐาน AI รุ่นใหม่และนักวิจัยที่ผลักดันขีดจำกัดของสิ่งที่ accelerators ปัจจุบันสามารถทำได้
วิวัฒนาการ: เจ็ดรุ่นของนวัตกรรมสถาปัตยกรรม
TPU v1: การเชี่ยวชาญเฉพาะการอนุมาน (2015)
Google เปิดตัว Tensor Processing Unit รุ่นแรกในปี 2015 เพื่อแก้ไขปัญหาสำคัญ: ปริมาณงานการอนุมานเครือข่ายนิวรัลอาจทำให้พื้นที่ datacenter ของบริษัทเพิ่มขึ้นเป็นสองเท่า⁵ วิศวกรออกแบบ TPU v1 เฉพาะสำหรับการอนุมานเท่านั้น โดยเอาความสามารถในการฝึกออกไปทั้งหมด เพื่อเพิ่มประสิทธิภาพและประสิทธิภาพพลังงานสูงสุดสำหรับโมเดลที่ถูก deploy chip นี้มี 256×256 systolic array ของ 8-bit integer multiply-accumulate units ส่งผลให้ได้ 92 teraops ต่อวินาทีด้วยกำลัง thermal design power เพียง 28-40 วัตต์เท่านั้น⁶
สถาปัตยกรรมนี้แสดงถึงความเรียบง่ายที่รุนแรง Matrix Multiply Unit เดียวประมวลผลการดำเนินการ INT8 ผ่าน weight-stationary dataflow โดยที่ weights คงอยู่ในตำแหน่งเดิมใน systolic array ขณะที่ activations ไหลในแนวนอนข้าม grid Partial sums จะถูกส่งผ่านในแนวตั้ง ซึ่งขจัดการเขียนหน่วยความจำกลางระหว่างขั้นตอนสำหรับการคูณเมทริกซ์ทั้งหมด chip ซึ่งเชื่อมต่อกับระบบ host ผ่าน PCIe อาศัย DDR3 DRAM สำหรับหน่วยความจำภายนอกและทำงานที่ 700 MHz ซึ่งถือว่าระมัดระวังเป็นพิเศษเพื่อประสิทธิภาพพลังงาน⁷
ผลการปรับปรุงประสิทธิภาพทำให้แม้แต่วิศวกรของ Google ยังประหลาดใจ TPU v1 ทำได้การปรับปรุง 30× ถึง 80× ในการดำเนินการต่อวัตต์เมื่อเทียบกับ CPUs และ GPUs ร่วมสมัยสำหรับปริมาณงานการอนุมานในการผลิต⁸ chip จัดการการจัดอันดับ Google Search, บริการแปลที่ประมวลผล 1 พันล้านคำขอต่อวัน และการแนะนำ YouTube สำหรับผู้ใช้ 2 พันล้านคน ความสำเร็จนี้ยืนยันข้อมูลเชิงลึกของสถาปัตยกรรมหลัก: ตัวเร่งที่สร้างขึ้นเฉพาะเจาะจงที่เพิ่มประสิทธิภาพสำหรับปริมาณงานที่แคบสามารถให้การปรับปรุงที่มีขนาดของลำดับมากกว่าโปรเซสเซอร์อเนกประสงค์
TPU v2: การเปิดใช้งานการฝึกที่มีขนาดใหญ่ (2017)
รุ่นที่สองเปลี่ยน TPUs จากตัวเร่งการอนุมานเท่านั้นเป็นแพลตฟอร์มการฝึกที่สมบูรณ์ Google ออกแบบสถาปัตยกรรมทั้งหมดใหม่รอบๆ การดำเนินการจุดลอยตัว โดยเปลี่ยนจาก 256×256 INT8 array เป็น dual 128×128 bfloat16 multiply-accumulators ต่อ core⁹ แต่ละ chip มี TensorCores สองตัวที่แชร์ 8GB ของ High Bandwidth Memory ต่อ core ซึ่งเป็นการอัปเกรดขนาดใหญ่จาก DDR3 ที่ให้ bandwidth ที่การฝึกเครือข่ายนิวรัลต้องการ
ความแม่นยำ Bfloat16 พิสูจน์แล้วว่าสำคัญต่อความสำเร็จของ TPU v2 รูปแบบนี้รักษาช่วง exponent 8-bit เดียวกันกับ FP32 ขณะที่ลด mantissa เหลือ 7 bits รักษาช่วงไดนามิกสำหรับการฝึกขณะที่ลดความต้องการ memory bandwidth ลงครึ่งหนึ่ง¹⁰ วิศวกรสังเกตว่าความแม่นยำ mantissa ที่ลดลงจริงๆ แล้วปรับปรุงการ generalization ในหลายโมเดลโดยทำหน้าที่เป็นรูปแบบของ regularization ขณะที่ช่วง FP32 exponent เต็มป้องกันปัญหา underflow และ overflow ที่รบกวนการฝึก FP16
นวัตกรรมทางสถาปัตยกรรมที่แยกความแตกต่าง TPU v2 อย่างแท้จริงคือ Inter-Chip Interconnect (ICI) ตัวเร่งก่อนหน้านี้ต้องการ Ethernet หรือ InfiniBand สำหรับการสื่อสารหลายชิป ซึ่งสร้างคอขวด latency และ bandwidth Google ออกแบบการเชื่อมโยงแบบสองทิศทางความเร็วสูงแบบกำหนดเองที่เชื่อมต่อ TPU แต่ละตัวโดยตรงกับเพื่อนบ้านสี่ตัวในโครงสร้าง 2D torus¹¹ interconnect ทำให้ TPU v2 "pods" ของชิปสูงสุด 256 ตัวทำงานเป็นตัวเร่งเชิงตรรกะเดียว โดยมีการดำเนินการร่วม เช่น all-reduce ดำเนินการเร็วกว่าทางเลือกที่ใช้เครือข่าย
TPU v3: การปรับขนาดประสิทธิภาพด้วยน้ำหล่อเย็น (2018)
Google ผลัก clock speeds และ core counts อย่างเข้มข้นใน TPU v3 ส่งผลให้ได้ 420 teraflops ต่อชิป ซึ่งมากกว่าสองเท่าของประสิทธิภาพ v2¹² ความหนาแน่นของพลังงานที่เพิ่มขึ้นบังคับให้เปลี่ยนแปลงสถาปัตยกรรมอย่างมาก: การหล่อเย็นด้วยของเหลว แต่ละ TPU v3 pod ต้องการโครงสร้างพื้นฐานการหล่อเย็นด้วยน้ำ ซึ่งเป็นการออกจากการออกแบบการหล่อเย็นด้วยอากาศของรุ่นก่อนหน้าและตัวเร่ง datacenter ส่วนใหญ่¹³
chip ยังคงสถาปัตยกรรม dual 128×128 MXU แต่เพิ่มจำนวน cores รวมและปรับปรุง memory bandwidth แต่ละ TPU v3 มีสี่ชิปที่มีสอง cores แต่ละตัว แชร์ 32GB ของ HBM memory รวมทั้งหมดข้ามชิป¹⁴ หน่วยประมวลผล vector ได้รับการเพิ่มประสิทธิภาพสำหรับ activation functions, การดำเนินการ normalization และการคำนวณ gradient ที่มักเป็นคอขวดการฝึกบน matrix units เพียงอย่างเดียว
การ deployment ปรับขนาดเป็น 2,048-chip pods โดยใช้โครงสร้าง 2D torus ICI เดียวกันกับ v2 แต่มี bandwidth ต่อลิงก์เพิ่มขึ้น Google ฝึกโมเดลที่มีขนาดใหญ่ขึ้นเรื่อยๆ บน v3 pods ค้นพบว่าโครงสร้าง torus topology ที่มีเส้นผ่านศูนย์กลางเครือข่ายลดลง (ระยะทางสูงสุดระหว่างชิปสองตัวใดๆ ปรับขนาดเป็น N/2 แทนที่จะเป็น N) ลด overhead การสื่อสารสำหรับทั้งกลยุทธ์การฝึก data-parallel และ model-parallel ให้เหลือน้อยที่สุด¹⁵
TPU v4: การก้าวหน้า Optical Circuit Switching (2021)
รุ่นที่สี่แสดงถึงการก้าวกระโดดทางสถาปัตยกรรมที่สำคัญที่สุดของ Google นับตั้งแต่ TPU ดั้งเดิม วิศวกรเพิ่มขนาด pod เป็น 4,096 ชิปขณะที่แนะนำ optical circuit switching (OCS) สำหรับ interconnect เทคโนโลยีที่ยืมมาจากโทรคมนาคมที่ปฏิวัติโครงสร้างพื้นฐาน ML ขนาด datacenter¹⁶
สถาปัตยกรรมหลักของ TPU v4 มี 128×128 MXUs สี่ตัวต่อ TensorCore ควบคู่ไปกับหน่วย vector และ scalar ที่เพิ่มประสิทธิภาพ แต่ละคู่ TensorCore แชร์ 128MB ของ Common Memory นอกจาก Vector Memory ต่อ core ซึ่งทำให้รูปแบบการจัดเตรียมและนำกลับมาใช้ข้อมูลที่ซับซ้อนมากขึ้น¹⁷ โครงสร้าง chip วิวัฒนาการจาก 2D เป็น 3D torus เชื่อมต่อ TPU แต่ละตัวกับเพื่อนบ้านหกตัวแทนที่จะเป็นสี่ตัว ลดเส้นผ่านศูนย์กลางเครือข่ายต่อไปและปรับปรุง bisection bandwidth
ระบบ optical circuit switching เปลี่ยนทุกอย่างเกี่ยวกับการ deployment ขนาดใหญ่ แทนที่จะเป็นสายเคเบิลคงที่ระหว่าง TPUs Google deploy สวิตช์แสงที่โปรแกรมได้ซึ่งสามารถกำหนดค่าใหม่แบบไดนามิกว่าชิปไหนเชื่อมต่อกับชิปไหน กระจก MEMS (microelectromechanical systems) เปลี่ยนทิศทางลำแสงทางกายภาพเพื่อเชื่อมต่อคู่ TPU โดยพลการเข้าด้วยกัน โดยแนะนำ latency เป็นศูนย์โดยพื้นฐานเกินกว่าเวลาการส่ง optical fiber¹⁸ สวิตช์กำหนดค่าใหม่ในหน้าต่างต่ำกว่า 10 นาโนวินาที เร็วกว่าการจับมือโปรโตคอลเครือข่ายส่วนใหญ่
สถาปัตยกรรม OCS เปิดใช้งานความสามารถที่เป็นไปไม่ได้มาก่อน Google สามารถจัดเตรียม "slices" ของขนาดใดก็ได้ ตั้งแต่สี่ชิปจนถึง 4,096-chip pod เต็มโดยการโปรแกรม optical switches ตามความเหมาะสม ชิปที่เสียหายสามารถถูก route รอบๆ ได้อย่างราบรื่นโดยไม่ทำให้ rack ทั้งหมดล่ม น่าทึ่งที่สุดคือ TPUs ที่อยู่ห่างไกลทางกายภาพในสถานที่ datacenter ต่างๆ สามารถอยู่ติดกันในเชิงตรรกะในโครงสร้างเครือข่าย แยกการจัดวางทางกายภาพและเชิงตรรกะออกจากกันอย่างสมบูรณ์¹⁹
TPU v4 ยังแนะนำ SparseCore โปรเซสเซอร์เฉพาะทางสำหรับจัดการการดำเนินการ embedding ที่ใช้ทุกวันในระบบแนะนำ โมเดลจัดอันดับ และโมเดลภาษาขนาดใหญ่ที่มี embedding คำศัพท์ขนาดใหญ่มาก SparseCore มีโปรเซสเซอร์เฉพาะสี่ตัวต่อชิป แต่ละตัวมี 2.5MB ของ scratchpad memory และ dataflow ที่เพิ่มประสิทธิภาพสำหรับรูปแบบการเข้าถึงหน่วยความจำแบบ sparse²⁰ โมเดลที่มี embeddings ขนาดใหญ่มากทำได้ความเร็วเพิ่มขึ้น 5-7× โดยใช้เพียง 5% ของพื้นที่ chip die และงบประมาณพลังงานรวม
TPU v5p และ v5e: การเชี่ยวชาญและขนาด (2022-2023)
Google แบ่งรุ่นที่ห้าเป็นสองผลิตภัณฑ์ที่แตกต่างกันซึ่งกำหนดเป้าหมายกรณีการใช้งานที่แตกต่างกัน TPU v5p ให้ความสำคัญกับประสิทธิภาพสูงสุดสำหรับการฝึกขนาดใหญ่ ขณะที่ v5e เพิ่มประสิทธิภาพสำหรับการอนุมานที่คุ้มค่าและงานฝึกขนาดเล็ก²¹
TPU v5p ทำได้ประมาณ 4.45 exaflops ต่อวินาทีข้าม 8,960-chip pods มากกว่าสองเท่าของขนาด pod สูงสุดของ v4²² bandwidth ของ interconnect ถึง 4,800 Gbps ต่อชิป และโครงสร้าง 3D torus เชื่อมต่อชิปใน 16×20×28 superpods ขนาดใหญ่ optical circuit switching fabric จัดการ 13,824 optical ports ข้าม 48 OCS units เพื่อเชื่อมต่อ v5p superpod ที่สมบูรณ์ ซึ่งแสดงถึงการ deployment optical switching การผลิตที่ใหญ่ที่สุดแห่งหนึ่งในประวัติศาสตร์การคำนวณ²³
TPU v5e ใช้วิธีการที่แตกต่าง ลดจำนวน core และ clock speed เพื่อให้ตรงกับเป้าหมายพลังงานและต้นทุนที่รุนแรง ชิปที่เพิ่มประสิทธิภาพสำหรับการอนุมานมีเพียง TPU core เดียวต่อชิปแทนที่จะเป็นสอง และกลับไปใช้โครงสร้าง 2D torus ซึ่งเพียงพอสำหรับขนาด pod ที่เล็กกว่า²⁴ การลดความซับซ้อนทางสถาปัตยกรรมทำให้ Google สามารถกำหนดราคา v5e ให้แข่งขันได้สำหรับปริมาณงานที่ประสิทธิภาพสมบูรณ์มีความสำคัญน้อยกว่าประสิทธิภาพต่อดอลลาร์
TPU v6e Trillium: การเพิ่ม Matrix Performance เป็นสี่เท่า (2024)
Trillium ทำเครื่องหมายจุดเปลี่ยนทางสถาปัตยกรรมอีกครั้งโดยการขยาย Matrix Multiply Unit จาก 128×128 เป็น 256×256 multiply-accumulators²⁵ array ที่ใหญ่กว่าเพิ่ม FLOPs ต่อรอบเป็นสี่เท่าที่ clock speed เดียวกัน ส่งผลให้ประสิทธิภาพการคำนวณสูงสุด 4.7× ของ TPU v5e ผ่านการผสมผสานของ MXU ที่ขยายและความถี่ clock ที่เพิ่มขึ้น
ระบบหน่วยความจำได้รับการอัปเกรดที่น่าทึ่งเท่าๆ กัน ความจุ HBM เพิ่มเป็นสองเท่าเป็น 32GB ต่อชิป โดยมี bandwidth เพิ่มเป็นสองเท่าโดยช่อง HBM รุ่นถัดไป²⁶ bandwidth ของ Interchip Interconnect เช่นกันเพิ่มเป็นสองเท่า ทำให้ pods ของ 256 Trillium chips สามารถรักษา throughput ที่สูงขึ้นสำหรับโมเดลที่กดดันทั้งการคำนวณและการสื่อสาร²⁷
Trillium มี SparseCore accelerator รุ่นที่สาม ที่มีความสามารถเพิ่มขึ้นสำหรับ embeddings ขนาดใหญ่มากในปริมาณงานการจัดอันดับและแนะนำ การออกแบบที่อัปเดตปรับปรุงรูปแบบการเข้าถึงหน่วยความจำและเพิ่ม bandwidth ที่เพียงพอระหว่าง SparseCores และ HBM สำหรับโมเดลที่ถูกครอบงำโดยการค้นหา embedding แทนที่จะเป็นการคูณเมทริกซ์²⁸
ประสิทธิภาพพลังงานปรับปรุง 67% เหนือ v5e แม้จะมีประสิทธิภาพเพิ่มขึ้นอย่างมาก²⁹ Google ทำได้ประสิทธิภาพผ่าน process nodes ขั้นสูง การเพิ่มประสิทธิภาพทางสถาปัตยกรรมที่ลดงานที่เสียไป และการ power gating ที่ระมัดระวังของหน่วยที่ไม่ได้ใช้ระหว่างการดำเนินการที่ไม่กดดันทุกส่วนของชิปพร้อมกัน
TPU v7 Ironwood: ยุค FP8 (2025)
TPU รุ่นที่เจ็ดของ Google ชื่อรหัส Ironwood แสดงถึง TPU แรกที่ออกแบบด้วยการสนับสนุน FP8 แบบ native และเพิ่มประสิทธิภาพเฉพาะสำหรับ "ยุคของการอนุมาน" ขณะที่รักษาประสิทธิภาพการฝึกที่ล้ำสมัย³⁰ แต่ละชิป Ironwood ส่งผล 4.6 petaFLOPS ของการคำนวณ FP8 แบบหนาแน่น ซึ่งเกินกว่า NVIDIA B200 ที่แข่งขันกันเล็กน้อยที่ 4.5 petaFLOPS ขณะที่ใช้ 600W thermal design power³¹
ระบบหน่วยความจำขยายเป็น 192GB ของ HBM3e memory ต่อชิป หกเท่าของความจุของ Trillium ด้วย bandwidth ที่ถึง 7.4TB/s³² การเพิ่มหน่วยความจำอย่างมากทำให้สามารถให้บริการโมเดลขนาดใหญ่มากที่มี key-value caches ที่เคยต้องการ tensor parallelism ที่ซับซ้อนข้ามตัวเร่งหลายตัว Google ออกแบบความจุหน่วยความจำเฉพาะเพื่อสนับสนุนโมเดลแบบ multi-modal ที่เกิดขึ้นใหม่และแอปพลิเคชัน long-context ที่ใกล้ million-token windows
interconnect ของ Ironwood ให้ 9.6 Tbps ของ aggregate bidirectional bandwidth ผ่าน ICI links สี่ตัว แปลเป็น 1.2 TB/s ของ peak per-chip bandwidth³³ สถาปัตยกรรมปรับขนาดจาก 256-chip pods สำหรับการ deployment ขนาดเล็กไปจนถึง 9,216-chip superpods ขนาดใหญ่มากที่ส่งผล 42.5 FP8 exaflops ของพลังการคำนวณ³⁴ เทคโนโลยี Jupiter datacenter network ของ Google สามารถสนับสนุน Ironwood superpods ได้ทฤษฎีสูงสุด 43 ตัวในคลัสเตอร์เดียว ซึ่งประมาณ 400,000 ตัวเร่งที่แสดงถึงขนาดการคำนวณที่เกือบไม่สามารถเข้าใจได้³⁵
การสนับสนุน FP8 แสดงถึงการเปลี่ยนแปลงพื้นฐานในกลยุทธ์ความแม่นยำ รุ่น TPU ก่อนหน้าเลียนแบบการดำเนินการ 8-bit โดยใช้เทคนิคซอฟต์แวร์ ซึ่งสร้าง overhead Ironwood ใช้หน่วย FP8 multiply-accumulate แบบ native ที่สนับสนุนทั้งรูปแบบ E4M3 (4-bit exponent, 3-bit mantissa) และ E5M2 (5-bit exponent, 2-bit mantissa)³⁶ การสนับสนุนรูปแบบคู่ทำให้สามารถผสม E4M3 สำหรับ forward passes ที่ความแม่นยำมีความสำคัญน้อยกว่าและ E5M2 สำหรับ backward passes ที่การรักษาขนาด gradient ป้องกันความไม่เสถียรของการฝึก
ความมุ่งมั่นของ Anthropic ในการ deploy ชิป Ironwood มากกว่าหนึ่งล้านตัวเริ่มต้นในปี 2026 แสดงให้เห็นความพร้อมการผลิตของสถาปัตยกรรม บริษัทวางแผนที่จะใช้ประโยชน์จากความจุ TPU มากกว่า gigawatt ซึ่งเพียงพอที่จะจ่ายไฟให้เมืองเล็กๆ โดยเฉพาะสำหรับการฝึกและให้บริการโมเดล Claude³⁷ ขนาดดังกล่าวเหนือกว่าแม้แต่การ deployment GPU ที่ใหญ่ที่สุดที่รู้จักและแสดงถึงการเดิมพันพื้นฐานบนสถาปัตยกรรม TPU สำหรับการพัฒนาโมเดล frontier
การอ้างอิงอย่างรวดเร็วรุ่นปัจจุบัน
ตารางต่อไปนี้ให้ข้อกำหนดที่สแกนได้สำหรับ TPUs รุ่นปัจจุบันสามรุ่นที่เกี่ยวข้องที่สุดกับการ deployment การผลิตในปี 2025:
ตารางที่ 1: ข้อกำหนดการคำนวณหลัก
[caption id="" align="alignnone" width="1386"] ข้อกำหนดTPU v5eTPU v5pTPU v6e (Trillium)TPU v7 (Ironwood) MXU Array Size 128×128 128×128 256×256 256×256 MACs per Cycle 16,384 16,384 65,536 65,536 Peak BF16 TFLOPS ~197 ~459 ~918 ~2,300 (est.) Peak FP8 PFLOPS N/A (emulated) N/A (emulated) N/A (emulated) 4.6 Native Precision BF16, INT8 BF16, INT8 BF16, INT8 BF16, FP8, INT8 TensorCores/Chip 1 2 1 1[/caption]
ข้อกำหนดTPU v5eTPU v5pTPU v6e (Trillium)TPU v7 (Ironwood) MXU Array Size 128×128 128×128 256×256 256×256 MACs per Cycle 16,384 16,384 65,536 65,536 Peak BF16 TFLOPS ~197 ~459 ~918 ~2,300 (est.) Peak FP8 PFLOPS N/A (emulated) N/A (emulated) N/A (emulated) 4.6 Native Precision BF16, INT8 BF16, INT8 BF16, INT8 BF16, FP8, INT8 TensorCores/Chip 1 2 1 1[/caption]
ตารางที่ 2: หน่วยความจำและ Bandwidth
[caption id="" align="alignnone" width="1380"]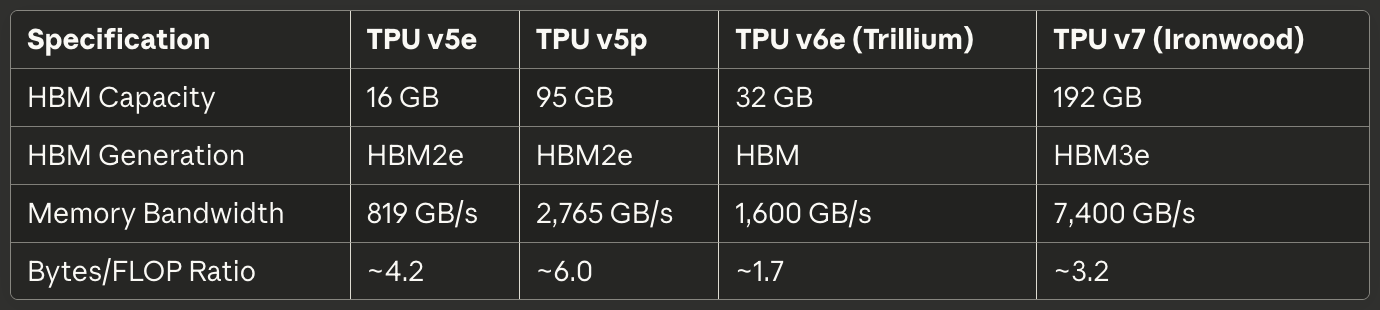 ข้อกำหนดTPU v5eTPU v5pTPU v6e (Trillium)TPU v7 (Ironwood) HBM Capacity 16 GB 95 GB 32 GB 192 GB HBM Generation HBM2e HBM2e HBM HBM3e Memory Bandwidth 819 GB/s 2,765 GB/s 1,600 GB/s 7,400 GB/s Bytes/FLOP Ratio ~4.2 ~6.0 ~1.7 ~3.2[/caption]
ข้อกำหนดTPU v5eTPU v5pTPU v6e (Trillium)TPU v7 (Ironwood) HBM Capacity 16 GB 95 GB 32 GB 192 GB HBM Generation HBM2e HBM2e HBM HBM3e Memory Bandwidth 819 GB/s 2,765 GB/s 1,600 GB/s 7,400 GB/s Bytes/FLOP Ratio ~4.2 ~6.0 ~1.7 ~3.2[/caption]
ตารางที่ 3: Interconnect และการปรับขนาด
[caption id="" align="alignnone" width="1384"]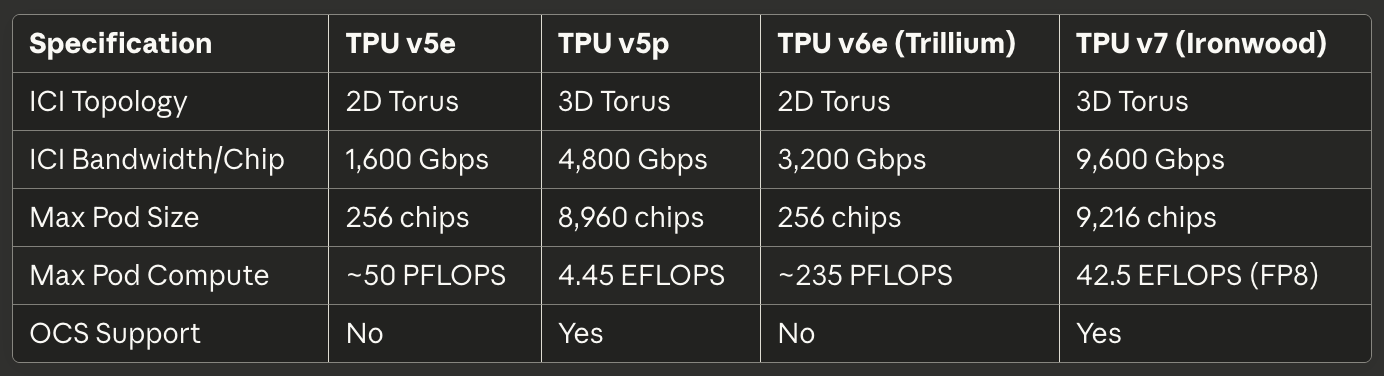 ข้อกำหนดTPU v5eTPU v5pTPU v6e (Trillium)TPU v7 (Ironwood) ICI Topology 2D Torus 3D Torus 2D Torus 3D Torus ICI Bandwidth/Chip 1,600 Gbps 4,800 Gbps 3,200 Gbps 9,600 Gbps Max Pod Size 256 chips 8,960 chips 256 chips 9,216 chips Max Pod Compute ~50 PFLOPS 4.45 EFLOPS ~235 PFLOPS 42.5 EFLOPS (FP8) OCS Support No Yes No Yes[/caption]
ข้อกำหนดTPU v5eTPU v5pTPU v6e (Trillium)TPU v7 (Ironwood) ICI Topology 2D Torus 3D Torus 2D Torus 3D Torus ICI Bandwidth/Chip 1,600 Gbps 4,800 Gbps 3,200 Gbps 9,600 Gbps Max Pod Size 256 chips 8,960 chips 256 chips 9,216 chips Max Pod Compute ~50 PFLOPS 4.45 EFLOPS ~235 PFLOPS 42.5 EFLOPS (FP8) OCS Support No Yes No Yes[/caption]
ตารางที่ 4: พลังงานและประสิทธิภาพ
[caption id="" align="alignnone" width="1380"] ข้อกำหนดTPU v5eTPU v5pTPU v6e (Trillium)TPU v7 (Ironwood) TDP ~120-200W ~250-300W ~120-200W 600W Cooling Air Liquid Air Liquid TFLOPS/Watt (BF16) ~1.0-1.6 ~1.5-1.8 ~4.6-7.7 ~3.8 Energy vs Prior Gen Baseline N/A 67% better than v5e 2× better than Trillium[/caption]
ข้อกำหนดTPU v5eTPU v5pTPU v6e (Trillium)TPU v7 (Ironwood) TDP ~120-200W ~250-300W ~120-200W 600W Cooling Air Liquid Air Liquid TFLOPS/Watt (BF16) ~1.0-1.6 ~1.5-1.8 ~4.6-7.7 ~3.8 Energy vs Prior Gen Baseline N/A 67% better than v5e 2× better than Trillium[/caption]
ตารางที่ 5: กรณีการใช้งานที่แนะนำ
[caption id="" align="alignnone" width="1382"] กรณีการใช้งาน ตัวเลือกที่ดีที่สุด เหตุผล Cost-optimized inference TPU v5e: Lowest cost per inference query Large-scale training (>1000 chips) TPU v5p or Ironwood 3D torus + OCS enables massive pods Medium training jobs (256 chips) TPU v6e Trillium Best perf/watt, 4.7× compute vs v5e Memory-bound models (>70B params), Ironwood 192GB HBM enables larger batch sizes Long-context inference (>100K tokens) Ironwood HBM capacity supports massive KV caches Embedding-heavy workloads TPU v5p or Ironwood SparseCore + large HBM[/caption]
กรณีการใช้งาน ตัวเลือกที่ดีที่สุด เหตุผล Cost-optimized inference TPU v5e: Lowest cost per inference query Large-scale training (>1000 chips) TPU v5p or Ironwood 3D torus + OCS enables massive pods Medium training jobs (256 chips) TPU v6e Trillium Best perf/watt, 4.7× compute vs v5e Memory-bound models (>70B params), Ironwood 192GB HBM enables larger batch sizes Long-context inference (>100K tokens) Ironwood HBM capacity supports massive KV caches Embedding-heavy workloads TPU v5p or Ironwood SparseCore + large HBM[/caption]
สถาปัตยกรรมฮาร์ดแวร์: ภายในซิลิคอน
คณิตศาสตร์ Systolic Array และ Dataflow
Matrix Multiply Unit เป็นหัวใจของสถาปัตยกรรม TPU และการเข้าใจ systolic arrays ต้องการการเข้าใจวิธีการที่แตกต่างอย่างพื้นฐานต่อ parallelism เมื่อเทียบกับ GPU SIMD lanes systolic array เชื่อมโยงหน่วย multiply-accumulate ใน grid ที่ข้อมูลไหลอย่างจังหวะผ่านโครงสร้าง ดังนั้น "systolic" ที่ทำให้นึกถึงการปั๊มเลือดอย่างจังหวะผ่านหัวใจ³⁸
พิจารณา 256×256 systolic array ของ TPU v6e ทำการคูณเมทริกซ์ C = A × B วิศวกรโหลดน้ำหนักของเมทริกซ์ B ลงในหน่วย multiply-accumulate 65,536 ตัวที่จัดเรียงใน grid ค่า activation ของเมทริกซ์ A เข้ามาจากขอบซ้ายและไหลในแนวนอนข้าม array หน่วย MAC แต่ละตัวคูณน้ำหนักที่เก็บไว้ด้วย activation ที่เข้ามา เพิ่มผลลัพธ์ลงในผลรวมบางส่วนที่มาจากข้างบน และส่งผ่านทั้ง activation (ในแนวนอน) และผลรวมบางส่วนที่อัปเดต (ในแนวตั้ง) ไปยังหน่วยเพื่อนบ้าน³⁹
รูปแบบ dataflow หมายความว่าค่า activation แต่ละค่าถูกนำมาใช้ใหม่ 256 ครั้งขณะที่มันเดินทางผ่านมิติแนวนอน และผลรวมบางส่วนแต่ละส่วนสะสมการมีส่วนร่วมจากการคูณ 256 ครั้งขณะที่มันไหลในแนวตั้ง สำคัญมาก ผลลัพธ์กลางทั้งหมดส่งผ่านโดยตรงระหว่างหน่วย MAC ที่อยู่ติดกันผ่านสายสั้นๆ แทนที่จะเดินทางไปกลับไปยังหน่วยความจำ สถาปัตยกรรมดำเนินการ multiply-accumulate 65,536 การดำเนินการทุกรอบ clock และระหว่างการคูณเมทริกซ์ทั้งหมดที่เกี่ยวข้องกับการดำเนินการที่อาจเป็นล้านๆ ค่ากลางเป็นศูนย์สัมผัส DRAM หรือแม้แต่ on-chip SRAM⁴⁰
รูปแบบ weight-stationary dataflow เพิ่มประสิทธิภาพสำหรับกรณีที่พบมากที่สุดในการอนุมานเครือข่ายนิวรัลและการฝึก: การคูณเมทริกซ์ activation ต่างๆ หลายตัวซ้ำๆ ด้วยเมทริกซ์น้ำหนักเดียวกัน วิศวกรโหลดน้ำหนักครั้งเดียว จากนั้นสตรีม activation batches ที่ไม่มีขอบเขตผ่าน array โดยไม่ต้องโหลดใหม่ รูปแบบนี้ทำงานได้ดีเป็นพิเศษสำหรับ convolutional layers, fully connected layers และการดำเนินการ Q·K^T และ attention·V ที่ครอบงำโมเดล transformer⁴¹
ประสิทธิภาพพลังงานมาจากการนำข้อมูลกลับมาใช้และ spatial locality การอ่านค่าจาก DRAM ใช้พลังงานประมาณ 200× เท่าของการดำเนินการ multiply-accumulate เดียว⁴² โดยการนำน้ำหนักแต่ละค่ามาใช้ใหม่ 256 ครั้งและ activation แต่ละค่า 256 ครั้งโดยไม่ต้องเข้าถึงหน่วยความจำ systolic array ทำได้อัตราส่วนการดำเนินการต่อวัตต์ที่เป็นไปไม่ได้สำหรับสถาปัตยกรรมที่เคลื่อนย้ายข้อมูลไปมาระหว่างหน่วยคำนวณและลำดับชั้นหน่วยความจำ
จุดอ่อนของ systolic array เกิดขึ้นกับรูปแบบการคำนวณแบบไดนามิกหรือไม่สม่ำเสมอ เพราะข้อมูลไหลผ่าน grid ตามตารางเวลาคงที่ สถาปัตยกรรมต่อสู้กับการดำเนินการตามเงื่อนไข เมทริกซ์แบบ sparse (เว้นแต่จะใช้ SparseCore) และการดำเนินการที่ต้องการรูปแบบการเข้าถึงแบบสุ่ม ความไม่ยืดหยุ่นแลกเปลี่ยนความเป็นทั่วไปกับประสิทธิภาพสุดขั้วในปริมาณงานเป้าหมาย: การคูณเมทริกซ์แบบหนาแน่นที่มีรูปแบบการเข้าถึงที่คาดเดาได้
สถาปัตยกรรมภายใน TensorCore
แต่ละชิป TPU มี TensorCores หนึ่งหรือมากกว่า หน่วยประมวลผลที่สมบูรณ์ซึ่งประกอบด้วย Matrix Multiply Unit, Vector Processing Unit และ Scalar Unit ที่ทำงานร่วมกัน⁴³ TensorCore แสดงถึงหน่วยสร้างพื้นฐานที่ซอฟต์แวร์กำหนดเป้าหมาย และการเข้าใจการปฏิสัมพันธ์ระหว่างองค์ประกอบสามส่วนอธิบายทั้งลักษณะประสิทธิภาพ TPU และรูปแบบการโปรแกรม
Matrix Multiply Unit ดำเนินการ multiply-accumulate 16,000 การดำเนินการต่อรอบบน bfloat16 หรือ FP8 inputs ด้วย FP32 accumulation⁴⁴ วิธี mixed-precision รักษาความแม่นยำเชิงตัวเลขใน accumulator ขณะที่ลด memory bandwidth สำหรับ inputs วิศวกรสังเกตว่าการรักษาความแม่นยำ FP32 ที่สมบูรณ์ระหว่าง accumulation ป้องกันข้อผิดพลาดการยกเลิกหายนะเมื่อรวมผลิตภัณฑ์กลางหลายร้อยหรือหลายพันครั้ง ขณะที่ inputs ความแม่นยำลดลงไม่ค่อยส่งผลต่อคุณภาพโมเดลสุดท้าย
Vector Processing Unit จัดการการดำเนินการที่ไม่เหมาะสมกับโครงสร้างแข็งของ MXU Activation functions (ReLU, GELU, SiLU), normalization layers (batch norm, layer norm), softmax, pooling, dropout และการดำเนินการ element-wise ทำงานบนสถาปัตยกรรม 128-lane SIMD ของ VPU⁴⁵ VPU ทำงานบน datatypes FP32 และ INT32 ให้ความแม่นยำที่ต้องการสำหรับการดำเนินการที่มีความไวเชิงตัวเลข เช่น softmax ที่ exponentials และการหารสามารถสร้างช่วงไดนามิกขนาดใหญ่
Scalar Unit ประสานงาน TensorCore ทั้งหมด โปรเซสเซอร์แบบ single-threaded ดำเนินการ control flow คำนวณที่อยู่หน่วยความจำสำหรับรูปแบบ indexing ที่ซับซ้อน และเริ่มต้นการถ่ายโอน DMA จาก High Bandwidth Memory ไปยัง Vector Memory⁴⁶ เพราะ scalar unit ทำงานแบบ single-threaded แต่ละ TensorCore สามารถสร้างคำขอ DMA เพียงหนึ่งอันต่อรอบ ซึ่งเป็นคอขวดสำหรับการดำเนินการที่เข้มข้นหน่วยความจำที่ไม่อิ่มตัว MXU หรือ VPU compute throughput
ลำดับชั้นหน่วยความจำที่ป้อน TensorCore กำหนดประสิทธิภาพที่บรรลุได้มากเท่ากับความสามารถการคำนวณดิบ Vector Memory (VMEM) ทำหน้าที่เป็น scratchpad SRAM ที่จัดการด้วยซอฟต์แวร์เฉพาะสำหรับแต่ละ TensorCore โดยทั่วไปมีขนาดหลายสิบเมกะไบต์ คอมไพเลอร์ XLA กำหนดตารางการเคลื่อนย้ายข้อมูลระหว่าง HBM และ VMEM อย่างชัดเจน ตัดสินใจสิ่งที่จะเตรียมไว้ในหน่วยความจำท้องถิ่นที่เร็วและเมื่อไหร่จะเขียนผลลัพธ์กลับ⁴⁷
Common Memory (CMEM) ที่มีอยู่ใน TPU v4 และรุ่นหลังๆ ให้พูลที่แชร์ขนาดใหญ่กว่าที่เข้าถึงได้ทุก TensorCores บนชิป สถาปัตยกรรม TPU v4 จัดสรร 128MB ของ CMEM ที่แชร์ระหว่าง TensorCores สองตัว ทำให้รูปแบบ producer-consumer ที่ซับซ้อนมากขึ้นที่ outputs ของ core หนึ่งป้อน inputs ของอีก core หนึ่งโดยไม่ต้องเดินทางกลับไปยัง HBM⁴⁸
ผลกระทบของโมเดลการโปรแกรมมีความสำคัญอย่างมาก เพราะ scalar unit เป็นแบบ single-thread และ vector memory ต้องการการจัดการอย่างชัดเจน การโปรแกรม TPU คล้ายกับการพัฒนาระบบฝังตัวยุค 1990 มากกว่าการโปรแกรม GPU สมัยใหม่ CUDA ทำนามธรรมการเคลื่อนย้ายหน่วยความจำด้วย unified memory และ caches ที่จัดการด้วยฮาร์ดแวร์ โค้ด TPU (ไม่ว่าจะถูกสร้างโดย XLA หรือเขียนด้วยมือใน Pallas) ต้องประสานงานการถ่ายโอนข้อมูลทุกครั้งอย่างชัดเจน การควบคุมแบบแมนวลทำให้การเพิ่มประสิทธิภาพผู้เชี่ยวชาญเป็นไปได้ แต่ยกระดับสำหรับประสิทธิภาพที่เก่งกาจ
สถาปัตยกรรม High Bandwidth Memory
TPUs สมัยใหม่ใช้ HBM (High Bandwidth Memory) หรือ HBM3e เทคโนโลยีหน่วยความจำที่แตกต่างอย่างมากจาก DDR SDRAM ที่พบใน CPUs และ GDDR ที่ใช้ใน GPUs หลายตัว HBM ซ้อน DRAM dies หลายตัวในแนวตั้งโดยใช้ through-silicon vias (TSVs) จากนั้นวาง stack โดยตรงติดกับ processor die บน silicon interposer⁴⁹ เส้นทางไฟฟ้าสั้นและอินเตอร์เฟซกว้างทำให้ bandwidth สูงกว่าเทคโนโลยีหน่วยความจำแบบเดิมอย่างมาก
TPU v7 Ironwood ใช้ 192GB ของ HBM3e ด้วย bandwidth รวม 7.4 TB/s⁵⁰ ระบบหน่วยความจำถูกแบ่งออกเป็นหลายช่อง แต่ละช่องให้การเข้าถึงอิสระไปยังส่วนแยกต่างหากของความจุทั้งหมด คอมไพเลอร์ XLA และ runtime ต้องแบ่ง tensors อย่างระมัดระวังข้ามช่อง HBM เพื่อเพิ่มการเข้าถึงแบบขนานสูงสุดและหลีกเลี่ยง hotspots ที่ช่องหนึ่งอิ่มตัวขณะที่อื่นๆ นั่งว่าง
ความกว้างอินเตอร์เฟซหน่วยความจำเหนือกว่า DRAM แบบเดิม ที่ช่อง DDR5 อาจให้ความกว้าง 64 bits ช่อง HBM โดยทั่วไปครอบคลุม 1,024 bits⁵¹ ความกว้างสุดขั้วทำให้ bandwidth สูงที่ clock speeds ที่ค่อนข้างเจียมเนื้อเจียมตัว ลดการใช้พลังงานและความท้าทายความสมบูรณ์สัญญาณเมื่อเทียบกับการผลักอินเตอร์เฟซแคบไปยังความถี่หลายจิกะเฮิรตซ์
ลักษณะ latency แตกต่างอย่างมากจากระบบหน่วยความจำ GPU TPUs ขาด hardware-managed caches เกินกว่าบัฟเฟอร์ท้องถิ่นขนาดเล็ก ดังนั้นสถาปัตยกรรมอาศัยซอฟต์แวร์จัดเตรียมข้อมูลลงใน VMEM ล่วงหน้าก่อนที่หน่วยคำนวณจะต้องการ การขาด caches หมายความว่า memory latency ส่งผลกระทบต่อประสิทธิภาพโดยตรงเว้นแต่คอมไพเลอร์จะซ่อน latency ผ่าน prefetching และ double-buffering ได้สำเร็จ⁵²
ข้อจำกัดความจุหน่วยความจำครอบงำปริมาณงานหลายอย่างมากกว่า compute throughput โมเดล 175 พันล้านพารามิเตอร์ที่มี bfloat16 weights ต้องการ 350GB เพื่อเก็บพารามิเตอร์ ซึ่งเกิน 192GB HBM ของ Ironwood แล้วแม้ก่อนที่จะคำนึงถึง activations, optimizer states หรือ gradient buffers การฝึกโมเดลดังกล่าวต้องการเทคนิคที่ซับซ้อน เช่น gradient checkpointing, optimizer state sharding ข้ามชิปหลายตัว และการกำหนดตารางเวลาการอัปเดตพารามิเตอร์ที่ระมัดระวังเพื่อลด memory footprint ให้น้อยที่สุด⁵³
TPU runtime บังคับใช้ข้อกำหนดการจัดวาง tensor เฉพาะเพื่อเพิ่มประสิทธิภาพ MXU สูงสุด เพราะ systolic array ประมวลผลข้อมูลใน 128×8 tiles tensors ควรจัดตำแหน่งกับมิติเหล่านี้เพื่อหลีกเลี่ยงการสูญเสียการ padding⁵⁴ เมทริกซ์ที่มีขนาดไม่ดีบังคับให้ฮาร์ดแวร์ประมวลผล partial tiles ที่มี MACs นั่งว่าง ลด FLOPS utilization โดยตรง คอมไพเลอร์พยายาม pad และปรับรูปร่าง tensors อัตโนมัติ แต่การเลือกเค้าโครงที่มีสติในสถาปัตยกรรมโมเดลสามารถปรับปรุงประสิทธิภาพได้อย่างมาก
SparseCore: การเร่งความเร็ว Embedding เฉพาะทาง
ขณะที่ Matrix Multiply Unit เป็นเลิศในการดำเนินการเมทริกซ์แบบหนาแน่น ปริมาณงานที่เข้มข้น embedding แสดงลักษณะที่แตกต่างอย่างมาก โมเดลแนะนำ ระบบจัดอันดับ และโมเดลภาษาขนาดใหญ่มักเข้าถึงตาราง embedding ขนาดใหญ่มาก (มักหลายร้อยจิกะไบต์) ผ่าน indices ที่ไม่สม่ำเสมอและขึ้นอยู่กับข้อมูล dataflow ที่มีโครงสร้างของ MXU ไม่ให้ประโยชน์สำหรับรูปแบบการเข้าถึงหน่วยความจำแบบ sparse เหล่านี้ กระตุ้นสถาปัตยกรรมเฉพาะทาง
เทคโนโลยีการเชื่อมต่อ: การเดินสายซูเปอร์คอมพิวเตอร์
สถาปัตยกรรมการเชื่อมต่อระหว่างชิป (ICI)
การเชื่อมต่อระหว่างชิปเป็นเทคโนโลยีสำคัญที่ช่วยให้ TPU สามารถทำงานเป็นซูเปอร์คอมพิวเตอร์แบบรวมเป็นหนึ่งเดียวแทนที่จะเป็นตัวเร่งที่แยกจากกัน ไม่เหมือนกับ GPU ที่สื่อสารผ่านเครือข่าย Ethernet หรือ InfiniBand, ICI ใช้การเชื่อมต่อซีเรียลความเร็วสูงแบบกำหนดเองที่เชื่อมต่อ TPU ข้างเคียงโดยตรงด้วยความหน่วงในระดับไมโครวินาทีและแบนด์วิดท์เทราบิตต่อวินาที⁶²
วิวัฒนาการของโทโพโลยีในแต่ละรุ่น TPU สะท้อนถึงความต้องการที่เปลี่ยนแปลงไปสำหรับการขยายขนาดพอด TPU v2, v3, v5e และ v6e ใช้โทโพโลยี torus แบบ 2 มิติซึ่งแต่ละชิปเชื่อมต่อกับเพื่อนบ้านที่ใกล้ที่สุดสี่ตัว (เหนือ ใต้ ตะวันออก และตะวันตก)⁶³ การเชื่อมต่อจะโค้งไปรอบขอบเขต สร้างโทโพโลยีเชิงตรรกะรูปโดนัทที่กำจัดชิปขอบที่มีการเชื่อมต่อน้อยกว่า กริด 16×16 ของ TPU 256 ตัวจึงให้ลักษณะแบนด์วิดท์และความหน่วงที่สม่ำเสมอไม่ว่าชิปสองตัวใดจะสื่อสารกัน
TPU v4 และ v5p อัปเกรดเป็นโทโพโลยี torus แบบ 3 มิติโดยแต่ละชิปเชื่อมต่อกับเพื่อนบ้านหกตัว⁶⁴ มิติเพิ่มเติมจะลดเส้นผ่านศูนย์กลางเครือข่าย—จำนวน hop สูงสุดระหว่างชิปสองตัวใดๆ—จากประมาณ 2√N เป็น 3∛N สำหรับพอด 4,096 ชิป hop สูงสุดจะลดจากประมาณ 128 เป็น 48 ซึ่งลดความหน่วงการสื่อสารในกรณีเลวร้ายที่สุดสำหรับการดำเนินงานที่ซิงโครไนซ์แบบโลก เช่น all-reduce อย่างมาก
โครงสร้าง toroidal ให้ข้อได้เปรียบสำคัญอีกประการหนึ่ง: แบนด์วิดท์ bisection ที่เท่ากันไม่ว่าปริมาณงานจะแบ่งพาร์ติชันข้ามชิปอย่างไร การตัดใดๆ ที่แบ่ง torus ออกเป็นสองส่วนจะข้ามลิงก์จำนวนเท่ากัน ป้องกันกรณีปัญหาที่การจัดวาง job ที่ไม่ดีสร้างคอขวดเครือข่าย⁶⁵ แบนด์วิดท์ bisection ที่สม่ำเสมอทำให้การจัดตารางง่ายขึ้นและเปิดใช้ความสามารถในการกำหนดค่าใหม่ของสวิตช์วงจรออปติคัลที่กล่าวถึงด้านล่าง
ข้อกำหนดแบนด์วิดท์ขยายได้อย่างน่าประทับใจในแต่ละรุ่น TPU v6e ให้แบนด์วิดท์ ICI 13 TB/s ต่อชิป⁶⁶ TPU v5p ถึง 4,800 Gbps ต่อชิปข้ามหกลิงก์ 3D torus⁶⁷ Ironwood ใช้สี่ลิงก์ ICI ด้วยแบนด์วิดท์สองทิศทางรวม 9.6 Tbps แปลเป็น 1.2 TB/s ต่อชิป⁶⁸ เพื่อเปรียบเทียบ เครือข่ายอินเทอร์เฟซ 400GbE ระดับสูงสุดให้แบนด์วิดท์สองทิศทาง 50GB/s—น้อกว่า TPU ICI สมัยใหม่หนึ่งอันดับความสำคัญ
เทคโนโลยีลิงก์ภายในแร็คใช้สายเคเบิลทองแดงต่อตรง (DAC) สำหรับระยะทางสั้นระหว่างชิปในลูกบาศก์ 4×4×4 เดียวกัน⁶⁹ การเชื่อมต่อทองแดงช่วยลดต้นทุนและพลังงานในขณะที่ให้แบนด์วิดท์ที่ต้องการสำหรับชิปที่เชื่อมต่อแน่นหนาที่ดำเนินการซิงโครไนซ์ ลิงก์ระหว่างลูกบาศก์และระดับพอดเปลี่ยนเป็นทรานส์ซีเวอร์ออปติคัล แลกต้นทุนและพลังงานที่สูงขึ้นกับระยะทางและแบนด์วิดท์ที่ต้องการเพื่อขยายไปยังแร็คดาต้าเซ็นเตอร์
การดำเนินงานแบบ collective ใช้ประโยชน์จากคุณสมบัติพิเศษของ ICI การดำเนินงาน All-reduce, all-gather และ reduce-scatter มักซิงโครไนซ์ activations และ gradients ข้ามชิปในระหว่างการเทรน ในคลัสเตอร์ GPU ที่ใช้ Ethernet collectives เหล่านี้จะข้ามเครือข่ายลำดับชั้นที่มีสวิตช์ สายเคเบิล และการ์ดอินเทอร์เฟซเครือข่าย ทำให้เกิดความหน่วงที่แต่ละ hop TPU ICI ใช้อัลกอริธึม collective ที่ปรับให้เหมาะสมโดยตรงในฮาร์ดแวร์ ดำเนินการ all-reduce ได้เร็วกว่าการใช้งาน GPU ที่ใช้ Ethernet แบบเทียบเท่า 10 เท่า⁷⁰
การสลับวงจรออปติคัล: การกำหนดค่าโทโพโลยีแบบไดนามิก
การนำ optical circuit switching (OCS) มาใช้กับ TPU v4 ของ Google เป็นหนึ่งในนวัตกรรมที่สำคัญที่สุดในด้านเครือข่ายดาต้าเซ็นเตอร์ในหลายทศวรรษ เครือข่าย packet-switched แบบดั้งเดิม—ไม่ว่าจะเป็น Ethernet หรือ InfiniBand—สร้างการเชื่อมต่อเชิงตรรกะโดยการ routing แพ็กเก็ต hop-by-hop ผ่านสวิตช์ที่ตรวจสอบ header และส่งต่อไปยังพอร์ตเอาต์พุตที่เหมาะสม OCS แทนที่จะใช้องค์ประกอบออปติคัลที่โปรแกรมได้เพื่อสร้างเส้นทางแสงทางกายภาพโดยตรงระหว่างจุดปลายทาง กำจัดความหน่วงการสลับทั้งหมด⁷¹
เทคโนโลยีหลักอาศัยกระจก MEMS (microelectromechanical systems) ที่หมุนทางกายภาพเพื่อเปลี่ยนทิศทางลำแสง เครื่องส่งสัญญาณใน TPU A ส่งแสงเข้าไปใน OCS กระจกเล็กๆ ภายใน OCS หมุนเพื่อสะท้อนลำแสงนั้นไปยังเครื่องรับใน TPU B การเชื่อมต่อจะกลายเป็นเส้นทางออปติคัลโดยตรงจาก A ไป B โดยมีความหน่วงที่เพิ่มขึ้นเป็นศูนย์นอกเหนือจากการแพร่กระจายของแสงผ่านไฟเบอร์⁷²
ความเร็วการกำหนดค่าใหม่กำหนดความเป็นไปได้ในทางปฏิบัติของ OCS ในระบบโปรดักชัน การใช้งานของ Google บรรลุเวลาการสลับที่ต่ำกว่า 10 นาโนวินาที—เร็วกว่าเวลาไปกลับของโปรโตคอลเครือข่ายทั่วไป⁷³ ความเร็วการกำหนดค่าใหม่ช่วยให้สามารถเปลี่ยนแปลงโทโพโลยีแบบไดนามิกให้ตรงกับความต้องการของปริมาณงานโดยไม่รบกวนงานที่ทำอยู่หรือต้องมีการวิศวกรรมการจราจรที่ประสานงานอย่างระมัดระวัง
TPU v5p แสดง OCS ในระดับขนาดใหญ่มาก สถาปัตยกรรมใช้สวิตช์วงจรออปติคัลที่ให้แบนด์วิดท์รวมสี่เพตาบิตต่อวินาทีข้าม switching fabric⁷⁴ superpod v5p เดี่ยวต้องการหน่วย OCS 48 หน่วยที่จัดการพอร์ตออปติคัล 13,824 พอร์ตเพื่อเดิน 8,960 ชิปในการกำหนดค่า 3D torus 16×20×28⁷⁵ ระบบการสลับแสดงถึงการใช้งานเครือข่ายออปติคัลที่ใหญ่ที่สุดอันดับหนึ่งในสภาพแวดล้อมคอมพิวติ้งใดๆ
OCS ให้ความสามารถที่เป็นไปไม่ได้กับเครือข่ายแบบดั้งเดิม โทโพโลยีทางกายภาพและโทโพโลยีเชิงตรรกะแยกออกจากกันอย่างสมบูรณ์— TPU สองตัวในมุมตรงข้ามของดาต้าเซ็นเตอร์ดูเหมือนเพื่อนบ้านที่อยู่ติดกันหาก OCS สร้างเส้นทางออปติคัลโดยตรง ชิปหรือลิงก์ที่เสียจะถูก routing รอบๆ โดยการโปรแกรมกระจกใหม่เพื่อไม่รวมคอมโพเนนต์ที่เสียและรักษาโครงสร้าง torus เชิงตรรกะ งานใหม่ได้รับ "slices" ของขนาดใดๆ โดยการโปรแกรม OCS เพื่อสร้างการกำหนดค่าพอดที่เหมาะสมโดยไม่ต้องเดิน re-cable แร็คทางกายภาพ⁷⁶
สถาปัตยกรรมผสานรวมกับเครือข่ายดาต้าเซ็นเตอร์ Jupiter ของ Google เพื่อขยายเกินพอดเดียว Jupiter ให้แบนด์วิดท์ bisection หลายเพตาบิตต่อวินาทีข้ามดาต้าเซ็นเตอร์ทั้งหมดโดยใช้สวิตช์ซิลิคอนแบบกำหนดเองและ control plane ของ Google⁷⁷ superpod TPU หลายตัวเชื่อมต่อผ่าน Jupiter fabric รองรับคลัสเตอร์ของตัวเร่งถึง 400,000 ตัวในทางทฤษฎีหากความจุเครือข่ายอนุญาต⁷⁸
ลักษณะการใช้พลังงานและความน่าเชื่อถือชอบ optical circuit switching สำหรับการใช้งานระดับ TPU สวิตช์แพ็กเก็ตแบบดั้งเดิมใช้พลังงานมากในการประมวลผลและส่งต่อแพ็กเก็ตในอัตราเทราบิตต่อวินาที สวิตช์ OCS ใช้พลังงานเฉพาะในการใช้งานกระจก MEMS ในระหว่างเหตุการณ์การกำหนดค่าใหม่ จากนั้นก็นิ่งไม่ทำงาน ส่งผ่านแสงด้วยการสูญเสียน้อยที่สุดในขณะที่การเชื่อมต่อยังคงเสถียร⁷⁹ ความเรียบง่ายของสถาปัตยกรรมปรับปรุงความน่าเชื่อถือโดยกำจัดตรรกะการประมวลผลและการบัฟเฟอร์แพ็กเก็ตที่ซับซ้อนซึ่งเสี่ยงต่อข้อผิดพลาดและความผิดปกติของประสิทธิภาพ
สถาปัตยกรรมพอดและลักษณะการขยายขนาด
พอด TPU แสดงถึงหน่วยเดี่ยวที่ใหญ่ที่สุดของ TPU ที่เชื่อมต่อผ่าน ICI ก่อตั้งเป็นตัวเร่งแบบรวมเป็นหนึ่งเดียว โครงสร้างทางกายภาพสร้างแบบลำดับชั้นจากชิปแต่ละตัวไปเป็นถาดไปเป็นลูกบาศก์ไปเป็นแร็คไปเป็นพอดสมบูรณ์⁸⁰ การเข้าใจลำดับชั้นมีความสำคัญสำหรับการคิดเหตุผลเกี่ยวกับความจุหน่วยความจำ แบนด์วิดท์การสื่อสาร และความทนทานต่อความผิดพลาดในระดับต่างๆ
บล็อกสร้างพื้นฐานประกอบด้วยสี่ชิปบนถาดเดียวที่เชื่อมต่อกับ CPU โฮสต์ผ่าน PCIe⁸¹ การเชื่อมต่อ PCIe จัดการการดำเนินงาน control plane การโหลดโปรแกรมเริ่มต้น และ infeed/outfeed สำหรับข้อมูลเทรนนิ่งและผลลัพธ์การอนุมาน การสื่อสารระหว่างชิปที่แท้จริงสำหรับการเทรนแบบกระจายไหลผ่าน ICI แทนที่จะเป็น PCIe หลีกเลี่ยงคอขวดแบนด์วิดท์ PCIe
ถาดสิบหก (64 ชิป) ก่อให้เกิดลูกบาศก์ 4×4×4 เดียว—หน่วยพื้นฐานสำหรับการสร้างพอด ภายในลูกบาศก์ การเชื่อมต่อ ICI ทั้งหมดใช้สายเคเบิลทองแดงต่อตรงเนื่องจากชิปอยู่ในแร็คเดียวกันด้วยระยะทางทางกายภาพที่สั้น⁸² ลูกบาศก์ใช้ 3D torus สมบูรณ์ด้วยการเชื่อมต่อแบบ wrap-around สร้างหน่วย 64 ชิปที่มีอิสระซึ่งสามารถทำงานแยกได้ในทางทฤษฎี
พอด TPU v4 ขยายไปถึง 64 ลูกบาศก์รวม 4,096 ชิป⁸³ การเชื่อมต่อระหว่างลูกบาศก์เปลี่ยนเป็นลิงก์ออปติคัลที่จัดการโดย optical circuit switching fabric OCS สามารถจัดเตรียมชิป 4,096 ตัวนี้เป็นพอดใหญ่เดี่ยว พอดเล็กหลายตัวที่เป็นอิสระ หรือกำหนดค่าใหม่แบบไดนามิกกลางงานหากจำเป็น ความยืดหยุ่นช่วยให้ผู้ปฏิบัติการดาต้าเซ็นเตอร์สามารถสมดุลการใช้งานข้ามขนาดงานและลำดับความสำคัญต่างๆ
TPU v5p ผลักขนาดพอดไปที่ 8,960 ชิปใน 3D torus 16×20×28⁸⁴ มิติเฉพาะสะท้อนการปรับให้เหมาะสมแบนด์วิดท์และเส้นผ่านศูนย์กลางอย่างระมัดระวัง—การแยกตัวประกอบเฉพาะมีความสำคัญสำหรับโทโพโลยีเครือข่าย! พอดให้การคำนวณ 4.45 exaflops และแสดงถึงหนึ่งในการกำหนดค่าพอดเดี่ยวที่ใหญ่ที่สุดที่ใช้งานในโปรดักชัน
Ironwood รองรับทั้งพอด 256 ชิปสำหรับการใช้งานขนาดเล็กและ superpod 9,216 ชิปสำหรับการเทรนโมเดล frontier ขนาดใหญ่⁸⁵ การกำหนดค่า 9,216 ชิปให้ 42.5 FP8 exaflops—การคำนวณมากกว่าทั้งรายชื่อ Top500 ของซูเปอร์คอมพิวเตอร์ที่มีเพียงห้าปีก่อนหน้า⁸⁶ ระดับดังกล่าวกำหนดใหม่ว่าองค์กรสามารถทำอะไรได้ด้วยการเทรนแบบซิงโครนัสแทนที่จะเป็นแนวทาง pipelined หรือ asynchronous
ประสิทธิภาพการขยายขนาดกำหนดว่าพอดที่ใหญ่กว่าช่วยได้จริงหรือไม่ ค่าใช้จ่ายการสื่อสารเพิ่มขึ้นตามขนาดพอดเมื่อชิปใช้เวลามากขึ้นในการซิงโครไนซ์แทนที่จะเป็นการคำนวณ Google Research เผยแพร่ผลลัพธ์ที่แสดงประสิทธิภาพการขยายขนาด 95% ที่ 32,768 TPUs สำหรับปริมาณงานเฉพาะ หมายความว่า TPU 32,768 ตัวให้ประสิทธิภาพ 95% ของที่การขยายขนาดเชิงเส้นที่สมบูรณ์แบบจะทำนาย⁸⁷ ประสิทธิภาพเกิดจาก collectives ที่เร่งด้วยฮาร์ดแวร์ การแปลงคอมไพเลอร์ที่ปรับให้เหมาะสม และแนวทางอัลกอริธึมที่ชาญฉลาดเพื่อลดความถี่การซิงโครไนซ์ gradient
ความทนทานต่อความผิดพลาดในระดับพอดต้องการการจัดการที่ซับซ้อน ความน่าจะเป็นทางสถิติรับประกันความผิดพลาดของคอมโพเนนต์ในระบบใดๆ ที่มีชิปหลายพันตัวทำงานต่อเนื่อง optical circuit switch ช่วยให้เกิดการลดทอนอย่างสง่างามโดยการกำหนดค่าใหม่รอบๆ คอมโพเนนต์ที่เสีย การ checkpointing การเทรนเกิดขึ้นในช่วงเวลาปกติ (โดยทั่วไปทุกๆ ไม่กี่นาที) ดังนั้นความผิดพลาดของงานต้องการการรีสตาร์ทเฉพาะจาก checkpoint สุดท้ายแทนที่จะเริ่มต้นใหม่⁸⁸
Software Stack: Compilers, Frameworks และ Programming Models
XLA Compiler: การปรับปรุงประสิทธิภาพ Computation Graphs
XLA (Accelerated Linear Algebra) เป็นรากฐานของ software stack ของ TPU ที่ทำการ compile high-level framework operations เป็น optimized machine code สำหรับการทำงานบน TPU⁸⁹ Compiler นี้ใช้การปรับปรุงประสิทธิภาพแบบเข้มข้นที่เป็นไปไม่ได้ใน general-purpose compilers เนื่องจากใช้ประโยชน์จากความรู้เฉพาะด้านเกี่ยวกับ machine learning workloads และลักษณะของสถาปัตยกรรม TPU
Fusion เป็นการปรับปรุงประสิทธิภาพที่มีผลกระทบสูงสุดของ XLA Compiler จะวิเคราะห์ computation graphs เพื่อระบุลำดับของ operations ที่สามารถทำงานได้โดยไม่ต้องสร้าง intermediate tensors ตัวอย่างง่าย ๆ: element-wise operations เช่น relu(batch_norm(conv(x))) ปกติต้องเขียน convolution output ไปยัง memory อ่านมันสำหรับ batch normalization เขียนผลลัพธ์นั้นไปยัง memory และอ่านอีกครั้งสำหรับ ReLU XLA ผสาน operations เหล่านี้เป็น kernel เดียวที่สร้าง ReLU output สุดท้ายโดยไม่มี intermediate memory traffic⁹⁰
ผลกระทบของ Fusion ขยายตามสถาปัตยกรรมของ TPU Memory bandwidth จำกัด workloads หลายตัวมากกว่า compute throughput—MXU สามารถทำ matrix multiplications ได้เร็วกว่าที่ memory system สามารถป้อนข้อมูลได้ การกำจัด intermediate memory writes และ reads ผ่าน fusion แปลงเป็นการปรับปรุงประสิทธิภาพโดยตรง มักจะให้ speedup 2× หรือมากกว่าสำหรับ networks ที่มี activation functions เยอะ⁹¹
Memory layout transformations ปรับปรุง tensor storage สำหรับข้อกำหนดของ hardware Neural networks มักจะแสดง tensors ในรูปแบบ NHWC (batch, height, width, channels) สำหรับ indexing ที่เข้าใจง่าย แต่ TPU MXUs ทำงานได้ดีที่สุดกับ layouts ที่สอดคล้องกับ 128×8 tiles⁹² XLA transpose, reshape และ pad tensors โดยอัตโนมัติเพื่อให้ตรงกับความต้องการของ hardware โดยใส่ layout transformations เฉพาะที่จำเป็นเท่านั้น และบางครั้งส่ง preferred layouts กลับไปใน graph เพื่อลด total transformation overhead
Compiler ใช้ sophisticated constant folding และ dead code elimination ML graphs มี subgraphs ที่ outputs ขึ้นอยู่กับ constants เท่านั้น—batch normalization parameters, inference dropout rates และ shape calculations ที่สามารถทำงานครั้งเดียวแทนที่จะทำทุก batch XLA ประเมิน subgraphs เหล่านี้ที่ compile time และแทนที่ด้วย constant tensors เพื่อลด runtime work⁹³
Cross-replica optimization ใช้ประโยชน์จากความรู้เกี่ยวกับ distributed execution เมื่อ training ข้าม TPU cores หลายตัว operations บางตัว (เช่น batch normalization statistics) ต้องการการรวม across all replicas XLA ระบุ patterns เหล่านี้และสร้าง optimized collective operations ที่ใช้ประโยชน์จาก hardware-accelerated all-reduce ของ ICI แทนที่จะใช้ aggregation ผ่าน explicit message passing⁹⁴
Compiler มุ่งเป้าไปที่ intermediate representation ชื่อ Mosaic โดยเฉพาะสำหรับ TPUs Mosaic ทำงานใน abstraction level ที่สูงกว่า assembly language แต่ต่ำกว่า input computation graph ภาษานี้เปิดเผย TPU architectural features เช่น systolic arrays, vector memory และ VMEM staging ขณะที่ซ่อน low-level details เช่น instruction scheduling และ register allocation⁹⁵
Auto-tuning capabilities เลือก optimal tile sizes และ operation parameters ผ่านการค้นหาเชิงประจักษ์ ระบบ XLA Auto-Tuning (XTAT) ลอง fusion strategies, memory layouts และ tile dimensions ที่แตกต่างกัน profile ประสิทธิภาพของแต่ละรูปแบบ และเลือก configuration ที่เร็วที่สุด⁹⁶ การค้นหาอาจต้องใช้ compile time มากสำหรับ models ที่ซับซ้อน แต่สร้าง runtime speedups ที่น่าทึ่งโดยการค้นพบการปรับปรุงประสิทธิภาพที่ขัดกับสัญชาตญาณที่มนุษย์ไม่ค่อยระบุด้วยตนเอง
JAX: Composable Transformations และ SPMD
JAX ให้ NumPy-compatible interface สำหรับ numerical computation ด้วย automatic differentiation, JIT compilation ไปยัง XLA และ first-class support สำหรับ program transformation⁹⁷ Functional programming paradigm และ composable transformation model ของ framework สอดคล้องกับ TPU execution models และ distributed parallelism patterns อย่างเป็นธรรมชาติ
JAX abstraction หลักใช้ mathematical transformations กับ functions Grad (f) คำนวณ gradient ของ f Jit (f) JIT-compile f ไปยัง XLA vmap(f) ทำ vectorize f เหนือมิติใหม่ สิ่งสำคัญคือ transformations compose: jit(grad(vmap(f))) ทำงานตรงตามที่คาดหวัง โดย compile vectorized gradient function⁹⁸ Compositional model ช่วยให้สามารถสร้าง distributed training loops ที่ซับซ้อนจาก components ที่เรียบง่ายและทดสอบได้
SPMD (Single Program, Multiple Data) เป็น distributed execution model ของ JAX Programmers เขียนโค้ดเสมือนกำหนดเป้าหมาย device เดียว จากนั้นเพิ่ม sharding annotations ที่บอกว่าจะ partition tensors ข้าม TPU cores หลายตัวอย่างไร XLA compiler และ GSPMD (General SPMD) subsystem แทรก communication operations โดยอัตโนมัติเพื่อรักษา program semantics ขณะที่ทำงานข้าม distributed devices⁹⁹
Sharding annotations ใช้ PartitionSpec เพื่อประกาศ distribution strategies PartitionSpec('batch', None) แบ่ง first dimension ของ tensor ข้าม 'batch' axis ของ device mesh ขณะที่ replicate second dimension PartitionSpec(None, 'model') ใช้ tensor parallelism โดย partition second dimension Annotations สามารถ compose ด้วย arbitrary tensor ranks และ device mesh dimensions¹⁰⁰
Automatic parallelization ของ GSPMD กำจัด boilerplate code จำนวนมาก Traditional distributed training ต้องแทรก all-gather ด้วยตนเองก่อน operations ที่ต้องการ full tensors, reduce-scatter หลังจากคำนวณ distributed gradients และ all-reduce สำหรับ global reductions GSPMD วิเคราะห์ sharding specifications และแทรก appropriate collectives โดยอัตโนมัติ ปลดปล่อย programmers ให้มุ่งเน้นไปที่ algorithm แทนที่จะเป็น communication engineering¹⁰¹
Compiler ส่ง sharding decisions ผ่าน computation graph โดยใช้ constraint solving หาก operation A ส่งออก sharded tensor ที่ operation B ใช้ GSPMD สรุป optimal sharding ของ B ตามวิธีที่ output ถูกใช้ อาจแทรก resharding operations เฉพาะที่จำเป็นทางคณิตศาสตร์เท่านั้น¹⁰² Automated inference ป้องกัน "sharding spaghetti" ที่รบกวน hand-written distributed code
JAX ให้การควบคุมแบบ fine-grained เมื่อ automation ไม่เพียงพอ with_sharding_constraint บังคับ specific sharding ใน graph locations โดย override automatic inference Custom PJIT (parallel JIT) annotations ระบุ exact device placement และ sharding strategies สำหรับ performance-critical code paths Layered model ช่วยให้ rapid prototyping ด้วย automatic sharding ขณะที่รองรับ expert optimization เมื่อจำเป็น¹⁰³
Shardy ปรากฏเป็น successor ของ GSPMD ในปี 2025 โดยใช้ improved constraint propagation algorithms และ handling ที่ดีขึ้นของ dynamic shapes¹⁰⁴ ระบบใหม่เปิดเผย optimization opportunities เพิ่มเติมโดยการใช้เหตุผลเกี่ยวกับ sharding choices ร่วมกันข้าม graph regions ที่ใหญ่กว่าแทนที่จะเป็น operation-by-operation
PyTorch/XLA: การนำ PyTorch มาสู่ TPUs
PyTorch/XLA ช่วยให้รัน PyTorch models บน TPUs ได้ด้วยการเปลี่ยนแปลงโค้ดเพียงเล็กน้อย เชื่อมช่องว่างระหว่าง imperative programming model ของ PyTorch และ graph-based compilation ของ XLA¹⁰⁵ การรวมนี้สมดุลระหว่างการรักษา developer experience ของ PyTorch กับการเปิดเผย TPU-specific optimizations
ความท้าทายพื้นฐานมาจาก eager execution philosophy ของ PyTorch PyTorch ทำ operations ทันทีเมื่อ Python statements ทำงาน ทำให้สามารถ debug ด้วย standard tools และ control flow ที่เป็นธรรมชาติ XLA ต้องการ capture complete computation graphs ก่อน compilation สร้างความตึงเครียดระหว่าง eager execution และ performance benefits ของ graph compilation¹⁰⁶
PyTorch/XLA 2.4 แนะนำ eager mode support เพื่อแก้ไข impedance mismatch การใช้งานนี้ trace PyTorch operations เป็น XLA graphs แบบ dynamic ทำให้ developers เขียน standard PyTorch code ขณะที่ยังได้ประโยชน์จาก XLA compilation¹⁰⁷ Mode นี้แลก compilation optimization opportunities บางส่วนกับ development velocity และ debugging simplicity
Graph mode ยังคงเป็น primary path สำหรับ production deployments Developers ทำเครื่องหมาย functions สำหรับ XLA compilation อย่างชัดเจนโดยใช้ decorators หรือ compilation APIs Explicit annotations ช่วยให้ aggressive optimization แต่ต้องการความเข้าใจว่า operations ใดควร fuse เป็น XLA graph เดียวเทียบกับ execute แยกกัน¹⁰⁸
Pallas integration นำ custom kernel development มาสู่ PyTorch/XLA Pallas ให้ low-level language สำหรับเขียน TPU kernels เมื่อ automatic fusion ของ XLA ไม่เพียงพอหรือ specialized operations ต้องการ hand-optimization¹⁰⁹ ภาษานี้เปิดเผย TPU memory hierarchy (VMEM, CMEM, HBM) และ compute units (MXU, VPU) ขณะที่ยังคง high-level กว่า raw assembly
Built-in Pallas kernels ใช้ performance-critical operations เช่น FlashAttention และ PagedAttention FlashAttention's tiled attention computation ลด memory bandwidth requirements จาก O(n²) เป็น O(n) สำหรับ sequence length n ช่วยให้ models ประมวลผล sequences ที่ยาวกว่าภายใน fixed memory budgets¹¹⁰ PagedAttention ปรับปรุง key-value cache management สำหรับ serving บรรลุ speedup 5× เทียบกับ padded implementations¹¹¹
PyTorch/XLA bridge พิสูจน์ว่ามีความสำคัญสำหรับ vLLM TPU—high-performance serving framework ที่ออกแบบสำหรับ GPUs เดิม การใช้งานนี้ใช้ JAX เป็น intermediate lowering path แม้สำหรับ PyTorch models โดยใช้ประโยชน์จาก superior parallelism support ของ JAX ขณะที่รักษา PyTorch frontend compatibility¹¹² สถาปัตยกรรมนี้บรรลุการปรับปรุงประสิทธิภาพ 2-5× ตลอดปี 2025 เทียบกับ initial prototypes
ความท้าทายด้าน model compatibility ยังคงอยู่แม้จะมีการปรับปรุง PyTorch operations บางตัวขาด XLA equivalents บังคับให้ fallback ไป CPU execution ที่ลดประสิทธิภาพ Dynamic control flow ได้รับการสนับสนุนไม่ดีจาก graph compilation มักต้องการการเปลี่ยนแปลงสถาปัตยกรรมเพื่อแทนที่ dynamic behavior ด้วย static, compilable alternatives PyTorch/XLA repository จัดทำเอกสาร compatibility และให้ migration guides สำหรับ problematic patterns ที่พบบ่อย¹¹³
Precision Formats: BFloat16, FP8 และ Quantization
การรองรับ reduced-precision arithmetic ของ TPU ช่วยให้เกิดการปรับปรุงประสิทธิภาพและ memory อย่างมากในขณะที่รักษาคุณภาพ model ที่ยอมรับได้ การเข้าใจ numerical properties ของรูปแบบที่แตกต่างกันและเมื่อใดควรใช้แต่ละรูปแบบเป็นสิ่งสำคัญสำหรับการบรรลุประสิทธิภาพที่เหมาะสม¹¹⁴
BFloat16 เป็นการเดิมพันช่วงแรกของ Google เกี่ยวกับ reduced-precision training ปรากฏครั้งแรกใน TPU v2 รูปแบบนี้รักษา 8-bit exponent ของ FP32 ขณะที่ตัด mantissa เหลือ 7 bits (บวก sign bit)¹¹⁵ Full exponent range ป้องกัน underflow และ overflow ที่รบกวน early FP16 training ที่ gradients หนีออกจาก representable range ของ FP16 บ่อยครั้ง
Reduced mantissa แนะนำ quantization error แต่ไม่ค่อยส่งผลต่อคุณภาพ model สุดท้าย Engineers สังเกตว่า models ที่ train ใน bfloat16 มักตรงกับ FP32-trained baselines ภายใน statistical noise อาจเพราะ quantization ทำหน้าที่เป็น regularization ป้องกัน overfitting กับ tiny numerical details¹¹⁶ รูปแบบนี้ลด memory bandwidth และ capacity requirements ครึ่งหนึ่งเทียบกับ FP32 แปลงเป็น performance gains บน memory-bound workloads โดยตรง
FP8 นำ reduced precision ไปไกลกว่า โดยบีบอัด weights และ activations เป็น 8 bits Standard encodings สองตัวมีอยู่: E4M3 (4-bit exponent, 3-bit mantissa) ให้ความสำคัญกับ precision สำหรับ forward passes ขณะที่ E5M2 (5-bit exponent, 2-bit mantissa) ให้ความสำคัญกับ range สำหรับ backward passes ที่ gradient magnitudes แตกต่างกันมาก¹¹⁷ Ironwood ใช้ native FP8 support สำหรับทั้งสองรูปแบบ ขณะที่ TPUs รุ่นเก่าเลียนแบบ FP8 ผ่าน software transformations¹¹⁸
Quantization awareness ระหว่าง training ช่วยให้ FP8 ประสบความสำเร็จทางตัวเลข Models ที่ train ตั้งแต่ต้นด้วย FP8 หรือ fine-tune ด้วย FP8-aware techniques เรียนรู้ weight distributions ที่ทนต่อ precision จำกัดของรูปแบบ Post-training quantization (การแปลง FP32 models เป็น FP8 หลัง training) มักลดคุณภาพโดยไม่มี calibration ที่ระมัดระวัง¹¹⁹
INT8 quantization ให้ memory savings และ inference speedups ที่ยิ่งใหญ่กว่า Accurate Quantized Training (AQT) ของ Google ช่วยให้ INT8 training บน TPUs ด้วยการสูญเสียคุณภาพเพียงเล็กน้อยเทียบกับ bfloat16 baselines¹²⁰ เทคนิคนี้ใช้ quantization-aware training ตั้งแต่ต้น ทำให้ models ปรับตัวกับข้อจำกัดของ INT8 ระหว่างการเรียนรู้แทนที่จะผ่าน post-training approximation
Mixed-precision strategies รวมรูปแบบอย่างมีกลยุทธ์ Forward passes อาจใช้ FP8 สำหรับ activations และ weights, backward passes ใช้ FP8 E5M2 หรือ bfloat16 สำหรับ gradients และ optimizer states ยังคงใน FP32 เพื่อ numerical stability ระหว่าง weight updates¹²¹ Mixed approach สมดุลความเร็ว memory และความแม่นยำ มักบรรลุ 90%+ ของคุณภาพ FP32 ขณะที่วิ่งเร็วกว่า 4×
Precision tradeoffs ขยายไปเกิน speed และ memory รวมถึงการพิจารณา numerical stability Batch normalization, layer normalization และ softmax ต้องการ numerical handling ที่ระมัดระวังใน reduced precision Large exponentials ใน softmax สามารถ overflow FP8 หรือ bfloat16 ranges การลบ maximum logit ก่อน exponentiation ป้องกัน overflow ขณะที่รักษา mathematical equivalence¹²² XLA compiler ใช้ transformations เหล่านี้โดยอัตโนมัติเมื่อปลอดภัย แต่ custom operations บางครั้งต้องการ manual numerical engineering
รูปแบบการเขียนโปรแกรมและกลยุทธ์การประมวลผลแบบขนาน
SPMD และการแบ่งพาร์ติชันอัตโนมัติ
แนวทาง Single Program, Multiple Data (SPMD) เป็นหัวใจสำคัญที่กำหนดวิธีคิดของโปรแกรมเมอร์เกี่ยวกับการทำงานของ TPU แทนที่จะเขียนโค้ดส่งผ่านข้อความแบบชัดเจนเพื่อประสานงานหลายโปรเซส นักพัฒนาเขียนโปรแกรมเดียวและใส่หมายเหตุเกี่ยวกับวิธีการแบ่งพาร์ติชันข้อมูลผ่านหลายอุปกรณ์¹²³ คอมไพเลอร์จะจัดการรายละเอียดด้านเทคนิคของการกระจาย การสื่อสาร และการซิงโครไนส์
GSPMD (General SPMD) ใช้งานตรรกะการแบ่งพาร์ติชันอัตโนมัติใน XLA ระบบจะวิเคราะห์หมายเหตุการแบ่งส่วน tensor และโครงสร้างกราฟการคำนวณเพื่อกำหนดว่าการดำเนินการต่างๆ ทำงานบนอุปกรณ์ใด และต้องการการสื่อสารแบบใดเพื่อรักษาความถูกต้องของความหมาย¹²⁴ การทำงานแบบอัตโนมัติช่วยขจัดข้อผิดพลาดหลายประเภทที่พบบ่อยในโค้ดกระจายที่เขียนด้วยมือ เช่น รูปร่าง tensor ที่ไม่ตรงกัน ลำดับการดำเนินการรวมที่ไม่ถูกต้อง และการค้างเนื่องจากการซิงโครไนส์ที่ไม่เหมาะสม
เอนจิ้นการแพร่กระจายข้อจำกัดของคอมไพเลอร์สามารถอนุมานการตัดสินใจแบ่งส่วนจากหมายเหตุขั้นต่ำ การใส่หมายเหตุเฉพาะการแบ่งส่วน input และ output ของโมเดลมักเพียงพอแล้ว GSPMD จะแพร่กระจายข้อจำกัดผ่านการดำเนินการระดับกลาง และเลือกการกระจายที่มีประสิทธิภาพโดยอัตโนมัติ¹²⁵ เมื่อมีการแบ่งส่วนที่ถูกต้องหลายแบบสำหรับการดำเนินการหนึ่ง คอมไพเลอร์จะประเมินต้นทุนการสื่อสารของทางเลือกต่างๆ และเลือกตัวเลือกที่มีต้นทุนต่ำสุด
การปรับปรุงขั้นสูงจะทำให้การสื่อสารทับซ้อนกับการคำนวณ การดำเนินการ All-reduce ที่ซิงโครไนส์ gradient ข้ามหลาย replica สามารถเริ่มต้นทันทีที่ gradient ของเลเยอร์แรกเสร็จสิ้น และทำงานแบบขนานกับ backward pass สำหรับเลเยอร์ถัดไป¹²⁶ คอมไพเลอร์จะจัดตารางเวลา collective โดยอัตโนมัติเพื่อเพิ่มการทับซ้อนสูงสุด ลดเวลาการสื่อสารลงเหลือ 2 เท่าหรือมากกว่าเมื่อเทียบกับการทำงานแบบลำดับ
Rematerialization แลกเปลี่ยนการคำนวณแทนหน่วยความจำ แทนที่จะเก็บ forward pass activation ทั้งหมดสำหรับการคำนวณ gradient คอมไพเลอร์จะคำนวณ activation ซ้ำแบบเลือกสรรระหว่าง backward pass เมื่อแรงกดดันหน่วยความจำเกินขีดจำกัด¹²⁷ การแลกเปลี่ยนนี้ทำงานได้ดีเป็นพิเศษบน TPU ที่การคำนวณมักเร็วกว่าแบนด์วิดท์หน่วยความจำ ทำให้การคำนวณซ้ำถูกกว่าการเคลื่อนย้ายหน่วยความจำ
Data Parallelism, Tensor Parallelism และ Pipeline Parallelism
Data parallelism เป็นกลยุทธ์การฝึกแบบกระจายที่ตรงไปตรงมาที่สุด: ทำซ้ำโมเดลสมบูรณ์ใน N อุปกรณ์ และประมวลผลแบตช์ข้อมูลที่แตกต่างกันในแต่ละ replica หลังจากคำนวณ gradient ในเครื่อง all-reduce จะรวม gradient ข้าม replica และอุปกรณ์ทั้งหมดจะใช้การอัปเดตน้ำหนักที่เหมือนกัน¹²⁸ แนวทางนี้ขยายขนาดแบบเชิงเส้นจนกว่าเวลาการสื่อสารจะเหนือกว่าเวลาการคำนวณ โดยทั่วไปจะเกิดขึ้นประมาณ 1,000 GPU ด้วยเครือข่าย Ethernet แต่ 10,000+ TPU ด้วย ICI¹²⁹
Tensor parallelism (เรียกอีกชื่อหนึ่งว่า model parallelism) แบ่งพาร์ติชันการดำเนินการแต่ละรายการข้ามอุปกรณ์ การคูณเมทริกซ์ Y = W @ X แยกเมทริกซ์น้ำหนัก W ข้ามอุปกรณ์ โดยแต่ละเครื่องคำนวณส่วนหนึ่งของผลลัพธ์¹³⁰ กลยุทธ์นี้ช่วยให้สามารถฝึกโมเดลที่เกินหน่วยความจำของอุปกรณ์เดียวโดยการกระจายการจัดเก็บพารามิเตอร์และการคำนวณ
รูปแบบการสื่อสารสำหรับ tensor parallelism แตกต่างอย่างมากจาก data parallelism แทนที่จะเป็น all-reduce หลังแต่ละเลเยอร์ tensor parallelism ต้องการ all-gather ก่อนการดำเนินการที่ต้องการ tensor เต็ม และ reduce-scatter หลังการคำนวณแบบกระจาย¹³¹ ปริมาณการสื่อสารขยายตามขนาด activation ของโมเดลแทนที่จะเป็นขนาดพารามิเตอร์ สร้างคอขวดที่แตกต่างจาก data parallelism
Pipeline parallelism แบ่งพาร์ติชันเลเยอร์โมเดลตามลำดับข้ามอุปกรณ์ ประมวลผล micro-batch ที่แตกต่างกันในหลายขั้นตอนพร้อมกัน GPipe ได้แนะนำกลยุทธ์นี้ด้วยการจัดตารางเวลาอย่างระมัดระวังเพื่อเพิ่มการใช้งาน pipeline สูงสุดในขณะที่จำกัดการใช้หน่วยความจำ¹³² แต่ละอุปกรณ์ประมวลผล forward pass ของ micro-batch หนึ่ง ส่ง activation ไปยังขั้นตอนถัดไป จากนั้นประมวลผล micro-batch ถัดไป—สร้าง pipeline ที่อุปกรณ์ทั้งหมดทำงานต่อเนื่องหลังจากการเริ่มต้น
Gradient staleness ทำให้ pipeline parallelism ซับซ้อน อุปกรณ์อัปเดตน้ำหนักโดยใช้ gradient ที่คำนวณจาก activation ที่อาจเก่าไปหลายสิบ micro-batch สร้างความเก่าที่อาจทำร้ายการบรรจบ¹³³ อัลกอริทึมการจัดตารางเวลาที่ซับซ้อนอย่าง PipeDream ช่วยลดความเก่าในขณะที่รักษา throughput สูง และผลลัพธ์เชิงประจักษ์แสดงให้เห็นว่าโมเดลส่วนใหญ่สามารถทนต่อความเก่าปานกลางได้โดยไม่เสื่อมสลายคุณภาพ
3D parallelism รวมกลยุทธ์ทั้งสามแบบ Data parallelism กระจายใน "มิติข้อมูล" tensor parallelism ใน "มิติโมเดล" และ pipeline parallelism ใน "มิติ pipeline"¹³⁴ การสมดุลมิติต่างๆ อย่างระมัดระวังตามสถาปัตยกรรมโมเดล โครงสร้างฮาร์ดแวร์ และต้นทุนการสื่อสารจะเพิ่ม throughput สูงสุด โมเดลระดับ GPT-3 มักใช้ 3D parallelism ด้วย data parallelism ข้าม 8-16 replica, tensor parallelism ข้าม 4-8 GPU และ pipeline parallelism ข้าม 4-16 ขั้นตอน
กลยุทธ์การแบ่งส่วนและการปรับปรุง
การเลือกกลยุทธ์การแบ่งส่วนต้องเข้าใจการดำเนินการทางคณิตศาสตร์และการพึ่งพาข้อมูล การคูณเมทริกซ์ C = A @ B อนุญาตให้มีการแบ่งส่วนที่ถูกต้องหลายแบบ: ทำซ้ำทั้ง A และ B และคำนวณผลลัพธ์บางส่วน (การสื่อสารก่อนการคำนวณ), แบ่งส่วน B ตามคอลัมน์และรวบรวมผลลัพธ์ (การสื่อสารหลังการคำนวณ), หรือแบ่งส่วน A ตามแถวและ B ตามคอลัมน์โดยไม่มีการสื่อสารแต่มีเมทริกซ์ต่ออุปกรณ์ที่เล็กกว่า¹³⁵
ต้นทุนการดำเนินการ collective กำหนดกลยุทธ์ที่เหมาะสม ต้นทุน All-reduce ขยายแบบเชิงเส้นกับขนาด tensor แต่ขยายแบบต่ำกว่าเชิงเส้นกับจำนวนอุปกรณ์โดยใช้อัลกอริทึมการลดแบบต้นไม้หรือแบบวงแหวน¹³⁶ All-gather และ reduce-scatter แสดงคุณสมบัติการขยายที่แตกต่างกัน คอมไพเลอร์จำลองต้นทุนเหล่านี้และเลือกกลยุทธ์การแบ่งส่วนที่ลดเวลาการสื่อสารทั้งหมด
Sequence parallelism กลายเป็นสิ่งสำคัญสำหรับโมเดลภาษาขนาดใหญ่ กลไก attention สร้างคอขวดหน่วยความจำเพราะ key-value cache เติบโตตามความยาวลำดับและขนาดแบตช์ การแบ่งพาร์ติชันตามมิติลำดับกระจายภาระหน่วยความจำข้ามอุปกรณ์ในขณะที่แนะนำการสื่อสารเฉพาะสำหรับการคำนวณ attention เท่านั้น¹³⁷
Expert parallelism จัดการโมเดล Mixture-of-Experts (MoE) ที่ expert แตกต่างกันประมวลผล token แตกต่างกัน กลยุทธ์การแบ่งส่วนทำซ้ำเลเยอร์ที่ใช้ร่วมกันข้ามอุปกรณ์ทั้งหมด แต่แบ่งพาร์ติชัน expert, กำหนดเส้นทางแต่ละ token ไปยังอุปกรณ์ expert ที่กำหนด¹³⁸ การกำหนดเส้นทางแบบไดนามิกสร้างรูปแบบการสื่อสารที่ไม่สม่ำเสมอ ท้าทายการดำเนินการ collective แบบดั้งเดิม ต้องการระบบรันไทม์ที่ซับซ้อนเพื่อลด latency และความไม่สมดุลของโหลด
Optimizer state sharding ลดค่าใช้จ่ายหน่วยความจำสำหรับโมเดลขนาดใหญ่ Optimizer อย่าง Adam เก็บสถิติ momentum และ variance สำหรับทุกพารามิเตอร์ ซึ่งเพิ่มความต้องการหน่วยความจำเป็นสามเท่าของพารามิเตอร์เพียงอย่างเดียว การแบ่งส่วน optimizer state ข้ามอุปกรณ์ในขณะที่เก็บพารามิเตอร์แบบทำซ้ำช่วยให้สามารถฝึกโมเดลที่ใหญ่ขึ้นภายในงบประมาณหน่วยความจำคงที่¹³⁹ กลยุทธ์นี้ต้องรวบรวมการอัปเดต optimizer state ระหว่างการคำนวณน้ำหนัก แต่ลดรอยเท้าหน่วยความจำต่ออุปกรณ์อย่างมาก
การวิเคราะห์ประสิทธิภาพและการทดสอบประสิทธิภาพ
ผลลัพธ์ MLPerf และตำแหน่งในการแข่งขัน
MLPerf ให้มาตรฐานอุตสาหกรรมในการวัดประสิทธิภาพของตัวเร่ง AI ในงาน training และ inference Google เสนอผลลัพธ์ TPU อย่างสม่ำเสมอที่แสดงประสิทธิภาพที่แข่งขันได้ และการพัฒนาข้ามรุ่นต่างๆ แสดงให้เห็นการปรับปรุงสถาปัตยกรรมอย่างชัดเจน¹⁴⁰
TPU v5e บรรลุผลลัพธ์ที่นำหน้าใน 8 จาก 9 หมวดหมู่ MLPerf training¹⁴¹ ความกว้างขวางแสดงให้เห็นความหลากหลายของสถาปัตยกรรมที่เกินไปจากโมเดลภาษาขนาดใหญ่เพียงอย่างเดียว—ประสิทธิภาพที่แข่งขันได้ในงาน computer vision ระบบแนะนำ และงานประมวลผลทางวิทยาศาสตร์ การ training BERT เสร็จสิ้นเร็วกว่า NVIDIA A100 GPU ถึง 2.8 เท่า ซึ่งยืนยันสถาปัตยกรรมที่ปรับให้เหมาะกับ transformer¹⁴²
MLPerf Training v5.0 ที่ประกาศในเดือนมิถุนายน 2025 ได้เปิดตัว benchmark Llama 3.1 405B ที่เป็นตัวแทนโมเดลที่ใหญ่ที่สุดในชุดทดสอบ¹⁴³ benchmark นี้ทดสอบการขยายขนาดแบบหลาย node การสูญเสียจากการสื่อสาร และความจุหน่วยความจำมากกว่าการทดสอบก่อนหน้า Google Cloud เข้าร่วมด้วยการส่ง TPU แม้ว่าการเปรียบเทียบประสิทธิภาพโดยละเอียดยังคงถูกระงับจนกว่าจะมีการเผยแพร่ผลลัพธ์อย่างเป็นทางการ
MLPerf Inference v5.0 รวม benchmark ใหม่สี่ตัว: Llama 3.1 405B, Llama 2 70B สำหรับแอปพลิเคชันที่ต้องการ latency ต่ำ, RGAT graph neural networks และ PointPainting สำหรับการตรวจจับวัตถุ 3D¹⁴⁴ ความหลากหลายผลักดันให้ตัวเร่งต้องทำงานเกินกว่างาน transformer ทั่วไปเข้าสู่ domain แอปพลิเคชันใหม่ๆ ที่สมมติฐานสถาปัตยกรรมอาจแตกต่างกัน
Inference benchmark โดยเฉพาะสนับสนุนจุดแข็งทางสถาปัตยกรรมของ TPU งาน batch inference ใช้ประโยชน์จากความขนานขนาดใหญ่ของ MXU บรรลุ throughput ที่สูงกว่าตัวเร่งคู่แข่งถึง 4 เท่าสำหรับการให้บริการ transformer¹⁴⁵ Single-query latency ได้ประโยชน์จากการประมวลผลแบบกำหนดได้ของ TPU และการไม่มี thermal throttling ส่งมอบ latency ที่สม่ำเสมอโดยไม่มีความแปรปรวนของประสิทธิภาพที่รบกวนการติดตั้ง GPU บางอย่าง
เมตริกประสิทธิภาพการใช้พลังงานแสดงให้เห็นว่าข้อได้เปรียบของ TPU ขยายตัวข้ามรุ่นต่างๆ TPU v4 แสดงประสิทธิภาพต่อวัตต์ที่ดีกว่า TPU v3 ถึง 2.7 เท่า และ Trillium ปรับปรุง 67% เมื่อเทียบกับ v5e¹⁴⁶ Ironwood อ้างว่ามีประสิทธิภาพต่อวัตต์ที่ดีกว่า Trillium 2 เท่า แม้จะมีประสิทธิภาพสัมบูรณ์ที่สูงกว่าอย่างมีนัยสำคัญ¹⁴⁷ การเพิ่มประสิทธิภาพรวมกันข้าม pod หลายพันชิป แปลเป็นค่าใช้จ่ายในการดำเนินงานของ datacenter หลายล้านดอลลาร์
ประสิทธิภาพ Training และ Inference ในโลกจริง
งานใน production เผยให้เห็นลักษณะประสิทธิภาพที่ไม่ปรากฏในการทดสอบสังเคราะห์ Google เผยแพร่ผลลัพธ์จากบริการภายในที่แสดงพฤติกรรม TPU ภายใต้รูปแบบการใช้งานจริงและข้อกำหนดการขยายขนาด¹⁴⁸
การ training ResNet-50 ImageNet เสร็จสิ้นใน 28 นาทีบน TPU pods ซึ่งเป็น benchmark ที่อ้างถึงกันอย่างแพร่หลายสำหรับประสิทธิภาพงาน computer vision¹⁴⁹ เมตริก time-to-accuracy จับภาพกระบวนการ training ที่สมบูรณ์ รวมถึงการโหลดข้อมูล การเพิ่มข้อมูล การซิงโครไนซ์ gradient แบบกระจาย และการบันทึก checkpoint—ไม่เพียงแค่ FLOPS เชิงทฤษฎี
การ training โมเดลภาษา T5-3B แสดงให้เห็นข้อได้เปรียบของ TPU ในสถาปัตยกรรม transformer โมเดล 3 พันล้านพารามิเตอร์ train ใน 12 ชั่วโมงบน TPU pods เปรียบเทียบกับ 31 ชั่วโมงในการกำหนดค่า GPU ที่เทียบเท่า¹⁵⁰ ความเร็วที่เพิ่มขึ้น 2.6 เท่า เกิดจากการดำเนินการ attention ที่เร่งด้วยฮาร์ดแวร์ การใช้ memory bandwidth อย่างมีประสิทธิภาพ และการสื่อสารแบบ collective ที่ปรับให้เหมาะสม
งานขนาด GPT-3 (175B พารามิเตอร์) บรรลุ time-to-accuracy ที่เร็วกว่า 1.7 เท่าบน TPU เมื่อเทียบกับ GPU ร่วมสมัย¹⁵¹ ช่องว่างประสิทธิภาพขยายตัวสำหรับโมเดลที่ใหญ่กว่า ที่ความจุและ bandwidth ของหน่วยความจำกลายเป็นข้อจำกัดที่สำคัญ HBM3e 192GB ของ Ironwood ช่วยให้สามารถให้บริการโมเดลที่ต้องการ tensor parallelism ที่ซับซ้อนบนทางเลือกที่มีหน่วยความจำต่ำกว่า
การวัดประสิทธิภาพการขยายขนาดแสดให้เห็นการเร่งความเร็วที่เกือบเป็นเส้นตรงในระดับที่ใหญ่มาก Google Research รายงานประสิทธิภาพการขยายขนาด 95% ที่ 32,768 TPU สำหรับงาน training transformer เฉพาะ¹⁵² เมตริกหมายความว่า TPU 32,768 ตัวส่งมอบประสิทธิภาพ 95% ของที่การขยายขนาดเชิงเส้นที่สมบูรณ์แบบจะทำนาย—น่าทึ่งเมื่อพิจารณาว่าค่าใช้จ่ายการสื่อสารเพิ่มขึ้นตามขนาด
เมตริกการใช้ FLOPS เผยให้เห็นว่างานใช้ประโยชน์จากการประมวลผลที่มีอยู่ได้อย่างมีประสิทธิภาพเพียงใด โมเดล transformer โดยทั่วไปบรรลุการใช้ FLOPS 90% บน TPU หมายความว่า 90% ของประสิทธิภาพสูงสุดเชิงทฤษฎีถูกแปลงเป็นงานจริง¹⁵³ การใช้ประโยชน์สูงเกิดจากการรวมการดำเนินการที่ขจัดคอขวดหน่วยความจำ ประสิทธิภาพ systolic-array ในการคูณเมทริกซ์ขนาดใหญ่ และการปรับให้เหมาะสมของคอมไพเลอร์ที่ลดรอบที่สูญเปล่า
บริการ inference ใน production แสดงประสิทธิภาพที่ยั่งยืนข้ามหลายพันล้านคำถามต่อวัน Google Translate ประมวลผล 1 พันล้านคำขอรายวันบน TPU¹⁵⁴ คำแนะนำ YouTube ให้บริการผู้ใช้ 2 พันล้านคนโดยใช้โมเดลที่เร่งด้วย TPU¹⁵⁵ Google Photos วิเคราะห์ 28 พันล้านภาพต่อเดือนสำหรับคุณสมบัติการค้นหาและการจัดระเบียบ¹⁵⁶ ขนาดการดำเนินงานยืนยันความน่าเชื่อถือและประสิทธิภาพต้นทุนเกินกว่าการติดตั้งต้นแบบวิจัย
ประสิทธิภาพการใช้พลังงานและต้นทุนการเป็นเจ้าของรวม
การใช้พลังงานส่งผลกระทบโดยตรงต่อต้นทุนการดำเนินงานของ data center และความยั่งยืนด้านสิ่งแวดล้อม การปรับปรุงประสิทธิภาพการใช้พลังงานของ TPU ข้ามรุ่นต่างๆ ลดทั้งค่าใช้จ่ายในการดำเนินงานและการปล่อยคาร์บอนในระดับใหญ่¹⁵⁷
TPU v4 เฉลี่ยเพียง 200W การใช้พลังงานในงาน production แม้จะมีข้อกำหนด TDP 250W¹⁵⁸ ช่องว่างระหว่างพลังงานเฉลี่ยและพีคช่วยให้การออกแบบความร้อนและการจัดหามีความยืดหยุ่น เปรียบเทียบกับ GPU ที่งานต่อเนื่องมักจะถึงขด จำกัด TDP ต้องการงบประมาณพลังงาน rack ที่อนุรักษ์นิยม
TDP 600W ของ Ironwood แสดงถึงพลังงานสัมบูรณ์ที่สูงกว่ารุ่นก่อนหน้า แต่ส่งมอบการประมวลผลต่อวัตต์ที่มากขึ้นอย่างมาก¹⁵⁹ ประสิทธิภาพ FP8 4.6 PFLOPS ต่อชิปให้ผลประมาณ 7.7 TFLOPS ต่อวัตต์—แข่งขันได้หรือเกินประสิทธิภาพ GPU ร่วมสมัยในงานที่เทียบเท่า
ประสิทธิภาพการใช้พลังงานของ datacenter (PUE) ขยายประสิทธิภาพระดับชิป Data center TPU ของ Google บรรลุ PUE 1.1 หมายความว่าค่าใช้จ่ายพลังงานเพิ่มเติมเพียง 10% เกินกว่าการใช้ชิปสำหรับการทำความเย็น การแปลงพลังงาน และเครือข่าย¹⁶⁰ PUE เฉลี่ยของอุตสาหกรรมอยู่ระหว่าง 1.5 ถึง 2.0 ที่พลังงานเพิ่มเติม 50-100% ไปยังค่าใช้จ่ายโครงสร้างพื้นฐาน PUE ต่ำเกิดจากระบบทำความเย็นขั้นสูง การส่งมอบพลังงานที่มีประสิทธิภาพ และการออกแบบ datacenter ที่มุ่งเน้นเพื่อปรับให้เหมาะสมสำหรับงาน ML
การพิจารณาความเข้มข้นคาร์บอนขยายเกินกว่าพลังงานไปถึงแหล่งพลังงาน Google ดำเนิน datacenter TPU ด้วยพลังงานคาร์บอนเป็นกลางผ่านการจัดหาพลังงานหมุนเวียนและโปรแกรมชดเชยคาร์บอน¹⁶¹ การบัญชีคาร์บอนมีความสำคัญมากขึ้นสำหรับองค์กรที่ติดตามการปล่อย Scope 2 จากการประมวลผลคลาวด์
การวิเคราะห์ต้นทุนการเป็นเจ้าของรวม (TCO) ต้องพิจารณาต้นทุนการซื้อ การใช้พลังงาน ข้อกำหนดการทำความเย็น และค่าใช้จ่ายการบำรุงรักษา การติดตั้ง TPU มักแสดงการลด TCO 20-30% เมื่อเทียบกับการติดตั้ง GPU ที่เทียบเท่า ขับเคลื่อนหลักโดยประสิทธิภาพต่อวัตต์ที่เหนือกว่าและความซับซ้อนการทำความเย็นที่ลดลง¹⁶²
ต้นทุนโครงสร้างพื้นฐานการทำความเย็นขยายแบบไม่เป็นเส้นตรงกับความหนาแน่นของพลังงาน Rack ที่ระบายความร้อนด้วยอากาศโดยทั่วไปสูงสุดที่ 15-20kW ต่อ rack ก่อนที่จะต้องการโซลูชันการทำความเย็นที่แปลก GPU พลังงานสูงผลักดันขีดจำกัดเหล่านี้ บางครั้งจำเป็นต้องใช้โครงสร้างพื้นฐานการทำความเย็นด้วยของเหลวที่มีต้นทุนเงินทุนและการดำเนินงานที่สูงกว่าอย่างมาก ประสิทธิภาพของ TPU ทำให้การติดตั้งมากขึ้นอยู่ในช่วงการทำความเย็นด้วยอากาศ ทำให้การออกแบบ datacenter ง่ายขึ้น¹⁶³
ข้อได้เปรียบทางเทคนิค: จุดเด่นของ TPU
การดำเนินการแบบรวมกลุ่มที่เร่งด้วยฮาร์ดแวร์
การรองรับการดำเนินการแบบรวมกลุ่มเฉพาะทางใน TPU ICI มอบข้อได้เปรียบที่สำคัญที่สุดประการหนึ่งเมื่อเทียบกับตัวเร่งความเร็วแบบเครือข่ายดั้งเดิม All-reduce ซึ่งเป็นการดำเนินการหลักสำหรับซิงโครไนซ์ gradients ข้ามการฝึกแบบกระจาย ทำงานได้เร็วกว่า 10 เท่าบน TPU ICI เมื่อเทียบกับการทำงานบน GPU ที่ใช้ Ethernet ในระดับเดียวกัน¹⁶⁴
ความแตกต่างด้านประสิทธิภาพเกิดจากการรวมเข้าด้วยกันทางสถาปัตยกรรม การดำเนินการแบบรวมกลุ่มที่ใช้ Ethernet ต้องผ่านหลายชั้น: โค้ดแอปพลิเคชันเรียกใช้ไลบรารีแบบรวมกลุ่ม (NCCL, Horovod ฯลฯ) ซึ่งสร้างแพ็กเก็ตที่ส่งให้กับ network stack ซึ่งถ่ายโอนข้อมูลไปยัง NIC ซึ่งทำการ serialize ลงสายสัญญาณ ผ่าน switch ทำการ deserialize ที่ NIC ปลายทาง และย้อนกลับกระบวนการ แต่ละชั้นเพิ่ม latency คัดลอกข้อมูลผ่านลำดับชั้นของหน่วยความจำ และใช้ CPU cycle สำหรับการประมวลผลโปรโตคอล¹⁶⁵
TPU ICI ทำการดำเนินการแบบรวมกลุ่มในฮาร์ดแวร์โดยไม่ต้องผ่านชั้นซอฟต์แวร์ การดำเนินการเริ่มต้นโดยตรงจาก TensorCore สตรีมข้อมูลผ่าน ICI link เฉพาะ และเสร็จสิ้นโดยไม่ต้องเกี่ยวข้องกับ host CPU เส้นทางฮาร์ดแวร์โดยตรงช่วยกำจัด overhead ที่ครอบงำการทำงานแบบดั้งเดิม¹⁶⁶
โครงสร้างแบบ optical circuit-switch ช่วยให้สามารถใช้อัลกอริทึมแบบรวมกลุ่มที่เหมาะสมที่สุดได้ All-reduce แบบ ring ต้องการเพียง 2(N-1) ข้อความสำหรับ N devices และโครงสร้าง torus ให้การกำหนดเส้นทางที่สั้นที่สุด ทำให้ latency น้อยที่สุด¹⁶⁷ Uniform bisection bandwidth ป้องกัน hotspot ที่การดำเนินการแบบรวมกลุ่มที่กำหนดเส้นทางไม่ดีทำให้เกิดการคับคั่งใน network link
พื้นที่หน่วยความจำแบบรวมและการเขียนโปรแกรมที่ง่ายขึ้น
โมเดลหน่วยความจำแบบรวมของ TPU ช่วยให้การเขียนโปรแกรมง่ายขึ้นเมื่อเทียบกับลำดับชั้นหน่วยความจำที่ซับซ้อนของ GPU โปรแกรมเมอร์สามารถคิดเกี่ยวกับ HBM pool เดียวแทนที่จะต้องจัดการการถ่ายโอนระหว่าง host RAM, GPU global memory, shared memory และ register file โมเดลที่ง่ายขึ้นช่วยลดบั๊กและเพิ่มความเร็วในการพัฒนา¹⁶⁸
การแตกเป็นส่วนของหน่วยความจำไม่เป็นปัญหาอีกต่อไป GPU จัดสรรหน่วยความจำจาก fragmented heap ที่การจัดสรรและการคืนสรรพากาลเวลาสร้างช่องว่างที่ต้องการการบีบอัด การจัดการหน่วยความจำของ TPU ผ่าน static analysis ของ compiler หลีกเลี่ยงการแตกเป็นส่วนในขณะรันไทม์ทั้งหมด—tensor ได้รับการกำหนดตำแหน่งที่กำหนดไว้ล่วงหน้าตาม computation graph¹⁶⁹
โมเดลการเขียนโปรแกรมช่วยกำจัดข้อผิดพลาดของ CUDA ทั้งหมด ไม่มี "illegal memory access" จาก pointer arithmetic ที่ไม่ถูกต้อง ไม่มีบั๊กความสอดคล้องของ cache ระหว่าง CPU และ GPU ไม่มีข้อผิดพลาดในการซิงโครไนซ์จากการขาดการเรียก cudaDeviceSynchronize() การแยกนามธรรมระดับสูงป้องกันข้อผิดพลาดทั่วไปในการเขียนโปรแกรม CUDA¹⁷⁰
การทำงานแบบกำหนดได้และความสามารถในการทำซำ
Non-associativity ของจุดทศนิยมสร้างความท้าทายด้านความสามารถในการทำซำในการประมวลผลแบบขนาน นิพจน์ (a + b) + c อาจให้ผลลัพธ์ที่แตกต่างจาก a + (b + c) เนื่องจากข้อผิดพลาดในการปัดเศษ และการลดแบบขนานสามารถรวมในลำดับที่แตกต่างกันในแต่ละครั้งขึ้นอยู่กับ race condition¹⁷¹
การทำงานของ TPU แสดงความแน่นอนที่แข็งแกร่งกว่าการทำงานของ GPU โดยทั่วไป รูปแบบ dataflow ที่คงที่ของ systolic array รับประกันลำดับการดำเนินการที่เหมือนกันในแต่ละครั้ง การดำเนินการแบบรวมกลุ่มตาม reduction tree ที่กำหนดได้แทนการรวมแบบฉวยโอกาสตามลำดับการมาถึง ความสามารถในการคาดการณ์ช่วยให้เกิดการฝึกที่ทำซำได้ที่ hyperparameter และข้อมูลเหมือนกันสร้าง model weight ที่เหมือนกันทุก bit¹⁷²
การดีบักได้ประโยชน์อย่างมากจากความแน่นอน การฝึกแบบไม่แน่นอนทำให้การค้นหาสาเหตุของความล้มเหลวเป็นไปไม่ได้เกือบ—NaN เกิดจากบั๊กอัลกอริทึมที่แท้จริงหรือ race condition แบบสุ่ม การทำงานแบบกำหนดได้หมายความว่าความล้มเหลวสามารถทำซำได้อย่างน่าเชื่อถือ ทำให้สามารถใช้วิธีการดีบักแบบเป็นระบบได้¹⁷³
แอปพลิเคชันการประมวลผลทางวิทยาศาสตร์ให้ความสำคัญกับความสามารถในการทำซำเป็นพิเศษ โมเดลภูมิอากาศ การจำลองการค้นพบยา และการวิจัยฟิสิกส์ต้องการผลลัพธ์ที่สามารถตรวจสอบได้ที่ช่วยให้นักวิจัยคนต่างๆ สามารถทำซำผลลัพธ์ที่เหมือนกันได้ ความแน่นอนของ TPU รองรับวิธีการทางวิทยาศาสตร์ได้ดีกว่าทางเลือกแบบไม่แน่นอนที่แข่งขันกัน¹⁷⁴
การเพิ่มประสิทธิภาพของ Compiler และประสิทธิภาพของนักพัฒนา
การเพิ่มประสิทธิภาพแบบก้าวร้าวของ XLA มอบการปรับปรุงประสิทธิภาพที่สำคัญ "out of the box" โดยไม่ต้องปรับแต่งด้วยตนเอง นักวิจัยรายงานการปรับปรุง 40% ใน model throughput จากการคอมไพล์เพียงอย่างเดียวเมื่อเทียบกับ eager execution framework¹⁷⁵ ประสิทธิภาพมาฟรี—ไม่ต้องใช้ kernel engineering
การเพิ่มประสิทธิภาพ Fusion เป็นประโยชน์กับนักพัฒนาเป็นพิเศษ การ fuse operation ด้วยตนเองใน CUDA ต้องการการเขียน custom kernel การทดสอบความถูกต้อง และการบำรุงรักษาโค้ดข้าม framework version XLA fuse operation โดยอัตโนมัติและอัปเดต และปรับกลยุทธ์ fusion เมื่อโมเดลพัฒนา กำจัดภาระการบำรุงรักษา¹⁷⁶
การทำ Layout transformation อัตโนมัติช่วยประหยัดเวลาการเพิ่มประสิทธิภาพด้วยตนเองหลายสัปดาห์ การกำหนด tensor layout ที่เหมาะสมสำหรับ GPU ต้องการการ profile การจัดเรียงที่แตกต่างกัน การใส่ transpose ด้วยตนเอง และการจัดการรูปแบบการจัดสรรหน่วยความจำอย่างระมัดระวัง XLA ลอง layout โดยอัตโนมัติและเลือกที่เร็วที่สุด ทำให้นักพัฒนาสามารถมุ่งเน้นไปที่สถาปัตยกรรมโมเดลแทนที่จะเป็น low-level performance engineering¹⁷⁷
การเพิ่มประสิทธิภาพทวีคูณสำหรับทีมวิจัย เวลาที่ประหยัดได้จากการเพิ่มประสิทธิภาพโครงสร้างพื้นฐานเร่งความก้าวหน้าทางวิทยาศาสตร์ ทำให้สามารถทำการทดลองได้มากขึ้นและรอบการทำซำได้เร็วขึ้น องค์กรรายงานการปรับปรุงความเร็วในการพัฒนา 3 เท่าเมื่อย้ายจากการเขียนโปรแกรม GPU CUDA ไปสู่เวิร์กโฟลว์ที่ใช้ TPU JAX¹⁷⁸
ข้อจำกัดทางเทคนิคและข้อเสียปรับปรุง
การล็อกแพลตฟอร์มและข้อจำกัดการติดตั้งภายในองค์กร
การเข้าถึง TPU มีให้บริการเฉพาะผ่าน Google Cloud Platform เท่านั้น ซึ่งป้องกันการติดตั้งภายในองค์กรและสร้างความกังวลเรื่องการถูกล็อกผู้ขาย¹⁷⁹ องค์กรที่มีข้อกำหนดเรื่องอำนาจอธิปไตยข้อมูล เครือข่ายที่แยกจากอินเทอร์เน็ต หรือนโยบายที่ห้ามใช้ public cloud จะไม่สามารถใช้ประโยชน์จาก TPU ได้ แม้จะมีความเหนือกว่าทางเทคนิค
ข้อจำกัดนี้มีความสำคัญมากขึ้นเมื่อ AI กลายเป็นโครงสร้างพื้นฐานที่สำคัญ การพึ่งพาผู้ให้บริการคลาวด์รายเดียวสร้างความเสี่ยงต่อความต่อเนื่องทางธุรกิจ—การเปลี่ยนแปลงราคา การหยุดชะงักของบริการ หรือการยกเลิกบริการอาจบังคับให้เกิดการโยกย้ายที่มีต้นทุนสูง¹⁸⁰ การมี GPU จากหลายผู้ขาย (ฮาร์ดแวร์ NVIDIA ที่ทำงานบน AWS, Azure, GCP และภายในองค์กร) ให้ตัวเลือกที่ TPU ไม่สามารถจัดหาได้ในเชิงสถาปัตยกรรม
กลยุทธ์ multi-cloud เผชิญกับการต้าน องค์กรที่มาตรฐานบน TPU ไม่สามารถขยายไปยังคลาวด์อื่นหรือใช้ multi-cloud redundancy ได้อย่างง่ายดายโดยไม่ต้องฝึกโมเดลใหม่หรือบำรุงรักษาโค้ดเบสแยกสำหรับสถาปัตยกรรมตัวเร่งที่ต่างกัน¹⁸¹ ความซับซ้อนในการดำเนินงานของการติดตั้ง GPU/TPU แบบไฮบริดมักจะมากกว่าการประหยัดต้นทุนจากการเลือกตัวเร่งที่เหมาะสม
ช่องว่างความพร้อมของระบบนิเวศ CUDA
แพลตฟอร์ม CUDA ของ NVIDIA ได้สะสมการพัฒนาระบบนิเวศ ไลบรารี เอกสาร และความรู้ของชุมชนมากว่า 15 ปี ซึ่ง TPU ไม่สามารถเทียบได้¹⁸² ช่องว่างของความพร้อมปรากฏในจุดเจ็บปวดมากมายสำหรับการนำ TPU มาใช้
ความพร้อมของไลบรารีสนับสนุน CUDA อย่างท่วมท้น โดเมนพิเศษเช่นคอมพิวเตอร์กราฟิกส์ พลศาสตร์โมเลกุล พลศาสตร์ของไหลเชิงคำนวณ และพันธุศาสตร์ ได้สะสมไลบรารีที่ปรับปรุงสำหรับ CUDA หลายพันตัวในหลายทศวรรษที่ผ่านมา TPU ทางเลือกมักไม่มี โดยต้องใช้ CPU fallback (ซึ่งทำลายประสิทธิภาพ) หรือใช้เวลาหลายเดือนในการพอร์ต¹⁸³
การสนับสนุนชุมชนต่างกันหลายอันดับ Stack Overflow มีคำถาม CUDA หลายแสนคำถามพร้อมคำตอบโดยละเอียด—GitHub repositories มีอยู่หลายล้าน การบรรยายในงานประชุม บทความวิชาการ และบล็อกโพสต์ส่วนใหญ่เน้นการเขียนโปรแกรม CUDA โปรแกรมเมอร์ TPU เผชิญกับทรัพยากรที่ค่อนข้างเบาบาง วงจรดีบักที่ยาวขึ้น และผู้เชี่ยวชาญน้อยกว่าในการปรึกษา¹⁸⁴
สื่อการศึกษาและบทช่วยสอนส่วนใหญ่เป้าหมาย CUDA หลักสูตรมหาวิทยาลัยสอนการเขียนโปรแกรม GPU โดยใช้ CUDA หลักสูตรออนไลน์เน้น CUDA pipeline ของคนเก่งผลิตวิศวกรที่มีประสบการณ์ CUDA มากกว่าผู้เชี่ยวชาญ TPU สร้างความท้าทายในการจ้างงานและการฝึกอบรม¹⁸⁵
การพัฒนา custom kernel เป็นตัวอย่างของช่องว่างระบบนิเวศ การเขียน CUDA kernel ที่ปรับปรุงแล้วยังคงซับซ้อนแต่ได้รับประโยชน์จากเอกสารที่ครอบคลุม เครื่องมือ profiling และโค้ดตัวอย่าง Pallas เปิดใช้ custom TPU kernel แต่ด้วยเครื่องมือที่เรียบง่ายน้อยกว่าและฐานความรู้ที่เล็กกว่า เส้นโค้งการเรียนรู้ไม่สนับสนุนการปรับปรุงทั้งหมดยกเว้นที่สำคัญต่อประสิทธิภาพที่สุด¹⁸⁶
ความเชี่ยวชาญ Workload และข้อจำกัดความยืดหยุ่น
สถาปัตยกรรม TPU ปรับปรุงสำหรับรูปแบบ workload เฉพาะ—หลักการคูณเมทริกซ์หนาแน่นด้วยรูปแบบการเข้าถึงปกติและขนาดแบทช์ใหญ่ การดำเนินการนอก sweet spot พบกับหน้าผาประสิทธิภาพ¹⁸⁷
รูปทรงไดนามิกท้าทายโมเดลการทำงาน TPU คอมไพเลอร์ XLA สมมติขนาด tensor คงที่สำหรับการปรับปรุงและการสร้างโค้ด โมเดลที่มีความยาวลำดับแปรผัน control flow แบบไดนามิก หรือรูปทรงที่ขึ้นอยู่กับข้อมูลต้องการ padding ไปยังขนาดสูงสุด (เสียการคำนวณและหน่วยความจำ) หรือคอมไพล์ใหม่สำหรับแต่ละรูปทรงที่แตกต่าง (ทำลายประสิทธิภาพ)¹⁸⁸
การดำเนินการ sparse ได้รับการสนับสนุนจำกัดแม้มี SparseCore การคูณเมทริกซ์แบบ sparse workload ที่พบบ่อยในการคำนวณทางวิทยาศาสตร์และ graph neural networks ขาดการใช้งานที่มีประสิทธิภาพบน MXU หรือ VPU SparseCore พิเศษจัดการ embedding tables แต่ไม่ใช่ sparse linear algebra ทั่วไป¹⁸⁹
การอนุมานแบทช์เล็กใช้ทรัพยากรขนาน TPU ไม่เต็มที่ systolic array 256×256 เจริญรุ่งเรืองบนเมทริกซ์ใหญ่ที่เติมตารางด้วยงานผลิต การอนุมานคำถามเดียวปล่อย MAC ส่วนใหญ่ว่างเปล่า ให้ latency และต้นทุนต่อคำถามแย่กว่าทางเลือก GPU ที่ปรับปรุงสำหรับสถานการณ์แบทช์ต่ำ¹⁹⁰
รูปแบบการคำนวณไม่ปกติปราบปราม systolic array ประสิทธิภาพ อัลกอริทึมที่มีการแตกแขนงที่คาดเดาไม่ได้ โครงสร้างแบบเรียกซ้ำ หรือการเข้าถึงหน่วยความจำ pointer-chasing แสดงประสิทธิภาพ TPU ที่ไม่ดีเพราะ dataflow คงที่ไม่สามารถปรับตัวกับพฤติกรรมที่ขึ้นอยู่กับ runtime¹⁹¹
Workload ที่ไม่ใช่ ML ไม่ค่อยได้รับประโยชน์จากการเร่ง TPU การจำลองทางวิทยาศาสตร์ การเข้ารหัสวิดีโอ การตรวจสอบบล็อกเชน และการเรนเดอร์ทั้งหมดทำงานได้เร็วขึ้นบนสถาปัตยกรรมทั่วไปของ GPU แม้ TPU จะมี FLOPs สูงสุดสูงกว่าสำหรับการดำเนินการเมทริกซ์¹⁹²
ช่องว่างของการดีบักและเครื่องมือการพัฒนา
ระบบนิเวศของ NVIDIA รวมเครื่องมือ profiling ที่พร้อม (Nsight Systems, Nsight Compute, nvprof) debugger (cuda-gdb) และเฟรมเวิร์กการวิเคราะห์ที่ได้รับการปรับปรุงมาหลายทศวรรษ เครื่องมือ TPU มีอยู่ แต่ล้าหลังอย่างมากในความซับซ้อน¹⁹³
XProf ให้ profiling พื้นฐานผ่านการรวม TensorBoard แต่ขาดการเข้าถึง hardware counter แบบละเอียดที่เครื่องมือ NVIDIA เปิดเผย การเข้าใจอัตรา cache miss, occupancy, warp divergence หรือ memory bank conflicts—เมตริกการปรับปรุง GPU ที่สำคัญทั้งหมด—ไม่มีเทียบเท่า TPU เพราะสถาปัตยกรรมต่างกันพื้นฐาน¹⁹⁴
ข้อความข้อผิดพลาดมักบิดเบือนสาเหตุหลัก ความล้มเหลวการคอมไพล์ XLA ผลิตข้อความลึกลับเกี่ยวกับ shape mismatches หรือการดำเนินการที่ไม่สนับสนุน โดยไม่มีคำแนะนำที่ชัดเจนในการแก้ไข ข้อผิดพลาด CUDA แม้จะโด่งดังในความไม่เป็นประโยชน์ แต่ได้รับประโยชน์จากคำอธิบาย StackOverflow และความรู้เผ่าพันธุ์สิบห้าปี¹⁹⁵
การดีบักการฝึกอบรมแบบกระจายบน multi-chip pods เข้าใกล้ความเป็นไปไม่ได้โดยไม่มีเครื่องมือพิเศษ race conditions, gradient synchronization bugs และความล้มเหลวการดำเนินการ collective ปรากฏเป็นข้อผิดพลาดไม่ตัดสินใจ (แย้งๆ แม้มีประโยชน์ determinism ของ TPU) ที่ทำซ้ำไม่สม่ำเสมอและต่อต้านการวินิจฉัยอย่างเป็นระบบ¹⁹⁶
วง iteration ขยายอย่างเจ็บปวดสำหรับโมเดลซับซ้อน การคอมไพล์ใหม่สำหรับการเปลี่ยนแปลงรูปทรงหรือการแก้ไขสถาปัตยกรรมอาจต้องการนาที แช่แข็งการพัฒนาขณะที่คอมไพเลอร์ churns โมเดลการทำงาน eager execution ของ CUDA เปิดใช้การวนซ้ำเร็วขึ้นแม้มีประสิทธิภาพสูงสุดต่ำกว่า¹⁹⁷
การนำไปใช้ในโลกจริง: การทำงานในระดับการผลิต
Anthropic Claude: กลยุทธ์หลายแพลตฟอร์ม
การประกาศของ Anthropic ในเดือนตุลาคม 2025 เกี่ยวกับการใช้งาน TPU chips กว่าหนึ่งล้านตัว ถือเป็นการมุ่งมั่นต่อ AI accelerator ที่ใหญ่ที่สุดที่เปิดเผยต่อสาธารณะในประวัติศาสตร์¹⁹⁸ บริษัทมีแผนที่จะเข้าถึงกำลังประมวลผลที่เกินกิกะวัตต์มากซึ่งจะเริ่มทำงานในปี 2026 โดยเฉพาะสำหรับการฝึกฝนและให้บริการโมเดล Claude ในอนาคต
ขนาดนี้มีมากกว่าการนำไปใช้ก่อนหน้านี้หลายเท่าตัว TPU chips หนึ่งล้านตัว ที่กำหนดค่าเป็น Ironwood TPUs จะส่งมอบการประมวลผล FP8 ประมาณ 4.6 exaflops—มากกว่า 40 เท่าของประสิทธิภาพรวมของรายการ supercomputer Top500 ทั้งหมดจากเพียงห้าปีก่อน¹⁹⁹ ความมุ่งมั่นนี้แสดงถึงความเชื่อมั่นใน TPU architecture สำหรับการพัฒนาโมเดลขั้นสูงในระดับที่เคยถือว่าเป็นนิยายวิทยาศาสตร์
Anthropic ดำเนินกลยุทธ์ hardware หลายแพลตฟอร์มอย่างมีเจตนาข้าม TPUs ของ Google, Trainium ของ Amazon และ GPUs ของ NVIDIA²⁰⁰ การกระจายนี้ให้ประกันกำลังการผลิต, อำนาจต่อรองราคา และการกระจายตามภูมิศาสตร์ Claude ให้บริการทั่วโลกจากการนำไปใช้ทั้งสามแพลตฟอร์ม โดยการกำหนดเส้นทางคำขอขึ้นอยู่กับความพร้อมของกำลังการผลิตและความต้องการเรื่อง latency ตามภูมิภาค
การตรวจสอบทางเทคนิคของบริษัทจากเดือนสิงหาคม 2025 เปิดเผยความซับซ้อนของการนำไปใช้ในระดับใหญ่ การกำหนดค่าผิดพลาดบน Claude API TPU servers ทำให้เกิดข้อผิดพลาดในการสร้าง token โดยบางครั้งกำหนดความน่าจะเป็นสูงอย่างไม่คาดคิดให้กับตัวอักษรไทยหรือจีนใน English prompts²⁰¹ เหตุการณ์นี้แสดงให้เห็นว่าแม้ข้อผิดพลาดง่ายๆ ยังส่งผลกระทบแบบไม่คาดเดาผ่านระบบที่ประมวลผล tokens หลายพันล้านรายการต่อวัน
การนำไปใช้แยกต่างหากทำให้เกิด bug แฝงใน XLA: TPU compiler ที่ส่งผลกระทบต่อ Claude Haiku 3.5 Bug นี้มีอยู่โดยไม่ถูกตรวจพบเป็นเดือนจนกระทั่งการผสมผสานระหว่าง model architecture และ compiler flag เฉพาะเจาะจงเปิดเผยข้อบกพร่องนี้²⁰² การค้นพบนี้เน้นย้ำว่าการนำไปใช้ในการผลิตพบกรณีพิเศษที่ไม่มีในสภาพแวดล้อมการพัฒนาและ staging
วิศวกร Anthropic อ้างถึง price-performance และประสิทธิภาพของ TPU เป็นเกณฑ์การเลือกหลัก เศรษฐศาสตร์ที่น่าสนใจเร่งการพัฒนาโดยช่วยให้สามารถทำการทดลองขนาดใหญ่ขึ้นภายในง예산ที่กำหนด²⁰³ การฝึกโมเดลขนาดใหญ่ขึ้น การสำรวจการกำหนดค่า hyperparameter มากขึ้น และการวนซ้ำเร็วขึ้น ล้วนมาจากการลดต้นทุนต่อ FLOP
Google Gemini: ออกแบบสำหรับ TPU ตั้งแต่เริ่มต้น
โมเดล Gemini ของ Google ฝึกฝนและให้บริการบน TPUs เพียงอย่างเดียว โดย architecture และขั้นตอนการฝึกฝนถูกออกแบบร่วมกันสำหรับลักษณะของ TPU ตั้งแต่เริ่มต้น²⁰⁴ การเชื่อมต่ออย่างใกล้ชิดช่วยให้สามารถใช้ประโยชน์จากการปรับแต่งเฉพาะ TPU ที่โมเดลข้ามแพลตฟอร์มไม่สามารถใช้ได้
การนำไปใช้ Gemini รายงานว่าใช้ TPU v6e chips 50,000 ตัวสำหรับการฝึกฝนและให้บริการโมเดลที่สำคัญที่สุด²⁰⁵ Pod ขนาดมหาศาลต้องการการจัดระเบียบอย่างซับซ้อน—การจัดกำหนดการงานข้าม chips หลายพันตัว, การประสานงาน checkpoint เพื่อป้องกันคอขวด, การกู้คืนความล้มเหลวเพื่อลดงานที่สูญหาย และการติดตามเรียลไทม์เพื่อระบุ nodes ที่เสื่อมสภาพก่อนที่ความล้มเหลวจะแพร่กระจาย
Google ฝึกฝน Gemini 2.0 บน Trillium TPUs เพื่อตรวจสอบ architecture รุ่นที่หกสำหรับการพัฒนาโมเดลขั้นสูง²⁰⁶ การฝึกฝนแสดงให้เห็นประสิทธิภาพการขยายขนาดไปยังจำนวน chips ที่ไม่เคยมีมาก่อน บรรลุ strong scaling เกิน plateaus ปกติที่ communication overhead เป็นใหญ่
โครงสร้างพื้นฐานให้บริการโมเดลใช้ประโยชน์จากการปรับแต่ง TPU inference โดยเฉพาะ การประมวลผล batch รวมคำขอของผู้ใช้หลายรายเพื่อเพิ่มการใช้งาน MXU ให้สูงสุด การจัดการ key-value cache ใช้ประโยชน์จากความจุ HBM ช่วยให้สามารถประมวลผล context ที่มีชีวิตยาวนานโดยไม่ต้อง disk swapping Architecture ส่งมอบเวลาตอบสนองที่ต่ำกว่าหนึ่งวินาทีสำหรับ queries ที่ซับซ้อนในขณะที่จัดการปริมาณคำขอทั่วโลกจำนวนมหาศาล²⁰⁷
ระบบติดตามการผลิตติดตาม TPUs กว่า 50,000+ ตัวอย่างต่อเนื่อง ตรวจจับความผิดปกติที่อาจลดคุณภาพโมเดลหรือความพร้อมใช้งาน²⁰⁸ Telemetry จับภาพอัตราข้อผิดพลาด, เปอร์เซ็นไทล์ latency, throughput, ความกดดัน memory และลักษณะความร้อนทุก chip Machine learning models วิเคราะห์ telemetry streams เอง คาดการณ์ความล้มเหลวก่อนที่จะเกิดขึ้นและเรียกการบำรุงรักษาเชิงป้องกัน
การนำไปใช้ในการผลิตเพิ่มเติม
Midjourney ย้ายจาก GPU ไป TPU infrastructure บรรลุการลดต้นทุน 65% และการปรับปรุง latency 40% สำหรับ workloads การสร้างภาพ²⁰⁹ บริการสร้างศิลปะประมวลผลภาพ 300,000 ภาพต่อนาทีในช่วงโหลดสูงสุด ต้องการ compute throughput มหาศาลและประสิทธิภาพที่สม่ำเสมอภายใต้รูปแบบการรับส่งข้อมูลแบบ bursty
โมเดลภาษา Cohere บน TPU บรรลุ throughput 3 เท่าของการนำไปใช้ GPU ก่อนหน้า²¹⁰ ความเร็วที่เพิ่มขึ้นช่วยให้สามารถให้บริการลูกค้าได้มากขึ้นจากพื้นที่โครงสร้างพื้นฐานเดิม ปรับปรุงเศรษฐศาสตร์ทางธุรกิจโดยตรง บริษัทใช้ประโยชน์จากความสามารถ SPMD ของ JAX เพื่อ parallelize โมเดลข้าม TPU pods อย่างมีประสิทธิภาพ
Snap ได้รับกำลังการผลิตสำหรับ TPU v6e chips 10,000 ตัวสนับสนุนฟีเจอร์ augmented reality, ระบบแนะนำ และเครื่องมือ creative AI²¹¹ การนำไปใช้ครอบคลุมหลายภูมิภาคทางภูมิศาสตร์ รับประกัน latency ต่ำสำหรับฐานผู้ใช้ทั่วโลกของ Snapchat ในขณะที่รักษาความสอดคล้องของโมเดลข้ามภูมิภาค
สถาบันการศึกษานำ TPU มาใช้สำหรับการวิจัยมากขึ้น โปรแกรม TPU Research Cloud (TRC) ให้การเข้าถึง TPU ฟรีแก่นักวิจัย ช่วยให้สามารถทำการทดลองในระดับที่เคยเข้าถึงได้เพียงห้องปฏิบัติการองค์กรที่ได้รับเงินทุนดีเท่านั้น²¹² การทำให้เป็นประชาธิปไตยเร่งความก้าวหน้าทางวิทยาศาสตร์โดยขจัดอุปสรรคทาง hardware สำหรับนักวิชาการที่ตรวจสอบคำถามพื้นฐานเกี่ยวกับความสามารถและข้อจำกัดของ AI
การ Debug, Profiling และการปรับแต่งประสิทธิภาพ
การผสานรวมระหว่าง XProf และ TensorBoard
XProf เป็นเครื่องมือ profiling หลักสำหรับ workload ของ TPU โดยให้การวิเคราะห์ประสิทธิภาพสำหรับโปรแกรม JAX, PyTorch/XLA และ TensorFlow ทั้งบน CPU, GPU และ TPU²¹³ เครื่องมือนี้ผสานรวมกับ TensorBoard สำหรับการแสดงผลแบบภาพ โดยนำเสนอข้อมูล profiling ผ่าน interface ที่คุ้นเคยซึ่ง ML engineer เข้าใจอยู่แล้ว
การติดตั้งต้องการปลั๊กอิน TensorBoard: pip install tensorboard_plugin_profile tensorboard ซึ่งจะเปิดใช้งาน toolchain ที่สมบูรณ์²¹⁴ การรัน profiling บน TPU VM ต้องจับ trace ระหว่าง training หรือ inference อัปโหลดผลลัพธ์ไปยัง TensorBoard และวิเคราะห์การแสดงผลแบบภาพเพื่อระบุ bottleneck
หน้า Overview Page แสดงเมตริกสรุปประสิทธิภาพระดับสูง รวมถึงการแยกย่อยเวลาของขั้นตอน การใช้งานอุปกรณ์ และการระบุ bottleneck ระดับบนสุด²¹⁵ หน้านี้จะเน้นให้เห็นทันทีว่า workload ถูกจำกัดด้วยการคำนวณ (MXU ทำงานต่อเนื่อง) หน่วยความจำ (รอการถ่ายโอน HBM) หรือการสื่อสาร (ถูกบล็อกด้วย collective operation)
Trace Viewer และการวิเคราะห์ Timeline
Trace Viewer แสดงการแสดงผลแบบภาพ timeline แบบละเอียดที่แสดงว่า operation ทำงานเมื่อไหร่ การถ่ายโอนข้อมูลเกิดขึ้นเมื่อไหร่ และเวลาว่างสะสมที่ไหน²¹⁶ Interface ที่ใช้ Chrome ช่วยให้ซูมได้ถึงระดับความละเอียดไมโครวินาที เผยให้เห็นพฤติกรรมการจัดตารางที่แม่นยำซึ่งเมตริกรวมปิดบัง
การทำความเข้าใจ trace ต้องการการจำแนกรูปแบบทั่วไป ช่องว่างที่ยาวนานระหว่าง operation บ่งชี้ overhead ของการคอมไพล์ bottleneck การโหลดข้อมูล หรือ Python overhead เนื่องจาก data pipeline ที่ปรับแต่งไม่ดี Operation ขนาดเล็กที่ซ้ำกันแนะนำว่าไม่มี fusion เพียงพอ Collective operation ที่ใช้เวลาหลายมิลลิวินาทีชี้ไปที่ความไร้ประสิทธิภาพในการสื่อสารหรือกลยุทธ์ sharding ที่ไม่ดี²¹⁷
การแบ่งสีแยกประเภท operation: เขียวสำหรับการคำนวณ น้ำเงินสำหรับการถ่ายโอนหน่วยความจำ ส้มสำหรับการสื่อสาร และแดงสำหรับเวลาว่าง Workload ที่ปรับแต่งแล้วแสดงบล็อกสีที่บรรจุแน่นกับช่องว่างสีแดงน้อยที่สุด โค้ดที่ปรับแต่งไม่ดีจะแสดง timeline แบบกระจัดกระจายกับแถบสีแดงยาวที่บ่งชี้ทรัพยากรที่เสียไป²¹⁸
การใช้งานขั้นสูงเกี่ยวข้องกับการเชื่อมโยงพฤติกรรม timeline กับซอร์สโค้ด PyTorch/XLA รองรับคำอธิบายประกอบของผู้ใช้ที่แทรกในโค้ดซึ่งปรากฏใน trace ทำให้สามารถแมปพฤติกรรมประสิทธิภาพกับส่วนประกอบของโมเดลเฉพาะ²¹⁹ คำอธิบายประกอบเหล่านี้เปลี่ยน trace ที่ไม่โปร่งใสให้เป็นข้อมูลเชิงลึกที่สามารถนำไปปฏิบัติได้เกี่ยวกับเลเยอร์หรือ operation ใดที่ต้องให้ความสำคัญในการปรับแต่ง
เครื่องมือ Memory Profile และการ Debug OOM
ข้อผิดพลาด Out-of-memory (OOM) ระบาดในการพัฒนาโมเดลขนาดใหญ่ เครื่องมือ Memory Profile Tool ตรวจสอบการใช้หน่วยความจำของอุปกรณ์ระหว่างการดำเนินการ จับภาพการใช้งานสูงสุดและรูปแบบการจัดสรรที่นำไปสู่ความล้มเหลวของ OOM²²⁰
เครื่องมือนี้แสดงภาพการใช้หน่วยความจำตลอดเวลา แสดงว่า tensor ใดใช้ความจุมากที่สุดและเมื่อไหร่ที่การใช้งานสูงสุดเกิดขึ้น การแสดงผลแบบภาพมักเผยให้เห็นการจัดสรรที่น่าแปลกใจ—gradient buffer ที่ใหญ่กว่าที่คาดไว้ activation memory ที่ควร checkpoint หรือ tensor ชั่วคราวที่ XLA ไม่สามารถกำจัดได้²²¹
กลยุทธ์การ debug เกี่ยวข้องกับการลดรอยความจำโดยทีละน้อยผ่านเทคนิคหลายอย่าง Gradient checkpointing จะคำนวณ activation ใหม่ระหว่าง backward pass แทนการเก็บไว้ การแบ่ง optimizer state กระจาย Adam momentum และ variance ข้ามอุปกรณ์ Mixed precision ลดหน่วยความจำ 2 เท่าเมื่อเทียบกับ FP32 Microbatching ประมวลผล batch ขนาดเล็กตามลำดับแทน batch ใหญ่หนึ่งอัน²²²
การปรับแต่งหน่วยความจำขั้นสูงต้องการการทำความเข้าใจการตัดสินใจของคอมไพเลอร์ แฟล็ก xla_dump_to จะส่งออก intermediate representation ที่แสดงว่า XLA เปลี่ยน computation graph อย่างไร การวิเคราะห์ IR เผยให้เห็นว่า fusion สำเร็จหรือไม่ การคัดลอกที่ไม่จำเป็นเกิดขึ้นที่ไหน และ operation ใดจัดสรรหน่วยความจำมากกว่าที่คาดไว้²²³
Input Pipeline Analyzer
การประมวลผลล่วงหน้าของ CPU มักเป็น bottleneck ของการ training TPU Input Pipeline Analyzer ระบุว่าการโหลดข้อมูลทันกับการใช้งานของ accelerator หรือไม่ หรือ TPU นั่งรออยู่เฉยๆ รอ batch²²⁴
เครื่องมือนี้แยกการวิเคราะห์ฝั่ง host (การประมวลผลล่วงหน้าของ CPU, data augmentation, การประกอบ batch) จากการดำเนินการฝั่งอุปกรณ์ (การคำนวณ TPU จริง) Workload ที่ถูกจำกัดด้วย input แสดงการใช้อุปกรณ์ลดลงระหว่างการโหลดข้อมูลในขณะที่การใช้ CPU สูงสุด Workload ที่ถูกจำกัดด้วยการคำนวณรักษาการใช้อุปกรณ์สูงด้วย CPU ที่ทำงานทันได้อย่างสบาย²²⁵
กลยุทธ์การปรับแต่งขึ้นอยู่กับตำแหน่งของ bottleneck การประมวลผลล่วงหน้าของ host ที่ช้าได้ประโยชน์จากการทำ data loading แบบขนานข้าม CPU core มากขึ้น ลดความซับซ้อนของ augmentation ต่อตัวอย่าง หรือ prefetch batch ล่วงหน้าก่อนการใช้งาน Bottleneck ฝั่งอุปกรณ์ต้องการการเปลี่ยนแปลง model architecture การ fusion ที่ดีขึ้น หรือการปรับ sharding แทนการปรับแต่ง data pipeline²²⁶
อนาคตของ Tensor Processing Units
วิวัฒนาการทางสถาปัตยกรรมเจ็ดรุ่นของ Google แสดงให้เห็นนวัตกรรมอย่างต่อเนื่องใน AI accelerators เฉพาะทาง การรองรับ FP8 ของ Ironwood ความจุหน่วยความจำขนาดใหญ่ และการปรับขนาด superpod แบบ 9,216 ชิปชี้ให้เห็นเส้นทางการพัฒนาในอนาคต²²⁷
การลดความแม่นยำจะยังคงดำเนินต่อไปสู่ FP4 หรือแม้แต่ต่ำกว่านั้นสำหรับการดำเนินการเฉพาะ งานวิจัยใหม่แสดงให้เห็นว่าการดำเนินการ neural network หลายประเภทสามารถทนต่อการ quantization ขั้นรุนแรงได้ด้วยขั้นตอนการฝึกอบรมที่รอบคอบ TPUs รุ่นต่อไปอาจใช้ระบบ mixed-precision ด้วย FP4 forward passes, FP8 backward passes และ FP32 optimizer updates²²⁸
ความจุหน่วยความจำแข่งกับการเติบโตของขนาดโมเดล โมเดลล่าสุดในปัจจุบันทำให้หน่วยความจำ accelerator ตึงเครียดอยู่แล้ว ต้องใช้กลยุทธ์ parallelism ที่ซับซ้อน TPUs รุ่นต่อไปอาจรวมเทคโนโลยีหน่วยความจำแบบ non-volatile เช่น 3D XPoint หรือ resistive RAM เพื่อให้หน่วยความจำ on-package ขนาด terabyte-scale โดยไม่มีการใช้พลังงานของ DRAM²²⁹
Optical interconnects สามารถขยายไปเกินกว่า circuit switching เพื่อรวม optical computing elements งานวิจัยสำรวจ photonic matrix multiplication ที่ดำเนินการด้วยความเร็วแสงและใช้พลังงานน้อยที่สุด ซึ่งอาจเสริม electronic systolic arrays ด้วย optical co-processors สำหรับการดำเนินการเฉพาะ²³⁰
การรองรับ sparsity จะขยายไปเกินกว่า embeddings ไปสู่ sparse linear algebra ทั่วไป เทคนิค neural network pruning แสดงให้เห็นว่าน้ำหนัก 90%+ สามารถตั้งเป็นศูนย์ได้โดยไม่สูญเสียคุณภาพ สถาปัตยกรรมในอนาคตอาจข้าม zero-valued computations แบบ native แทนที่จะคำนวณและทิ้งอย่างชัดเจน²³¹
หลักการสถาปัตยกรรมที่เป็นรากฐานของความสำเร็จ TPU—domain specialization, custom interconnect, co-designed software stacks และ building-scale orchestration—ชี้ไปสู่อนาคตของ accelerators เฉพาะทางที่เพิ่มขึ้น แทนที่จะเป็น processors แบบ one-size-fits-all เราอาจเห็น accelerators ที่ปรับให้เหมาะสมสำหรับการฝึกเทียบกับ inference, convolutional networks เทียบกับ transformers, dense เทียบกับ sparse models และ short เทียบกับ long sequences²³²
วิศวกรที่กำลังสร้าง AI infrastructure ในปัจจุบันควรเข้าใจสถาปัตยกรรม TPU อย่างลึกซึ้ง ไม่ว่าจะเป็นการ deploy บน Google Cloud การแข่งขันกับ Google ในตลาด accelerator หรือการออกแบบระบบ ML รุ่นต่อไป หลักการออกแบบและ tradeoffs ที่ฝังอยู่ใน TPU เผยให้เห็นความจริงพื้นฐานเกี่ยวกับสิ่งที่ AI workloads ต้องการจาก hardware คณิตศาสตร์ systolic array การออกแบบ memory hierarchy, interconnect topology และกลยุทธ์การปรับแต่ง compiler แสดงถึงภูมิปญญาที่สะสมมาหลายทศวรรษซึ่งสามารถนำไปใช้ได้ไกลเกินกว่า TPU เอง
ความตึงเครียดระหว่าง specialization และ generality ที่กำหนด TPU เทียบกับ GPU จะคงอยู่ไปเรื่อยๆ TPUs เสียสละความยืดหยุ่นเพื่อประสิทธิภาพขั้นสูงในงานแคบๆ GPUs เสียสละประสิทธิภาพสูงสุดเพื่อความใช้งานที่กว้างขึ้น ไม่มีแนวทางใดโดดเด่น—การเลือกที่เหมาะสมขึ้นอยู่กับลักษณะ workload, scale, ข้อจำกัดด้านต้นทุน และความต้องการการปฏิบัติการ องค์กรที่ประสบความสำเร็จกับ AI ในระดับใหญ่ใช้กลยุทธ์ heterogeneous มากขึ้น โดยจับคู่สถาปัตยกรรม accelerator กับความต้องการ workload แทนการมาตรฐานในแพลตฟอร์มเดียว
ความมุ่งมั่นล้าน-ชิปของ Anthropic ต่อ TPU แสดงให้เห็นว่าสถาปัตยกรรมได้บรรลุความแก่กล่าวในการผลิตในระดับสูงสุด การ deployment หลาย-gigawatt ที่จะมาออนไลน์ในปี 2026 จะฝึกโมเดลที่ผลักดันขอบเขตของสิ่งที่ AI สามารถบรรลุได้ และ infrastructure ที่ทำให้โมเดลเหล่านั้นเป็นไปได้รวบรวมความซับซ้อนทางวิศวกรรมที่องค์กรน้อยแห่งเทียบได้ การเข้าใจว่า multiply-accumulate units 65,536 หน่วยใน systolic array ร่วมมือกันฝึกโมเดลล่าสุดมีความสำคัญสำหรับทุกคนที่จริงจังเกี่ยวกับอนาคตของ AI
อ้างอิง
-
Google Cloud Press Corner, "Anthropic to Expand Use of Google Cloud TPUs and Services," October 23, 2025, https://www.googlecloudpresscorner.com/2025-10-23-Anthropic-to-Expand-Use-of-Google-Cloud-TPUs-and-Services.
-
TrendForce, "Google Unveils 7th-Gen TPU Ironwood with 9,216-Chip Superpod, Taking Aim at NVIDIA," November 7, 2025, https://www.trendforce.com/news/2025/11/07/news-google-unveils-7th-gen-tpu-ironwood-with-9216-chip-superpod-taking-aim-at-nvidia/.
-
Norman P. Jouppi et al., "TPU v4: An Optically Reconfigurable Supercomputer for Machine Learning with Hardware Support for Embeddings," in Proceedings of the 50th Annual International Symposium on Computer Architecture (2023), arXiv:2304.01433.
-
Anthropic, "Expanding our use of Google Cloud TPUs and Services," Anthropic News, October 2025, https://www.anthropic.com/news/expanding-our-use-of-google-cloud-tpus-and-services.
-
Google Cloud Blog, "Quantifying the performance of the TPU, our first machine learning chip," April 2017, https://cloud.google.com/blog/products/gcp/quantifying-the-performance-of-the-tpu-our-first-machine-learning-chip.
-
Norman P. Jouppi et al., "In-Datacenter Performance Analysis of a Tensor Processing Unit," Proceedings of the 44th Annual International Symposium on Computer Architecture (2017), arXiv:1704.04760.
-
Jouppi et al., "In-Datacenter Performance Analysis."
-
Jouppi et al., "In-Datacenter Performance Analysis."
-
Jonathan Hui, "AI Chips: Google TPU," Medium, เข้าถึงเมื่อ December 2025, https://jonathan-hui.medium.com/ai-chips-tpu-3fa0b2451a2d.
-
Wikipedia, "Bfloat16 floating-point format," เข้าถึงเมื่อ December 2025, https://en.wikipedia.org/wiki/Bfloat16_floating-point_format.
-
Henry Ko, "TPU Deep Dive," บล็อกส่วนตัว, เข้าถึงเมื่อ December 2025, https://henryhmko.github.io/posts/tpu/tpu.html.
-
Wikipedia, "Tensor Processing Unit," เข้าถึงเมื่อ December 2025, https://en.wikipedia.org/wiki/Tensor_Processing_Unit.
-
Wikipedia, "Tensor Processing Unit."
-
Wikipedia, "Tensor Processing Unit."
-
Ko, "TPU Deep Dive."
-
Jouppi et al., "TPU v4: An Optically Reconfigurable Supercomputer."
-
Jouppi et al., "TPU v4: An Optically Reconfigurable Supercomputer."
-
Jouppi et al., "TPU v4: An Optically Reconfigurable Supercomputer."
-
Jouppi et al., "TPU v4: An Optically Reconfigurable Supercomputer."
-
OpenXLA Project, "A deep dive into SparseCore for Large Embedding Models (LEM)," เข้าถึงเมื่อ December 2025, https://openxla.org/xla/sparsecore.
-
JAX Scaling Guide, "How to Think About TPUs," เข้าถึงเมื่อ December 2025, https://jax-ml.github.io/scaling-book/tpus/.
-
JAX Scaling Guide, "How to Think About TPUs."
-
Ko, "TPU Deep Dive."
-
JAX Scaling Guide, "How to Think About TPUs."
-
Google Cloud Blog, "Introducing Trillium, sixth-generation TPUs," May 2024, https://cloud.google.com/blog/products/compute/introducing-trillium-6th-gen-tpus.
-
Google Cloud Blog, "Introducing Trillium."
-
Google Cloud Blog, "Introducing Trillium."
-
Google Cloud Blog, "Introducing Trillium."
-
Google Cloud Blog, "Introducing Trillium."
-
Google Blog, "Ironwood: The first Google TPU for the age of inference," November 2025, https://blog.google/products/google-cloud/ironwood-tpu-age-of-inference/.
-
XPU.pub, "Google Adds FP8 to Ironwood TPU; Can It Beat Blackwell?" April 16, 2025, https://xpu.pub/2025/04/16/google-ironwood/.
-
TrendForce, "Google Unveils 7th-Gen TPU Ironwood."
-
The Register, "Google's 7th-gen Ironwood TPUs promise 42 AI exaFLOPS pods," April 10, 2025, https://www.theregister.com/2025/04/10/googles_7thgen_ironwood_tpus_debut/.
-
TrendForce, "Google Unveils 7th-Gen TPU Ironwood."
-
Ko, "TPU Deep Dive."
-
XPU.pub, "Google Adds FP8 to Ironwood TPU."
-
Google Cloud Press Corner, "Anthropic to Expand Use."
-
Telesens, "Understanding Matrix Multiplication on a Weight-Stationary Systolic Architecture," July 30, 2018, https://telesens.co/2018/07/30/systolic-architectures/.
-
Telesens, "Understanding Matrix Multiplication."
-
Jouppi et al., "In-Datacenter Performance Analysis."
-
Telesens, "Understanding Matrix Multiplication."
-
CP Lu, "Should We All Embrace Systolic Arrays?" Medium, เข้าถึงเมื่อ December 2025, https://cplu.medium.com/should-we-all-embrace-systolic-array-df3830f193dc.
-
Google Cloud Documentation, "TPU architecture," เข้าถึงเมื่อ December 2025, https://docs.cloud.google.com/tpu/docs/system-architecture-tpu-vm.
-
Google Cloud Documentation, "TPU architecture."
-
Hui, "AI Chips: Google TPU."
-
Telnyx, "Architecture insights: MXU and TPU components," เข้าถึงเมื่อ December 2025, https://telnyx.com/learn-ai/mxu-tpu.
-
Ko, "TPU Deep Dive."
-
Jouppi et al., "TPU v4: An Optically Reconfigurable Supercomputer."
-
SemiEngineering, "Tensor Processing Unit (TPU)," เข้าถึงเมื่อ December 2025, https://semiengineering.com/knowledge_centers/integrated-circuit/ic-types/processors/tensor-processing-unit-tpu/.
-
TrendForce, "Google Unveils 7th-Gen TPU Ironwood."
-
SemiEngineering, "Tensor Processing Unit (TPU)."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Google Cloud Documentation, "Cloud TPU performance guide," เข้าถึงเมื่อ December 2025, https://cloud.google.com/tpu/docs/performance-guide.
-
OpenXLA Project, "A deep dive into SparseCore."
-
OpenXLA Project, "A deep dive into SparseCore."
-
OpenXLA Project, "A deep dive into SparseCore."
-
Jouppi et al., "TPU v4: An Optically Reconfigurable Supercomputer."
-
OpenXLA Project, "A deep dive into SparseCore."
-
Jouppi et al., "TPU v4: An Optically Reconfigurable Supercomputer."
-
OpenXLA Project, "A deep dive into SparseCore."
-
JAX Scaling Guide, "How to Think About TPUs."
-
JAX Scaling Guide, "How to Think About TPUs."
-
JAX Scaling Guide, "How to Think About TPUs."
-
Ko, "TPU Deep Dive."
-
JAX Scaling Guide, "How to Think About TPUs."
-
JAX Scaling Guide, "How to Think About TPUs."
-
TrendForce, "Google Unveils 7th-Gen TPU Ironwood."
-
Ko, "TPU Deep Dive."
-
Anthropic, "Expanding our use of Google Cloud TPUs."
-
Jouppi et al., "TPU v4: An Optically Reconfigurable Supercomputer."
-
Jouppi et al., "TPU v4: An Optically Reconfigurable Supercomputer."
-
Jouppi et al., "TPU v4: An Optically Reconfigurable Supercomputer."
-
Jouppi et al., "TPU v4: An Optically Reconfigurable Supercomputer."
-
Ko, "TPU Deep Dive."
-
Jouppi et al., "TPU v4: An Optically Reconfigurable Supercomputer."
-
Leon Poutievski, "Mission Apollo: Landing Optical Circuit Switching at Datacenter Scale," LinkedIn, June 2022, https://www.linkedin.com/posts/leon-poutievski-8910a851_mission-apollo-landing-optical-circuit-switching-activity-6968472071534235649-cB4l.
-
Ko, "TPU Deep Dive."
-
Jouppi et al., "TPU v4: An Optically Reconfigurable Supercomputer."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Jouppi et al., "TPU v4: An Optically Reconfigurable Supercomputer."
-
JAX Scaling Guide, "How to Think About TPUs."
-
TrendForce, "Google Unveils 7th-Gen TPU Ironwood."
-
TrendForce, "Google Unveils 7th-Gen TPU Ironwood."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
OpenXLA Project, "XLA: Optimizing Compiler for Machine Learning," เข้าถึงเมื่อ December 2025, https://openxla.org/xla.
-
Daniel Snider and Ruofan Liang, "Operator Fusion in XLA: Analysis and Evaluation," บทความวิชาการ, เข้าถึงเมื่อ December 2025, https://danielsnider.ca/papers/Operator_Fusion_in_XLA_Analysis_and_Evaluation.pdf.
-
Snider and Liang, "Operator Fusion in XLA."
-
APXML, "Memory-Aware Data Layout Transformations (NCHW/NHWC)," เข้าถึงเมื่อ December 2025, https://apxml.com/courses/compiler-runtime-optimization-ml/chapter-3-advanced-graph-level-optimizations/memory-aware-layout-transformations.
-
OpenXLA Project, "XLA."
-
PyTorch Documentation, "Pytorch/XLA Overview," เข้าถึงเมื่อ December 2025, https://docs.pytorch.org/xla/master/learn/xla-overview.html.
-
OpenXLA Project, "A deep dive into SparseCore."
-
Mangpo Phothilimthana et al., "A Flexible Approach to Autotuning Multi-Pass Machine Learning Compilers," PACT 2021, เข้าถึงเมื่อ December 2025, https://mangpo.net/papers/xla-autotuning-pact2021.pdf.
-
JAX Documentation, "Introduction to parallel programming," เข้าถึงเมื่อ December 2025, https://docs.jax.dev/en/latest/sharded-computation.html.
-
GitHub, "jax-ml/jax: Composable transformations of Python+NumPy programs," เข้าถึงเมื่อ December 2025, https://github.com/jax-ml/jax.
-
OpenXLA Project, "Shardy Guide for JAX Users," เข้าถึงเมื่อ December 2025, https://openxla.org/shardy/getting_started_jax.
-
JAX Documentation, "Introduction to parallel programming."
-
OpenXLA Project, "Shardy Guide for JAX Users."
-
OpenXLA Project, "Shardy Guide for JAX Users."
-
JAX Documentation, "Introduction to parallel programming."
-
OpenXLA Project, "Shardy Guide for JAX Users."
-
PyTorch Documentation, "Pytorch/XLA Overview."
-
GitHub, "RFC: Evolving PyTorch/XLA for a more native experience on TPU," Issue #9684, เข้าถึงเมื่อ December 2025, https://github.com/pytorch/xla/issues/9684.
-
Google Cloud Blog, "PyTorch/XLA 2.4 improves Pallas and adds 'eager mode,'" เข้าถึงเมื่อ December 2025, https://cloud.google.com/blog/products/ai-machine-learning/pytorch-xla-2-4-improves-pallas-and-adds-eager-mode/.
-
PyTorch Documentation, "Pytorch/XLA Overview."
-
PyTorch Documentation, "Custom Kernels via Pallas," เข้าถึงเมื่อ December 2025, https://docs.pytorch.org/xla/master/features/pallas.html.
-
PyTorch Documentation, "Custom Kernels via Pallas."
-
PyTorch Documentation, "Custom Kernels via Pallas."
-
vLLM Blog, "vLLM TPU: A New Unified Backend Supporting PyTorch and JAX on TPU," October 16, 2025, https://blog.vllm.ai/2025/10/16/vllm-tpu.html.
-
GitHub, "pytorch/xla," เข้าถึงเมื่อ December 2025, https://github.com/pytorch/xla.
-
StackGpu, "FP8, BF16, and INT8: How Low-Precision Formats Are Revolutionizing Deep Learning Throughput," Medium, เข้าถึงเมื่อ December 2025, https://medium.com/@StackGpu/fp8-bf16-and-int8-how-low-precision-formats-are-revolutionizing-deep-learning-throughput-e6c1f3adabc2.
-
Wikipedia, "Bfloat16 floating-point format."
-
Wikipedia, "Bfloat16 floating-point format."
-
Paulius Micikevicius et al., "FP8 Formats for Deep Learning," arXiv:2209.05433, September 2022.
-
XPU.pub, "Google Adds FP8 to Ironwood TPU."
-
Micikevicius et al., "FP8 Formats for Deep Learning."
-
Google Cloud Blog, "Accurate Quantized Training (AQT) for TPU v5e," เข้าถึงเมื่อ December 2025, https://cloud.google.com/blog/products/compute/accurate-quantized-training-aqt-for-tpu-v5e.
-
StackGpu, "FP8, BF16, and INT8."
-
Jeffrey Tse, "Understanding the FP64, FP32, FP16, BFLOAT16, TF32, FP8 Formats," บล็อกส่วนตัว, December 9, 2024, https://jeffreytse.net/computer/2024/12/09/understanding-the-fp64-fp32-fp16-bfloat16-tf32-fp8-formats.html.
-
PyTorch Blog, "PyTorch/XLA SPMD: Scale Up Model Training and Serving with Automatic Parallelization," เข้าถึงเมื่อ December 2025, https://pytorch.org/blog/pytorch-xla-spmd/.
-
OpenXLA Project, "Shardy Guide for JAX Users."
-
JAX Documentation, "Introduction to parallel programming."
-
OpenXLA Project, "Shardy Guide for JAX Users."
-
Ko, "TPU Deep Dive."
-
JAX Documentation, "Introduction to parallel programming."
-
Anthropic, "Expanding our use of Google Cloud TPUs."
-
JAX Documentation, "Introduction to parallel programming."
-
JAX Documentation, "Introduction to parallel programming."
-
Adam Roberts et al., "Scaling Up Models and Data with t5x and seqio," arXiv:2203.17189, March 2022.
-
Roberts et al., "Scaling Up Models and Data."
-
JAX Documentation, "Introduction to parallel programming."
-
JAX Documentation, "Introduction to parallel programming."
-
OpenXLA Project, "Shardy Guide for JAX Users."
-
Roberts et al., "Scaling Up Models and Data."
-
Roberts et al., "Scaling Up Models and Data."
-
Ko, "TPU Deep Dive."
-
MLCommons, "Benchmark MLPerf Training," เข้าถึงเมื่อ December 2025, https://mlcommons.org/benchmarks/training/.
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
HPCwire, "MLPerf Training v5.0 Benchmark Results Reflect Rapid Growth in the Field of AI," June 2025, https://www.hpcwire.com/off-the-wire/mlperf-training-v5-0-benchmark-results-reflect-rapid-growth-in-the-field-of-ai/.
-
MLCommons, "MLCommons Releases New MLPerf Inference v5.0 Benchmark Results," April 2025, https://mlcommons.org/2025/04/mlperf-inference-v5-0-results/.
-
Ko, "TPU Deep Dive."
-
Google Cloud Blog, "TPU v4 enables performance, energy and CO2e efficiency gains," เข้าถึงเมื่อ December 2025, https://cloud.google.com/blog/topics/systems/tpu-v4-enables-performance-energy-and-co2e-efficiency-gains.
-
TrendForce, "Google Unveils 7th-Gen TPU Ironwood."
-
Google Cloud Blog, "Quantifying the performance of the TPU."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Artech Digital, "Energy-Efficient GPU vs. TPU Allocation," เข้าถึงเมื่อ December 2025, https://www.artech-digital.com/blog/energy-efficient-gpu-vs-tpu-allocation.
-
Wikipedia, "Tensor Processing Unit."
-
XPU.pub, "Google Adds FP8 to Ironwood TPU."
-
Ko, "TPU Deep Dive."
-
Google Cloud Blog, "TPU v4 enables performance, energy and CO2e efficiency gains."
-
ByteBridge, "GPU and TPU Comparative Analysis Report," Medium, เข้าถึงเมื่อ December 2025, https://bytebridge.medium.com/gpu-and-tpu-comparative-analysis-report-a5268e4f0d2a.
-
ByteBridge, "GPU and TPU Comparative Analysis Report."
-
Anthropic, "Expanding our use of Google Cloud TPUs."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
DataCamp, "Understanding TPUs vs GPUs in AI: A Comprehensive Guide," เข้าถึงเมื่อ December 2025, https://www.datacamp.com/blog/tpu-vs-gpu-ai.
-
Ko, "TPU Deep Dive."
-
DataCamp, "Understanding TPUs vs GPUs in AI."
-
Grigory Sapunov, "FP64, FP32, FP16, BFLOAT16, TF32, and other members of the ZOO," Medium, เข้าถึงเมื่อ December 2025, https://moocaholic.medium.com/fp64-fp32-fp16-bfloat16-tf32-and-other-members-of-the-zoo-a1ca7897d407.
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Snider and Liang, "Operator Fusion in XLA."
-
APXML, "Memory-Aware Data Layout Transformations."
-
Google Cloud Blog, "How Lightricks trains video diffusion models at scale with JAX on TPU," เข้าถึงเมื่อ December 2025, https://cloud.google.com/blog/products/media-entertainment/how-lightricks-trains-video-diffusion-models-at-scale-with-jax-on-tpu.
-
CloudOptimo, "TPU vs GPU: What's the Difference in 2025?" เข้าถึงเมื่อ December 2025, https://www.cloudoptimo.com/blog/tpu-vs-gpu-what-is-the-difference-in-2025/.
-
Phoenix NAP, "TPU vs. GPU: Differences Explained," เข้าถึงเมื่อ December 2025, https://phoenixnap.com/kb/tpu-vs-gpu.
-
CloudOptimo, "TPU vs GPU."
-
DataCamp, "Understanding TPUs vs GPUs in AI."
-
Tailscale, "TPU vs GPU: Which Is Better for AI Infrastructure in 2025?" เข้าถึงเมื่อ December 2025, https://tailscale.com/learn/what-is-tpu-vs-gpu.
-
DataCamp, "Understanding TPUs vs GPUs in AI."
-
DataCamp, "Understanding TPUs vs GPUs in AI."
-
PyTorch Documentation, "Custom Kernels via Pallas."
-
Phoenix NAP, "TPU vs. GPU: Differences Explained."
-
Ko, "TPU Deep Dive."
-
OpenMetal, "TPU vs GPU: Pros and Cons," เข้าถึงเมื่อ December 2025, https://openmetal.io/docs/product-guides/private-cloud/tpu-vs-gpu-pros-and-cons/.
-
OpenMetal, "TPU vs GPU: Pros and Cons."
-
Phoenix NAP, "TPU vs. GPU: Differences Explained."
-
PRIMO.ai, "Processing Units - CPU, GPU, APU, TPU, VPU, FPGA, QPU," เข้าถึงเมื่อ December 2025, https://primo.ai/index.php?title=Processing_Units_-_CPU%2C_GPU%2C_APU%2C_TPU%2C_VPU%2C_FPGA%2C_QPU.
-
DataCamp, "Understanding TPUs vs GPUs in AI."
-
Google Cloud Documentation, "Profile your model on Cloud TPU VMs," เข้าถึงเมื่อ December 2025, https://cloud.google.com/tpu/docs/cloud-tpu-tools.
-
DataCamp, "Understanding TPUs vs GPUs in AI."
-
Ko, "TPU Deep Dive."
-
GitHub, "RFC: Evolving PyTorch/XLA."
-
Google Cloud Press Corner, "Anthropic to Expand Use."
-
TrendForce, "Google Unveils 7th-Gen TPU Ironwood."
-
Maginative, "Anthropic Secures 1M Google TPUs While Keeping Amazon as Primary Training Partner," เข้าถึงเมื่อ December 2025, https://www.maginative.com/article/anthropic-secures-1m-google-tpus-while-keeping-amazon-as-primary-training-partner/.
-
Anthropic, "A postmortem of three recent issues," Engineering Blog, August 2025, https://www.anthropic.com/engineering/a-postmortem-of-three-recent-issues.
-
Anthropic, "A postmortem of three recent issues."
-
AI Magazine, "Why Anthropic Uses Google Cloud TPUs for AI Infrastructure," เข้าถึงเมื่อ December 2025, https://aimagazine.com/news/why-anthropic-uses-google-cloud-tpus-for-ai-infrastructure.
-
Google Cloud Blog, "Ironwood TPUs and new Axion-based VMs for your AI workloads," November 2025, https://cloud.google.com/blog/products/compute/ironwood-tpus-and-new-axion-based-vms-for-your-ai-workloads.
-
Ko, "TPU Deep Dive."
-
TrendForce, "Google Unveils 7th-Gen TPU Ironwood."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Google Cloud, "Tensor Processing Units (TPUs)," เข้าถึงเมื่อ December 2025, https://cloud.google.com/tpu.
-
TensorFlow Documentation, "Optimize TensorFlow performance using the Profiler," เข้าถึงเมื่อ December 2025, https://www.tensorflow.org/guide/profiler.
-
Google Cloud Documentation, "Profile your model on Cloud TPU VMs."
-
TensorFlow Documentation, "TensorFlow Profiler: Profile model performance," เข้าถึงเมื่อ December 2025, https://www.tensorflow.org/tensorboard/tensorboard_profiling_keras.
-
Google Cloud Documentation, "Profile your model on Cloud TPU VMs."
-
Google Cloud Blog, "PyTorch/XLA: Performance debugging on Cloud TPU VM: Part III," เข้าถึงเมื่อ December 2025, https://cloud.google.com/blog/topics/developers-practitioners/pytorchxla-performance-debugging-cloud-tpu-vm-part-iii.
-
Google Cloud Blog, "PyTorch/XLA: Performance debugging Part III."
-
Google Cloud Documentation, "Profile PyTorch XLA workloads," เข้าถึงเมื่อ December 2025, https://docs.cloud.google.com/tpu/docs/pytorch-xla-performance-profiling-tpu-vm.
-
TensorFlow Documentation, "Optimize TensorFlow performance using the Profiler."
-
TensorFlow Documentation, "Optimize TensorFlow performance using the Profiler."
-
Ko, "TPU Deep Dive."
-
Google Cloud Documentation, "Cloud TPU performance guide."
-
TensorFlow Documentation, "Optimize TensorFlow performance using the Profiler."
-
TensorFlow Documentation, "Optimize TensorFlow performance using the Profiler."
-
TensorFlow Documentation, "Optimize TensorFlow performance using the Profiler."
-
TrendForce, "Google Unveils 7th-Gen TPU Ironwood."
-
Tse, "Understanding the FP64, FP32, FP16, BFLOAT16, TF32, FP8 Formats."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."


