
As TPUs (Tensor Processing Units) do Google alimentam a maioria dos modelos de AI de ponta com os quais você interage diariamente, ainda assim a maioria dos engenheiros permanece surpreendentemente pouco familiarizada com sua arquitetura. Embora as GPUs da NVIDIA dominem a atenção dos desenvolvedores, as TPUs silenciosamente treinam e servem o Gemini 2.0, Claude e dezenas de outros modelos de fronteira em escalas que levariam à falência a maioria das organizações usando infraestrutura convencional de GPU. A Anthropic recentemente se comprometeu a implantar mais de um milhão de chips TPU—representando mais de um gigawatt de capacidade computacional—para treinar futuros modelos Claude.¹ A mais recente geração Ironwood do Google entrega 42,5 exaflops de computação FP8 através de superpods de 9.216 chips, uma escala que redefine o que significa infraestrutura de AI em produção.²
A sofisticação técnica por trás das TPUs se estende muito além de métricas simples de performance. Esses processadores incorporam uma filosofia de design fundamentalmente diferente das GPUs, trocando flexibilidade de propósito geral por especialização extrema em multiplicação de matrizes e operações de tensor. Engenheiros que entendem a arquitetura de TPU podem explorar arrays sistólicos 256×256 que processam 65.536 operações multiply-accumulate por ciclo, aproveitar aceleradores SparseCore de terceira geração para workloads intensivos em embedding, e programar switches de circuito óptico que reconfiguram topologias de datacenter multi-petabit em menos de 10 nanossegundos.³ A arquitetura abrange tudo, desde decisões de design em nível de transistor até orquestração de supercomputadores em escala de edifício.
O conteúdo técnico à frente exige atenção cuidadosa. Examinamos sete gerações de evolução de TPU, dissecamos matemática de arrays sistólicos e padrões de dataflow, exploramos hierarquias de memória desde tiles SRAM até canais HBM3e, analisamos otimizações do compilador XLA no nível de representação intermediária, e investigamos por que operações coletivas executam 10× mais rápido que clusters de GPU equivalentes baseados em Ethernet.⁴ Você encontrará especificações em nível de registrador, modelagem de performance cycle-accurate, e os tradeoffs arquiteturais que tornam as TPUs simultaneamente mais poderosas e mais restritas que GPUs. A profundidade aqui serve engenheiros construindo a próxima geração de infraestrutura de AI e pesquisadores empurrando os limites do que os aceleradores atuais podem alcançar.
A Evolução: Sete Gerações de Inovação Arquitetural
TPU v1: Especialização Somente em Inferência (2015)
Google implantou a primeira Unidade de Processamento Tensor em 2015 para resolver um problema crítico: cargas de trabalho de inferência de redes neurais ameaçavam dobrar a pegada de datacenter da empresa.⁵ Os engenheiros projetaram a TPU v1 exclusivamente para inferência, removendo totalmente as capacidades de treinamento para maximizar desempenho e eficiência energética para modelos implementados. O chip apresentava um array sistólico 256×256 de unidades multiply-accumulate de inteiros de 8 bits, entregando 92 teraops por segundo com apenas 28-40 watts de thermal design power.⁶
A arquitetura incorporava minimalismo radical. Uma única Unidade de Multiplicação de Matrizes processava operações INT8 através de dataflow weight-stationary, onde pesos permaneciam fixos no array sistólico enquanto ativações fluíam horizontalmente através da grade. Somas parciais são propagadas verticalmente, eliminando escritas de memória intermediárias para toda a multiplicação de matrizes. O chip, conectado aos sistemas host via PCIe, dependia de DRAM DDR3 para memória externa e operava a 700 MHz—deliberadamente conservador para eficiência energética.⁷
Os ganhos de desempenho surpreenderam até mesmo os engenheiros do Google. A TPU v1 alcançou melhorias de 30× a 80× em operações por watt comparada a CPUs e GPUs contemporâneas para cargas de trabalho de inferência em produção.⁸ O chip lidou com ranking de busca do Google, serviços de tradução processando 1 bilhão de solicitações diárias, e recomendações do YouTube para 2 bilhões de usuários. O sucesso validou uma percepção arquitetural central: aceleradores especializados otimizados para cargas de trabalho específicas poderiam entregar melhorias de ordens de magnitude sobre processadores de propósito geral.
TPU v2: Habilitando Treinamento em Escala (2017)
A segunda geração transformou TPUs de aceleradores somente para inferência em plataformas completas de treinamento. Google redesenhou toda a arquitetura em torno de operações de ponto flutuante, substituindo o array 256×256 INT8 por duplos multiply-accumulators bfloat16 128×128 por core.⁹ Cada chip continha dois TensorCores compartilhando 8GB de High Bandwidth Memory por core, uma atualização massiva do DDR3 que forneceu a largura de banda que o treinamento de redes neurais demandava.
A precisão bfloat16 provou ser crítica para o sucesso da TPU v2. O formato mantém a mesma faixa de expoente de 8 bits do FP32 enquanto reduz a mantissa para 7 bits, preservando faixa dinâmica para treinamento enquanto reduz pela metade os requisitos de largura de banda de memória.¹⁰ Os engenheiros observaram que a precisão reduzida da mantissa na verdade melhorou a generalização em muitos modelos ao atuar como uma forma de regularização, enquanto a faixa completa do expoente FP32 preveniu os problemas de underflow e overflow que assolaram o treinamento FP16.
A inovação arquitetural que realmente diferenciou a TPU v2 foi o Inter-Chip Interconnect (ICI). Aceleradores anteriores requeriam Ethernet ou InfiniBand para comunicação multi-chip, introduzindo gargalos de latência e largura de banda. Google projetou links bidirecionais de alta velocidade customizados que conectavam cada TPU diretamente a quatro vizinhos em uma topologia de torus 2D.¹¹ O interconnect habilitou "pods" TPU v2 de até 256 chips para funcionar como um único acelerador lógico, com operações coletivas como all-reduce executando muito mais rápido que alternativas baseadas em rede.
TPU v3: Escalonamento de Desempenho com Resfriamento Líquido (2018)
Google aumentou agressivamente velocidades de clock e contagens de cores na TPU v3, entregando 420 teraflops por chip—mais que dobrando o desempenho da v2.¹² A densidade de potência aumentada forçou uma mudança arquitetural dramática: resfriamento líquido. Cada pod TPU v3 requeria infraestrutura de resfriamento líquido, um afastamento dos designs resfriados a ar de gerações anteriores e da maioria dos aceleradores de datacenter.¹³
O chip manteve a arquitetura dual 128×128 MXU mas aumentou o número total de cores e melhorou a largura de banda de memória. Cada TPU v3 continha quatro chips com dois cores cada, compartilhando 32GB de memória HBM total entre os chips.¹⁴ As unidades de processamento vetorial receberam melhorias para funções de ativação, operações de normalização e computações de gradiente que frequentemente criavam gargalos de treinamento nas unidades de matriz sozinhas.
Implementações escalaram para pods de 2.048 chips usando a mesma topologia ICI de torus 2D da v2 mas com largura de banda aumentada por link. Google treinou modelos cada vez maiores em pods v3, descobrindo que o diâmetro de rede reduzido da topologia torus (distância máxima entre quaisquer dois chips escala como N/2 em vez de N) minimizava overhead de comunicação tanto para estratégias de treinamento data-parallel quanto model-parallel.¹⁵
TPU v4: Avanço em Optical Circuit Switching (2021)
A quarta geração representou o salto arquitetural mais significativo do Google desde a TPU original. Os engenheiros aumentaram a escala do pod para 4.096 chips enquanto introduziram optical circuit switching (OCS) para interconnect, uma tecnologia emprestada de telecomunicações que revolucionou a infraestrutura de ML em escala de datacenter.¹⁶
A arquitetura central da TPU v4 apresentava quatro 128×128 MXUs por TensorCore ao lado de unidades vetoriais e escalares aprimoradas. Cada par de TensorCores compartilhava 128MB de Common Memory além da Vector Memory por core, habilitando padrões mais sofisticados de staging e reutilização de dados.¹⁷ A topologia do chip evoluiu de torus 2D para 3D, conectando cada TPU a seis vizinhos em vez de quatro, reduzindo ainda mais o diâmetro da rede e melhorando a largura de banda de bisecção.
O sistema de optical circuit switching mudou tudo sobre implementação em grande escala. Em vez de cabeamento fixo entre TPUs, Google implantou switches ópticos programáveis que poderiam reconfigurar dinamicamente quais chips conectavam a quais. Espelhos MEMS (microelectromechanical systems) redirecionam fisicamente feixes de luz para conectar pares arbitrários de TPUs, introduzindo essencialmente zero latência além do tempo de transmissão da fibra óptica.¹⁸ Os switches reconfiguram em janelas sub-10-nanossegundos, mais rápido que a maioria dos handshakes de protocolos de rede.
A arquitetura OCS habilitou capacidades anteriormente impossíveis. Google poderia provisionar "slices" de qualquer tamanho, de quatro chips até o pod completo de 4.096 chips, programando os switches ópticos apropriadamente. Chips falhados poderiam ser contornados seamlessly sem derrubar racks inteiros. Mais notavelmente, TPUs fisicamente distantes em diferentes localizações de datacenter poderiam ser logicamente adjacentes na topologia da rede, desacoplando completamente layout físico e lógico.¹⁹
A TPU v4 também introduziu SparseCore, um processador especializado para lidar com operações de embedding usadas todos os dias em sistemas de recomendação, modelos de ranking e grandes modelos de linguagem com embeddings massivos de vocabulário. O SparseCore apresentava quatro processadores dedicados por chip, cada um com 2.5MB de memória scratchpad e dataflow otimizado para padrões de acesso de memória esparsa.²⁰ Modelos com embeddings ultra-grandes alcançaram speedups de 5-7× usando apenas 5% da área total do die do chip e orçamento de energia.
TPU v5p e v5e: Especialização e Escala (2022-2023)
Google dividiu a quinta geração em dois produtos distintos visando diferentes casos de uso. A TPU v5p priorizou máximo desempenho para treinamento em grande escala, enquanto a v5e otimizou para inferência custo-efetiva e trabalhos de treinamento menores.²¹
A TPU v5p alcançou aproximadamente 4.45 exaflops por segundo através de pods de 8.960 chips, mais que dobrando o tamanho máximo de pod da v4.²² A largura de banda do interconnect atingiu 4.800 Gbps por chip, e a topologia de torus 3D conectou chips em superpods massivos 16×20×28. O fabric de optical circuit switching gerenciou 13.824 portas ópticas através de 48 unidades OCS para cabear um superpod v5p completo, representando uma das maiores implementações de switching óptico em produção na história da computação.²³
A TPU v5e tomou uma abordagem diferente, reduzindo contagem de cores e velocidade de clock para atingir alvos agressivos de energia e custo. Chips otimizados para inferência continham apenas um core TPU por chip em vez de dois, e retornaram à topologia de torus 2D, que era suficiente para tamanhos menores de pods.²⁴ A simplificação arquitetural habilitou Google a precificar a v5e competitivamente para cargas de trabalho onde desempenho absoluto importava menos que desempenho por dólar.
TPU v6e Trillium: Quadruplicando Desempenho de Matrizes (2024)
Trillium marcou outro ponto de inflexão arquitetural expandindo a Matrix Multiply Unit de 128×128 para 256×256 multiply-accumulators.²⁵ O array maior quadruplicou FLOPs por ciclo na mesma velocidade de clock, entregando 4.7× o desempenho de computação de pico da TPU v5e através de uma combinação da MXU expandida e frequências de clock aumentadas.
O subsistema de memória recebeu atualizações igualmente dramáticas. A capacidade HBM dobrou para 32GB por chip, com largura de banda dobrada por canais HBM de próxima geração.²⁶ A largura de banda do Interchip Interconnect similarmente dobrou, habilitando pods de 256 chips Trillium a sustentar maior throughput para modelos que stressavam tanto computação quanto comunicação.²⁷
Trillium apresentou o acelerador SparseCore de terceira geração, com capacidades aprimoradas para embeddings ultra-grandes em cargas de trabalho de ranking e recomendação. O design atualizado melhorou padrões de acesso de memória e aumentou a largura de banda adequada entre SparseCores e HBM para modelos dominados por lookups de embedding em vez de multiplicações de matrizes.²⁸
A eficiência energética melhorou 67% sobre a v5e apesar dos ganhos substanciais de desempenho.²⁹ Google alcançou os ganhos de eficiência através de nós de processo avançados, otimizações arquiteturais que reduziram trabalho desperdiçado, e power gating cuidadoso de unidades não utilizadas durante operações que não stressavam todas as partes do chip simultaneamente.
TPU v7 Ironwood: A Era FP8 (2025)
A TPU de sétima geração do Google, codinome Ironwood, representa a primeira TPU projetada com suporte FP8 nativo e otimizada especificamente para a "era da inferência" enquanto mantém desempenho de treinamento estado-da-arte.³⁰ Cada chip Ironwood entrega 4.6 petaFLOPS de computação FP8 densa—levemente excedendo os 4.5 petaFLOPS do B200 concorrente da NVIDIA—enquanto consome 600W de thermal design power.³¹
O sistema de memória expandiu para 192GB de memória HBM3e por chip, seis vezes a capacidade do Trillium, com largura de banda atingindo 7.4TB/s.³² O aumento dramático de memória habilita servir modelos ultra-grandes com caches key-value que anteriormente requeriam paralelismo de tensor complexo através de múltiplos aceleradores. Google especificamente projetou a capacidade de memória para suportar modelos multi-modais emergentes e aplicações de contexto longo aproximando-se de janelas de milhão de tokens.
O interconnect do Ironwood fornece 9.6 Tbps de largura de banda bidirecional agregada através de quatro links ICI, traduzindo-se em 1.2 TB/s de largura de banda de pico por chip.³³ A arquitetura escala de pods de 256 chips para implementações menores até superpods massivos de 9.216 chips entregando 42.5 exaflops FP8 de poder computacional.³⁴ A tecnologia de rede de datacenter Jupiter do Google poderia teoricamente suportar até 43 superpods Ironwood em um único cluster—aproximadamente 400.000 aceleradores representando uma escala quase incompreensível de computação.³⁵
O suporte FP8 representa uma mudança fundamental na estratégia de precisão. Gerações anteriores de TPU emulavam operações de 8 bits usando técnicas de software, que introduziam overhead. Ironwood implementa unidades multiply-accumulate FP8 nativas suportando formatos tanto E4M3 (expoente de 4 bits, mantissa de 3 bits) quanto E5M2 (expoente de 5 bits, mantissa de 2 bits).³⁶ O suporte de formato duplo habilita misturar E4M3 para passes diretos onde precisão importa menos e E5M2 para passes reversos onde manter magnitudes de gradiente previne instabilidade de treinamento.
O compromisso da Anthropic de implementar mais de um milhão de chips Ironwood começando em 2026 demonstra a prontidão de produção da arquitetura. A empresa planeja alavancar bem mais de um gigawatt de capacidade TPU—suficiente para energizar uma cidade pequena—exclusivamente para treinar e servir modelos Claude.³⁷ A escala empequeñece até mesmo as maiores implementações conhecidas de GPU e representa uma aposta fundamental na arquitetura TPU para desenvolvimento de modelos de fronteira.
Referência Rápida da Geração Atual
As seguintes tabelas fornecem especificações escaneáveis para as três TPUs de geração atual mais relevantes para implementações de produção em 2025:
Tabela 1: Especificações de Computação Principal
[caption id="" align="alignnone" width="1386"] EspecificaçãoTPU v5eTPU v5pTPU v6e (Trillium)TPU v7 (Ironwood) Tamanho do Array MXU 128×128 128×128 256×256 256×256 MACs por Ciclo 16,384 16,384 65,536 65,536 Pico BF16 TFLOPS ~197 ~459 ~918 ~2,300 (est.) Pico FP8 PFLOPS N/A (emulado) N/A (emulado) N/A (emulado) 4.6 Precisão Nativa BF16, INT8 BF16, INT8 BF16, INT8 BF16, FP8, INT8 TensorCores/Chip 1 2 1 1 [/caption]
EspecificaçãoTPU v5eTPU v5pTPU v6e (Trillium)TPU v7 (Ironwood) Tamanho do Array MXU 128×128 128×128 256×256 256×256 MACs por Ciclo 16,384 16,384 65,536 65,536 Pico BF16 TFLOPS ~197 ~459 ~918 ~2,300 (est.) Pico FP8 PFLOPS N/A (emulado) N/A (emulado) N/A (emulado) 4.6 Precisão Nativa BF16, INT8 BF16, INT8 BF16, INT8 BF16, FP8, INT8 TensorCores/Chip 1 2 1 1 [/caption]
Tabela 2: Memória e Largura de Banda
[caption id="" align="alignnone" width="1380"]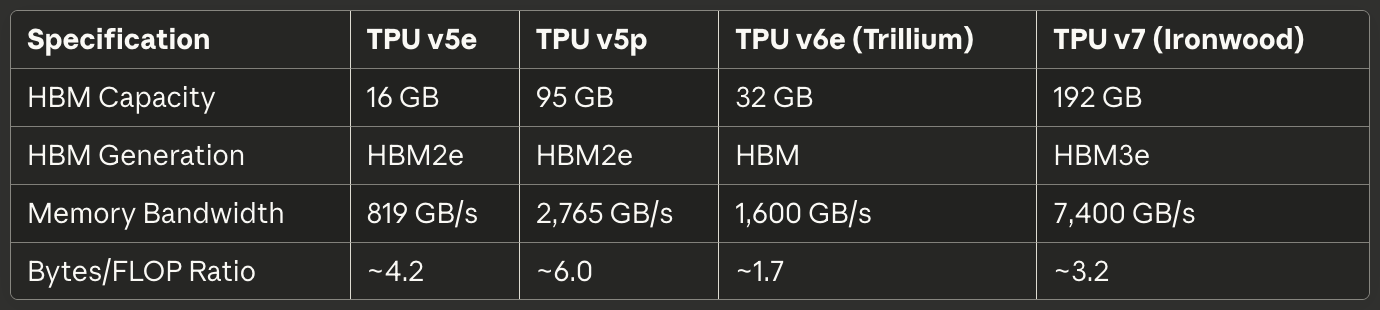 EspecificaçãoTPU v5eTPU v5pTPU v6e (Trillium)TPU v7 (Ironwood) Capacidade HBM 16 GB 95 GB 32 GB 192 GB Geração HBM HBM2e HBM2e HBM HBM3e Largura de Banda de Memória 819 GB/s 2,765 GB/s 1,600 GB/s 7,400 GB/s Razão Bytes/FLOP ~4.2 ~6.0 ~1.7 ~3.2 [/caption]
EspecificaçãoTPU v5eTPU v5pTPU v6e (Trillium)TPU v7 (Ironwood) Capacidade HBM 16 GB 95 GB 32 GB 192 GB Geração HBM HBM2e HBM2e HBM HBM3e Largura de Banda de Memória 819 GB/s 2,765 GB/s 1,600 GB/s 7,400 GB/s Razão Bytes/FLOP ~4.2 ~6.0 ~1.7 ~3.2 [/caption]
Tabela 3: Interconnect e Escalabilidade
[caption id="" align="alignnone" width="1384"]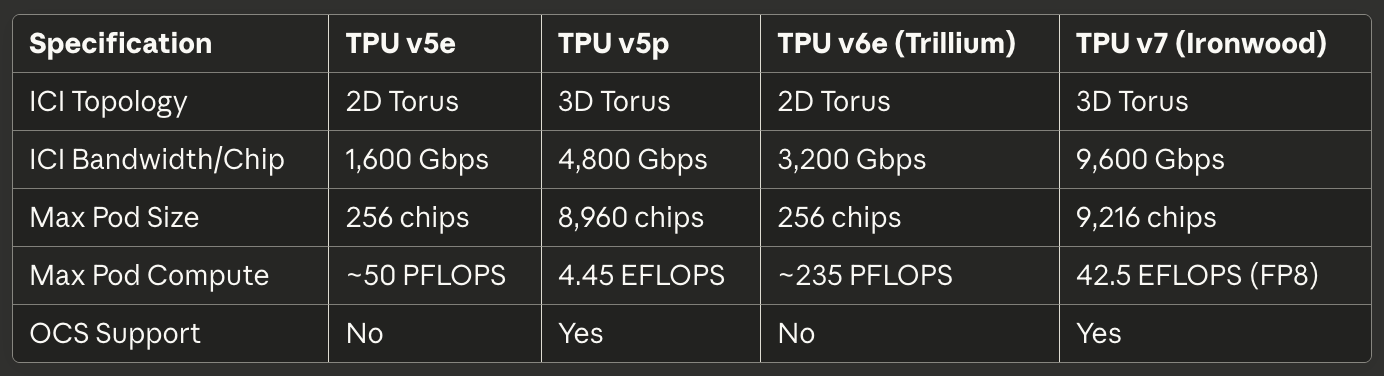 EspecificaçãoTPU v5eTPU v5pTPU v6e (Trillium)TPU v7 (Ironwood) Topologia ICI Torus 2D Torus 3D Torus 2D Torus 3D Largura de Banda ICI/Chip 1,600 Gbps 4,800 Gbps 3,200 Gbps 9,600 Gbps Tamanho Máx. do Pod 256 chips 8,960 chips 256 chips 9,216 chips Computação Máx. do Pod ~50 PFLOPS 4.45 EFLOPS ~235 PFLOPS 42.5 EFLOPS (FP8) Suporte OCS Não Sim Não Sim [/caption]
EspecificaçãoTPU v5eTPU v5pTPU v6e (Trillium)TPU v7 (Ironwood) Topologia ICI Torus 2D Torus 3D Torus 2D Torus 3D Largura de Banda ICI/Chip 1,600 Gbps 4,800 Gbps 3,200 Gbps 9,600 Gbps Tamanho Máx. do Pod 256 chips 8,960 chips 256 chips 9,216 chips Computação Máx. do Pod ~50 PFLOPS 4.45 EFLOPS ~235 PFLOPS 42.5 EFLOPS (FP8) Suporte OCS Não Sim Não Sim [/caption]
Tabela 4: Energia e Eficiência
[caption id="" align="alignnone" width="1380"] EspecificaçãoTPU v5eTPU v5pTPU v6e (Trillium)TPU v7 (Ironwood) TDP ~120-200W ~250-300W ~120-200W 600W Resfriamento Ar Líquido Ar Líquido TFLOPS/Watt (BF16) ~1.0-1.6 ~1.5-1.8 ~4.6-7.7 ~3.8 Energia vs Geração Anterior Baseline N/A 67% melhor que v5e 2× melhor que Trillium [/caption]
EspecificaçãoTPU v5eTPU v5pTPU v6e (Trillium)TPU v7 (Ironwood) TDP ~120-200W ~250-300W ~120-200W 600W Resfriamento Ar Líquido Ar Líquido TFLOPS/Watt (BF16) ~1.0-1.6 ~1.5-1.8 ~4.6-7.7 ~3.8 Energia vs Geração Anterior Baseline N/A 67% melhor que v5e 2× melhor que Trillium [/caption]
Tabela 5: Casos de Uso Recomendados
[caption id="" align="alignnone" width="1382"] Caso de Uso Melhor Escolha Justificativa Inferência otimizada para custo TPU v5e Menor custo por consulta de inferência Treinamento em grande escala (>1000 chips) TPU v5p ou Ironwood Torus 3D + OCS habilita pods massivos Trabalhos de treinamento médios (256 chips) TPU v6e Trillium Melhor perf/watt, 4.7× computação vs v5e Modelos limitados por memória (>70B params) Ironwood 192GB HBM habilita batch sizes maiores Inferência de contexto longo (>100K tokens) Ironwood Capacidade HBM suporta caches KV massivos Cargas de trabalho intensivas em embedding TPU v5p ou Ironwood SparseCore + HBM grande [/caption]
Caso de Uso Melhor Escolha Justificativa Inferência otimizada para custo TPU v5e Menor custo por consulta de inferência Treinamento em grande escala (>1000 chips) TPU v5p ou Ironwood Torus 3D + OCS habilita pods massivos Trabalhos de treinamento médios (256 chips) TPU v6e Trillium Melhor perf/watt, 4.7× computação vs v5e Modelos limitados por memória (>70B params) Ironwood 192GB HBM habilita batch sizes maiores Inferência de contexto longo (>100K tokens) Ironwood Capacidade HBM suporta caches KV massivos Cargas de trabalho intensivas em embedding TPU v5p ou Ironwood SparseCore + HBM grande [/caption]
Arquitetura de Hardware: Dentro do Silício
Matemática e Dataflow de Arrays Sistólicos
A Matrix Multiply Unit forma o coração da arquitetura TPU, e entender arrays sistólicos requer compreender sua abordagem fundamentalmente diferente ao paralelismo comparado às lanes SIMD de GPU. Um array sistólico encadeia unidades multiply-accumulate em uma grade onde dados fluem ritmicamente através da estrutura—daí "sistólico," evocando o bombeamento rítmico do sangue através do coração.³⁸
Considere o array sistólico 256×256 da TPU v6e executando a multiplicação de matrizes C = A × B. Os engenheiros pré-carregam os pesos da matriz B nas 65.536 unidades multiply-accumulate individuais arranjadas em uma grade. Os valores de ativação da matriz A entram pela borda esquerda e fluem horizontalmente através do array. Cada unidade MAC multiplica seu peso armazenado pela ativação que chega, adiciona o resultado a uma soma parcial chegando de cima, e passa tanto a ativação (horizontalmente) quanto a soma parcial atualizada (verticalmente) para unidades vizinhas.³⁹
O padrão de dataflow significa que cada valor de ativação é reutilizado 256 vezes conforme atravessa a dimensão horizontal, e cada soma parcial acumula contribuições de 256 multiplicações conforme flui verticalmente. Criticamente, todos os resultados intermediários passam diretamente entre unidades MAC adjacentes via fios curtos em vez de fazer round-trip para memória. A arquitetura executa 65.536 operações multiply-accumulate a cada ciclo de clock, e durante toda a multiplicação de matrizes envolvendo potencialmente milhões de operações, zero valores intermediários tocam DRAM ou mesmo SRAM on-chip.⁴⁰
O padrão de dataflow weight-stationary otimiza para o caso mais comum em inferência e treinamento de redes neurais: multiplicar repetidamente muitas matrizes de ativação diferentes pela mesma matriz de pesos. Os engenheiros carregam pesos uma vez, então transmitem batches ilimitados de ativação através do array sem recarregar. O padrão funciona excepcionalmente bem para camadas convolucionais, camadas totalmente conectadas, e as operações Q·K^T e attention·V que dominam modelos transformer.⁴¹
A eficiência energética deriva da reutilização de dados e localidade espacial. Ler um valor da DRAM consome aproximadamente 200× mais energia que uma única operação multiply-accumulate.⁴² Ao reutilizar cada peso 256 vezes e cada ativação 256 vezes sem acessos de memória, o array sistólico alcança razões operações-por-watt impossíveis para arquiteturas que transportam dados de um lado para outro entre unidades de computação e hierarquias de memória.
A fraqueza do array sistólico emerge com padrões de computação dinâmicos ou irregulares. Porque dados fluem através da grade em uma programação fixa, a arquitetura luta com execução condicional, matrizes esparsas (a menos que usando SparseCore), e operações que requerem padrões de acesso aleatório. A inflexibilidade troca generalidade por eficiência extrema em sua carga de trabalho alvo: multiplicação densa de matrizes com padrões de acesso previsíveis.
Arquitetura Interna do TensorCore
Cada chip TPU contém um ou mais TensorCores—a unidade de processamento completa compreendendo a Matrix Multiply Unit, Vector Processing Unit e Scalar Unit trabalhando em conjunto.⁴³ O TensorCore representa o bloco de construção fundamental que o software visa, e entender a interação entre seus três componentes explica tanto características de desempenho TPU quanto padrões de programação.
A Matrix Multiply Unit executa 16.000 operações multiply-accumulate por ciclo em entradas bfloat16 ou FP8 com acumulação FP32.⁴⁴ A abordagem de precisão mista preserva precisão numérica no acumulador enquanto reduz largura de banda de memória para entradas. Os engenheiros observaram que manter precisão FP32 completa durante acumulação previne erros catastróficos de cancelamento ao somar centenas ou milhares de produtos intermediários, enquanto entradas de precisão reduzida raramente afetam qualidade final do modelo.
A Vector Processing Unit lida com operações mal adequadas à estrutura rígida da MXU. Funções de ativação (ReLU, GELU, SiLU), camadas de normalização (batch norm, layer norm), softmax, pooling, dropout e operações elemento-wise executam na arquitetura SIMD de 128 lanes da VPU.⁴⁵ A VPU opera em tipos de dados FP32 e INT32, fornecendo a precisão requerida para operações numericamente sensíveis como softmax, onde exponenciais e divisões podem criar grandes faixas dinâmicas.
A Scalar Unit orquestra todo o TensorCore. O processador single-threaded executa fluxo de controle, calcula endereços de memória para padrões de indexação complexos, e inicia transferências DMA da High Bandwidth Memory para Vector Memory.⁴⁶ Porque a scalar unit executa single-threaded, cada TensorCore pode criar apenas uma solicitação DMA por ciclo—um gargalo para operações intensivas em memória que não saturam o throughput de computação da MXU ou VPU.
A hierarquia de memória alimentando o TensorCore determina desempenho alcançável tanto quanto capacidade de computação bruta. A Vector Memory (VMEM) atua como uma SRAM scratchpad gerenciada por software exclusiva a cada TensorCore, tipicamente dimensionada em dezenas de megabytes. O compilador XLA agenda explicitamente movimento de dados entre HBM e VMEM, decidindo o que staging na memória local rápida e quando escrever resultados de volta.⁴⁷
A Common Memory (CMEM), presente em gerações TPU v4 e posteriores, fornece um pool compartilhado maior acessível a todos TensorCores em um chip. A arquitetura TPU v4 alocou 128MB de CMEM compartilhada entre dois TensorCores, habilitando padrões mais sofisticados producer-consumer nos quais saídas de um core alimentam entradas de outro core sem round-trip para HBM.⁴⁸
As implicações do modelo de programação importam enormemente. Porque a scalar unit é single-thread e a vector memory requer gerenciamento explícito, programação TPU assemelha-se ao desenvolvimento de sistemas embarcados da era 1990s mais que programação GPU moderna. CUDA abstrai movimento de memória com unified memory e caches gerenciados por hardware; código TPU (seja gerado por XLA ou escrito à mão em Pallas) deve orquestrar explicitamente cada transferência de dados. Controle manual habilita otimização expert mas eleva a barra para desempenho competente.
Arquitetura de High Bandwidth Memory
TPUs modernas usam HBM (High Bandwidth Memory), ou HBM3e, uma tecnologia de memória radicalmente diferente da DDR SDRAM encontrada em CPUs, e da GDDR usada em muitas GPUs. HBM empilha múltiplos dies DRAM verticalmente usando through-silicon vias (TSVs), então coloca a pilha diretamente adjacente ao die do processador em um interposer de silício.⁴⁹ O caminho elétrico curto e interface ampla habilitam largura de banda dramaticamente maior que tecnologias de memória convencionais.
A TPU v7 Ironwood implementa 192GB de HBM3e com largura de banda total de 7.4 TB/s.⁵⁰ O sistema de memória é dividido em múltiplos canais, cada um fornecendo acesso independente a uma porção separada da capacidade total. O compilador XLA e runtime devem cuidadosamente particionar tensores através dos canais HBM para maximizar acesso paralelo e evitar hotspots onde um canal satura enquanto outros ficam ociosos.
A largura da interface de memória empequeñece DRAM convencional. Onde um canal DDR5 pode fornecer 64 bits de largura, um canal HBM tipicamente abrange 1.024 bits.⁵¹ A largura extrema habilita alta largura de banda em velocidades de clock relativamente modestas, reduzindo consumo de energia e desafios de integridade de sinal comparado a empurrar interfaces estreitas para frequências multi-gigahertz.
Características de latência diferem substancialmente de sistemas de memória GPU. TPUs carecem de caches gerenciados por hardware além de pequenos buffers locais, então a arquitetura depende de software staging explícito de dados em VMEM bem antes das unidades de computação precisarem deles. A falta de caches significa que latência de memória impacta diretamente desempenho a menos que o compilador esconda com sucesso latência através de prefetching e double-buffering.⁵²
Limites de capacidade de memória dominam muitas cargas de trabalho mais que throughput de computação. Um modelo de 175 bilhões de parâmetros com pesos bfloat16 requer 350GB para armazenar parâmetros—já excedendo os 192GB HBM do Ironwood mesmo antes de considerar ativações, estados de optimizer, ou buffers de gradiente. Treinar tais modelos demanda técnicas sofisticadas como gradient checkpointing, sharding de estado de optimizer através de múltiplos chips, e agendamento cuidadoso de atualizações de parâmetros para minimizar pegada de memória.⁵³
O runtime TPU impõe requisitos específicos de layout de tensor para maximizar eficiência MXU. Porque o array sistólico processa dados em tiles 128×8, tensores devem alinhar a essas dimensões para evitar desperdício de padding.⁵⁴ Matrizes mal dimensionadas forçam o hardware a processar tiles parciais com MACs ociosos, reduzindo diretamente utilização de FLOPS. O compilador tenta pads e reshape tensores automaticamente, mas escolhas conscientes de layout na arquitetura do modelo podem melhorar substancialmente desempenho.
SparseCore: Aceleração Especializada de Embedding
Enquanto a Matrix Multiply Unit excela em operações densas de matriz, cargas de trabalho intensivas em embedding exibem características radicalmente diferentes. Modelos de recomendação, sistemas de ranking e grandes modelos de linguagem frequentemente acessam tabelas de embedding massivas (frequentemente centenas de gigabytes) através de índices irregulares, dependentes de dados. O dataflow estruturado da MXU não fornece vantagem para esses padrões de acesso de memória esparsa, motivando a arquitetura especializada do SparseCore.⁵⁵
SparseCore implementa um processador de dataflow tiled fundamentalmente diferente do array sistólico da MXU. A TPU v4 apresentava quatro SparseCores por chip, cada um contendo 16 tiles de computação.⁵⁶ Cada tile opera como uma unidade de dataflow independente com memória scratchpad local (SPMEM) e elementos de processamento. Os tiles executam em paralelo, processando subconjuntos disjuntos de operações de embedding simultaneamente.
A hierarquia de memória coloca dados hot em SPMEM pequena e rápida enquanto mantém as tabelas de embedding completas em HBM. O compilador XLA analisa padrões de acesso de embedding para determinar quais vetores de embedding merecem cache em SPMEM versus buscar sob demanda da HBM.⁵⁷ A estratégia assemelha-se a hierarquias de cache CPU tradicionais, mas com software em vez de hardware fazendo decisões de placement.
SparseCores conectam diretamente aos canais HBM, contornando o caminho de memória do TensorCore inteiramente. A conexão dedicada previne operações de embedding de competir com operações densas de matriz por largura de banda de memória, habilitando ambas a proceder em paralelo.⁵⁸ O particionamento funciona excepcionalmente bem para modelos como Deep Learning Recommendation Models (DLRMs) que intercalam camadas densas de redes neurais com grandes lookups de embedding.
A estratégia mod-sharding distribui embeddings através de SparseCores computando target_sc_id = col_id % num_total_sparse_cores.⁵⁹ A função de sharding simples garante balanceamento de carga quando IDs de embedding são distribuídos uniformemente, mas pode criar hotspots para padrões de acesso enviesados. Engenheiros trabalhando com dados do mundo real frequentemente precisam analisar distribuições de frequência de embedding e rebalancear manualmente sharding para evitar gargalos.
Ganhos de desempenho do SparseCore alcançam 5-7× comparado a implementar operações idênticas na MXU e VPU, enquanto consomem apenas 5% da área do die do chip e energia.⁶⁰ A vantagem dramática de eficiência deriva de construir o dataflow propositalmente para operações esparsas em vez de forçá-las através de infraestrutura de matriz densa. O princípio de especialização aplica-se recursivamente dentro da arquitetura TPU: assim como TPUs se especializam além do design de propósito geral das GPUs, SparseCores se especializam além do design orientado a matrizes das TPUs.
O SparseCore de terceira geração do Trillium introduziu largura SIMD variável (8 elementos para FP32, 16 para bfloat16) e melhorou padrões de acesso de memória, reduzindo largura de banda desperdiçada de leituras desalinhadas.⁶¹ A evolução arquitetural demonstra o investimento contínuo do Google em aceleração de embedding conforme grandes modelos de linguagem tendem a vocabulários maiores e padrões mais sofisticados de retrieval-augmented generation.
Tecnologia de Interconexão: Conectando o Supercomputador
Arquitetura de Interconexão Inter-Chip (ICI)
A Interconexão Inter-Chip é a tecnologia crítica que permite aos TPUs funcionarem como supercomputadores unificados ao invés de aceleradores isolados. Diferentemente de GPUs que se comunicam através de redes Ethernet ou InfiniBand, o ICI implementa links seriais personalizados de alta velocidade conectando diretamente TPUs vizinhos com latência na escala de microssegundos e largura de banda de terabits por segundo.⁶²
A evolução da topologia entre gerações de TPU reflete requisitos em mudança para escalabilidade de pod. TPU v2, v3, v5e e v6e implementam topologias de toro 2D nas quais cada chip se conecta aos seus quatro vizinhos mais próximos (norte, sul, leste e oeste).⁶³ Os links se conectam nas bordas, criando uma topologia lógica em formato de donut que elimina chips de borda com menos conexões. Uma grade 16×16 de 256 TPUs assim oferece características uniformes de largura de banda e latência independentemente de quais dois chips se comunicam.
TPU v4 e v5p evoluíram para topologias de toro 3D com cada chip se conectando a seis vizinhos.⁶⁴ A dimensão adicional reduz o diâmetro da rede—a contagem máxima de saltos entre quaisquer dois chips—de aproximadamente 2√N para 3∛N. Para um pod de 4.096 chips, os saltos máximos caem de aproximadamente 128 para 48, reduzindo substancialmente a latência de comunicação no pior caso para operações de sincronização global como all-reduce.
A estrutura toroidal oferece outra vantagem crítica: largura de banda de bisseção igual independentemente de como as cargas de trabalho se particionam entre chips. Qualquer corte que divide o toro pela metade cruza o mesmo número de links, prevenindo casos patológicos onde o posicionamento inadequado de jobs cria gargalos de rede.⁶⁵ A largura de banda de bisseção uniforme simplifica o escalonamento e habilita a reconfigurabilidade do switch de circuito óptico discutida abaixo.
As especificações de largura de banda escalam impressionantemente entre gerações. TPU v6e fornece 13 TB/s de largura de banda ICI por chip.⁶⁶ TPU v5p alcançou 4.800 Gbps por chip através de seis links de toro 3D.⁶⁷ Ironwood implementa quatro links ICI com largura de banda bidirecional agregada de 9,6 Tbps, traduzindo-se em 1,2 TB/s por chip.⁶⁸ Para comparação, uma interface de rede 400GbE de primeira linha fornece 50GB/s de largura de banda bidirecional—uma ordem de magnitude menor que o ICI de TPU moderno.
A tecnologia de link dentro de racks usa cabos copper de conexão direta (DAC) para distâncias curtas entre chips no mesmo cubo 4×4×4.⁶⁹ As conexões de cobre minimizam custo e energia enquanto fornecem a largura de banda necessária para chips fortemente acoplados executando operações sincronizadas. Links inter-cubo e em escala de pod transitam para transceptores ópticos, trocando maior custo e energia pela distância e largura de banda necessárias para abranger racks de datacenter.
Operações coletivas exploram as propriedades únicas do ICI. Operações all-reduce, all-gather e reduce-scatter frequentemente sincronizam ativações e gradientes entre chips durante o treinamento. Em clusters de GPU baseados em Ethernet, essas coletivas atravessam uma rede hierárquica com switches, cabos e placas de interface de rede, introduzindo latência a cada salto. O ICI de TPU implementa algoritmos coletivos otimizados diretamente em hardware, executando operações all-reduce 10× mais rapidamente que implementações equivalentes de GPU baseadas em Ethernet.⁷⁰
Comutação de Circuito Óptico: Reconfiguração Dinâmica de Topologia
A implantação da comutação de circuito óptico (OCS) do Google com TPU v4 representou uma das inovações mais significativas em redes de datacenter em décadas. Redes tradicionais de comutação de pacotes—seja Ethernet ou InfiniBand—estabelecem conexões lógicas roteando pacotes salto-a-salto através de switches que examinam cabeçalhos e encaminham para portas de saída apropriadas. OCS ao invés disso usa elementos ópticos programáveis para criar caminhos físicos diretos de luz entre pontos finais, eliminando completamente a latência de comutação.⁷¹
A tecnologia central depende de espelhos MEMS (sistemas microeletromecânicos) que rotacionam fisicamente para redirecionar feixes de luz. Um transmissor no TPU A envia luz para o OCS. Pequenos espelhos dentro do OCS rotacionam para refletir esse feixe de luz para um receptor no TPU B. A conexão torna-se um caminho óptico direto de A para B com essencialmente zero latência adicionada além da propagação da luz através da fibra.⁷²
A velocidade de reconfiguração determina a praticidade do OCS em sistemas de produção. A implantação do Google alcança tempos de comutação sub-10-nanossegundos—mais rápido que tempos típicos de round-trip de protocolos de rede.⁷³ A velocidade de reconfiguração habilita mudanças dinâmicas de topologia correspondendo aos requisitos de carga de trabalho sem interromper jobs em execução ou exigir engenharia de tráfego cuidadosamente coordenada.
TPU v5p demonstrou OCS em escala massiva. A arquitetura usa switches de circuito óptico que entregam quatro petabits por segundo de largura de banda agregada através do fabric de comutação.⁷⁴ Um único superpod v5p requer 48 unidades OCS gerenciando 13.824 portas ópticas para conectar 8.960 chips na configuração de toro 3D 16×20×28.⁷⁵ O sistema de comutação representa uma das maiores implantações de redes ópticas em qualquer ambiente de computação.
OCS fornece capacidades impossíveis com redes tradicionais. Topologia física e topologia lógica se desacoplam completamente—dois TPUs em cantos opostos do datacenter aparecem como vizinhos adjacentes se o OCS criar caminhos ópticos diretos. Chips ou links com falha são contornados reprogramando espelhos para excluir componentes defeituosos e manter a estrutura lógica de toro. Novos jobs recebem "fatias" de qualquer tamanho programando o OCS para criar configurações apropriadas de pod sem recabear fisicamente racks.⁷⁶
A arquitetura integra com a rede de datacenter Jupiter do Google para escalar além de um único pod. Jupiter entrega largura de banda de bisseção multi-petabit-por-segundo através de datacenters inteiros usando switches de silício personalizados do Google e plano de controle.⁷⁷ Múltiplos superpods TPU se conectam via fabric Jupiter, teoricamente suportando clusters de até 400.000 aceleradores se a capacidade de rede permitir.⁷⁸
Características de consumo de energia e confiabilidade favorecem a comutação de circuito óptico para implantações em escala TPU. Switches tradicionais de pacotes consomem energia substancial processando e encaminhando pacotes a taxas de terabit-por-segundo. Switches OCS consomem energia apenas para operar espelhos MEMS durante eventos de reconfiguração, depois ficam ociosos, passando luz com perda mínima enquanto as conexões permanecem estáveis.⁷⁹ A simplicidade da arquitetura melhora a confiabilidade eliminando processamento complexo de pacotes e lógica de buffer propensa a bugs e anomalias de performance.
Arquitetura de Pod e Características de Escalabilidade
Pods TPU representam a maior unidade única de TPUs conectados através de ICI, formando um acelerador unificado. A estrutura física se constrói hierarquicamente de chips individuais para bandejas para cubos para racks para pods completos.⁸⁰ Entender a hierarquia importa para raciocinar sobre capacidade de memória, largura de banda de comunicação e tolerância a falhas em diferentes escalas.
O bloco de construção fundamental consiste de quatro chips em uma única bandeja conectados a uma CPU host via PCIe.⁸¹ A conexão PCIe lida com operações de plano de controle, carregamento inicial de programa e infeed/outfeed para dados de treinamento e resultados de inferência. A comunicação inter-chip real para treinamento distribuído flui através de ICI ao invés de PCIe, evitando gargalos de largura de banda PCIe.
Dezesseis bandejas (64 chips) formam um único cubo 4×4×4—a unidade básica para construção de pod. Dentro de um cubo, todas as conexões ICI usam cabos copper de conexão direta já que chips residem no mesmo rack com distâncias físicas curtas.⁸² O cubo implementa um toro 3D completo com conexões de wraparound, criando uma unidade auto-contida de 64 chips que poderia teoricamente operar independentemente.
Pods TPU v4 escalam para 64 cubos totalizando 4.096 chips.⁸³ As conexões inter-cubo transitam para links ópticos gerenciados pelo fabric de comutação de circuito óptico. O OCS pode provisionar esses 4.096 chips como um único pod enorme, múltiplos pods independentes menores, ou reconfigurar dinamicamente meio-job se necessário. A flexibilidade permite operadores de datacenter balancearem utilização entre diferentes tamanhos e prioridades de job.
TPU v5p empurrou a escala de pod para 8.960 chips em um toro 3D 16×20×28.⁸⁴ As dimensões específicas refletem otimização cuidadosa de largura de banda e diâmetro—fatorações primas importam para topologia de rede! O pod entrega 4,45 exaflops de computação e representa uma das maiores configurações de pod único implantadas em produção.
Ironwood suporta tanto pods de 256 chips para implantações menores quanto superpods de 9.216 chips para treinamento massivo de modelos de fronteira.⁸⁵ A configuração de 9.216 chips entrega 42,5 FP8 exaflops—mais computação que toda a lista Top500 de supercomputadores continha apenas cinco anos antes.⁸⁶ A escala redefine o que organizações podem realizar com treinamento síncrono ao invés de abordagens pipeline ou assíncronas.
Eficiência de escalabilidade determina se pods maiores realmente ajudam. Overhead de comunicação aumenta com tamanho de pod conforme chips gastam mais tempo sincronizando ao invés de computando. Google Research publicou resultados demonstrando 95% de eficiência de escalabilidade em 32.768 TPUs para cargas de trabalho específicas, significando que 32.768 TPUs entregaram 95% da performance que escalabilidade linear perfeita preveria.⁸⁷ A eficiência deriva de coletivas aceleradas por hardware, transformações otimizadas de compilador e abordagens algorítmicas inteligentes para reduzir frequência de sincronização de gradiente.
Tolerância a falhas na escala de pod requer manuseio sofisticado. Probabilidade estatística garante falhas de componentes em qualquer sistema com milhares de chips executando continuamente. O switch de circuito óptico habilita degradação graciosa reconfigurando ao redor de componentes com falha. Checkpointing de treinamento ocorre em intervalos regulares (tipicamente a cada poucos minutos), então falha de job requer reiniciar apenas do último checkpoint ao invés de do zero.⁸⁸
Stack de Software: Compiladores, Frameworks e Modelos de Programação
Compilador XLA: Otimizando Grafos de Computação
XLA (Accelerated Linear Algebra) forma a base do stack de software da TPU, compilando operações de frameworks de alto nível em código de máquina otimizado para execução na TPU.⁸⁹ O compilador implementa otimizações agressivas impossíveis em compiladores de propósito geral porque explora conhecimento de domínio sobre cargas de trabalho de machine learning e características da arquitetura TPU.
Fusão representa a otimização mais impactante do XLA. O compilador analisa grafos de computação para identificar sequências de operações que podem executar sem materializar tensores intermediários. Um exemplo simples: operações element-wise como relu(batch_norm(conv(x))) normalmente requerem escrever a saída da convolução na memória, lê-la para normalização em lote, escrever esse resultado na memória e ler novamente para ReLU. XLA funde essas operações em um único kernel que produz a saída final do ReLU sem tráfego de memória intermediário.⁹⁰
O impacto da fusão escala com a arquitetura da TPU. Largura de banda de memória restringe muitas cargas de trabalho mais que throughput de computação—a MXU pode realizar multiplicações matriciais mais rapidamente que o sistema de memória pode alimentá-la com dados. Eliminar escritas e leituras de memória intermediárias através de fusão se traduz diretamente em melhorias de performance, frequentemente entregando speedup de 2× ou mais para redes com muitas funções de ativação.⁹¹
Transformações de layout de memória otimizam armazenamento de tensores para requisitos de hardware. Redes neurais frequentemente representam tensores no formato NHWC (batch, height, width, channels) para indexação intuitiva, mas MXUs da TPU performam melhor com layouts que se alinham com tiles de 128×8.⁹² XLA automaticamente transpõe, reshape e preenche tensores para coincidir com preferências de hardware, inserindo transformações de layout apenas onde necessário e às vezes propagando layouts preferidos para trás através do grafo para minimizar overhead total de transformação.
O compilador implementa constant folding e dead code elimination sofisticados. Grafos de ML frequentemente contêm subgrafos cujas saídas dependem apenas de constantes—parâmetros de normalização em lote, taxas de dropout para inferência, e cálculos de formato que podem ser executados uma vez ao invés de por lote. XLA avalia esses subgrafos em tempo de compilação e os substitui por tensores constantes, reduzindo trabalho em runtime.⁹³
Otimização cross-replica explora conhecimento sobre execução distribuída. Quando treinando através de múltiplos cores de TPU, certas operações (como estatísticas de normalização em lote) requerem agregação através de todas as réplicas. XLA identifica esses padrões e gera operações coletivas otimizadas que exploram all-reduce acelerado por hardware do ICI ao invés de implementar agregação através de passagem explícita de mensagens.⁹⁴
O compilador visa uma representação intermediária, Mosaic, especificamente para TPUs. Mosaic opera em um nível de abstração mais alto que linguagem assembly mas mais baixo que o grafo de computação de entrada. A linguagem expõe características arquiteturais da TPU, como arrays sistólicos, memória vetorial e staging VMEM, enquanto esconde detalhes de baixo nível, como agendamento de instruções e alocação de registradores.⁹⁵
Capacidades de auto-tuning selecionam tamanhos ótimos de tile e parâmetros de operação através de busca empírica. O sistema XLA Auto-Tuning (XTAT) tenta diferentes estratégias de fusão, layouts de memória e dimensões de tile, perfila a performance de cada variante e seleciona a configuração mais rápida.⁹⁶ A busca pode requerer tempo substancial de compilação para modelos complexos, mas produz speedups dramáticos em runtime descobrindo otimizações contra-intuitivas que humanos raramente identificam manualmente.
JAX: Transformações Composáveis e SPMD
JAX fornece uma interface compatível com NumPy para computação numérica com diferenciação automática, compilação JIT para XLA, e suporte de primeira classe para transformação de programa.⁹⁷ O paradigma de programação funcional do framework e modelo de transformação composável se alinham naturalmente com modelos de execução TPU e padrões de paralelismo distribuído.
A abstração central do JAX aplica transformações matemáticas a funções. Grad (f) computa o gradiente de f. Jit (f) JIT-compila f para XLA. vmap(f) vetoriza f sobre uma nova dimensão. Criticamente, transformações compõem: jit(grad(vmap(f))) funciona exatamente como esperado, compilando uma função de gradiente vetorizada.⁹⁸ O modelo composicional permite construir loops de treinamento distribuído complexos a partir de componentes simples e testáveis.
SPMD (Single Program, Multiple Data) representa o modelo de execução distribuída do JAX. Programadores escrevem código como se visassem um único dispositivo, então adicionam anotações de sharding indicando como particionar tensores através de múltiplos cores de TPU. O compilador XLA e subsistema GSPMD (General SPMD) automaticamente inserem operações de comunicação para manter semântica do programa enquanto executam através de dispositivos distribuídos.⁹⁹
Anotações de sharding usam PartitionSpec para declarar estratégias de distribuição. PartitionSpec('batch', None) fragmenta a primeira dimensão de um tensor através do eixo 'batch' do mesh de dispositivos enquanto replica a segunda dimensão. PartitionSpec(None, 'model') implementa paralelismo de tensor particionando a segunda dimensão. As anotações podem ser compostas com ranks arbitrários de tensor e dimensões de mesh de dispositivos.¹⁰⁰
Paralelização automática do GSPMD elimina vastas quantidades de código boilerplate. Treinamento distribuído tradicional requer inserir manualmente um all-gather antes de operações que precisam de tensores completos, um reduce-scatter após computar gradientes distribuídos, e um all-reduce para reduções globais. GSPMD analisa especificações de sharding e automaticamente insere coletivos apropriados, liberando programadores para focar no algoritmo ao invés de engenharia de comunicação.¹⁰¹
O compilador propaga decisões de sharding através do grafo de computação usando resolução de restrições. Se a operação A produz um tensor fragmentado consumido pela operação B, GSPMD infere o sharding ótimo de B baseado em como a saída é usada, potencialmente inserindo operações de resharding apenas onde matematicamente necessário.¹⁰² A inferência automatizada previne o "spaghetti de sharding" que aflige código distribuído escrito à mão.
JAX fornece controle fino quando automação falha. with_sharding_constraint força sharding específico em localizações do grafo, sobrescrevendo inferência automática. Anotações PJIT (parallel JIT) customizadas especificam posicionamento exato de dispositivo e estratégias de sharding para caminhos de código críticos para performance. O modelo em camadas permite prototipagem rápida com sharding automático enquanto suporta otimização especializada onde requerido.¹⁰³
Shardy emergiu como sucessor do GSPMD em 2025, implementando algoritmos melhorados de propagação de restrições e melhor manipulação de formas dinâmicas.¹⁰⁴ O novo sistema expõe oportunidades adicionais de otimização raciocinando sobre escolhas de sharding conjuntamente através de regiões maiores do grafo ao invés de operação por operação.
PyTorch/XLA: Trazendo PyTorch para TPUs
PyTorch/XLA permite executar modelos PyTorch em TPUs com mudanças mínimas de código, conectando a lacuna entre o modelo de programação imperativo do PyTorch e compilação baseada em grafo do XLA.¹⁰⁵ A integração equilibra preservar a experiência de desenvolvedor do PyTorch com exposição de otimizações específicas de TPU.
O desafio fundamental deriva da filosofia de execução eager do PyTorch. PyTorch executa operações imediatamente conforme declarações Python executam, habilitando debugging com ferramentas padrão e fluxo de controle natural. XLA requer capturar grafos de computação completos antes da compilação, criando tensão entre execução eager e os benefícios de performance da compilação de grafo.¹⁰⁶
PyTorch/XLA 2.4 introduziu suporte a modo eager, abordando o impedance mismatch. A implementação dinamicamente rastreia operações PyTorch em grafos XLA, permitindo desenvolvedores escrever código PyTorch padrão enquanto ainda se beneficiam da compilação XLA.¹⁰⁷ O modo troca algumas oportunidades de otimização de compilação por velocidade de desenvolvimento e simplicidade de debugging.
Modo de grafo permanece o caminho principal para deployments de produção. Desenvolvedores explicitamente marcam funções para compilação XLA usando decoradores ou APIs de compilação. As anotações explícitas habilitam otimização agressiva mas requerem entender quais operações devem ser fundidas em um único grafo XLA versus executadas independentemente.¹⁰⁸
Integração Pallas traz desenvolvimento de kernel customizado para PyTorch/XLA. Pallas fornece uma linguagem de baixo nível para escrever kernels TPU quando fusão automática do XLA falha ou operações especializadas requerem otimização manual.¹⁰⁹ A linguagem expõe hierarquia de memória TPU (VMEM, CMEM, HBM) e unidades de computação (MXU, VPU) enquanto permanece de nível mais alto que assembly puro.
Kernels Pallas built-in implementam operações críticas para performance como FlashAttention e PagedAttention. Computação de atenção tiled do FlashAttention reduz requisitos de largura de banda de memória de O(n²) para O(n) para comprimento de sequência n, habilitando modelos a processar sequências muito mais longas dentro de orçamentos fixos de memória.¹¹⁰ PagedAttention otimiza gerenciamento de cache key-value para serving, alcançando speedup de 5× comparado a implementações padded.¹¹¹
A bridge PyTorch/XLA provou crítica para vLLM TPU—um framework de serving de alta performance projetado inicialmente para GPUs. A implementação na verdade usa JAX como caminho intermediário de lowering mesmo para modelos PyTorch, explorando suporte superior de paralelismo do JAX enquanto mantém compatibilidade de frontend PyTorch.¹¹² A arquitetura alcançou melhorias de performance de 2-5× ao longo de 2025 comparado a protótipos iniciais.
Desafios de compatibilidade de modelo persistem apesar de melhorias. Algumas operações PyTorch carecem de equivalentes XLA, forçando fallback para execução CPU que degrada performance. Fluxo de controle dinâmico é pobremente suportado por compilação de grafo, frequentemente necessitando mudanças arquiteturais para substituir comportamento dinâmico com alternativas estáticas e compiláveis. O repositório PyTorch/XLA documenta compatibilidade e fornece guias de migração para padrões problemáticos comuns.¹¹³
Formatos de Precisão: BFloat16, FP8 e Quantização
Suporte da TPU para aritmética de precisão reduzida habilita melhorias dramáticas de performance e memória enquanto mantém qualidade de modelo aceitável. Entender as propriedades numéricas de diferentes formatos e quando aplicar cada um prova crítico para alcançar performance ótima.¹¹⁴
BFloat16 representa a aposta inicial do Google em treinamento de precisão reduzida, primeiro aparecendo na TPU v2. O formato mantém o expoente de 8 bits do FP32 enquanto trunca a mantissa para 7 bits (mais bit de sinal).¹¹⁵ A faixa completa de expoente previne o underflow e overflow que afligiam treinamento FP16 inicial, onde gradientes frequentemente escapavam da faixa representável do FP16.
A mantissa reduzida introduz erro de quantização mas raramente impacta qualidade final do modelo. Engenheiros observaram que modelos treinados em bfloat16 tipicamente coincidem com baselines treinados em FP32 dentro do ruído estatístico, provavelmente porque a quantização atua como uma forma de regularização, prevenindo overfitting a pequenos detalhes numéricos.¹¹⁶ O formato corta pela metade largura de banda de memória e requisitos de capacidade comparado a FP32, traduzindo-se diretamente em ganhos de performance em cargas de trabalho limitadas por memória.
FP8 leva precisão reduzida mais longe, comprimindo pesos e ativações para 8 bits. Duas codificações padrão existem: E4M3 (expoente de 4 bits, mantissa de 3 bits) prioriza precisão para passes forward, enquanto E5M2 (expoente de 5 bits, mantissa de 2 bits) prioriza faixa para passes backward onde magnitudes de gradiente variam amplamente.¹¹⁷ Ironwood implementa suporte nativo FP8 para ambos os formatos, enquanto TPUs anteriores emulavam FP8 através de transformações de software.¹¹⁸
Consciência de quantização durante treinamento habilita sucesso numérico do FP8. Modelos treinados do zero com FP8 ou fine-tuned com técnicas FP8-aware aprendem distribuições de peso que toleram a precisão limitada do formato. Quantização pós-treinamento (convertendo modelos FP32 para FP8 após treinamento) frequentemente degrada qualidade sem calibração cuidadosa.¹¹⁹
Quantização INT8 entrega economias de memória ainda maiores e speedups de inferência. Accurate Quantized Training (AQT) do Google habilita treinamento INT8 em TPUs com perda mínima de qualidade comparado a baselines bfloat16.¹²⁰ A técnica aplica treinamento quantization-aware do zero, permitindo modelos adaptarem a restrições INT8 durante aprendizado ao invés de através de aproximação pós-treinamento.
Estratégias de precisão mista combinam formatos estrategicamente. Passes forward podem usar FP8 para ativações e pesos, passes backward usam FP8 E5M2 ou bfloat16 para gradientes, e estados do optimizer permanecem em FP32 para estabilidade numérica durante atualizações de peso.¹²¹ A abordagem mista equilibra velocidade, memória e acurácia, frequentemente alcançando 90%+ da qualidade FP32 enquanto executa 4× mais rápido.
Tradeoffs de precisão se estendem além de velocidade e memória para incluir considerações de estabilidade numérica. Batch normalization, layer normalization e softmax requerem manipulação numérica cuidadosa em precisão reduzida. Exponenciais grandes em softmax podem causar overflow em faixas FP8 ou bfloat16; subtrair o logit máximo antes da exponenciação previne overflow enquanto mantém equivalência matemática.¹²² O compilador XLA implementa essas transformações automaticamente quando seguro, mas operações customizadas às vezes requerem engenharia numérica manual.
Modelos de Programação e Estratégias de Paralelismo
SPMD e Particionamento Automático
O paradigma Single Program, Multiple Data (SPMD) molda fundamentalmente como os programadores pensam sobre a execução em TPU. Em vez de escrever código explícito de message-passing para coordenar múltiplos processos, os desenvolvedores escrevem um único programa e anotam como os dados devem ser particionados entre dispositivos.¹²³ O compilador cuida dos detalhes mecânicos de distribuição, comunicação e sincronização.
GSPMD (General SPMD) implementa a lógica de particionamento automático no XLA. O sistema analisa anotações de sharding de tensores e a estrutura do grafo computacional para determinar onde as operações são executadas em quais dispositivos e qual comunicação é necessária para manter a semântica correta.¹²⁴ A automação elimina classes inteiras de bugs comuns em código distribuído escrito manualmente—formatos de tensor incompatíveis, ordenações incorretas de operações coletivas e deadlocks de sincronização inadequada.
O mecanismo de propagação de restrições do compilador infere decisões de sharding a partir de anotações mínimas. Anotar apenas o sharding de entrada e saída de um modelo frequentemente é suficiente; GSPMD propaga restrições através de operações intermediárias e automaticamente seleciona distribuições eficientes.¹²⁵ Quando múltiplos shardings válidos existem para uma operação, o compilador estima os custos de comunicação das alternativas e seleciona a opção de menor custo.
Otimizações avançadas sobrepõem comunicação com computação. Operações all-reduce que sincronizam gradientes entre réplicas podem começar assim que os gradientes da primeira camada são completados, executando em paralelo com passes backward para camadas subsequentes.¹²⁶ O compilador automaticamente agenda coletivos para maximizar a sobreposição, reduzindo o tempo de comunicação adequado em 2× ou mais comparado à execução sequencial.
Rematerialização troca computação por memória. Em vez de armazenar todas as ativações do passe forward para computação de gradiente, o compilador recomputa seletivamente ativações durante passes backward quando a pressão de memória excede limites.¹²⁷ O tradeoff funciona particularmente bem em TPUs onde a computação frequentemente supera a largura de banda de memória, tornando a recomputação mais barata que o tráfego de memória.
Paralelismo de Dados, Paralelismo de Tensor e Paralelismo de Pipeline
Paralelismo de dados representa a estratégia de treinamento distribuído mais direta: replicar o modelo completo entre N dispositivos e processar batches de dados diferentes em cada réplica. Após computar gradientes localmente, um all-reduce agrega gradientes entre réplicas, e todos os dispositivos aplicam atualizações de peso idênticas.¹²⁸ A abordagem escala linearmente até o tempo de comunicação dominar o tempo de computação—tipicamente em torno de 1.000 GPUs com rede Ethernet mas 10.000+ TPUs com ICI.¹²⁹
Paralelismo de tensor (também chamado paralelismo de modelo) particiona operações individuais entre dispositivos. Uma multiplicação de matriz Y = W @ X divide a matriz de peso W entre dispositivos, com cada um computando uma porção da saída.¹³⁰ A estratégia permite treinar modelos que excedem a memória de dispositivo único ao distribuir armazenamento de parâmetros e computação.
O padrão de comunicação para paralelismo de tensor difere significativamente do paralelismo de dados. Em vez de all-reduce após cada camada, paralelismo de tensor requer um all-gather antes de operações que necessitam tensores completos e um reduce-scatter após computações distribuídas.¹³¹ O volume de comunicação escala com o tamanho de ativação do modelo em vez do tamanho de parâmetro, criando gargalos diferentes do paralelismo de dados.
Paralelismo de pipeline particiona camadas sequenciais de modelo entre dispositivos, processando diferentes micro-batches em diferentes estágios simultaneamente. GPipe introduziu a estratégia com agendamento cuidadoso para maximizar utilização de pipeline enquanto limita uso de memória.¹³² Cada dispositivo processa o passe forward de um micro-batch, envia ativações para o próximo estágio, então processa o próximo micro-batch—criando um pipeline onde todos os dispositivos trabalham continuamente após o ramp-up inicial.
Staleness de gradiente complica o paralelismo de pipeline. Dispositivos atualizam pesos usando gradientes computados de ativações potencialmente dezenas de micro-batches antigas, criando staleness que pode prejudicar a convergência.¹³³ Algoritmos de agendamento sofisticados como PipeDream minimizam staleness enquanto mantêm alto throughput, e resultados empíricos demonstram que a maioria dos modelos tolera staleness moderado sem degradação de qualidade.
Paralelismo 3D combina todas as três estratégias. Paralelismo de dados distribui na dimensão "dados", paralelismo de tensor na dimensão "modelo", e paralelismo de pipeline na dimensão "pipeline".¹³⁴ Balancear cuidadosamente dimensões baseado na arquitetura do modelo, topologia de hardware e custos de comunicação maximiza throughput. Modelos em escala GPT-3 comumente usam paralelismo 3D com paralelismo de dados entre 8-16 réplicas, paralelismo de tensor entre 4-8 GPUs, e paralelismo de pipeline entre 4-16 estágios.
Estratégias de Sharding e Otimização
Selecionar estratégias de sharding requer entender as operações matemáticas e suas dependências de dados. Multiplicação de matriz C = A @ B permite múltiplos shardings válidos: replicar tanto A quanto B e computar resultados parciais (comunicação antes da computação), fazer shard de B por coluna e reunir resultados (comunicação após computação), ou fazer shard de A por linha e B por coluna sem comunicação mas com matrizes menores por dispositivo.¹³⁵
Custos de operação coletiva determinam estratégias ótimas. Custos de all-reduce escalam linearmente com tamanho de tensor mas sublinearmente com contagem de dispositivos usando algoritmos de redução baseados em árvore ou anel:¹³⁶ All-gather e reduce-scatter exibem propriedades de escalonamento diferentes. O compilador modela esses custos e seleciona estratégias de sharding minimizando tempo total de comunicação.
Paralelismo de sequência emerge como crítico para modelos de linguagem grandes. Mecanismos de atenção criam gargalos de memória porque caches key-value crescem com comprimento de sequência e tamanho de batch. Particionar ao longo da dimensão de sequência distribui o fardo de memória entre dispositivos enquanto introduz comunicação apenas para a computação de atenção em si.¹³⁷
Paralelismo de expert lida com modelos Mixture-of-Experts (MoE) onde diferentes experts processam diferentes tokens. A estratégia de sharding replica camadas compartilhadas em todos os dispositivos mas particiona experts, roteando cada token para seu dispositivo expert designado.¹³⁸ O roteamento dinâmico cria padrões de comunicação irregulares que desafiam operações coletivas tradicionais, requerendo sistemas de runtime sofisticados para minimizar latência e desbalanceamento de carga.
Sharding de estado do otimizador reduz overhead de memória para modelos grandes. Otimizadores como Adam armazenam estatísticas de momentum e variância para cada parâmetro, o que triplica requisitos de memória além daqueles para parâmetros sozinhos. Fazer sharding de estados de otimizador entre dispositivos enquanto mantém parâmetros replicados permite treinar modelos maiores dentro de orçamentos fixos de memória.¹³⁹ A estratégia requer reunir atualizações de estado de otimizador durante computações de peso mas reduz substancialmente a pegada de memória por dispositivo.
Análise de Desempenho e Benchmarking
Resultados MLPerf e Posicionamento Competitivo
O MLPerf fornece benchmarks padrão da indústria medindo o desempenho de aceleradores AI em cargas de trabalho de treinamento e inferência. O Google regularmente submete resultados de TPU demonstrando desempenho competitivo, e a evolução entre gerações mostra claras melhorias arquiteturais.¹⁴⁰
A TPU v5e alcançou resultados líderes em 8 das 9 categorias de treinamento MLPerf.¹⁴¹ A amplitude demonstra versatilidade arquitetural além de apenas large language models—desempenho competitivo em visão computacional, sistemas de recomendação e cargas de trabalho de computação científica. O treinamento BERT foi concluído 2.8× mais rápido que as GPUs NVIDIA A100, validando a arquitetura otimizada para transformers.¹⁴²
O MLPerf Training v5.0, anunciado em junho de 2025, introduziu um benchmark Llama 3.1 405B representando o maior modelo na suíte.¹⁴³ O benchmark testa escalabilidade multi-nós, overhead de comunicação e capacidade de memória mais do que testes anteriores. O Google Cloud participou com submissões de TPU, embora comparações detalhadas de desempenho permaneçam embargadas aguardando a publicação dos resultados oficiais.
O MLPerf Inference v5.0 incluiu quatro novos benchmarks: Llama 3.1 405B, Llama 2 70B para aplicações de baixa latência, redes neurais gráficas RGAT e PointPainting para detecção de objetos 3D.¹⁴⁴ A diversidade empurra os aceleradores além das cargas de trabalho convencionais de transformers para domínios emergentes de aplicação onde suposições arquiteturais podem diferir.
Benchmarks de inferência particularmente favorecem os pontos fortes arquiteturais da TPU. Cargas de trabalho de inferência em lote alavancam o paralelismo massivo da MXU, alcançando throughput 4× maior que aceleradores concorrentes para servir transformers.¹⁴⁵ A latência de consulta única se beneficia da execução determinística da TPU e ausência de throttling térmico, entregando latência consistente sem a variância de desempenho que aflige alguns deployments de GPU.
Métricas de eficiência energética mostram vantagens da TPU se expandindo entre gerações. A TPU v4 demonstrou 2.7× melhor desempenho por watt que a TPU v3, e Trillium melhorou 67% sobre v5e.¹⁴⁶ Ironwood reivindica 2× melhor desempenho por watt que Trillium apesar de desempenho absoluto significativamente maior.¹⁴⁷ Os ganhos de eficiência se acumulam em pods de milhares de chips, traduzindo-se em milhões de dólares em custos operacionais de datacenter.
Desempenho Real de Treinamento e Inferência
Cargas de trabalho de produção revelam características de desempenho ausentes de benchmarks sintéticos. O Google publica resultados de serviços internos demonstrando comportamento da TPU sob padrões reais de uso e requisitos de escalabilidade.¹⁴⁸
O treinamento ResNet-50 ImageNet completa em 28 minutos em pods TPU, um benchmark amplamente citado para desempenho de carga de trabalho de visão computacional.¹⁴⁹ A métrica de tempo-para-precisão captura o processo completo de treinamento, incluindo carregamento de dados, augmentação, sincronização distribuída de gradientes e salvamento de checkpoints—não apenas FLOPs teóricos.
O treinamento do modelo de linguagem T5-3B demonstra vantagens da TPU em arquiteturas transformer. O modelo de 3 bilhões de parâmetros treina em 12 horas em pods TPU, comparado a 31 horas em configurações GPU equivalentes.¹⁵⁰ A aceleração de 2.6× deriva de operações de atenção aceleradas por hardware, utilização eficiente de largura de banda de memória e comunicações coletivas otimizadas.
Cargas de trabalho escala GPT-3 (175B parâmetros) alcançam tempo-para-precisão 1.7× mais rápido em TPUs do que em GPUs contemporâneas.¹⁵¹ A diferença de desempenho aumenta para modelos ainda maiores, onde capacidade e largura de banda de memória se tornam restrições críticas. A HBM3e de 192GB da Ironwood permite servir modelos que requerem paralelismo de tensores complexo em alternativas de menor memória.
Medições de eficiência de escala demonstram speedup quase linear para escalas enormes. O Google Research reportou 95% de eficiência de escala em 32,768 TPUs para cargas de trabalho específicas de treinamento de transformer.¹⁵² A métrica significa que 32,768 TPUs entregaram 95% do desempenho que o escalonamento linear perfeito previria—notável dado que o overhead de comunicação aumenta com a escala.
Métricas de utilização FLOPS revelam quão efetivamente as cargas de trabalho alavancam a computação disponível. Modelos transformer tipicamente alcançam 90% de utilização FLOPS em TPUs, significando que 90% do desempenho teórico de pico é traduzido em trabalho real.¹⁵³ A alta utilização deriva da fusão de operações eliminando gargalos de memória, eficiência de arrays sistólicos em multiplicações de matrizes grandes e otimizações do compilador que minimizam ciclos desperdiçados.
Serviços de inferência de produção demonstram desempenho sustentado em bilhões de consultas por dia. O Google Translate processa 1 bilhão de solicitações diariamente em TPUs.¹⁵⁴ As recomendações do YouTube servem 2 bilhões de usuários usando modelos acelerados por TPU.¹⁵⁵ O Google Photos analisa 28 bilhões de imagens mensalmente para recursos de busca e organização.¹⁵⁶ A escala operacional valida confiabilidade e custo-eficiência além de deployments de protótipos de pesquisa.
Eficiência Energética e Custo Total de Propriedade
O consumo de energia impacta diretamente os custos operacionais de data centers e sustentabilidade ambiental. As melhorias de eficiência energética da TPU entre gerações reduzem tanto despesas operacionais quanto emissões de carbono em escala.¹⁵⁷
A TPU v4 teve média de apenas 200W de consumo de energia em cargas de trabalho de produção apesar de uma especificação TDP de 250W.¹⁵⁸ A margem entre energia média e de pico permite design térmico flexível e provisionamento. Compare com GPUs, onde cargas de trabalho sustentadas frequentemente atingem limites TDP, requerendo orçamentos conservativos de energia de rack.
O TDP de 600W da Ironwood representa maior energia absoluta que gerações anteriores mas entrega dramaticamente mais computação por watt.¹⁵⁹ O desempenho FP8 de 4.6 PFLOPS por chip resulta em aproximadamente 7.7 TFLOPS por watt—competitivo ou excedendo a eficiência de GPU contemporânea em cargas de trabalho equivalentes.
A efetividade de uso de energia do datacenter (PUE) amplifica a eficiência de nível de chip. Os data centers TPU do Google alcançam um PUE de 1.1, significando apenas 10% de overhead de energia além do consumo do chip para resfriamento, conversão de energia e networking.¹⁶⁰ A média da indústria de PUE varia de 1.5 a 2.0, onde 50-100% de energia adicional vai para overhead de infraestrutura. O baixo PUE deriva de sistemas de resfriamento avançados, entrega eficiente de energia e design deliberado de datacenter otimizando para cargas de trabalho ML.
Considerações de intensidade de carbono se estendem além da energia para incluir fontes de energia. O Google opera datacenters TPU com energia carbono-neutra através de aquisição de energia renovável e programas de compensação de carbono.¹⁶¹ A contabilização de carbono importa crescentemente para organizações rastreando emissões Scope 2 de computação em nuvem.
Análise de custo total de propriedade (TCO) deve contabilizar custos de aquisição, consumo de energia, requisitos de resfriamento e despesas de manutenção. Deployments TPU comumente mostram reduções de TCO de 20-30% comparados a instalações GPU equivalentes, impulsionadas principalmente por desempenho superior por watt e complexidade reduzida de resfriamento.¹⁶²
Custos de infraestrutura de resfriamento escalam não-linearmente com densidade de energia. Racks resfriados a ar tipicamente chegam ao máximo de 15-20kW por rack antes de requerer soluções exóticas de resfriamento. GPUs de alta potência empurram esses limites, às vezes necessitando infraestrutura de resfriamento líquido com custos substancialmente maiores de capital e operacionais. A eficiência da TPU mantém mais deployments dentro da faixa de resfriamento a ar, simplificando o design de datacenter.¹⁶³
Vantagens Técnicas: Onde as TPUs se Destacam
Operações Coletivas Aceleradas por Hardware
O suporte especializado a operações coletivas no TPU ICI oferece uma das vantagens mais significativas em relação aos aceleradores tradicionais conectados em rede. A operação all-reduce, que é fundamental para sincronizar gradientes no treinamento distribuído, executa 10× mais rápido no TPU ICI do que implementações equivalentes baseadas em Ethernet com GPU.¹⁶⁴
A diferença de performance deriva da integração arquitetural. As operações coletivas baseadas em Ethernet atravessam múltiplas camadas: o código da aplicação invoca a biblioteca coletiva (NCCL, Horovod, etc.), que gera pacotes que são entregues à pilha de rede, que transfere dados para a NIC, que serializa no cabo, atravessa switches, deserializa nas NICs receptoras e reverte o processo. Cada camada adiciona latência, copia dados através das hierarquias de memória e consome ciclos de CPU para processamento de protocolo.¹⁶⁵
O TPU ICI implementa operações coletivas em hardware sem atravessar a camada de software. A operação inicia diretamente do TensorCore, transmite dados por links ICI dedicados e completa sem envolver a CPU host. O caminho direto de hardware elimina o overhead que domina implementações tradicionais.¹⁶⁶
A topologia de circuit-switch óptico permite algoritmos coletivos otimizados. O all-reduce baseado em anel requer apenas 2(N-1) mensagens para N dispositivos, e a topologia torus fornece roteamento de caminho mais curto, minimizando latência.¹⁶⁷ A largura de banda uniforme de bissecção previne gargalos onde operações coletivas mal roteadas congestionam links de rede.
Espaço de Memória Unificado e Programação Simplificada
O modelo de memória unificado da TPU simplifica a programação comparado às hierarquias complexas de memória das GPUs. Os programadores raciocinam sobre um único pool HBM em vez de gerenciar transferências entre RAM host, memória global da GPU, memória compartilhada e arquivos de registradores. O modelo simplificado reduz bugs e permite velocidade de desenvolvimento mais rápida.¹⁶⁸
A fragmentação de memória deixa de ser uma preocupação. GPUs alocam memória de um heap fragmentado, onde alocações e desalocações ao longo do tempo criam lacunas que requerem compactação. O gerenciamento de memória da TPU via análise estática do compilador evita fragmentação em tempo de execução inteiramente—tensores são atribuídos a locais predeterminados baseados no grafo de computação.¹⁶⁹
O modelo de programação elimina classes inteiras de erros CUDA. Não há mais "acesso ilegal à memória" de aritmética de ponteiro incorreta, não há bugs de coerência de cache entre CPU e GPU, não há erros de sincronização de chamadas cudaDeviceSynchronize() ausentes. A abstração de nível mais alto previne as armadilhas comuns na programação CUDA.¹⁷⁰
Execução Determinística e Reprodutibilidade
A não-associatividade de ponto flutuante cria desafios de reprodutibilidade em computação paralela. A expressão (a + b) + c pode produzir resultados diferentes de a + (b + c) devido a erros de arredondamento, e reduções paralelas podem somar em ordens diferentes entre execuções dependendo de condições de corrida.¹⁷¹
A execução da TPU exibe determinismo mais forte que implementações típicas de GPU. O padrão fixo de fluxo de dados do systolic array garante ordenação idêntica de operações entre execuções. Operações coletivas seguem árvores de redução determinísticas em vez de agregação oportunística baseada em ordem de chegada. A previsibilidade permite treinamento reproduzível onde hiperparâmetros e dados idênticos produzem pesos de modelo bit-idênticos.¹⁷²
A depuração se beneficia enormemente do determinismo. Treinamento não-determinístico torna a identificação da causa raiz de falhas quase impossível—o NaN vem de um bug algorítmico genuíno ou condição de corrida aleatória? Execução determinística significa que falhas se reproduzem confiavelmente, permitindo abordagens sistemáticas de depuração.¹⁷³
Aplicações de computação científica valorizam particularmente a reprodutibilidade. Modelos climáticos, simulações de descoberta de medicamentos e pesquisa em física requerem resultados verificáveis que permitem a diferentes pesquisadores reproduzir resultados idênticos. O determinismo da TPU suporta melhor o método científico que alternativas não-determinísticas competitivas.¹⁷⁴
Otimizações do Compilador e Produtividade do Desenvolvedor
A otimização agressiva do XLA oferece melhorias substanciais de performance "prontas para uso" sem ajustes manuais. Pesquisadores reportam melhorias de 40% no throughput de modelos apenas da compilação comparado a frameworks de execução eager.¹⁷⁵ A performance vem grátis—não é necessária engenharia de kernel.
A otimização de fusão beneficia particularmente os desenvolvedores. Fusionar operações manualmente em CUDA requer escrever kernels customizados, testar correção e manter o código através de versões de framework. O XLA automaticamente funde operações e atualizações, e adapta estratégias de fusão conforme modelos evoluem, eliminando o fardo de manutenção.¹⁷⁶
A automação de transformação de layout economiza semanas de otimização manual. Determinar layouts otimizados de tensores para GPU requer criar perfis de diferentes arranjos, inserir transposes manualmente e gerenciar cuidadosamente padrões de alocação de memória. O XLA tenta layouts automaticamente e seleciona o mais rápido, liberando desenvolvedores para focar na arquitetura do modelo em vez de engenharia de performance de baixo nível.¹⁷⁷
O ganho de produtividade se compõe para equipes de pesquisa. O tempo economizado na otimização de infraestrutura acelera o progresso científico, permitindo mais experimentos e ciclos de iteração mais rápidos. Organizações reportam melhorias de velocidade de desenvolvimento de 3× ao migrar da programação GPU CUDA para workflows baseados em TPU JAX.¹⁷⁸
## Limitações Técnicas and Desvantagens
Lock-In de Plataforma e Restrições On-Premises
O acesso a TPU está disponível exclusivamente através do Google Cloud Platform, impedindo deployment on-premises e levantando preocupações sobre vendor lock-in.¹⁷⁹ Organizações com requisitos de soberania de dados, redes air-gapped ou políticas contra nuvem pública não podem aproveitar TPU independentemente da superioridade técnica.
A restrição importa cada vez mais conforme AI se torna infraestrutura crítica. A dependência de um único provedor de nuvem cria riscos de continuidade de negócios—mudanças de preços, interrupções de disponibilidade ou descontinuação de serviço poderiam forçar migrações custosas.¹⁸⁰ A disponibilidade de GPUs de múltiplos fornecedores (hardware NVIDIA rodando em AWS, Azure, GCP e on-prem) oferece opcionalidade que TPU arquiteturalmente impede.
Estratégias multi-cloud encontram fricção. Organizações padronizando em TPU não conseguem facilmente expandir para outras nuvens ou implementar redundância multi-cloud sem retreinar modelos ou manter codebases separados para diferentes arquiteturas de aceleradores.¹⁸¹ A complexidade operacional de deployments híbridos GPU/TPU frequentemente supera as economias de custo da seleção ótima de aceleradores.
Gap de Maturidade do Ecossistema CUDA
A plataforma CUDA da NVIDIA acumulou mais de 15 anos de desenvolvimento de ecossistema, bibliotecas, documentação e conhecimento da comunidade que TPU não consegue igualar.¹⁸² O gap de maturidade se manifesta em numerosos pontos de dor para adoção de TPU.
A disponibilidade de bibliotecas favorece esmagadoramente CUDA. Domínios especializados como computação gráfica, dinâmica molecular, dinâmica de fluidos computacional e genômica acumularam milhares de bibliotecas otimizadas para CUDA ao longo das últimas décadas. Equivalentes TPU frequentemente não existem, exigindo fallback para CPU (que destrói performance) ou meses de esforço de porting.¹⁸³
O suporte da comunidade difere por ordens de magnitude. Stack Overflow contém centenas de milhares de perguntas sobre CUDA com respostas detalhadas—repositórios GitHub chegam aos milhões. Palestras de conferências, artigos acadêmicos e posts de blog focam predominantemente em programação CUDA. Programadores TPU enfrentam recursos comparativamente escassos, ciclos de debugging mais longos e menos especialistas para consultar.¹⁸⁴
Materiais educacionais e tutoriais esmagadoramente targetam CUDA. Cursos universitários ensinam programação GPU usando CUDA. Cursos online focam em CUDA. O pipeline de talentos produz muito mais engenheiros com experiência em CUDA que especialistas em TPU, criando desafios de contratação e treinamento.¹⁸⁵
O desenvolvimento de kernel customizado exemplifica o gap do ecossistema. Escrever kernels CUDA otimizados permanece não-trivial mas se beneficia de documentação extensa, ferramentas de profiling e código de exemplo. Pallas habilita kernels TPU customizados, mas com tooling menos maduro e uma base de conhecimento menor. A curva de aprendizado desencoraja todas exceto as otimizações mais críticas para performance.¹⁸⁶
Especialização de Workload e Restrições de Flexibilidade
A arquitetura TPU otimiza para padrões específicos de workload—primariamente multiplicação densa de matrizes com padrões de acesso regular e batch sizes grandes. Operações fora do sweet spot encontram penhascos de performance.¹⁸⁷
Shapes dinâmicos desafiam modelos de execução TPU. O compilador XLA assume dimensões fixas de tensor para otimização e geração de código. Modelos com comprimentos de sequência variáveis, fluxo de controle dinâmico ou shapes dependentes de dados requerem padding para tamanhos máximos (desperdiçando compute e memória) ou recompilação para cada shape distinto (destruindo performance).¹⁸⁸
Operações esparsas recebem suporte limitado apesar do SparseCore. Multiplicação esparsa matriz-matriz, um workload comum em computação científica e redes neurais de grafo, carece de implementações eficientes em MXU ou VPU. O SparseCore especializado lida com tabelas de embedding mas não álgebra linear esparsa geral.¹⁸⁹
Inferência com small batch subutiliza recursos paralelos do TPU. O array sistólico 256×256 prospera em matrizes grandes que preenchem a grade com trabalho produtivo. Inferência de query única deixa a maioria dos MACs ociosos, resultando em latência e custo por query piores que alternativas GPU otimizadas para cenários de low-batch.¹⁹⁰
Padrões de computação irregulares derrotam a eficiência do array sistólico. Algoritmos com branching imprevisível, estruturas recursivas ou acesso de memória pointer-chasing exibem performance TPU ruim porque o dataflow fixo não consegue se adaptar ao comportamento dependente de runtime.¹⁹¹
Workloads não-ML raramente se beneficiam de aceleração TPU. Simulações científicas, codificação de vídeo, verificação blockchain e rendering todos rodam mais rápido na arquitetura mais geral de GPUs apesar do peak FLOPs mais alto do TPU para operações de matriz.¹⁹²
Gaps de Tooling de Debugging e Desenvolvimento
O ecossistema da NVIDIA inclui ferramentas de profiling maduras (Nsight Systems, Nsight Compute, nvprof), debuggers (cuda-gdb) e frameworks de análise que foram refinados ao longo de décadas. Tooling TPU existe, mas fica substancialmente atrás em sofisticação.¹⁹³
XProf oferece profiling básico através de integração TensorBoard mas carece do acesso granular a contadores de hardware que ferramentas NVIDIA expõem. Entender cache miss rates, occupancy, warp divergence ou memory bank conflicts—todas métricas críticas de otimização GPU—não tem equivalente TPU porque a arquitetura difere fundamentalmente.¹⁹⁴
Mensagens de erro frequentemente obscurecem causas raiz. Falhas de compilação XLA produzem mensagens crípticas sobre shape mismatches ou operações não suportadas, sem orientação clara sobre resolução. Erros CUDA, embora infames por sua falta de ajuda, se beneficiam de quinze anos de explicações do StackOverflow e conhecimento tribal.¹⁹⁵
Debugging de treinamento distribuído em pods multi-chip se aproxima da impossibilidade sem ferramentas especializadas. Race conditions, bugs de sincronização de gradiente e falhas de operação coletiva se manifestam como erros não-determinísticos (ironicamente, apesar das vantagens de determinismo do TPU) que reproduzem inconsistentemente e resistem a diagnóstico sistemático.¹⁹⁶
O loop de iteração se estende dolorosamente para modelos complexos. Recompilação para mudanças de shape ou modificações de arquitetura pode exigir minutos, congelando desenvolvimento enquanto o compilador processa. O modelo de execução eager do CUDA habilita iteração mais rápida apesar de performance de pico menor.¹⁹⁷
Implantações no Mundo Real: Produção em Escala
Anthropic Claude: Estratégia Multi-Plataforma
O anúncio da Anthropic em outubro de 2025 sobre a implantação de mais de um milhão de chips TPU representa o maior compromisso publicamente divulgado de aceleradores de AI na história.¹⁹⁸ A empresa planeja acessar bem mais de um gigawatt de capacidade de computação entrando em funcionamento em 2026 exclusivamente para treinamento e servir futuros modelos Claude.
A escala supera implantações anteriores por ordens de magnitude. Um milhão de chips, configurados como TPUs Ironwood, forneceria aproximadamente 4,6 exaflops de computação FP8—mais de 40× o desempenho total de toda a lista Top500 de supercomputadores de apenas cinco anos atrás.¹⁹⁹ O compromisso sinaliza confiança na arquitetura TPU para desenvolvimento de modelos de fronteira em escalas anteriormente consideradas ficção científica.
A Anthropic segue uma estratégia deliberada de hardware multi-plataforma através de TPUs do Google, Trainium da Amazon e GPUs NVIDIA.²⁰⁰ A diversificação oferece seguro de capacidade, alavancagem de preços e distribuição geográfica. O Claude serve globalmente a partir de implantações em todas as três plataformas, com roteamento de solicitações baseado na disponibilidade de capacidade e requisitos de latência regional.
O relatório técnico pós-incidente da empresa de agosto de 2025 revelou complexidades de implantação em escala. Uma configuração incorreta nos servidores TPU da API Claude causou erros de geração de tokens, ocasionalmente atribuindo probabilidades inesperadamente altas a caracteres tailandeses ou chineses em prompts em inglês.²⁰¹ O incidente demonstrou que mesmo erros simples se propagam de forma imprevisível através de sistemas processando bilhões de tokens diariamente.
Uma implantação separada desencadeou um bug latente no compilador XLA: TPU afetando o Claude Haiku 3.5. O bug havia existido não detectado por meses até que uma combinação específica de arquitetura de modelo e flag do compilador expôs o defeito.²⁰² A descoberta enfatiza que a implantação em produção encontra casos extremos ausentes dos ambientes de desenvolvimento e teste.
Engenheiros da Anthropic citaram preço-desempenho e eficiência do TPU como critérios primários de seleção. A economia atrativa acelera o desenvolvimento ao permitir experimentos maiores dentro de orçamentos fixos.²⁰³ treinar modelos maiores, explorar mais configurações de hiperparâmetros e iterar mais rápido derivam da redução de custos por FLOP.
Google Gemini: Projetado para TPU Desde o Início
Os modelos Gemini do Google treinam e servem exclusivamente em TPUs, com arquitetura e procedimentos de treinamento co-projetados para características do TPU desde o início.²⁰⁴ O acoplamento apertado permite explorar otimizações específicas do TPU que modelos multi-plataforma não conseguem aproveitar.
A implantação do Gemini supostamente usa 50.000 chips TPU v6e para treinamento e servir as variantes de modelo mais significativas.²⁰⁵ Os enormes pods em escala requerem orquestração sofisticada—agendamento de tarefas através de milhares de chips, coordenação de checkpoints para prevenir gargalos, recuperação de falhas para minimizar trabalho perdido e monitoramento em tempo real para identificar nós degradados antes que falhas se propaguem.
O Google treinou o Gemini 2.0 em TPUs Trillium, validando a arquitetura de sexta geração para desenvolvimento de modelos de fronteira.²⁰⁶ A execução de treinamento demonstrou eficiência de escala para contagens de chips sem precedentes, alcançando escala forte além de platôs típicos onde o overhead de comunicação domina.
A infraestrutura de servir modelos especificamente aproveita otimizações de inferência TPU. Processamento em lote agrega múltiplas solicitações de usuários para maximizar utilização MXU. Gerenciamento de cache chave-valor aproveita capacidade HBM, permitindo processamento de contexto de longa duração sem swap de disco. A arquitetura entrega tempos de resposta sub-segundo para consultas complexas enquanto lida com volume massivo de solicitações globais.²⁰⁷
Sistemas de monitoramento de produção rastreiam continuamente 50.000+ TPUs, detectando anomalias que podem degradar qualidade ou disponibilidade do modelo.²⁰⁸ A telemetria captura taxas de erro, percentis de latência, throughput, pressão de memória e características térmicas através de cada chip. Modelos de machine learning analisam os próprios fluxos de telemetria, prevendo falhas antes que ocorram e disparando manutenção preventiva.
Implantações Adicionais em Produção
A Midjourney migrou de infraestrutura GPU para TPU, alcançando 65% de redução de custo e 40% de melhoria de latência para cargas de trabalho de geração de imagens.²⁰⁹ O serviço de geração de arte processa 300.000 imagens por minuto em pico de carga, requerendo throughput de computação massivo e desempenho consistente sob padrões de tráfego intermitente.
Os modelos de linguagem da Cohere em TPU alcançaram 3× o throughput de implantações GPU anteriores.²¹⁰ A aceleração permitiu servir mais clientes a partir da mesma pegada de infraestrutura, melhorando diretamente a economia do negócio. A empresa aproveitou capacidades SPMD do JAX para paralelizar eficientemente modelos através de pods TPU.
O Snap garantiu capacidade para 10.000 chips TPU v6e suportando recursos de realidade aumentada, sistemas de recomendação e ferramentas de AI criativa.²¹¹ A implantação abrange múltiplas regiões geográficas, garantindo baixa latência para a base global de usuários do Snapchat enquanto mantém consistência do modelo através das regiões.
Instituições acadêmicas adotam cada vez mais TPU para pesquisa. O programa TPU Research Cloud (TRC) fornece acesso gratuito a TPU para pesquisadores, permitindo experimentos em escalas anteriormente acessíveis apenas a laboratórios corporativos bem financiados.²¹² A democratização acelera o progresso científico ao remover barreiras de hardware para acadêmicos investigando questões fundamentais sobre capacidades e limitações de AI.
Depuração, Profiling e Otimização de Performance
Integração XProf e TensorBoard
O XProf forma a principal ferramenta de profiling para workloads de TPU, fornecendo análise de performance para programas JAX, PyTorch/XLA e TensorFlow em CPUs, GPUs e TPUs.²¹³ A ferramenta se integra com o TensorBoard para visualização, apresentando dados de profiling através de interfaces familiares que engenheiros de ML já compreendem.
A instalação requer o plugin do TensorBoard: pip install tensorboard_plugin_profile tensorboard. Isso habilita a cadeia completa de ferramentas.²¹⁴ Executar profiling em VMs de TPU envolve capturar traces durante treinamento ou inferência, fazer upload dos resultados para o TensorBoard, e analisar a visualização para identificar gargalos.
A Página de Visão Geral fornece métricas resumidas de performance de alto nível, incluindo divisão do tempo de step, utilização do dispositivo, e identificação de gargalos de nível superior.²¹⁵ A página imediatamente destaca se os workloads estão limitados por computação (MXU rodando continuamente), limitados por memória (aguardando transferências HBM), ou limitados por comunicação (bloqueados em operações coletivas).
Visualizador de Trace e Análise de Timeline
O Visualizador de Trace exibe visualizações detalhadas de timeline mostrando exatamente quando as operações executam, quando transferências de dados ocorrem, e onde o tempo ocioso se acumula.²¹⁶ A interface baseada no Chrome permite zoom com resolução de microssegundo, revelando comportamento preciso de agendamento que métricas agregadas obscurecem.
Compreender o trace requer reconhecer padrões comuns. Longos intervalos entre operações indicam overhead de compilação, gargalos de carregamento de dados, ou overhead de Python devido a pipelines de dados mal otimizados. Operações pequenas repetidas sugerem fusão insuficiente. Operações coletivas que duram milissegundos apontam para ineficiências de comunicação ou estratégias de sharding ruins.²¹⁷
A codificação por cores distingue tipos de operação: verde para computação, azul para transferências de memória, laranja para comunicação, e vermelho para tempo ocioso. Workloads otimizados mostram blocos coloridos densamente empacotados com intervalos vermelhos mínimos. Código mal otimizado exibe timelines esparsas com longas faixas vermelhas indicando recursos desperdiçados.²¹⁸
O uso avançado envolve correlacionar comportamento de timeline com código fonte. PyTorch/XLA suporta anotações de usuário inseridas no código que aparecem nos traces, permitindo mapear comportamento de performance para componentes específicos do modelo.²¹⁹ As anotações transformam traces opacos em insights acionáveis sobre quais camadas ou operações precisam de foco de otimização.
Ferramenta de Perfil de Memória e Depuração de OOM
Erros de falta de memória (OOM) assolam o desenvolvimento de modelos grandes. A Ferramenta de Perfil de Memória monitora o uso de memória do dispositivo durante a execução, capturando picos de utilização e padrões de alocação que levam a falhas OOM.²²⁰
A ferramenta visualiza o consumo de memória ao longo do tempo, mostrando quais tensores consomem mais capacidade e quando o pico de uso ocorre. A visualização frequentemente revela alocações surpreendentes—buffers de gradiente maiores que o esperado, memória de ativação que deveria usar checkpoint, ou tensores temporários que o XLA falhou em eliminar.²²¹
A estratégia de depuração envolve reduzir iterativamente a pegada de memória através de múltiplas técnicas. Gradient checkpointing recomputa ativações durante passes backward ao invés de armazená-las. Sharding de estado do optimizer distribui momentum e variância do Adam entre dispositivos. Precisão mista reduz memória em 2× comparado ao FP32. Microbatching processa batches menores sequencialmente ao invés de um batch grande.²²²
Otimização avançada de memória requer compreender decisões do compilador. A flag xla_dump_to exporta representações intermediárias mostrando como o XLA transformou o grafo computacional. Analisar o IR revela se a fusão teve sucesso, onde cópias desnecessárias ocorrem, e quais operações alocam mais memória que o esperado.²²³
Analisador de Pipeline de Entrada
Pré-processamento de CPU frequentemente cria gargalos no treinamento de TPU. O Analisador de Pipeline de Entrada identifica se o carregamento de dados acompanha o consumo do acelerador ou se TPUs ficam ociosas aguardando batches.²²⁴
A ferramenta separa análise do lado host (pré-processamento de CPU, data augmentation, montagem de batch) da execução do lado device (computação real da TPU). Workloads limitados por entrada mostram utilização do dispositivo caindo durante carregamento de dados enquanto utilização de CPU atinge picos. Workloads limitados por computação mantêm alta utilização do dispositivo com CPU confortavelmente acompanhando o ritmo.²²⁵
Estratégias de otimização dependem da localização do gargalo. Pré-processamento lento do host se beneficia de paralelizar carregamento de dados em mais cores de CPU, reduzir complexidade de augmentation por amostra, ou prefetch de batches antes do consumo. Gargalos do lado device requerem mudanças na arquitetura do modelo, melhor fusão, ou ajustes de sharding ao invés de ajuste do pipeline de dados.²²⁶
O Futuro das Unidades de Processamento Tensor
A evolução arquitetural de sete gerações do Google demonstra inovação contínua em aceleradores de IA especializados. O suporte FP8 do Ironwood, capacidade massiva de memória e escalonamento de superpod de 9.216 chips sugerem trajetórias para desenvolvimento futuro.²²⁷
A redução de precisão provavelmente continuará em direção ao FP4 ou ainda menor para operações específicas. Pesquisas emergentes demonstram que muitas operações de redes neurais toleram quantização extrema com procedimentos de treinamento cuidadosos. TPUs futuros podem implementar sistemas de precisão mista com passadas diretas FP4, passadas reversas FP8 e atualizações de otimizador FP32.²²⁸
A capacidade de memória compete contra o crescimento do tamanho dos modelos. Modelos de fronteira atuais já sobrecarregam a memória do acelerador, exigindo estratégias sofisticadas de paralelismo. TPUs de próxima geração podem integrar tecnologias de memória não-volátil como 3D XPoint ou RAM resistiva, permitindo memória em escala de terabyte no pacote sem o consumo de energia da DRAM.²²⁹
Interconexões ópticas poderiam se estender além do circuit switching para incluir elementos de computação óptica. Pesquisas exploram multiplicação de matrizes fotônica executada na velocidade da luz com energia mínima, potencialmente aumentando arrays sistólicos eletrônicos com co-processadores ópticos para operações específicas.²³⁰
O suporte à esparsidade provavelmente se expandirá além de embeddings para álgebra linear esparsa geral. Técnicas de poda de redes neurais demonstram que mais de 90% dos pesos podem ser zerados sem perda de qualidade. Arquiteturas futuras podem nativamente pular computações de valor zero em vez de explicitamente computá-las e descartá-las.²³¹
Os princípios arquiteturais subjacentes ao sucesso da TPU—especialização de domínio, interconexão personalizada, pilhas de software co-projetadas e orquestração em escala de edifício—apontam para um futuro de aceleradores cada vez mais especializados. Em vez de processadores universais, podemos ver aceleradores otimizados para treinamento versus inferência, redes convolucionais versus transformers, modelos densos versus esparsos, e sequências curtas versus longas.²³²
Engenheiros construindo infraestrutura de IA hoje devem compreender profundamente a arquitetura TPU. Seja implantando no Google Cloud, competindo com o Google no mercado de aceleradores, ou projetando sistemas de ML de próxima geração, os princípios de design e trade-offs incorporados na TPU revelam verdades fundamentais sobre o que cargas de trabalho de IA exigem do hardware. A matemática de array sistólico, design de hierarquia de memória, topologia de interconexão e estratégias de otimização de compilador representam décadas de sabedoria acumulada aplicável muito além da própria TPU.
A tensão entre especialização e generalidade que define TPU versus GPU persistirá indefinidamente. TPUs sacrificam flexibilidade por eficiência extrema em cargas de trabalho estreitas. GPUs sacrificam eficiência máxima por aplicabilidade mais ampla. Nenhuma abordagem domina—a escolha ótima depende inteiramente das características da carga de trabalho, escala, restrições de custo e requisitos operacionais. Organizações que têm sucesso com IA em escala adotam cada vez mais estratégias heterogêneas, combinando arquiteturas de acelerador às demandas da carga de trabalho em vez de padronizar em uma única plataforma.
O compromisso de um milhão de chips da Anthropic com TPU demonstra que a arquitetura alcançou maturidade de produção nas mais altas escalas. As implantações de multi-gigawatt entrando em operação em 2026 treinarão modelos que expandem os limites do que a IA pode alcançar, e a infraestrutura que permite esses modelos incorpora sofisticação de engenharia que poucas organizações conseguiram igualar. Compreender como 65.536 unidades de multiplicação-acumulação em um array sistólico colaboram para treinar modelos de fronteira importa para qualquer um sério sobre o futuro da IA.
Referências
-
Google Cloud Press Corner, "Anthropic to Expand Use of Google Cloud TPUs and Services," 23 de outubro de 2025, https://www.googlecloudpresscorner.com/2025-10-23-Anthropic-to-Expand-Use-of-Google-Cloud-TPUs-and-Services.
-
TrendForce, "Google Unveils 7th-Gen TPU Ironwood with 9,216-Chip Superpod, Taking Aim at NVIDIA," 7 de novembro de 2025, https://www.trendforce.com/news/2025/11/07/news-google-unveils-7th-gen-tpu-ironwood-with-9216-chip-superpod-taking-aim-at-nvidia/.
-
Norman P. Jouppi et al., "TPU v4: An Optically Reconfigurable Supercomputer for Machine Learning with Hardware Support for Embeddings," em Proceedings of the 50th Annual International Symposium on Computer Architecture (2023), arXiv:2304.01433.
-
Anthropic, "Expanding our use of Google Cloud TPUs and Services," Anthropic News, outubro de 2025, https://www.anthropic.com/news/expanding-our-use-of-google-cloud-tpus-and-services.
-
Google Cloud Blog, "Quantifying the performance of the TPU, our first machine learning chip," abril de 2017, https://cloud.google.com/blog/products/gcp/quantifying-the-performance-of-the-tpu-our-first-machine-learning-chip.
-
Norman P. Jouppi et al., "In-Datacenter Performance Analysis of a Tensor Processing Unit," Proceedings of the 44th Annual International Symposium on Computer Architecture (2017), arXiv:1704.04760.
-
Jouppi et al., "In-Datacenter Performance Analysis."
-
Jouppi et al., "In-Datacenter Performance Analysis."
-
Jonathan Hui, "AI Chips: Google TPU," Medium, acessado em dezembro de 2025, https://jonathan-hui.medium.com/ai-chips-tpu-3fa0b2451a2d.
-
Wikipedia, "Bfloat16 floating-point format," acessado em dezembro de 2025, https://en.wikipedia.org/wiki/Bfloat16_floating-point_format.
-
Henry Ko, "TPU Deep Dive," blog pessoal, acessado em dezembro de 2025, https://henryhmko.github.io/posts/tpu/tpu.html.
-
Wikipedia, "Tensor Processing Unit," acessado em dezembro de 2025, https://en.wikipedia.org/wiki/Tensor_Processing_Unit.
-
Wikipedia, "Tensor Processing Unit."
-
Wikipedia, "Tensor Processing Unit."
-
Ko, "TPU Deep Dive."
-
Jouppi et al., "TPU v4: An Optically Reconfigurable Supercomputer."
-
Jouppi et al., "TPU v4: An Optically Reconfigurable Supercomputer."
-
Jouppi et al., "TPU v4: An Optically Reconfigurable Supercomputer."
-
Jouppi et al., "TPU v4: An Optically Reconfigurable Supercomputer."
-
OpenXLA Project, "A deep dive into SparseCore for Large Embedding Models (LEM)," acessado em dezembro de 2025, https://openxla.org/xla/sparsecore.
-
JAX Scaling Guide, "How to Think About TPUs," acessado em dezembro de 2025, https://jax-ml.github.io/scaling-book/tpus/.
-
JAX Scaling Guide, "How to Think About TPUs."
-
Ko, "TPU Deep Dive."
-
JAX Scaling Guide, "How to Think About TPUs."
-
Google Cloud Blog, "Introducing Trillium, sixth-generation TPUs," maio de 2024, https://cloud.google.com/blog/products/compute/introducing-trillium-6th-gen-tpus.
-
Google Cloud Blog, "Introducing Trillium."
-
Google Cloud Blog, "Introducing Trillium."
-
Google Cloud Blog, "Introducing Trillium."
-
Google Cloud Blog, "Introducing Trillium."
-
Google Blog, "Ironwood: The first Google TPU for the age of inference," novembro de 2025, https://blog.google/products/google-cloud/ironwood-tpu-age-of-inference/.
-
XPU.pub, "Google Adds FP8 to Ironwood TPU; Can It Beat Blackwell?" 16 de abril de 2025, https://xpu.pub/2025/04/16/google-ironwood/.
-
TrendForce, "Google Unveils 7th-Gen TPU Ironwood."
-
The Register, "Google's 7th-gen Ironwood TPUs promise 42 AI exaFLOPS pods," 10 de abril de 2025, https://www.theregister.com/2025/04/10/googles_7thgen_ironwood_tpus_debut/.
-
TrendForce, "Google Unveils 7th-Gen TPU Ironwood."
-
Ko, "TPU Deep Dive."
-
XPU.pub, "Google Adds FP8 to Ironwood TPU."
-
Google Cloud Press Corner, "Anthropic to Expand Use."
-
Telesens, "Understanding Matrix Multiplication on a Weight-Stationary Systolic Architecture," 30 de julho de 2018, https://telesens.co/2018/07/30/systolic-architectures/.
-
Telesens, "Understanding Matrix Multiplication."
-
Jouppi et al., "In-Datacenter Performance Analysis."
-
Telesens, "Understanding Matrix Multiplication."
-
CP Lu, "Should We All Embrace Systolic Arrays?" Medium, acessado em dezembro de 2025, https://cplu.medium.com/should-we-all-embrace-systolic-array-df3830f193dc.
-
Google Cloud Documentation, "TPU architecture," acessado em dezembro de 2025, https://docs.cloud.google.com/tpu/docs/system-architecture-tpu-vm.
-
Google Cloud Documentation, "TPU architecture."
-
Hui, "AI Chips: Google TPU."
-
Telnyx, "Architecture insights: MXU and TPU components," acessado em dezembro de 2025, https://telnyx.com/learn-ai/mxu-tpu.
-
Ko, "TPU Deep Dive."
-
Jouppi et al., "TPU v4: An Optically Reconfigurable Supercomputer."
-
SemiEngineering, "Tensor Processing Unit (TPU)," acessado em dezembro de 2025, https://semiengineering.com/knowledge_centers/integrated-circuit/ic-types/processors/tensor-processing-unit-tpu/.
-
TrendForce, "Google Unveils 7th-Gen TPU Ironwood."
-
SemiEngineering, "Tensor Processing Unit (TPU)."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Google Cloud Documentation, "Cloud TPU performance guide," acessado em dezembro de 2025, https://cloud.google.com/tpu/docs/performance-guide.
-
OpenXLA Project, "A deep dive into SparseCore."
-
OpenXLA Project, "A deep dive into SparseCore."
-
OpenXLA Project, "A deep dive into SparseCore."
-
Jouppi et al., "TPU v4: An Optically Reconfigurable Supercomputer."
-
OpenXLA Project, "A deep dive into SparseCore."
-
Jouppi et al., "TPU v4: An Optically Reconfigurable Supercomputer."
-
OpenXLA Project, "A deep dive into SparseCore."
-
JAX Scaling Guide, "How to Think About TPUs."
-
JAX Scaling Guide, "How to Think About TPUs."
-
JAX Scaling Guide, "How to Think About TPUs."
-
Ko, "TPU Deep Dive."
-
JAX Scaling Guide, "How to Think About TPUs."
-
JAX Scaling Guide, "How to Think About TPUs."
-
TrendForce, "Google Unveils 7th-Gen TPU Ironwood."
-
Ko, "TPU Deep Dive."
-
Anthropic, "Expanding our use of Google Cloud TPUs."
-
Jouppi et al., "TPU v4: An Optically Reconfigurable Supercomputer."
-
Jouppi et al., "TPU v4: An Optically Reconfigurable Supercomputer."
-
Jouppi et al., "TPU v4: An Optically Reconfigurable Supercomputer."
-
Jouppi et al., "TPU v4: An Optically Reconfigurable Supercomputer."
-
Ko, "TPU Deep Dive."
-
Jouppi et al., "TPU v4: An Optically Reconfigurable Supercomputer."
-
Leon Poutievski, "Mission Apollo: Landing Optical Circuit Switching at Datacenter Scale," LinkedIn, junho de 2022, https://www.linkedin.com/posts/leon-poutievski-8910a851_mission-apollo-landing-optical-circuit-switching-activity-6968472071534235649-cB4l.
-
Ko, "TPU Deep Dive."
-
Jouppi et al., "TPU v4: An Optically Reconfigurable Supercomputer."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Jouppi et al., "TPU v4: An Optically Reconfigurable Supercomputer."
-
JAX Scaling Guide, "How to Think About TPUs."
-
TrendForce, "Google Unveils 7th-Gen TPU Ironwood."
-
TrendForce, "Google Unveils 7th-Gen TPU Ironwood."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
OpenXLA Project, "XLA: Optimizing Compiler for Machine Learning," acessado em dezembro de 2025, https://openxla.org/xla.
-
Daniel Snider e Ruofan Liang, "Operator Fusion in XLA: Analysis and Evaluation," artigo acadêmico, acessado em dezembro de 2025, https://danielsnider.ca/papers/Operator_Fusion_in_XLA_Analysis_and_Evaluation.pdf.
-
Snider e Liang, "Operator Fusion in XLA."
-
APXML, "Memory-Aware Data Layout Transformations (NCHW/NHWC)," acessado em dezembro de 2025, https://apxml.com/courses/compiler-runtime-optimization-ml/chapter-3-advanced-graph-level-optimizations/memory-aware-layout-transformations.
-
OpenXLA Project, "XLA."
-
PyTorch Documentation, "Pytorch/XLA Overview," acessado em dezembro de 2025, https://docs.pytorch.org/xla/master/learn/xla-overview.html.
-
OpenXLA Project, "A deep dive into SparseCore."
-
Mangpo Phothilimthana et al., "A Flexible Approach to Autotuning Multi-Pass Machine Learning Compilers," PACT 2021, acessado em dezembro de 2025, https://mangpo.net/papers/xla-autotuning-pact2021.pdf.
-
JAX Documentation, "Introduction to parallel programming," acessado em dezembro de 2025, https://docs.jax.dev/en/latest/sharded-computation.html.
-
GitHub, "jax-ml/jax: Composable transformations of Python+NumPy programs," acessado em dezembro de 2025, https://github.com/jax-ml/jax.
-
OpenXLA Project, "Shardy Guide for JAX Users," acessado em dezembro de 2025, https://openxla.org/shardy/getting_started_jax.
-
JAX Documentation, "Introduction to parallel programming."
-
OpenXLA Project, "Shardy Guide for JAX Users."
-
OpenXLA Project, "Shardy Guide for JAX Users."
-
JAX Documentation, "Introduction to parallel programming."
-
OpenXLA Project, "Shardy Guide for JAX Users."
-
PyTorch Documentation, "Pytorch/XLA Overview."
-
GitHub, "RFC: Evolving PyTorch/XLA for a more native experience on TPU," Issue #9684, acessado em dezembro de 2025, https://github.com/pytorch/xla/issues/9684.
-
Google Cloud Blog, "PyTorch/XLA 2.4 improves Pallas and adds 'eager mode,'" acessado em dezembro de 2025, https://cloud.google.com/blog/products/ai-machine-learning/pytorch-xla-2-4-improves-pallas-and-adds-eager-mode/.
-
PyTorch Documentation, "Pytorch/XLA Overview."
-
PyTorch Documentation, "Custom Kernels via Pallas," acessado em dezembro de 2025, https://docs.pytorch.org/xla/master/features/pallas.html.
-
PyTorch Documentation, "Custom Kernels via Pallas."
-
PyTorch Documentation, "Custom Kernels via Pallas."
-
vLLM Blog, "vLLM TPU: A New Unified Backend Supporting PyTorch and JAX on TPU," 16 de outubro de 2025, https://blog.vllm.ai/2025/10/16/vllm-tpu.html.
-
GitHub, "pytorch/xla," acessado em dezembro de 2025, https://github.com/pytorch/xla.
-
StackGpu, "FP8, BF16, and INT8: How Low-Precision Formats Are Revolutionizing Deep Learning Throughput," Medium, acessado em dezembro de 2025, https://medium.com/@StackGpu/fp8-bf16-and-int8-how-low-precision-formats-are-revolutionizing-deep-learning-throughput-e6c1f3adabc2.
-
Wikipedia, "Bfloat16 floating-point format."
-
Wikipedia, "Bfloat16 floating-point format."
-
Paulius Micikevicius et al., "FP8 Formats for Deep Learning," arXiv:2209.05433, setembro de 2022.
-
XPU.pub, "Google Adds FP8 to Ironwood TPU."
-
Micikevicius et al., "FP8 Formats for Deep Learning."
-
Google Cloud Blog, "Accurate Quantized Training (AQT) for TPU v5e," acessado em dezembro de 2025, https://cloud.google.com/blog/products/compute/accurate-quantized-training-aqt-for-tpu-v5e.
-
StackGpu, "FP8, BF16, and INT8."
-
Jeffrey Tse, "Understanding the FP64, FP32, FP16, BFLOAT16, TF32, FP8 Formats," blog pessoal, 9 de dezembro de 2024, https://jeffreytse.net/computer/2024/12/09/understanding-the-fp64-fp32-fp16-bfloat16-tf32-fp8-formats.html.
-
PyTorch Blog, "PyTorch/XLA SPMD: Scale Up Model Training and Serving with Automatic Parallelization," acessado em dezembro de 2025, https://pytorch.org/blog/pytorch-xla-spmd/.
-
OpenXLA Project, "Shardy Guide for JAX Users."
-
JAX Documentation, "Introduction to parallel programming."
-
OpenXLA Project, "Shardy Guide for JAX Users."
-
Ko, "TPU Deep Dive."
-
JAX Documentation, "Introduction to parallel programming."
-
Anthropic, "Expanding our use of Google Cloud TPUs."
-
JAX Documentation, "Introduction to parallel programming."
-
JAX Documentation, "Introduction to parallel programming."
-
Adam Roberts et al., "Scaling Up Models and Data with t5x and seqio," arXiv:2203.17189, março de 2022.
-
Roberts et al., "Scaling Up Models and Data."
-
JAX Documentation, "Introduction to parallel programming."
-
JAX Documentation, "Introduction to parallel programming."
-
OpenXLA Project, "Shardy Guide for JAX Users."
-
Roberts et al., "Scaling Up Models and Data."
-
Roberts et al., "Scaling Up Models and Data."
-
Ko, "TPU Deep Dive."
-
MLCommons, "Benchmark MLPerf Training," acessado em dezembro de 2025, https://mlcommons.org/benchmarks/training/.
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
HPCwire, "MLPerf Training v5.0 Benchmark Results Reflect Rapid Growth in the Field of AI," junho de 2025, https://www.hpcwire.com/off-the-wire/mlperf-training-v5-0-benchmark-results-reflect-rapid-growth-in-the-field-of-ai/.
-
MLCommons, "MLCommons Releases New MLPerf Inference v5.0 Benchmark Results," abril de 2025, https://mlcommons.org/2025/04/mlperf-inference-v5-0-results/.
-
Ko, "TPU Deep Dive."
-
Google Cloud Blog, "TPU v4 enables performance, energy and CO2e efficiency gains," acessado em dezembro de 2025, https://cloud.google.com/blog/topics/systems/tpu-v4-enables-performance-energy-and-co2e-efficiency-gains.
-
TrendForce, "Google Unveils 7th-Gen TPU Ironwood."
-
Google Cloud Blog, "Quantifying the performance of the TPU."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Artech Digital, "Energy-Efficient GPU vs. TPU Allocation," acessado em dezembro de 2025, https://www.artech-digital.com/blog/energy-efficient-gpu-vs-tpu-allocation.
-
Wikipedia, "Tensor Processing Unit."
-
XPU.pub, "Google Adds FP8 to Ironwood TPU."
-
Ko, "TPU Deep Dive."
-
Google Cloud Blog, "TPU v4 enables performance, energy and CO2e efficiency gains."
-
ByteBridge, "GPU and TPU Comparative Analysis Report," Medium, acessado em dezembro de 2025, https://bytebridge.medium.com/gpu-and-tpu-comparative-analysis-report-a5268e4f0d2a.
-
ByteBridge, "GPU and TPU Comparative Analysis Report."
-
Anthropic, "Expanding our use of Google Cloud TPUs."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
DataCamp, "Understanding TPUs vs GPUs in AI: A Comprehensive Guide," acessado em dezembro de 2025, https://www.datacamp.com/blog/tpu-vs-gpu-ai.
-
Ko, "TPU Deep Dive."
-
DataCamp, "Understanding TPUs vs GPUs in AI."
-
Grigory Sapunov, "FP64, FP32, FP16, BFLOAT16, TF32, and other members of the ZOO," Medium, acessado em dezembro de 2025, https://moocaholic.medium.com/fp64-fp32-fp16-bfloat16-tf32-and-other-members-of-the-zoo-a1ca7897d407.
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Snider e Liang, "Operator Fusion in XLA."
-
APXML, "Memory-Aware Data Layout Transformations."
-
Google Cloud Blog, "How Lightricks trains video diffusion models at scale with JAX on TPU," acessado em dezembro de 2025, https://cloud.google.com/blog/products/media-entertainment/how-lightricks-trains-video-diffusion-models-at-scale-with-jax-on-tpu.
-
CloudOptimo, "TPU vs GPU: What's the Difference in 2025?" acessado em dezembro de 2025, https://www.cloudoptimo.com/blog/tpu-vs-gpu-what-is-the-difference-in-2025/.
-
Phoenix NAP, "TPU vs. GPU: Differences Explained," acessado em dezembro de 2025, https://phoenixnap.com/kb/tpu-vs-gpu.
-
CloudOptimo, "TPU vs GPU."
-
DataCamp, "Understanding TPUs vs GPUs in AI."
-
Tailscale, "TPU vs GPU: Which Is Better for AI Infrastructure in 2025?" acessado em dezembro de 2025, https://tailscale.com/learn/what-is-tpu-vs-gpu.
-
DataCamp, "Understanding TPUs vs GPUs in AI."
-
DataCamp, "Understanding TPUs vs GPUs in AI."
-
PyTorch Documentation, "Custom Kernels via Pallas."
-
Phoenix NAP, "TPU vs. GPU: Differences Explained."
-
Ko, "TPU Deep Dive."
-
OpenMetal, "TPU vs GPU: Pros and Cons," acessado em dezembro de 2025, https://openmetal.io/docs/product-guides/private-cloud/tpu-vs-gpu-pros-and-cons/.
-
OpenMetal, "TPU vs GPU: Pros and Cons."
-
Phoenix NAP, "TPU vs. GPU: Differences Explained."
-
PRIMO.ai, "Processing Units - CPU, GPU, APU, TPU, VPU, FPGA, QPU," acessado em dezembro de 2025, https://primo.ai/index.php?title=Processing_Units_-_CPU%2C_GPU%2C_APU%2C_TPU%2C_VPU%2C_FPGA%2C_QPU.
-
DataCamp, "Understanding TPUs vs GPUs in AI."
-
Google Cloud Documentation, "Profile your model on Cloud TPU VMs," acessado em dezembro de 2025, https://cloud.google.com/tpu/docs/cloud-tpu-tools.
-
DataCamp, "Understanding TPUs vs GPUs in AI."
-
Ko, "TPU Deep Dive."
-
GitHub, "RFC: Evolving PyTorch/XLA."
-
Google Cloud Press Corner, "Anthropic to Expand Use."
-
TrendForce, "Google Unveils 7th-Gen TPU Ironwood."
-
Maginative, "Anthropic Secures 1M Google TPUs While Keeping Amazon as Primary Training Partner," acessado em dezembro de 2025, https://www.maginative.com/article/anthropic-secures-1m-google-tpus-while-keeping-amazon-as-primary-training-partner/.
-
Anthropic, "A postmortem of three recent issues," Engineering Blog, agosto de 2025, https://www.anthropic.com/engineering/a-postmortem-of-three-recent-issues.
-
Anthropic, "A postmortem of three recent issues."
-
AI Magazine, "Why Anthropic Uses Google Cloud TPUs for AI Infrastructure," acessado em dezembro de 2025, https://aimagazine.com/news/why-anthropic-uses-google-cloud-tpus-for-ai-infrastructure.
-
Google Cloud Blog, "Ironwood TPUs and new Axion-based VMs for your AI workloads," novembro de 2025, https://cloud.google.com/blog/products/compute/ironwood-tpus-and-new-axion-based-vms-for-your-ai-workloads.
-
Ko, "TPU Deep Dive."
-
TrendForce, "Google Unveils 7th-Gen TPU Ironwood."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Google Cloud, "Tensor Processing Units (TPUs)," acessado em dezembro de 2025, https://cloud.google.com/tpu.
-
TensorFlow Documentation, "Optimize TensorFlow performance using the Profiler," acessado em dezembro de 2025, https://www.tensorflow.org/guide/profiler.
-
Google Cloud Documentation, "Profile your model on Cloud TPU VMs."
-
TensorFlow Documentation, "TensorFlow Profiler: Profile model performance," acessado em dezembro de 2025, https://www.tensorflow.org/tensorboard/tensorboard_profiling_keras.
-
Google Cloud Documentation, "Profile your model on Cloud TPU VMs."
-
Google Cloud Blog, "PyTorch/XLA: Performance debugging on Cloud TPU VM: Part III," acessado em dezembro de 2025, https://cloud.google.com/blog/topics/developers-practitioners/pytorchxla-performance-debugging-cloud-tpu-vm-part-iii.
-
Google Cloud Blog, "PyTorch/XLA: Performance debugging Part III."
-
Google Cloud Documentation, "Profile PyTorch XLA workloads," acessado em dezembro de 2025, https://docs.cloud.google.com/tpu/docs/pytorch-xla-performance-profiling-tpu-vm.
-
TensorFlow Documentation, "Optimize TensorFlow performance using the Profiler."
-
TensorFlow Documentation, "Optimize TensorFlow performance using the Profiler."
-
Ko, "TPU Deep Dive."
-
Google Cloud Documentation, "Cloud TPU performance guide."
-
TensorFlow Documentation, "Optimize TensorFlow performance using the Profiler."
-
TensorFlow Documentation, "Optimize TensorFlow performance using the Profiler."
-
TensorFlow Documentation, "Optimize TensorFlow performance using the Profiler."
-
TrendForce, "Google Unveils 7th-Gen TPU Ironwood."
-
Tse, "Understanding the FP64, FP32, FP16, BFLOAT16, TF32, FP8 Formats."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."


