
Las Unidades de Procesamiento Tensor de Google alimentan la mayoría de los modelos de AI de vanguardia con los que interactúas diariamente, sin embargo, la mayoría de los ingenieros permanecen sorprendentemente poco familiarizados con su arquitectura. Mientras que las GPU de NVIDIA dominan la mentalidad de los desarrolladores, las TPU entrenan y sirven silenciosamente Gemini 2.0, Claude, y docenas de otros modelos de frontera a escalas que llevarían a la bancarrota a la mayoría de las organizaciones usando infraestructura GPU convencional. Anthropic recientemente se comprometió a desplegar más de un millón de chips TPU—representando más de un gigavatio de capacidad de cómputo—para entrenar futuros modelos Claude.¹ La última generación Ironwood de Google entrega 42.5 exaflops de cómputo FP8 a través de superpods de 9,216 chips, una escala que redefine lo que significa la infraestructura de AI de producción.²
La sofisticación técnica detrás de las TPU se extiende mucho más allá de simples métricas de rendimiento. Estos procesadores encarnan una filosofía de diseño fundamentalmente diferente a las GPU, intercambiando flexibilidad de propósito general por especialización extrema en multiplicación de matrices y operaciones de tensores. Los ingenieros que entienden la arquitectura TPU pueden explotar arreglos sistólicos de 256×256 que procesan 65,536 operaciones de multiplicación-acumulación por ciclo, aprovechar aceleradores SparseCore de tercera generación para cargas de trabajo intensivas en embeddings, y programar conmutadores de circuito óptico que reconfiguran topologías de datacenter multi-petabit en menos de 10 nanosegundos.³ La arquitectura abarca desde decisiones de diseño a nivel de transistor hasta orquestación de supercomputadoras a escala de edificio.
El contenido técnico que sigue demanda atención cuidadosa. Examinamos siete generaciones de evolución TPU, diseccionamos las matemáticas de arreglos sistólicos y patrones de flujo de datos, exploramos jerarquías de memoria desde tiles SRAM hasta canales HBM3e, analizamos optimizaciones del compilador XLA a nivel de representación intermedia, e investigamos por qué las operaciones colectivas se ejecutan 10× más rápido que clusters GPU equivalentes basados en Ethernet.⁴ Encontrarás especificaciones a nivel de registro, modelado de rendimiento con precisión de ciclo, y las compensaciones arquitectónicas que hacen que las TPU sean simultáneamente más poderosas y más restringidas que las GPU. La profundidad aquí sirve a ingenieros construyendo la siguiente generación de infraestructura de AI e investigadores empujando los límites de lo que los aceleradores actuales pueden lograr.
La Evolución: Siete Generaciones de Innovación Arquitectónica
TPU v1: Especialización Solo para Inferencia (2015)
Google desplegó la primera Unidad de Procesamiento Tensor en 2015 para abordar un problema crítico: las cargas de trabajo de inferencia de redes neuronales amenazaban con duplicar la huella del centro de datos de la empresa.⁵ Los ingenieros diseñaron TPU v1 exclusivamente para inferencia, eliminando completamente las capacidades de entrenamiento para maximizar el rendimiento y la eficiencia energética de los modelos desplegados. El chip presentaba un arreglo sistólico de 256×256 unidades de multiplicación-acumulación de enteros de 8 bits, entregando 92 teraops por segundo con solo 28-40 watts de potencia de diseño térmico.⁶
La arquitectura encarnaba un minimalismo radical. Una sola Unidad de Multiplicación de Matrices procesaba operaciones INT8 a través de flujo de datos estacionario de pesos, donde los pesos permanecían fijos en el arreglo sistólico mientras las activaciones fluían horizontalmente a través de la cuadrícula. Las sumas parciales se propagan verticalmente, eliminando las escrituras de memoria intermedias para toda la multiplicación de matrices. El chip, conectado a sistemas host vía PCIe, dependía de DDR3 DRAM para memoria externa y operaba a 700 MHz—deliberadamente conservador para eficiencia energética.⁷
Las ganancias de rendimiento asombraron incluso a los ingenieros de Google. TPU v1 logró mejoras de 30× a 80× en operaciones por watt comparado con CPUs y GPUs contemporáneos para cargas de trabajo de inferencia en producción.⁸ El chip manejó la clasificación de Google Search, servicios de traducción procesando 1 billón de solicitudes diarias, y recomendaciones de YouTube para 2 billones de usuarios. El éxito validó una percepción arquitectónica central: los aceleradores construidos específicamente optimizados para cargas de trabajo específicas podrían entregar mejoras de orden de magnitud sobre los procesadores de propósito general.
TPU v2: Habilitando el Entrenamiento a Escala (2017)
La segunda generación transformó las TPUs de aceleradores solo para inferencia en plataformas completas de entrenamiento. Google rediseñó toda la arquitectura alrededor de operaciones de punto flotante, reemplazando el arreglo INT8 de 256×256 con multiplicadores-acumuladores bfloat16 de 128×128 duales por núcleo.⁹ Cada chip contenía dos TensorCores compartiendo 8GB de Memoria de Alto Ancho de Banda por núcleo, una actualización masiva desde DDR3 que proporcionó el ancho de banda que el entrenamiento de redes neuronales demandaba.
La precisión bfloat16 resultó crítica para el éxito de TPU v2. El formato mantiene el mismo rango de exponente de 8 bits que FP32 mientras reduce la mantisa a 7 bits, preservando el rango dinámico para entrenamiento mientras reduce a la mitad los requerimientos de ancho de banda de memoria.¹⁰ Los ingenieros observaron que la precisión reducida de mantisa en realidad mejoró la generalización en muchos modelos al actuar como una forma de regularización, mientras que el rango completo de exponente FP32 previno los problemas de underflow y overflow que plagaron el entrenamiento FP16.
La innovación arquitectónica que verdaderamente diferenció a TPU v2 fue la Interconexión Inter-Chip (ICI). Los aceleradores anteriores requerían Ethernet o InfiniBand para comunicación multi-chip, introduciendo cuellos de botella de latencia y ancho de banda. Google diseñó enlaces bidireccionales de alta velocidad personalizados que conectaron cada TPU directamente a cuatro vecinos en una topología de toro 2D.¹¹ La interconexión habilitó "pods" TPU v2 de hasta 256 chips para funcionar como un solo acelerador lógico, con operaciones colectivas como all-reduce ejecutándose mucho más rápido que alternativas basadas en red.
TPU v3: Escalado de Rendimiento con Refrigeración Líquida (2018)
Google aumentó agresivamente las velocidades de reloj y conteos de núcleos en TPU v3, entregando 420 teraflops por chip—más que duplicando el rendimiento de v2.¹² La densidad de potencia aumentada forzó un cambio arquitectónico dramático: refrigeración líquida. Cada pod TPU v3 requería infraestructura de refrigeración por agua, una desviación de los diseños refrigerados por aire de generaciones anteriores y la mayoría de aceleradores de centros de datos.¹³
El chip mantuvo la arquitectura dual MXU 128×128 pero aumentó el número total de núcleos y mejoró el ancho de banda de memoria. Cada TPU v3 contenía cuatro chips con dos núcleos cada uno, compartiendo 32GB de memoria HBM total a través de los chips.¹⁴ Las unidades de procesamiento vectorial recibieron mejoras para funciones de activación, operaciones de normalización y cálculos de gradientes que frecuentemente creaban cuellos de botella en el entrenamiento solo en las unidades matriciales.
Los despliegues escalaron a pods de 2,048 chips usando la misma topología de toro 2D ICI que v2 pero con mayor ancho de banda por enlace. Google entrenó modelos cada vez más grandes en pods v3, descubriendo que el diámetro de red reducido de la topología de toro (la distancia máxima entre dos chips escala como N/2 en lugar de N) minimizó la sobrecarga de comunicación para estrategias de entrenamiento tanto paralelo de datos como paralelo de modelos.¹⁵
TPU v4: Avance en Conmutación de Circuitos Ópticos (2021)
La cuarta generación representó el salto arquitectónico más significativo de Google desde la TPU original. Los ingenieros aumentaron la escala del pod a 4,096 chips mientras introducían conmutación de circuitos ópticos (OCS) para interconexión, una tecnología prestada de las telecomunicaciones que revolucionó la infraestructura ML a escala de centro de datos.¹⁶
La arquitectura central de TPU v4 presentó cuatro MXUs de 128×128 por TensorCore junto con unidades vectoriales y escalares mejoradas. Cada par de TensorCore compartía 128MB de Memoria Común además de la Memoria Vectorial por núcleo, habilitando patrones más sofisticados de staging y reutilización de datos.¹⁷ La topología del chip evolucionó de toro 2D a 3D, conectando cada TPU a seis vecinos en lugar de cuatro, reduciendo aún más el diámetro de red y mejorando el ancho de banda de bisección.
El sistema de conmutación de circuitos ópticos cambió todo sobre el despliegue a gran escala. En lugar de cableado fijo entre TPUs, Google desplegó conmutadores ópticos programables que podían reconfigurar dinámicamente qué chips se conectaban con cuáles. Espejos MEMS (sistemas microelectromecánicos) redirigen físicamente haces de luz para conectar pares de TPU arbitrarios, introduciendo esencialmente cero latencia más allá del tiempo de transmisión de fibra óptica.¹⁸ Los conmutadores se reconfiguran en ventanas de sub-10-nanosegundos, más rápido que la mayoría de protocolos de red.
La arquitectura OCS habilitó capacidades previamente imposibles. Google podría aprovisionar "slices" de cualquier tamaño, desde cuatro chips hasta el pod completo de 4,096 chips, programando apropiadamente los conmutadores ópticos. Los chips fallidos podrían ser enrutados sin problemas sin tumbar racks completos. Más notablemente, TPUs físicamente distantes en diferentes ubicaciones de centros de datos podrían ser lógicamente adyacentes en la topología de red, desacoplando completamente el diseño físico y lógico.¹⁹
TPU v4 también introdujo SparseCore, un procesador especializado para manejar operaciones de embeddings usadas todos los días en sistemas de recomendaciones, modelos de ranking, y modelos de lenguaje grandes con embeddings de vocabulario masivos. El SparseCore presentó cuatro procesadores dedicados por chip, cada uno con 2.5MB de memoria scratchpad y flujo de datos optimizado para patrones de acceso de memoria dispersa.²⁰ Los modelos con embeddings ultra-grandes lograron aceleraciones de 5-7× usando solo el 5% del área total del die del chip y presupuesto de energía.
TPU v5p y v5e: Especialización y Escala (2022-2023)
Google dividió la quinta generación en dos productos distintos dirigidos a diferentes casos de uso. TPU v5p priorizó el máximo rendimiento para entrenamiento a gran escala, mientras v5e optimizó para inferencia costo-efectiva y trabajos de entrenamiento más pequeños.²¹
TPU v5p logró aproximadamente 4.45 exaflops por segundo a través de pods de 8,960 chips, más que duplicando el tamaño máximo de pod de v4.²² El ancho de banda de interconexión alcanzó 4,800 Gbps por chip, y la topología de toro 3D conectó chips en superpods masivos de 16×20×28. El fabric de conmutación de circuitos ópticos manejó 13,824 puertos ópticos a través de 48 unidades OCS para cablear un superpod v5p completo, representando uno de los despliegues de conmutación óptica más grandes en la historia de la computación.²³
TPU v5e tomó un enfoque diferente, reduciendo el conteo de núcleos y velocidad de reloj para alcanzar objetivos agresivos de potencia y costo. Los chips optimizados para inferencia contenían solo un núcleo TPU por chip en lugar de dos, y regresaron a la topología de toro 2D, que fue suficiente para tamaños de pod más pequeños.²⁴ La simplificación arquitectónica habilitó a Google a precio v5e competitivamente para cargas de trabajo donde el rendimiento absoluto importaba menos que el rendimiento por dólar.
TPU v6e Trillium: Cuadruplicando el Rendimiento Matricial (2024)
Trillium marcó otro punto de inflexión arquitectónica al expandir la Unidad de Multiplicación de Matrices de 128×128 a 256×256 multiplicadores-acumuladores.²⁵ El arreglo más grande cuadruplicó los FLOPs por ciclo a la misma velocidad de reloj, entregando 4.7× el rendimiento de cómputo pico de TPU v5e a través de una combinación del MXU expandido y frecuencias de reloj aumentadas.
El subsistema de memoria recibió actualizaciones igualmente dramáticas. La capacidad HBM se duplicó a 32GB por chip, con ancho de banda duplicado por canales HBM de próxima generación.²⁶ El ancho de banda de Interconexión Interchip se duplicó similarmente, habilitando pods de 256 chips Trillium para sostener mayor throughput para modelos que estresaban tanto cómputo como comunicación.²⁷
Trillium presentó el acelerador SparseCore de tercera generación, con capacidades mejoradas para embeddings ultra-grandes en cargas de trabajo de ranking y recomendaciones. El diseño actualizado mejoró los patrones de acceso a memoria y aumentó el ancho de banda adecuado entre SparseCores y HBM para modelos dominados por búsquedas de embeddings en lugar de multiplicaciones de matrices.²⁸
La eficiencia energética mejoró 67% sobre v5e a pesar de las ganancias sustanciales de rendimiento.²⁹ Google logró las ganancias de eficiencia a través de nodos de proceso avanzados, optimizaciones arquitectónicas que redujeron el trabajo desperdiciado, y cuidadoso power gating de unidades no utilizadas durante operaciones que no estresaban todas las partes del chip simultáneamente.
TPU v7 Ironwood: La Era FP8 (2025)
La TPU de séptima generación de Google, con nombre código Ironwood, representa la primera TPU diseñada con soporte nativo FP8 y optimizada específicamente para la "era de la inferencia" mientras mantiene rendimiento de entrenamiento de vanguardia.³⁰ Cada chip Ironwood entrega 4.6 petaFLOPS de cómputo denso FP8—excediendo ligeramente el B200 competidor de NVIDIA en 4.5 petaFLOPS—mientras consume 600W de potencia de diseño térmico.³¹
El sistema de memoria se expandió a 192GB de memoria HBM3e por chip, seis veces la capacidad de Trillium, con ancho de banda alcanzando 7.4TB/s.³² El aumento dramático de memoria permite servir modelos ultra-grandes con caches key-value que anteriormente requerían paralelismo de tensor complejo a través de múltiples aceleradores. Google diseñó específicamente la capacidad de memoria para soportar modelos multi-modales emergentes y aplicaciones de contexto largo acercándose a ventanas de millón de tokens.
La interconexión de Ironwood proporciona 9.6 Tbps de ancho de banda bidireccional agregado a través de cuatro enlaces ICI, traduciéndose a 1.2 TB/s de ancho de banda pico por chip.³³ La arquitectura escala desde pods de 256 chips para despliegues más pequeños hasta superpods masivos de 9,216 chips entregando 42.5 FP8 exaflops de poder de cómputo.³⁴ La tecnología de red del centro de datos Jupiter de Google teóricamente podría soportar hasta 43 superpods Ironwood en un solo clúster—aproximadamente 400,000 aceleradores representando una escala casi incomprensible de cómputo.³⁵
El soporte FP8 representa un cambio fundamental en la estrategia de precisión. Las generaciones anteriores de TPU emulaban operaciones de 8 bits usando técnicas de software, lo que introducía sobrecarga. Ironwood implementa unidades de multiplicación-acumulación FP8 nativas soportando tanto formatos E4M3 (exponente de 4 bits, mantisa de 3 bits) como E5M2 (exponente de 5 bits, mantisa de 2 bits).³⁶ El soporte de formato dual habilita mezclar E4M3 para pases hacia adelante donde la precisión importa menos y E5M2 para pases hacia atrás donde mantener las magnitudes de gradientes previene inestabilidad de entrenamiento.
El compromiso de Anthropic de desplegar más de un millón de chips Ironwood comenzando en 2026 demuestra la preparación para producción de la arquitectura. La empresa planea aprovechar bien más de un gigawatt de capacidad TPU—suficiente para alimentar una ciudad pequeña—exclusivamente para entrenar y servir modelos Claude.³⁷ La escala empequeñece incluso los despliegues GPU más significativos conocidos y representa una apuesta fundamental en la arquitectura TPU para el desarrollo de modelos de frontera.
Referencia Rápida de Generación Actual
Las siguientes tablas proporcionan especificaciones escaneables para las tres TPUs de generación actual más relevantes para despliegues de producción en 2025:
Tabla 1: Especificaciones de Cómputo Central

Tabla 2: Memoria y Ancho de Banda
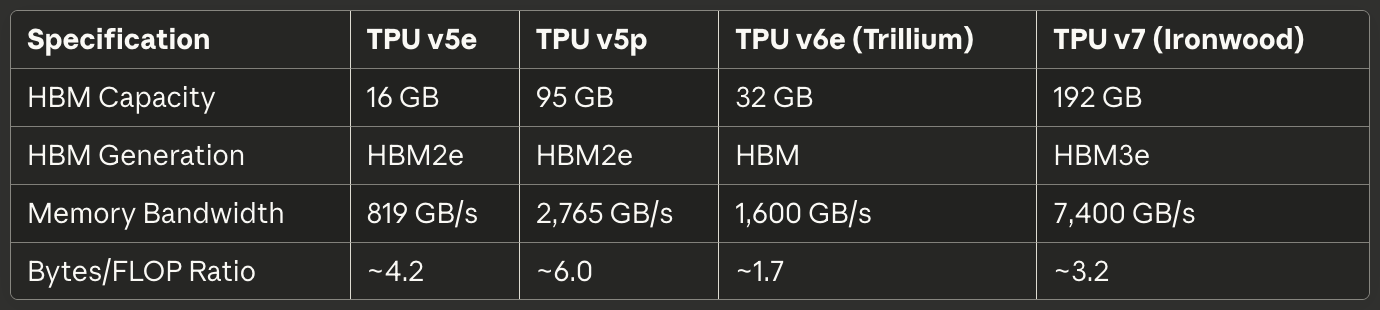
Tabla 3: Interconexión y Escalado
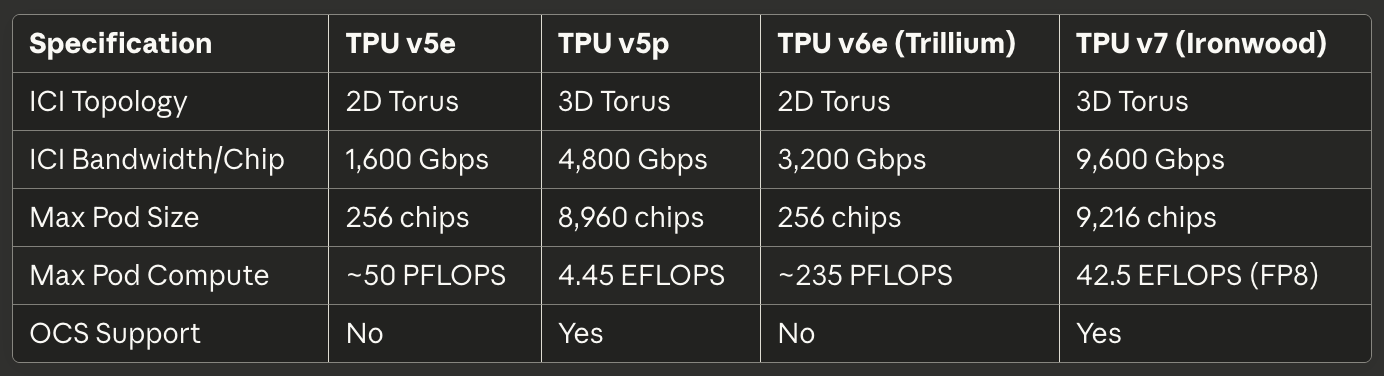
Tabla 4: Potencia y Eficiencia

Tabla 5: Casos de Uso Recomendados

Arquitectura de Hardware: Dentro del Silicio
Matemáticas del Arreglo Sistólico y Flujo de Datos
La Unidad de Multiplicación de Matrices forma el corazón de la arquitectura TPU, y entender los arreglos sistólicos requiere comprender su enfoque fundamentalmente diferente al paralelismo comparado con los carriles SIMD de GPU. Un arreglo sistólico encadena unidades de multiplicación-acumulación en una cuadrícula donde los datos fluyen rítmicamente a través de la estructura—de ahí "sistólico", evocando el bombeo rítmico de sangre a través del corazón.³⁸
Considere el arreglo sistólico 256×256 de TPU v6e realizando la multiplicación de matrices C = A × B. Los ingenieros precargan los pesos de la matriz B en las 65,536 unidades individuales de multiplicación-acumulación arregladas en una cuadrícula. Los valores de activación de la matriz A entran desde el borde izquierdo y fluyen horizontalmente a través del arreglo. Cada unidad MAC multiplica su peso almacenado por la activación entrante, suma el resultado a una suma parcial llegando desde arriba, y pasa tanto la activación (horizontalmente) como la suma parcial actualizada (verticalmente) a unidades vecinas.³⁹
El patrón de flujo de datos significa que cada valor de activación se reutiliza 256 veces mientras atraviesa la dimensión horizontal, y cada suma parcial acumula contribuciones de 256 multiplicaciones mientras fluye verticalmente. Críticamente, todos los resultados intermedios pasan directamente entre unidades MAC adyacentes vía cables cortos en lugar de ir y volver a memoria. La arquitectura realiza 65,536 operaciones de multiplicación-acumulación cada ciclo de reloj, y durante toda la multiplicación de matrices que involucra potencialmente millones de operaciones, cero valores intermedios tocan DRAM o incluso SRAM en chip.⁴⁰
El patrón de flujo de datos estacionario de pesos optimiza para el caso más común en inferencia y entrenamiento de redes neuronales: multiplicar repetidamente muchas matrices de activación diferentes por la misma matriz de pesos. Los ingenieros cargan pesos una vez, luego transmiten lotes de activación ilimitados a través del arreglo sin recargar. El patrón funciona excepcionalmente bien para capas convolucionales, capas completamente conectadas, y las operaciones Q·K^T y attention·V que dominan los modelos transformer.⁴¹
La eficiencia energética surge de la reutilización de datos y localidad espacial. Leer un valor de DRAM consume aproximadamente 200× tanta energía como una sola operación de multiplicación-acumulación.⁴² Al reutilizar cada peso 256 veces y cada activación 256 veces sin accesos a memoria, el arreglo sistólico logra ratios de operaciones por watt imposibles para arquitecturas que transfieren datos de ida y vuelta entre unidades de cómputo y jerarquías de memoria.
La debilidad del arreglo sistólico emerge con patrones de computación dinámicos o irregulares. Porque los datos fluyen a través de la cuadrícula en un horario fijo, la arquitectura lucha con ejecución condicional, matrices dispersas (a menos que use SparseCore), y operaciones que requieren patrones de acceso aleatorios. La inflexibilidad intercambia generalidad por eficiencia extrema en su carga de trabajo objetivo: multiplicación de matrices densas con patrones de acceso predecibles.
Arquitectura Interna TensorCore
Cada chip TPU contiene uno o más TensorCores—la unidad de procesamiento completa que comprende la Unidad de Multiplicación de Matrices, Unidad de Procesamiento Vectorial, y Unidad Escalar trabajando en concierto.⁴³ El TensorCore representa el bloque de construcción fundamental que el software dirige, y entender la interacción entre sus tres componentes explica tanto las características de rendimiento TPU como los patrones de programación.
La Unidad de Multiplicación de Matrices ejecuta 16,000 operaciones de multiplicación-acumulación por ciclo en entradas bfloat16 o FP8 con acumulación FP32.⁴⁴ El enfoque de precisión mixta preserva precisión numérica en el acumulador mientras reduce el ancho de banda de memoria para entradas. Los ingenieros observaron que mantener precisión completa FP32 durante acumulación previene errores de cancelación catastrófica al sumar cientos o miles de productos intermedios, mientras que las entradas de precisión reducida rara vez afectan la calidad final del modelo.
La Unidad de Procesamiento Vectorial maneja operaciones mal adaptadas a la estructura rígida del MXU. Funciones de activación (ReLU, GELU, SiLU), capas de normalización (batch norm, layer norm), softmax, pooling, dropout, y operaciones elemento por elemento se ejecutan en la arquitectura SIMD de 128 carriles del VPU.⁴⁵ El VPU opera en tipos de datos FP32 e INT32, proporcionando la precisión requerida para operaciones numéricamente sensibles como softmax, donde exponenciales y divisiones pueden crear grandes rangos dinámicos.
La Unidad Escalar orquesta todo el TensorCore. El procesador de un solo hilo ejecuta flujo de control, calcula direcciones de memoria para patrones de indexación complejos, e inicia transferencias DMA desde Memoria de Alto Ancho de Banda hacia Memoria Vectorial.⁴⁶ Porque la unidad escalar corre en un solo hilo, cada TensorCore puede crear solo una solicitud DMA por ciclo—un cuello de botella para operaciones intensivas en memoria que no saturan el throughput de cómputo MXU o VPU.
La jerarquía de memoria alimentando el TensorCore determina el rendimiento alcanzable tanto como la capacidad bruta de cómputo. La Memoria Vectorial (VMEM) actúa como un scratchpad SRAM manejado por software exclusivo a cada TensorCore, típicamente dimensionado en decenas de megabytes. El compilador XLA programa explícitamente el movimiento de datos entre HBM y VMEM, decidiendo qué organizar en la memoria local rápida y cuándo escribir resultados de vuelta.⁴⁷
La Memoria Común (CMEM), presente en TPU v4 y generaciones posteriores, proporciona un pool compartido más grande accesible a todos los TensorCores en un chip. La arquitectura TPU v4 asignó 128MB de CMEM compartida entre dos TensorCores, habilitando patrones más sofisticados de productor-consumidor en los que las salidas de un núcleo alimentan las entradas de otro núcleo sin ir y volver a HBM.⁴⁸.
Las implicaciones del modelo de programación importan enormemente. Porque la unidad escalar es de un solo hilo y la memoria vectorial requiere gestión explícita, la programación TPU se asemeja más al desarrollo de sistemas embebidos de la era de 1990 que a la programación GPU moderna. CUDA abstrae el movimiento de memoria con memoria unificada y caches gestionados por hardware; el código TPU (ya sea generado por XLA o escrito a mano en Pallas) debe orquestar explícitamente cada transferencia de datos. El control manual habilita optimización experta pero eleva la barra para rendimiento competente.
Arquitectura de Memoria de Alto Ancho de Banda
Las TPUs modernas usan HBM (Memoria de Alto Ancho de Banda), o HBM3e, una tecnología de memoria radicalmente diferente de la DDR SDRAM encontrada en CPUs, y la GDDR usada en muchos GPUs. HBM apila múltiples dies DRAM verticalmente usando vías a través de silicio (TSVs), luego coloca la pila directamente adyacente al die del procesador en un interposer de silicio.⁴⁹ El camino eléctrico corto y la interfaz ancha habilitan ancho de banda dramáticamente más alto que las tecnologías de memoria convencionales.
TPU v7 Ironwood implementa 192GB de HBM3e con un ancho de banda total de 7.4 TB/s.⁵⁰ El sistema de memoria se divide en múltiples canales, cada uno proporcionando acceso independiente a una porción separada de la capacidad total. El compilador XLA y el runtime deben particionar cuidadosamente tensores a través de canales HBM para maximizar acceso paralelo y evitar hotspots donde un canal se satura mientras otros permanecen inactivos.
El ancho de la interfaz de memoria empequeñece el DRAM convencional. Donde un canal DDR5 podría proporcionar 64 bits de ancho, un canal HBM típicamente abarca 1,024 bits.⁵¹ El ancho extremo habilita alto ancho de banda a velocidades de reloj relativamente modestas, reduciendo el consumo de energía y desafíos de integridad de señal comparado con empujar interfaces estrechas a frecuencias de multi-gigahertz.
Las características de latencia difieren sustancialmente de los sistemas de memoria GPU. Las TPUs carecen de caches gestionados por hardware más allá de pequeños buffers locales, por lo que la arquitectura depende de software explícitamente organizando datos en VMEM mucho antes de que las unidades de cómputo los necesiten. La falta de caches significa que la latencia de memoria impacta directamente el rendimiento a menos que el compilador oculte exitosamente la latencia a través de prefetching y double-buffering.⁵²
Los límites de capacidad de memoria dominan muchas cargas de trabajo más que el throughput de cómputo. Un modelo de 175 billones de parámetros con pesos bfloat16 requiere 350GB para almacenar parámetros—ya excediendo los 192GB HBM de Ironwood incluso antes de contabilizar activaciones, estados del optimizador, o buffers de gradiente. Entrenar tales modelos demanda técnicas sofisticadas como gradient checkpointing, sharding de estados del optimizador a través de múltiples chips, y programación cuidadosa de actualizaciones de parámetros para minimizar la huella de memoria.⁵³
El runtime TPU hace cumplir requerimientos específicos de layout de tensor para maximizar eficiencia MXU. Porque el arreglo sistólico procesa datos en tiles de 128×8, los tensores deberían alinearse a estas dimensiones para evitar desperdicio de relleno.⁵⁴ Las matrices mal dimensionadas fuerzan al hardware a procesar tiles parciales con MACs permaneciendo inactivos, reduciendo directamente la utilización de FLOPS. El compilador intenta rellenar y remodelar tensores automáticamente, pero decisiones conscientes de layout en la arquitectura del modelo pueden mejorar sustancialmente el rendimiento.
SparseCore: Aceleración Especializada de Embeddings
Mientras que la Unidad de Multiplicación de Matrices sobresale en operaciones de matrices densas, las cargas de trabajo intensivas en embeddings exhiben características radicalmente diferentes. Los modelos de recomendaciones, sistemas de ranking, y modelos de lenguaje grandes frecuentemente acceden tablas de embeddings masivas (a menudo cientos de gigabytes) a través de índices irregulares, dependientes de datos. El flujo de datos estructurado del MXU no proporciona ventaja para estos patrones de acceso de memoria dispersa, motivando la arquitectura especializada de SparseCore.⁵⁵
SparseCore implementa un procesador de flujo de datos en tiles fundamentalmente diferente del arreglo sistólico del MXU. TPU v4 presentó cuatro SparseCores por chip, cada uno conteniendo 16 tiles de cómputo.⁵⁶ Cada tile opera como una unidad independiente de flujo de datos con memoria scratchpad local (SPMEM) y elementos de procesamiento. Los tiles se ejecutan en paralelo, procesando subconjuntos disjuntos de operaciones de embedding simultáneamente.
La jerarquía de memoria coloca datos calientes en SPMEM pequeña y rápida mientras mantiene las tablas completas de embedding en HBM. El compilador XLA analiza patrones de acceso de embedding para determinar qué vectores de embedding merecen caché en SPMEM versus fetching bajo demanda de HBM.⁵⁷ La estrategia se asemeja a jerarquías de cache CPU tradicionales, pero con software en lugar de hardware tomando decisiones de colocación.
Los SparseCores se conectan directamente a canales HBM, evitando completamente el camino de memoria del TensorCore. La conexión dedicada previene que las operaciones de embedding compitan con operaciones de matrices densas por ancho de banda de memoria, habilitando que ambas procedan en paralelo.⁵⁸ El particionado funciona excepcionalmente bien para modelos como Modelos de Recomendación de Aprendizaje Profundo (DLRMs) que intercalan capas de redes neuronales densas con búsquedas grandes de embeddings.
La estrategia de mod-sharding distribuye embeddings a través de SparseCores calculando target_sc_id = col_id % num_total_sparse_cores.⁵⁹ La función de sharding simple asegura balanceamiento de carga cuando los IDs de embedding se distribuyen uniformemente, pero puede crear hotspots para patrones de acceso sesgados. Los ingenieros trabajando con datos del mundo real a menudo necesitan analizar distribuciones de frecuencia de embeddings y rebalancear manualmente el sharding para evitar cuellos de botella.
Las ganancias de rendimiento de SparseCore alcanzan 5-7× comparado con implementar operaciones idénticas en el MXU y VPU, mientras consumen solo 5% del área del die del chip y energía.⁶⁰ La ventaja dramática de eficiencia surge de construir específicamente el flujo de datos para operaciones dispersas en lugar de forzarlas a través de infraestructura de matrices densas. El principio de especialización se aplica recursivamente dentro de la arquitectura TPU: así como las TPUs se especializan más allá del diseño de propósito general de los GPUs, los SparseCores se especializan más allá del diseño orientado a matrices de las TPUs.
El SparseCore de tercera generación de Trillium introdujo ancho SIMD variable (8 elementos para FP32, 16 para bfloat16) y patrones mejorados de acceso a memoria, reduciendo ancho de banda desperdiciado de lecturas mal alineadas.⁶¹ La evolución arquitectónica demuestra la inversión continua de Google en aceleración de embeddings mientras los modelos de lenguaje grandes tienden hacia vocabularios más grandes y patrones más sofisticados de generación aumentada por recuperación.
Tecnología de Interconexión: Cableando la Supercomputadora
Arquitectura de Interconexión Inter-Chip (ICI)
La Interconexión Inter-Chip es la tecnología crítica que permite que las TPUs funcionen como supercomputadoras unificadas en lugar de aceleradores aislados. A diferencia de las GPUs que se comunican a través de redes Ethernet o InfiniBand, ICI implementa enlaces seriales personalizados de alta velocidad que conectan directamente TPUs vecinas con latencia a escala de microsegundos y ancho de banda de terabits por segundo.⁶²
La evolución de topología a través de las generaciones de TPU refleja los requisitos cambiantes para el escalado de pods. TPU v2, v3, v5e y v6e implementan topologías de toro 2D en las que cada chip se conecta a sus cuatro vecinos más cercanos (norte, sur, este y oeste).⁶³ Los enlaces se envuelven en los límites, creando una topología lógica en forma de dona que elimina chips de borde con menos conexiones. Una cuadrícula de 16×16 de 256 TPUs proporciona así características uniformes de ancho de banda y latencia independientemente de qué dos chips se comuniquen.
TPU v4 y v5p se actualizaron a topologías de toro 3D con cada chip conectándose a seis vecinos.⁶⁴ La dimensión adicional reduce el diámetro de red—el conteo máximo de saltos entre dos chips cualesquiera—de aproximadamente 2√N a 3∛N. Para un pod de 4,096 chips, los saltos máximos caen de aproximadamente 128 a 48, reduciendo sustancialmente la latencia de comunicación del peor caso para operaciones de sincronización global como all-reduce.
La estructura toroidal proporciona otra ventaja crítica: igual ancho de banda de bisección independientemente de cómo las cargas de trabajo se particionen a través de los chips. Cualquier corte que divida el toro por la mitad cruza el mismo número de enlaces, previniendo casos patológicos donde la mala ubicación de trabajos crea cuellos de botella en la red.⁶⁵ El ancho de banda uniforme de bisección simplifica la programación y habilita la reconfigurabilidad del switch de circuito óptico discutida abajo.
Las especificaciones de ancho de banda escalan impresionantemente a través de las generaciones. TPU v6e proporciona 13 TB/s de ancho de banda ICI por chip.⁶⁶ TPU v5p alcanzó 4,800 Gbps por chip a través de seis enlaces de toro 3D.⁶⁷ Ironwood implementa cuatro enlaces ICI con un ancho de banda bidireccional agregado de 9.6 Tbps, traduciendo a 1.2 TB/s por chip.⁶⁸ Para comparación, una interfaz de red 400GbE de primer nivel proporciona 50GB/s de ancho de banda bidireccional—un orden de magnitud menos que ICI de TPU moderna.
La tecnología de enlaces dentro de racks usa cables de cobre de conexión directa (DAC) para distancias cortas entre chips en el mismo cubo de 4×4×4.⁶⁹ Las conexiones de cobre minimizan el costo y la energía mientras proporcionan el ancho de banda requerido para chips estrechamente acoplados ejecutando operaciones sincronizadas. Los enlaces inter-cubo y a escala de pod transicionan a transceptores ópticos, intercambiando mayor costo y energía por la distancia y ancho de banda necesarios para abarcar racks de datacenter.
Las operaciones colectivas explotan las propiedades únicas de ICI. Las operaciones all-reduce, all-gather y reduce-scatter frecuentemente sincronizan activaciones y gradientes a través de chips durante el entrenamiento. En clusters de GPU basados en Ethernet, estas colectivas atraviesan una red jerárquica con switches, cables y tarjetas de interfaz de red, introduciendo latencia en cada salto. TPU ICI implementa algoritmos colectivos optimizados directamente en hardware, ejecutando operaciones all-reduce 10× más rápido que implementaciones equivalentes de GPU basadas en Ethernet.⁷⁰
Conmutación de Circuito Óptico: Reconfiguración Dinámica de Topología
El despliegue de conmutación de circuito óptico (OCS) por parte de Google con TPU v4 representó una de las innovaciones más significativas en redes de datacenter en décadas. Las redes tradicionales de conmutación de paquetes—ya sea Ethernet o InfiniBand—establecen conexiones lógicas enrutando paquetes salto por salto a través de switches que examinan encabezados y reenvían a puertos de salida apropiados. OCS en su lugar usa elementos ópticos programables para crear rutas físicas directas de luz entre puntos finales, eliminando completamente la latencia de conmutación.⁷¹
La tecnología central se basa en espejos MEMS (sistemas microelectromecánicos) que rotan físicamente para redirigir haces de luz. Un transmisor en TPU A envía luz al OCS. Pequeños espejos dentro del OCS rotan para reflejar ese haz de luz a un receptor en TPU B. La conexión se convierte en una ruta óptica directa de A a B con esencialmente cero latencia añadida más allá de la propagación de luz a través de la fibra.⁷²
La velocidad de reconfiguración determina la practicidad de OCS en sistemas de producción. El despliegue de Google logra tiempos de conmutación sub-10-nanosegundos—más rápido que los tiempos típicos de ida y vuelta de protocolos de red.⁷³ La velocidad de reconfiguración habilita cambios dinámicos de topología que coinciden con los requisitos de carga de trabajo sin interrumpir trabajos en ejecución o requerir ingeniería de tráfico cuidadosamente coordinada.
TPU v5p demostró OCS a escala masiva. La arquitectura usa switches de circuito óptico que entregan cuatro petabits por segundo de ancho de banda agregado a través del fabric de conmutación.⁷⁴ Un solo superpod v5p requiere 48 unidades OCS gestionando 13,824 puertos ópticos para cablear 8,960 chips en la configuración de toro 3D de 16×20×28.⁷⁵ El sistema de conmutación representa uno de los despliegues de redes ópticas más grandes en cualquier entorno de computación.
OCS proporciona capacidades imposibles con redes tradicionales. La topología física y la topología lógica se desacoplan completamente—dos TPUs en esquinas opuestas del datacenter aparecen como vecinos adyacentes si el OCS crea rutas ópticas directas. Chips o enlaces fallidos se enrutan alrededor reprogramando espejos para excluir componentes defectuosos y mantener la estructura de toro lógica. Nuevos trabajos reciben "rebanadas" de cualquier tamaño programando el OCS para crear configuraciones de pod apropiadas sin re-cablear físicamente racks.⁷⁶
La arquitectura se integra con la red de datacenter Jupiter de Google para escalar más allá de un solo pod. Jupiter entrega ancho de banda de bisección de multi-petabits por segundo a través de datacenters enteros usando switches de silicio personalizados y plano de control de Google.⁷⁷ Múltiples superpods TPU se conectan vía fabric Jupiter, teóricamente soportando clusters de hasta 400,000 aceleradores si la capacidad de red lo permite.⁷⁸
El consumo de energía y las características de confiabilidad favorecen la conmutación de circuito óptico para despliegues a escala TPU. Los switches de paquetes tradicionales consumen energía sustancial procesando y reenviando paquetes a tasas de terabits por segundo. Los switches OCS consumen energía solo para operar espejos MEMS durante eventos de reconfiguración, luego permanecen inactivos, pasando luz con pérdida mínima mientras las conexiones permanecen estables.⁷⁹ La simplicidad de la arquitectura mejora la confiabilidad eliminando el procesamiento complejo de paquetes y lógica de buffering propensa a bugs y anomalías de rendimiento.
Arquitectura de Pod y Características de Escalado
Los pods TPU representan la unidad más grande de TPUs conectadas a través de ICI, formando un acelerador unificado. La estructura física se construye jerárquicamente desde chips individuales hasta bandejas hasta cubos hasta racks hasta pods completos.⁸⁰ Entender la jerarquía importa para razonar sobre capacidad de memoria, ancho de banda de comunicación y tolerancia a fallos a diferentes escalas.
El bloque de construcción fundamental consiste en cuatro chips en una sola bandeja conectados a un CPU host vía PCIe.⁸¹ La conexión PCIe maneja operaciones del plano de control, carga inicial del programa e infeed/outfeed para datos de entrenamiento y resultados de inferencia. La comunicación inter-chip real para entrenamiento distribuido fluye a través de ICI en lugar de PCIe, evitando cuellos de botella de ancho de banda PCIe.
Dieciséis bandejas (64 chips) forman un solo cubo de 4×4×4—la unidad básica para construcción de pod. Dentro de un cubo, todas las conexiones ICI usan cables de cobre de conexión directa ya que los chips residen en el mismo rack con distancias físicas cortas.⁸² El cubo implementa un toro 3D completo con conexiones de envolvimiento, creando una unidad auto-contenida de 64 chips que podría teóricamente operar independientemente.
Los pods TPU v4 escalan hasta 64 cubos totalizando 4,096 chips.⁸³ Las conexiones inter-cubo transicionan a enlaces ópticos gestionados por el fabric de conmutación de circuito óptico. El OCS puede aprovisionar estos 4,096 chips como un solo pod enorme, múltiples pods independientes más pequeños, o reconfigurar dinámicamente a mitad de trabajo si se requiere. La flexibilidad permite a los operadores de datacenter balancear utilización a través de diferentes tamaños y prioridades de trabajos.
TPU v5p empujó la escala de pod a 8,960 chips en un toro 3D de 16×20×28.⁸⁴ Las dimensiones específicas reflejan optimización cuidadosa de ancho de banda y diámetro—¡las factorizaciones primas importan para topología de red! El pod entrega 4.45 exaflops de cómputo y representa una de las configuraciones de pod único más grandes desplegadas en producción.
Ironwood soporta tanto pods de 256 chips para despliegues más pequeños como superpods de 9,216 chips para entrenamiento masivo de modelos de frontera.⁸⁵ La configuración de 9,216 chips entrega 42.5 FP8 exaflops—más cómputo que toda la lista Top500 de supercomputadoras contenía solo cinco años antes.⁸⁶ La escala redefine lo que las organizaciones pueden lograr con entrenamiento síncrono en lugar de enfoques por tuberías o asíncronos.
La eficiencia de escalado determina si los pods más grandes realmente ayudan. La sobrecarga de comunicación aumenta con el tamaño del pod ya que los chips pasan más tiempo sincronizándose en lugar de computando. Google Research publicó resultados demostrando 95% de eficiencia de escalado a 32,768 TPUs para cargas de trabajo específicas, significando que 32,768 TPUs entregaron 95% del rendimiento que el escalado lineal perfecto predeciría.⁸⁷ La eficiencia se deriva de colectivas aceleradas por hardware, transformaciones de compilador optimizadas y enfoques algorítmicos inteligentes para reducir la frecuencia de sincronización de gradientes.
La tolerancia a fallos a escala de pod requiere manejo sofisticado. La probabilidad estadística garantiza fallas de componentes en cualquier sistema con miles de chips corriendo continuamente. El switch de circuito óptico habilita degradación elegante reconfigurando alrededor de componentes fallidos. El checkpointing de entrenamiento ocurre a intervalos regulares (típicamente cada pocos minutos), por lo que la falla de trabajo requiere reiniciar solo desde el último checkpoint en lugar de desde cero.⁸⁸
Pila de Software: Compiladores, Frameworks y Modelos de Programación
Compilador XLA: Optimización de Gráficos de Computación
XLA (Accelerated Linear Algebra) forma la base de la pila de software de la TPU, compilando operaciones de frameworks de alto nivel en código máquina optimizado para ejecución en la TPU.⁸⁹ El compilador implementa optimizaciones agresivas imposibles en compiladores de propósito general porque explota el conocimiento del dominio sobre cargas de trabajo de machine learning y las características de la arquitectura de TPU.
La fusión representa la optimización más impactante de XLA. El compilador analiza gráficos de computación para identificar secuencias de operaciones que pueden ejecutarse sin materializar tensores intermedios. Un ejemplo simple: operaciones elemento por elemento como relu(batch_norm(conv(x))) normalmente requieren escribir la salida de la convolución a memoria, leerla para la normalización por lotes, escribir ese resultado a memoria, y leer nuevamente para ReLU. XLA fusiona estas operaciones en un solo kernel que produce la salida final de ReLU sin tráfico de memoria intermedio.⁹⁰
El impacto de la fusión escala con la arquitectura de TPU. El ancho de banda de memoria limita muchas cargas de trabajo más que el throughput de cómputo—el MXU puede realizar multiplicaciones de matrices más rápido de lo que el sistema de memoria puede alimentarlo con datos. Eliminar escrituras y lecturas de memoria intermedias a través de fusión se traduce directamente en mejoras de rendimiento, a menudo entregando 2× o más aceleración para redes con muchas funciones de activación.⁹¹
Las transformaciones de layout de memoria optimizan el almacenamiento de tensores para los requisitos del hardware. Las redes neuronales a menudo representan tensores en el formato NHWC (lote, altura, ancho, canales) para indexación intuitiva, pero los MXUs de TPU funcionan mejor con layouts que se alinean con tiles de 128×8.⁹² XLA automáticamente transpone, remodela y rellena tensores para coincidir con las preferencias del hardware, insertando transformaciones de layout solo donde es necesario y a veces propagando layouts preferidos hacia atrás a través del gráfico para minimizar el overhead total de transformación.
El compilador implementa constant folding sofisticado y eliminación de código muerto. Los gráficos de ML frecuentemente contienen subgráficos cuyas salidas dependen solo de constantes—parámetros de normalización por lotes, tasas de dropout de inferencia, y cálculos de forma que pueden ejecutarse una vez en lugar de por lote. XLA evalúa estos subgráficos en tiempo de compilación y los reemplaza con tensores constantes, reduciendo el trabajo en tiempo de ejecución.⁹³
La optimización cross-replica explota el conocimiento sobre ejecución distribuida. Al entrenar a través de múltiples cores de TPU, ciertas operaciones (como estadísticas de normalización por lotes) requieren agregación a través de todas las réplicas. XLA identifica estos patrones y genera operaciones colectivas optimizadas que explotan el all-reduce acelerado por hardware de ICI en lugar de implementar agregación a través de paso explícito de mensajes.⁹⁴
El compilador apunta a una representación intermedia, Mosaic, específicamente para TPUs. Mosaic opera a un nivel de abstracción más alto que el lenguaje ensamblador pero más bajo que el gráfico de computación de entrada. El lenguaje expone características arquitecturales de TPU, como arrays sistólicos, memoria vectorial, y staging de VMEM, mientras oculta detalles de bajo nivel, como scheduling de instrucciones y asignación de registros.⁹⁵
Las capacidades de auto-tuning seleccionan tamaños de tile óptimos y parámetros de operación a través de búsqueda empírica. El sistema XLA Auto-Tuning (XTAT) prueba diferentes estrategias de fusión, layouts de memoria, y dimensiones de tile, perfila el rendimiento de cada variante, y selecciona la configuración más rápida.⁹⁶ La búsqueda puede requerir tiempo de compilación sustancial para modelos complejos, pero produce aceleraciones dramáticas en tiempo de ejecución al descubrir optimizaciones contraintuitivas que los humanos rara vez identifican manualmente.
JAX: Transformaciones Componibles y SPMD
JAX proporciona una interfaz compatible con NumPy para computación numérica con diferenciación automática, compilación JIT a XLA, y soporte de primera clase para transformación de programas.⁹⁷ El paradigma de programación funcional del framework y el modelo de transformación componible se alinean naturalmente con los modelos de ejecución de TPU y patrones de paralelismo distribuido.
La abstracción central de JAX aplica transformaciones matemáticas a funciones. Grad(f) calcula el gradiente de f. Jit(f) compila f con JIT a XLA. vmap(f) vectoriza f sobre una nueva dimensión. Críticamente, las transformaciones se componen: jit(grad(vmap(f))) funciona exactamente como se esperaría, compilando una función de gradiente vectorizada.⁹⁸ El modelo composicional permite construir bucles de entrenamiento distribuido complejos a partir de componentes simples y verificables.
SPMD (Single Program, Multiple Data) representa el modelo de ejecución distribuida de JAX. Los programadores escriben código como si apuntaran a un solo dispositivo, luego agregan anotaciones de sharding indicando cómo particionar tensores a través de múltiples cores de TPU. El compilador XLA y el subsistema GSPMD (General SPMD) insertan automáticamente operaciones de comunicación para mantener la semántica del programa mientras ejecutan a través de dispositivos distribuidos.⁹⁹
Las anotaciones de sharding usan PartitionSpec para declarar estrategias de distribución. PartitionSpec('batch', None) divide la primera dimensión de un tensor a través del eje 'batch' de la malla de dispositivos mientras replica la segunda dimensión. PartitionSpec(None, 'model') implementa paralelismo de tensor al particionar la segunda dimensión. Las anotaciones pueden componerse con rangos de tensor arbitrarios y dimensiones de malla de dispositivos.¹⁰⁰
La paralelización automática de GSPMD elimina vastas cantidades de código repetitivo. El entrenamiento distribuido tradicional requiere insertar manualmente un all-gather antes de operaciones que necesitan tensores completos, un reduce-scatter después de calcular gradientes distribuidos, y un all-reduce para reducciones globales. GSPMD analiza especificaciones de sharding y automáticamente inserta colectivos apropiados, liberando a los programadores para enfocarse en el algoritmo en lugar de la ingeniería de comunicación.¹⁰¹
El compilador propaga decisiones de sharding a través del gráfico de computación usando resolución de restricciones. Si la operación A produce un tensor dividido consumido por la operación B, GSPMD infiere el sharding óptimo de B basado en cómo se usa la salida, potencialmente insertando operaciones de resharding solo donde es matemáticamente necesario.¹⁰² La inferencia automatizada previene el "sharding spaghetti" que plaga el código distribuido escrito a mano.
JAX proporciona control fino cuando la automatización es insuficiente. with_sharding_constraint fuerza sharding específico en ubicaciones del gráfico, anulando la inferencia automática. Las anotaciones PJIT (parallel JIT) personalizadas especifican colocación exacta de dispositivos y estrategias de sharding para rutas de código críticas para el rendimiento. El modelo en capas permite prototipado rápido con sharding automático mientras soporta optimización experta donde se requiere.¹⁰³
Shardy surgió como el sucesor de GSPMD en 2025, implementando algoritmos mejorados de propagación de restricciones y mejor manejo de formas dinámicas.¹⁰⁴ El nuevo sistema expone oportunidades de optimización adicionales al razonar sobre opciones de sharding conjuntamente a través de regiones de gráfico más grandes en lugar de operación por operación.
PyTorch/XLA: Llevando PyTorch a TPUs
PyTorch/XLA permite ejecutar modelos de PyTorch en TPUs con cambios mínimos de código, cerrando la brecha entre el modelo de programación imperativa de PyTorch y la compilación basada en gráficos de XLA.¹⁰⁵ La integración equilibra preservar la experiencia de desarrollador de PyTorch con exponer optimizaciones específicas de TPU.
El desafío fundamental surge de la filosofía de ejecución eager de PyTorch. PyTorch ejecuta operaciones inmediatamente conforme las declaraciones Python se ejecutan, habilitando depuración con herramientas estándar y flujo de control natural. XLA requiere capturar gráficos de computación completos antes de la compilación, creando tensión entre la ejecución eager y los beneficios de rendimiento de la compilación de gráficos.¹⁰⁶
PyTorch/XLA 2.4 introdujo soporte para modo eager, abordando el desajuste de impedancia. La implementación traza dinámicamente operaciones de PyTorch en gráficos XLA, permitiendo a los desarrolladores escribir código PyTorch estándar mientras aún se benefician de la compilación XLA.¹⁰⁷ El modo intercambia algunas oportunidades de optimización de compilación por velocidad de desarrollo y simplicidad de depuración.
El modo gráfico permanece como la ruta primaria para despliegues de producción. Los desarrolladores marcan explícitamente funciones para compilación XLA usando decoradores o APIs de compilación. Las anotaciones explícitas habilitan optimización agresiva pero requieren entender qué operaciones deben fusionarse en un solo gráfico XLA versus ejecutarse independientemente.¹⁰⁸
La integración de Pallas trae desarrollo de kernels personalizados a PyTorch/XLA. Pallas proporciona un lenguaje de bajo nivel para escribir kernels de TPU cuando la fusión automática de XLA es insuficiente u operaciones especializadas requieren optimización manual.¹⁰⁹ El lenguaje expone la jerarquía de memoria de TPU (VMEM, CMEM, HBM) y unidades de cómputo (MXU, VPU) mientras permanece a un nivel más alto que el ensamblador crudo.
Los kernels integrados de Pallas implementan operaciones críticas para el rendimiento como FlashAttention y PagedAttention. El cómputo de attention en tiles de FlashAttention reduce los requisitos de ancho de banda de memoria de O(n²) a O(n) para longitud de secuencia n, habilitando modelos para procesar secuencias mucho más largas dentro de presupuestos fijos de memoria.¹¹⁰ PagedAttention optimiza la gestión de cache de key-value para serving, logrando 5× aceleración comparado con implementaciones con padding.¹¹¹
El puente PyTorch/XLA resultó crítico para vLLM TPU—un framework de serving de alto rendimiento diseñado inicialmente para GPUs. La implementación en realidad usa JAX como una ruta de lowering intermedia incluso para modelos de PyTorch, explotando el soporte superior de paralelismo de JAX mientras mantiene compatibilidad de frontend de PyTorch.¹¹² La arquitectura logró mejoras de rendimiento de 2-5× a lo largo de 2025 comparado con prototipos iniciales.
Los desafíos de compatibilidad de modelos persisten a pesar de las mejoras. Algunas operaciones de PyTorch carecen de equivalentes XLA, forzando un fallback a ejecución CPU que degrada el rendimiento. El flujo de control dinámico está pobremente soportado por la compilación de gráficos, a menudo necesitando cambios arquitecturales para reemplazar comportamiento dinámico con alternativas estáticas y compilables. El repositorio PyTorch/XLA documenta compatibilidad y proporciona guías de migración para patrones problemáticos comunes.¹¹³
Formatos de Precisión: BFloat16, FP8, y Cuantización
El soporte de TPU para aritmética de precisión reducida habilita mejoras dramáticas de rendimiento y memoria mientras mantiene calidad de modelo aceptable. Entender las propiedades numéricas de diferentes formatos y cuándo aplicar cada uno resulta crítico para lograr rendimiento óptimo.¹¹⁴
BFloat16 representa la apuesta temprana de Google en entrenamiento de precisión reducida, apareciendo primero en TPU v2. El formato mantiene el exponente de 8 bits de FP32 mientras trunca la mantisa a 7 bits (más bit de signo).¹¹⁵ El rango completo de exponente previene el underflow y overflow que plagaron el entrenamiento FP16 temprano, donde los gradientes frecuentemente escapaban del rango representable de FP16.
La mantisa reducida introduce error de cuantización pero rara vez impacta la calidad final del modelo. Los ingenieros observaron que los modelos entrenados en bfloat16 típicamente igualan las líneas base entrenadas en FP32 dentro del ruido estadístico, probablemente porque la cuantización actúa como una forma de regularización, previniendo overfitting a detalles numéricos diminutos.¹¹⁶ El formato reduce a la mitad los requisitos de ancho de banda y capacidad de memoria comparado con FP32, traduciéndose directamente en ganancias de rendimiento en cargas de trabajo limitadas por memoria.
FP8 lleva la precisión reducida más lejos, comprimiendo pesos y activaciones a 8 bits. Existen dos codificaciones estándar: E4M3 (exponente de 4 bits, mantisa de 3 bits) prioriza precisión para pases hacia adelante, mientras E5M2 (exponente de 5 bits, mantisa de 2 bits) prioriza rango para pases hacia atrás donde las magnitudes de gradiente varían ampliamente.¹¹⁷ Ironwood implementa soporte nativo FP8 para ambos formatos, mientras que TPUs anteriores emulaban FP8 a través de transformaciones de software.¹¹⁸
La conciencia de cuantización durante el entrenamiento habilita el éxito numérico de FP8. Los modelos entrenados desde cero con FP8 o ajustados con técnicas conscientes de FP8 aprenden distribuciones de pesos que toleran la precisión limitada del formato. La cuantización post-entrenamiento (convertir modelos FP32 a FP8 después del entrenamiento) a menudo degrada la calidad sin calibración cuidadosa.¹¹⁹
La cuantización INT8 entrega ahorros de memoria aún mayores y aceleraciones de inferencia. El Accurate Quantized Training (AQT) de Google habilita entrenamiento INT8 en TPUs con pérdida mínima de calidad comparado con líneas base bfloat16.¹²⁰ La técnica aplica entrenamiento consciente de cuantización desde cero, permitiendo a los modelos adaptarse a las restricciones de INT8 durante el aprendizaje en lugar de a través de aproximación post-entrenamiento.
Las estrategias de precisión mixta combinan formatos estratégicamente. Los pases hacia adelante podrían usar FP8 para activaciones y pesos, los pases hacia atrás usan FP8 E5M2 o bfloat16 para gradientes, y los estados del optimizador permanecen en FP32 para estabilidad numérica durante actualizaciones de pesos.¹²¹ El enfoque mixto equilibra velocidad, memoria y precisión, a menudo logrando 90%+ de calidad FP32 mientras ejecuta 4× más rápido.
Los tradeoffs de precisión se extienden más allá de velocidad y memoria para incluir consideraciones de estabilidad numérica. La normalización por lotes, normalización por capas, y softmax requieren manejo numérico cuidadoso en precisión reducida. Los exponenciales grandes en softmax pueden desbordar los rangos FP8 o bfloat16; restar el logit máximo antes de la exponenciación previene el overflow mientras mantiene equivalencia matemática.¹²² El compilador XLA implementa estas transformaciones automáticamente cuando es seguro, pero las operaciones personalizadas a veces requieren ingeniería numérica manual.
## Modelos de Programación y Estrategias de Paralelización
SPMD y Particionado Automático
El paradigma Single Program, Multiple Data (SPMD) moldea fundamentalmente cómo los programadores piensan sobre la ejecución en TPU. En lugar de escribir código explícito de paso de mensajes para coordinar múltiples procesos, los desarrolladores escriben un solo programa y anotan cómo los datos deben particionarse entre dispositivos.¹²³ El compilador maneja los detalles mecánicos de distribución, comunicación y sincronización.
GSPMD (General SPMD) implementa la lógica de particionado automático en XLA. El sistema analiza las anotaciones de sharding de tensores y la estructura del grafo computacional para determinar dónde se ejecutan las operaciones en qué dispositivos y qué comunicación se requiere para mantener la semántica correcta.¹²⁴ La automatización elimina clases enteras de errores comunes en código distribuido escrito manualmente—formas de tensores no coincidentes, ordenamientos incorrectos de operaciones colectivas, y deadlocks por sincronización inapropiada.
El motor de propagación de restricciones del compilador infiere decisiones de sharding a partir de anotaciones mínimas. Anotar solo el sharding de entrada y salida de un modelo a menudo es suficiente; GSPMD propaga restricciones a través de operaciones intermedias y selecciona automáticamente distribuciones eficientes.¹²⁵ Cuando existen múltiples shardings válidos para una operación, el compilador estima los costos de comunicación de las alternativas y selecciona la opción de menor costo.
Las optimizaciones avanzadas superponen comunicación con computación. Las operaciones all-reduce que sincronizan gradientes entre réplicas pueden comenzar tan pronto como se completen los gradientes de la primera capa, ejecutándose en paralelo con los pases hacia atrás para capas subsecuentes.¹²⁶ El compilador programa automáticamente las colectivas para maximizar la superposición, reduciendo el tiempo de comunicación adecuado en 2× o más comparado con la ejecución secuencial.
La rematerialización intercambia computación por memoria. En lugar de almacenar todas las activaciones del pase hacia adelante para el cálculo de gradientes, el compilador recomputa selectivamente las activaciones durante los pases hacia atrás cuando la presión de memoria excede los umbrales.¹²⁷ El intercambio funciona particularmente bien en TPUs donde el cómputo a menudo supera el ancho de banda de memoria, haciendo la recomputación más barata que el tráfico de memoria.
Paralelismo de Datos, Paralelismo de Tensores y Paralelismo de Pipeline
El paralelismo de datos representa la estrategia de entrenamiento distribuido más directa: replicar el modelo completo a través de N dispositivos y procesar diferentes lotes de datos en cada réplica. Después de computar gradientes localmente, un all-reduce agrega gradientes entre réplicas, y todos los dispositivos aplican actualizaciones de pesos idénticas.¹²⁸ El enfoque escala linealmente hasta que el tiempo de comunicación domina el tiempo de computación—típicamente alrededor de 1,000 GPUs con redes Ethernet pero 10,000+ TPUs con ICI.¹²⁹
El paralelismo de tensores (también llamado paralelismo de modelo) particiona operaciones individuales entre dispositivos. Una multiplicación de matrices Y = W @ X divide la matriz de pesos W entre dispositivos, con cada uno computando una porción de la salida.¹³⁰ La estrategia permite entrenar modelos que exceden la memoria de un solo dispositivo distribuyendo el almacenamiento de parámetros y la computación.
El patrón de comunicación para el paralelismo de tensores difiere significativamente del paralelismo de datos. En lugar de all-reduce después de cada capa, el paralelismo de tensores requiere un all-gather antes de operaciones que requieren tensores completos y un reduce-scatter después de computaciones distribuidas.¹³¹ El volumen de comunicación escala con el tamaño de activaciones del modelo en lugar del tamaño de parámetros, creando diferentes cuellos de botella que el paralelismo de datos.
El paralelismo de pipeline particiona capas secuenciales del modelo entre dispositivos, procesando diferentes micro-lotes en diferentes etapas simultáneamente. GPipe introdujo la estrategia con programación cuidadosa para maximizar la utilización del pipeline mientras limita el uso de memoria.¹³² Cada dispositivo procesa el pase hacia adelante de un micro-lote, envía activaciones a la siguiente etapa, luego procesa el siguiente micro-lote—creando un pipeline donde todos los dispositivos trabajan continuamente después del arranque inicial.
La obsolescencia de gradientes complica el paralelismo de pipeline. Los dispositivos actualizan pesos usando gradientes computados de activaciones potencialmente de docenas de micro-lotes anteriores, creando obsolescencia que puede dañar la convergencia.¹³³ Algoritmos sofisticados de programación como PipeDream minimizan la obsolescencia mientras mantienen alto rendimiento, y resultados empíricos demuestran que la mayoría de los modelos toleran obsolescencia moderada sin degradación de calidad.
El paralelismo 3D combina las tres estrategias. El paralelismo de datos distribuye a través de la dimensión "datos", el paralelismo de tensores a través de la dimensión "modelo", y el paralelismo de pipeline a través de la dimensión "pipeline".¹³⁴ Balancear cuidadosamente las dimensiones basado en arquitectura del modelo, topología de hardware y costos de comunicación maximiza el rendimiento. Los modelos a escala GPT-3 comúnmente usan paralelismo 3D con paralelismo de datos entre 8-16 réplicas, paralelismo de tensores entre 4-8 GPUs, y paralelismo de pipeline entre 4-16 etapas.
Estrategias de Sharding y Optimización
Seleccionar estrategias de sharding requiere entender las operaciones matemáticas y sus dependencias de datos. La multiplicación de matrices C = A @ B permite múltiples shardings válidos: replicar tanto A como B y computar resultados parciales (comunicación antes de computación), fragmentar B por columnas y recopilar resultados (comunicación después de computación), o fragmentar A por filas y B por columnas sin comunicación pero con matrices más pequeñas por dispositivo.¹³⁵
Los costos de operaciones colectivas determinan estrategias óptimas. Los costos de all-reduce escalan linealmente con el tamaño del tensor pero sublinealmente con el conteo de dispositivos usando algoritmos de reducción basados en árbol o anillo:¹³⁶ All-gather y reduce-scatter exhiben diferentes propiedades de escalado. El compilador modela estos costos y selecciona estrategias de sharding que minimizan el tiempo total de comunicación.
El paralelismo de secuencia emerge como crítico para grandes modelos de lenguaje. Los mecanismos de atención crean cuellos de botella de memoria porque los caches key-value crecen con la longitud de secuencia y el tamaño del lote. Particionar a lo largo de la dimensión de secuencia distribuye la carga de memoria entre dispositivos mientras introduce comunicación solo para el cálculo de atención mismo.¹³⁷
El paralelismo de expertos maneja modelos Mixture-of-Experts (MoE) donde diferentes expertos procesan diferentes tokens. La estrategia de sharding replica capas compartidas en todos los dispositivos pero particiona expertos, enrutando cada token a su dispositivo experto designado.¹³⁸ El enrutamiento dinámico crea patrones de comunicación irregulares que desafían las operaciones colectivas tradicionales, requiriendo sistemas de tiempo de ejecución sofisticados para minimizar latencia y desbalance de carga.
El sharding del estado del optimizador reduce la sobrecarga de memoria para modelos grandes. Los optimizadores como Adam almacenan estadísticas de momentum y varianza para cada parámetro, lo que triplica los requerimientos de memoria más allá de los parámetros solos. Fragmentar estados de optimizador entre dispositivos mientras se mantienen parámetros replicados permite entrenar modelos más grandes dentro de presupuestos fijos de memoria.¹³⁹ La estrategia requiere recopilar actualizaciones de estado del optimizador durante cálculos de pesos pero reduce sustancialmente la huella de memoria por dispositivo.
Análisis de Rendimiento y Benchmarking
Resultados de MLPerf y Posicionamiento Competitivo
MLPerf proporciona benchmarks estándar de la industria que miden el rendimiento de aceleradores de AI a través de cargas de trabajo de entrenamiento e inferencia. Google envía regularmente resultados de TPU demostrando rendimiento competitivo, y la evolución entre generaciones muestra mejoras arquitectónicas claras.¹⁴⁰
TPU v5e logró resultados líderes en 8 de 9 categorías de entrenamiento de MLPerf.¹⁴¹ La amplitud demuestra versatilidad arquitectónica más allá de solo modelos de lenguaje grandes—rendimiento competitivo a través de cargas de trabajo de visión por computadora, sistemas de recomendación y computación científica. El entrenamiento de BERT se completó 2.8× más rápido que las GPU NVIDIA A100, validando la arquitectura optimizada para transformers.¹⁴²
MLPerf Training v5.0, anunciado en junio de 2025, introdujo un benchmark de Llama 3.1 405B representando el modelo más grande en la suite.¹⁴³ El benchmark pone a prueba el escalado multi-nodo, la sobrecarga de comunicación y la capacidad de memoria más que pruebas anteriores. Google Cloud participó con envíos de TPU, aunque las comparaciones de rendimiento detalladas permanecen bajo embargo pendiente de la publicación de resultados oficiales.
MLPerf Inference v5.0 incluyó cuatro nuevos benchmarks: Llama 3.1 405B, Llama 2 70B para aplicaciones de baja latencia, redes neuronales de grafos RGAT, y PointPainting para detección de objetos 3D.¹⁴⁴ La diversidad empuja a los aceleradores más allá de las cargas de trabajo de transformer convencionales hacia dominios de aplicación emergentes donde las suposiciones arquitectónicas pueden diferir.
Los benchmarks de inferencia favorecen particularmente las fortalezas arquitectónicas de TPU. Las cargas de trabajo de inferencia por lotes aprovechan el paralelismo masivo del MXU, logrando 4× mayor throughput que aceleradores competidores para el servicio de transformers.¹⁴⁵ La latencia de consulta única se beneficia de la ejecución determinística de TPU y la ausencia de throttling térmico, entregando latencia consistente sin la varianza de rendimiento que afecta algunos despliegues de GPU.
Las métricas de eficiencia energética muestran ventajas de TPU expandiéndose a través de generaciones. TPU v4 demostró 2.7× mejor rendimiento por watt que TPU v3, y Trillium mejoró 67% sobre v5e.¹⁴⁶ Ironwood afirma 2× mejor rendimiento por watt que Trillium a pesar de un rendimiento absoluto significativamente mayor.¹⁴⁷ Las ganancias de eficiencia se acumulan a través de pods de mil chips, traduciéndose en millones de dólares en costos operacionales de datacenter.
Rendimiento Real de Entrenamiento e Inferencia
Las cargas de trabajo de producción revelan características de rendimiento ausentes de benchmarks sintéticos. Google publica resultados de servicios internos demostrando el comportamiento de TPU bajo patrones de uso real y requisitos de escalado.¹⁴⁸
El entrenamiento de ResNet-50 ImageNet se completa en 28 minutos en pods de TPU, un benchmark ampliamente citado para el rendimiento de cargas de trabajo de visión por computadora.¹⁴⁹ La métrica de tiempo a precisión captura el proceso completo de entrenamiento, incluyendo carga de datos, aumento, sincronización de gradientes distribuidos y guardado de checkpoints—no solo FLOPs teóricos.
El entrenamiento del modelo de lenguaje T5-3B demuestra ventajas de TPU en arquitecturas de transformer. El modelo de 3 mil millones de parámetros entrena en 12 horas en pods de TPU, comparado con 31 horas en configuraciones equivalentes de GPU.¹⁵⁰ La aceleración de 2.6× proviene de operaciones de atención aceleradas por hardware, utilización eficiente de ancho de banda de memoria y comunicaciones colectivas optimizadas.
Las cargas de trabajo a escala GPT-3 (175B parámetros) logran 1.7× tiempo más rápido a precisión en TPUs que en GPUs contemporáneas.¹⁵¹ La brecha de rendimiento se amplía para modelos aún más grandes, donde la capacidad y ancho de banda de memoria se vuelven restricciones críticas. Los 192GB HBM3e de Ironwood permiten servir modelos que requieren paralelismo de tensores complejo en alternativas de menor memoria.
Las mediciones de eficiencia de escalado demuestran aceleración casi lineal a escalas enormes. Google Research reportó 95% de eficiencia de escalado a 32,768 TPUs para cargas de trabajo específicas de entrenamiento de transformers.¹⁵² La métrica significa que 32,768 TPUs entregaron 95% del rendimiento que el escalado lineal perfecto predecirían—notable dado que la sobrecarga de comunicación aumenta con la escala.
Las métricas de utilización de FLOPS revelan cuán efectivamente las cargas de trabajo aprovechan el cómputo disponible. Los modelos de transformer típicamente logran 90% de utilización de FLOPS en TPUs, significando que 90% del rendimiento pico teórico se traduce en trabajo real.¹⁵³ La alta utilización proviene de la fusión de operaciones eliminando cuellos de botella de memoria, eficiencia del arreglo sistólico en multiplicaciones de matrices grandes y optimizaciones del compilador que minimizan ciclos desperdiciados.
Los servicios de inferencia de producción demuestran rendimiento sostenido a través de miles de millones de consultas por día. Google Translate procesa 1 mil millones de solicitudes diariamente en TPUs.¹⁵⁴ Las recomendaciones de YouTube sirven 2 mil millones de usuarios usando modelos acelerados por TPU.¹⁵⁵ Google Photos analiza 28 mil millones de imágenes mensualmente para características de búsqueda y organización.¹⁵⁶ La escala operacional valida confiabilidad y costo-eficiencia más allá de despliegues de prototipos de investigación.
Eficiencia Energética y Costo Total de Propiedad
El consumo de energía impacta directamente los costos operacionales del data center y la sostenibilidad ambiental. Las mejoras de eficiencia energética de TPU a través de generaciones reducen tanto los gastos operacionales como las emisiones de carbono a escala.¹⁵⁷
TPU v4 promedió solo 200W de consumo de energía en cargas de trabajo de producción a pesar de una especificación TDP de 250W.¹⁵⁸ El margen entre la energía promedio y pico permite diseño térmico flexible y aprovisionamiento. Contrasta con GPUs, donde las cargas de trabajo sostenidas a menudo alcanzan límites TDP, requiriendo presupuestos de energía de rack conservadores.
El TDP de 600W de Ironwood representa energía absoluta mayor que generaciones anteriores pero entrega dramáticamente más cómputo por watt.¹⁵⁹ El rendimiento FP8 de 4.6 PFLOPS por chip produce aproximadamente 7.7 TFLOPS por watt—competitivo con o excediendo la eficiencia de GPU contemporánea en cargas de trabajo equivalentes.
La efectividad de uso de energía del datacenter (PUE) amplifica la eficiencia a nivel de chip. Los data centers de TPU de Google logran un PUE de 1.1, significando solo 10% de sobrecarga de energía más allá del consumo del chip para enfriamiento, conversión de energía y networking.¹⁶⁰ El PUE promedio de la industria varía de 1.5 a 2.0, donde 50-100% de energía adicional va a sobrecarga de infraestructura. El bajo PUE proviene de sistemas de enfriamiento avanzados, entrega de energía eficiente y diseño deliberado de datacenter optimizando para cargas de trabajo de ML.
Las consideraciones de intensidad de carbono se extienden más allá de la energía para incluir fuentes de energía. Google opera datacenters de TPU con energía carbono-neutral a través de adquisición de energía renovable y programas de compensación de carbono.¹⁶¹ La contabilidad de carbono importa cada vez más para organizaciones rastreando emisiones Scope 2 de cloud computing.
El análisis de costo total de propiedad (TCO) debe considerar costos de adquisición, consumo de energía, requisitos de enfriamiento y gastos de mantenimiento. Los despliegues de TPU comúnmente muestran reducciones de TCO del 20-30% comparado con instalaciones equivalentes de GPU, impulsadas principalmente por rendimiento superior por watt y complejidad de enfriamiento reducida.¹⁶²
Los costos de infraestructura de enfriamiento escalan no linealmente con la densidad de energía. Los racks enfriados por aire típicamente llegan al límite de 15-20kW por rack antes de requerir soluciones de enfriamiento exóticas. Las GPUs de alta energía empujan estos límites, a veces necesitando infraestructura de enfriamiento líquido con costos de capital y operacionales sustancialmente mayores. La eficiencia de TPU mantiene más despliegues dentro del rango de enfriamiento por aire, simplificando el diseño del datacenter.¹⁶³
Ventajas Técnicas: Donde Destacan los TPUs
Operaciones Colectivas Aceleradas por Hardware
El soporte especializado para operaciones colectivas en TPU ICI ofrece una de las ventajas más significativas sobre los aceleradores de red tradicionales. All-reduce, la operación fundamental para sincronizar gradientes a través de entrenamiento distribuido, se ejecuta 10× más rápido en TPU ICI que las implementaciones equivalentes basadas en Ethernet con GPU.¹⁶⁴
La brecha de rendimiento se origina en la integración arquitectónica. Las operaciones colectivas basadas en Ethernet atraviesan múltiples capas: el código de aplicación invoca la librería colectiva (NCCL, Horovod, etc.), que genera paquetes que se entregan al stack de red, que transfiere datos al NIC, que serializa en el cable, atraviesa switches, deserializa en los NICs receptores, y revierte el proceso. Cada capa añade latencia, copia datos a través de jerarquías de memoria, y consume ciclos de CPU para procesamiento de protocolos.¹⁶⁵
TPU ICI implementa operaciones colectivas en hardware sin atravesar la capa de software. La operación se inicia directamente desde el TensorCore, transmite datos sobre enlaces ICI dedicados, y se completa sin involucrar la CPU host. El camino directo de hardware elimina la sobrecarga que domina las implementaciones tradicionales.¹⁶⁶
La topología de conmutador de circuito óptico permite algoritmos colectivos óptimos. El all-reduce basado en anillo requiere solo 2(N-1) mensajes para N dispositivos, y la topología torus proporciona enrutamiento de camino más corto, minimizando la latencia.¹⁶⁷ El ancho de banda uniforme de bisección previene puntos calientes donde las operaciones colectivas mal enrutadas congestionan los enlaces de red.
Espacio de Memoria Unificado y Programación Simplificada
El modelo de memoria unificado del TPU simplifica la programación comparado con las jerarquías de memoria complejas de los GPUs. Los programadores razonan sobre un solo pool HBM en lugar de gestionar transferencias entre RAM host, memoria global GPU, memoria compartida, y archivos de registro. El modelo simplificado reduce errores y permite una velocidad de desarrollo más rápida.¹⁶⁸
La fragmentación de memoria desaparece como preocupación. Los GPUs asignan memoria desde un heap fragmentado, donde las asignaciones y desasignaciones a lo largo del tiempo crean huecos que requieren compactación. La gestión de memoria TPU a través del análisis estático del compilador evita la fragmentación en tiempo de ejecución completamente—los tensores se asignan ubicaciones predeterminadas basadas en el grafo de computación.¹⁶⁹
El modelo de programación elimina clases enteras de errores CUDA. No más "acceso ilegal a memoria" por aritmética de punteros incorrecta, no hay errores de coherencia de caché entre CPU y GPU, no hay errores de sincronización por llamadas faltantes a cudaDeviceSynchronize(). La abstracción de nivel superior previene las trampas comunes en la programación CUDA.¹⁷⁰
Ejecución Determinística y Reproducibilidad
La no-asociatividad de punto flotante crea desafíos de reproducibilidad en computación paralela. La expresión (a + b) + c puede producir resultados diferentes que a + (b + c) debido a errores de redondeo, y las reducciones paralelas pueden sumar en diferentes órdenes a través de ejecuciones dependiendo de condiciones de carrera.¹⁷¹
La ejecución TPU exhibe determinismo más fuerte que las implementaciones típicas de GPU. El patrón de flujo de datos fijo del array sistólico asegura ordenamiento idéntico de operaciones a través de ejecuciones. Las operaciones colectivas siguen árboles de reducción determinísticos en lugar de agregación oportunista basada en orden de llegada. La predictibilidad permite entrenamiento reproducible donde hiperparámetros y datos idénticos producen pesos de modelo bit-idénticos.¹⁷²
La depuración se beneficia enormemente del determinismo. El entrenamiento no determinístico hace casi imposible encontrar la causa raíz de fallas—¿es el NaN de un error algorítmico genuino o condición de carrera aleatoria? La ejecución determinística significa que las fallas se reproducen confiablemente, permitiendo enfoques de depuración sistemáticos.¹⁷³
Las aplicaciones de computación científica valoran particularmente la reproducibilidad. Modelos climáticos, simulaciones de descubrimiento de medicamentos, e investigación de física requieren resultados verificables que permitan a diferentes investigadores reproducir resultados idénticos. El determinismo del TPU apoya mejor el método científico que las alternativas no determinísticas competidoras.¹⁷⁴
Optimizaciones del Compilador y Productividad del Desarrollador
La optimización agresiva de XLA entrega mejoras sustanciales de rendimiento "desde el primer momento" sin ajuste manual. Los investigadores reportan mejoras del 40% en throughput de modelo solo por compilación comparado con frameworks de ejecución inmediata.¹⁷⁵ El rendimiento viene gratis—no se requiere ingeniería de kernels.
La optimización de fusión beneficia particularmente a los desarrolladores. Fusionar operaciones manualmente en CUDA requiere escribir kernels personalizados, probar corrección, y mantener el código a través de versiones de framework. XLA automáticamente fusiona operaciones y actualiza, y adapta estrategias de fusión mientras los modelos evolucionan, eliminando la carga de mantenimiento.¹⁷⁶
La automatización de transformación de layout ahorra semanas de optimización manual. Determinar layouts óptimos de tensores para GPU requiere perfilar diferentes arreglos, insertar transpuestas manualmente, y gestionar cuidadosamente patrones de asignación de memoria. XLA prueba layouts automáticamente y selecciona el más rápido, liberando a los desarrolladores para enfocarse en arquitectura de modelo en lugar de ingeniería de rendimiento de bajo nivel.¹⁷⁷
La ganancia de productividad se compone para equipos de investigación. El tiempo ahorrado en optimización de infraestructura acelera el progreso científico, permitiendo más experimentos y ciclos de iteración más rápidos. Las organizaciones reportan mejoras de velocidad de desarrollo de 3× al moverse de programación GPU CUDA a flujos de trabajo basados en TPU JAX.¹⁷⁸
Limitaciones Técnicas y Desventajas
Dependencia de Plataforma y Restricciones On-Premises
El acceso a TPU está disponible exclusivamente a través de Google Cloud Platform, impidiendo el despliegue on-premises y generando preocupaciones sobre dependencia del proveedor.¹⁷⁹ Las organizaciones con requisitos de soberanía de datos, redes aisladas o políticas contra la nube pública no pueden aprovechar TPU independientemente de la superioridad técnica.
Esta restricción importa cada vez más a medida que la AI se convierte en infraestructura crítica. La dependencia de un único proveedor de nube crea riesgos de continuidad del negocio: cambios de precios, interrupciones de disponibilidad o descontinuación del servicio podrían forzar migraciones costosas.¹⁸⁰ La disponibilidad de GPU de múltiples proveedores (hardware NVIDIA ejecutándose en AWS, Azure, GCP y on-prem) proporciona opciones que TPU excluye arquitectónicamente.
Las estrategias multi-cloud encuentran fricción. Las organizaciones que se estandarizan en TPU no pueden expandirse fácilmente a otras nubes o implementar redundancia multi-cloud sin reentrenar modelos o mantener bases de código separadas para diferentes arquitecturas de aceleradores.¹⁸¹ La complejidad operacional de despliegues híbridos GPU/TPU a menudo supera los ahorros de costo de la selección óptima de aceleradores.
Brecha de Madurez del Ecosistema CUDA
La plataforma CUDA de NVIDIA ha acumulado más de 15 años de desarrollo de ecosistema, bibliotecas, documentación y conocimiento comunitario que TPU no puede igualar.¹⁸² La brecha de madurez se manifiesta en numerosos puntos problemáticos para la adopción de TPU.
La disponibilidad de bibliotecas favorece abrumadoramente a CUDA. Dominios especializados como gráficos computacionales, dinámica molecular, dinámica de fluidos computacional y genómica han acumulado miles de bibliotecas optimizadas para CUDA durante las últimas décadas. Los equivalentes de TPU a menudo no existen, requiriendo respaldo a CPU (que destruye el rendimiento) o meses de esfuerzo de portabilidad.¹⁸³
El soporte comunitario difiere por órdenes de magnitud. Stack Overflow contiene cientos de miles de preguntas sobre CUDA con respuestas detalladas; los repositorios de GitHub se cuentan por millones. Las charlas de conferencias, artículos académicos y posts de blogs se enfocan predominantemente en programación CUDA. Los programadores de TPU enfrentan recursos comparativamente escasos, ciclos de debugging más largos y menos expertos para consultar.¹⁸⁴
Los materiales educativos y tutoriales se enfocan abrumadoramente en CUDA. Los cursos universitarios enseñan programación de GPU usando CUDA. Los cursos en línea se enfocan en CUDA. El pipeline de talento produce muchos más ingenieros con experiencia en CUDA que expertos en TPU, creando desafíos de contratación y entrenamiento.¹⁸⁵
El desarrollo de kernels personalizados ejemplifica la brecha del ecosistema. Escribir kernels CUDA optimizados sigue siendo no trivial pero se beneficia de documentación extensa, herramientas de profiling y código de ejemplo. Pallas habilita kernels TPU personalizados, pero con herramientas menos maduras y una base de conocimiento más pequeña. La curva de aprendizaje desalienta todas excepto las optimizaciones más críticas para el rendimiento.¹⁸⁶
Especialización de Cargas de Trabajo y Restricciones de Flexibilidad
La arquitectura de TPU optimiza para patrones específicos de carga de trabajo, principalmente multiplicación densa de matrices con patrones de acceso regulares y tamaños de lote grandes. Las operaciones fuera del punto óptimo encuentran caídas de rendimiento.¹⁸⁷
Las formas dinámicas desafían los modelos de ejecución de TPU. El compilador XLA asume dimensiones fijas de tensores para optimización y generación de código. Los modelos con longitudes de secuencia variables, flujo de control dinámico o formas dependientes de datos requieren padding a tamaños máximos (desperdiciando cómputo y memoria) o recompilación para cada forma distinta (destruyendo el rendimiento).¹⁸⁸
Las operaciones dispersas reciben soporte limitado a pesar de SparseCore. La multiplicación matriz-matriz dispersa, una carga de trabajo común en computación científica y redes neuronales de grafos, carece de implementaciones eficientes en MXU o VPU. El SparseCore especializado maneja tablas de embedding pero no álgebra lineal dispersa general.¹⁸⁹
La inferencia de lotes pequeños subutiliza los recursos paralelos de TPU. El arreglo sistólico de 256×256 prospera en matrices grandes que llenan la grilla con trabajo productivo. La inferencia de consulta única deja la mayoría de MAC inactivos, produciendo latencia y costo por consulta peor que alternativas GPU optimizadas para escenarios de lote bajo.¹⁹⁰
Los patrones de computación irregulares derrotan la eficiencia del arreglo sistólico. Los algoritmos con ramificación impredecible, estructuras recursivas o acceso de memoria pointer-chasing exhiben bajo rendimiento en TPU porque el flujo de datos fijo no puede adaptarse al comportamiento dependiente del tiempo de ejecución.¹⁹¹
Las cargas de trabajo no-ML raramente se benefician de la aceleración TPU. Simulaciones científicas, codificación de video, verificación blockchain y renderizado todos ejecutan más rápido en la arquitectura más general de GPU a pesar del mayor pico de FLOPs de TPU para operaciones de matrices.¹⁹²
Brechas de Tooling de Debugging y Desarrollo
El ecosistema de NVIDIA incluye herramientas maduras de profiling (Nsight Systems, Nsight Compute, nvprof), debuggers (cuda-gdb) y frameworks de análisis que han sido refinados durante décadas. El tooling de TPU existe, pero se retrasa sustancialmente en sofisticación.¹⁹³
XProf proporciona profiling básico a través de integración con TensorBoard pero carece del acceso granular a contadores de hardware que exponen las herramientas de NVIDIA. Entender tasas de cache miss, ocupación, divergencia de warp o conflictos de bancos de memoria (todas métricas críticas de optimización de GPU) no tiene equivalente en TPU porque la arquitectura difiere fundamentalmente.¹⁹⁴
Los mensajes de error a menudo oscurecen las causas raíz. Los fallos de compilación XLA producen mensajes crípticos sobre desajustes de forma u operaciones no soportadas, sin orientación clara sobre resolución. Los errores CUDA, aunque infames por su falta de ayuda, se benefician de quince años de explicaciones de StackOverflow y conocimiento tribal.¹⁹⁵
El debugging de entrenamiento distribuido en pods multi-chip se acerca a la imposibilidad sin herramientas especializadas. Las condiciones de carrera, bugs de sincronización de gradientes y fallos de operaciones colectivas se manifiestan como errores no deterministas (irónicamente, a pesar de las ventajas de determinismo de TPU) que se reproducen inconsistentemente y resisten el diagnóstico sistemático.¹⁹⁶
El loop de iteración se extiende dolorosamente para modelos complejos. La recompilación para cambios de forma o modificaciones de arquitectura puede requerir minutos, congelando el desarrollo mientras el compilador trabaja. El modelo de ejecución eager de CUDA habilita iteración más rápida a pesar del menor rendimiento pico.¹⁹⁷
Despliegues en el Mundo Real: Producción a Escala
Anthropic Claude: Estrategia Multiplataforma
El anuncio de Anthropic en octubre de 2025 sobre el despliegue de más de un millón de chips TPU representa el compromiso de aceleradores de AI más grande divulgado públicamente en la historia.¹⁹⁸ La empresa planea acceder a más de un gigavatio de capacidad de cómputo que entrará en funcionamiento en 2026 exclusivamente para entrenar y servir futuros modelos Claude.
La escala empequeñece despliegues anteriores por órdenes de magnitud. Un millón de chips, configurados como TPUs Ironwood, entregarían aproximadamente 4.6 exaflops de cómputo FP8—más de 40× el rendimiento total de toda la lista Top500 de supercomputadoras de apenas cinco años antes.¹⁹⁹ El compromiso señala confianza en la arquitectura TPU para el desarrollo de modelos frontera a escalas previamente consideradas ciencia ficción.
Anthropic persigue una estrategia deliberada de hardware multiplataforma a través de los TPUs de Google, Trainium de Amazon y GPUs de NVIDIA.²⁰⁰ La diversificación proporciona seguro de capacidad, apalancamiento de precios y distribución geográfica. Claude sirve globalmente desde despliegues a través de las tres plataformas, con enrutamiento de solicitudes basado en disponibilidad de capacidad y requisitos de latencia regional.
El informe técnico postmortem de la empresa de agosto de 2025 reveló complejidades de despliegue a escala. Una configuración incorrecta en los servidores TPU de la API Claude causó errores de generación de tokens, ocasionalmente asignando probabilidades inesperadamente altas a caracteres tailandeses o chinos en prompts en inglés.²⁰¹ El incidente demostró que incluso errores simples se propagan de manera impredecible a través de sistemas que procesan miles de millones de tokens diariamente.
Un despliegue separado disparó un bug latente en el compilador XLA: TPU que afectaba Claude Haiku 3.5. El bug había existido sin detectar por meses hasta que una combinación específica de arquitectura de modelo y flag de compilador expuso el defecto.²⁰² El descubrimiento enfatiza que el despliegue en producción encuentra casos límite ausentes en entornos de desarrollo y staging.
Los ingenieros de Anthropic citaron la relación precio-rendimiento y eficiencia de TPU como criterios primarios de selección. Los beneficios económicos convincentes aceleran el desarrollo al permitir experimentos más grandes dentro de presupuestos fijos.²⁰³ entrenar modelos más grandes, explorar más configuraciones de hiperparámetros e iterar más rápido todo proviene de reducir costos por FLOP.
Google Gemini: Diseñado para TPU Desde el Inicio
Los modelos Gemini de Google entrenan y sirven exclusivamente en TPUs, con arquitectura y procedimientos de entrenamiento co-diseñados para características TPU desde el principio.²⁰⁴ El acoplamiento estrecho permite explotar optimizaciones específicas de TPU que los modelos multiplataforma no pueden aprovechar.
El despliegue de Gemini reportadamente usa 50,000 chips TPU v6e para entrenar y servir las variantes de modelo más significativas.²⁰⁵ Los pods enormes requieren orquestación sofisticada—programación de trabajos a través de miles de chips, coordinación de checkpoints para prevenir cuellos de botella, recuperación de fallos para minimizar trabajo perdido y monitoreo en tiempo real para identificar nodos degradados antes de que los fallos se propaguen.
Google entrenó Gemini 2.0 en TPUs Trillium, validando la arquitectura de sexta generación para desarrollo de modelos frontera.²⁰⁶ La ejecución de entrenamiento demostró eficiencia de escalado a conteos de chips sin precedentes, logrando escalado fuerte más allá de mesetas típicas donde la sobrecarga de comunicación domina.
La infraestructura de servicio de modelos específicamente aprovecha optimizaciones de inferencia TPU. El procesamiento por lotes agrega múltiples solicitudes de usuarios para maximizar la utilización MXU. La gestión de caché clave-valor aprovecha la capacidad HBM, permitiendo procesamiento de contexto de larga duración sin intercambio de disco. La arquitectura entrega tiempos de respuesta sub-segundo para consultas complejas mientras maneja volumen de solicitudes globales masivo.²⁰⁷
Los sistemas de monitoreo de producción rastrean continuamente 50,000+ TPUs, detectando anomalías que podrían degradar la calidad del modelo o disponibilidad.²⁰⁸ La telemetría captura tasas de error, percentiles de latencia, rendimiento, presión de memoria y características térmicas a través de cada chip. Los modelos de machine learning analizan los flujos de telemetría mismos, prediciendo fallos antes de que ocurran y disparando mantenimiento preventivo.
Despliegues de Producción Adicionales
Midjourney migró de infraestructura GPU a TPU, logrando una reducción de costos del 65% y una mejora de latencia del 40% para cargas de trabajo de generación de imágenes.²⁰⁹ El servicio de generación de arte procesa 300,000 imágenes por minuto en carga pico, requiriendo rendimiento de cómputo masivo y performance consistente bajo patrones de tráfico con ráfagas.
Los modelos de lenguaje de Cohere en TPU lograron 3× el rendimiento de despliegues GPU previos.²¹⁰ La aceleración permitió servir más clientes desde la misma huella de infraestructura, mejorando directamente los beneficios del negocio. La empresa aprovechó las capacidades SPMD de JAX para paralelizar eficientemente modelos a través de pods TPU.
Snap aseguró capacidad para 10,000 chips TPU v6e que soportan características de realidad aumentada, sistemas de recomendación y herramientas de AI creativa.²¹¹ El despliegue abarca múltiples regiones geográficas, asegurando baja latencia para la base de usuarios global de Snapchat mientras mantiene consistencia de modelo a través de regiones.
Las instituciones académicas adoptan cada vez más TPU para investigación. El programa TPU Research Cloud (TRC) proporciona acceso TPU gratuito a investigadores, permitiendo experimentos a escalas previamente accesibles solo para laboratorios corporativos bien financiados.²¹² La democratización acelera el progreso científico al remover barreras de hardware para académicos investigando preguntas fundamentales sobre capacidades y limitaciones de AI.
Depuración, Profiling y Optimización del Rendimiento
Integración de XProf y TensorBoard
XProf constituye la herramienta principal de profiling para cargas de trabajo de TPU, proporcionando análisis de rendimiento para programas de JAX, PyTorch/XLA y TensorFlow en CPUs, GPUs y TPUs.²¹³ La herramienta se integra con TensorBoard para visualización, presentando datos de profiling a través de interfaces familiares que los ingenieros de ML ya comprenden.
La instalación requiere el plugin de TensorBoard: pip install tensorboard_plugin_profile tensorboard. Esto habilita la cadena de herramientas completa.²¹⁴ Ejecutar profiling en VMs de TPU implica capturar trazas durante entrenamiento o inferencia, subir los resultados a TensorBoard y analizar la visualización para identificar cuellos de botella.
La Página de Resumen proporciona métricas de resumen de rendimiento de alto nivel, incluyendo desglose de tiempo por paso, utilización del dispositivo e identificación de cuellos de botella de nivel superior.²¹⁵ La página destaca inmediatamente si las cargas de trabajo están limitadas por cómputo (MXU ejecutándose continuamente), limitadas por memoria (esperando transferencias HBM) o limitadas por comunicación (bloqueadas en operaciones colectivas).
Visor de Trazas y Análisis de Línea de Tiempo
El Visor de Trazas muestra visualizaciones detalladas de línea de tiempo que muestran exactamente cuándo se ejecutan las operaciones, cuándo ocurren las transferencias de datos y dónde se acumula el tiempo inactivo.²¹⁶ La interfaz basada en Chrome permite hacer zoom hasta resolución de microsegundos, revelando comportamiento de programación preciso que las métricas agregadas oscurecen.
Comprender la traza requiere reconocer patrones comunes. Los largos intervalos entre operaciones indican sobrecarga de compilación, cuellos de botella en la carga de datos o sobrecarga de Python debido a pipelines de datos mal optimizados. Las operaciones pequeñas repetidas sugieren fusión insuficiente. Las operaciones colectivas que duran milisegundos apuntan a ineficiencias de comunicación o estrategias de fragmentación deficientes.²¹⁷
La codificación por colores distingue tipos de operaciones: verde para cómputo, azul para transferencias de memoria, naranja para comunicación y rojo para tiempo inactivo. Las cargas de trabajo optimizadas muestran bloques coloreados densamente empacados con mínimos espacios rojos. El código mal optimizado exhibe líneas de tiempo dispersas con largas extensiones rojas indicando recursos desperdiciados.²¹⁸
El uso avanzado implica correlacionar el comportamiento de la línea de tiempo con el código fuente. PyTorch/XLA soporta anotaciones de usuario insertadas en el código que aparecen en las trazas, permitiendo mapear el comportamiento del rendimiento a componentes específicos del modelo.²¹⁹ Las anotaciones transforman trazas opacas en insights accionables sobre qué capas u operaciones necesitan foco de optimización.
Herramienta de Perfil de Memoria y Depuración de OOM
Los errores de falta de memoria (OOM) afligen el desarrollo de modelos grandes. La Herramienta de Perfil de Memoria monitorea el uso de memoria del dispositivo durante la ejecución, capturando la utilización pico y los patrones de asignación que llevan a fallas OOM.²²⁰
La herramienta visualiza el consumo de memoria a lo largo del tiempo, mostrando qué tensores consumen más capacidad y cuándo ocurre el uso pico. La visualización a menudo revela asignaciones sorprendentes—buffers de gradiente más grandes de lo esperado, memoria de activación que debería usar checkpoint, o tensores temporales que XLA falló en eliminar.²²¹
La estrategia de depuración implica reducir iterativamente la huella de memoria a través de múltiples técnicas. El checkpointing de gradientes recomputa activaciones durante pases hacia atrás en lugar de almacenarlas. La fragmentación del estado del optimizador distribuye el momentum y la varianza de Adam entre dispositivos. La precisión mixta reduce la memoria en 2× comparado con FP32. El microbatching procesa lotes más pequeños secuencialmente en lugar de un lote grande.²²²
La optimización avanzada de memoria requiere comprender las decisiones del compilador. La bandera xla_dump_to exporta representaciones intermedias mostrando cómo XLA transformó el grafo de computación. Analizar el IR revela si la fusión tuvo éxito, dónde ocurren copias innecesarias y qué operaciones asignan más memoria de lo esperado.²²³
Analizador de Pipeline de Entrada
El preprocesamiento de CPU frecuentemente crea cuellos de botella en el entrenamiento de TPU. El Analizador de Pipeline de Entrada identifica si la carga de datos mantiene el ritmo con el consumo del acelerador o si las TPUs permanecen inactivas esperando lotes.²²⁴
La herramienta separa el análisis del lado host (preprocesamiento de CPU, aumento de datos, ensamblaje de lotes) de la ejecución del lado dispositivo (computación real de TPU). Las cargas de trabajo limitadas por entrada muestran la utilización del dispositivo cayendo durante la carga de datos mientras la utilización de CPU alcanza picos. Las cargas de trabajo limitadas por cómputo mantienen alta utilización del dispositivo con CPU manteniendo cómodamente el ritmo.²²⁵
Las estrategias de optimización dependen de la ubicación del cuello de botella. El preprocesamiento lento del host se beneficia de paralelizar la carga de datos a través de más núcleos de CPU, reducir la complejidad de aumento por muestra, o hacer prefetch de lotes antes del consumo. Los cuellos de botella del lado dispositivo requieren cambios en la arquitectura del modelo, mejor fusión o ajustes de fragmentación en lugar de ajuste del pipeline de datos.²²⁶
## El Futuro de las Unidades de Procesamiento Tensorial
La evolución arquitectónica de siete generaciones de Google demuestra innovación continua en aceleradores especializados de AI. El soporte FP8 de Ironwood, su capacidad masiva de memoria y el escalado de superpod de 9,216 chips sugieren trayectorias para el desarrollo futuro.²²⁷
La reducción de precisión probablemente continuará hacia FP4 o incluso menor para operaciones específicas. La investigación emergente demuestra que muchas operaciones de redes neuronales toleran cuantización extrema con procedimientos de entrenamiento cuidadosos. Los TPUs futuros podrían implementar sistemas de precisión mixta con pases hacia adelante FP4, pases hacia atrás FP8 y actualizaciones de optimizador FP32.²²⁸
La capacidad de memoria compite contra el crecimiento del tamaño de los modelos. Los modelos de frontera actuales ya tensionan la memoria del acelerador, requiriendo estrategias sofisticadas de paralelismo. Los TPUs de próxima generación podrían integrar tecnologías de memoria no volátil como 3D XPoint o RAM resistiva, habilitando memoria en paquete a escala de terabytes sin el consumo de energía de DRAM.²²⁹
Las interconexiones ópticas podrían extenderse más allá del conmutador de circuitos para incluir elementos de computación óptica. La investigación explora multiplicación de matrices fotónica ejecutada a velocidad de luz con potencia mínima, potencialmente aumentando los arreglos sistólicos electrónicos con co-procesadores ópticos para operaciones específicas.²³⁰
El soporte de dispersión probablemente se expandirá más allá de embeddings hacia álgebra lineal dispersa general. Las técnicas de poda de redes neuronales demuestran que más del 90% de los pesos pueden ser puestos a cero sin pérdida de calidad. Las arquitecturas futuras podrían saltarse nativamente las computaciones de valor cero en lugar de explícitamente computarlas y descartarlas.²³¹
Los principios arquitectónicos subyacentes al éxito de TPU—especialización de dominio, interconexión personalizada, stacks de software co-diseñados y orquestación a escala de edificio—apuntan hacia un futuro de aceleradores cada vez más especializados. En lugar de procesadores que sirven para todo, podríamos ver aceleradores optimizados para entrenamiento versus inferencia, redes convolucionales versus transformers, modelos densos versus dispersos, y secuencias cortas versus largas.²³²
Los ingenieros que construyen infraestructura de AI hoy deberían entender profundamente la arquitectura TPU. Ya sea desplegando en Google Cloud, compitiendo con Google en el mercado de aceleradores, o diseñando sistemas ML de próxima generación, los principios de diseño y compromisos encarnados en TPU revelan verdades fundamentales sobre lo que las cargas de trabajo de AI demandan del hardware. Las matemáticas de arreglo sistólico, el diseño de jerarquía de memoria, la topología de interconexión y las estrategias de optimización del compilador representan décadas de sabiduría acumulada aplicable mucho más allá del TPU mismo.
La tensión entre especialización y generalidad que define TPU versus GPU persistirá indefinidamente. Los TPUs sacrifican flexibilidad por eficiencia extrema en cargas de trabajo estrechas. Los GPUs sacrifican eficiencia pico por aplicabilidad más amplia. Ningún enfoque domina—la elección óptima depende enteramente de características de carga de trabajo, escala, restricciones de costo y requerimientos operacionales. Las organizaciones que tienen éxito con AI a escala adoptan estrategias heterogéneas cada vez más, emparejando arquitecturas de aceleradores con demandas de carga de trabajo en lugar de estandarizar en una sola plataforma.
El compromiso de un millón de chips de Anthropic con TPU demuestra que la arquitectura ha alcanzado madurez de producción en las escalas más altas. Los despliegues multi-gigavatio que entran en línea en 2026 entrenarán modelos empujando los límites de lo que AI puede lograr, y la infraestructura habilitando esos modelos encarna sofisticación de ingeniería que pocas organizaciones han igualado. Entender cómo 65,536 unidades de multiplicación-acumulación en un arreglo sistólico colaboran para entrenar modelos de frontera importa para cualquiera serio sobre el futuro de AI.
Referencias
-
Google Cloud Press Corner, "Anthropic to Expand Use of Google Cloud TPUs and Services," 23 de octubre de 2025, https://www.googlecloudpresscorner.com/2025-10-23-Anthropic-to-Expand-Use-of-Google-Cloud-TPUs-and-Services.
-
TrendForce, "Google Unveils 7th-Gen TPU Ironwood with 9,216-Chip Superpod, Taking Aim at NVIDIA," 7 de noviembre de 2025, https://www.trendforce.com/news/2025/11/07/news-google-unveils-7th-gen-tpu-ironwood-with-9216-chip-superpod-taking-aim-at-nvidia/.
-
Norman P. Jouppi et al., "TPU v4: An Optically Reconfigurable Supercomputer for Machine Learning with Hardware Support for Embeddings," en Proceedings of the 50th Annual International Symposium on Computer Architecture (2023), arXiv:2304.01433.
-
Anthropic, "Expanding our use of Google Cloud TPUs and Services," Anthropic News, octubre de 2025, https://www.anthropic.com/news/expanding-our-use-of-google-cloud-tpus-and-services.
-
Google Cloud Blog, "Quantifying the performance of the TPU, our first machine learning chip," abril de 2017, https://cloud.google.com/blog/products/gcp/quantifying-the-performance-of-the-tpu-our-first-machine-learning-chip.
-
Norman P. Jouppi et al., "In-Datacenter Performance Analysis of a Tensor Processing Unit," Proceedings of the 44th Annual International Symposium on Computer Architecture (2017), arXiv:1704.04760.
-
Jouppi et al., "In-Datacenter Performance Analysis."
-
Jouppi et al., "In-Datacenter Performance Analysis."
-
Jonathan Hui, "AI Chips: Google TPU," Medium, consultado en diciembre de 2025, https://jonathan-hui.medium.com/ai-chips-tpu-3fa0b2451a2d.
-
Wikipedia, "Bfloat16 floating-point format," consultado en diciembre de 2025, https://en.wikipedia.org/wiki/Bfloat16_floating-point_format.
-
Henry Ko, "TPU Deep Dive," blog personal, consultado en diciembre de 2025, https://henryhmko.github.io/posts/tpu/tpu.html.
-
Wikipedia, "Tensor Processing Unit," consultado en diciembre de 2025, https://en.wikipedia.org/wiki/Tensor_Processing_Unit.
-
Wikipedia, "Tensor Processing Unit."
-
Wikipedia, "Tensor Processing Unit."
-
Ko, "TPU Deep Dive."
-
Jouppi et al., "TPU v4: An Optically Reconfigurable Supercomputer."
-
Jouppi et al., "TPU v4: An Optically Reconfigurable Supercomputer."
-
Jouppi et al., "TPU v4: An Optically Reconfigurable Supercomputer."
-
Jouppi et al., "TPU v4: An Optically Reconfigurable Supercomputer."
-
OpenXLA Project, "A deep dive into SparseCore for Large Embedding Models (LEM)," consultado en diciembre de 2025, https://openxla.org/xla/sparsecore.
-
JAX Scaling Guide, "How to Think About TPUs," consultado en diciembre de 2025, https://jax-ml.github.io/scaling-book/tpus/.
-
JAX Scaling Guide, "How to Think About TPUs."
-
Ko, "TPU Deep Dive."
-
JAX Scaling Guide, "How to Think About TPUs."
-
Google Cloud Blog, "Introducing Trillium, sixth-generation TPUs," mayo de 2024, https://cloud.google.com/blog/products/compute/introducing-trillium-6th-gen-tpus.
-
Google Cloud Blog, "Introducing Trillium."
-
Google Cloud Blog, "Introducing Trillium."
-
Google Cloud Blog, "Introducing Trillium."
-
Google Cloud Blog, "Introducing Trillium."
-
Google Blog, "Ironwood: The first Google TPU for the age of inference," noviembre de 2025, https://blog.google/products/google-cloud/ironwood-tpu-age-of-inference/.
-
XPU.pub, "Google Adds FP8 to Ironwood TPU; Can It Beat Blackwell?" 16 de abril de 2025, https://xpu.pub/2025/04/16/google-ironwood/.
-
TrendForce, "Google Unveils 7th-Gen TPU Ironwood."
-
The Register, "Google's 7th-gen Ironwood TPUs promise 42 AI exaFLOPS pods," 10 de abril de 2025, https://www.theregister.com/2025/04/10/googles_7thgen_ironwood_tpus_debut/.
-
TrendForce, "Google Unveils 7th-Gen TPU Ironwood."
-
Ko, "TPU Deep Dive."
-
XPU.pub, "Google Adds FP8 to Ironwood TPU."
-
Google Cloud Press Corner, "Anthropic to Expand Use."
-
Telesens, "Understanding Matrix Multiplication on a Weight-Stationary Systolic Architecture," 30 de julio de 2018, https://telesens.co/2018/07/30/systolic-architectures/.
-
Telesens, "Understanding Matrix Multiplication."
-
Jouppi et al., "In-Datacenter Performance Analysis."
-
Telesens, "Understanding Matrix Multiplication."
-
CP Lu, "Should We All Embrace Systolic Arrays?" Medium, consultado en diciembre de 2025, https://cplu.medium.com/should-we-all-embrace-systolic-array-df3830f193dc.
-
Google Cloud Documentation, "TPU architecture," consultado en diciembre de 2025, https://docs.cloud.google.com/tpu/docs/system-architecture-tpu-vm.
-
Google Cloud Documentation, "TPU architecture."
-
Hui, "AI Chips: Google TPU."
-
Telnyx, "Architecture insights: MXU and TPU components," consultado en diciembre de 2025, https://telnyx.com/learn-ai/mxu-tpu.
-
Ko, "TPU Deep Dive."
-
Jouppi et al., "TPU v4: An Optically Reconfigurable Supercomputer."
-
SemiEngineering, "Tensor Processing Unit (TPU)," consultado en diciembre de 2025, https://semiengineering.com/knowledge_centers/integrated-circuit/ic-types/processors/tensor-processing-unit-tpu/.
-
TrendForce, "Google Unveils 7th-Gen TPU Ironwood."
-
SemiEngineering, "Tensor Processing Unit (TPU)."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Google Cloud Documentation, "Cloud TPU performance guide," consultado en diciembre de 2025, https://cloud.google.com/tpu/docs/performance-guide.
-
OpenXLA Project, "A deep dive into SparseCore."
-
OpenXLA Project, "A deep dive into SparseCore."
-
OpenXLA Project, "A deep dive into SparseCore."
-
Jouppi et al., "TPU v4: An Optically Reconfigurable Supercomputer."
-
OpenXLA Project, "A deep dive into SparseCore."
-
Jouppi et al., "TPU v4: An Optically Reconfigurable Supercomputer."
-
OpenXLA Project, "A deep dive into SparseCore."
-
JAX Scaling Guide, "How to Think About TPUs."
-
JAX Scaling Guide, "How to Think About TPUs."
-
JAX Scaling Guide, "How to Think About TPUs."
-
Ko, "TPU Deep Dive."
-
JAX Scaling Guide, "How to Think About TPUs."
-
JAX Scaling Guide, "How to Think About TPUs."
-
TrendForce, "Google Unveils 7th-Gen TPU Ironwood."
-
Ko, "TPU Deep Dive."
-
Anthropic, "Expanding our use of Google Cloud TPUs."
-
Jouppi et al., "TPU v4: An Optically Reconfigurable Supercomputer."
-
Jouppi et al., "TPU v4: An Optically Reconfigurable Supercomputer."
-
Jouppi et al., "TPU v4: An Optically Reconfigurable Supercomputer."
-
Jouppi et al., "TPU v4: An Optically Reconfigurable Supercomputer."
-
Ko, "TPU Deep Dive."
-
Jouppi et al., "TPU v4: An Optically Reconfigurable Supercomputer."
-
Leon Poutievski, "Mission Apollo: Landing Optical Circuit Switching at Datacenter Scale," LinkedIn, junio de 2022, https://www.linkedin.com/posts/leon-poutievski-8910a851_mission-apollo-landing-optical-circuit-switching-activity-6968472071534235649-cB4l.
-
Ko, "TPU Deep Dive."
-
Jouppi et al., "TPU v4: An Optically Reconfigurable Supercomputer."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Jouppi et al., "TPU v4: An Optically Reconfigurable Supercomputer."
-
JAX Scaling Guide, "How to Think About TPUs."
-
TrendForce, "Google Unveils 7th-Gen TPU Ironwood."
-
TrendForce, "Google Unveils 7th-Gen TPU Ironwood."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
OpenXLA Project, "XLA: Optimizing Compiler for Machine Learning," consultado en diciembre de 2025, https://openxla.org/xla.
-
Daniel Snider and Ruofan Liang, "Operator Fusion in XLA: Analysis and Evaluation," artículo académico, consultado en diciembre de 2025, https://danielsnider.ca/papers/Operator_Fusion_in_XLA_Analysis_and_Evaluation.pdf.
-
Snider and Liang, "Operator Fusion in XLA."
-
APXML, "Memory-Aware Data Layout Transformations (NCHW/NHWC)," consultado en diciembre de 2025, https://apxml.com/courses/compiler-runtime-optimization-ml/chapter-3-advanced-graph-level-optimizations/memory-aware-layout-transformations.
-
OpenXLA Project, "XLA."
-
PyTorch Documentation, "Pytorch/XLA Overview," consultado en diciembre de 2025, https://docs.pytorch.org/xla/master/learn/xla-overview.html.
-
OpenXLA Project, "A deep dive into SparseCore."
-
Mangpo Phothilimthana et al., "A Flexible Approach to Autotuning Multi-Pass Machine Learning Compilers," PACT 2021, consultado en diciembre de 2025, https://mangpo.net/papers/xla-autotuning-pact2021.pdf.
-
JAX Documentation, "Introduction to parallel programming," consultado en diciembre de 2025, https://docs.jax.dev/en/latest/sharded-computation.html.
-
GitHub, "jax-ml/jax: Composable transformations of Python+NumPy programs," consultado en diciembre de 2025, https://github.com/jax-ml/jax.
-
OpenXLA Project, "Shardy Guide for JAX Users," consultado en diciembre de 2025, https://openxla.org/shardy/getting_started_jax.
-
JAX Documentation, "Introduction to parallel programming."
-
OpenXLA Project, "Shardy Guide for JAX Users."
-
OpenXLA Project, "Shardy Guide for JAX Users."
-
JAX Documentation, "Introduction to parallel programming."
-
OpenXLA Project, "Shardy Guide for JAX Users."
-
PyTorch Documentation, "Pytorch/XLA Overview."
-
GitHub, "RFC: Evolving PyTorch/XLA for a more native experience on TPU," Issue #9684, consultado en diciembre de 2025, https://github.com/pytorch/xla/issues/9684.
-
Google Cloud Blog, "PyTorch/XLA 2.4 improves Pallas and adds 'eager mode,'" consultado en diciembre de 2025, https://cloud.google.com/blog/products/ai-machine-learning/pytorch-xla-2-4-improves-pallas-and-adds-eager-mode/.
-
PyTorch Documentation, "Pytorch/XLA Overview."
-
PyTorch Documentation, "Custom Kernels via Pallas," consultado en diciembre de 2025, https://docs.pytorch.org/xla/master/features/pallas.html.
-
PyTorch Documentation, "Custom Kernels via Pallas."
-
PyTorch Documentation, "Custom Kernels via Pallas."
-
vLLM Blog, "vLLM TPU: A New Unified Backend Supporting PyTorch and JAX on TPU," 16 de octubre de 2025, https://blog.vllm.ai/2025/10/16/vllm-tpu.html.
-
GitHub, "pytorch/xla," consultado en diciembre de 2025, https://github.com/pytorch/xla.
-
StackGpu, "FP8, BF16, and INT8: How Low-Precision Formats Are Revolutionizing Deep Learning Throughput," Medium, consultado en diciembre de 2025, https://medium.com/@StackGpu/fp8-bf16-and-int8-how-low-precision-formats-are-revolutionizing-deep-learning-throughput-e6c1f3adabc2.
-
Wikipedia, "Bfloat16 floating-point format."
-
Wikipedia, "Bfloat16 floating-point format."
-
Paulius Micikevicius et al., "FP8 Formats for Deep Learning," arXiv:2209.05433, septiembre de 2022.
-
XPU.pub, "Google Adds FP8 to Ironwood TPU."
-
Micikevicius et al., "FP8 Formats for Deep Learning."
-
Google Cloud Blog, "Accurate Quantized Training (AQT) for TPU v5e," consultado en diciembre de 2025, https://cloud.google.com/blog/products/compute/accurate-quantized-training-aqt-for-tpu-v5e.
-
StackGpu, "FP8, BF16, and INT8."
-
Jeffrey Tse, "Understanding the FP64, FP32, FP16, BFLOAT16, TF32, FP8 Formats," blog personal, 9 de diciembre de 2024, https://jeffreytse.net/computer/2024/12/09/understanding-the-fp64-fp32-fp16-bfloat16-tf32-fp8-formats.html.
-
PyTorch Blog, "PyTorch/XLA SPMD: Scale Up Model Training and Serving with Automatic Parallelization," consultado en diciembre de 2025, https://pytorch.org/blog/pytorch-xla-spmd/.
-
OpenXLA Project, "Shardy Guide for JAX Users."
-
JAX Documentation, "Introduction to parallel programming."
-
OpenXLA Project, "Shardy Guide for JAX Users."
-
Ko, "TPU Deep Dive."
-
JAX Documentation, "Introduction to parallel programming."
-
Anthropic, "Expanding our use of Google Cloud TPUs."
-
JAX Documentation, "Introduction to parallel programming."
-
JAX Documentation, "Introduction to parallel programming."
-
Adam Roberts et al., "Scaling Up Models and Data with t5x and seqio," arXiv:2203.17189, marzo de 2022.
-
Roberts et al., "Scaling Up Models and Data."
-
JAX Documentation, "Introduction to parallel programming."
-
JAX Documentation, "Introduction to parallel programming."
-
OpenXLA Project, "Shardy Guide for JAX Users."
-
Roberts et al., "Scaling Up Models and Data."
-
Roberts et al., "Scaling Up Models and Data."
-
Ko, "TPU Deep Dive."
-
MLCommons, "Benchmark MLPerf Training," consultado en diciembre de 2025, https://mlcommons.org/benchmarks/training/.
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
HPCwire, "MLPerf Training v5.0 Benchmark Results Reflect Rapid Growth in the Field of AI," junio de 2025, https://www.hpcwire.com/off-the-wire/mlperf-training-v5-0-benchmark-results-reflect-rapid-growth-in-the-field-of-ai/.
-
MLCommons, "MLCommons Releases New MLPerf Inference v5.0 Benchmark Results," abril de 2025, https://mlcommons.org/2025/04/mlperf-inference-v5-0-results/.
-
Ko, "TPU Deep Dive."
-
Google Cloud Blog, "TPU v4 enables performance, energy and CO2e efficiency gains," consultado en diciembre de 2025, https://cloud.google.com/blog/topics/systems/tpu-v4-enables-performance-energy-and-co2e-efficiency-gains.
-
TrendForce, "Google Unveils 7th-Gen TPU Ironwood."
-
Google Cloud Blog, "Quantifying the performance of the TPU."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Artech Digital, "Energy-Efficient GPU vs. TPU Allocation," consultado en diciembre de 2025, https://www.artech-digital.com/blog/energy-efficient-gpu-vs-tpu-allocation.
-
Wikipedia, "Tensor Processing Unit."
-
XPU.pub, "Google Adds FP8 to Ironwood TPU."
-
Ko, "TPU Deep Dive."
-
Google Cloud Blog, "TPU v4 enables performance, energy and CO2e efficiency gains."
-
ByteBridge, "GPU and TPU Comparative Analysis Report," Medium, consultado en diciembre de 2025, https://bytebridge.medium.com/gpu-and-tpu-comparative-analysis-report-a5268e4f0d2a.
-
ByteBridge, "GPU and TPU Comparative Analysis Report."
-
Anthropic, "Expanding our use of Google Cloud TPUs."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
DataCamp, "Understanding TPUs vs GPUs in AI: A Comprehensive Guide," consultado en diciembre de 2025, https://www.datacamp.com/blog/tpu-vs-gpu-ai.
-
Ko, "TPU Deep Dive."
-
DataCamp, "Understanding TPUs vs GPUs in AI."
-
Grigory Sapunov, "FP64, FP32, FP16, BFLOAT16, TF32, and other members of the ZOO," Medium, consultado en diciembre de 2025, https://moocaholic.medium.com/fp64-fp32-fp16-bfloat16-tf32-and-other-members-of-the-zoo-a1ca7897d407.
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Snider and Liang, "Operator Fusion in XLA."
-
APXML, "Memory-Aware Data Layout Transformations."
-
Google Cloud Blog, "How Lightricks trains video diffusion models at scale with JAX on TPU," consultado en diciembre de 2025, https://cloud.google.com/blog/products/media-entertainment/how-lightricks-trains-video-diffusion-models-at-scale-with-jax-on-tpu.
-
CloudOptimo, "TPU vs GPU: What's the Difference in 2025?" consultado en diciembre de 2025, https://www.cloudoptimo.com/blog/tpu-vs-gpu-what-is-the-difference-in-2025/.
-
Phoenix NAP, "TPU vs. GPU: Differences Explained," consultado en diciembre de 2025, https://phoenixnap.com/kb/tpu-vs-gpu.
-
CloudOptimo, "TPU vs GPU."
-
DataCamp, "Understanding TPUs vs GPUs in AI."
-
Tailscale, "TPU vs GPU: Which Is Better for AI Infrastructure in 2025?" consultado en diciembre de 2025, https://tailscale.com/learn/what-is-tpu-vs-gpu.
-
DataCamp, "Understanding TPUs vs GPUs in AI."
-
DataCamp, "Understanding TPUs vs GPUs in AI."
-
PyTorch Documentation, "Custom Kernels via Pallas."
-
Phoenix NAP, "TPU vs. GPU: Differences Explained."
-
Ko, "TPU Deep Dive."
-
OpenMetal, "TPU vs GPU: Pros and Cons," consultado en diciembre de 2025, https://openmetal.io/docs/product-guides/private-cloud/tpu-vs-gpu-pros-and-cons/.
-
OpenMetal, "TPU vs GPU: Pros and Cons."
-
Phoenix NAP, "TPU vs. GPU: Differences Explained."
-
PRIMO.ai, "Processing Units - CPU, GPU, APU, TPU, VPU, FPGA, QPU," consultado en diciembre de 2025, https://primo.ai/index.php?title=Processing_Units_-_CPU%2C_GPU%2C_APU%2C_TPU%2C_VPU%2C_FPGA%2C_QPU.
-
DataCamp, "Understanding TPUs vs GPUs in AI."
-
Google Cloud Documentation, "Profile your model on Cloud TPU VMs," consultado en diciembre de 2025, https://cloud.google.com/tpu/docs/cloud-tpu-tools.
-
DataCamp, "Understanding TPUs vs GPUs in AI."
-
Ko, "TPU Deep Dive."
-
GitHub, "RFC: Evolving PyTorch/XLA."
-
Google Cloud Press Corner, "Anthropic to Expand Use."
-
TrendForce, "Google Unveils 7th-Gen TPU Ironwood."
-
Maginative, "Anthropic Secures 1M Google TPUs While Keeping Amazon as Primary Training Partner," consultado en diciembre de 2025, https://www.maginative.com/article/anthropic-secures-1m-google-tpus-while-keeping-amazon-as-primary-training-partner/.
-
Anthropic, "A postmortem of three recent issues," Engineering Blog, agosto de 2025, https://www.anthropic.com/engineering/a-postmortem-of-three-recent-issues.
-
Anthropic, "A postmortem of three recent issues."
-
AI Magazine, "Why Anthropic Uses Google Cloud TPUs for AI Infrastructure," consultado en diciembre de 2025, https://aimagazine.com/news/why-anthropic-uses-google-cloud-tpus-for-ai-infrastructure.
-
Google Cloud Blog, "Ironwood TPUs and new Axion-based VMs for your AI workloads," noviembre de 2025, https://cloud.google.com/blog/products/compute/ironwood-tpus-and-new-axion-based-vms-for-your-ai-workloads.
-
Ko, "TPU Deep Dive."
-
TrendForce, "Google Unveils 7th-Gen TPU Ironwood."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Google Cloud, "Tensor Processing Units (TPUs)," consultado en diciembre de 2025, https://cloud.google.com/tpu.
-
TensorFlow Documentation, "Optimize TensorFlow performance using the Profiler," consultado en diciembre de 2025, https://www.tensorflow.org/guide/profiler.
-
Google Cloud Documentation, "Profile your model on Cloud TPU VMs."
-
TensorFlow Documentation, "TensorFlow Profiler: Profile model performance," consultado en diciembre de 2025, https://www.tensorflow.org/tensorboard/tensorboard_profiling_keras.
-
Google Cloud Documentation, "Profile your model on Cloud TPU VMs."
-
Google Cloud Blog, "PyTorch/XLA: Performance debugging on Cloud TPU VM: Part III," consultado en diciembre de 2025, https://cloud.google.com/blog/topics/developers-practitioners/pytorchxla-performance-debugging-cloud-tpu-vm-part-iii.
-
Google Cloud Blog, "PyTorch/XLA: Performance debugging Part III."
-
Google Cloud Documentation, "Profile PyTorch XLA workloads," consultado en diciembre de 2025, https://docs.cloud.google.com/tpu/docs/pytorch-xla-performance-profiling-tpu-vm.
-
TensorFlow Documentation, "Optimize TensorFlow performance using the Profiler."
-
TensorFlow Documentation, "Optimize TensorFlow performance using the Profiler."
-
Ko, "TPU Deep Dive."
-
Google Cloud Documentation, "Cloud TPU performance guide."
-
TensorFlow Documentation, "Optimize TensorFlow performance using the Profiler."
-
TensorFlow Documentation, "Optimize TensorFlow performance using the Profiler."
-
TensorFlow Documentation, "Optimize TensorFlow performance using the Profiler."
-
TrendForce, "Google Unveils 7th-Gen TPU Ironwood."
-
Tse, "Understanding the FP64, FP32, FP16, BFLOAT16, TF32, FP8 Formats."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."


