
Google의 Tensor Processing Unit은 여러분이 매일 상호작용하는 최첨단 AI 모델의 대부분을 구동하지만, 대부분의 엔지니어들은 놀랍게도 이들의 아키텍처에 익숙하지 않습니다. NVIDIA GPU가 개발자들의 관심을 지배하는 동안, TPU는 기존 GPU 인프라를 사용했다면 대부분의 조직을 파산시켰을 규모로 Gemini 2.0, Claude, 그리고 수십 개의 다른 최첨단 모델들을 조용히 훈련시키고 서빙하고 있습니다. Anthropic은 최근 미래의 Claude 모델을 훈련시키기 위해 100만 개 이상의 TPU 칩—1기가와트 이상의 컴퓨팅 용량을 나타내는—을 배포하기로 약속했습니다.¹ Google의 최신 Ironwood 세대는 9,216개 칩 superpod에 걸쳐 42.5 exaflops의 FP8 컴퓨팅을 제공하며, 이는 프로덕션 AI 인프라의 의미를 재정의하는 규모입니다.²
TPU 뒤에 숨은 기술적 정교함은 단순한 성능 지표를 훨씬 뛰어넘습니다. 이러한 프로세서들은 GPU와 근본적으로 다른 설계 철학을 구현하며, 범용 유연성을 행렬 곱셈과 텐서 연산의 극도의 특화로 교환합니다. TPU 아키텍처를 이해하는 엔지니어들은 사이클당 65,536개의 곱셈-누적 연산을 처리하는 256×256 systolic array를 활용하고, 임베딩 집약적 워크로드를 위한 3세대 SparseCore 가속기를 레버리지하며, 10나노초 미만으로 멀티 페타비트 데이터센터 토폴로지를 재구성하는 광학 회로 스위치를 프로그래밍할 수 있습니다.³ 이 아키텍처는 트랜지스터 레벨 설계 결정부터 빌딩 규모의 슈퍼컴퓨터 오케스트레이션까지 모든 것을 아우릅니다.
앞으로 다룰 기술적 내용은 신중한 주의가 필요합니다. 우리는 7세대에 걸친 TPU 진화를 살펴보고, systolic array 수학과 데이터플로우 패턴을 분석하며, SRAM 타일부터 HBM3e 채널까지의 메모리 계층구조를 탐구하고, 중간 표현 레벨에서의 XLA 컴파일러 최적화를 분석하며, 집합 연산이 동등한 Ethernet 기반 GPU 클러스터보다 10배 빠르게 실행되는 이유를 조사합니다.⁴ 여러분은 레지스터 레벨 사양, 사이클 정확도 성능 모델링, 그리고 TPU를 GPU보다 동시에 더 강력하면서도 더 제약적으로 만드는 아키텍처적 트레이드오프들을 접하게 될 것입니다. 여기서 다루는 깊이는 차세대 AI 인프라를 구축하는 엔지니어들과 현재 가속기들이 달성할 수 있는 것의 경계를 넓히는 연구자들에게 도움이 됩니다.
진화: 7세대 아키텍처 혁신
TPU v1: 추론 전용 특화 (2015)
Google은 2015년에 첫 번째 Tensor Processing Unit을 배포하여 중요한 문제를 해결했습니다: 신경망 추론 워크로드가 회사의 데이터센터 공간을 두 배로 늘릴 위험이 있었습니다.⁵ 엔지니어들은 TPU v1을 추론 전용으로 설계하여 훈련 기능을 완전히 제거하고 배포된 모델의 성능과 전력 효율성을 최대화했습니다. 이 칩은 256×256 시스톨릭 배열의 8비트 정수 곱셈-누적 유닛을 특징으로 하며, 단 28-40와트의 열 설계 전력으로 초당 92테라옵스를 제공했습니다.⁶
아키텍처는 극도의 미니멀리즘을 구현했습니다. 단일 Matrix Multiply Unit이 가중치 고정 데이터플로우를 통해 INT8 연산을 처리했는데, 여기서 가중치는 시스톨릭 배열에 고정되어 있고 활성화값이 그리드를 가로질러 수평으로 스트리밍됩니다. 부분합은 수직으로 전파되어 전체 행렬 곱셈에 대한 중간 메모리 쓰기를 제거합니다. PCIe를 통해 호스트 시스템에 연결된 이 칩은 외부 메모리로 DDR3 DRAM에 의존했으며, 전력 효율성을 위해 의도적으로 보수적인 700MHz에서 동작했습니다.⁷
성능 향상은 Google의 엔지니어들조차 놀라게 했습니다. TPU v1은 프로덕션 추론 워크로드에서 동시대의 CPU와 GPU에 비해 와트당 연산에서 30배에서 80배의 개선을 달성했습니다.⁸ 이 칩은 Google Search 순위 매기기, 일일 10억 요청을 처리하는 번역 서비스, 20억 사용자를 위한 YouTube 추천을 처리했습니다. 이 성공은 핵심 아키텍처적 통찰을 검증했습니다: 좁은 워크로드에 최적화된 전용 가속기가 범용 프로세서보다 차수 단위의 개선을 제공할 수 있다는 것입니다.
TPU v2: 대규모 훈련 활성화 (2017)
두 번째 세대는 TPU를 추론 전용 가속기에서 완전한 훈련 플랫폼으로 변화시켰습니다. Google은 부동소수점 연산을 중심으로 전체 아키텍처를 재설계하여 256×256 INT8 배열을 코어당 듀얼 128×128 bfloat16 곱셈-누적기로 교체했습니다.⁹ 각 칩은 코어당 8GB의 High Bandwidth Memory를 공유하는 두 개의 TensorCore를 포함했는데, 이는 신경망 훈련이 요구하는 대역폭을 제공한 DDR3에서의 대대적인 업그레이드였습니다.
bfloat16 정밀도는 TPU v2의 성공에 중요했습니다. 이 형식은 FP32와 동일한 8비트 지수 범위를 유지하면서 가수를 7비트로 줄여 메모리 대역폭 요구사항을 절반으로 줄이면서 훈련을 위한 동적 범위를 보존합니다.¹⁰ 엔지니어들은 감소된 가수 정밀도가 실제로 정규화의 한 형태로 작용하여 많은 모델에서 일반화를 개선하는 반면, 완전한 FP32 지수 범위는 FP16 훈련을 괴롭혔던 언더플로우와 오버플로우 문제를 방지한다고 관찰했습니다.
TPU v2를 진정으로 차별화시킨 아키텍처적 혁신은 Inter-Chip Interconnect (ICI)였습니다. 이전의 가속기들은 멀티칩 통신을 위해 Ethernet이나 InfiniBand를 필요로 했는데, 이는 지연시간과 대역폭 병목을 야기했습니다. Google은 각 TPU를 2D 토러스 토폴로지에서 4개의 이웃에 직접 연결하는 맞춤형 고속 양방향 링크를 설계했습니다.¹¹ 이 인터커넥트는 최대 256개 칩의 TPU v2 "pod"가 단일 논리 가속기로 기능할 수 있게 했으며, all-reduce와 같은 집합 연산이 네트워크 기반 대안보다 훨씬 빠르게 실행되었습니다.
TPU v3: 수냉식 성능 확장 (2018)
Google은 TPU v3에서 클록 속도와 코어 수를 공격적으로 증가시켜 칩당 420테라플롭스를 제공했는데, 이는 v2의 성능보다 두 배 이상이었습니다.¹² 증가된 전력 밀도는 극적인 아키텍처 변화를 강요했습니다: 액체 냉각. 각 TPU v3 pod는 수냉 인프라를 필요로 했는데, 이는 이전 세대와 대부분의 데이터센터 가속기의 공냉 설계에서 벗어난 것이었습니다.¹³
칩은 듀얼 128×128 MXU 아키텍처를 유지했지만 총 코어 수를 늘리고 메모리 대역폭을 개선했습니다. 각 TPU v3는 각각 두 개의 코어를 가진 네 개의 칩을 포함했고, 칩 전체에서 총 32GB의 HBM 메모리를 공유했습니다.¹⁴ 벡터 처리 유닛은 행렬 유닛에서만 훈련을 병목시키는 경우가 많은 활성화 함수, 정규화 연산, 그래디언트 계산에 대한 향상을 받았습니다.
배포는 v2와 동일한 2D 토러스 ICI 토폴로지를 사용하지만 링크당 대역폭을 증가시켜 2,048칩 pod로 확장되었습니다. Google은 v3 pod에서 점점 더 큰 모델을 훈련했고, 토러스 토폴로지의 감소된 네트워크 지름(임의의 두 칩 간 최대 거리가 N이 아닌 N/2로 스케일)이 데이터 병렬과 모델 병렬 훈련 전략 모두에서 통신 오버헤드를 최소화한다는 것을 발견했습니다.¹⁵
TPU v4: 광회로 스위칭 돌파구 (2021)
네 번째 세대는 원래 TPU 이후 Google의 가장 중요한 아키텍처적 도약을 나타냈습니다. 엔지니어들은 pod 규모를 4,096칩으로 늘리면서 인터커넥트를 위한 광회로 스위칭(OCS)을 도입했는데, 이는 텔레콤에서 차용한 기술로 데이터센터 규모의 ML 인프라에 혁명을 일으켰습니다.¹⁶
TPU v4의 코어 아키텍처는 향상된 벡터 및 스칼라 유닛과 함께 TensorCore당 4개의 128×128 MXU를 특징으로 했습니다. 각 TensorCore 쌍은 코어별 Vector Memory에 추가하여 128MB의 Common Memory를 공유했으며, 이를 통해 더 정교한 데이터 스테이징과 재사용 패턴이 가능했습니다.¹⁷ 칩 토폴로지는 2D에서 3D 토러스로 발전하여 각 TPU를 4개가 아닌 6개의 이웃에 연결함으로써 네트워크 지름을 더욱 줄이고 이등분 대역폭을 개선했습니다.
광회로 스위칭 시스템은 대규모 배포에 관한 모든 것을 바꾸었습니다. TPU 간의 고정 케이블링 대신, Google은 어떤 칩이 어떤 칩에 연결되는지 동적으로 재구성할 수 있는 프로그래밍 가능한 광스위치를 배포했습니다. MEMS(미세전자기계시스템) 미러가 물리적으로 광빔을 리다이렉트하여 임의의 TPU 쌍을 함께 패치하며, 광섬유 전송 시간 외에는 본질적으로 지연시간이 없습니다.¹⁸ 스위치는 10나노초 미만의 창에서 재구성되어 대부분의 네트워크 프로토콜 핸드셰이크보다 빠릅니다.
OCS 아키텍처는 이전에 불가능했던 기능을 가능하게 했습니다. Google은 광스위치를 적절히 프로그래밍하여 4칩에서 전체 4,096칩 pod까지 모든 크기의 "슬라이스"를 프로비저닝할 수 있었습니다. 실패한 칩은 전체 랙을 중단시키지 않고 원활하게 우회 라우팅될 수 있었습니다. 가장 놀랍게도, 서로 다른 데이터센터 위치의 물리적으로 먼 TPU들이 네트워크 토폴로지에서 논리적으로 인접할 수 있어 물리적 및 논리적 레이아웃을 완전히 분리했습니다.¹⁹
TPU v4는 또한 추천 시스템, 순위 모델, 그리고 대규모 어휘 임베딩을 가진 대형 언어 모델에서 매일 사용되는 임베딩 연산을 처리하기 위한 전문 프로세서인 SparseCore를 도입했습니다. SparseCore는 칩당 4개의 전용 프로세서를 특징으로 했으며, 각각 2.5MB의 스크래치패드 메모리와 희소 메모리 접근 패턴에 최적화된 데이터플로우를 가졌습니다.²⁰ 초대형 임베딩을 가진 모델은 전체 칩 다이 면적과 전력 예산의 단 5%를 사용하여 5-7배의 속도 향상을 달성했습니다.
TPU v5p와 v5e: 특화와 규모 (2022-2023)
Google은 다섯 번째 세대를 서로 다른 사용 사례를 대상으로 하는 두 개의 별개 제품으로 나누었습니다. TPU v5p는 대규모 훈련을 위한 최대 성능을 우선시했고, v5e는 비용 효과적인 추론과 작은 훈련 작업에 최적화되었습니다.²¹
TPU v5p는 8,960칩 pod에서 초당 약 4.45엑사플롭스를 달성하여 v4의 최대 pod 크기를 두 배 이상 늘렸습니다.²² 인터커넥트 대역폭은 칩당 4,800Gbps에 달했으며, 3D 토러스 토폴로지는 대규모 16×20×28 슈퍼pod에서 칩들을 연결했습니다. 광회로 스위칭 패브릭은 48개의 OCS 유닛에 걸쳐 13,824개의 광포트를 관리하여 완전한 v5p 슈퍼pod를 배선했으며, 이는 컴퓨팅 역사상 가장 큰 프로덕션 광스위칭 배포 중 하나를 나타냅니다.²³
TPU v5e는 다른 접근법을 택하여 공격적인 전력과 비용 목표를 달성하기 위해 코어 수와 클록 속도를 줄였습니다. 추론에 최적화된 칩은 두 개가 아닌 칩당 하나의 TPU 코어만을 포함했으며, 작은 pod 크기에 충분한 2D 토러스 토폴로지로 돌아갔습니다.²⁴ 아키텍처적 단순화로 Google은 절대 성능보다 달러당 성능이 덜 중요한 워크로드에서 v5e를 경쟁력 있게 가격을 책정할 수 있었습니다.
TPU v6e Trillium: 행렬 성능 4배 증가 (2024)
Trillium은 Matrix Multiply Unit을 128×128에서 256×256 곱셈-누적기로 확장하여 또 다른 아키텍처적 변곡점을 만들었습니다.²⁵ 더 큰 배열은 동일한 클록 속도에서 사이클당 FLOPS를 4배로 늘렸으며, 확장된 MXU와 증가된 클록 주파수의 조합을 통해 TPU v5e보다 4.7배의 피크 컴퓨트 성능을 제공했습니다.
메모리 서브시스템은 동등하게 극적인 업그레이드를 받았습니다. HBM 용량은 칩당 32GB로 두 배가 되었고, 차세대 HBM 채널로 대역폭이 두 배가 되었습니다.²⁶ Interchip Interconnect 대역폭도 마찬가지로 두 배가 되어 256 Trillium 칩의 pod가 컴퓨트와 통신 모두에 스트레스를 주는 모델에서 더 높은 처리량을 유지할 수 있게 했습니다.²⁷
Trillium은 순위 및 추천 워크로드에서 초대형 임베딩을 위한 향상된 기능을 갖춘 3세대 SparseCore 가속기를 특징으로 했습니다. 업데이트된 설계는 메모리 액세스 패턴을 개선하고 행렬 곱셈보다 임베딩 룩업이 지배적인 모델을 위해 SparseCores와 HBM 간의 적절한 대역폭을 증가시켰습니다.²⁸
상당한 성능 향상에도 불구하고 에너지 효율성은 v5e보다 67% 개선되었습니다.²⁹ Google은 고급 프로세스 노드, 낭비되는 작업을 줄이는 아키텍처 최적화, 그리고 동시에 칩의 모든 부분에 스트레스를 주지 않는 연산 중 사용되지 않는 유닛의 신중한 전력 게이팅을 통해 효율성 향상을 달성했습니다.
TPU v7 Ironwood: FP8 시대 (2025)
코드명 Ironwood인 Google의 7세대 TPU는 네이티브 FP8 지원으로 설계된 최초의 TPU이며 최첨단 훈련 성능을 유지하면서 "추론의 시대"에 특화된 최적화를 나타냅니다.³⁰ 각 Ironwood 칩은 4.6페타FLOPS의 조밀한 FP8 컴퓨트를 제공하여 NVIDIA의 경쟁 B200의 4.5페타FLOPS를 약간 초과하면서 600W의 열 설계 전력을 소모합니다.³¹
메모리 시스템은 칩당 192GB의 HBM3e 메모리로 확장되어 Trillium의 6배 용량이 되었고, 대역폭은 7.4TB/s에 달했습니다.³² 극적인 메모리 증가는 이전에 여러 가속기에 걸친 복잡한 텐서 병렬처리를 필요로 했던 키-값 캐시를 가진 초대형 모델 서빙을 가능하게 합니다. Google은 메모리 용량을 신흥 멀티모달 모델과 백만 토큰 창에 접근하는 긴 컨텍스트 애플리케이션을 지원하도록 특별히 설계했습니다.
Ironwood의 인터커넥트는 4개의 ICI 링크를 통해 9.6Tbps의 총 양방향 대역폭을 제공하여 칩당 1.2TB/s의 피크 대역폭으로 변환됩니다.³³ 아키텍처는 작은 배포를 위한 256칩 pod에서 42.5 FP8 엑사플롭스의 컴퓨트 파워를 제공하는 대규모 9,216칩 슈퍼pod까지 확장됩니다.³⁴ Google의 Jupiter 데이터센터 네트워크 기술은 이론적으로 단일 클러스터에서 최대 43개의 Ironwood 슈퍼pod를 지원할 수 있으며, 이는 거의 상상할 수 없는 규모의 컴퓨트를 나타내는 약 400,000개의 가속기입니다.³⁵
FP8 지원은 정밀도 전략의 근본적인 변화를 나타냅니다. 이전 TPU 세대들은 소프트웨어 기술을 사용하여 8비트 연산을 에뮬레이션했는데, 이는 오버헤드를 야기했습니다. Ironwood는 E4M3 (4비트 지수, 3비트 가수)와 E5M2 (5비트 지수, 2비트 가수) 형식을 모두 지원하는 네이티브 FP8 곱셈-누적 유닛을 구현합니다.³⁶ 듀얼 형식 지원은 정밀도가 덜 중요한 순전파를 위한 E4M3와 그래디언트 크기 유지가 훈련 불안정성을 방지하는 역전파를 위한 E5M2의 혼합을 가능하게 합니다.
2026년부터 100만 개 이상의 Ironwood 칩을 배포하겠다는 Anthropic의 약속은 아키텍처의 프로덕션 준비성을 보여줍니다. 이 회사는 Claude 모델 훈련과 서빙을 위해 독점적으로 1기가와트가 훨씬 넘는 TPU 용량을 활용할 계획인데, 이는 작은 도시에 전력을 공급할 수 있을 만큼의 전력입니다.³⁷ 이 규모는 가장 중요한 알려진 GPU 배포조차 왜소하게 만들며 프론티어 모델 개발을 위한 TPU 아키텍처에 대한 근본적인 투자를 나타냅니다.
현세대 빠른 참조
다음 표는 2025년 프로덕션 배포에 가장 관련성이 높은 3개의 현세대 TPU에 대한 스캔 가능한 사양을 제공합니다:
표 1: 핵심 컴퓨트 사양
[caption id="" align="alignnone" width="1386"] 사양TPU v5eTPU v5pTPU v6e (Trillium)TPU v7 (Ironwood) MXU 배열 크기 128×128 128×128 256×256 256×256 사이클당 MAC 16,384 16,384 65,536 65,536 피크 BF16 TFLOPS ~197 ~459 ~918 ~2,300 (추정) 피크 FP8 PFLOPS N/A (에뮬레이션) N/A (에뮬레이션) N/A (에뮬레이션) 4.6 네이티브 정밀도 BF16, INT8 BF16, INT8 BF16, INT8 BF16, FP8, INT8 칩당 TensorCore 1 2 1 1 [/caption]
사양TPU v5eTPU v5pTPU v6e (Trillium)TPU v7 (Ironwood) MXU 배열 크기 128×128 128×128 256×256 256×256 사이클당 MAC 16,384 16,384 65,536 65,536 피크 BF16 TFLOPS ~197 ~459 ~918 ~2,300 (추정) 피크 FP8 PFLOPS N/A (에뮬레이션) N/A (에뮬레이션) N/A (에뮬레이션) 4.6 네이티브 정밀도 BF16, INT8 BF16, INT8 BF16, INT8 BF16, FP8, INT8 칩당 TensorCore 1 2 1 1 [/caption]
표 2: 메모리 및 대역폭
[caption id="" align="alignnone" width="1380"]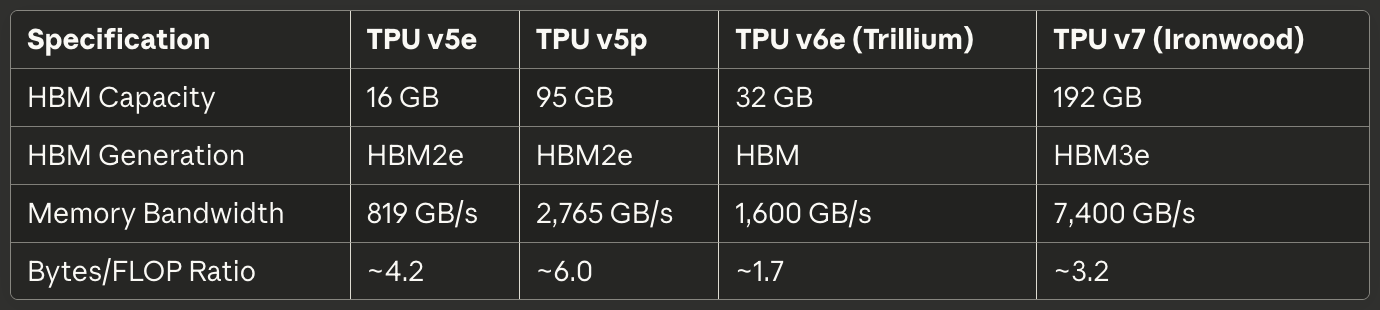 사양TPU v5eTPU v5pTPU v6e (Trillium)TPU v7 (Ironwood) HBM 용량 16 GB 95 GB 32 GB 192 GB HBM 세대 HBM2e HBM2e HBM HBM3e 메모리 대역폭 819 GB/s 2,765 GB/s 1,600 GB/s 7,400 GB/s 바이트/FLOP 비율 ~4.2 ~6.0 ~1.7 ~3.2 [/caption]
사양TPU v5eTPU v5pTPU v6e (Trillium)TPU v7 (Ironwood) HBM 용량 16 GB 95 GB 32 GB 192 GB HBM 세대 HBM2e HBM2e HBM HBM3e 메모리 대역폭 819 GB/s 2,765 GB/s 1,600 GB/s 7,400 GB/s 바이트/FLOP 비율 ~4.2 ~6.0 ~1.7 ~3.2 [/caption]
표 3: 인터커넥트 및 스케일링
[caption id="" align="alignnone" width="1384"]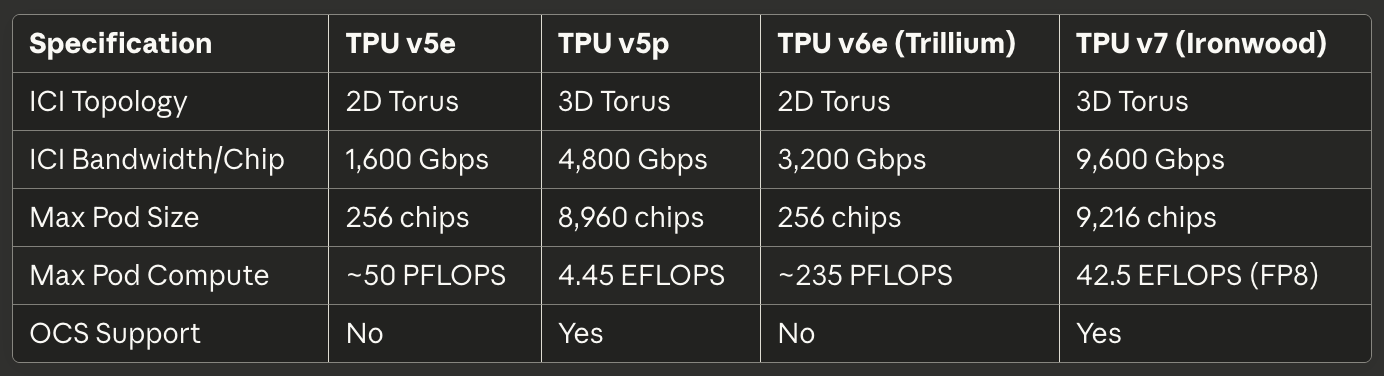 사양TPU v5eTPU v5pTPU v6e (Trillium)TPU v7 (Ironwood) ICI 토폴로지 2D Torus 3D Torus 2D Torus 3D Torus 칩당 ICI 대역폭 1,600 Gbps 4,800 Gbps 3,200 Gbps 9,600 Gbps 최대 Pod 크기 256칩 8,960칩 256칩 9,216칩 최대 Pod 컴퓨트 ~50 PFLOPS 4.45 EFLOPS ~235 PFLOPS 42.5 EFLOPS (FP8) OCS 지원 없음 있음 없음 있음 [/caption]
사양TPU v5eTPU v5pTPU v6e (Trillium)TPU v7 (Ironwood) ICI 토폴로지 2D Torus 3D Torus 2D Torus 3D Torus 칩당 ICI 대역폭 1,600 Gbps 4,800 Gbps 3,200 Gbps 9,600 Gbps 최대 Pod 크기 256칩 8,960칩 256칩 9,216칩 최대 Pod 컴퓨트 ~50 PFLOPS 4.45 EFLOPS ~235 PFLOPS 42.5 EFLOPS (FP8) OCS 지원 없음 있음 없음 있음 [/caption]
표 4: 전력 및 효율성
[caption id="" align="alignnone" width="1380"] 사양TPU v5eTPU v5pTPU v6e (Trillium)TPU v7 (Ironwood) TDP ~120-200W ~250-300W ~120-200W 600W 냉각 공냉 액냉 공냉 액냉 TFLOPS/와트 (BF16) ~1.0-1.6 ~1.5-1.8 ~4.6-7.7 ~3.8 이전 세대 대비 에너지 기준선 N/A v5e보다 67% 향상 Trillium보다 2배 향상 [/caption]
사양TPU v5eTPU v5pTPU v6e (Trillium)TPU v7 (Ironwood) TDP ~120-200W ~250-300W ~120-200W 600W 냉각 공냉 액냉 공냉 액냉 TFLOPS/와트 (BF16) ~1.0-1.6 ~1.5-1.8 ~4.6-7.7 ~3.8 이전 세대 대비 에너지 기준선 N/A v5e보다 67% 향상 Trillium보다 2배 향상 [/caption]
표 5: 권장 사용 사례
[caption id="" align="alignnone" width="1382"] 사용 사례 최적 선택 근거 비용 최적화 추론 TPU v5e: 추론 쿼리당 가장 낮은 비용 대규모 훈련 (>1000칩) TPU v5p 또는 Ironwood 3D torus + OCS가 대규모 pod 활성화 중간 훈련 작업 (256칩) TPU v6e Trillium 최고 perf/watt, v5e 대비 4.7배 컴퓨트 메모리 집약 모델 (>70B 파라미터) Ironwood 192GB HBM이 더 큰 배치 크기 활성화 긴 컨텍스트 추론 (>100K 토큰) Ironwood HBM 용량이 대규모 KV 캐시 지원 임베딩 집약 워크로드 TPU v5p 또는 Ironwood SparseCore + 대용량 HBM [/caption]
사용 사례 최적 선택 근거 비용 최적화 추론 TPU v5e: 추론 쿼리당 가장 낮은 비용 대규모 훈련 (>1000칩) TPU v5p 또는 Ironwood 3D torus + OCS가 대규모 pod 활성화 중간 훈련 작업 (256칩) TPU v6e Trillium 최고 perf/watt, v5e 대비 4.7배 컴퓨트 메모리 집약 모델 (>70B 파라미터) Ironwood 192GB HBM이 더 큰 배치 크기 활성화 긴 컨텍스트 추론 (>100K 토큰) Ironwood HBM 용량이 대규모 KV 캐시 지원 임베딩 집약 워크로드 TPU v5p 또는 Ironwood SparseCore + 대용량 HBM [/caption]
## 하드웨어 아키텍처: 실리콘 내부
시스톨릭 배열 수학과 데이터플로우
Matrix Multiply Unit은 TPU 아키텍처의 심장부를 형성하며, 시스톨릭 배열을 이해하려면 GPU SIMD 레인에 비해 병렬처리에 대한 근본적으로 다른 접근법을 파악해야 합니다. 시스톨릭 배열은 곱셈-누적 유닛을 격자로 연결하여 데이터가 구조를 통해 리듬감 있게 흐르도록 합니다—따라서 심장을 통한 혈액의 리듬적 펌핑을 연상시키는 "시스톨릭"이라고 불립니다.³⁸
TPU v6e의 256×256 시스톨릭 배열이 행렬 곱셈 C = A × B를 수행하는 것을 고려해보세요. 엔지니어들은 격자로 배열된 65,536개의 개별 곱셈-누적 유닛에 행렬 B의 가중치를 미리 로드합니다. 행렬 A의 활성화 값은 왼쪽 가장자리에서 들어와 배열을 가로질러 수평으로 흐릅니다. 각 MAC 유닛은 저장된 가중치에 들어오는 활성화를 곱하고 결과를 위에서 도착하는 부분합에 더한 다음 활성화(수평으로)와 업데이트된 부분합(수직으로)을 이웃 유닛에 전달합니다.³⁹
데이터플로우 패턴은 각 활성화 값이 수평 차원을 가로지르면서 256번 재사용되고, 각 부분합이 수직으로 흐르면서 256개의 곱셈에서 기여를 누적한다는 것을 의미합니다. 중요한 점은 모든 중간 결과가 메모리로 왕복하지 않고 짧은 와이어를 통해 인접 MAC 유닛 간에 직접 전달된다는 것입니다. 아키텍처는 모든 클록 사이클에 65,536번의 곱셈-누적 연산을 수행하며, 잠재적으로 수백만 번의 연산을 포함하는 전체 행렬 곱셈 동안 중간 값이 DRAM이나 심지어 온칩 SRAM도 건드리지 않습니다.⁴⁰
가중치 고정 데이터플로우 패턴은 신경망 추론과 훈련에서 가장 일반적인 경우에 최적화됩니다: 동일한 가중치 행렬에 많은 다른 활성화 행렬을 반복적으로 곱하는 것입니다. 엔지니어들은 가중치를 한 번 로드한 다음 재로딩 없이 무제한 활성화 배치를 배열을 통해 스트리밍합니다. 이 패턴은 컨볼루션 레이어, 완전 연결 레이어, 그리고 트랜스포머 모델을 지배하는 Q·K^T 및 attention·V 연산에서 매우 잘 작동합니다.⁴¹
에너지 효율성은 데이터 재사용과 공간적 지역성에서 비롯됩니다. DRAM에서 값을 읽는 것은 단일 곱셈-누적 연산보다 대략 200배 더 많은 에너지를 소모합니다.⁴² 메모리 액세스 없이 각 가중치를 256번, 각 활성화를 256번 재사용함으로써 시스톨릭 배열은 컴퓨트 유닛과 메모리 계층 간에 데이터를 왕복시키는 아키텍처에서는 불가능한 와트당 연산 비율을 달성합니다.
시스톨릭 배열의 약점은 동적이거나 불규칙한 계산 패턴에서 나타납니다. 데이터가 고정된 일정에 따라 격자를 통해 흐르기 때문에 아키텍처는 조건부 실행, 희소 행렬(SparseCore를 사용하지 않는 한), 그리고 무작위 액세스 패턴을 요구하는 연산에 어려움을 겪습니다. 비유연성은 일반성을 대상 워크로드인 예측 가능한 액세스 패턴을 가진 조밀한 행렬 곱셈에서의 극도의 효율성과 교환합니다.
TensorCore 내부 아키텍처
각 TPU 칩은 하나 이상의 TensorCore를 포함합니다—Matrix Multiply Unit, Vector Processing Unit, 그리고 Scalar Unit이 협력하여 작동하는 완전한 처리 유닛입니다.⁴³ TensorCore는 소프트웨어가 대상으로 하는 기본 구성 요소를 나타내며, 세 구성요소 간의 상호작용을 이해하면 TPU 성능 특성과 프로그래밍 패턴을 모두 설명할 수 있습니다.
Matrix Multiply Unit은 FP32 누적과 함께 bfloat16 또는 FP8 입력에서 사이클당 16,000번의 곱셈-누적 연산을 실행합니다.⁴⁴ 혼합 정밀도 접근법은 입력에 대한 메모리 대역폭을 줄이면서 누적기에서 수치적 정확도를 보존합니다. 엔지니어들은 누적 중에 완전한 FP32 정밀도를 유지하는 것이 수백 또는 수천 개의 중간 곱셈을 합할 때 파멸적 소거 오류를 방지하는 반면, 감소된 정밀도 입력은 최종 모델 품질에 거의 영향을 주지 않는다고 관찰했습니다.
Vector Processing Unit은 MXU의 경직된 구조에 적합하지 않은 연산을 처리합니다. 활성화 함수(ReLU, GELU, SiLU), 정규화 레이어(배치 노름, 레이어 노름), softmax, 풀링, 드롭아웃, 그리고 요소별 연산이 VPU의 128-레인 SIMD 아키텍처에서 실행됩니다.⁴⁵ VPU는 FP32 및 INT32 데이터타입에서 작동하여 지수와 나눗셈이 큰 동적 범위를 만들 수 있는 softmax와 같은 수치적으로 민감한 연산에 필요한 정밀도를 제공합니다.
Scalar Unit은 전체 TensorCore를 조율합니다. 단일 스레드 프로세서는 제어 흐름을 실행하고, 복잡한 인덱싱 패턴을 위한 메모리 주소를 계산하며, High Bandwidth Memory에서 Vector Memory로의 DMA 전송을 시작합니다.⁴⁶ 스칼라 유닛이 단일 스레드로 실행되기 때문에 각 TensorCore는 사이클당 하나의 DMA 요청만 생성할 수 있는데, 이는 MXU나 VPU 컴퓨트 처리량을 포화시키지 않는 메모리 집약적 연산의 병목입니다.
TensorCore에 공급하는 메모리 계층은 원시 컴퓨트 능력만큼 달성 가능한 성능을 결정합니다. Vector Memory (VMEM)는 각 TensorCore 전용의 소프트웨어 관리 스크래치패드 SRAM으로 작용하며, 일반적으로 수십 메가바이트 크기입니다. XLA 컴파일러는 HBM과 VMEM 간의 데이터 이동을 명시적으로 스케줄링하여 빠른 로컬 메모리에 무엇을 스테이징할지와 언제 결과를 다시 쓸지 결정합니다.⁴⁷
TPU v4 이후 세대에 존재하는 Common Memory (CMEM)는 칩의 모든 TensorCore가 액세스할 수 있는 더 큰 공유 풀을 제공합니다. TPU v4 아키텍처는 두 TensorCore 간에 공유되는 128MB의 CMEM을 할당하여 한 코어의 출력이 HBM으로 왕복하지 않고 다른 코어의 입력을 공급하는 더 정교한 생산자-소비자 패턴을 가능하게 했습니다.⁴⁸
프로그래밍 모델의 함의는 매우 중요합니다. 스칼라 유닛이 단일 스레드이고 벡터 메모리가 명시적 관리를 요구하기 때문에 TPU 프로그래밍은 현대 GPU 프로그래밍보다 1990년대 임베디드 시스템 개발에 더 유사합니다. CUDA는 통합 메모리와 하드웨어 관리 캐시로 메모리 이동을 추상화합니다; TPU 코드(XLA로 생성되든 Pallas로 손으로 작성되든)는 모든 데이터 전송을 명시적으로 조율해야 합니다. 수동 제어는 전문가 최적화를 가능하게 하지만 능숙한 성능을 위한 기준을 높입니다.
High Bandwidth Memory 아키텍처
현대 TPU는 CPU에서 발견되는 DDR SDRAM이나 많은 GPU에서 사용되는 GDDR과 근본적으로 다른 메모리 기술인 HBM(High Bandwidth Memory) 또는 HBM3e를 사용합니다. HBM은 실리콘 관통 비아(TSV)를 사용하여 여러 DRAM 다이를 수직으로 스택한 다음 실리콘 인터포저에서 프로세서 다이 바로 옆에 스택을 배치합니다.⁴⁹ 짧은 전기 경로와 넓은 인터페이스는 기존 메모리 기술보다 극적으로 높은 대역폭을 가능하게 합니다.
TPU v7 Ironwood는 총 대역폭 7.4TB/s로 192GB의 HBM3e를 구현합니다.⁵⁰ 메모리 시스템은 여러 채널로 나뉘며, 각각 총 용량의 별도 부분에 독립적인 액세스를 제공합니다. XLA 컴파일러와 런타임은 병렬 액세스를 최대화하고 한 채널이 포화되는 동안 다른 채널이 유휴 상태에 있는 핫스팟을 피하기 위해 HBM 채널에 걸쳐 텐서를 신중하게 분할해야 합니다.
메모리 인터페이스 너비는 기존 DRAM을 압도합니다. DDR5 채널이 64비트의 너비를 제공할 수 있는 반면, HBM 채널은 일반적으로 1,024비트에 걸쳐 있습니다.⁵¹ 극도의 너비는 상대적으로 적당한 클록 속도에서 높은 대역폭을 가능하게 하여 좁은 인터페이스를 멀티기가헤르츠 주파수로 밀어붙이는 것에 비해 전력 소모와 신호 무결성 문제를 줄입니다.
지연시간 특성은 GPU 메모리 시스템과 상당히 다릅니다. TPU는 작은 로컬 버퍼를 넘어서는 하드웨어 관리 캐시가 없으므로 아키텍처는 컴퓨트 유닛이 필요로 하기 훨씬 전에 소프트웨어가 VMEM으로 데이터를 명시적으로 스테이징하는 것에 의존합니다. 캐시가 없다는 것은 컴파일러가 프리페칭과 더블 버퍼링을 통해 지연시간을 성공적으로 숨기지 못하면 메모리 지연시간이 성능에 직접 영향을 미친다는 것을 의미합니다.⁵²
메모리 용량 제한이 컴퓨트 처리량보다 많은 워크로드를 지배합니다. bfloat16 가중치를 가진 1,750억 매개변수 모델은 매개변수 저장에 350GB가 필요한데, 이는 이미 활성화, 옵티마이저 상태, 또는 그래디언트 버퍼를 고려하기 전에 Ironwood의 192GB HBM을 초과합니다. 이러한 모델을 훈련하려면 그래디언트 체크포인팅, 여러 칩에 걸친 옵티마이저 상태 샤딩, 그리고 메모리 공간을 최소화하기 위한 매개변수 업데이트의 신중한 스케줄링과 같은 정교한 기술이 필요합니다.⁵³
TPU 런타임은 MXU 효율성을 최대화하기 위해 특정 텐서 레이아웃 요구사항을 강제합니다. 시스톨릭 배열이 128×8 타일로 데이터를 처리하기 때문에 텐서는 패딩 낭비를 피하기 위해 이러한 차원에 정렬되어야 합니다.⁵⁴ 잘못 크기가 조정된 행렬은 하드웨어가 MAC이 유휴 상태인 부분 타일을 처리하도록 강제하여 FLOPS 활용도를 직접 줄입니다. 컴파일러는 텐서를 자동으로 패딩하고 재구성하려고 시도하지만 모델 아키텍처에서의 의식적인 레이아웃 선택은 성능을 상당히 개선할 수 있습니다.
SparseCore: 특화된 임베딩 가속
Matrix Multiply Unit이 조밀한 행렬 연산에서 뛰어난 반면, 임베딩 집약적 워크로드는 근본적으로 다른 특성을 보입니다. 추천 모델, 순위 시스템, 그리고 대형 언어 모델은 불규칙하고 데이터 의존적인 인덱스를 통해 대규모 임베딩 테이블(종종 수백 기가바이트)에 자주 액세스합니다. MXU의 구조화된 데이터플로우는 이러한 희소 메모리 액세스 패턴에 대해 아무런 장점을 제공하지 않아 SparseCore의 특화된 아키텍처를 동기부여합니다.⁵⁵
SparseCore는 MXU의 시스톨릭 배열과 근본적으로 다른 타일형 데이터플로우 프로세서를 구현합니다. TPU v4는 칩당 4개의 SparseCore를 특징으로 했으며, 각각 16개의 컴퓨트 타일을 포함했습니다.⁵⁶ 각 타일은 로컬 스크래치패드 메모리(SPMEM)와 처리 요소를 가진 독립적인 데이터플로우 유닛으로 작동합니다. 타일들은 병렬로 실행되어 임베딩 연산의 분리된 하위집합을 동시에 처리합니다.
메모리 계층은 핫 데이터를 작고 빠른 SPMEM에 배치하면서 전체 임베딩 테이블을 HBM에 유지합니다. XLA 컴파일러는 임베딩 액세스 패턴을 분석하여 어떤 임베딩 벡터가 SPMEM에서 캐싱할 가치가 있는지 HBM에서 필요에 따라 페칭할지 결정합니다.⁵⁷ 이 전략은 기존 CPU 캐시 계층과 유사하지만 하드웨어가 아닌 소프트웨어가 배치 결정을 내립니다.
SparseCores는 TensorCore의 메모리 경로를 완전히 우회하여 HBM 채널에 직접 연결됩니다. 전용 연결은 임베딩 연산이 메모리 대역폭에 대해 조밀한 행렬 연산과 경쟁하는 것을 방지하여 둘 다 병렬로 진행할 수 있게 합니다.⁵⁸ 분할은 조밀한 신경망 레이어와 대규모 임베딩 룩업을 인터리브하는 Deep Learning Recommendation Models (DLRM)과 같은 모델에서 매우 잘 작동합니다.
mod-샤딩 전략은 target_sc_id = col_id % num_total_sparse_cores를 계산하여 SparseCores에 걸쳐 임베딩을 분산합니다.⁵⁹ 간단한 샤딩 함수는 임베딩 ID가 균등하게 분산될 때 로드 밸런싱을 보장하지만 왜곡된 액세스 패턴에서 핫스팟을 생성할 수 있습니다. 실제 데이터로 작업하는 엔지니어들은 종종 임베딩 빈도 분포를 분석하고 병목을 피하기 위해 샤딩을 수동으로 재균형해야 합니다.
SparseCore의 성능 향상은 칩 다이 면적과 전력의 단 5%만 소모하면서 MXU와 VPU에서 동일한 연산을 구현하는 것에 비해 5-7배에 달합니다.⁶⁰ 극적인 효율성 장점은 희소 연산을 조밀한 행렬 인프라를 통해 강제하지 않고 목적에 맞게 구축한 데이터플로우에서 비롯됩니다. 특화 원칙은 TPU 아키텍처 내에서 재귀적으로 적용됩니다: TPU가 GPU의 범용 설계를 넘어 특화되는 것과 마찬가지로 SparseCores는 TPU의 행렬 지향 설계를 넘어 특화됩니다.
Trillium의 3세대 SparseCore는 가변 SIMD 너비(FP32용 8요소, bfloat16용 16요소)와 개선된 메모리 액세스 패턴을 도입하여 정렬되지 않은 읽기에서 낭비되는 대역폭을 줄였습니다.⁶¹ 아키텍처적 진화는 대형 언어 모델이 더 큰 어휘와 더 정교한 검색 증강 생성 패턴으로 경향을 보이면서 Google의 임베딩 가속에 대한 지속적인 투자를 보여줍니다.
인터커넥트 기술: 슈퍼컴퓨터의 배선
Inter-Chip Interconnect (ICI) 아키텍처
Inter-Chip Interconnect는 TPU가 고립된 가속기가 아닌 통합된 슈퍼컴퓨터로서 기능할 수 있게 하는 핵심 기술입니다. Ethernet 또는 InfiniBand 네트워크를 통해 통신하는 GPU와 달리, ICI는 마이크로초 규모의 지연 시간과 테라비트/초 대역폭으로 인접한 TPU를 직접 연결하는 맞춤형 고속 직렬 링크를 구현합니다.⁶²
TPU 세대별 토폴로지 진화는 포드 스케일링에 대한 요구사항 변화를 반영합니다. TPU v2, v3, v5e, v6e는 각 칩이 가장 가까운 네 개의 이웃(북쪽, 남쪽, 동쪽, 서쪽)에 연결되는 2D 토러스 토폴로지를 구현합니다.⁶³ 링크는 경계에서 감싸져서 연결이 적은 엣지 칩을 제거하는 도넛 모양의 논리적 토폴로지를 생성합니다. 따라서 256개 TPU의 16×16 그리드는 어떤 두 칩이 통신하든 관계없이 균일한 대역폭과 지연 시간 특성을 제공합니다.
TPU v4와 v5p는 각 칩이 여섯 개의 이웃에 연결되는 3D 토러스 토폴로지로 업그레이드되었습니다.⁶⁴ 추가 차원은 네트워크 직경(임의의 두 칩 사이의 최대 홉 수)을 대략 2√N에서 3∛N으로 줄입니다. 4,096칩 포드의 경우, 최대 홉이 약 128에서 48로 감소하여 all-reduce와 같은 전역 동기화 연산의 최악의 경우 통신 지연 시간을 대폭 줄입니다.
토로이달 구조는 또 다른 중요한 이점을 제공합니다: 워크로드가 칩 전체에 어떻게 분할되든 동일한 바이섹션 대역폭을 제공합니다. 토러스를 반으로 나누는 모든 절단은 동일한 수의 링크를 통과하므로, 잘못된 작업 배치가 네트워크 병목을 만드는 병리적인 경우를 방지합니다.⁶⁵ 균일한 바이섹션 대역폭은 스케줄링을 단순화하고 아래에서 논의할 광학 회로 스위치 재구성 기능을 가능하게 합니다.
대역폭 사양은 세대별로 인상적으로 확장됩니다. TPU v6e는 칩당 13TB/s의 ICI 대역폭을 제공합니다.⁶⁶ TPU v5p는 여섯 개의 3D 토러스 링크를 통해 칩당 4,800Gbps에 달했습니다.⁶⁷ Ironwood는 9.6Tbps 총 양방향 대역폭을 가진 네 개의 ICI 링크를 구현하여, 칩당 1.2TB/s로 변환됩니다.⁶⁸ 비교해보면, 최상급 400GbE 네트워크 인터페이스는 50GB/s 양방향 대역폭을 제공하는데, 이는 현대 TPU ICI보다 한 자릿수 적은 수준입니다.
랙 내 링크 기술은 동일한 4×4×4 큐브 내 칩 간의 짧은 거리에 대해 직접 연결 구리(DAC) 케이블을 사용합니다.⁶⁹ 구리 연결은 동기화된 작업을 실행하는 긴밀하게 결합된 칩에 필요한 대역폭을 제공하면서 비용과 전력을 최소화합니다. 큐브 간 및 포드 스케일 링크는 광학 트랜시버로 전환하여, 더 높은 비용과 전력을 데이터센터 랙에 걸친 거리와 대역폭과 교환합니다.
집합 연산은 ICI의 고유한 특성을 활용합니다. All-reduce, all-gather, reduce-scatter 연산은 훈련 중 칩 전체에서 활성화와 기울기를 자주 동기화합니다. Ethernet 기반 GPU 클러스터에서, 이러한 집합 연산은 스위치, 케이블, 네트워크 인터페이스 카드가 있는 계층적 네트워크를 통과하여 각 홉에서 지연을 발생시킵니다. TPU ICI는 최적화된 집합 알고리즘을 하드웨어에서 직접 구현하여, 동등한 Ethernet 기반 GPU 구현보다 10배 빠르게 all-reduce 연산을 실행합니다.⁷⁰
광학 회로 스위칭: 동적 토폴로지 재구성
TPU v4와 함께한 Google의 광학 회로 스위칭(OCS) 배치는 수십 년 간 데이터센터 네트워킹에서 가장 중요한 혁신 중 하나였습니다. 전통적인 패킷 스위치 네트워크(Ethernet 또는 InfiniBand)는 헤더를 검사하고 적절한 출력 포트로 전달하는 스위치를 통해 패킷을 홉 바이 홉으로 라우팅하여 논리적 연결을 설정합니다. 반면 OCS는 프로그래밍 가능한 광학 요소를 사용하여 끝점 간에 직접 물리적 광 경로를 생성하여 스위칭 지연을 완전히 제거합니다.⁷¹
핵심 기술은 광선을 리디렉션하기 위해 물리적으로 회전하는 MEMS(microelectromechanical systems) 거울에 의존합니다. TPU A의 송신기가 OCS로 광을 보냅니다. OCS 내부의 작은 거울들이 회전하여 그 광선을 TPU B의 수신기로 반사시킵니다. 연결은 광섬유를 통한 광 전파 이외에는 본질적으로 추가 지연이 없는 A에서 B로의 직접 광학 경로가 됩니다.⁷²
재구성 속도는 생산 시스템에서 OCS의 실용성을 결정합니다. Google의 배치는 10나노초 미만의 스위칭 시간을 달성합니다—일반적인 네트워크 프로토콜 왕복 시간보다 빠릅니다.⁷³ 재구성 속도는 실행 중인 작업을 방해하거나 신중하게 조정된 트래픽 엔지니어링을 요구하지 않으면서 워크로드 요구사항에 맞는 동적 토폴로지 변경을 가능하게 합니다.
TPU v5p는 대규모 스케일에서 OCS를 시연했습니다. 아키텍처는 스위칭 패브릭 전체에서 초당 4페타비트의 총 대역폭을 제공하는 광학 회로 스위치를 사용합니다.⁷⁴ 단일 v5p 슈퍼포드는 16×20×28 3D 토러스 구성에서 8,960개 칩을 연결하기 위해 13,824개의 광학 포트를 관리하는 48개의 OCS 유닛이 필요합니다.⁷⁵ 스위칭 시스템은 모든 컴퓨팅 환경에서 가장 큰 광학 네트워킹 배치 중 하나를 나타냅니다.
OCS는 전통적인 네트워크로는 불가능한 기능을 제공합니다. 물리적 토폴로지와 논리적 토폴로지가 완전히 분리됩니다—OCS가 직접 광학 경로를 만들면 데이터센터 반대편 모서리에 있는 두 TPU가 인접한 이웃으로 나타납니다. 실패한 칩이나 링크는 거울을 재프로그래밍하여 결함 있는 구성 요소를 제외하고 논리적 토러스 구조를 유지함으로써 우회됩니다. 새로운 작업은 OCS를 프로그래밍하여 랙을 물리적으로 재배선하지 않고도 적절한 포드 구성을 만들어 모든 크기의 "슬라이스"를 받습니다.⁷⁶
아키텍처는 단일 포드를 넘어서 확장하기 위해 Google의 Jupiter 데이터센터 네트워크와 통합됩니다. Jupiter는 Google의 맞춤형 실리콘 스위치와 제어 플레인을 사용하여 전체 데이터센터에 걸쳐 멀티 페타비트/초 바이섹션 대역폭을 제공합니다.⁷⁷ 여러 TPU 슈퍼포드는 Jupiter 패브릭을 통해 연결되어, 네트워크 용량이 허용하면 이론적으로 최대 400,000개 가속기의 클러스터를 지원합니다.⁷⁸
전력 소비와 신뢰성 특성은 TPU 스케일 배치에서 광학 회로 스위칭을 선호합니다. 전통적인 패킷 스위치는 테라비트/초 속도로 패킷을 처리하고 전달하는 데 상당한 전력을 소비합니다. OCS 스위치는 재구성 이벤트 중에만 MEMS 거울을 작동하는 데 전력을 소비한 다음, 연결이 안정적으로 유지되는 동안 최소한의 손실로 광을 통과시키며 유휴 상태를 유지합니다.⁷⁹ 아키텍처의 단순성은 버그와 성능 이상에 취약한 복잡한 패킷 처리 및 버퍼링 로직을 제거함으로써 신뢰성을 향상시킵니다.
포드 아키텍처와 스케일링 특성
TPU 포드는 ICI를 통해 연결된 TPU의 가장 큰 단일 유닛으로, 통합된 가속기를 형성합니다. 물리적 구조는 개별 칩에서 트레이, 큐브, 랙, 완전한 포드로 계층적으로 구축됩니다.⁸⁰ 계층구조를 이해하는 것은 다양한 스케일에서의 메모리 용량, 통신 대역폭, 장애 허용성을 추론하는 데 중요합니다.
기본 구성 요소는 PCIe를 통해 호스트 CPU에 연결된 단일 트레이의 네 개 칩으로 구성됩니다.⁸¹ PCIe 연결은 제어 플레인 작업, 초기 프로그램 로딩, 훈련 데이터와 추론 결과에 대한 인피드/아웃피드를 처리합니다. 분산 훈련을 위한 실제 칩 간 통신은 PCIe 대역폭 병목을 피하기 위해 PCIe가 아닌 ICI를 통해 흐릅니다.
16개 트레이(64개 칩)가 단일 4×4×4 큐브를 형성합니다—포드 구성의 기본 단위입니다. 큐브 내에서는 칩이 같은 랙에 있어 물리적 거리가 짧기 때문에 모든 ICI 연결이 직접 연결 구리 케이블을 사용합니다.⁸² 큐브는 래핑 연결로 완전한 3D 토러스를 구현하여, 이론적으로 독립적으로 작동할 수 있는 자체 포함된 64칩 유닛을 만듭니다.
TPU v4 포드는 총 4,096개 칩의 64개 큐브로 확장됩니다.⁸³ 큐브 간 연결은 광학 회로 스위칭 패브릭에 의해 관리되는 광학 링크로 전환됩니다. OCS는 이러한 4,096개 칩을 단일 거대한 포드, 여러 개의 작은 독립 포드로 프로비저닝하거나 필요에 따라 작업 중에 동적으로 재구성할 수 있습니다. 유연성은 데이터센터 운영자가 다양한 작업 크기와 우선순위 전반에서 활용도의 균형을 맞출 수 있게 합니다.
TPU v5p는 포드 스케일을 16×20×28 3D 토러스의 8,960개 칩으로 확장했습니다.⁸⁴ 특정 차원은 신중한 대역폭 및 직경 최적화를 반영합니다—소인수분해는 네트워크 토폴로지에 중요합니다! 포드는 4.45 엑사플롭스의 컴퓨팅을 제공하며 생산에 배치된 가장 큰 단일 포드 구성 중 하나를 나타냅니다.
Ironwood는 작은 배치용 256칩 포드와 대규모 프론티어 모델 훈련용 9,216칩 슈퍼포드를 모두 지원합니다.⁸⁵ 9,216칩 구성은 42.5 FP8 엑사플롭스를 제공합니다—불과 5년 전 슈퍼컴퓨터 Top500 전체 목록보다 더 많은 컴퓨팅 성능입니다.⁸⁶ 이 스케일은 파이프라인 또는 비동기 접근법이 아닌 동기 훈련으로 조직이 달성할 수 있는 것을 재정의합니다.
스케일링 효율성은 더 큰 포드가 실제로 도움이 되는지를 결정합니다. 칩이 컴퓨팅보다 동기화에 더 많은 시간을 소비하면서 포드 크기와 함께 통신 오버헤드가 증가합니다. Google Research는 특정 워크로드에서 32,768개 TPU에서 95% 스케일링 효율성을 달성했다는 결과를 발표했는데, 이는 32,768개 TPU가 완벽한 선형 스케일링이 예측하는 성능의 95%를 제공했다는 의미입니다.⁸⁷ 효율성은 하드웨어 가속 집합 연산, 최적화된 컴파일러 변환, 기울기 동기화 빈도를 줄이는 영리한 알고리즘 접근법에서 비롯됩니다.
포드 스케일에서의 장애 허용성에는 정교한 처리가 필요합니다. 통계적 확률은 지속적으로 실행되는 수천 개의 칩이 있는 시스템에서 구성 요소 장애를 보장합니다. 광학 회로 스위치는 실패한 구성 요소 주변을 재구성하여 우아한 성능 저하를 가능하게 합니다. 훈련 체크포인팅은 정기적인 간격(보통 몇 분마다)으로 발생하므로, 작업 실패는 처음부터가 아닌 마지막 체크포인트에서만 재시작하면 됩니다.⁸⁸
소프트웨어 스택: 컴파일러, 프레임워크, 그리고 프로그래밍 모델
XLA 컴파일러: 계산 그래프 최적화
XLA(Accelerated Linear Algebra)는 TPU 소프트웨어 스택의 기반을 형성하며, 고수준 프레임워크 연산을 TPU에서 실행할 수 있는 최적화된 머신 코드로 컴파일합니다.⁸⁹ 이 컴파일러는 머신러닝 워크로드와 TPU 아키텍처 특성에 대한 도메인 지식을 활용하여 범용 컴파일러로는 불가능한 적극적인 최적화를 구현합니다.
Fusion은 XLA의 가장 효과적인 최적화입니다. 컴파일러는 계산 그래프를 분석하여 중간 텐서를 실체화하지 않고 실행할 수 있는 연산 시퀀스를 식별합니다. 간단한 예시로, relu(batch_norm(conv(x)))와 같은 요소별 연산은 일반적으로 합성곱 출력을 메모리에 쓰고, 배치 정규화를 위해 이를 읽고, 그 결과를 메모리에 쓴 다음, ReLU를 위해 다시 읽어야 합니다. XLA는 이러한 연산들을 중간 메모리 트래픽 없이 최종 ReLU 출력을 생성하는 단일 커널로 융합합니다.⁹⁰
Fusion의 영향력은 TPU 아키텍처에 따라 확장됩니다. 많은 워크로드에서 계산 처리량보다 메모리 대역폭이 제약 요소가 됩니다. MXU는 메모리 시스템이 데이터를 공급할 수 있는 속도보다 빠르게 행렬 곱셈을 수행할 수 있습니다. Fusion을 통해 중간 메모리 쓰기와 읽기를 제거하는 것은 직접적인 성능 향상으로 이어지며, 활성화 함수가 많은 네트워크에서 종종 2배 이상의 속도 향상을 제공합니다.⁹¹
메모리 레이아웃 변환은 하드웨어 요구사항에 맞게 텐서 저장을 최적화합니다. 신경망은 직관적인 인덱싱을 위해 NHWC 형식(배치, 높이, 너비, 채널)으로 텐서를 표현하는 경우가 많지만, TPU MXU는 128×8 타일과 정렬된 레이아웃에서 최고 성능을 발휘합니다.⁹² XLA는 자동으로 텐서를 전치, 재형성, 패딩하여 하드웨어 선호사항에 맞추고, 필요한 경우에만 레이아웃 변환을 삽입하며, 때로는 전체 변환 오버헤드를 최소화하기 위해 선호 레이아웃을 그래프 뒤쪽으로 전파합니다.
컴파일러는 정교한 상수 폴딩과 데드 코드 제거를 구현합니다. ML 그래프는 상수에만 의존하는 출력을 가진 서브그래프를 자주 포함합니다. 배치 정규화 매개변수, 추론 드롭아웃 비율, 배치마다가 아닌 한 번만 실행될 수 있는 형태 계산 등입니다. XLA는 컴파일 시점에 이러한 서브그래프를 평가하고 상수 텐서로 대체하여 런타임 작업을 줄입니다.⁹³
크로스 복제본 최적화는 분산 실행에 대한 지식을 활용합니다. 여러 TPU 코어에서 훈련할 때 특정 연산(배치 정규화 통계 등)은 모든 복제본에 걸친 집계가 필요합니다. XLA는 이러한 패턴을 식별하고 명시적 메시지 전달을 통한 집계 구현 대신 ICI의 하드웨어 가속 all-reduce를 활용하는 최적화된 집합 연산을 생성합니다.⁹⁴
컴파일러는 TPU 전용 중간 표현인 Mosaic을 대상으로 합니다. Mosaic은 어셈블리 언어보다 높지만 입력 계산 그래프보다는 낮은 추상화 수준에서 작동합니다. 이 언어는 명령어 스케줄링과 레지스터 할당과 같은 저수준 세부사항을 숨기면서 시스톨릭 배열, 벡터 메모리, VMEM 스테이징과 같은 TPU 아키텍처 기능을 노출합니다.⁹⁵
자동 튜닝 기능은 경험적 탐색을 통해 최적의 타일 크기와 연산 매개변수를 선택합니다. XLA Auto-Tuning (XTAT) 시스템은 다양한 융합 전략, 메모리 레이아웃, 타일 차원을 시도하고 각 변형의 성능을 프로파일링하여 가장 빠른 구성을 선택합니다.⁹⁶ 복잡한 모델의 경우 상당한 컴파일 시간이 필요할 수 있지만, 인간이 수동으로 거의 식별하지 못하는 반직관적인 최적화를 발견하여 극적인 런타임 속도 향상을 제공합니다.
JAX: 합성 가능한 변환과 SPMD
JAX는 자동 미분, XLA로의 JIT 컴파일, 프로그램 변환에 대한 일급 지원을 갖춘 수치 계산용 NumPy 호환 인터페이스를 제공합니다.⁹⁷ 이 프레임워크의 함수형 프로그래밍 패러다임과 합성 가능한 변환 모델은 TPU 실행 모델과 분산 병렬처리 패턴과 자연스럽게 일치합니다.
핵심 JAX 추상화는 함수에 수학적 변환을 적용합니다. Grad(f)는 f의 그래디언트를 계산합니다. Jit(f)는 f를 XLA로 JIT 컴파일합니다. vmap(f)는 새로운 차원에 대해 f를 벡터화합니다. 중요한 점은 변환이 합성된다는 것입니다. jit(grad(vmap(f)))는 예상대로 정확히 작동하여 벡터화된 그래디언트 함수를 컴파일합니다.⁹⁸ 합성 모델은 간단하고 테스트 가능한 구성요소로부터 복잡한 분산 훈련 루프를 구축할 수 있게 해줍니다.
SPMD(Single Program, Multiple Data)는 JAX의 분산 실행 모델을 나타냅니다. 프로그래머는 단일 장치를 대상으로 하는 것처럼 코드를 작성한 다음, 여러 TPU 코어에 걸쳐 텐서를 분할하는 방법을 나타내는 샤딩 주석을 추가합니다. XLA 컴파일러와 GSPMD(General SPMD) 서브시스템은 분산 장치에서 실행하면서 프로그램 의미를 유지하기 위해 자동으로 통신 연산을 삽입합니다.⁹⁹
샤딩 주석은 PartitionSpec을 사용하여 분산 전략을 선언합니다. PartitionSpec('batch', None)은 두 번째 차원은 복제하면서 텐서의 첫 번째 차원을 장치 메시의 'batch' 축에 걸쳐 샤드합니다. PartitionSpec(None, 'model')은 두 번째 차원을 분할하여 텐서 병렬처리를 구현합니다. 이러한 주석은 임의의 텐서 순위와 장치 메시 차원과 합성될 수 있습니다.¹⁰⁰
GSPMD의 자동 병렬화는 방대한 양의 상용구 코드를 제거합니다. 전통적인 분산 훈련은 전체 텐서가 필요한 연산 전에 all-gather를 수동으로 삽입하고, 분산 그래디언트 계산 후 reduce-scatter를, 전역 축약을 위해 all-reduce를 삽입해야 합니다. GSPMD는 샤딩 명세를 분석하고 적절한 집합 연산을 자동으로 삽입하여 프로그래머가 통신 엔지니어링보다는 알고리즘에 집중할 수 있게 해줍니다.¹⁰¹
컴파일러는 제약 조건 해결을 사용하여 계산 그래프 전반에 걸쳐 샤딩 결정을 전파합니다. 연산 A가 연산 B에서 소비되는 샤드된 텐서를 출력하는 경우, GSPMD는 출력이 어떻게 사용되는지에 따라 B의 최적 샤딩을 추론하고, 수학적으로 필요한 경우에만 재샤딩 연산을 삽입할 수 있습니다.¹⁰² 자동화된 추론은 수작업으로 작성된 분산 코드를 괴롭히는 "샤딩 스파게티"를 방지합니다.
JAX는 자동화가 부족한 경우 세밀한 제어를 제공합니다. with_sharding_constraint는 그래프 위치에서 특정 샤딩을 강제하여 자동 추론을 무시합니다. 커스텀 PJIT(parallel JIT) 주석은 성능이 중요한 코드 경로에 대한 정확한 장치 배치와 샤딩 전략을 지정합니다. 계층화된 모델은 자동 샤딩을 통한 빠른 프로토타이핑을 가능하게 하면서 필요한 경우 전문가 최적화를 지원합니다.¹⁰³
Shardy는 2025년 GSPMD의 후속작으로 등장하여 개선된 제약 조건 전파 알고리즘과 동적 형태의 더 나은 처리를 구현합니다.¹⁰⁴ 새로운 시스템은 연산별이 아닌 더 큰 그래프 영역에 걸쳐 샤딩 선택을 공동으로 추론하여 추가적인 최적화 기회를 노출합니다.
PyTorch/XLA: PyTorch를 TPU로 가져오기
PyTorch/XLA는 최소한의 코드 변경으로 TPU에서 PyTorch 모델을 실행할 수 있게 하여 PyTorch의 명령형 프로그래밍 모델과 XLA의 그래프 기반 컴파일 사이의 격차를 해소합니다.¹⁰⁵ 이 통합은 PyTorch의 개발자 경험을 보존하는 것과 TPU 특정 최적화를 노출하는 것 사이의 균형을 맞춥니다.
근본적인 과제는 PyTorch의 즉시 실행 철학에서 비롯됩니다. PyTorch는 Python 문이 실행될 때 즉시 연산을 실행하여 표준 도구로 디버깅을 가능하게 하고 자연스러운 제어 흐름을 제공합니다. XLA는 컴파일 전에 완전한 계산 그래프를 캡처해야 하므로 즉시 실행과 그래프 컴파일의 성능 이점 사이에 긴장을 조성합니다.¹⁰⁶
PyTorch/XLA 2.4는 임피던스 미스매치를 해결하는 eager 모드 지원을 도입했습니다. 구현은 PyTorch 연산을 XLA 그래프로 동적으로 추적하여 개발자가 표준 PyTorch 코드를 작성하면서도 XLA 컴파일의 이점을 누릴 수 있게 합니다.¹⁰⁷ 이 모드는 일부 컴파일 최적화 기회를 개발 속도와 디버깅 단순성과 교환합니다.
그래프 모드는 여전히 프로덕션 배포의 주요 경로입니다. 개발자는 데코레이터나 컴파일 API를 사용하여 XLA 컴파일을 위한 함수를 명시적으로 표시합니다. 명시적 주석은 적극적인 최적화를 가능하게 하지만 어떤 연산이 단일 XLA 그래프로 융합되어야 하는지 독립적으로 실행되어야 하는지 이해해야 합니다.¹⁰⁸
Pallas 통합은 PyTorch/XLA에 커스텀 커널 개발을 가져옵니다. Pallas는 XLA의 자동 융합이 부족하거나 특수한 연산이 수작업 최적화를 요구할 때 TPU 커널을 작성하기 위한 저수준 언어를 제공합니다.¹⁰⁹ 이 언어는 원시 어셈블리보다 높은 수준을 유지하면서 TPU 메모리 계층(VMEM, CMEM, HBM)과 계산 유닛(MXU, VPU)을 노출합니다.
내장 Pallas 커널은 FlashAttention과 PagedAttention 같은 성능이 중요한 연산을 구현합니다. FlashAttention의 타일형 어텐션 계산은 시퀀스 길이 n에 대해 메모리 대역폭 요구사항을 O(n²)에서 O(n)로 줄여 고정된 메모리 예산 내에서 모델이 훨씬 더 긴 시퀀스를 처리할 수 있게 합니다.¹¹⁰ PagedAttention은 서빙을 위한 키-값 캐시 관리를 최적화하여 패딩된 구현 대비 5배 속도 향상을 달성합니다.¹¹¹
PyTorch/XLA 브리지는 원래 GPU용으로 설계된 고성능 서빙 프레임워크인 vLLM TPU에 중요했습니다. 구현은 실제로 PyTorch 모델에 대해서도 중간 변환 경로로 JAX를 사용하여 PyTorch 프론트엔드 호환성을 유지하면서 JAX의 우수한 병렬처리 지원을 활용합니다.¹¹² 이 아키텍처는 2025년 동안 초기 프로토타입 대비 2-5배 성능 향상을 달성했습니다.
개선에도 불구하고 모델 호환성 문제는 지속됩니다. 일부 PyTorch 연산은 XLA 동등 연산이 부족하여 성능을 저하시키는 CPU 실행으로의 폴백을 강요합니다. 동적 제어 흐름은 그래프 컴파일에서 잘 지원되지 않아 종종 동적 동작을 정적이고 컴파일 가능한 대안으로 대체하는 아키텍처 변경이 필요합니다. PyTorch/XLA 저장소는 호환성을 문서화하고 일반적인 문제 패턴에 대한 마이그레이션 가이드를 제공합니다.¹¹³
정밀도 형식: BFloat16, FP8, 그리고 양자화
TPU의 축소 정밀도 산술 지원은 허용 가능한 모델 품질을 유지하면서 극적인 성능과 메모리 향상을 가능하게 합니다. 다양한 형식의 수치적 속성과 각각을 언제 적용할지 이해하는 것은 최적의 성능을 달성하는 데 중요합니다.¹¹⁴
BFloat16은 TPU v2에서 처음 등장한 축소 정밀도 훈련에 대한 Google의 초기 투자를 나타냅니다. 이 형식은 FP32의 8비트 지수를 유지하면서 가수를 7비트(플러스 부호 비트)로 잘라냅니다.¹¹⁵ 전체 지수 범위는 그래디언트가 FP16 표현 가능 범위를 자주 벗어나는 초기 FP16 훈련을 괴롭혔던 언더플로와 오버플로를 방지합니다.
축소된 가수는 양자화 오류를 도입하지만 최종 모델 품질에 거의 영향을 미치지 않습니다. 엔지니어들은 bfloat16으로 훈련된 모델이 일반적으로 통계적 노이즈 범위 내에서 FP32 훈련된 기준선과 일치함을 관찰했는데, 양자화가 작은 수치 세부사항에 과적합을 방지하는 정규화의 한 형태로 작용하기 때문인 것으로 보입니다.¹¹⁶ 이 형식은 FP32 대비 메모리 대역폭과 용량 요구사항을 절반으로 줄여 메모리 바운드 워크로드에서 직접적인 성능 향상으로 이어집니다.
FP8은 축소 정밀도를 더욱 발전시켜 가중치와 활성화를 8비트로 압축합니다. 두 가지 표준 인코딩이 존재합니다: E4M3(4비트 지수, 3비트 가수)은 순방향 패스의 정밀도를 우선시하고, E5M2(5비트 지수, 2비트 가수)는 그래디언트 크기가 크게 변하는 역방향 패스의 범위를 우선시합니다.¹¹⁷ Ironwood는 두 형식 모두에 대한 네이티브 FP8 지원을 구현하는 반면, 이전 TPU들은 소프트웨어 변환을 통해 FP8을 에뮬레이트했습니다.¹¹⁸
훈련 중 양자화 인식은 FP8의 수치적 성공을 가능하게 합니다. FP8로 처음부터 훈련되거나 FP8 인식 기법으로 파인튜닝된 모델은 형식의 제한된 정밀도를 허용하는 가중치 분포를 학습합니다. 훈련 후 양자화(훈련 후 FP32 모델을 FP8로 변환)는 신중한 보정 없이는 종종 품질을 저하시킵니다.¹¹⁹
INT8 양자화는 훨씬 더 큰 메모리 절약과 추론 속도 향상을 제공합니다. Google의 Accurate Quantized Training(AQT)은 bfloat16 기준선 대비 최소한의 품질 손실로 TPU에서 INT8 훈련을 가능하게 합니다.¹²⁰ 이 기법은 처음부터 양자화 인식 훈련을 적용하여 훈련 후 근사가 아닌 학습 중에 모델이 INT8의 제약 조건에 적응할 수 있게 합니다.
혼합 정밀도 전략은 형식을 전략적으로 결합합니다. 순방향 패스는 활성화와 가중치에 FP8을 사용할 수 있고, 역방향 패스는 그래디언트에 FP8 E5M2 또는 bfloat16을 사용하며, 옵티마이저 상태는 가중치 업데이트 중 수치 안정성을 위해 FP32로 유지됩니다.¹²¹ 혼합 접근법은 속도, 메모리, 정확도의 균형을 맞춰 종종 FP32 품질의 90% 이상을 달성하면서 4배 빠르게 실행됩니다.
정밀도 트레이드오프는 속도와 메모리를 넘어 수치 안정성 고려사항까지 확장됩니다. 배치 정규화, 레이어 정규화, 소프트맥스는 축소 정밀도에서 신중한 수치 처리가 필요합니다. 소프트맥스의 큰 지수는 FP8 또는 bfloat16 범위를 오버플로시킬 수 있으므로; 지수화 전에 최대 로짓을 빼는 것은 수학적 동등성을 유지하면서 오버플로를 방지합니다.¹²² XLA 컴파일러는 안전할 때 이러한 변환을 자동으로 구현하지만, 커스텀 연산은 때때로 수동 수치 엔지니어링이 필요합니다.
프로그래밍 모델 및 병렬화 전략
SPMD와 자동 분할
Single Program, Multiple Data (SPMD) 패러다임은 프로그래머가 TPU 실행에 대해 사고하는 방식을 근본적으로 형성합니다. 여러 프로세스를 조정하기 위해 명시적인 메시지 전달 코드를 작성하는 대신, 개발자는 단일 프로그램을 작성하고 데이터가 장치 간에 어떻게 분할되어야 하는지 주석을 달면 됩니다.¹²³ 컴파일러가 분산, 통신, 동기화의 기계적 세부 사항을 처리합니다.
GSPMD (General SPMD)는 XLA에서 자동 분할 로직을 구현합니다. 시스템은 텐서 샤딩 주석과 계산 그래프 구조를 분석하여 어떤 장치에서 어떤 연산이 실행될지와 올바른 의미를 유지하기 위해 어떤 통신이 필요한지 결정합니다.¹²⁴ 자동화는 수작업으로 작성한 분산 코드에서 흔히 발생하는 전체 클래스의 버그들—맞지 않는 텐서 형태, 잘못된 집합 연산 순서, 부적절한 동기화로 인한 교착 상태—을 제거합니다.
컴파일러의 제약 전파 엔진은 최소한의 주석으로부터 샤딩 결정을 추론합니다. 모델의 입력과 출력 샤딩만 주석을 다는 것으로도 충분한 경우가 많습니다. GSPMD는 중간 연산들을 통해 제약을 전파하고 효율적인 분산을 자동으로 선택합니다.¹²⁵ 연산에 대해 여러 유효한 샤딩이 존재할 때, 컴파일러는 대안들의 통신 비용을 추정하고 가장 낮은 비용의 옵션을 선택합니다.
고급 최적화는 통신과 계산을 겹칩니다. 레플리카 간에 그래디언트를 동기화하는 All-reduce 연산은 첫 번째 레이어의 그래디언트가 완료되자마자 시작할 수 있으며, 후속 레이어들의 역방향 패스와 병렬로 실행됩니다.¹²⁶ 컴파일러는 자동으로 집합 연산을 스케줄링하여 겹침을 최대화하고, 순차 실행 대비 적절한 통신 시간을 2배 이상 줄입니다.
재구체화(Rematerialization)는 계산과 메모리를 교환합니다. 그래디언트 계산을 위해 모든 순방향 패스 활성화를 저장하는 대신, 컴파일러는 메모리 압박이 임계값을 초과할 때 역방향 패스 동안 활성화를 선택적으로 재계산합니다.¹²⁷ 이 트레이드오프는 계산이 메모리 대역폭을 능가하는 TPU에서 특히 잘 작동하여, 재계산을 메모리 트래픽보다 저렴하게 만듭니다.
데이터 병렬화, 텐서 병렬화, 파이프라인 병렬화
데이터 병렬화는 가장 직관적인 분산 학습 전략을 나타냅니다. 완전한 모델을 N개 장치에 복제하고 각 레플리카에서 서로 다른 데이터 배치를 처리합니다. 로컬로 그래디언트를 계산한 후, all-reduce가 레플리카 간에 그래디언트를 집계하고 모든 장치가 동일한 가중치 업데이트를 적용합니다.¹²⁸ 이 접근법은 통신 시간이 계산 시간을 지배할 때까지 선형적으로 확장됩니다—일반적으로 이더넷 네트워킹에서는 약 1,000개 GPU까지, ICI를 사용한 TPU에서는 10,000개 이상까지입니다.¹²⁹
텐서 병렬화(모델 병렬화라고도 함)는 개별 연산을 장치 간에 분할합니다. 행렬 곱셈 Y = W @ X는 가중치 행렬 W를 장치 간에 분할하여 각각이 출력의 일부를 계산합니다.¹³⁰ 이 전략은 매개변수 저장과 계산을 분산시켜 단일 장치 메모리를 초과하는 모델 학습을 가능하게 합니다.
텐서 병렬화의 통신 패턴은 데이터 병렬화와 상당히 다릅니다. 각 레이어 후 all-reduce 대신, 텐서 병렬화는 완전한 텐서가 필요한 연산 전에 all-gather를, 분산 계산 후에 reduce-scatter를 필요로 합니다.¹³¹ 통신 볼륨은 매개변수 크기가 아닌 모델 활성화 크기에 따라 스케일되어, 데이터 병렬화와는 다른 병목 현상을 만듭니다.
파이프라인 병렬화는 순차적 모델 레이어를 장치 간에 분할하여, 서로 다른 마이크로 배치를 서로 다른 스테이지에서 동시에 처리합니다. GPipe는 메모리 사용량을 제한하면서 파이프라인 활용도를 최대화하는 신중한 스케줄링으로 이 전략을 도입했습니다.¹³² 각 장치는 하나의 마이크로 배치의 순방향 패스를 처리하고, 활성화를 다음 스테이지로 보낸 다음, 다음 마이크로 배치를 처리하여—초기 램프업 후 모든 장치가 지속적으로 작동하는 파이프라인을 만듭니다.
그래디언트 지연이 파이프라인 병렬화를 복잡하게 만듭니다. 장치들은 잠재적으로 수십 개의 마이크로 배치만큼 오래된 활성화로부터 계산된 그래디언트를 사용하여 가중치를 업데이트하여, 수렴에 해를 끼칠 수 있는 지연을 만듭니다.¹³³ PipeDream과 같은 정교한 스케줄링 알고리즘은 높은 처리량을 유지하면서 지연을 최소화하고, 경험적 결과는 대부분의 모델이 품질 저하 없이 적당한 지연을 견딜 수 있음을 보여줍니다.
3D 병렬화는 세 가지 전략을 모두 결합합니다. 데이터 병렬화는 "데이터" 차원에서 분산하고, 텐서 병렬화는 "모델" 차원에서, 파이프라인 병렬화는 "파이프라인" 차원에서 분산합니다.¹³⁴ 모델 아키텍처, 하드웨어 토폴로지, 통신 비용을 기반으로 차원을 신중하게 균형 맞추면 처리량이 최대화됩니다. GPT-3 규모의 모델들은 일반적으로 8-16개 레플리카의 데이터 병렬화, 4-8개 GPU의 텐서 병렬화, 4-16개 스테이지의 파이프라인 병렬화로 3D 병렬화를 사용합니다.
샤딩 전략 및 최적화
샤딩 전략 선택은 수학적 연산과 그들의 데이터 의존성 이해를 필요로 합니다. 행렬 곱셈 C = A @ B는 여러 유효한 샤딩을 허용합니다: A와 B를 모두 복제하고 부분 결과를 계산(계산 전 통신), B를 열 방향으로 샤딩하고 결과를 수집(계산 후 통신), 또는 A를 행 방향으로 B를 열 방향으로 샤딩하여 통신 없이 하지만 더 작은 장치별 행렬로 처리.¹³⁵
집합 연산 비용이 최적 전략을 결정합니다. All-reduce 비용은 텐서 크기에 선형적으로 스케일되지만 트리 기반 또는 링 기반 리덕션 알고리즘을 사용하여 장치 수에 하위 선형적으로 스케일됩니다:¹³⁶ All-gather와 reduce-scatter는 다른 스케일링 속성을 보입니다. 컴파일러는 이러한 비용을 모델링하고 총 통신 시간을 최소화하는 샤딩 전략을 선택합니다.
시퀀스 병렬화는 대규모 언어 모델에 중요하게 나타납니다. 어텐션 메커니즘은 키-값 캐시가 시퀀스 길이와 배치 크기에 따라 증가하기 때문에 메모리 병목을 만듭니다. 시퀀스 차원을 따라 분할하면 어텐션 계산 자체에만 통신을 도입하면서 메모리 부담을 장치 간에 분산시킵니다.¹³⁷
전문가 병렬화는 서로 다른 전문가가 서로 다른 토큰을 처리하는 Mixture-of-Experts (MoE) 모델을 처리합니다. 샤딩 전략은 공유 레이어를 모든 장치에 복제하되 전문가들을 분할하여, 각 토큰을 지정된 전문가 장치로 라우팅합니다.¹³⁸ 동적 라우팅은 전통적인 집합 연산에 도전하는 불규칙한 통신 패턴을 만들어, 지연과 로드 불균형을 최소화하는 정교한 런타임 시스템을 필요로 합니다.
옵티마이저 상태 샤딩은 대규모 모델의 메모리 오버헤드를 줄입니다. Adam과 같은 옵티마이저는 모든 매개변수에 대한 모멘텀과 분산 통계를 저장하여, 매개변수만의 메모리 요구사항의 3배를 만듭니다. 매개변수를 복제된 상태로 유지하면서 옵티마이저 상태를 장치 간에 샤딩하면 고정된 메모리 예산 내에서 더 큰 모델 학습이 가능해집니다.¹³⁹ 이 전략은 가중치 계산 동안 옵티마이저 상태 업데이트를 수집해야 하지만 장치별 메모리 풋프린트를 상당히 줄입니다.
성능 분석 및 벤치마킹
MLPerf 결과 및 경쟁 포지셔닝
MLPerf는 훈련 및 추론 워크로드에서 AI 가속기 성능을 측정하는 업계 표준 벤치마크를 제공합니다. Google은 정기적으로 TPU 결과를 제출하여 경쟁력 있는 성능을 입증하며, 세대별 발전은 명확한 아키텍처 개선을 보여줍니다.¹⁴⁰
TPU v5e는 MLPerf 훈련 9개 카테고리 중 8개에서 선도적인 결과를 달성했습니다.¹⁴¹ 이러한 광범위한 성과는 단순히 대형 언어 모델을 넘어선 아키텍처의 다양성을 보여주며, 컴퓨터 비전, 추천 시스템, 과학 컴퓨팅 워크로드에서 경쟁력 있는 성능을 입증합니다. BERT 훈련은 NVIDIA A100 GPU보다 2.8배 빠르게 완료되어 트랜스포머 최적화 아키텍처를 검증했습니다.¹⁴²
2025년 6월에 발표된 MLPerf Training v5.0은 제품군에서 가장 큰 모델인 Llama 3.1 405B 벤치마크를 도입했습니다.¹⁴³ 이 벤치마크는 이전 테스트보다 멀티노드 스케일링, 통신 오버헤드, 메모리 용량을 더욱 집중적으로 테스트합니다. Google Cloud는 TPU 제출로 참여했지만, 공식 결과 발표 대기로 인해 상세한 성능 비교는 아직 공개되지 않았습니다.
MLPerf Inference v5.0에는 네 가지 새로운 벤치마크가 포함되었습니다: Llama 3.1 405B, 저지연 애플리케이션용 Llama 2 70B, RGAT 그래프 신경망, 3D 객체 탐지용 PointPainting.¹⁴⁴ 이러한 다양성은 가속기를 기존 트랜스포머 워크로드를 넘어 아키텍처 가정이 다를 수 있는 새로운 애플리케이션 영역으로 확장시킵니다.
추론 벤치마크는 특히 TPU의 아키텍처 강점을 활용합니다. 배치 추론 워크로드는 MXU의 대규모 병렬성을 활용하여 트랜스포머 서빙에서 경쟁 가속기보다 4배 높은 처리량을 달성합니다.¹⁴⁵ 단일 쿼리 지연 시간은 TPU의 결정적 실행과 열 스로틀링 부재의 이점을 누리며, 일부 GPU 배포를 괴롭히는 성능 변동 없이 일관된 지연 시간을 제공합니다.
에너지 효율성 지표는 세대를 거치며 TPU의 우위가 확대되고 있음을 보여줍니다. TPU v4는 TPU v3보다 와트당 2.7배 뛰어난 성능을 보였고, Trillium은 v5e보다 67% 개선되었습니다.¹⁴⁶ Ironwood는 현저히 높은 절대 성능에도 불구하고 Trillium보다 와트당 2배 뛰어난 성능을 주장합니다.¹⁴⁷ 효율성 향상은 수천 개 칩 포드 전체에 걸쳐 복합되어 데이터센터 운영 비용에서 수백만 달러의 절약으로 이어집니다.
실제 훈련 및 추론 성능
실제 워크로드는 합성 벤치마크에서 나타나지 않는 성능 특성을 보여줍니다. Google은 실제 사용 패턴과 확장 요구사항 하에서 TPU 동작을 보여주는 내부 서비스 결과를 공개합니다.¹⁴⁸
ResNet-50 ImageNet 훈련은 TPU 포드에서 28분 만에 완료되며, 이는 컴퓨터 비전 워크로드 성능을 위해 널리 인용되는 벤치마크입니다.¹⁴⁹ 정확도까지의 시간 지표는 데이터 로딩, 증강, 분산 그래디언트 동기화, 체크포인트 저장을 포함한 완전한 훈련 프로세스를 포착하며, 단순한 이론적 FLOP이 아닙니다.
T5-3B 언어 모델 훈련은 트랜스포머 아키텍처에서 TPU의 우위를 보여줍니다. 30억 파라미터 모델은 TPU 포드에서 12시간에 훈련되며, 이는 동등한 GPU 구성의 31시간과 비교됩니다.¹⁵⁰ 2.6배 속도 향상은 하드웨어 가속 어텐션 연산, 효율적인 메모리 대역폭 활용, 최적화된 집합 통신에서 비롯됩니다.
GPT-3 규모 워크로드(1750억 파라미터)는 동시대 GPU보다 TPU에서 1.7배 빠른 정확도까지의 시간을 달성합니다.¹⁵¹ 성능 격차는 더 큰 모델에서 확대되며, 이때 메모리 용량과 대역폭이 중요한 제약이 됩니다. Ironwood의 192GB HBM3e는 낮은 메모리 대안에서는 복잡한 텐서 병렬성이 필요한 모델을 서빙할 수 있게 합니다.
스케일링 효율성 측정은 거대한 규모에서 거의 선형적인 속도 향상을 보여줍니다. Google Research는 특정 트랜스포머 훈련 워크로드에서 32,768개 TPU에서 95% 스케일링 효율성을 보고했습니다.¹⁵² 이 지표는 32,768개 TPU가 완벽한 선형 스케일링이 예측하는 성능의 95%를 제공했다는 의미로, 통신 오버헤드가 규모에 따라 증가하는 점을 고려하면 놀라운 결과입니다.
FLOPS 활용률 지표는 워크로드가 사용 가능한 컴퓨팅을 얼마나 효과적으로 활용하는지 보여줍니다. 트랜스포머 모델은 일반적으로 TPU에서 90% FLOPS 활용률을 달성하며, 이는 이론적 최고 성능의 90%가 실제 작업으로 전환됨을 의미합니다.¹⁵³ 높은 활용률은 메모리 병목을 제거하는 연산 융합, 대형 행렬 곱셈에서의 시스톨릭 어레이 효율성, 낭비되는 사이클을 최소화하는 컴파일러 최적화에서 비롯됩니다.
실제 추론 서비스는 하루 수십억 쿼리에 걸쳐 지속적인 성능을 보여줍니다. Google Translate는 TPU에서 매일 10억 건의 요청을 처리합니다.¹⁵⁴ YouTube 추천은 TPU 가속 모델을 사용하여 20억 사용자에게 서비스를 제공합니다.¹⁵⁵ Google Photos는 검색 및 구성 기능을 위해 월 280억 장의 이미지를 분석합니다.¹⁵⁶ 이러한 운영 규모는 연구 프로토타입 배포를 넘어선 신뢰성과 비용 효율성을 검증합니다.
에너지 효율성 및 총 소유 비용
전력 소비는 데이터센터 운영 비용과 환경 지속가능성에 직접적인 영향을 미칩니다. TPU의 세대별 에너지 효율성 개선은 대규모에서 운영 비용과 탄소 배출을 모두 줄입니다.¹⁵⁷
TPU v4는 250W TDP 사양에도 불구하고 실제 워크로드에서 평균 200W 전력 소비만 보였습니다.¹⁵⁸ 평균과 최대 전력 간의 여유는 유연한 열 설계와 프로비저닝을 가능하게 합니다. 지속적인 워크로드가 종종 TDP 한계에 도달하여 보수적인 랙 전력 예산이 필요한 GPU와 대조됩니다.
Ironwood의 600W TDP는 이전 세대보다 높은 절대 전력을 나타내지만 와트당 훨씬 더 많은 컴퓨팅을 제공합니다.¹⁵⁹ 칩당 4.6 PFLOPS FP8 성능은 약 7.7 TFLOPS/와트를 제공하며, 동등한 워크로드에서 동시대 GPU 효율성과 경쟁하거나 이를 초과합니다.
데이터센터 전력 사용 효율성(PUE)은 칩 수준 효율성을 증폭시킵니다. Google의 TPU 데이터센터는 1.1의 PUE를 달성하며, 이는 냉각, 전력 변환, 네트워킹을 위한 칩 소비 외 10%의 전력 오버헤드만 있음을 의미합니다.¹⁶⁰ 업계 평균 PUE는 1.5에서 2.0 범위로, 50-100%의 추가 전력이 인프라 오버헤드로 소비됩니다. 낮은 PUE는 고급 냉각 시스템, 효율적인 전력 공급, ML 워크로드를 최적화하는 신중한 데이터센터 설계에서 비롯됩니다.
탄소 집약도 고려사항은 전력을 넘어 에너지 원천을 포함합니다. Google은 재생 에너지 조달 및 탄소 상쇄 프로그램을 통해 탄소 중립 전력으로 TPU 데이터센터를 운영합니다.¹⁶¹ 탄소 회계는 클라우드 컴퓨팅에서 Scope 2 배출을 추적하는 조직들에게 점점 더 중요해지고 있습니다.
총 소유 비용(TCO) 분석은 취득 비용, 전력 소비, 냉각 요구사항, 유지보수 비용을 고려해야 합니다. TPU 배포는 일반적으로 동등한 GPU 설치와 비교하여 20-30% TCO 감소를 보여주며, 이는 주로 뛰어난 와트당 성능과 냉각 복잡성 감소에서 비롯됩니다.¹⁶²
냉각 인프라 비용은 전력 밀도에 따라 비선형적으로 확장됩니다. 공냉 랙은 일반적으로 특수 냉각 솔루션이 필요하기 전까지 랙당 15-20kW에서 최고치를 보입니다. 고전력 GPU는 이러한 한계를 밀어붙여 때로는 상당히 높은 자본 및 운영 비용을 가진 액체 냉각 인프라를 필요로 합니다. TPU의 효율성은 더 많은 배포를 공냉 범위 내에 유지하여 데이터센터 설계를 단순화합니다.¹⁶³
기술적 장점: TPU가 뛰어난 영역
하드웨어 가속 집합 연산
TPU ICI의 특화된 집합 연산 지원은 기존 네트워크 기반 가속기 대비 가장 중요한 장점 중 하나를 제공합니다. 분산 훈련에서 그래디언트 동기화를 위한 핵심 연산인 all-reduce는 TPU ICI에서 동등한 Ethernet 기반 GPU 구현보다 10배 빠르게 실행됩니다.¹⁶⁴
성능 격차는 아키텍처 통합에서 비롯됩니다. Ethernet 기반 집합 연산은 여러 계층을 거칩니다: 애플리케이션 코드가 집합 라이브러리(NCCL, Horovod 등)를 호출하고, 패킷을 생성하여 네트워크 스택에 전달한 후, NIC로 데이터를 전송하고, 와이어로 직렬화하여 스위치를 거쳐 수신 NIC에서 역직렬화하는 과정을 거칩니다. 각 계층은 지연 시간을 추가하고, 메모리 계층 구조를 통해 데이터를 복사하며, 프로토콜 처리를 위해 CPU 사이클을 소모합니다.¹⁶⁵
TPU ICI는 소프트웨어 계층을 거치지 않고 하드웨어에서 집합 연산을 구현합니다. 연산은 TensorCore에서 직접 시작되어 전용 ICI 링크를 통해 데이터를 스트리밍하고, 호스트 CPU의 개입 없이 완료됩니다. 직접적인 하드웨어 경로는 기존 구현에서 지배적인 오버헤드를 제거합니다.¹⁶⁶
광학 회로 스위치 토폴로지는 최적의 집합 알고리즘을 가능하게 합니다. 링 기반 all-reduce는 N개 디바이스에 대해 2(N-1) 메시지만 필요하며, 토러스 토폴로지는 최단 경로 라우팅을 제공하여 지연 시간을 최소화합니다.¹⁶⁷ 균등한 이등분 대역폭은 라우팅이 잘못된 집합 연산이 네트워크 링크를 혼잡하게 만드는 핫스팟을 방지합니다.
통합 메모리 공간과 단순화된 프로그래밍
TPU의 통합 메모리 모델은 GPU의 복잡한 메모리 계층 구조와 비교하여 프로그래밍을 단순화합니다. 프로그래머는 호스트 RAM, GPU 글로벌 메모리, 공유 메모리, 레지스터 파일 간의 전송을 관리하는 대신 단일 HBM 풀에 대해서만 생각하면 됩니다. 단순화된 모델은 버그를 줄이고 더 빠른 개발 속도를 가능하게 합니다.¹⁶⁸
메모리 조각화는 더 이상 문제가 되지 않습니다. GPU는 조각화된 힙에서 메모리를 할당하는데, 시간이 지남에 따라 할당과 할당 해제로 인해 압축이 필요한 구멍이 생깁니다. 컴파일러의 정적 분석을 통한 TPU 메모리 관리는 런타임 조각화를 완전히 방지합니다. 텐서들은 계산 그래프를 기반으로 미리 결정된 위치에 할당됩니다.¹⁶⁹
프로그래밍 모델은 전체 CUDA 오류 클래스를 제거합니다. 잘못된 포인터 연산으로 인한 "불법 메모리 접근" 오류, CPU와 GPU 간 캐시 일관성 버그, cudaDeviceSynchronize() 호출 누락으로 인한 동기화 오류가 더 이상 발생하지 않습니다. 높은 수준의 추상화는 CUDA 프로그래밍에서 흔히 발생하는 함정을 방지합니다.¹⁷⁰
결정론적 실행과 재현성
부동소수점의 비결합성은 병렬 컴퓨팅에서 재현성 문제를 야기합니다. (a + b) + c 표현식은 반올림 오류로 인해 a + (b + c)와 다른 결과를 낼 수 있으며, 병렬 리덕션은 경쟁 조건에 따라 실행마다 다른 순서로 합계를 계산할 수 있습니다.¹⁷¹
TPU 실행은 일반적인 GPU 구현보다 강한 결정론성을 보입니다. 시스톨릭 배열의 고정된 데이터 플로우 패턴은 실행 간 동일한 연산 순서를 보장합니다. 집합 연산은 도착 순서에 기반한 기회적 집계가 아닌 결정론적 리덕션 트리를 따릅니다. 예측 가능성은 동일한 하이퍼파라미터와 데이터가 비트 단위로 동일한 모델 가중치를 생성하는 재현 가능한 훈련을 가능하게 합니다.¹⁷²
디버깅은 결정론성으로부터 엄청난 이점을 얻습니다. 비결정론적 훈련은 실패 원인을 찾는 것을 거의 불가능하게 만듭니다. NaN이 진짜 알고리즘 버그에서 온 것인지 무작위 경쟁 조건에서 온 것인지 알 수 없습니다. 결정론적 실행은 실패가 안정적으로 재현되어 체계적인 디버깅 접근법을 가능하게 합니다.¹⁷³
과학 컴퓨팅 애플리케이션은 특히 재현성을 중시합니다. 기후 모델, 신약 개발 시뮬레이션, 물리학 연구는 다른 연구자들이 동일한 결과를 재현할 수 있도록 하는 검증 가능한 결과를 요구합니다. TPU의 결정론성은 경쟁하는 비결정론적 대안보다 과학적 방법을 더 잘 지원합니다.¹⁷⁴
컴파일러 최적화와 개발자 생산성
XLA의 적극적인 최적화는 수동 튜닝 없이 "즉시 사용 가능한" 상당한 성능 향상을 제공합니다. 연구자들은 즉시 실행 프레임워크와 비교하여 컴파일만으로도 모델 처리량이 40% 향상된다고 보고합니다.¹⁷⁵ 성능은 무료로 제공되며 커널 엔지니어링이 필요하지 않습니다.
퓨전 최적화는 특히 개발자에게 도움이 됩니다. CUDA에서 연산을 수동으로 퓨전하려면 커스텀 커널을 작성하고, 정확성을 테스트하며, 프레임워크 버전 간에 코드를 유지 관리해야 합니다. XLA는 연산을 자동으로 퓨전하고 업데이트하며, 모델이 진화함에 따라 퓨전 전략을 조정하여 유지 관리 부담을 제거합니다.¹⁷⁶
레이아웃 변환 자동화는 수주간의 수동 최적화를 절약합니다. GPU를 위한 최적의 텐서 레이아웃을 결정하려면 다양한 배열을 프로파일링하고, 수동으로 전치를 삽입하며, 메모리 할당 패턴을 신중하게 관리해야 합니다. XLA는 레이아웃을 자동으로 시도하고 가장 빠른 것을 선택하여, 개발자가 낮은 수준의 성능 엔지니어링보다는 모델 아키텍처에 집중할 수 있게 합니다.¹⁷⁷
생산성 향상은 연구팀에게 복합적으로 작용합니다. 인프라 최적화에 절약된 시간은 과학적 진보를 가속화하여 더 많은 실험과 더 빠른 반복 주기를 가능하게 합니다. 조직들은 GPU CUDA 프로그래밍에서 TPU JAX 기반 워크플로우로 이동할 때 3배의 개발 속도 향상을 보고합니다.¹⁷⁸
## 기술적 한계와 단점
플랫폼 종속과 온프레미스 제약사항
TPU 접근은 Google Cloud Platform을 통해서만 독점적으로 가능하며, 이로 인해 온프레미스 배포가 불가능하고 벤더 종속에 대한 우려가 제기됩니다.¹⁷⁹ 데이터 주권 요구사항, 격리된 네트워크 또는 퍼블릭 클라우드 사용 금지 정책을 가진 조직들은 기술적 우수성과 관계없이 TPU를 활용할 수 없습니다.
AI가 핵심 인프라가 되면서 이러한 제약은 점점 더 중요해지고 있습니다. 단일 클라우드 제공업체에 대한 의존성은 비즈니스 연속성 위험을 야기합니다—가격 변경, 가용성 중단 또는 서비스 중단으로 인해 비용이 많이 드는 마이그레이션이 강요될 수 있습니다.¹⁸⁰ 여러 벤더로부터 GPU를 사용할 수 있다는 점(AWS, Azure, GCP 및 온프레미스에서 실행되는 NVIDIA 하드웨어)은 TPU 아키텍처가 구조적으로 배제하는 선택의 여지를 제공합니다.
멀티클라우드 전략은 마찰을 겪게 됩니다. TPU를 표준화한 조직들은 모델을 재학습하거나 서로 다른 가속기 아키텍처를 위한 별도의 코드베이스를 유지하지 않고서는 다른 클라우드로 버스팅하거나 멀티클라우드 중복성을 구현하기 어렵습니다.¹⁸¹ 하이브리드 GPU/TPU 배포의 운영 복잡성은 종종 최적의 가속기 선택으로 인한 비용 절감 효과를 압도합니다.
CUDA 생태계 성숙도 격차
NVIDIA의 CUDA 플랫폼은 15년 이상의 생태계 개발, 라이브러리, 문서화, 그리고 커뮤니티 지식을 축적해 왔으며, 이는 TPU가 따라잡을 수 없는 수준입니다.¹⁸² 성숙도 격차는 TPU 채택에 있어 수많은 문제점으로 나타납니다.
라이브러리 가용성은 압도적으로 CUDA에 유리합니다. 컴퓨터 그래픽스, 분자 역학, 전산유체역학, 유전체학 같은 전문 도메인들은 지난 수십 년 동안 수천 개의 CUDA 최적화 라이브러리를 축적해 왔습니다. TPU 등가물은 종종 존재하지 않아, CPU 폴백(성능을 파괴함)이나 수개월의 포팅 작업을 요구합니다.¹⁸³
커뮤니티 지원은 차이가 몇 배나 납니다. Stack Overflow에는 상세한 답변이 있는 CUDA 질문이 수십만 개 포함되어 있으며, GitHub 리포지토리는 수백만 개에 달합니다. 컨퍼런스 발표, 학술 논문, 블로그 포스트들은 주로 CUDA 프로그래밍에 초점을 맞춥니다. TPU 프로그래머들은 상대적으로 부족한 리소스, 더 긴 디버깅 주기, 그리고 상담할 수 있는 전문가가 적다는 문제에 직면합니다.¹⁸⁴
교육 자료와 튜토리얼은 압도적으로 CUDA를 대상으로 합니다. 대학교 과정들은 CUDA를 사용하여 GPU 프로그래밍을 가르칩니다. 온라인 과정들도 CUDA에 집중합니다. 인재 파이프라인은 TPU 전문가보다 CUDA 경험이 있는 엔지니어를 훨씬 더 많이 배출하여, 채용과 교육에 어려움을 야기합니다.¹⁸⁵
커스텀 커널 개발은 생태계 격차를 보여주는 대표적인 예입니다. 최적화된 CUDA 커널 작성은 여전히 쉽지 않지만 광범위한 문서, 프로파일링 도구, 예제 코드의 혜택을 받습니다. Pallas가 커스텀 TPU 커널을 가능하게 하지만, 도구의 성숙도가 낮고 지식 기반이 더 작습니다. 학습 곡선이 가장 성능이 중요한 최적화를 제외하고는 모두 억제합니다.¹⁸⁶
워크로드 전문화 및 유연성 제약
TPU의 아키텍처는 특정 워크로드 패턴에 최적화되어 있습니다—주로 정규 액세스 패턴과 대용량 배치 크기를 가진 밀집 행렬 곱셈입니다. 최적점 밖의 작업들은 성능 급락을 경험합니다.¹⁸⁷
동적 모양은 TPU 실행 모델에 도전을 제기합니다. XLA 컴파일러는 최적화와 코드 생성을 위해 고정된 텐서 차원을 가정합니다. 가변 시퀀스 길이, 동적 제어 흐름 또는 데이터 종속적 모양을 가진 모델들은 최대 크기로의 패딩(컴퓨트와 메모리 낭비) 또는 각각의 고유한 모양에 대한 재컴파일(성능 파괴)을 요구합니다.¹⁸⁸
희소 연산은 SparseCore에도 불구하고 제한적인 지원을 받습니다. 과학 컴퓨팅과 그래프 신경망에서 일반적인 워크로드인 희소 행렬-행렬 곱셈은 MXU나 VPU에서 효율적인 구현이 부족합니다. 전용 SparseCore는 임베딩 테이블을 처리하지만 일반적인 희소 선형대수는 처리하지 못합니다.¹⁸⁹
소규모 배치 추론은 TPU의 병렬 리소스를 충분히 활용하지 못합니다. 256×256 시스톨릭 어레이는 그리드를 생산적인 작업으로 채우는 대형 행렬에서 번영합니다. 단일 쿼리 추론은 대부분의 MAC을 유휴 상태로 두어, 저배치 시나리오에 최적화된 GPU 대안보다 쿼리당 지연 시간과 비용이 더 나쁩니다.¹⁹⁰
불규칙한 계산 패턴은 시스톨릭 어레이 효율성을 무력화시킵니다. 예측할 수 없는 분기, 재귀적 구조 또는 포인터 추적 메모리 액세스를 가진 알고리즘들은 고정된 데이터플로우가 런타임 종속적 행동에 적응할 수 없기 때문에 TPU 성능이 저조합니다.¹⁹¹
비ML 워크로드는 TPU 가속의 혜택을 받는 경우가 거의 없습니다. 과학 시뮬레이션, 비디오 인코딩, 블록체인 검증, 렌더링은 모두 행렬 연산에서 TPU의 더 높은 피크 FLOPs에도 불구하고 GPU의 더 일반적인 아키텍처에서 더 빠르게 실행됩니다.¹⁹²
디버깅 및 개발 도구 격차
NVIDIA의 생태계는 수십 년에 걸쳐 정제된 성숙한 프로파일링 도구(Nsight Systems, Nsight Compute, nvprof), 디버거(cuda-gdb), 분석 프레임워크를 포함합니다. TPU 도구는 존재하지만 정교함에서 상당히 뒤떨어집니다.¹⁹³
XProf는 TensorBoard 통합을 통해 기본적인 프로파일링을 제공하지만 NVIDIA 도구들이 노출하는 세밀한 하드웨어 카운터 접근이 부족합니다. 캐시 미스 비율, 점유율, 워프 발산 또는 메모리 뱅크 충돌—모든 중요한 GPU 최적화 메트릭을 이해하는 것—은 아키텍처가 근본적으로 다르기 때문에 TPU에는 등가물이 없습니다.¹⁹⁴
오류 메시지가 종종 근본 원인을 모호하게 만듭니다. XLA 컴파일 실패는 모양 불일치나 지원되지 않는 작업에 대한 수수께끼 같은 메시지를 생성하며, 해결에 대한 명확한 지침이 없습니다. 도움이 되지 않기로 악명 높은 CUDA 오류들도 15년간의 StackOverflow 설명과 부족 지식의 혜택을 받습니다.¹⁹⁵
멀티칩 포드에서의 분산 훈련 디버깅은 전문 도구 없이는 거의 불가능에 가깝습니다. 경쟁 조건, 그래디언트 동기화 버그, 집합 연산 실패는 일관성 없이 재현되고 체계적인 진단에 저항하는 비결정적 오류로 나타납니다(아이러니하게도 TPU의 결정론적 이점에도 불구하고).¹⁹⁶
복잡한 모델에 대한 반복 루프는 고통스럽게 길어집니다. 모양 변경이나 아키텍처 수정을 위한 재컴파일은 수 분이 걸릴 수 있으며, 컴파일러가 작동하는 동안 개발을 정지시킵니다. CUDA의 즉시 실행 모델은 더 낮은 피크 성능에도 불구하고 더 빠른 반복을 가능하게 합니다.¹⁹⁷
실제 배포: 대규모 프로덕션 환경
Anthropic Claude: 멀티 플랫폼 전략
Anthropic의 2025년 10월 100만 개 이상의 TPU 칩 배포 발표는 역사상 가장 큰 규모로 공개적으로 공개된 AI 가속기 투자를 나타냅니다.¹⁹⁸ 이 회사는 향후 Claude 모델의 훈련과 서빙을 위해 2026년에 가동될 1기가와트 이상의 컴퓨팅 용량에 독점적으로 접근할 계획입니다.
이 규모는 이전 배포들을 여러 단계 차이로 압도합니다. Ironwood TPU로 구성된 100만 개의 칩은 약 4.6 엑사플롭스의 FP8 컴퓨팅 성능을 제공할 것으로 예상되며, 이는 불과 5년 전 전체 Top500 슈퍼컴퓨터 목록의 총 성능보다 40배 이상 높습니다.¹⁹⁹ 이러한 투자는 이전에는 공상과학소설로 여겨졌던 규모의 프론티어 모델 개발에서 TPU 아키텍처에 대한 확신을 보여줍니다.
Anthropic은 Google의 TPU, Amazon의 Trainium, NVIDIA GPU를 아우르는 신중한 멀티 플랫폼 하드웨어 전략을 추진합니다.²⁰⁰ 이러한 다각화는 용량 보험, 가격 협상력, 지리적 분산을 제공합니다. Claude는 세 플랫폼 모두의 배포를 통해 전 세계적으로 서비스를 제공하며, 용량 가용성과 지역별 지연 시간 요구사항에 따라 요청을 라우팅합니다.
2025년 8월 회사의 기술 사후 분석은 대규모 배포의 복잡성을 드러냈습니다. Claude API TPU 서버의 잘못된 구성으로 인해 토큰 생성 오류가 발생했으며, 영어 프롬프트에서 태국어나 중국어 문자에 예상치 못하게 높은 확률을 할당하는 경우가 있었습니다.²⁰¹ 이 사건은 간단한 오류조차도 매일 수십억 개의 토큰을 처리하는 시스템에서 예측할 수 없게 연쇄적으로 발생할 수 있음을 보여주었습니다.
별도의 배포에서는 Claude Haiku 3.5에 영향을 미치는 XLA: TPU 컴파일러의 잠재적 버그가 발생했습니다. 이 버그는 특정 모델 아키텍처와 컴파일러 플래그 조합이 결함을 노출시킬 때까지 몇 달 동안 탐지되지 않았습니다.²⁰² 이 발견은 프로덕션 배포가 개발 및 스테이징 환경에서는 없던 경계 사례를 발견한다는 점을 강조합니다.
Anthropic 엔지니어들은 TPU의 가격 대비 성능과 효율성을 주요 선택 기준으로 꼽았습니다. 매력적인 경제성은 고정된 예산 내에서 더 큰 실험을 가능하게 하여 개발을 가속화합니다.²⁰³ 더 큰 모델 훈련, 더 많은 하이퍼파라미터 구성 탐색, 더 빠른 반복이 모두 FLOP당 비용 절감에서 비롯됩니다.
Google Gemini: 처음부터 TPU를 위해 설계
Google의 Gemini 모델은 처음부터 TPU 특성에 맞게 아키텍처와 훈련 절차가 공동 설계되어 TPU에서만 훈련되고 서빙됩니다.²⁰⁴ 이러한 긴밀한 결합은 크로스 플랫폼 모델이 활용할 수 없는 TPU 특화 최적화를 활용할 수 있게 합니다.
Gemini 배포는 가장 중요한 모델 변형의 훈련과 서빙에 50,000개의 TPU v6e 칩을 사용하는 것으로 알려져 있습니다.²⁰⁵ 이러한 거대한 파드 규모는 정교한 오케스트레이션을 필요로 합니다—수천 개의 칩에 걸친 작업 스케줄링, 병목 현상을 방지하기 위한 체크포인트 조정, 손실된 작업을 최소화하기 위한 장애 복구, 장애가 전파되기 전에 성능이 저하된 노드를 식별하기 위한 실시간 모니터링입니다.
Google은 6세대 아키텍처를 프론티어 모델 개발에 검증하면서 Trillium TPU에서 Gemini 2.0을 훈련했습니다.²⁰⁶ 이 훈련 실행은 전례 없는 칩 수까지의 확장 효율성을 입증했으며, 통신 오버헤드가 지배적인 일반적인 한계점을 넘어서는 강한 확장성을 달성했습니다.
모델 서빙 인프라는 TPU 추론 최적화를 특별히 활용합니다. 배치 처리는 여러 사용자 요청을 집계하여 MXU 활용도를 최대화합니다. 키-값 캐시 관리는 HBM 용량을 활용하여 디스크 스와핑 없이 장시간 컨텍스트 처리를 가능하게 합니다. 이 아키텍처는 대규모 글로벌 요청 볼륨을 처리하면서 복잡한 쿼리에 대해 1초 미만의 응답 시간을 제공합니다.²⁰⁷
프로덕션 모니터링 시스템은 50,000개 이상의 TPU를 지속적으로 추적하여 모델 품질이나 가용성을 저하시킬 수 있는 이상 징후를 탐지합니다.²⁰⁸ 텔레메트리는 모든 칩에서 오류율, 지연시간 백분위수, 처리량, 메모리 압력, 열 특성을 캡처합니다. 머신 러닝 모델들이 텔레메트리 스트림 자체를 분석하여 장애가 발생하기 전에 예측하고 예방적 유지보수를 트리거합니다.
추가 프로덕션 배포
Midjourney는 GPU에서 TPU 인프라로 마이그레이션하여 이미지 생성 워크로드에서 65%의 비용 절감과 40%의 지연시간 개선을 달성했습니다.²⁰⁹ 이 아트 생성 서비스는 최고 부하 시 분당 300,000개의 이미지를 처리하며, 대규모 컴퓨팅 처리량과 돌발적 트래픽 패턴 하에서 일관된 성능이 필요합니다.
Cohere의 TPU 기반 언어 모델은 이전 GPU 배포 대비 3배의 처리량을 달성했습니다.²¹⁰ 이러한 속도 향상은 동일한 인프라 규모에서 더 많은 고객에게 서비스를 제공할 수 있게 하여 비즈니스 경제성을 직접적으로 개선했습니다. 이 회사는 JAX의 SPMD 기능을 활용하여 TPU 파드 전반에 걸쳐 모델을 효율적으로 병렬화했습니다.
Snap은 증강현실 기능, 추천 시스템, 창작 AI 도구를 지원하기 위해 10,000개의 TPU v6e 칩 용량을 확보했습니다.²¹¹ 이 배포는 여러 지리적 지역에 걸쳐 있어 Snapchat의 글로벌 사용자 기반을 위한 낮은 지연시간을 보장하면서 지역 간 모델 일관성을 유지합니다.
학술 기관들이 연구를 위해 TPU를 점점 더 많이 채택하고 있습니다. TPU Research Cloud (TRC) 프로그램은 연구자들에게 무료 TPU 접근을 제공하여 이전에는 자금이 풍부한 기업 연구소에서만 접근 가능했던 규모의 실험을 가능하게 합니다.²¹² 이러한 민주화는 AI 역량과 한계에 대한 기본적인 질문을 조사하는 학계의 하드웨어 장벽을 제거함으로써 과학적 진보를 가속화합니다.
디버깅, 프로파일링, 그리고 성능 최적화
XProf와 TensorBoard 통합
XProf는 TPU 워크로드를 위한 주요 프로파일링 도구로, CPU, GPU, TPU 전반에 걸쳐 JAX, PyTorch/XLA, TensorFlow 프로그램에 대한 성능 분석을 제공합니다.²¹³ 이 도구는 시각화를 위해 TensorBoard와 통합되어, ML 엔지니어들이 이미 이해하고 있는 친숙한 인터페이스를 통해 프로파일링 데이터를 제시합니다.
설치에는 TensorBoard 플러그인이 필요합니다: pip install tensorboard_plugin_profile tensorboard. 이를 통해 완전한 툴체인이 활성화됩니다.²¹⁴ TPU VM에서 프로파일링을 실행하는 것은 훈련이나 추론 중 트레이스를 캡처하고, 결과를 TensorBoard에 업로드하며, 시각화를 분석하여 병목지점을 식별하는 과정을 포함합니다.
Overview Page는 단계별 시간 분석, 디바이스 사용률, 최상위 병목지점 식별을 포함한 상위 수준의 성능 요약 지표를 제공합니다.²¹⁵ 이 페이지는 워크로드가 컴퓨트 집약적(MXU가 지속적으로 실행), 메모리 집약적(HBM 전송 대기), 또는 통신 집약적(집합 연산에서 블록됨)인지를 즉시 강조합니다.
Trace Viewer와 타임라인 분석
Trace Viewer는 연산이 정확히 언제 실행되고, 데이터 전송이 언제 발생하며, 유휴 시간이 어디에 누적되는지 보여주는 상세한 타임라인 시각화를 표시합니다.²¹⁶ Chrome 기반 인터페이스는 마이크로초 해상도까지 확대를 가능하게 하여, 집계 지표가 가리는 정확한 스케줄링 동작을 드러냅니다.
트레이스를 이해하려면 일반적인 패턴을 인식해야 합니다. 연산 간 긴 간격은 컴파일 오버헤드, 데이터 로딩 병목, 또는 최적화되지 않은 데이터 파이프라인으로 인한 Python 오버헤드를 나타냅니다. 반복되는 작은 연산들은 불충분한 융합을 시사합니다. 밀리초에 걸친 집합 연산들은 통신 비효율성이나 잘못된 샤딩 전략을 지적합니다.²¹⁷
색상 코딩은 연산 유형을 구별합니다: 컴퓨트는 녹색, 메모리 전송은 파란색, 통신은 주황색, 유휴 시간은 빨간색입니다. 최적화된 워크로드는 최소한의 빨간색 간격으로 조밀하게 패킹된 컬러 블록을 보여줍니다. 최적화가 잘못된 코드는 리소스 낭비를 나타내는 긴 빨간색 구간이 있는 희소한 타임라인을 보입니다.²¹⁸
고급 사용법은 타임라인 동작과 소스 코드를 상관시키는 것을 포함합니다. PyTorch/XLA는 코드에 삽입된 사용자 어노테이션을 지원하여 트레이스에 나타나게 하고, 성능 동작을 특정 모델 컴포넌트에 매핑할 수 있게 합니다.²¹⁹ 어노테이션은 불투명한 트레이스를 어떤 레이어나 연산에 최적화 집중이 필요한지에 대한 실행 가능한 인사이트로 변환합니다.
Memory Profile Tool과 OOM 디버깅
메모리 부족(OOM) 오류는 대형 모델 개발을 괴롭힙니다. Memory Profile Tool은 실행 중 디바이스 메모리 사용량을 모니터링하여 OOM 실패로 이어지는 피크 사용률과 할당 패턴을 캡처합니다.²²⁰
이 도구는 시간에 따른 메모리 소비를 시각화하여, 어떤 텐서가 가장 많은 용량을 소비하고 언제 피크 사용량이 발생하는지 보여줍니다. 시각화는 종종 놀라운 할당들을 드러냅니다—예상보다 큰 그래디언트 버퍼, 체크포인트해야 할 활성화 메모리, 또는 XLA가 제거하지 못한 임시 텐서들입니다.²²¹
디버깅 전략은 여러 기법을 통해 메모리 풋프린트를 반복적으로 줄이는 것을 포함합니다. 그래디언트 체크포인팅은 활성화를 저장하는 대신 역전파 과정에서 재계산합니다. Optimizer state 샤딩은 Adam 모멘텀과 분산을 디바이스 간에 분산시킵니다. Mixed precision은 FP32 대비 메모리를 2배 줄입니다. 마이크로배칭은 하나의 큰 배치 대신 작은 배치들을 순차적으로 처리합니다.²²²
고급 메모리 최적화는 컴파일러 결정을 이해할 것을 요구합니다. xla_dump_to 플래그는 XLA가 계산 그래프를 어떻게 변환했는지 보여주는 중간 표현을 내보냅니다. IR을 분석하면 융합이 성공했는지, 불필요한 복사가 어디서 발생하는지, 어떤 연산이 예상보다 많은 메모리를 할당하는지를 드러냅니다.²²³
Input Pipeline Analyzer
CPU 전처리는 종종 TPU 훈련의 병목지점이 됩니다. Input Pipeline Analyzer는 데이터 로딩이 가속기 소비를 따라가는지 아니면 TPU가 배치를 기다리며 유휴 상태에 있는지를 식별합니다.²²⁴
이 도구는 호스트 측 분석(CPU 전처리, 데이터 증강, 배치 어셈블리)과 디바이스 측 실행(실제 TPU 계산)을 분리합니다. 입력 집약적 워크로드는 CPU 사용률이 피크일 때 데이터 로딩 중 디바이스 사용률이 떨어지는 것을 보여줍니다. 컴퓨트 집약적 워크로드는 CPU가 편안하게 따라가면서 높은 디바이스 사용률을 유지합니다.²²⁵
최적화 전략은 병목지점 위치에 따라 다릅니다. 느린 호스트 전처리는 더 많은 CPU 코어에 걸쳐 데이터 로딩을 병렬화하거나, 샘플당 증강 복잡성을 줄이거나, 소비 전에 배치를 미리 가져오는 것이 도움됩니다. 디바이스 측 병목지점은 데이터 파이프라인 튜닝보다는 모델 아키텍처 변경, 더 나은 융합, 또는 샤딩 조정을 필요로 합니다.²²⁶
## Tensor Processing Unit의 미래
Google의 7세대 아키텍처 진화는 특화된 AI 가속기에서 지속적인 혁신을 보여줍니다. Ironwood의 FP8 지원, 대용량 메모리 용량, 9,216개 칩 superpod 확장은 미래 개발의 궤적을 시사합니다.²²⁷
정밀도 감소는 특정 작업에서 FP4 또는 더 낮은 수준까지 지속될 가능성이 높습니다. 새로운 연구에 따르면 많은 신경망 작업이 신중한 훈련 절차를 통해 극도의 양자화를 허용합니다. 미래의 TPU는 FP4 순방향 패스, FP8 역방향 패스, FP32 최적화기 업데이트를 갖춘 혼합 정밀도 시스템을 구현할 수 있습니다.²²⁸
메모리 용량은 모델 크기 증가와의 경쟁에 직면해 있습니다. 현재의 최첨단 모델들은 이미 가속기 메모리에 부담을 주어 정교한 병렬 처리 전략을 필요로 합니다. 차세대 TPU는 3D XPoint나 저항성 RAM과 같은 비휘발성 메모리 기술을 통합하여 DRAM의 전력 소비 없이 테라바이트 규모의 온패키지 메모리를 구현할 수 있을 것입니다.²²⁹
광학 인터커넥트는 회로 스위칭을 넘어 광학 컴퓨팅 요소를 포함하도록 확장될 수 있습니다. 연구에서는 최소한의 전력으로 광속으로 실행되는 포토닉 행렬 곱셈을 탐구하고 있으며, 이는 특정 작업을 위한 광학 보조 프로세서로 전자 systolic array를 보강할 가능성이 있습니다.²³⁰
희소성 지원은 임베딩을 넘어 일반적인 희소 선형 대수로 확장될 가능성이 높습니다. 신경망 가지치기 기술은 가중치의 90% 이상을 품질 손실 없이 0으로 만들 수 있음을 보여줍니다. 미래의 아키텍처는 명시적으로 계산하고 폐기하는 대신 0값 계산을 기본적으로 건너뛸 수 있을 것입니다.²³¹
TPU 성공의 기반이 되는 아키텍처 원칙—도메인 특화, 맞춤형 인터커넥트, 공동 설계된 소프트웨어 스택, 건물 규모 오케스트레이션—은 점점 더 특화된 가속기의 미래를 가리킵니다. 만능 프로세서보다는 훈련 대 추론, 합성곱 네트워크 대 transformer, 밀집 대 희소 모델, 짧은 대 긴 시퀀스에 최적화된 가속기를 보게 될 수 있습니다.²³²
오늘날 AI 인프라를 구축하는 엔지니어들은 TPU 아키텍처를 깊이 이해해야 합니다. Google Cloud에 배포하거나, 가속기 시장에서 Google과 경쟁하거나, 차세대 ML 시스템을 설계할 때, TPU에 구현된 설계 원칙과 트레이드오프는 AI 워크로드가 하드웨어에 요구하는 근본적인 진실을 보여줍니다. systolic array 수학, 메모리 계층 설계, 인터커넥트 토폴로지, 컴파일러 최적화 전략은 TPU 자체를 훨씬 뛰어넘어 적용 가능한 수십 년간 축적된 지혜를 나타냅니다.
TPU 대 GPU를 정의하는 특화와 범용성 사이의 긴장은 무한히 지속될 것입니다. TPU는 좁은 워크로드에서 극도의 효율성을 위해 유연성을 희생합니다. GPU는 더 넓은 적용 가능성을 위해 최고 효율성을 희생합니다. 어느 접근법도 지배적이지 않습니다—최적의 선택은 전적으로 워크로드 특성, 규모, 비용 제약, 운영 요구사항에 달려 있습니다. 대규모 AI에서 성공하는 조직들은 단일 플랫폼으로 표준화하기보다는 워크로드 요구사항에 가속기 아키텍처를 맞추는 이종 전략을 점점 더 채택하고 있습니다.
Anthropic의 백만 칩 TPU 투입은 이 아키텍처가 최고 규모에서 생산 성숙도를 달성했음을 보여줍니다. 2026년에 온라인으로 제공될 멀티 기가와트 배포는 AI가 달성할 수 있는 경계를 넓히는 모델을 훈련할 것이며, 이러한 모델을 가능하게 하는 인프라는 소수의 조직만이 달성한 엔지니어링 정교함을 구현합니다. systolic array의 65,536개 곱셈-누적 유닛이 최첨단 모델을 훈련하기 위해 어떻게 협력하는지 이해하는 것은 AI의 미래를 진지하게 생각하는 모든 사람에게 중요합니다.
참고문헌
-
Google Cloud Press Corner, "Anthropic to Expand Use of Google Cloud TPUs and Services," October 23, 2025, https://www.googlecloudpresscorner.com/2025-10-23-Anthropic-to-Expand-Use-of-Google-Cloud-TPUs-and-Services.
-
TrendForce, "Google Unveils 7th-Gen TPU Ironwood with 9,216-Chip Superpod, Taking Aim at NVIDIA," November 7, 2025, https://www.trendforce.com/news/2025/11/07/news-google-unveils-7th-gen-tpu-ironwood-with-9216-chip-superpod-taking-aim-at-nvidia/.
-
Norman P. Jouppi et al., "TPU v4: An Optically Reconfigurable Supercomputer for Machine Learning with Hardware Support for Embeddings," in Proceedings of the 50th Annual International Symposium on Computer Architecture (2023), arXiv:2304.01433.
-
Anthropic, "Expanding our use of Google Cloud TPUs and Services," Anthropic News, October 2025, https://www.anthropic.com/news/expanding-our-use-of-google-cloud-tpus-and-services.
-
Google Cloud Blog, "Quantifying the performance of the TPU, our first machine learning chip," April 2017, https://cloud.google.com/blog/products/gcp/quantifying-the-performance-of-the-tpu-our-first-machine-learning-chip.
-
Norman P. Jouppi et al., "In-Datacenter Performance Analysis of a Tensor Processing Unit," Proceedings of the 44th Annual International Symposium on Computer Architecture (2017), arXiv:1704.04760.
-
Jouppi et al., "In-Datacenter Performance Analysis."
-
Jouppi et al., "In-Datacenter Performance Analysis."
-
Jonathan Hui, "AI Chips: Google TPU," Medium, accessed December 2025, https://jonathan-hui.medium.com/ai-chips-tpu-3fa0b2451a2d.
-
Wikipedia, "Bfloat16 floating-point format," accessed December 2025, https://en.wikipedia.org/wiki/Bfloat16_floating-point_format.
-
Henry Ko, "TPU Deep Dive," 개인 블로그, accessed December 2025, https://henryhmko.github.io/posts/tpu/tpu.html.
-
Wikipedia, "Tensor Processing Unit," accessed December 2025, https://en.wikipedia.org/wiki/Tensor_Processing_Unit.
-
Wikipedia, "Tensor Processing Unit."
-
Wikipedia, "Tensor Processing Unit."
-
Ko, "TPU Deep Dive."
-
Jouppi et al., "TPU v4: An Optically Reconfigurable Supercomputer."
-
Jouppi et al., "TPU v4: An Optically Reconfigurable Supercomputer."
-
Jouppi et al., "TPU v4: An Optically Reconfigurable Supercomputer."
-
Jouppi et al., "TPU v4: An Optically Reconfigurable Supercomputer."
-
OpenXLA Project, "A deep dive into SparseCore for Large Embedding Models (LEM)," accessed December 2025, https://openxla.org/xla/sparsecore.
-
JAX Scaling Guide, "How to Think About TPUs," accessed December 2025, https://jax-ml.github.io/scaling-book/tpus/.
-
JAX Scaling Guide, "How to Think About TPUs."
-
Ko, "TPU Deep Dive."
-
JAX Scaling Guide, "How to Think About TPUs."
-
Google Cloud Blog, "Introducing Trillium, sixth-generation TPUs," May 2024, https://cloud.google.com/blog/products/compute/introducing-trillium-6th-gen-tpus.
-
Google Cloud Blog, "Introducing Trillium."
-
Google Cloud Blog, "Introducing Trillium."
-
Google Cloud Blog, "Introducing Trillium."
-
Google Cloud Blog, "Introducing Trillium."
-
Google Blog, "Ironwood: The first Google TPU for the age of inference," November 2025, https://blog.google/products/google-cloud/ironwood-tpu-age-of-inference/.
-
XPU.pub, "Google Adds FP8 to Ironwood TPU; Can It Beat Blackwell?" April 16, 2025, https://xpu.pub/2025/04/16/google-ironwood/.
-
TrendForce, "Google Unveils 7th-Gen TPU Ironwood."
-
The Register, "Google's 7th-gen Ironwood TPUs promise 42 AI exaFLOPS pods," April 10, 2025, https://www.theregister.com/2025/04/10/googles_7thgen_ironwood_tpus_debut/.
-
TrendForce, "Google Unveils 7th-Gen TPU Ironwood."
-
Ko, "TPU Deep Dive."
-
XPU.pub, "Google Adds FP8 to Ironwood TPU."
-
Google Cloud Press Corner, "Anthropic to Expand Use."
-
Telesens, "Understanding Matrix Multiplication on a Weight-Stationary Systolic Architecture," July 30, 2018, https://telesens.co/2018/07/30/systolic-architectures/.
-
Telesens, "Understanding Matrix Multiplication."
-
Jouppi et al., "In-Datacenter Performance Analysis."
-
Telesens, "Understanding Matrix Multiplication."
-
CP Lu, "Should We All Embrace Systolic Arrays?" Medium, accessed December 2025, https://cplu.medium.com/should-we-all-embrace-systolic-array-df3830f193dc.
-
Google Cloud Documentation, "TPU architecture," accessed December 2025, https://docs.cloud.google.com/tpu/docs/system-architecture-tpu-vm.
-
Google Cloud Documentation, "TPU architecture."
-
Hui, "AI Chips: Google TPU."
-
Telnyx, "Architecture insights: MXU and TPU components," accessed December 2025, https://telnyx.com/learn-ai/mxu-tpu.
-
Ko, "TPU Deep Dive."
-
Jouppi et al., "TPU v4: An Optically Reconfigurable Supercomputer."
-
SemiEngineering, "Tensor Processing Unit (TPU)," accessed December 2025, https://semiengineering.com/knowledge_centers/integrated-circuit/ic-types/processors/tensor-processing-unit-tpu/.
-
TrendForce, "Google Unveils 7th-Gen TPU Ironwood."
-
SemiEngineering, "Tensor Processing Unit (TPU)."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Google Cloud Documentation, "Cloud TPU performance guide," accessed December 2025, https://cloud.google.com/tpu/docs/performance-guide.
-
OpenXLA Project, "A deep dive into SparseCore."
-
OpenXLA Project, "A deep dive into SparseCore."
-
OpenXLA Project, "A deep dive into SparseCore."
-
Jouppi et al., "TPU v4: An Optically Reconfigurable Supercomputer."
-
OpenXLA Project, "A deep dive into SparseCore."
-
Jouppi et al., "TPU v4: An Optically Reconfigurable Supercomputer."
-
OpenXLA Project, "A deep dive into SparseCore."
-
JAX Scaling Guide, "How to Think About TPUs."
-
JAX Scaling Guide, "How to Think About TPUs."
-
JAX Scaling Guide, "How to Think About TPUs."
-
Ko, "TPU Deep Dive."
-
JAX Scaling Guide, "How to Think About TPUs."
-
JAX Scaling Guide, "How to Think About TPUs."
-
TrendForce, "Google Unveils 7th-Gen TPU Ironwood."
-
Ko, "TPU Deep Dive."
-
Anthropic, "Expanding our use of Google Cloud TPUs."
-
Jouppi et al., "TPU v4: An Optically Reconfigurable Supercomputer."
-
Jouppi et al., "TPU v4: An Optically Reconfigurable Supercomputer."
-
Jouppi et al., "TPU v4: An Optically Reconfigurable Supercomputer."
-
Jouppi et al., "TPU v4: An Optically Reconfigurable Supercomputer."
-
Ko, "TPU Deep Dive."
-
Jouppi et al., "TPU v4: An Optically Reconfigurable Supercomputer."
-
Leon Poutievski, "Mission Apollo: Landing Optical Circuit Switching at Datacenter Scale," LinkedIn, June 2022, https://www.linkedin.com/posts/leon-poutievski-8910a851_mission-apollo-landing-optical-circuit-switching-activity-6968472071534235649-cB4l.
-
Ko, "TPU Deep Dive."
-
Jouppi et al., "TPU v4: An Optically Reconfigurable Supercomputer."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Jouppi et al., "TPU v4: An Optically Reconfigurable Supercomputer."
-
JAX Scaling Guide, "How to Think About TPUs."
-
TrendForce, "Google Unveils 7th-Gen TPU Ironwood."
-
TrendForce, "Google Unveils 7th-Gen TPU Ironwood."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
OpenXLA Project, "XLA: Optimizing Compiler for Machine Learning," accessed December 2025, https://openxla.org/xla.
-
Daniel Snider and Ruofan Liang, "Operator Fusion in XLA: Analysis and Evaluation," 학술 논문, accessed December 2025, https://danielsnider.ca/papers/Operator_Fusion_in_XLA_Analysis_and_Evaluation.pdf.
-
Snider and Liang, "Operator Fusion in XLA."
-
APXML, "Memory-Aware Data Layout Transformations (NCHW/NHWC)," accessed December 2025, https://apxml.com/courses/compiler-runtime-optimization-ml/chapter-3-advanced-graph-level-optimizations/memory-aware-layout-transformations.
-
OpenXLA Project, "XLA."
-
PyTorch Documentation, "Pytorch/XLA Overview," accessed December 2025, https://docs.pytorch.org/xla/master/learn/xla-overview.html.
-
OpenXLA Project, "A deep dive into SparseCore."
-
Mangpo Phothilimthana et al., "A Flexible Approach to Autotuning Multi-Pass Machine Learning Compilers," PACT 2021, accessed December 2025, https://mangpo.net/papers/xla-autotuning-pact2021.pdf.
-
JAX Documentation, "Introduction to parallel programming," accessed December 2025, https://docs.jax.dev/en/latest/sharded-computation.html.
-
GitHub, "jax-ml/jax: Composable transformations of Python+NumPy programs," accessed December 2025, https://github.com/jax-ml/jax.
-
OpenXLA Project, "Shardy Guide for JAX Users," accessed December 2025, https://openxla.org/shardy/getting_started_jax.
-
JAX Documentation, "Introduction to parallel programming."
-
OpenXLA Project, "Shardy Guide for JAX Users."
-
OpenXLA Project, "Shardy Guide for JAX Users."
-
JAX Documentation, "Introduction to parallel programming."
-
OpenXLA Project, "Shardy Guide for JAX Users."
-
PyTorch Documentation, "Pytorch/XLA Overview."
-
GitHub, "RFC: Evolving PyTorch/XLA for a more native experience on TPU," Issue #9684, accessed December 2025, https://github.com/pytorch/xla/issues/9684.
-
Google Cloud Blog, "PyTorch/XLA 2.4 improves Pallas and adds 'eager mode,'" accessed December 2025, https://cloud.google.com/blog/products/ai-machine-learning/pytorch-xla-2-4-improves-pallas-and-adds-eager-mode/.
-
PyTorch Documentation, "Pytorch/XLA Overview."
-
PyTorch Documentation, "Custom Kernels via Pallas," accessed December 2025, https://docs.pytorch.org/xla/master/features/pallas.html.
-
PyTorch Documentation, "Custom Kernels via Pallas."
-
PyTorch Documentation, "Custom Kernels via Pallas."
-
vLLM Blog, "vLLM TPU: A New Unified Backend Supporting PyTorch and JAX on TPU," October 16, 2025, https://blog.vllm.ai/2025/10/16/vllm-tpu.html.
-
GitHub, "pytorch/xla," accessed December 2025, https://github.com/pytorch/xla.
-
StackGpu, "FP8, BF16, and INT8: How Low-Precision Formats Are Revolutionizing Deep Learning Throughput," Medium, accessed December 2025, https://medium.com/@StackGpu/fp8-bf16-and-int8-how-low-precision-formats-are-revolutionizing-deep-learning-throughput-e6c1f3adabc2.
-
Wikipedia, "Bfloat16 floating-point format."
-
Wikipedia, "Bfloat16 floating-point format."
-
Paulius Micikevicius et al., "FP8 Formats for Deep Learning," arXiv:2209.05433, September 2022.
-
XPU.pub, "Google Adds FP8 to Ironwood TPU."
-
Micikevicius et al., "FP8 Formats for Deep Learning."
-
Google Cloud Blog, "Accurate Quantized Training (AQT) for TPU v5e," accessed December 2025, https://cloud.google.com/blog/products/compute/accurate-quantized-training-aqt-for-tpu-v5e.
-
StackGpu, "FP8, BF16, and INT8."
-
Jeffrey Tse, "Understanding the FP64, FP32, FP16, BFLOAT16, TF32, FP8 Formats," 개인 블로그, December 9, 2024, https://jeffreytse.net/computer/2024/12/09/understanding-the-fp64-fp32-fp16-bfloat16-tf32-fp8-formats.html.
-
PyTorch Blog, "PyTorch/XLA SPMD: Scale Up Model Training and Serving with Automatic Parallelization," accessed December 2025, https://pytorch.org/blog/pytorch-xla-spmd/.
-
OpenXLA Project, "Shardy Guide for JAX Users."
-
JAX Documentation, "Introduction to parallel programming."
-
OpenXLA Project, "Shardy Guide for JAX Users."
-
Ko, "TPU Deep Dive."
-
JAX Documentation, "Introduction to parallel programming."
-
Anthropic, "Expanding our use of Google Cloud TPUs."
-
JAX Documentation, "Introduction to parallel programming."
-
JAX Documentation, "Introduction to parallel programming."
-
Adam Roberts et al., "Scaling Up Models and Data with t5x and seqio," arXiv:2203.17189, March 2022.
-
Roberts et al., "Scaling Up Models and Data."
-
JAX Documentation, "Introduction to parallel programming."
-
JAX Documentation, "Introduction to parallel programming."
-
OpenXLA Project, "Shardy Guide for JAX Users."
-
Roberts et al., "Scaling Up Models and Data."
-
Roberts et al., "Scaling Up Models and Data."
-
Ko, "TPU Deep Dive."
-
MLCommons, "Benchmark MLPerf Training," accessed December 2025, https://mlcommons.org/benchmarks/training/.
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
HPCwire, "MLPerf Training v5.0 Benchmark Results Reflect Rapid Growth in the Field of AI," June 2025, https://www.hpcwire.com/off-the-wire/mlperf-training-v5-0-benchmark-results-reflect-rapid-growth-in-the-field-of-ai/.
-
MLCommons, "MLCommons Releases New MLPerf Inference v5.0 Benchmark Results," April 2025, https://mlcommons.org/2025/04/mlperf-inference-v5-0-results/.
-
Ko, "TPU Deep Dive."
-
Google Cloud Blog, "TPU v4 enables performance, energy and CO2e efficiency gains," accessed December 2025, https://cloud.google.com/blog/topics/systems/tpu-v4-enables-performance-energy-and-co2e-efficiency-gains.
-
TrendForce, "Google Unveils 7th-Gen TPU Ironwood."
-
Google Cloud Blog, "Quantifying the performance of the TPU."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Artech Digital, "Energy-Efficient GPU vs. TPU Allocation," accessed December 2025, https://www.artech-digital.com/blog/energy-efficient-gpu-vs-tpu-allocation.
-
Wikipedia, "Tensor Processing Unit."
-
XPU.pub, "Google Adds FP8 to Ironwood TPU."
-
Ko, "TPU Deep Dive."
-
Google Cloud Blog, "TPU v4 enables performance, energy and CO2e efficiency gains."
-
ByteBridge, "GPU and TPU Comparative Analysis Report," Medium, accessed December 2025, https://bytebridge.medium.com/gpu-and-tpu-comparative-analysis-report-a5268e4f0d2a.
-
ByteBridge, "GPU and TPU Comparative Analysis Report."
-
Anthropic, "Expanding our use of Google Cloud TPUs."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
DataCamp, "Understanding TPUs vs GPUs in AI: A Comprehensive Guide," accessed December 2025, https://www.datacamp.com/blog/tpu-vs-gpu-ai.
-
Ko, "TPU Deep Dive."
-
DataCamp, "Understanding TPUs vs GPUs in AI."
-
Grigory Sapunov, "FP64, FP32, FP16, BFLOAT16, TF32, and other members of the ZOO," Medium, accessed December 2025, https://moocaholic.medium.com/fp64-fp32-fp16-bfloat16-tf32-and-other-members-of-the-zoo-a1ca7897d407.
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Snider and Liang, "Operator Fusion in XLA."
-
APXML, "Memory-Aware Data Layout Transformations."
-
Google Cloud Blog, "How Lightricks trains video diffusion models at scale with JAX on TPU," accessed December 2025, https://cloud.google.com/blog/products/media-entertainment/how-lightricks-trains-video-diffusion-models-at-scale-with-jax-on-tpu.
-
CloudOptimo, "TPU vs GPU: What's the Difference in 2025?" accessed December 2025, https://www.cloudoptimo.com/blog/tpu-vs-gpu-what-is-the-difference-in-2025/.
-
Phoenix NAP, "TPU vs. GPU: Differences Explained," accessed December 2025, https://phoenixnap.com/kb/tpu-vs-gpu.
-
CloudOptimo, "TPU vs GPU."
-
DataCamp, "Understanding TPUs vs GPUs in AI."
-
Tailscale, "TPU vs GPU: Which Is Better for AI Infrastructure in 2025?" accessed December 2025, https://tailscale.com/learn/what-is-tpu-vs-gpu.
-
DataCamp, "Understanding TPUs vs GPUs in AI."
-
DataCamp, "Understanding TPUs vs GPUs in AI."
-
PyTorch Documentation, "Custom Kernels via Pallas."
-
Phoenix NAP, "TPU vs. GPU: Differences Explained."
-
Ko, "TPU Deep Dive."
-
OpenMetal, "TPU vs GPU: Pros and Cons," accessed December 2025, https://openmetal.io/docs/product-guides/private-cloud/tpu-vs-gpu-pros-and-cons/.
-
OpenMetal, "TPU vs GPU: Pros and Cons."
-
Phoenix NAP, "TPU vs. GPU: Differences Explained."
-
PRIMO.ai, "Processing Units - CPU, GPU, APU, TPU, VPU, FPGA, QPU," accessed December 2025, https://primo.ai/index.php?title=Processing_Units_-_CPU%2C_GPU%2C_APU%2C_TPU%2C_VPU%2C_FPGA%2C_QPU.
-
DataCamp, "Understanding TPUs vs GPUs in AI."
-
Google Cloud Documentation, "Profile your model on Cloud TPU VMs," accessed December 2025, https://cloud.google.com/tpu/docs/cloud-tpu-tools.
-
DataCamp, "Understanding TPUs vs GPUs in AI."
-
Ko, "TPU Deep Dive."
-
GitHub, "RFC: Evolving PyTorch/XLA."
-
Google Cloud Press Corner, "Anthropic to Expand Use."
-
TrendForce, "Google Unveils 7th-Gen TPU Ironwood."
-
Maginative, "Anthropic Secures 1M Google TPUs While Keeping Amazon as Primary Training Partner," accessed December 2025, https://www.maginative.com/article/anthropic-secures-1m-google-tpus-while-keeping-amazon-as-primary-training-partner/.
-
Anthropic, "A postmortem of three recent issues," Engineering Blog, August 2025, https://www.anthropic.com/engineering/a-postmortem-of-three-recent-issues.
-
Anthropic, "A postmortem of three recent issues."
-
AI Magazine, "Why Anthropic Uses Google Cloud TPUs for AI Infrastructure," accessed December 2025, https://aimagazine.com/news/why-anthropic-uses-google-cloud-tpus-for-ai-infrastructure.
-
Google Cloud Blog, "Ironwood TPUs and new Axion-based VMs for your AI workloads," November 2025, https://cloud.google.com/blog/products/compute/ironwood-tpus-and-new-axion-based-vms-for-your-ai-workloads.
-
Ko, "TPU Deep Dive."
-
TrendForce, "Google Unveils 7th-Gen TPU Ironwood."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Google Cloud, "Tensor Processing Units (TPUs)," accessed December 2025, https://cloud.google.com/tpu.
-
TensorFlow Documentation, "Optimize TensorFlow performance using the Profiler," accessed December 2025, https://www.tensorflow.org/guide/profiler.
-
Google Cloud Documentation, "Profile your model on Cloud TPU VMs."
-
TensorFlow Documentation, "TensorFlow Profiler: Profile model performance," accessed December 2025, https://www.tensorflow.org/tensorboard/tensorboard_profiling_keras.
-
Google Cloud Documentation, "Profile your model on Cloud TPU VMs."
-
Google Cloud Blog, "PyTorch/XLA: Performance debugging on Cloud TPU VM: Part III," accessed December 2025, https://cloud.google.com/blog/topics/developers-practitioners/pytorchxla-performance-debugging-cloud-tpu-vm-part-iii.
-
Google Cloud Blog, "PyTorch/XLA: Performance debugging Part III."
-
Google Cloud Documentation, "Profile PyTorch XLA workloads," accessed December 2025, https://docs.cloud.google.com/tpu/docs/pytorch-xla-performance-profiling-tpu-vm.
-
TensorFlow Documentation, "Optimize TensorFlow performance using the Profiler."
-
TensorFlow Documentation, "Optimize TensorFlow performance using the Profiler."
-
Ko, "TPU Deep Dive."
-
Google Cloud Documentation, "Cloud TPU performance guide."
-
TensorFlow Documentation, "Optimize TensorFlow performance using the Profiler."
-
TensorFlow Documentation, "Optimize TensorFlow performance using the Profiler."
-
TensorFlow Documentation, "Optimize TensorFlow performance using the Profiler."
-
TrendForce, "Google Unveils 7th-Gen TPU Ironwood."
-
Tse, "Understanding the FP64, FP32, FP16, BFLOAT16, TF32, FP8 Formats."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."
-
Ko, "TPU Deep Dive."


