
تُشغّل وحدات معالجة Tensor من Google غالبية نماذج الذكاء الاصطناعي المتطورة التي تتفاعل معها يومياً، ومع ذلك يبقى معظم المهندسين غير مألوفين بشكل مفاجئ مع بنيتها المعمارية. بينما تهيمن GPU من NVIDIA على أذهان المطورين، تقوم TPU بصمت بتدريب وخدمة Gemini 2.0 و Claude وعشرات النماذج الحدودية الأخرى بمقاييس من شأنها إفلاس معظم المؤسسات التي تستخدم البنية التحتية التقليدية لـ GPU. التزمت Anthropic مؤخراً بنشر أكثر من مليون شريحة TPU—تمثل أكثر من جيجاوات من قدرة الحوسبة—لتدريب نماذج Claude المستقبلية.¹ يقدم جيل Ironwood الأحدث من Google 42.5 exaflops من حوسبة FP8 عبر superpods بـ 9,216 شريحة، مقياس يعيد تعريف ما تعنيه البنية التحتية للذكاء الاصطناعي في الإنتاج.²
التطور التقني وراء TPU يمتد إلى ما هو أبعد من مقاييس الأداء البسيطة. هذه المعالجات تجسد فلسفة تصميم مختلفة جوهرياً عن GPU، تتاجر بالمرونة متعددة الأغراض مقابل التخصص الشديد في ضرب المصفوفات وعمليات tensor. المهندسون الذين يفهمون بنية TPU يمكنهم استغلال المصفوفات النظامية 256×256 التي تعالج 65,536 عملية ضرب-تراكم لكل دورة، والاستفادة من مسرعات SparseCore الجيل الثالث للأحمال كثيفة التضمين، وبرمجة مفاتيح الدوائر البصرية التي تعيد تكوين طوبولوجيات مراكز البيانات متعددة petabit في أقل من 10 nanoseconds.³ تمتد البنية المعمارية من كل شيء بدءاً من قرارات التصميم على مستوى الترانزستور إلى تنسيق الحاسوب العملاق على مستوى المبنى.
المحتوى التقني القادم يتطلب انتباهاً دقيقاً. نفحص سبعة أجيال من تطور TPU، ونشرح رياضيات المصفوفات النظامية وأنماط تدفق البيانات، ونستكشف التسلسلات الهرمية للذاكرة من بلاطات SRAM إلى قنوات HBM3e، ونحلل تحسينات مترجم XLA على مستوى التمثيل الوسيط، ونحقق في سبب تنفيذ العمليات الجماعية أسرع بـ 10× من مجموعات GPU المكافئة القائمة على Ethernet.⁴ ستواجه مواصفات على مستوى السجلات، ونمذجة أداء دقيقة الدورات، والمقايضات المعمارية التي تجعل TPU أكثر قوة وأكثر قيوداً من GPU في الوقت نفسه. العمق هنا يخدم المهندسين الذين يبنون الجيل التالي من البنية التحتية للذكاء الاصطناعي والباحثين الذين يدفعون حدود ما يمكن للمسرعات الحالية تحقيقه.
التطور: سبعة أجيال من الابتكار في البنية المعمارية
TPU v1: تخصص الاستنتاج فقط (2015)
نشرت Google أول وحدة معالجة الموترات في عام 2015 لمعالجة مشكلة حرجة: أعباء عمل الاستنتاج في الشبكات العصبية كانت تهدد بمضاعفة البصمة المركزية لمراكز البيانات في الشركة.⁵ قام المهندسون بتصميم TPU v1 حصريًا للاستنتاج، وإزالة قدرات التدريب بالكامل لتعظيم الأداء وكفاءة الطاقة للنماذج المنتشرة. تضمنت الشريحة مصفوفة نظامية 256×256 من وحدات الضرب والتجميع 8-بت، مما يوفر 92 تيرا عملية في الثانية بقوة تصميم حراري تتراوح من 28-40 واط فقط.⁶
جسدت البنية المعمارية البساطة الجذرية. قامت وحدة ضرب المصفوفة الواحدة بمعالجة عمليات INT8 من خلال تدفق البيانات الثابت للوزن، حيث بقيت الأوزان ثابتة في المصفوفة النظامية بينما تتدفق التفعيلات أفقيًا عبر الشبكة. يتم نشر المجاميع الجزئية عموديًا، مما يلغي عمليات الكتابة الوسطية في الذاكرة للكامل ضرب المصفوفة. الشريحة، المتصلة بالأنظمة المضيفة عبر PCIe، اعتمدت على DDR3 DRAM للذاكرة الخارجية وعملت بتردد 700 MHz—محافظة عمدًا لكفاءة الطاقة.⁷
أبهرت مكاسب الأداء حتى مهندسي Google. حقق TPU v1 تحسينات من 30× إلى 80× في العمليات لكل واط مقارنة بـ CPUs و GPUs المعاصرة لأعباء عمل الاستنتاج في الإنتاج.⁸ تعاملت الشريحة مع ترتيب Google Search وخدمات الترجمة التي تعالج مليار طلب يوميًا وتوصيات YouTube لملياري مستخدم. نجح النجاح في التحقق من رؤية معمارية أساسية: المسرعات المبنية لأغراض محددة والمحسنة لأعباء العمل الضيقة يمكن أن تحقق تحسينات بحجم درجات مقارنة بالمعالجات ذات الأغراض العامة.
TPU v2: تمكين التدريب على نطاق واسع (2017)
حول الجيل الثاني TPUs من مسرعات الاستنتاج فقط إلى منصات تدريب كاملة. أعادت Google تصميم البنية المعمارية بأكملها حول عمليات النقطة العائمة، واستبدلت مصفوفة 256×256 INT8 بمضاعفات-مجمعات bfloat16 128×128 مزدوجة لكل نواة.⁹ احتوت كل شريحة على TensorCores اثنين يتشاركان 8GB من ذاكرة النطاق العالي لكل نواة، وهو ترقية ضخمة من DDR3 وفرت النطاق الذي تطلبه تدريب الشبكات العصبية.
أثبت دقة bfloat16 أنه حاسم لنجاح TPU v2. يحتفظ التنسيق بنفس نطاق الأس 8-بت كما في FP32 بينما يقلل المانتيسا إلى 7 بت، ويحافظ على النطاق الديناميكي للتدريب بينما يخفض متطلبات نطاق ذاكرة إلى النصف.¹⁰ لاحظ المهندسون أن دقة المانتيسا المقلصة حسنت فعليًا التعميم في العديد من النماذج من خلال العمل كشكل من أشكال التنظيم، بينما نطاق الأس FP32 الكامل منع مشكلات التدفق السفلي والعلوي التي ابتليت بها تدريب FP16.
الابتكار المعماري الذي ميز TPU v2 حقًا كان الربط البيني للشرائح (ICI). المسرعات السابقة تطلبت Ethernet أو InfiniBand للاتصال متعدد الشرائح، مما أدخل زمن الاستجابة وعقد ضيق النطاق. صممت Google روابط ثنائية الاتجاه عالية السرعة مخصصة التي ربطت كل TPU مباشرة بأربعة جيران في طوبولوجية طارة ثنائية الأبعاد.¹¹ مكن الربط "قرون" TPU v2 من حتى 256 شريحة للعمل كمسرع منطقي واحد، مع عمليات جماعية مثل all-reduce تنفذ أسرع بكثير من البدائل القائمة على الشبكة.
TPU v3: تدرج الأداء المبرد بالماء (2018)
دفعت Google سرعات الساعة وعدد النوى بقوة في TPU v3، مما يوفر 420 تيرافلوب لكل شريحة—أكثر من مضاعفة أداء v2.¹² أدت الكثافة القدرة المتزايدة لفرض تغيير معماري دراماتيكي: التبريد السائل. تطلبت كل قرنة TPU v3 بنية تحتية للتبريد بالماء، وهو انحراف من تصاميم التبريد بالهواء للأجيال السابقة ومعظم مسرعات مراكز البيانات.¹³
حافظت الشريحة على بنية MXU 128×128 المزدوجة لكن زادت العدد الإجمالي للنوى وحسنت نطاق الذاكرة. احتوت كل TPU v3 على أربع شرائح مع نواتين لكل منها، تتشارك 32GB من ذاكرة HBM الإجمالية عبر الشرائح.¹⁴ حصلت وحدات المعالجة الشعاعية على تحسينات لوظائف التفعيل وعمليات التطبيع وحسابات التدرج التي كثيرًا ما كانت عقدة ضيقة للتدريب على وحدات المصفوفة وحدها.
تدرجت النشريات إلى قرون 2048 شريحة باستخدام نفس طوبولوجية ICI طارة ثنائية الأبعاد كـ v2 لكن بنطاق أكبر لكل رابط. دربت Google نماذج أكبر تدريجيًا على قرون v3، مكتشفة أن قطر الشبكة المقلص لطوبولوجية الطارة (المسافة القصوى بين أي شريحتين تتدرج كـ N/2 بدلاً من N) قلل من نفقات الاتصال لكل من استراتيجيات التدريب المتوازي للبيانات والنموذج.¹⁵
TPU v4: اختراق تبديل الدائرة البصرية (2021)
مثل الجيل الرابع أهم قفزة معمارية لـ Google منذ TPU الأصلي. زاد المهندسون حجم القرنة إلى 4096 شريحة بينما قدموا تبديل الدائرة البصرية (OCS) للربط، وهي تقنية مستعارة من الاتصالات التي ثورت بنية تحتية ML على نطاق مركز البيانات.¹⁶
تضمنت بنية نواة TPU v4 أربع 128×128 MXUs لكل TensorCore إلى جانب وحدات شعاعية وقياسية محسنة. تشارك كل زوج TensorCore 128MB من الذاكرة المشتركة بالإضافة إلى ذاكرة الشعاع لكل نواة، مما يمكن أنماط تدرج البيانات وإعادة الاستخدام الأكثر تطورًا.¹⁷ تطورت طوبولوجية الشريحة من طارة ثنائية إلى ثلاثية الأبعاد، ربط كل TPU بستة جيران بدلاً من أربعة، مما قلل أكثر من قطر الشبكة وحسن نطاق القسم.
نظام تبديل الدائرة البصرية غير كل شيء حول النشر على نطاق واسع. بدلاً من الكابلات الثابتة بين TPUs، نشرت Google مبدلات بصرية قابلة للبرمجة التي يمكن أن تعيد تكوين بشكل ديناميكي أي الشرائح متصلة بأي. مرايا MEMS (أنظمة كهروميكانيكية دقيقة) توجه فعليًا أشعة الضوء لتوصيل أزواج TPU عشوائية معًا، مقدمة زمن استجابة صفري أساسًا ما عدا وقت انتقال الألياف البصرية.¹⁸ المبدلات تعيد التكوين في نوافذ أقل من 10 نانوثانية، أسرع من معظم مصافحات بروتوكول الشبكة.
مكنت بنية OCS قدرات كانت مستحيلة سابقًا. يمكن لـ Google توفير "شرائح" من أي حجم، من أربع شرائح إلى قرنة 4096 شريحة كاملة، من خلال برمجة المبدلات البصرية بشكل مناسب. الشرائح الفاشلة يمكن توجيهها حولها بسلاسة دون إسقاط رفوف كاملة. الأكثر إثارة، TPUs البعيدة فعليًا في مواقع مراكز بيانات مختلفة يمكن أن تكون متجاورة منطقيًا في طوبولوجية الشبكة، فصل التخطيط الفعلي والمنطقي بالكامل.¹⁹
قدم TPU v4 أيضًا SparseCore، معالج متخصص للتعامل مع عمليات التضمين المستخدمة كل يوم في أنظمة التوصية ونماذج الترتيب ونماذج اللغة الكبيرة مع تضمينات المفردات الضخمة. تضمن SparseCore أربعة معالجات مخصصة لكل شريحة، كل منها بـ 2.5MB من ذاكرة المسودة وتدفق بيانات محسن لأنماط وصول الذاكرة المتناثرة.²⁰ حققت النماذج مع التضمينات فائقة الكبر تسريعات 5-7× باستخدام 5% فقط من إجمالي مساحة قالب الشريحة وميزانية الطاقة.
TPU v5p و v5e: التخصص والنطاق (2022-2023)
قسمت Google الجيل الخامس إلى منتجين مميزين يستهدفان حالات استخدام مختلفة. أولى TPU v5p الأولوية للأداء الأقصى للتدريب على نطاق واسع، بينما حسن v5e للاستنتاج الفعال التكلفة ووظائف التدريب الأصغر.²¹
حقق TPU v5p حوالي 4.45 إكسافلوب في الثانية عبر قرون 8960 شريحة، أكثر من مضاعفة الحد الأقصى لحجم قرنة v4.²² وصل نطاق الربط إلى 4800 Gbps لكل شريحة، وربطت طوبولوجية الطارة ثلاثية الأبعاد الشرائح في قرون فائقة ضخمة 16×20×28. أدارت نسيج تبديل الدائرة البصرية 13824 منفذ بصري عبر 48 وحدة OCS لربط قرنة فائقة v5p كاملة، مما يمثل واحدًا من أكبر نشريات تبديل بصري إنتاجي في تاريخ الحوسبة.²³
اتخذ TPU v5e نهجًا مختلفًا، مقللاً عدد النوى وسرعة الساعة لتحقيق أهداف طاقة وتكلفة عدوانية. احتوت الشرائح المحسنة للاستنتاج على نواة TPU واحدة فقط لكل شريحة بدلاً من اثنين، وعادت إلى طوبولوجية الطارة ثنائية الأبعاد، والتي كانت كافية لأحجام القرون الأصغر.²⁴ مكن التبسيط المعماري Google من تسعير v5e تنافسيًا لأعباء العمل حيث الأداء المطلق أهمية أقل من الأداء لكل دولار.
TPU v6e Trillium: مضاعفة أداء المصفوفة أربع مرات (2024)
مثل Trillium نقطة انعطاف معمارية أخرى من خلال توسيع وحدة ضرب المصفوفة من 128×128 إلى 256×256 مضاعف-مجمع.²⁵ ضاعفت المصفوفة الأكبر FLOPs لكل دورة أربع مرات بنفس سرعة الساعة، مما يوفر 4.7× أداء الحوسبة الذروة لـ TPU v5e من خلال مزيج من MXU الموسع وترددات الساعة المتزايدة.
حصل نظام فرعي الذاكرة على ترقيات دراماتيكية بنفس القدر. ضاعفت سعة HBM إلى 32GB لكل شريحة، مع نطاق مضاعف بواسطة قنوات HBM الجيل التالي.²⁶ ضاعف نطاق الربط بين الشرائح بالمثل، مما يمكن قرون 256 شريحة Trillium للحفاظ على نطاق أعلى للنماذج التي أجهدت كل من الحوسبة والاتصال.²⁷
تضمن Trillium مسرع SparseCore الجيل الثالث، مع قدرات محسنة للتضمينات فائقة الكبر في أعباء عمل الترتيب والتوصية. حسن التصميم المحدث أنماط وصول الذاكرة وزاد النطاق المناسب بين SparseCores و HBM للنماذج المهيمنة بواسطة عمليات البحث التضمين بدلاً من ضربات المصفوفة.²⁸
تحسنت كفاءة الطاقة بـ 67% مقارنة بـ v5e رغم المكاسب الكبيرة في الأداء.²⁹ حققت Google مكاسب الكفاءة من خلال عقد العمليات المتقدمة والتحسينات المعمارية التي قللت العمل المهدر وإغلاق الطاقة الدقيق للوحدات غير المستخدمة أثناء العمليات التي لم تجهد كل أجزاء الشريحة بشكل متزامن.
TPU v7 Ironwood: عصر FP8 (2025)
TPU الجيل السابع من Google، المسمى رمزيًا Ironwood، يمثل أول TPU مصمم بدعم FP8 الأصلي ومحسن خصيصًا لـ "عصر الاستنتاج" بينما يحافظ على أداء التدريب المتطور.³⁰ تقدم كل شريحة Ironwood 4.6 بيتافلوب من حوسبة FP8 الكثيفة—متجاوزة قليلاً منافس NVIDIA's B200 عند 4.5 بيتافلوب—بينما تسحب 600W قدرة التصميم الحراري.³¹
توسع نظام الذاكرة إلى 192GB من ذاكرة HBM3e لكل شريحة، ست مرات سعة Trillium، مع نطاق يصل إلى 7.4TB/s.³² الزيادة الدراماتيكية في الذاكرة تمكن خدمة النماذج فائقة الكبر مع ذاكرات التخزين المؤقت للقيم المفتاحية التي تطلبت سابقًا توازي موتر معقد عبر مسرعات متعددة. صممت Google سعة الذاكرة خصيصًا لدعم النماذج متعددة الوسائط الناشئة وتطبيقات السياق الطويل التي تقترب من نوافذ مليون رمز.
يوفر ربط Ironwood 9.6 Tbps من نطاق ثنائي الاتجاه المجمع من خلال أربعة روابط ICI، مترجمًا إلى 1.2 TB/s من نطاق الذروة لكل شريحة.³³ تتدرج البنية من قرون 256 شريحة للنشريات الأصغر إلى قرون فائقة ضخمة 9216 شريحة تقدم 42.5 FP8 إكسافلوب من قدرة الحوسبة.³⁴ تقنية شبكة مركز بيانات Jupiter من Google يمكن نظريًا أن تدعم حتى 43 قرنة فائقة Ironwood في مجموعة واحدة—حوالي 400000 مسرع يمثل نطاق حوسبة لا يمكن تصوره تقريبًا.³⁵
دعم FP8 يمثل تحولاً أساسيًا في استراتيجية الدقة. أجيال TPU السابقة حاكت عمليات 8-بت باستخدام تقنيات برمجية، مما أدخل نفقات. ينفذ Ironwood وحدات ضرب-تجميع FP8 أصلية تدعم كل من تنسيقات E4M3 (4-بت أس، 3-بت مانتيسا) و E5M2 (5-بت أس، 2-بت مانتيسا).³⁶ دعم التنسيق المزدوج يمكن خلط E4M3 للمرور الأمامي حيث الدقة تهم أقل و E5M2 للمرور الخلفي حيث المحافظة على مقادير التدرج تمنع عدم استقرار التدريب.
التزام Anthropic بنشر أكثر من مليون شريحة Ironwood بدءًا من 2026 يظهر استعداد البنية للإنتاج. تخطط الشركة لاستغلال أكثر من جيجاوات من قدرة TPU—كافية لتشغيل مدينة صغيرة—حصريًا لتدريب وخدمة نماذج Claude.³⁷ النطاق يتفوق على حتى أكبر نشريات GPU المعروفة ويمثل رهانًا أساسيًا على بنية TPU لتطوير النماذج الرائدة.
مرجع سريع للجيل الحالي
تقدم الجداول التالية مواصفات قابلة للمسح للثلاث TPUs الجيل الحالي الأكثر صلة بنشريات الإنتاج في 2025:
جدول 1: مواصفات الحوسبة الأساسية
[caption id="" align="alignnone" width="1386"] المواصفاتTPU v5eTPU v5pTPU v6e (Trillium)TPU v7 (Ironwood) حجم مصفوفة MXU 128×128 128×128 256×256 256×256 MACs لكل دورة 16,384 16,384 65,536 65,536 ذروة BF16 TFLOPS ~197 ~459 ~918 ~2,300 (مقدر) ذروة FP8 PFLOPS غير متاح (محاكي) غير متاح (محاكي) غير متاح (محاكي) 4.6 دقة أصلية BF16, INT8 BF16, INT8 BF16, INT8 BF16, FP8, INT8 TensorCores/شريحة 1 2 1 1 [/caption]
المواصفاتTPU v5eTPU v5pTPU v6e (Trillium)TPU v7 (Ironwood) حجم مصفوفة MXU 128×128 128×128 256×256 256×256 MACs لكل دورة 16,384 16,384 65,536 65,536 ذروة BF16 TFLOPS ~197 ~459 ~918 ~2,300 (مقدر) ذروة FP8 PFLOPS غير متاح (محاكي) غير متاح (محاكي) غير متاح (محاكي) 4.6 دقة أصلية BF16, INT8 BF16, INT8 BF16, INT8 BF16, FP8, INT8 TensorCores/شريحة 1 2 1 1 [/caption]
جدول 2: الذاكرة والنطاق
[caption id="" align="alignnone" width="1380"]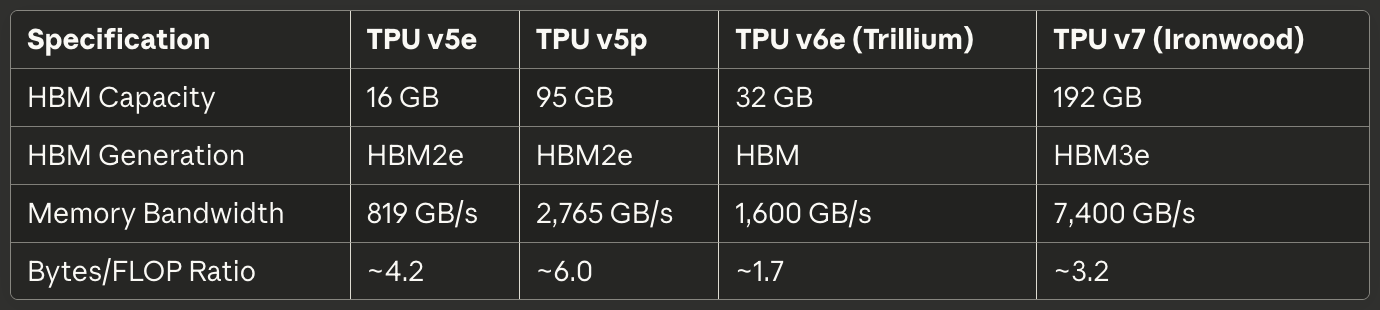 المواصفاتTPU v5eTPU v5pTPU v6e (Trillium)TPU v7 (Ironwood) سعة HBM 16 GB 95 GB 32 GB 192 GB جيل HBM HBM2e HBM2e HBM HBM3e نطاق الذاكرة 819 GB/s 2,765 GB/s 1,600 GB/s 7,400 GB/s نسبة Bytes/FLOP ~4.2 ~6.0 ~1.7 ~3.2 [/caption]
المواصفاتTPU v5eTPU v5pTPU v6e (Trillium)TPU v7 (Ironwood) سعة HBM 16 GB 95 GB 32 GB 192 GB جيل HBM HBM2e HBM2e HBM HBM3e نطاق الذاكرة 819 GB/s 2,765 GB/s 1,600 GB/s 7,400 GB/s نسبة Bytes/FLOP ~4.2 ~6.0 ~1.7 ~3.2 [/caption]
جدول 3: الربط والتدرج
[caption id="" align="alignnone" width="1384"]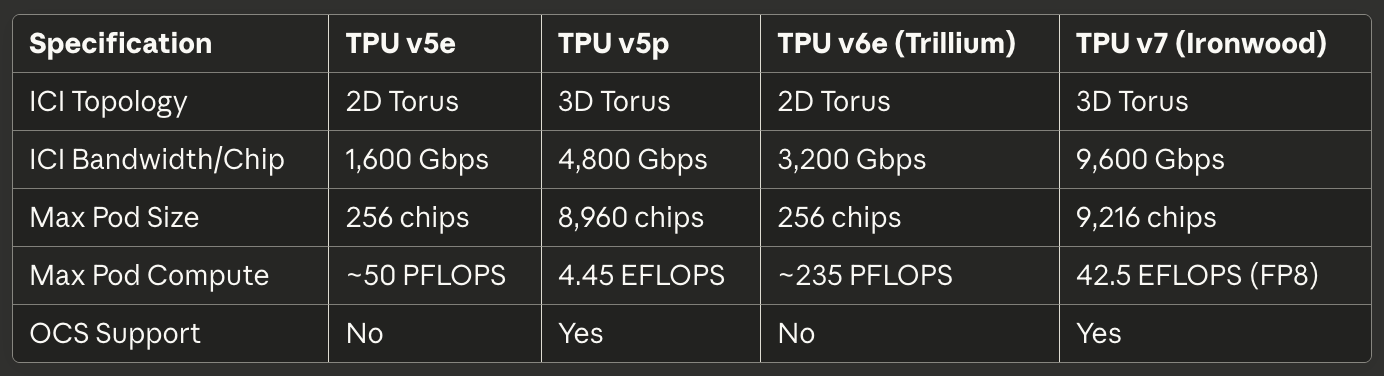 المواصفاتTPU v5eTPU v5pTPU v6e (Trillium)TPU v7 (Ironwood) طوبولوجية ICI طارة ثنائية الأبعاد طارة ثلاثية الأبعاد طارة ثنائية الأبعاد طارة ثلاثية الأبعاد نطاق ICI/شريحة 1,600 Gbps 4,800 Gbps 3,200 Gbps 9,600 Gbps أقصى حجم قرنة 256 شريحة 8,960 شريحة 256 شريحة 9,216 شريحة أقصى حوسبة قرنة ~50 PFLOPS 4.45 EFLOPS ~235 PFLOPS 42.5 EFLOPS (FP8) دعم OCS لا نعم لا نعم [/caption]
المواصفاتTPU v5eTPU v5pTPU v6e (Trillium)TPU v7 (Ironwood) طوبولوجية ICI طارة ثنائية الأبعاد طارة ثلاثية الأبعاد طارة ثنائية الأبعاد طارة ثلاثية الأبعاد نطاق ICI/شريحة 1,600 Gbps 4,800 Gbps 3,200 Gbps 9,600 Gbps أقصى حجم قرنة 256 شريحة 8,960 شريحة 256 شريحة 9,216 شريحة أقصى حوسبة قرنة ~50 PFLOPS 4.45 EFLOPS ~235 PFLOPS 42.5 EFLOPS (FP8) دعم OCS لا نعم لا نعم [/caption]
جدول 4: الطاقة والكفاءة
[caption id="" align="alignnone" width="1380"] المواصفاتTPU v5eTPU v5pTPU v6e (Trillium)TPU v7 (Ironwood) TDP ~120-200W ~250-300W ~120-200W 600W التبريد هواء سائل هواء سائل TFLOPS/واط (BF16) ~1.0-1.6 ~1.5-1.8 ~4.6-7.7 ~3.8 الطاقة مقابل الجيل السابق خط الأساس غير متاح 67% أفضل من v5e 2× أفضل من Trillium [/caption]
المواصفاتTPU v5eTPU v5pTPU v6e (Trillium)TPU v7 (Ironwood) TDP ~120-200W ~250-300W ~120-200W 600W التبريد هواء سائل هواء سائل TFLOPS/واط (BF16) ~1.0-1.6 ~1.5-1.8 ~4.6-7.7 ~3.8 الطاقة مقابل الجيل السابق خط الأساس غير متاح 67% أفضل من v5e 2× أفضل من Trillium [/caption]
جدول 5: حالات الاستخدام الموصى بها
[caption id="" align="alignnone" width="1382"] حالة الاستخدام أفضل خيار التبرير الاستنتاج محسن التكلفة TPU v5e: أقل تكلفة لكل استعلام استنتاج التدريب على نطاق واسع (>1000 شريحة) TPU v5p أو Ironwood طارة ثلاثية الأبعاد + OCS يمكن قرون ضخمة وظائف تدريب متوسطة (256 شريحة) TPU v6e Trillium أفضل أداء/واط، 4.7× حوسبة مقابل v5e النماذج مقيدة الذاكرة (>70B معاملات) Ironwood 192GB HBM يمكن أحجام دفع أكبر استنتاج السياق الطويل (>100K رموز) Ironwood سعة HBM تدعم ذاكرات KV ضخمة أعباء العمل الثقيلة التضمين TPU v5p أو Ironwood SparseCore + HBM كبير [/caption]
حالة الاستخدام أفضل خيار التبرير الاستنتاج محسن التكلفة TPU v5e: أقل تكلفة لكل استعلام استنتاج التدريب على نطاق واسع (>1000 شريحة) TPU v5p أو Ironwood طارة ثلاثية الأبعاد + OCS يمكن قرون ضخمة وظائف تدريب متوسطة (256 شريحة) TPU v6e Trillium أفضل أداء/واط، 4.7× حوسبة مقابل v5e النماذج مقيدة الذاكرة (>70B معاملات) Ironwood 192GB HBM يمكن أحجام دفع أكبر استنتاج السياق الطويل (>100K رموز) Ironwood سعة HBM تدعم ذاكرات KV ضخمة أعباء العمل الثقيلة التضمين TPU v5p أو Ironwood SparseCore + HBM كبير [/caption]
البنية المعمارية للأجهزة: داخل السيليكون
رياضيات المصفوفة النظامية وتدفق البيانات
تشكل وحدة ضرب المصفوفة قلب بنية TPU، وفهم المصفوفات النظامية يتطلب إدراك نهجها المختلف جوهريًا للتوازي مقارنة بمسارات GPU SIMD. تربط المصفوفة النظامية وحدات الضرب والتجميع في شبكة حيث تتدفق البيانات بإيقاع عبر البنية—ومن هنا "نظامية"، مستحضرة الضخ الإيقاعي للدم عبر القلب.³⁸
اعتبر مصفوفة TPU v6e النظامية 256×256 التي تنجز ضرب المصفوفة C = A × B. يحمل المهندسون مسبقًا أوزان مصفوفة B في 65536 وحدة ضرب-تجميع فردية مرتبة في شبكة. قيم تفعيل مصفوفة A تدخل من الحافة اليسرى وتتدفق أفقيًا عبر المصفوفة. كل وحدة MAC تضرب وزنها المخزن بالتفعيل الوارد، تضيف النتيجة إلى مجموع جزئي يصل من أعلى، وتمرر كل من التفعيل (أفقيًا) والمجموع الجزئي المحدث (عموديًا) إلى الوحدات المجاورة.³⁹
نمط تدفق البيانات يعني كل قيمة تفعيل تُعاد استخدامها 256 مرة كما تجتاز البعد الأفقي، وكل مجموع جزئي يجمع مساهمات من 256 ضربة كما يتدفق عموديًا. حاسمًا، كل النتائج الوسطية تمر مباشرة بين وحدات MAC المجاورة عبر أسلاك قصيرة بدلاً من الرحلة المستديرة إلى الذاكرة. تنجز البنية 65536 عملية ضرب-تجميع كل دورة ساعة، وأثناء ضرب المصفوفة بأكمله الذي يشمل ملايين العمليات المحتملة، صفر قيم وسطية تلمس DRAM أو حتى SRAM على الشريحة.⁴⁰
نمط تدفق البيانات ثابت الوزن يحسن للحالة الأكثر شيوعًا في استنتاج وتدريب الشبكات العصبية: ضرب عدة مصفوفات تفعيل مختلفة متكررًا بنفس مصفوفة الوزن. يحمل المهندسون الأوزان مرة واحدة، ثم يرسلون دفع تفعيل غير محدودة عبر المصفوفة دون إعادة التحميل. النمط يعمل بشكل استثنائي جيد للطبقات التحويلية والطبقات المتصلة بالكامل وعمليات Q·K^T و attention·V التي تهيمن على نماذج المحول.⁴¹
كفاءة الطاقة تنبع من إعادة استخدام البيانات والمحلية المكانية. قراءة قيمة من DRAM تستهلك حوالي 200× من الطاقة كعملية ضرب-تجميع واحدة.⁴² بإعادة استخدام كل وزن 256 مرة وكل تفعيل 256 مرة دون وصولات ذاكرة، تحقق المصفوفة النظامية نسب عمليات لكل واط مستحيلة للبنيات التي تنقل البيانات ذهابًا وإيابًا بين وحدات الحوسبة وهياكل الذاكرة.
ضعف المصفوفة النظامية يظهر مع أنماط الحوسبة الديناميكية أو غير المنتظمة. لأن البيانات تتدفق عبر الشبكة في جدول ثابت، تكافح البنية مع التنفيذ الشرطي والمصفوفات المتناثرة (إلا باستخدام SparseCore) والعمليات التي تتطلب أنماط وصول عشوائية. عدم المرونة يتاجر بالعمومية لكفاءة مفرطة على عبء عملها المستهدف: ضرب المصفوفة الكثيف مع أنماط وصول قابلة للتنبؤ.
البنية الداخلية لـ TensorCore
تحتوي كل شريحة TPU على واحد أو أكثر من TensorCores—وحدة المعالجة الكاملة التي تضم وحدة ضرب المصفوفة ووحدة المعالجة الشعاعية والوحدة القياسية التي تعمل بشكل متضافر.⁴³ يمثل TensorCore الكتلة البنائية الأساسية التي يستهدفها البرمجيات، وفهم التفاعل بين مكوناته الثلاثة يفسر كل من خصائص أداء TPU وأنماط البرمجة.
تنفذ وحدة ضرب المصفوفة 16000 عملية ضرب-تجميع لكل دورة على مدخلات bfloat16 أو FP8 مع تجميع FP32.⁴⁴ نهج الدقة المختلطة يحافظ على الدقة العددية في المجمع بينما يقلل نطاق الذاكرة للمدخلات. لاحظ المهندسون أن الحفاظ على دقة FP32 كاملة أثناء التجميع يمنع أخطاء الإلغاء الكارثية عند جمع مئات أو آلاف المنتجات الوسطية، بينما المدخلات قليلة الدقة نادرًا تؤثر على جودة النموذج النهائية.
تتعامل وحدة المعالجة الشعاعية مع العمليات غير المناسبة لبنية MXU الصلبة. وظائف التفعيل (ReLU، GELU، SiLU)، طبقات التطبيع (تطبيع الدفع، تطبيع الطبقة)، softmax، التجميع، dropout، والعمليات عنصر بعنصر تنفذ على بنية SIMD 128-مسار للـ VPU.⁴⁵ يعمل VPU على أنواع بيانات FP32 و INT32، مما يوفر الدقة المطلوبة للعمليات الحساسة عدديًا مثل softmax، حيث يمكن للأسس والقسمة أن تخلق نطاقات ديناميكية كبيرة.
تنسق الوحدة القياسية TensorCore بأكمله. ينفذ المعالج أحادي الخيط تدفق التحكم، ويحسب عناوين الذاكرة لأنماط الفهرسة المعقدة، ويبدأ نقل DMA من ذاكرة النطاق العالي إلى ذاكرة الشعاع.⁴⁶ لأن الوحدة القياسية تعمل أحادية الخيط، كل TensorCore يمكن أن ينشئ طلب DMA واحد فقط لكل دورة—عقدة ضيقة للعمليات كثيفة الذاكرة التي لا تشبع نطاق حوسبة MXU أو VPU.
هيكل الذاكرة الذي يغذي TensorCore يحدد الأداء القابل للتحقيق بقدر قدرة الحوسبة الخام. تعمل ذاكرة الشعاع (VMEM) كـ SRAM مدارة بالبرمجيات حصرية لكل TensorCore، عادة بحجم عشرات الميجابايت. مجمع XLA يجدول صراحة حركة البيانات بين HBM و VMEM، مقررًا ما يُرحل إلى الذاكرة المحلية السريعة ومتى تُكتب النتائج عائدة.⁴⁷
الذاكرة المشتركة (CMEM)، الموجودة في TPU v4 والأجيال اللاحقة، توفر مجموعة مشتركة أكبر يمكن الوصول إليها لكل TensorCores على الشريحة. خصصت بنية TPU v4 128MB من CMEM مشتركة بين TensorCores اثنين، مما يمكن أنماط منتج-مستهلك أكثر تطورًا حيث مخرجات نواة واحدة تغذي مدخلات نواة أخرى دون الرحلة المستديرة إلى HBM.⁴⁸
آثار نموذج البرمجة مهمة جدًا. لأن الوحدة القياسية أحادية الخيط وذاكرة الشعاع تتطلب إدارة صريحة، برمجة TPU تشبه تطوير أنظمة مدمجة عصر التسعينات أكثر من برمجة GPU الحديثة. CUDA يجرد حركة الذاكرة مع الذاكرة الموحدة والذاكرات التخزينية المدارة بالأجهزة؛ رمز TPU (سواء أُنتج بواسطة XLA أو كُتب يدويًا في Pallas) يجب أن ينسق صراحة كل نقل بيانات. التحكم اليدوي يمكن التحسين الخبير لكن يرفع المستوى للأداء المختص.
بنية ذاكرة النطاق العالي
تستخدم TPUs الحديثة HBM (ذاكرة النطاق العالي)، أو HBM3e، تقنية ذاكرة مختلفة جذريًا من DDR SDRAM الموجودة في CPUs، و GDDR المستخدمة في العديد من GPUs. تكدس HBM عدة قوالب DRAM عموديًا باستخدام فتحات عبر السيليكون (TSVs)، ثم تضع الكومة مجاورة مباشرة لقالب المعالج على وسيطة سيليكون.⁴⁹ المسار الكهربائي القصير والواجهة العريضة تمكن نطاق أعلى دراماتيكيًا من تقنيات الذاكرة التقليدية.
ينفذ TPU v7 Ironwood 192GB من HBM3e بنطاق إجمالي 7.4 TB/s.⁵⁰ ينقسم نظام الذاكرة إلى قنوات متعددة، كل منها توفر وصول مستقل لجزء منفصل من السعة الإجمالية. يجب على مجمع XLA والتشغيل تقسيم الموترات بعناية عبر قنوات HBM لتعظيم الوصول المتوازي وتجنب النقاط الساخنة حيث قناة واحدة تشبع بينما أخريات تبقى خاملة.
عرض واجهة الذاكرة يتفوق على DRAM التقليدي. حيث قناة DDR5 قد توفر 64 بت من العرض، قناة HBM تمتد عادة 1024 بت.⁵¹ العرض المفرط يمكن نطاق عالي بترددات ساعة متواضعة نسبيًا، مقللًا استهلاك الطاقة وتحديات تكامل الإشارة مقارنة بدفع واجهات ضيقة إلى ترددات متعددة الجيجاهرتز.
خصائص زمن الاستجابة تختلف بشكل كبير من أنظمة ذاكرة GPU. تفتقر TPUs للذاكرات التخزينية المدارة بالأجهزة ما عدا محافظ محلية صغيرة، لذا تعتمد البنية على البرمجيات التي ترحل البيانات صراحة إلى VMEM قبل أن تحتاجها وحدات الحوسبة بوقت كافٍ. نقص الذاكرات التخزينية يعني زمن استجابة الذاكرة يؤثر مباشرة على الأداء إلا إذا نجح المجمع في إخفاء زمن الاستجابة من خلال الجلب المسبق والتخزين المؤقت المزدوج.⁵²
حدود سعة الذاكرة تهيمن على العديد من أعباء العمل أكثر من نطاق الحوسبة. نموذج 175 مليار معامل مع أوزان bfloat16 يتطلب 350GB لتخزين المعاملات—متجاوزًا بالفعل 192GB HBM لـ Ironwood حتى قبل احتساب التفعيلات وحالات المحسن أو محافظ التدرج. تدريب مثل هذه النماذج يطلب تقنيات متطورة مثل نقاط تفتيش التدرج وتقطيع حالة المحسن عبر شرائح متعددة وجدولة دقيقة لتحديثات المعاملات لتقليل بصمة الذاكرة.⁵³
تشغيل TPU يفرض متطلبات تخطيط موتر محددة لتعظيم كفاءة MXU. لأن المصفوفة النظامية تعالج البيانات في بلاطات 128×8، يجب أن تتماشى الموترات مع هذه الأبعاد لتجنب إهدار الحشو.⁵⁴ المصفوفات ضعيفة الحجم تجبر الأجهزة على معالجة بلاطات جزئية مع MACs تبقى خاملة، مقللة مباشرة استخدام FLOPS. المجمع يحاول حشو وإعادة تشكيل الموترات تلقائيًا، لكن اختيارات التخطيط الواعية في بنية النموذج يمكن أن تحسن الأداء بشكل كبير.
SparseCore: تسريع التضمين المتخصص
بينما تتفوق وحدة ضرب المصفوفة في عمليات المصفوفة الكثيفة، أعباء العمل كثيفة التضمين تظهر خصائص مختلفة جذريًا. نماذج التوصية وأنظمة الترتيب ونماذج اللغة الكبيرة تصل كثيرًا لجداول تضمين ضخمة (غالبًا مئات الجيجابايت) من خلال فهارس غير منتظمة تعتمد على البيانات. تدفق البيانات المنظم لـ MXU لا يوفر ميزة لهذه أنماط الوصول المتناثرة للذاكرة، مما يحفز بنية SparseCore المتخصصة.⁵⁵
ينفذ SparseCore معالج تدفق بيانات مبلط مختلف جوهريًا من المصفوفة النظامية لـ MXU. تضمن TPU v4 أربعة SparseCores لكل شريحة، كل منها يحتوي على 16 بلاطة حوسبة.⁵⁶ كل بلاطة تعمل كوحدة تدفق بيانات مستقلة مع ذاكرة المسودة المحلية (SPMEM) وعناصر المعالجة. البلاطات تنفذ بشكل متوازي، معالجة مجموعات فرعية منفصلة من عمليات التضمين بشكل متزامن.
هيكل الذاكرة يضع البيانات الساخنة في SPMEM صغيرة وسريعة بينما يبقي جداول التضمين الكاملة في HBM. مجمع XLA يحلل أنماط وصول التضمين لتحديد أي موترات تضمين تستحق التخزين المؤقت في SPMEM مقابل الجلب عند الطلب من HBM.⁵⁷ الاستراتيجية تشبه هياكل ذاكرة تخزينية CPU التقليدية، لكن مع البرمجيات بدلاً من الأجهزة تتخذ قرارات الوضع.
تتصل SparseCores مباشرة بقنوات HBM، متجاوزة مسار ذاكرة TensorCore بالكامل. الاتصال المخصص يمنع عمليات التضمين من المنافسة مع عمليات المصفوفة الكثيفة لنطاق الذاكرة، مما يمكن كليهما للمتابعة بشكل متوازي.⁵⁸ التقسيم يعمل بشكل استثنائي جيد للنماذج مثل نماذج التوصية للتعلم العميق (DLRMs) التي تتداخل طبقات الشبكة العصبية الكثيفة مع عمليات بحث التضمين الكبيرة.
استراتيجية mod-sharding توزع التضمينات عبر SparseCores بحساب target_sc_id = col_id % num_total_sparse_cores.⁵⁹ وظيفة التقطيع البسيطة تضمن توازن الحمل عندما تكون معرفات التضمين موزعة بشكل موحد، لكن يمكن أن تخلق نقاط ساخنة لأنماط الوصول المنحرفة. المهندسون الذين يعملون مع البيانات الحقيقية غالبًا يحتاجون لتحليل توزيعات تردد التضمين وإعادة توازن التقطيع يدويًا لتجنب عقد الضيق.
مكاسب الأداء من SparseCore تصل 5-7× مقارنة بتنفيذ عمليات مطابقة على MXU و VPU، بينما تستهلك 5% فقط من مساحة قالب الشريحة والطاقة.⁶⁰ ميزة الكفاءة الدراماتيكية تنبع من بناء تدفق البيانات لأغراض العمليات المتناثرة بدلاً من إجبارها عبر بنية تحتية مصفوفة كثيفة. مبدأ التخصص ينطبق بشكل تكراري داخل بنية TPU: تمامًا كما تختص TPUs ما وراء تصميم GPUs ذي الأغراض العامة، تختص SparseCores ما وراء تصميم TPUs الموجه للمصفوفة.
قدم SparseCore الجيل الثالث لـ Trillium عرض SIMD متغير (8 عناصر لـ FP32، 16 لـ bfloat16) وأنماط وصول ذاكرة محسنة، مقللًا النطاق المهدر من القراءات غير المحاذية.⁶¹ التطور المعماري يظهر استثمار Google المستمر في تسريع التضمين كما تتجه نماذج اللغة الكبيرة نحو مفردات أكبر وأنماط إنتاج محسنة بالاسترجاع أكثر تطورًا.
تقنية الربط المتداخل: توصيل الحاسوب الفائق
معمارية الربط المتداخل بين الرقائق (ICI)
الربط المتداخل بين الرقائق هو التقنية الحاسمة التي تمكن وحدات TPU من العمل كحواسيب فائقة موحدة بدلاً من مسرّعات معزولة. على عكس وحدات GPU التي تتواصل عبر شبكات Ethernet أو InfiniBand، تطبق ICI روابط تسلسلية عالية السرعة مخصصة تربط وحدات TPU المتجاورة مباشرة بزمن استجابة على نطاق الميكروثانية وعرض نطاق ترددي بالتيرابت في الثانية.⁶²
تطور الطوبولوجيا عبر أجيال TPU يعكس المتطلبات المتغيرة لتوسيع نطاق الكبسولة. وحدات TPU v2 و v3 و v5e و v6e تطبق طوبولوجيات الطارة ثنائية الأبعاد حيث تتصل كل رقاقة بجيرانها الأربعة الأقرب (شمال، جنوب، شرق، وغرب).⁶³ الروابط تلتف حول الحدود، مما يخلق طوبولوجيا منطقية على شكل دونات تلغي الرقائق الطرفية ذات الاتصالات الأقل. شبكة 16×16 من 256 وحدة TPU تقدم بالتالي خصائص عرض نطاق وزمن استجابة موحدة بغض النظر عن أي رقاقتين تتواصلان.
وحدات TPU v4 و v5p ترقت إلى طوبولوجيات الطارة ثلاثية الأبعاد مع اتصال كل رقاقة بستة جيران.⁶⁴ البُعد الإضافي يقلل قطر الشبكة - العدد الأقصى للقفزات بين أي رقاقتين - من تقريباً 2√N إلى 3∛N. لكبسولة من 4,096 رقاقة، تنخفض القفزات القصوى من حوالي 128 إلى 48، مما يقلل بشكل كبير من زمن الاستجابة الأسوأ للعمليات المتزامنة عالمياً مثل all-reduce.
الهيكل الطاري يقدم ميزة حاسمة أخرى: عرض نطاق تقطيع متساوي بغض النظر عن كيفية تقسيم أعباء العمل عبر الرقائق. أي قطع يقسم الطارة نصفين يعبر نفس عدد الروابط، مما يمنع الحالات المرضية حيث الوضع السيء للمهام يخلق عقد ضيقة في الشبكة.⁶⁵ عرض النطاق المتساوي للتقطيع يبسط الجدولة ويمكّن إعادة التكوين لمفتاح الدائرة الضوئية المناقشة أدناه.
مواصفات عرض النطاق تتوسع بشكل مثير عبر الأجيال. وحدة TPU v6e تقدم 13 TB/s من عرض نطاق ICI لكل رقاقة.⁶⁶ وحدة TPU v5p وصلت إلى 4,800 Gbps لكل رقاقة عبر ستة روابط طارة ثلاثية الأبعاد.⁶⁷ Ironwood تطبق أربعة روابط ICI بعرض نطاق إجمالي ثنائي الاتجاه 9.6 Tbps، مما يترجم إلى 1.2 TB/s لكل رقاقة.⁶⁸ للمقارنة، واجهة شبكة 400GbE من الطراز الأول تقدم عرض نطاق ثنائي الاتجاه 50GB/s - أقل بمرتبة من حجم من ICI لـTPU الحديثة.
تقنية الروابط داخل الرفوف تستخدم كابلات النحاس المرفقة مباشرة (DAC) للمسافات القصيرة بين الرقائق في نفس مكعب 4×4×4.⁶⁹ الاتصالات النحاسية تقلل التكلفة والطاقة بينما تقدم عرض النطاق المطلوب للرقائق المترابطة بإحكام التي تنفذ عمليات متزامنة. روابط بين المكعبات وعلى نطاق الكبسولة تنتقل إلى أجهزة الإرسال الضوئية، مقايضة تكلفة وطاقة أعلى للمسافة وعرض النطاق المطلوب لامتداد رفوف مركز البيانات.
العمليات الجماعية تستغل الخصائص الفريدة لـICI. عمليات all-reduce و all-gather و reduce-scatter كثيراً ما تتزامن التفعيلات والتدرجات عبر الرقائق أثناء التدريب. على مجموعات GPU القائمة على Ethernet، هذه الجماعيات تعبر شبكة هرمية مع مفاتيح وكابلات وبطاقات واجهة شبكة، مما يدخل زمن استجابة في كل قفزة. ICI لـTPU تطبق خوارزميات جماعية محسنة مباشرة في الأجهزة، منفذة عمليات all-reduce أسرع بـ10 مرات من تطبيقات GPU المعادلة القائمة على Ethernet.⁷⁰
التبديل الضوئي للدائرة: إعادة التكوين الديناميكي للطوبولوجيا
نشر Google لتبديل الدائرة الضوئية (OCS) مع TPU v4 مثّل واحداً من أهم الابتكارات في شبكات مراكز البيانات في عقود. الشبكات التقليدية المحولة للحزم - سواء Ethernet أو InfiniBand - تؤسس اتصالات منطقية بتوجيه الحزم قفزة بقفزة عبر مفاتيح تفحص الرؤوس وتحول إلى منافذ الإخراج المناسبة. OCS بدلاً من ذلك يستخدم عناصر ضوئية قابلة للبرمجة لإنشاء مسارات ضوء فيزيائية مباشرة بين نقاط النهاية، مما يلغي زمن استجابة التبديل تماماً.⁷¹
التقنية الأساسية تعتمد على مرايا MEMS (أنظمة كهروميكانيكية دقيقة) التي تدور فيزيائياً لإعادة توجيه أشعة الضوء. مرسل على TPU A يرسل ضوء إلى OCS. مرايا صغيرة داخل OCS تدور لتعكس شعاع الضوء ذلك إلى مستقبل على TPU B. الاتصال يصبح مساراً ضوئياً مباشراً من A إلى B مع زمن استجابة إضافي صفر تقريباً ما عدا انتشار الضوء عبر الألياف.⁷²
سرعة إعادة التكوين تحدد عملية OCS في أنظمة الإنتاج. نشر Google يحقق أوقات تبديل أقل من 10 نانوثانية - أسرع من أوقات الذهاب والإياب النموذجية لبروتوكولات الشبكة.⁷³ سرعة إعادة التكوين تمكن تغييرات الطوبولوجيا الديناميكية المطابقة لمتطلبات أعباء العمل دون تعطيل المهام الجارية أو تطلب هندسة ترافيك منسقة بعناية.
وحدة TPU v5p أظهرت OCS على نطاق ضخم. المعمارية تستخدم مفاتيح دائرة ضوئية تقدم أربعة بيتابت في الثانية من عرض النطاق الإجمالي عبر نسيج التبديل.⁷⁴ كبسولة فائقة واحدة v5p تتطلب 48 وحدة OCS تدير 13,824 منفذ ضوئي لتوصيل 8,960 رقاقة في تكوين الطارة ثلاثية الأبعاد 16×20×28.⁷⁵ نظام التبديل يمثل واحداً من أكبر نشرات الشبكات الضوئية في أي بيئة حاسوبية.
OCS يقدم قدرات مستحيلة مع الشبكات التقليدية. الطوبولوجيا الفيزيائية والطوبولوجيا المنطقية تنفصلان تماماً - وحدتان TPU في أركان متقابلة من مركز البيانات تظهران كجيران متجاورين إذا أنشأ OCS مسارات ضوئية مباشرة. الرقائق أو الروابط الفاشلة يتم توجيهها حولها بإعادة برمجة المرايا لاستبعاد المكونات المعطوبة والحفاظ على الهيكل المنطقي للطارة. المهام الجديدة تتلقى "شرائح" من أي حجم ببرمجة OCS لإنشاء تكوينات كبسولة مناسبة دون إعادة تكبيل الرفوف فيزيائياً.⁷⁶
المعمارية تتكامل مع شبكة مركز بيانات Jupiter من Google للتوسع ما وراء كبسولة واحدة. Jupiter تقدم عرض نطاق تقطيع متعدد البيتابت في الثانية عبر مراكز بيانات كاملة باستخدام مفاتيح السيليكون المخصصة من Google ومستوى التحكم.⁷⁷ كبسولات TPU فائقة متعددة تتصل عبر نسيج Jupiter، مدعومة نظرياً مجموعات تصل إلى 400,000 مسرّع إذا سمحت سعة الشبكة.⁷⁸
خصائص استهلاك الطاقة والموثوقية تفضل تبديل الدائرة الضوئية لنشرات بحجم TPU. مفاتيح الحزم التقليدية تستهلك طاقة كبيرة لمعالجة وتحويل الحزم بمعدلات تيرابت في الثانية. مفاتيح OCS تستهلك طاقة فقط لتشغيل مرايا MEMS أثناء أحداث إعادة التكوين، ثم تجلس خاملة، تمرر الضوء بفقدان أدنى بينما الاتصالات تبقى مستقرة.⁷⁹ بساطة المعمارية تحسن الموثوقية بإلغاء معالجة الحزم المعقدة ومنطق التخزين المؤقت المعرض للأخطاء وشذوذ الأداء.
معمارية الكبسولة وخصائص التوسع
كبسولات TPU تمثل أكبر وحدة واحدة من وحدات TPU متصلة عبر ICI، مشكّلة مسرّعاً موحداً. الهيكل الفيزيائي يبنى هرمياً من الرقائق الفردية إلى الصواني إلى المكعبات إلى الرفوف إلى الكبسولات الكاملة.⁸⁰ فهم الهرمية مهم للاستدلال حول سعة الذاكرة وعرض نطاق الاتصال وتحمل الأخطاء على نطاقات مختلفة.
الوحدة البنائية الأساسية تتكون من أربع رقائق على صينية واحدة متصلة بـCPU مضيف عبر PCIe.⁸¹ اتصال PCIe يتعامل مع عمليات مستوى التحكم والتحميل الأولي للبرنامج والإدخال/الإخراج لبيانات التدريب ونتائج الاستنتاج. الاتصال الفعلي بين الرقائق للتدريب الموزع يتدفق عبر ICI بدلاً من PCIe، متجنباً عقد عرض نطاق PCIe.
ستة عشر صينية (64 رقاقة) تشكل مكعباً واحداً 4×4×4 - الوحدة الأساسية لبناء الكبسولة. داخل المكعب، جميع اتصالات ICI تستخدم كابلات النحاس المرفقة مباشرة لأن الرقائق تقيم في نفس الرف مع مسافات فيزيائية قصيرة.⁸² المكعب ينفذ طارة ثلاثية الأبعاد كاملة مع اتصالات التفاف، منشئاً وحدة 64 رقاقة مكتفية ذاتياً يمكنها نظرياً العمل بشكل مستقل.
كبسولات TPU v4 تتوسع إلى 64 مكعباً بإجمالي 4,096 رقاقة.⁸³ الاتصالات بين المكعبات تنتقل إلى روابط ضوئية مدارة بواسطة نسيج تبديل الدائرة الضوئية. OCS يمكنه توفير هذه الـ4,096 رقاقة ككبسولة واحدة هائلة، أو كبسولات مستقلة أصغر متعددة، أو إعادة تكوين ديناميكي وسط المهمة إذا تطلب الأمر. المرونة تمكن مشغلي مراكز البيانات من موازنة الاستخدام عبر أحجام ومأولويات مهام مختلفة.
وحدة TPU v5p دفعت نطاق الكبسولة إلى 8,960 رقاقة في طارة ثلاثية الأبعاد 16×20×28.⁸⁴ الأبعاد المحددة تعكس تحسين عرض النطاق والقطر الدقيق - التحليلات الأولية مهمة لطوبولوجيا الشبكة! الكبسولة تقدم 4.45 إكسافلوبس من الحوسبة وتمثل واحدة من أكبر تكوينات الكبسولة الواحدة المنشورة في الإنتاج.
Ironwood يدعم كبسولات 256 رقاقة للنشرات الأصغر وكبسولات فائقة 9,216 رقاقة لتدريب نماذج الحدود الضخمة.⁸⁵ تكوين الـ9,216 رقاقة يقدم 42.5 FP8 إكسافلوبس - حوسبة أكثر مما احتوته قائمة Top500 الكاملة للحواسيب الفائقة قبل خمس سنوات فقط.⁸⁶ النطاق يعيد تعريف ما يمكن للمؤسسات إنجازه بالتدريب المتزامن بدلاً من الأساليب المتدرجة أو غير المتزامنة.
كفاءة التوسع تحدد ما إذا كانت الكبسولات الأكبر تساعد فعلاً. عبء الاتصال يزيد مع حجم الكبسولة حيث تقضي الرقائق وقتاً أكثر في المزامنة بدلاً من الحوسبة. Google Research نشرت نتائج تُظهر كفاءة توسع 95% عند 32,768 TPU لأعباء عمل محددة، أي أن 32,768 TPU قدمت 95% من الأداء الذي يتوقعه التوسع الخطي المثالي.⁸⁷ الكفاءة تنبع من الجماعيات المعجلة بالأجهزة وتحويلات المترجم المحسنة والأساليب الخوارزمية الذكية لتقليل تردد مزامنة التدرج.
تحمل الأخطاء على نطاق الكبسولة يتطلب تعاملاً متطوراً. الاحتمال الإحصائي يضمن فشل المكونات في أي نظام بآلاف الرقائق تعمل باستمرار. مفتاح الدائرة الضوئية يمكّن التدهور الرشيق بإعادة التكوين حول المكونات الفاشلة. إنقاذ التدريب يحدث على فترات منتظمة (عادة كل بضع دقائق)، لذا فشل المهمة يتطلب إعادة تشغيل فقط من آخر نقطة إنقاذ بدلاً من البداية.⁸⁸
مجموعة البرمجيات: المترجمات، والأطر، ونماذج البرمجة
مترجم XLA: تحسين الرسوم البيانية للحوسبة
يشكل XLA (الجبر الخطي المُسرَّع) أساس مجموعة البرمجيات الخاصة بـ TPU، حيث يترجم عمليات الأطر عالية المستوى إلى كود آلة محسّن للتنفيذ على TPU.⁸⁹ يطبق المترجم تحسينات عدوانية مستحيلة في المترجمات عامة الغرض لأنه يستغل المعرفة المجالية حول أعباء عمل تعلم الآلة وخصائص معمارية TPU.
يمثل الدمج التحسين الأكثر تأثيراً في XLA. يحلل المترجم الرسوم البيانية للحوسبة لتحديد تسلسلات العمليات التي يمكن تنفيذها دون تجسيد tensors وسطية. مثال بسيط: العمليات على مستوى العناصر مثل relu(batch_norm(conv(x))) تتطلب عادة كتابة مخرجات الالتفاف إلى الذاكرة، وقراءتها للتطبيع المجمع، وكتابة تلك النتيجة إلى الذاكرة، والقراءة مرة أخرى لـ ReLU. يدمج XLA هذه العمليات في نواة واحدة تنتج مخرجات ReLU النهائية دون حركة مرور ذاكرة وسطية.⁹⁰
يتزايد تأثير الدمج مع معمارية TPU. تقيد عرض نطاق الذاكرة العديد من أعباء العمل أكثر من إنتاجية الحوسبة—يمكن لـ MXU تنفيذ ضرب المصفوفات أسرع من قدرة نظام الذاكرة على تغذيته بالبيانات. إزالة عمليات الكتابة والقراءة الوسطية من الذاكرة من خلال الدمج يترجم مباشرة إلى تحسينات في الأداء، وغالباً ما يحقق تسريع 2× أو أكثر للشبكات الثقيلة بدوال التفعيل.⁹¹
تحسن تحويلات تخطيط الذاكرة تخزين tensor لمتطلبات الأجهزة. غالباً ما تمثل الشبكات العصبية tensors في تنسيق NHWC (batch، height، width، channels) للفهرسة البديهية، لكن MXUs في TPU تعمل بأفضل شكل مع تخطيطات تتماشى مع بلاطات 128×8.⁹² يحول XLA تلقائياً ويعيد تشكيل ويحشو tensors لتتطابق مع تفضيلات الأجهزة، مدرجاً تحويلات التخطيط فقط عند الضرورة وأحياناً ينشر التخطيطات المفضلة للخلف عبر الرسم البياني لتقليل إجمالي عبء التحويل.
ينفذ المترجم طي ثوابت متطور وإزالة الكود الميت. تحتوي الرسوم البيانية لـ ML بشكل متكرر على رسوم فرعية تعتمد مخرجاتها فقط على الثوابت—معاملات التطبيع المجمع، ومعدلات dropout للاستدلال، وحسابات الشكل التي يمكن تنفيذها مرة واحدة بدلاً من كل مجموعة. يقيم XLA هذه الرسوم الفرعية في وقت الترجمة ويستبدلها بـ tensors ثابتة، مقللاً من العمل في وقت التشغيل.⁹³
يستغل التحسين عبر النسخ المتماثلة المعرفة حول التنفيذ الموزع. عند التدريب عبر نوى TPU متعددة، تتطلب عمليات معينة (مثل إحصائيات التطبيع المجمع) تجميعاً عبر جميع النسخ المتماثلة. يحدد XLA هذه الأنماط وينتج عمليات جماعية محسّنة تستغل تقليل الكل المُسرَّع بالأجهزة في ICI بدلاً من تنفيذ التجميع من خلال تمرير رسائل صريح.⁹⁴
يستهدف المترجم تمثيلاً وسطياً، Mosaic، خصيصاً لـ TPUs. يعمل Mosaic على مستوى تجريد أعلى من لغة التجميع لكن أقل من الرسم البياني للحوسبة المدخل. تكشف اللغة ميزات معمارية TPU، مثل المصفوفات الانقباضية وذاكرة المتجهات وتدريج VMEM، بينما تخفي التفاصيل منخفضة المستوى، مثل جدولة التعليمات وتخصيص السجلات.⁹⁵
تختار قدرات الضبط التلقائي أحجام البلاطات المثلى ومعاملات العمليات من خلال البحث التجريبي. يجرب نظام XLA Auto-Tuning (XTAT) استراتيجيات دمج مختلفة وتخطيطات ذاكرة وأبعاد بلاطات، ويحلل أداء كل متغير، ويختار أسرع تكوين.⁹⁶ يمكن أن يتطلب البحث وقت ترجمة كبير للنماذج المعقدة، لكنه ينتج تسريعات دراماتيكية في وقت التشغيل من خلال اكتشاف تحسينات مناقضة للبديهة نادراً ما يحددها البشر يدوياً.
JAX: التحويلات القابلة للتركيب و SPMD
يوفر JAX واجهة متوافقة مع NumPy للحوسبة العددية مع التفاضل التلقائي وترجمة JIT إلى XLA ودعم من الدرجة الأولى لتحويل البرامج.⁹⁷ نموذج البرمجة الوظيفية للإطار ونموذج التحويل القابل للتركيب يتماشى بطبيعته مع نماذج تنفيذ TPU وأنماط التوازي الموزع.
يطبق تجريد JAX الأساسي تحويلات رياضية على الدوال. Grad (f) يحسب تدرج f. Jit (f) يترجم f بـ JIT إلى XLA. vmap(f) يجعل f متجهة على بُعد جديد. الأمر المهم هو أن التحويلات تتركب: jit(grad(vmap(f))) يعمل كما هو متوقع تماماً، مترجماً دالة تدرج متجهة.⁹⁸ يمكّن النموذج التركيبي من بناء حلقات تدريب موزعة معقدة من مكونات بسيطة قابلة للاختبار.
يمثل SPMD (برنامج واحد، بيانات متعددة) نموذج التنفيذ الموزع لـ JAX. يكتب المبرمجون الكود كما لو كانوا يستهدفون جهازاً واحداً، ثم يضيفون تعليقات توضيحية للتقسيم تشير إلى كيفية تقسيم tensors عبر نوى TPU متعددة. يدرج مترجم XLA ونظام GSPMD (SPMD العام) تلقائياً عمليات الاتصال للحفاظ على دلالات البرنامج أثناء التنفيذ عبر الأجهزة الموزعة.⁹⁹
تستخدم التعليقات التوضيحية للتقسيم PartitionSpec لإعلان استراتيجيات التوزيع. PartitionSpec('batch', None) يقسم البُعد الأول لـ tensor عبر محور 'batch' في شبكة الأجهزة بينما يكرر البُعد الثاني. PartitionSpec(None, 'model') ينفذ توازي tensor بتقسيم البُعد الثاني. يمكن تركيب التعليقات التوضيحية مع أرقام tensor وأبعاد شبكة أجهزة تعسفية.¹⁰⁰
يزيل التوازي التلقائي لـ GSPMD كميات هائلة من الكود النموذجي. يتطلب التدريب الموزع التقليدي إدراج تجميع الكل يدوياً قبل العمليات التي تحتاج tensors كاملة، وتبعيث التقليل بعد حساب التدرجات الموزعة، وتقليل الكل للتقليلات الشاملة. يحلل GSPMD مواصفات التقسيم ويدرج تلقائياً الجماعيات المناسبة، محرراً المبرمجين للتركيز على الخوارزمية بدلاً من هندسة الاتصالات.¹⁰¹
ينشر المترجم قرارات التقسيم عبر الرسم البياني للحوسبة باستخدام حل القيود. إذا كانت العملية A تخرج tensor مقسم تستهلكه العملية B، يستنتج GSPMD التقسيم الأمثل لـ B بناءً على كيفية استخدام المخرجات، مدرجاً عمليات إعادة التقسيم فقط حيث ضروري رياضياً.¹⁰² يمنع الاستدلال التلقائي "مأكولات التقسيم" التي تصيب الكود الموزع المكتوب يدوياً.
يوفر JAX تحكماً دقيقاً عندما يفشل التشغيل التلقائي. with_sharding_constraint يجبر تقسيماً محدداً في مواقع الرسم البياني، متجاوزاً الاستدلال التلقائي. تعليقات PJIT (JIT المتوازي) المخصصة تحدد وضع الجهاز الدقيق واستراتيجيات التقسيم لمسارات الكود الحرجة للأداء. يمكّن النموذج المتدرج من النماذج الأولية السريعة مع التقسيم التلقائي بينما يدعم تحسين الخبراء حيث مطلوب.¹⁰³
ظهر Shardy كخليفة لـ GSPMD في 2025، منفذاً خوارزميات انتشار قيود محسّنة وتعاملاً أفضل مع الأشكال الديناميكية.¹⁰⁴ يكشف النظام الجديد فرص تحسين إضافية من خلال التفكير في اختيارات التقسيم مجتمعة عبر مناطق رسم بياني أكبر بدلاً من عملية تلو الأخرى.
PyTorch/XLA: جلب PyTorch إلى TPUs
يمكّن PyTorch/XLA من تشغيل نماذج PyTorch على TPUs مع تغييرات كود قليلة، مجسراً الفجوة بين نموذج البرمجة الحتمي لـ PyTorch وترجمة XLA القائمة على الرسم البياني.¹⁰⁵ يوازن التكامل بين الحفاظ على تجربة مطور PyTorch وكشف تحسينات خاصة بـ TPU.
ينبع التحدي الأساسي من فلسفة التنفيذ الحريص لـ PyTorch. ينفذ PyTorch العمليات فوراً عند تنفيذ بيانات Python، مما يمكّن التصحيح بأدوات قياسية وتدفق تحكم طبيعي. يتطلب XLA التقاط رسوم بيانية حوسبة كاملة قبل الترجمة، مما يخلق توتراً بين التنفيذ الحريص وفوائد الأداء لترجمة الرسم البياني.¹⁰⁶
قدم PyTorch/XLA 2.4 دعم الوضع الحريص، معالجاً عدم التطابق في المقاومة. ينفذ التطبيق تتبعاً ديناميكياً لعمليات PyTorch في رسوم XLA البيانية، مما يسمح للمطورين بكتابة كود PyTorch قياسي بينما لا يزالون يستفيدون من ترجمة XLA.¹⁰⁷ يقايض الوضع بعض فرص تحسين الترجمة مقابل سرعة التطوير وبساطة التصحيح.
يبقى وضع الرسم البياني المسار الأساسي للانتشار الإنتاجي. يعلم المطورون صراحة الدوال لترجمة XLA باستخدام decorators أو APIs الترجمة. تمكّن التعليقات التوضيحية الصريحة تحسيناً عدوانياً لكنها تتطلب فهماً لأي العمليات يجب دمجها في رسم XLA بياني واحد مقابل التنفيذ المستقل.¹⁰⁸
يجلب تكامل Pallas تطوير نواة مخصصة إلى PyTorch/XLA. يوفر Pallas لغة منخفضة المستوى لكتابة نوى TPU عندما يقصر الدمج التلقائي لـ XLA أو تتطلب العمليات المتخصصة تحسيناً يدوياً.¹⁰⁹ تكشف اللغة التسلسل الهرمي لذاكرة TPU (VMEM، CMEM، HBM) ووحدات الحوسبة (MXU، VPU) بينما تبقى على مستوى أعلى من التجميع الخام.
تنفذ نوى Pallas المدمجة العمليات الحرجة للأداء مثل FlashAttention و PagedAttention. حساب الانتباه المبلط في FlashAttention يقلل متطلبات عرض نطاق الذاكرة من O(n²) إلى O(n) لطول تسلسل n، مما يمكّن النماذج من معالجة تسلسلات أطول بكثير ضمن ميزانيات ذاكرة ثابتة.¹¹⁰ يحسن PagedAttention إدارة ذاكرة التخزين المؤقت للمفاتيح والقيم للخدمة، محققاً تسريع 5× مقارنة بالتطبيقات المحشوة.¹¹¹
أثبت جسر PyTorch/XLA أهمية حاسمة لـ vLLM TPU—إطار خدمة عالي الأداء مصمم أصلاً لـ GPUs. يستخدم التطبيق فعلياً JAX كمسار خفض وسطي حتى لنماذج PyTorch، مستغلاً دعم التوازي المتفوق لـ JAX بينما يحافظ على توافق واجهة PyTorch.¹¹² حقق المعمارية تحسينات أداء 2-5× خلال 2025 مقارنة بالنماذج الأولية الأولى.
تستمر تحديات توافق النماذج رغم التحسينات. تفتقر بعض عمليات PyTorch إلى مكافئات XLA، مما يجبر العودة إلى تنفيذ CPU الذي يدهور الأداء. تدفق التحكم الديناميكي غير مدعوم جيداً بترجمة الرسم البياني، وغالباً ما يستلزم تغييرات معمارية لاستبدال السلوك الديناميكي ببدائل ثابتة قابلة للترجمة. يوثق مستودع PyTorch/XLA التوافق ويوفر أدلة هجرة للأنماط الإشكالية الشائعة.¹¹³
تنسيقات الدقة: BFloat16 و FP8 والتكميم
يمكّن دعم TPU للحساب بدقة مخفّضة تحسينات دراماتيكية في الأداء والذاكرة مع الحفاظ على جودة نموذج مقبولة. فهم الخصائص العددية للتنسيقات المختلفة ومتى تطبق كلاً منها يثبت أهميته الحاسمة لتحقيق الأداء الأمثل.¹¹⁴
يمثل BFloat16 رهان Google المبكر على التدريب بدقة مخفّضة، ظهر أول مرة في TPU v2. يحتفظ التنسيق بأس FP32 ذو 8 بت بينما يقطع mantissa إلى 7 بت (زائد بت الإشارة).¹¹⁵ نطاق الأس الكامل يمنع التدني والفيض الذي ابتلى التدريب المبكر بـ FP16، حيث هربت التدرجات بشكل متكرر من النطاق القابل للتمثيل في FP16.
تدخل mantissa المخفّضة خطأ تكميم لكنها نادراً ما تؤثر على جودة النموذج النهائية. لاحظ المهندسون أن النماذج المدربة في bfloat16 تطابق عادة خطوط الأساس المدربة بـ FP32 ضمن الضوضاء الإحصائية، على الأرجح لأن التكميم يعمل كشكل من أشكال التنظيم، مانعاً الإفراط في التلاؤم مع التفاصيل العددية الصغيرة.¹¹⁶ يخفض التنسيق إلى النصف متطلبات عرض نطاق وسعة الذاكرة مقارنة بـ FP32، مترجماً مباشرة إلى مكاسب أداء في أعباء العمل المقيدة بالذاكرة.
يأخذ FP8 الدقة المخفّضة إلى أبعد من ذلك، ضاغطاً الأوزان والتفعيلات إلى 8 بت. يوجد ترميزان قياسيان: E4M3 (أس 4 بت، mantissa 3 بت) يعطي الأولوية للدقة في التمريرات الأمامية، بينما E5M2 (أس 5 بت، mantissa 2 بت) يعطي الأولوية للنطاق في التمريرات الخلفية حيث تتفاوت مقادير التدرج بشكل واسع.¹¹⁷ ينفذ Ironwood دعماً أصلياً لـ FP8 للتنسيقين، بينما TPUs السابقة حاكت FP8 من خلال تحويلات برمجية.¹¹⁸
يمكّن الوعي بالتكميم أثناء التدريب النجاح العددي لـ FP8. النماذج المدربة من الصفر بـ FP8 أو المضبوطة بتقنيات واعية بـ FP8 تتعلم توزيعات أوزان تتحمل دقة التنسيق المحدودة. التكميم بعد التدريب (تحويل نماذج FP32 إلى FP8 بعد التدريب) غالباً ما يدهور الجودة دون معايرة دقيقة.¹¹⁹
يقدم تكميم INT8 وفورات ذاكرة أكبر وتسريعات استدلال. Accurate Quantized Training (AQT) من Google يمكّن تدريب INT8 على TPUs مع فقدان جودة قليل مقارنة بخطوط أساس bfloat16.¹²⁰ تطبق التقنية تدريباً واعياً بالتكميم من الصفر، مسمحة للنماذج بالتكيف مع قيود INT8 أثناء التعلم بدلاً من التقريب بعد التدريب.
تجمع استراتيجيات الدقة المختلطة التنسيقات بشكل استراتيجي. قد تستخدم التمريرات الأمامية FP8 للتفعيلات والأوزان، وتستخدم التمريرات الخلفية FP8 E5M2 أو bfloat16 للتدرجات، وتبقى حالات المحسّن في FP32 للاستقرار العددي أثناء تحديثات الأوزان.¹²¹ يوازن النهج المختلط السرعة والذاكرة والدقة، وغالباً ما يحقق 90%+ من جودة FP32 بينما يعمل أسرع بـ 4×.
تمتد مقايضات الدقة إلى ما وراء السرعة والذاكرة لتشمل اعتبارات الاستقرار العددي. التطبيع المجمع وتطبيع الطبقة و softmax تتطلب تعاملاً عددياً دقيقاً في الدقة المخفّضة. يمكن للأسس الكبيرة في softmax أن تفيض نطاقات FP8 أو bfloat16؛ طرح أقصى logit قبل الأس يمنع الفيض بينما يحافظ على التكافؤ الرياضي.¹²² ينفذ مترجم XLA هذه التحويلات تلقائياً عند الأمان، لكن العمليات المخصصة أحياناً تتطلب هندسة عددية يدوية.
نماذج البرمجة واستراتيجيات المعالجة المتوازية
SPMD والتقسيم التلقائي
يشكل نموذج البرنامج الواحد، البيانات المتعددة (SPMD) بشكل جوهري كيفية تفكير المبرمجين في تنفيذ TPU. بدلاً من كتابة كود تمرير الرسائل الصريح لتنسيق عمليات متعددة، يكتب المطورون برنامجاً واحداً ويقومون بتوصيف كيفية تقسيم البيانات عبر الأجهزة.¹²³ يتعامل المترجم مع التفاصيل الآلية للتوزيع والتواصل والمزامنة.
ينفذ GSPMD (General SPMD) منطق التقسيم التلقائي في XLA. يحلل النظام توصيفات تقسيم tensor وهيكل الرسم البياني الحاسوبي لتحديد مكان تنفيذ العمليات على أي أجهزة وما هو التواصل المطلوب للحفاظ على الدلالات الصحيحة.¹²⁴ يزيل التشغيل التلقائي فئات كاملة من الأخطاء الشائعة في الكود الموزع المكتوب يدوياً—أشكال tensor غير متطابقة، وترتيبات عمليات جماعية غير صحيحة، وحالات توقف من المزامنة غير السليمة.
يستنتج محرك انتشار القيود في المترجم قرارات التقسيم من الحد الأدنى من التوصيفات. غالباً ما يكفي توصيف تقسيم مدخلات ومخرجات النموذج فقط؛ ينشر GSPMD القيود من خلال العمليات الوسيطة ويختار تلقائياً توزيعات فعالة.¹²⁵ عندما توجد عدة تقسيمات صالحة لعملية ما، يقدر المترجم تكاليف التواصل للبدائل ويختار الخيار الأقل تكلفة.
تتداخل التحسينات المتقدمة التواصل مع الحوسبة. عمليات all-reduce التي تزامن التدرجات عبر النسخ يمكن أن تبدأ بمجرد اكتمال تدرجات الطبقة الأولى، وتنفذ بشكل متوازٍ مع التمريرات الخلفية للطبقات اللاحقة.¹²⁶ يجدول المترجم تلقائياً العمليات الجماعية لتعظيم التداخل، مما يقلل وقت التواصل المناسب بنسبة 2× أو أكثر مقارنة بالتنفيذ التسلسلي.
تبادل إعادة التجسيد الحوسبة بالذاكرة. بدلاً من تخزين جميع تفعيلات التمرير الأمامي لحوسبة التدرج، يعيد المترجم حوسبة التفعيلات بشكل انتقائي أثناء التمريرات الخلفية عندما يتجاوز ضغط الذاكرة العتبات.¹²⁷ تعمل المقايضة بشكل جيد بشكل خاص على TPU حيث تتفوق الحوسبة غالباً على عرض نطاق الذاكرة، مما يجعل إعادة الحوسبة أرخص من حركة مرور الذاكرة.
التوازي للبيانات، وتوازي tensor، والتوازي المتسلسل
يمثل توازي البيانات أكثر استراتيجيات التدريب الموزع وضوحاً: نسخ النموذج الكامل عبر N جهاز ومعالجة دُفع بيانات مختلفة على كل نسخة. بعد حوسبة التدرجات محلياً، تجمع all-reduce التدرجات عبر النسخ، وتطبق جميع الأجهزة تحديثات أوزان متطابقة.¹²⁸ يتوسع النهج خطياً حتى يهيمن وقت التواصل على وقت الحوسبة—عادة حوالي 1,000 GPU مع شبكات Ethernet ولكن أكثر من 10,000+ TPU مع ICI.¹²⁹
يقسم توازي tensor (يُسمى أيضاً توازي النموذج) العمليات الفردية عبر الأجهزة. ضرب المصفوفات Y = W @ X يقسم مصفوفة الأوزان W عبر الأجهزة، مع حوسبة كل جزء من الناتج.¹³⁰ تتيح الاستراتيجية تدريب نماذج تتجاوز ذاكرة الجهاز الواحد من خلال توزيع تخزين المعاملات والحوسبة.
يختلف نمط التواصل لتوازي tensor بشكل كبير عن توازي البيانات. بدلاً من all-reduce بعد كل طبقة، يتطلب توازي tensor all-gather قبل العمليات التي تتطلب tensor كاملة و reduce-scatter بعد الحوسبات الموزعة.¹³¹ يتوسع حجم التواصل مع حجم تفعيل النموذج بدلاً من حجم المعامل، مما يخلق اختناقات مختلفة عن توازي البيانات.
يقسم التوازي المتسلسل طبقات النموذج التسلسلية عبر الأجهزة، معالجة دُفع فرعية مختلفة على مراحل مختلفة في الوقت نفسه. قدم GPipe الاستراتيجية مع جدولة دقيقة لتعظيم استخدام خط الأنابيب مع حصر استخدام الذاكرة.¹³² يعالج كل جهاز التمرير الأمامي لدفعة فرعية واحدة، ويرسل التفعيلات إلى المرحلة التالية، ثم يعالج الدفعة الفرعية التالية—مما يخلق خط أنابيب حيث تعمل جميع الأجهزة بشكل مستمر بعد الارتفاع الأولي.
يعقد قِدم التدرج التوازي المتسلسل. تحدث الأجهزة الأوزان باستخدام تدرجات محوسبة من تفعيلات قد تكون قديمة بعشرات الدُفع الفرعية، مما يخلق قِدماً قد يضر بالتقارب.¹³³ خوارزميات الجدولة المتطورة مثل PipeDream تقلل القِدم مع الحفاظ على إنتاجية عالية، والنتائج التجريبية تظهر أن معظم النماذج تتحمل القِدم المعتدل دون تدهور الجودة.
يجمع التوازي ثلاثي الأبعاد الاستراتيجيات الثلاث جميعها. يوزع توازي البيانات عبر بُعد "البيانات"، وتوازي tensor عبر بُعد "النموذج"، والتوازي المتسلسل عبر بُعد "خط الأنابيب".¹³⁴ الموازنة الدقيقة للأبعاد بناءً على هندسة النموذج، وطوبولوجيا الأجهزة، وتكاليف التواصل تعظم الإنتاجية. نماذج بحجم GPT-3 تستخدم عادة التوازي ثلاثي الأبعاد مع توازي البيانات عبر 8-16 نسخة، وتوازي tensor عبر 4-8 GPU، والتوازي المتسلسل عبر 4-16 مرحلة.
استراتيجيات التقسيم والتحسين
يتطلب اختيار استراتيجيات التقسيم فهم العمليات الرياضية وتبعيات بياناتها. ضرب المصفوفات C = A @ B يسمح بتقسيمات صالحة متعددة: نسخ كل من A و B وحوسبة نتائج جزئية (التواصل قبل الحوسبة)، تقسيم B عمودياً وجمع النتائج (التواصل بعد الحوسبة)، أو تقسيم A أفقياً و B عمودياً دون تواصل ولكن مع مصفوفات أصغر لكل جهاز.¹³⁵
تحدد تكاليف العمليات الجماعية الاستراتيجيات المثلى. تتوسع تكاليف all-reduce خطياً مع حجم tensor ولكن دون خطياً مع عدد الأجهزة باستخدام خوارزميات التقليل المبنية على الشجرة أو الحلقة:¹³⁶ all-gather و reduce-scatter تظهر خصائص توسع مختلفة. يمذجة المترجم هذه التكاليف ويختار استراتيجيات التقسيم التي تقلل إجمالي وقت التواصل.
يبرز التوازي التسلسلي كأمر بالغ الأهمية لنماذج اللغة الكبيرة. آليات الانتباه تخلق اختناقات في الذاكرة لأن مخازن key-value تنمو مع طول التسلسل وحجم الدفعة. التقسيم على طول بُعد التسلسل يوزع عبء الذاكرة عبر الأجهزة مع إدخال التواصل فقط لحوسبة الانتباه نفسها.¹³⁷
يتعامل توازي الخبراء مع نماذج Mixture-of-Experts (MoE) حيث يعالج خبراء مختلفون رموزاً مختلفة. تنسخ استراتيجية التقسيم الطبقات المشتركة عبر جميع الأجهزة ولكنها تقسم الخبراء، موجهة كل رمز إلى جهاز الخبير المخصص له.¹³⁸ التوجيه الديناميكي يخلق أنماط تواصل غير منتظمة تتحدى العمليات الجماعية التقليدية، مما يتطلب أنظمة تشغيل متطورة لتقليل زمن الاستجابة وعدم توازن الحمل.
يقلل تقسيم حالة المحسن من عبء الذاكرة للنماذج الكبيرة. المحسنات مثل Adam تخزن إحصائيات الزخم والتباين لكل معامل، مما يضاعف متطلبات الذاكرة ثلاث مرات عن تلك المطلوبة للمعاملات وحدها. تقسيم حالات المحسن عبر الأجهزة مع الحفاظ على نسخ المعاملات يتيح تدريب نماذج أكبر ضمن ميزانيات ذاكرة ثابتة.¹³⁹ تتطلب الاستراتيجية جمع تحديثات حالة المحسن أثناء حوسبات الأوزان ولكنها تقلل بشكل كبير من بصمة الذاكرة لكل جهاز.
تحليل الأداء وقياس الأداء المرجعي
نتائج MLPerf والموضع التنافسي
تقدم MLPerf معايير صناعية قياسية لقياس أداء مسرعات AI عبر أعباء العمل للتدريب والاستنتاج. تقدم Google بانتظام نتائج TPU التي تُظهر أداءً تنافسياً، والتطور عبر الأجيال يُظهر تحسينات معمارية واضحة.¹⁴⁰
حقق TPU v5e نتائج رائدة في 8 من 9 فئات تدريب MLPerf.¹⁴¹ يُظهر هذا الاتساع تنوعاً معمارياً يتجاوز مجرد نماذج اللغة الكبيرة—أداء تنافسي عبر رؤية الحاسوب وأنظمة التوصيات وأعباء العمل الحاسوبية العلمية. أكمل تدريب BERT بسرعة 2.8× أسرع من وحدات NVIDIA A100 GPU، مما يؤكد المعمارية المُحسَّنة للمحولات.¹⁴²
MLPerf Training v5.0، التي أُعلن عنها في يونيو 2025، قدمت معياراً لـ Llama 3.1 405B يمثل أكبر نموذج في المجموعة.¹⁴³ يُجهد المعيار توسيع العقد المتعددة والحمل الإضافي للاتصال وسعة الذاكرة أكثر من الاختبارات السابقة. شاركت Google Cloud بمساهمات TPU، رغم أن المقارنات التفصيلية للأداء تبقى محظورة بانتظار نشر النتائج الرسمية.
تضمنت MLPerf Inference v5.0 أربعة معايير جديدة: Llama 3.1 405B، وLlama 2 70B للتطبيقات منخفضة الكمون، وشبكات RGAT العصبية الرسومية، وPointPainting لاكتشاف الكائنات ثلاثية الأبعاد.¹⁴⁴ يدفع التنوع المسرعات خارج أعباء عمل المحولات التقليدية إلى مجالات تطبيقات ناشئة حيث قد تختلف الافتراضات المعمارية.
معايير الاستنتاج تُفضل بشكل خاص نقاط القوة المعمارية لـ TPU. أعباء عمل الاستنتاج المجمع تستفيد من التوازي الهائل لـ MXU، محققة إنتاجية 4× أعلى من المسرعات المنافسة لخدمة المحولات.¹⁴⁵ كمون الاستعلام الواحد يستفيد من التنفيذ الحتمي لـ TPU وغياب التحكم الحراري، مما يوفر كموناً ثابتاً دون تباين الأداء الذي يُصيب بعض نشر GPU.
مقاييس الكفاءة في استهلاك الطاقة تُظهر مزايا TPU تتوسع عبر الأجيال. أظهر TPU v4 أداءً أفضل بـ 2.7× لكل واط من TPU v3، وحسَّن Trillium بنسبة 67% عن v5e.¹⁴⁶ يدعي Ironwood أداءً أفضل بـ 2× لكل واط من Trillium رغم الأداء المطلق الأعلى بشكل كبير.¹⁴⁷ مكاسب الكفاءة تتراكم عبر الكبسولات ذات الألف رقاقة، مما يترجم إلى ملايين الدولارات في تكاليف تشغيل مراكز البيانات.
أداء التدريب والاستنتاج في العالم الحقيقي
أعباء العمل الإنتاجية تكشف خصائص الأداء الغائبة عن المعايير التركيبية. تنشر Google نتائج من الخدمات الداخلية تُظهر سلوك TPU تحت أنماط الاستخدام الحقيقية ومتطلبات التوسيع.¹⁴⁸
يكمل تدريب ResNet-50 ImageNet في 28 دقيقة على كبسولات TPU، وهو معيار مرجعي مُستشهد به على نطاق واسع لأداء أعباء عمل رؤية الحاسوب.¹⁴⁹ يُلتقط مقياس الوقت للدقة العملية التدريبية الكاملة، بما في ذلك تحميل البيانات والتعزيز ومزامنة التدرج الموزع وحفظ نقاط التحقق—وليس فقط FLOPs النظرية.
يُظهر تدريب نموذج اللغة T5-3B مزايا TPU على معماريات المحولات. يتدرب النموذج ذو الثلاثة مليارات معامل في 12 ساعة على كبسولات TPU، مقارنة بـ 31 ساعة على تكوينات GPU المعادلة.¹⁵⁰ يأتي التسريع بـ 2.6× من عمليات الانتباه المُسرَّعة بالأجهزة واستغلال عرض نطاق الذاكرة الفعال والاتصالات الجماعية المُحسَّنة.
أعباء عمل بحجم GPT-3 (175B معامل) تحقق وقتاً أسرع بـ 1.7× للوصول للدقة على TPUs مقارنة بـ GPUs المعاصرة.¹⁵¹ تتسع فجوة الأداء للنماذج الأكبر حتى، حيث تصبح سعة الذاكرة وعرض النطاق قيوداً حرجة. HBM3e بسعة 192GB في Ironwood تُمكن من خدمة نماذج تتطلب توازي موتر معقد على البدائل ذات الذاكرة الأقل.
قياسات كفاءة التوسيع تُظهر تسريعاً شبه خطي لمقاييس هائلة. أفادت Google Research بكفاءة توسيع 95% عند 32,768 TPU لأعباء عمل تدريب محولات محددة.¹⁵² يعني المقياس أن 32,768 TPU سلمت 95% من الأداء الذي سيتنبأ به التوسيع الخطي المثالي—أمر ملحوظ نظراً لأن الحمل الإضافي للاتصال يزداد مع المقياس.
مقاييس استغلال FLOPS تكشف مدى فعالية أعباء العمل في الاستفادة من الحاسوب المتاح. نماذج المحولات تحقق عادة 90% استغلال FLOPS على TPUs، أي أن 90% من الأداء النظري الأقصى يُترجم إلى عمل فعلي.¹⁵³ الاستغلال العالي ينبع من دمج العمليات الذي يقضي على عقد الذاكرة وكفاءة المصفوفة الانقباضية في ضرب المصفوفات الكبيرة وتحسينات المُجمِّع التي تقلل الدورات المُهدرة.
خدمات الاستنتاج الإنتاجية تُظهر أداءً مستداماً عبر مليارات الاستعلامات يومياً. يعالج Google Translate مليار طلب يومياً على TPUs.¹⁵⁴ توصيات YouTube تخدم 2 مليار مستخدم باستخدام نماذج مُسرَّعة بـ TPU.¹⁵⁵ يحلل Google Photos 28 مليار صورة شهرياً لميزات البحث والتنظيم.¹⁵⁶ المقياس التشغيلي يؤكد الموثوقية والفعالية من حيث التكلفة خارج نشر النماذج الأولية البحثية.
كفاءة الطاقة والتكلفة الإجمالية للملكية
استهلاك الطاقة يؤثر مباشرة على تكاليف تشغيل مراكز البيانات والاستدامة البيئية. تحسينات كفاءة الطاقة في TPU عبر الأجيال تقلل من المصاريف التشغيلية والانبعاثات الكربونية على نطاق واسع.¹⁵⁷
بلغ متوسط استهلاك TPU v4 للطاقة 200W فقط في أعباء العمل الإنتاجية رغم مواصفات TDP بـ 250W.¹⁵⁸ الهامش بين متوسط وذروة الطاقة يُمكن التصميم الحراري المرن والتزويد. قارن مع GPUs، حيث أعباء العمل المستمرة غالباً ما تصل لحدود TDP، مما يتطلب ميزانيات طاقة محافظة للرفوف.
TDP بـ 600W في Ironwood يمثل طاقة مطلقة أعلى من الأجيال السابقة لكنه يوفر حاسوباً أكثر بشكل كبير لكل واط.¹⁵⁹ أداء 4.6 PFLOPS FP8 لكل رقاقة ينتج حوالي 7.7 TFLOPS لكل واط—تنافسي مع أو يتجاوز كفاءة GPU المعاصرة على أعباء العمل المعادلة.
فعالية استخدام الطاقة في مراكز البيانات (PUE) تُضخم كفاءة مستوى الرقاقة. تحقق مراكز بيانات TPU في Google PUE بـ 1.1، أي فقط 10% حمل إضافي للطاقة خارج استهلاك الرقاقة للتبريد وتحويل الطاقة والشبكات.¹⁶⁰ متوسط PUE الصناعي يتراوح من 1.5 إلى 2.0، حيث 50-100% طاقة إضافية تذهب للحمل الإضافي للبنية التحتية. PUE المنخفض ينبع من أنظمة التبريد المتقدمة وتوصيل الطاقة الفعال وتصميم مراكز البيانات المدروس المُحسَّن لأعباء عمل ML.
اعتبارات كثافة الكربون تمتد خارج الطاقة لتشمل مصادر الطاقة. تُشغل Google مراكز بيانات TPU على طاقة محايدة الكربون من خلال شراء الطاقة المتجددة وبرامج تعويض الكربون.¹⁶¹ محاسبة الكربون مهمة بشكل متزايد للمنظمات التي تتتبع انبعاثات النطاق 2 من الحوسبة السحابية.
تحليل التكلفة الإجمالية للملكية (TCO) يجب أن يحسب تكاليف الاستحواذ واستهلاك الطاقة ومتطلبات التبريد ومصاريف الصيانة. نشر TPU يُظهر عادة تخفيضات TCO بـ 20-30% مقارنة بتركيبات GPU المعادلة، مدفوعة أساساً بالأداء الفائق لكل واط وتعقيد التبريد المُقلل.¹⁶²
تكاليف البنية التحتية للتبريد تتوسع بشكل غير خطي مع كثافة الطاقة. الرفوف المبردة بالهواء عادة ما تصل لـ 15-20kW لكل رف قبل أن تتطلب حلول تبريد غريبة. GPUs عالية الطاقة تدفع هذه الحدود، أحياناً تستدعي بنية تحتية للتبريد السائل بتكاليف رأسمالية وتشغيلية أعلى بشكل كبير. كفاءة TPU تحافظ على مزيد من النشر ضمن مدى التبريد بالهواء، مما يُبسط تصميم مراكز البيانات.¹⁶³
المزايا التقنية: حيث تتفوق وحدات TPU
العمليات الجماعية المتسارعة بالأجهزة
يوفر الدعم المتخصص للعمليات الجماعية في TPU ICI إحدى أهم المزايا مقارنة بالمسرعات التقليدية القائمة على الشبكة. عملية All-reduce، وهي العملية الأساسية لمزامنة التدرجات عبر التدريب الموزع، تنفذ بسرعة أكبر 10 مرات على TPU ICI مقارنة بتطبيقات GPU المكافئة القائمة على Ethernet.¹⁶⁴
تنشأ فجوة الأداء من التكامل المعماري. العمليات الجماعية القائمة على Ethernet تمر عبر طبقات متعددة: كود التطبيق يستدعي مكتبة العمليات الجماعية (NCCL، Horovod، إلخ)، والتي تولد حزم تُسلم إلى مكدس الشبكة، والذي ينقل البيانات إلى NIC، والذي يسلسل على السلك، يعبر المبدلات، يلغي التسلسل في NICs المستقبلة، ويعكس العملية. كل طبقة تضيف زمن استجابة، وتنسخ البيانات عبر هياكل الذاكرة، وتستهلك دورات CPU لمعالجة البروتوكول.¹⁶⁵
يطبق TPU ICI العمليات الجماعية في الأجهزة دون المرور عبر طبقة البرمجيات. تبدأ العملية مباشرة من TensorCore، وتدفق البيانات عبر روابط ICI المخصصة، وتكتمل دون إشراك CPU المضيف. يلغي المسار المباشر للأجهزة النفقات العامة التي تهيمن على التطبيقات التقليدية.¹⁶⁶
تتيح طوبولوجيا مبدل الدائرة البصرية خوارزميات جماعية مثلى. يتطلب all-reduce القائم على الحلقة فقط 2(N-1) رسائل لـ N أجهزة، وتوفر طوبولوجيا torus توجيهاً بأقصر مسار، مما يقلل زمن الاستجابة.¹⁶⁷ يمنع عرض النطاق الموحد للقسم النقاط الساخنة حيث تؤدي العمليات الجماعية سيئة التوجيه إلى احتقان روابط الشبكة.
مساحة الذاكرة الموحدة والبرمجة المبسطة
يبسط نموذج الذاكرة الموحد لـ TPU البرمجة مقارنة بهياكل الذاكرة المعقدة لوحدات GPU. يتعامل المبرمجون مع مجموعة HBM واحدة بدلاً من إدارة عمليات النقل بين RAM المضيف وذاكرة GPU العامة والذاكرة المشتركة وملفات السجل. النموذج المبسط يقلل الأخطاء ويتيح سرعة تطوير أكبر.¹⁶⁸
تختفي تجزئة الذاكرة كمشكلة. تخصص وحدات GPU الذاكرة من كومة مجزأة، حيث تخلق عمليات التخصيص وإلغاء التخصيص بمرور الوقت فجوات تتطلب ضغطاً. إدارة ذاكرة TPU عبر التحليل الثابت للمترجم تتجنب التجزئة في وقت التشغيل تماماً - يتم تعيين مواقع محددة مسبقاً للتنسورات بناءً على رسم الحوسبة.¹⁶⁹
يلغي نموذج البرمجة فئات كاملة من أخطاء CUDA. لا مزيد من "الوصول غير القانوني للذاكرة" من حساب المؤشر الخاطئ، ولا أخطاء تماسك ذاكرة التخزين المؤقت بين CPU وGPU، ولا أخطاء مزامنة من استدعاءات cudaDeviceSynchronize() المفقودة. التجريد عالي المستوى يمنع المشاكل الشائعة في برمجة CUDA.¹⁷⁰
التنفيذ المحدد وقابلية الاستنساخ
تخلق اللاترابطية للفاصلة العائمة تحديات في قابلية الاستنساخ في الحوسبة المتوازية. قد ينتج التعبير (a + b) + c نتائج مختلفة عن a + (b + c) بسبب أخطاء التقريب، ويمكن للتقليلات المتوازية أن تجمع بترتيبات مختلفة عبر التشغيلات اعتماداً على حالات السباق.¹⁷¹
يظهر تنفيذ TPU تحديداً أقوى من تطبيقات GPU النموذجية. نمط تدفق البيانات الثابت للمصفوفة الانقباضية يضمن ترتيب عمليات متطابق عبر التشغيلات. تتبع العمليات الجماعية أشجار تقليل محددة بدلاً من التجميع الانتهازي المبني على ترتيب الوصول. القابلية للتنبؤ تتيح تدريباً قابلاً للاستنساخ حيث تنتج المعاملات الفائقة والبيانات المتطابقة أوزان نموذج متطابقة بت بت.¹⁷²
يستفيد التنقيح بشكل كبير من التحديد. يجعل التدريب غير المحدد تحديد السبب الجذري للفشل مستحيلاً تقريباً - هل NaN من خطأ خوارزمي حقيقي أم حالة سباق عشوائية؟ التنفيذ المحدد يعني أن الفشل يتكرر بشكل موثوق، مما يتيح مناهج تنقيح منهجية.¹⁷³
تقدر تطبيقات الحوسبة العلمية قابلية الاستنساخ بشكل خاص. نماذج المناخ ومحاكيات اكتشاف الأدوية وبحوث الفيزياء تتطلب نتائج قابلة للتحقق تتيح لباحثين مختلفين استنساخ نتائج متطابقة. يدعم تحديد TPU الطريقة العلمية بشكل أفضل من البدائل غير المحددة المتنافسة.¹⁷⁴
تحسينات المترجم وإنتاجية المطور
يوفر التحسين القوي لـ XLA تحسينات أداء كبيرة "جاهزة للاستخدام" دون ضبط يدوي. يفيد الباحثون بتحسينات 40% في إنتاجية النموذج من التجميع وحده مقارنة بأطر التنفيذ المباشر.¹⁷⁵ يأتي الأداء مجاناً - لا حاجة لهندسة kernel.
يفيد تحسين الانصهار المطورين بشكل خاص. يتطلب انصهار العمليات اليدوي في CUDA كتابة kernels مخصصة واختبار الصحة وصيانة الكود عبر إصدارات الإطار. يصهر XLA العمليات تلقائياً ويحدث ويكيف استراتيجيات الانصهار مع تطور النماذج، مما يلغي عبء الصيانة.¹⁷⁶
توفر أتمتة تحويل التخطيط أسابيع من التحسين اليدوي. يتطلب تحديد تخطيطات tensor المثلى لـ GPU ملامح ترتيبات مختلفة وإدراج transposes يدوياً وإدارة أنماط تخصيص الذاكرة بعناية. يجرب XLA التخطيطات تلقائياً ويختار الأسرع، مما يحرر المطورين للتركيز على معمارية النموذج بدلاً من هندسة الأداء منخفضة المستوى.¹⁷⁷
تتضاعف مكاسب الإنتاجية لفرق البحث. الوقت المحفوظ في تحسين البنية التحتية يسرع التقدم العلمي، مما يتيح تجارب أكثر ودورات تكرار أسرع. تفيد المؤسسات بتحسينات سرعة تطوير 3 مرات عند الانتقال من برمجة GPU CUDA إلى سير عمل TPU القائم على JAX.¹⁷⁸
القيود التقنية والعيوب
الارتباط بالمنصة وقيود البيئة المحلية
يتوفر الوصول إلى TPU حصرياً من خلال Google Cloud Platform، مما يمنع النشر في البيئة المحلية ويثير مخاوف الارتباط بالمورد.¹⁷⁹ المؤسسات التي لديها متطلبات سيادة البيانات أو شبكات معزولة أو سياسات ضد السحابة العامة لا يمكنها الاستفادة من TPU بغض النظر عن التفوق التقني.
هذا القيد يصبح أكثر أهمية مع تحول AI إلى بنية تحتية حيوية. الاعتماد على مورد سحابي واحد يخلق مخاطر استمرارية العمل—تغييرات التسعير، انقطاع التوافر، أو وقف الخدمة يمكن أن يفرض هجرات مكلفة.¹⁸⁰ توافر GPU من موردين متعددين (أجهزة NVIDIA التي تعمل على AWS و Azure و GCP والبيئة المحلية) يوفر خيارات يمنعها TPU معمارياً.
تواجه استراتيجيات السحابة المتعددة احتكاكاً. المؤسسات التي توحد معاييرها على TPU لا يمكنها بسهولة الانتقال إلى سحابات أخرى أو تنفيذ التكرار متعدد السحابات دون إعادة تدريب النماذج أو الحفاظ على قواعد أكواد منفصلة لبنى مسرعات مختلفة.¹⁸¹ التعقيد التشغيلي لعمليات النشر المختلطة GPU/TPU غالباً ما يفوق الوفورات في التكلفة من الاختيار الأمثل للمسرع.
فجوة نضج نظام CUDA البيئي
منصة CUDA من NVIDIA قد تراكمت لديها أكثر من 15 عاماً من تطوير النظام البيئي والمكتبات والوثائق ومعرفة المجتمع التي لا يستطيع TPU مضاهاتها.¹⁸² فجوة النضج تتجلى في نقاط ألم عديدة لتبني TPU.
توافر المكتبات يفضل CUDA بشكل ساحق. المجالات المتخصصة مثل رسومات الحاسوب وديناميكيات الجزيئات وديناميكيات السوائل الحاسوبية وعلم الجينوم قد جمعت آلاف المكتبات المحسنة لـ CUDA على مدى العقود الماضية. معادلات TPU غالباً ما لا توجد، مما يتطلب إما العودة إلى CPU (مما يدمر الأداء) أو أشهر من جهد النقل.¹⁸³
دعم المجتمع يختلف بمراتب من حيث الحجم. Stack Overflow يحتوي على مئات الآلاف من أسئلة CUDA مع إجابات مفصلة—مستودعات GitHub تعد بالملايين. المحاضرات المؤتمرية والأوراق الأكاديمية ومنشورات المدونات تركز بشكل أساسي على برمجة CUDA. مبرمجو TPU يواجهون موارد متناثرة نسبياً ودورات تصحيح أطول وخبراء أقل للاستشارة.¹⁸⁴
المواد التعليمية والدروس تستهدف CUDA بشكل ساحق. الدورات الجامعية تعلم برمجة GPU باستخدام CUDA. الدورات عبر الإنترنت تركز على CUDA. خط أنابيب المواهب ينتج مهندسين ذوي خبرة في CUDA أكثر بكثير من خبراء TPU، مما يخلق تحديات في التوظيف والتدريب.¹⁸⁵
تطوير النواة المخصصة يمثل فجوة النظام البيئي. كتابة نواة CUDA محسنة تبقى غير بسيطة لكنها تستفيد من الوثائق الشاملة وأدوات التحليل الشخصي وأمثلة الأكواد. Pallas يمكن نواة TPU المخصصة، لكن بأدوات أقل نضجاً وقاعدة معرفة أصغر. منحنى التعلم يثني عن كل التحسينات ما عدا الأكثر أهمية للأداء.¹⁸⁶
تخصص أعباء العمل وقيود المرونة
بنية TPU تحسن لأنماط أعباء عمل محددة—بشكل أساسي ضرب المصفوفات الكثيفة مع أنماط وصول منتظمة وأحجام دفعات كبيرة. العمليات خارج النقطة المثلى تواجه انحدارات في الأداء.¹⁸⁷
الأشكال الديناميكية تتحدى نماذج تنفيذ TPU. مجمع XLA يفترض أبعاد tensor ثابتة للتحسين وتوليد الكود. النماذج ذات أطوال التسلسل المتغيرة أو التحكم في التدفق الديناميكي أو الأشكال المعتمدة على البيانات تتطلب حشو إلى الأحجام القصوى (إهدار للحوسبة والذاكرة) أو إعادة تجميع لكل شكل مميز (تدمير الأداء)¹⁸⁸
العمليات المتناثرة تتلقى دعماً محدوداً رغم SparseCore. ضرب مصفوفة-مصفوفة متناثرة، عبء عمل شائع في الحوسبة العلمية والشبكات العصبية الرسمية، يفتقر لتطبيقات فعالة على MXU أو VPU. SparseCore المتخصص يتعامل مع جداول التضمين لكن ليس الجبر الخطي المتناثر العام.¹⁸⁹
الاستنتاج بدفعات صغيرة يستغل موارد TPU المتوازية بشكل ناقص. المصفوفة النسيجية 256×256 تزدهر على المصفوفات الكبيرة التي تملأ الشبكة بعمل منتج. استنتاج الاستعلام الواحد يترك معظم MACs خاملة، منتجاً زمن استجابة وتكلفة لكل استعلام أسوأ من بدائل GPU المحسنة لسيناريوهات الدفعات المنخفضة.¹⁹⁰
أنماط الحوسبة غير المنتظمة تهزم كفاءة المصفوفة النسيجية. الخوارزميات ذات التفرع غير المتوقع أو الهياكل المتكررة أو الوصول للذاكرة بتتبع المؤشر تظهر أداء TPU ضعيف لأن تدفق البيانات الثابت لا يستطيع التكيف مع السلوك المعتمد على وقت التشغيل.¹⁹¹
أعباء العمل غير ML نادراً ما تستفيد من تسريع TPU. المحاكيات العلمية وترميز الفيديو والتحقق من blockchain والعرض كلها تعمل أسرع على بنية GPU الأكثر عمومية رغم FLOPs الذروة الأعلى لـ TPU لعمليات المصفوفة.¹⁹²
فجوات أدوات التصحيح والتطوير
نظام NVIDIA البيئي يشمل أدوات تحليل شخصي ناضجة (Nsight Systems، Nsight Compute، nvprof) ومصححات (cuda-gdb) وأطر تحليل تم تنقيحها على مدى عقود. أدوات TPU موجودة، لكنها تتخلف بشكل كبير في التطور.¹⁹³
XProf يوفر تحليل شخصي أساسي من خلال تكامل TensorBoard لكن يفتقر للوصول المفصل لعدادات الأجهزة الذي تكشفه أدوات NVIDIA. فهم معدلات فقدان الذاكرة المؤقتة والإشغال وتشعب warp أو تعارضات بنوك الذاكرة—كلها مقاييس تحسين GPU حيوية—ليس لها معادل TPU لأن البنية تختلف جذرياً.¹⁹⁴
رسائل الخطأ غالباً ما تغطي الأسباب الجذرية. فشل تجميع XLA ينتج رسائل غامضة حول عدم تطابق الأشكال أو العمليات غير المدعومة، دون توجيه واضح للحل. أخطاء CUDA، رغم شهرتها بعدم المساعدة، تستفيد من خمسة عشر عاماً من شروحات StackOverflow والمعرفة القبلية.¹⁹⁵
تصحيح التدريب الموزع على pods متعددة الشرائح يقارب الاستحالة دون أدوات متخصصة. شروط السباق وأخطاء مزامنة التدرج وفشل العمليات الجماعية تتجلى كأخطاء غير حتمية (بشكل ساخر، رغم مزايا حتمية TPU) تتكرر بشكل غير متسق وتقاوم التشخيص المنهجي.¹⁹⁶
حلقة التكرار تمتد بشكل مؤلم للنماذج المعقدة. إعادة التجميع لتغييرات الشكل أو تعديلات البنية يمكن أن تتطلب دقائق، تجمد التطوير بينما المجمع يعمل. نموذج التنفيذ المتحمس لـ CUDA يمكن تكرار أسرع رغم أداء الذروة الأقل.¹⁹⁷
النشر في العالم الحقيقي: الإنتاج على نطاق واسع
Anthropic Claude: استراتيجية متعددة المنصات
يمثل إعلان Anthropic في أكتوبر 2025 عن نشر أكثر من مليون شريحة TPU أكبر التزام مُفصح عنه علناً لمسرّعات الذكاء الاصطناعي في التاريخ.¹⁹⁸ تخطط الشركة للوصول إلى ما يزيد عن جيجاوات من قدرة الحوسبة التي ستبدأ العمل في 2026 حصرياً لتدريب وتشغيل نماذج Claude المستقبلية.
النطاق يفوق عمليات النشر السابقة بعدة مراتب. مليون شريحة، مُكوَّنة كوحدات Ironwood TPUs، ستوفر حوالي 4.6 إكسافلوب من حوسبة FP8—أكثر من 40 ضعف الأداء الإجمالي لقائمة أفضل 500 حاسوب فائق بالكامل من خمس سنوات فقط.¹⁹⁹ يشير هذا الالتزام إلى الثقة في بنية TPU لتطوير النماذج الحدودية على نطاقات كانت تُعتبر خيال علمي من قبل.
تتبع Anthropic استراتيجية أجهزة متعددة المنصات بشكل مدروس عبر وحدات TPU من Google، وTrainium من Amazon، ووحدات GPU من NVIDIA.²⁰⁰ يوفر التنويع تأميناً للسعة، ونفوذاً في التسعير، وتوزيعاً جغرافياً. يعمل Claude عالمياً من خلال عمليات نشر عبر المنصات الثلاث جميعها، مع توجيه الطلبات بناءً على توفر السعة ومتطلبات زمن الاستجابة الإقليمي.
كشفت المراجعة التقنية للشركة من أغسطس 2025 عن تعقيدات النشر على نطاق واسع. تسبب خطأ في تكوين خوادم Claude API TPU في أخطاء توليد الرموز، مما أدى أحياناً إلى تخصيص احتماليات مرتفعة بشكل غير متوقع للحروف التايلاندية أو الصينية في المحفزات الإنجليزية.²⁰¹ أظهر الحادث أن حتى الأخطاء البسيطة تتتالى بشكل غير متوقع عبر الأنظمة التي تعالج مليارات الرموز يومياً.
أثار نشر منفصل خطأً كامناً في مترجم XLA: TPU يؤثر على Claude Haiku 3.5. كان الخطأ موجوداً بدون اكتشاف لأشهر حتى كشفت تركيبة معينة من بنية النموذج وعلامة المترجم عن العيب.²⁰² يؤكد الاكتشاف أن نشر الإنتاج يجد حالات حدية غائبة عن بيئات التطوير والتجريب.
استشهد مهندسو Anthropic بأداء السعر والكفاءة لوحدة TPU كمعايير اختيار أساسية. تسرّع الاقتصاديات المقنعة التطوير من خلال تمكين تجارب أكبر ضمن ميزانيات ثابتة.²⁰³ تدريب نماذج أكبر، واستكشاف تكوينات أكثر للمعاملات الفائقة، والتكرار بشكل أسرع كلها تنبع من تقليل تكاليف كل FLOP.
Google Gemini: مصمم لوحدة TPU منذ البداية
تُدرب نماذج Google Gemini وتعمل حصرياً على وحدات TPU، مع بنية وإجراءات تدريب مصممة مشتركة لخصائص TPU من البداية.²⁰⁴ يمكّن الترابط الوثيق من استغلال تحسينات خاصة بوحدة TPU لا يمكن للنماذج متعددة المنصات الاستفادة منها.
يستخدم نشر Gemini حسب التقارير 50,000 شريحة TPU v6e للتدريب وتشغيل أكبر متغيرات النموذج.²⁰⁵ تتطلب مقاييس الحاضنة الضخمة تنسيقاً معقداً—جدولة المهام عبر آلاف الشرائح، وتنسيق نقاط التفتيش لمنع الاختناقات، واستعادة الأعطال لتقليل العمل المفقود، والمراقبة الفورية لتحديد العقد المتدهورة قبل انتشار الأعطال.
دربت Google نموذج Gemini 2.0 على وحدات Trillium TPUs، مما يصادق على بنية الجيل السادس لتطوير النموذج الحدودي.²⁰⁶ أظهرت عملية التدريب كفاءة التوسع إلى أعداد شرائح غير مسبوقة، محققة توسعاً قوياً يتجاوز الهضاب النمطية حيث تهيمن أعباء الاتصال.
تستفيد البنية التحتية لتشغيل النموذج تحديداً من تحسينات استنتاج TPU. تجمع المعالجة المجمعة طلبات مستخدمين متعددة لتعظيم استخدام MXU. تستفيد إدارة ذاكرة التخزين المؤقت للمفاتيح والقيم من سعة HBM، مما يمكّن معالجة السياق طويل المدى دون تبديل القرص. توفر البنية أوقات استجابة أقل من الثانية للاستعلامات المعقدة بينما تتعامل مع حجم طلبات عالمي ضخم.²⁰⁷
تتتبع أنظمة مراقبة الإنتاج بشكل مستمر أكثر من 50,000 وحدة TPU، وتكتشف الشذوذ الذي قد يقلل من جودة النموذج أو توفره.²⁰⁸ تلتقط القياسات معدلات الأخطاء، ومئويات زمن الاستجابة، والإنتاجية، وضغط الذاكرة، والخصائص الحرارية عبر كل شريحة. تحلل نماذج التعلم الآلي تدفقات القياسات نفسها، وتتنبأ بالأعطال قبل حدوثها وتؤدي إلى صيانة وقائية.
عمليات نشر إنتاج إضافية
هاجرت Midjourney من بنية GPU إلى TPU، محققة تخفيضاً في التكلفة بنسبة 65% وتحسناً في زمن الاستجابة بنسبة 40% لأحمال عمل توليد الصور.²⁰⁹ تعالج خدمة توليد الفن 300,000 صورة في الدقيقة في ذروة الحمولة، وتتطلب إنتاجية حوسبة ضخمة وأداءً ثابتاً تحت أنماط حركة مرور متقطعة.
حققت نماذج اللغة من Cohere على TPU إنتاجية أكثر بـ 3 مرات من عمليات نشر GPU السابقة.²¹⁰ مكّنت السرعة من خدمة المزيد من العملاء من نفس البصمة التحتية، مما يحسن اقتصاديات الأعمال مباشرة. استفادت الشركة من قدرات SPMD في JAX لتوازي النماذج بكفاءة عبر حاضنات TPU.
أمنت Snap سعة لـ 10,000 شريحة TPU v6e تدعم ميزات الواقع المعزز، وأنظمة التوصيات، وأدوات الذكاء الاصطناعي الإبداعية.²¹¹ يمتد النشر عبر مناطق جغرافية متعددة، مما يضمن زمن استجابة منخفض لقاعدة مستخدمي Snapchat العالمية بينما يحافظ على اتساق النموذج عبر المناطق.
تتبنى المؤسسات الأكاديمية وحدة TPU بشكل متزايد للبحث. يوفر برنامج TPU Research Cloud (TRC) وصولاً مجانياً لوحدة TPU للباحثين، مما يمكّن التجارب على نطاقات كانت متاحة سابقاً فقط للمختبرات الشركاتية ذات التمويل الجيد.²¹² يسرّع إضفاء الطابع الديمقراطي التقدم العلمي من خلال إزالة حواجز الأجهزة للأكاديميين الذين يبحثون في أسئلة أساسية حول قدرات ومحدودية الذكاء الاصطناعي.
تصحيح الأخطاء والتحليل وتحسين الأداء
تكامل XProf مع TensorBoard
يُشكل XProف الأداة الأساسية لتحليل أداء أحمال العمل على TPU، حيث يوفر تحليل الأداء لبرامج JAX و PyTorch/XLA و TensorFlow عبر وحدات CPU و GPU و TPU.²¹³ تتكامل الأداة مع TensorBoard للتصور، وتعرض بيانات التحليل من خلال واجهات مألوفة يفهمها مهندسو التعلم الآلي بالفعل.
يتطلب التثبيت إضافة TensorBoard: pip install tensorboard_plugin_profile tensorboard. هذا يُمكن سلسلة الأدوات الكاملة.²¹⁴ تشغيل التحليل على TPU VMs يتضمن التقاط التتبعات أثناء التدريب أو الاستنتاج، ورفع النتائج إلى TensorBoard، وتحليل التصور لتحديد نقاط الاختناق.
توفر صفحة النظرة العامة مقاييس ملخص الأداء عالية المستوى، بما في ذلك تحليل وقت الخطوة، واستخدام الجهاز، وتحديد نقاط الاختناق على المستوى الأعلى.²¹⁵ تسلط الصفحة الضوء فوراً على ما إذا كانت أحمال العمل مقيدة بالحوسبة (MXU يعمل بشكل مستمر)، أو مقيدة بالذاكرة (انتظار عمليات نقل HBM)، أو مقيدة بالاتصال (محجوبة في العمليات الجماعية).
عارض التتبع وتحليل الجدولة الزمنية
يعرض عارض التتبع تصورات مفصلة للجدولة الزمنية تُظهر بالضبط متى تُنفذ العمليات، ومتى تحدث عمليات نقل البيانات، وأين يتراكم الوقت الخامل.²¹⁶ تُمكن الواجهة القائمة على Chrome من التكبير إلى دقة الميكروثانية، مما يكشف سلوك الجدولة الدقيق الذي تخفيه المقاييس المجمعة.
فهم التتبع يتطلب التعرف على الأنماط الشائعة. الفجوات الطويلة بين العمليات تشير إلى حمولة التحويل البرمجي، أو نقاط اختناق تحميل البيانات، أو حمولة Python بسبب خطوط أنابيب البيانات المُحسنة بشكل ضعيف. العمليات الصغيرة المتكررة تشير إلى دمج غير كافٍ. العمليات الجماعية التي تمتد لميليثوانٍ تشير إلى عدم كفاءة الاتصال أو استراتيجيات تقسيم ضعيفة.²¹⁷
ترميز الألوان يميز أنواع العمليات: الأخضر للحوسبة، والأزرق لعمليات نقل الذاكرة، والبرتقالي للاتصال، والأحمر للوقت الخامل. أحمال العمل المُحسنة تُظهر كتل ملونة مضغوطة بكثافة مع فجوات حمراء قليلة. الكود المُحسن بشكل ضعيف يُظهر جداول زمنية متناثرة مع امتدادات حمراء طويلة تشير إلى موارد مُهدرة.²¹⁸
الاستخدام المتقدم يتضمن ربط سلوك الجدولة الزمنية بكود المصدر. PyTorch/XLA يدعم التعليقات التوضيحية المدرجة في الكود التي تظهر في التتبعات، مما يُمكن ربط سلوك الأداء بمكونات النموذج المحددة.²¹⁹ التعليقات التوضيحية تحول التتبعات الغامضة إلى رؤى قابلة للتنفيذ حول أي طبقات أو عمليات تحتاج تركيز التحسين.
أداة تحليل الذاكرة وتصحيح أخطاء OOM
أخطاء نفاد الذاكرة (OOM) تُؤرق تطوير النماذج الكبيرة. أداة تحليل الذاكرة تراقب استخدام ذاكرة الجهاز أثناء التنفيذ، وتلتقط الاستخدام الذروي وأنماط التخصيص التي تؤدي إلى فشل OOM.²²⁰
الأداة تُصور استهلاك الذاكرة عبر الوقت، مُظهرة أي tensors تستهلك أكبر سعة ومتى يحدث الاستخدام الذروي. التصور كثيراً ما يكشف تخصيصات مفاجئة—مخازن التدرج أكبر من المتوقع، أو ذاكرة التنشيط التي يجب وضع نقاط مراجعة لها، أو tensors مؤقتة فشل XLA في إزالتها.²²¹
استراتيجية التصحيح تتضمن تقليل بصمة الذاكرة تدريجياً من خلال تقنيات متعددة. نقاط مراجعة التدرج تُعيد حساب التنشيطات أثناء ممرات للخلف بدلاً من تخزينها. تقسيم حالة المُحسن يوزع momentum و variance الخاص بـ Adam عبر الأجهزة. الدقة المختلطة تقلل الذاكرة بمقدار 2× مقارنة بـ FP32. المعالجة المجمعة الصغيرة تعالج دفعات أصغر تسلسلياً بدلاً من دفعة واحدة كبيرة.²²²
تحسين الذاكرة المتقدم يتطلب فهم قرارات المُحول البرمجي. علَم xla_dump_to يُصدر التمثيلات الوسطية التي تُظهر كيف حول XLA رسم الحوسبة البياني. تحليل IR يكشف ما إذا نجح الدمج، وأين تحدث النسخ غير الضرورية، وأي عمليات تُخصص ذاكرة أكثر من المتوقع.²²³
محلل خط أنابيب الإدخال
المعالجة المسبقة للـ CPU كثيراً ما تُشكل نقطة اختناق لتدريب TPU. محلل خط أنابيب الإدخال يحدد ما إذا كان تحميل البيانات يواكب استهلاك المُسرع أم أن وحدات TPU تبقى خاملة في انتظار الدفعات.²²⁴
الأداة تفصل تحليل الجانب المضيف (المعالجة المسبقة للـ CPU، وتعزيز البيانات، وتجميع الدفعات) عن تنفيذ الجانب الجهاز (حوسبة TPU الفعلية). أحمال العمل المقيدة بالإدخال تُظهر انخفاض استخدام الجهاز أثناء تحميل البيانات بينما يصل استخدام CPU إلى ذروته. أحمال العمل المقيدة بالحوسبة تحافظ على استخدام عالي للجهاز مع CPU يواكب براحة.²²⁵
استراتيجيات التحسين تعتمد على موقع نقطة الاختناق. المعالجة المسبقة البطيئة للمضيف تستفيد من توزي تحميل البيانات عبر المزيد من نوى CPU، أو تقليل تعقيد التعزيز لكل عينة، أو الجلب المسبق للدفعات قبل الاستهلاك. نقاط الاختناق في جانب الجهاز تتطلب تغييرات في بنية النموذج، أو دمج أفضل، أو تعديلات التقسيم بدلاً من ضبط خط أنابيب البيانات.²²⁶
مستقبل وحدات معالجة الموترات
يُظهر التطور المعماري السبعة أجيال من Google الابتكار المستمر في مسرّعات AI المتخصصة. دعم Ironwood لـ FP8 وسعة الذاكرة الهائلة وتوسيع نطاق superpod بـ 9,216 رقاقة يشير إلى مسارات للتطوير المستقبلي.²²⁷
من المحتمل أن يستمر تقليل الدقة نحو FP4 أو حتى أقل للعمليات المحددة. تُظهر الأبحاث الناشئة أن العديد من عمليات الشبكات العصبية تتحمل الكمية الشديدة مع إجراءات التدريب الدقيقة. قد تنفذ TPUs المستقبلية أنظمة دقة مختلطة مع تمريرات أمامية FP4 وتمريرات خلفية FP8 وتحديثات محسن FP32.²²⁸
تتسابق سعة الذاكرة ضد نمو حجم النموذج. النماذج الحدودية الحالية تُجهد بالفعل ذاكرة المسرع، مما يتطلب استراتيجيات توازي متطورة. قد تدمج TPUs الجيل القادم تقنيات الذاكرة غير المتطايرة مثل 3D XPoint أو RAM المقاوم، مما يُمكّن ذاكرة بمقياس تيرابايت على الحزمة دون استهلاك طاقة DRAM.²²⁹
يمكن للربط البصري أن يمتد إلى ما هو أبعد من تبديل الدوائر ليشمل عناصر الحوسبة البصرية. تستكشف الأبحاث ضرب المصفوفة الفوتوني المنفذ بسرعة الضوء مع الحد الأدنى من الطاقة، مما قد يُعزز المصفوفات الانقباضية الإلكترونية بمعالجات مساعدة بصرية لعمليات محددة.²³⁰
من المحتمل أن يتوسع دعم التناثر إلى ما هو أبعد من التضمينات إلى الجبر الخطي المتناثر العام. تُظهر تقنيات تقليم الشبكة العصبية أن أكثر من 90% من الأوزان يمكن إلغاؤها دون فقدان الجودة. قد تتخطى الهياكل المستقبلية بشكل أصلي الحسابات ذات القيمة الصفرية بدلاً من حسابها صراحة وتجاهلها.²³¹
المبادئ المعمارية الأساسية لنجاح TPU - التخصص في المجال والربط المخصص ومجموعات البرمجيات المصممة معًا وتنظيم مقياس البناء - تشير إلى مستقبل مسرعات متخصصة بشكل متزايد. بدلاً من معالجات مناسبة للجميع، قد نرى مسرعات محسنة للتدريب مقابل الاستنتاج والشبكات التطبيقية مقابل المحولات والنماذج الكثيفة مقابل المتناثرة والتسلسلات القصيرة مقابل الطويلة.²³²
يجب على المهندسين الذين يبنون بنية AI اليوم فهم هيكل TPU بعمق. سواء كانوا ينشرون على Google Cloud أو يتنافسون مع Google في سوق المسرع أو يصممون أنظمة ML الجيل القادم، فإن مبادئ التصميم والمقايضات المجسدة في TPU تكشف حقائق أساسية حول ما تتطلبه أحمال عمل AI من الأجهزة. رياضيات المصفوفة الانقباضية وتصميم تسلسل الذاكرة وطوبولوجيا الربط واستراتيجيات تحسين المترجم تمثل عقودًا من الحكمة المتراكمة القابلة للتطبيق إلى ما هو أبعد من TPU نفسه.
التوتر بين التخصص والعمومية الذي يُعرّف TPU مقابل GPU سيستمر إلى أجل غير مسمى. تُضحي TPUs بالمرونة من أجل الكفاءة القصوى في أحمال العمل الضيقة. تُضحي GPUs بالكفاءة القصوى من أجل قابلية التطبيق الأوسع. لا يهيمن أي نهج - الخيار الأمثل يعتمد كلياً على خصائص حمل العمل والمقياس وقيود التكلفة والمتطلبات التشغيلية. تتبنى المنظمات الناجحة مع AI على نطاق واسع بشكل متزايد استراتيجيات غير متجانسة، تطابق هياكل المسرع مع متطلبات حمل العمل بدلاً من التوحيد على منصة واحدة.
التزام Anthropic بمليون رقاقة لـ TPU يُظهر أن الهيكل قد حقق نضج الإنتاج في أعلى المقاييس. النشر متعدد الجيجاوات القادم عبر الإنترنت في 2026 سيدرب نماذج تدفع حدود ما يمكن لـ AI تحقيقه، والبنية التحتية التي تُمكن هذه النماذج تُجسد تطورًا هندسيًا قليل من المنظمات قد ضاهته. فهم كيف تتعاون 65,536 وحدة ضرب وتجميع في مصفوفة انقباضية لتدريب النماذج الحدودية مهم لأي شخص جاد حول مستقبل AI.
المراجع
-
Google Cloud Press Corner، "Anthropic to Expand Use of Google Cloud TPUs and Services"، 23 أكتوبر 2025، https://www.googlecloudpresscorner.com/2025-10-23-Anthropic-to-Expand-Use-of-Google-Cloud-TPUs-and-Services.
-
TrendForce، "Google Unveils 7th-Gen TPU Ironwood with 9,216-Chip Superpod, Taking Aim at NVIDIA"، 7 نوفمبر 2025، https://www.trendforce.com/news/2025/11/07/news-google-unveils-7th-gen-tpu-ironwood-with-9216-chip-superpod-taking-aim-at-nvidia/.
-
Norman P. Jouppi وآخرون، "TPU v4: An Optically Reconfigurable Supercomputer for Machine Learning with Hardware Support for Embeddings"، في Proceedings of the 50th Annual International Symposium on Computer Architecture (2023)، arXiv:2304.01433.
-
Anthropic، "Expanding our use of Google Cloud TPUs and Services"، Anthropic News، أكتوبر 2025، https://www.anthropic.com/news/expanding-our-use-of-google-cloud-tpus-and-services.
-
Google Cloud Blog، "Quantifying the performance of the TPU, our first machine learning chip"، أبريل 2017، https://cloud.google.com/blog/products/gcp/quantifying-the-performance-of-the-tpu-our-first-machine-learning-chip.
-
Norman P. Jouppi وآخرون، "In-Datacenter Performance Analysis of a Tensor Processing Unit"، Proceedings of the 44th Annual International Symposium on Computer Architecture (2017)، arXiv:1704.04760.
-
Jouppi وآخرون، "In-Datacenter Performance Analysis".
-
Jouppi وآخرون، "In-Datacenter Performance Analysis".
-
Jonathan Hui، "AI Chips: Google TPU"، Medium، تم الوصول إليه ديسمبر 2025، https://jonathan-hui.medium.com/ai-chips-tpu-3fa0b2451a2d.
-
Wikipedia، "Bfloat16 floating-point format"، تم الوصول إليه ديسمبر 2025، https://en.wikipedia.org/wiki/Bfloat16_floating-point_format.
-
Henry Ko، "TPU Deep Dive"، مدونة شخصية، تم الوصول إليه ديسمبر 2025، https://henryhmko.github.io/posts/tpu/tpu.html.
-
Wikipedia، "Tensor Processing Unit"، تم الوصول إليه ديسمبر 2025، https://en.wikipedia.org/wiki/Tensor_Processing_Unit.
-
Wikipedia، "Tensor Processing Unit".
-
Wikipedia، "Tensor Processing Unit".
-
Ko، "TPU Deep Dive".
-
Jouppi وآخرون، "TPU v4: An Optically Reconfigurable Supercomputer".
-
Jouppi وآخرون، "TPU v4: An Optically Reconfigurable Supercomputer".
-
Jouppi وآخرون، "TPU v4: An Optically Reconfigurable Supercomputer".
-
Jouppi وآخرون، "TPU v4: An Optically Reconfigurable Supercomputer".
-
OpenXLA Project، "A deep dive into SparseCore for Large Embedding Models (LEM)"، تم الوصول إليه ديسمبر 2025، https://openxla.org/xla/sparsecore.
-
JAX Scaling Guide، "How to Think About TPUs"، تم الوصول إليه ديسمبر 2025، https://jax-ml.github.io/scaling-book/tpus/.
-
JAX Scaling Guide، "How to Think About TPUs".
-
Ko، "TPU Deep Dive".
-
JAX Scaling Guide، "How to Think About TPUs".
-
Google Cloud Blog، "Introducing Trillium, sixth-generation TPUs"، مايو 2024، https://cloud.google.com/blog/products/compute/introducing-trillium-6th-gen-tpus.
-
Google Cloud Blog، "Introducing Trillium".
-
Google Cloud Blog، "Introducing Trillium".
-
Google Cloud Blog، "Introducing Trillium".
-
Google Cloud Blog، "Introducing Trillium".
-
Google Blog، "Ironwood: The first Google TPU for the age of inference"، نوفمبر 2025، https://blog.google/products/google-cloud/ironwood-tpu-age-of-inference/.
-
XPU.pub، "Google Adds FP8 to Ironwood TPU; Can It Beat Blackwell?"، 16 أبريل 2025، https://xpu.pub/2025/04/16/google-ironwood/.
-
TrendForce، "Google Unveils 7th-Gen TPU Ironwood".
-
The Register، "Google's 7th-gen Ironwood TPUs promise 42 AI exaFLOPS pods"، 10 أبريل 2025، https://www.theregister.com/2025/04/10/googles_7thgen_ironwood_tpus_debut/.
-
TrendForce، "Google Unveils 7th-Gen TPU Ironwood".
-
Ko، "TPU Deep Dive".
-
XPU.pub، "Google Adds FP8 to Ironwood TPU".
-
Google Cloud Press Corner، "Anthropic to Expand Use".
-
Telesens، "Understanding Matrix Multiplication on a Weight-Stationary Systolic Architecture"، 30 يوليو 2018، https://telesens.co/2018/07/30/systolic-architectures/.
-
Telesens، "Understanding Matrix Multiplication".
-
Jouppi وآخرون، "In-Datacenter Performance Analysis".
-
Telesens، "Understanding Matrix Multiplication".
-
CP Lu، "Should We All Embrace Systolic Arrays?"، Medium، تم الوصول إليه ديسمبر 2025، https://cplu.medium.com/should-we-all-embrace-systolic-array-df3830f193dc.
-
Google Cloud Documentation، "TPU architecture"، تم الوصول إليه ديسمبر 2025، https://docs.cloud.google.com/tpu/docs/system-architecture-tpu-vm.
-
Google Cloud Documentation، "TPU architecture".
-
Hui، "AI Chips: Google TPU".
-
Telnyx، "Architecture insights: MXU and TPU components"، تم الوصول إليه ديسمبر 2025، https://telnyx.com/learn-ai/mxu-tpu.
-
Ko، "TPU Deep Dive".
-
Jouppi وآخرون، "TPU v4: An Optically Reconfigurable Supercomputer".
-
SemiEngineering، "Tensor Processing Unit (TPU)"، تم الوصول إليه ديسمبر 2025، https://semiengineering.com/knowledge_centers/integrated-circuit/ic-types/processors/tensor-processing-unit-tpu/.
-
TrendForce، "Google Unveils 7th-Gen TPU Ironwood".
-
SemiEngineering، "Tensor Processing Unit (TPU)".
-
Ko، "TPU Deep Dive".
-
Ko، "TPU Deep Dive".
-
Google Cloud Documentation، "Cloud TPU performance guide"، تم الوصول إليه ديسمبر 2025، https://cloud.google.com/tpu/docs/performance-guide.
-
OpenXLA Project، "A deep dive into SparseCore".
-
OpenXLA Project، "A deep dive into SparseCore".
-
OpenXLA Project، "A deep dive into SparseCore".
-
Jouppi وآخرون، "TPU v4: An Optically Reconfigurable Supercomputer".
-
OpenXLA Project، "A deep dive into SparseCore".
-
Jouppi وآخرون، "TPU v4: An Optically Reconfigurable Supercomputer".
-
OpenXLA Project، "A deep dive into SparseCore".
-
JAX Scaling Guide، "How to Think About TPUs".
-
JAX Scaling Guide، "How to Think About TPUs".
-
JAX Scaling Guide، "How to Think About TPUs".
-
Ko، "TPU Deep Dive".
-
JAX Scaling Guide، "How to Think About TPUs".
-
JAX Scaling Guide، "How to Think About TPUs".
-
TrendForce، "Google Unveils 7th-Gen TPU Ironwood".
-
Ko، "TPU Deep Dive".
-
Anthropic، "Expanding our use of Google Cloud TPUs".
-
Jouppi وآخرون، "TPU v4: An Optically Reconfigurable Supercomputer".
-
Jouppi وآخرون، "TPU v4: An Optically Reconfigurable Supercomputer".
-
Jouppi وآخرون، "TPU v4: An Optically Reconfigurable Supercomputer".
-
Jouppi وآخرون، "TPU v4: An Optically Reconfigurable Supercomputer".
-
Ko، "TPU Deep Dive".
-
Jouppi وآخرون، "TPU v4: An Optically Reconfigurable Supercomputer".
-
Leon Poutievski، "Mission Apollo: Landing Optical Circuit Switching at Datacenter Scale"، LinkedIn، يونيو 2022، https://www.linkedin.com/posts/leon-poutievski-8910a851_mission-apollo-landing-optical-circuit-switching-activity-6968472071534235649-cB4l.
-
Ko، "TPU Deep Dive".
-
Jouppi وآخرون، "TPU v4: An Optically Reconfigurable Supercomputer".
-
Ko، "TPU Deep Dive".
-
Ko، "TPU Deep Dive".
-
Ko، "TPU Deep Dive".
-
Jouppi وآخرون، "TPU v4: An Optically Reconfigurable Supercomputer".
-
JAX Scaling Guide، "How to Think About TPUs".
-
TrendForce، "Google Unveils 7th-Gen TPU Ironwood".
-
TrendForce، "Google Unveils 7th-Gen TPU Ironwood".
-
Ko، "TPU Deep Dive".
-
Ko، "TPU Deep Dive".
-
OpenXLA Project، "XLA: Optimizing Compiler for Machine Learning"، تم الوصول إليه ديسمبر 2025، https://openxla.org/xla.
-
Daniel Snider و Ruofan Liang، "Operator Fusion in XLA: Analysis and Evaluation"، ورقة أكاديمية، تم الوصول إليه ديسمبر 2025، https://danielsnider.ca/papers/Operator_Fusion_in_XLA_Analysis_and_Evaluation.pdf.
-
Snider و Liang، "Operator Fusion in XLA".
-
APXML، "Memory-Aware Data Layout Transformations (NCHW/NHWC)"، تم الوصول إليه ديسمبر 2025، https://apxml.com/courses/compiler-runtime-optimization-ml/chapter-3-advanced-graph-level-optimizations/memory-aware-layout-transformations.
-
OpenXLA Project، "XLA".
-
PyTorch Documentation، "Pytorch/XLA Overview"، تم الوصول إليه ديسمبر 2025، https://docs.pytorch.org/xla/master/learn/xla-overview.html.
-
OpenXLA Project، "A deep dive into SparseCore".
-
Mangpo Phothilimthana وآخرون، "A Flexible Approach to Autotuning Multi-Pass Machine Learning Compilers"، PACT 2021، تم الوصول إليه ديسمبر 2025، https://mangpo.net/papers/xla-autotuning-pact2021.pdf.
-
JAX Documentation، "Introduction to parallel programming"، تم الوصول إليه ديسمبر 2025، https://docs.jax.dev/en/latest/sharded-computation.html.
-
GitHub، "jax-ml/jax: Composable transformations of Python+NumPy programs"، تم الوصول إليه ديسمبر 2025، https://github.com/jax-ml/jax.
-
OpenXLA Project، "Shardy Guide for JAX Users"، تم الوصول إليه ديسمبر 2025، https://openxla.org/shardy/getting_started_jax.
-
JAX Documentation، "Introduction to parallel programming".
-
OpenXLA Project، "Shardy Guide for JAX Users".
-
OpenXLA Project، "Shardy Guide for JAX Users".
-
JAX Documentation، "Introduction to parallel programming".
-
OpenXLA Project، "Shardy Guide for JAX Users".
-
PyTorch Documentation، "Pytorch/XLA Overview".
-
GitHub، "RFC: Evolving PyTorch/XLA for a more native experience on TPU"، Issue #9684، تم الوصول إليه ديسمبر 2025، https://github.com/pytorch/xla/issues/9684.
-
Google Cloud Blog، "PyTorch/XLA 2.4 improves Pallas and adds 'eager mode,'"، تم الوصول إليه ديسمبر 2025، https://cloud.google.com/blog/products/ai-machine-learning/pytorch-xla-2-4-improves-pallas-and-adds-eager-mode/.
-
PyTorch Documentation، "Pytorch/XLA Overview".
-
PyTorch Documentation، "Custom Kernels via Pallas"، تم الوصول إليه ديسمبر 2025، https://docs.pytorch.org/xla/master/features/pallas.html.
-
PyTorch Documentation، "Custom Kernels via Pallas".
-
PyTorch Documentation، "Custom Kernels via Pallas".
-
vLLM Blog، "vLLM TPU: A New Unified Backend Supporting PyTorch and JAX on TPU"، 16 أكتوبر 2025، https://blog.vllm.ai/2025/10/16/vllm-tpu.html.
-
GitHub، "pytorch/xla"، تم الوصول إليه ديسمبر 2025، https://github.com/pytorch/xla.
-
StackGpu، "FP8, BF16, and INT8: How Low-Precision Formats Are Revolutionizing Deep Learning Throughput"، Medium، تم الوصول إليه ديسمبر 2025، https://medium.com/@StackGpu/fp8-bf16-and-int8-how-low-precision-formats-are-revolutionizing-deep-learning-throughput-e6c1f3adabc2.
-
Wikipedia، "Bfloat16 floating-point format".
-
Wikipedia، "Bfloat16 floating-point format".
-
Paulius Micikevicius وآخرون، "FP8 Formats for Deep Learning"، arXiv:2209.05433، سبتمبر 2022.
-
XPU.pub، "Google Adds FP8 to Ironwood TPU".
-
Micikevicius وآخرون، "FP8 Formats for Deep Learning".
-
Google Cloud Blog، "Accurate Quantized Training (AQT) for TPU v5e"، تم الوصول إليه ديسمبر 2025، https://cloud.google.com/blog/products/compute/accurate-quantized-training-aqt-for-tpu-v5e.
-
StackGpu، "FP8, BF16, and INT8".
-
Jeffrey Tse، "Understanding the FP64, FP32, FP16, BFLOAT16, TF32, FP8 Formats"، مدونة شخصية، 9 ديسمبر 2024، https://jeffreytse.net/computer/2024/12/09/understanding-the-fp64-fp32-fp16-bfloat16-tf32-fp8-formats.html.
-
PyTorch Blog، "PyTorch/XLA SPMD: Scale Up Model Training and Serving with Automatic Parallelization"، تم الوصول إليه ديسمبر 2025، https://pytorch.org/blog/pytorch-xla-spmd/.
-
OpenXLA Project، "Shardy Guide for JAX Users".
-
JAX Documentation، "Introduction to parallel programming".
-
OpenXLA Project، "Shardy Guide for JAX Users".
-
Ko، "TPU Deep Dive".
-
JAX Documentation، "Introduction to parallel programming".
-
Anthropic، "Expanding our use of Google Cloud TPUs".
-
JAX Documentation، "Introduction to parallel programming".
-
JAX Documentation، "Introduction to parallel programming".
-
Adam Roberts وآخرون، "Scaling Up Models and Data with t5x and seqio"، arXiv:2203.17189، مارس 2022.
-
Roberts وآخرون، "Scaling Up Models and Data".
-
JAX Documentation، "Introduction to parallel programming".
-
JAX Documentation، "Introduction to parallel programming".
-
OpenXLA Project، "Shardy Guide for JAX Users".
-
Roberts وآخرون، "Scaling Up Models and Data".
-
Roberts وآخرون، "Scaling Up Models and Data".
-
Ko، "TPU Deep Dive".
-
MLCommons، "Benchmark MLPerf Training"، تم الوصول إليه ديسمبر 2025، https://mlcommons.org/benchmarks/training/.
-
Ko، "TPU Deep Dive".
-
Ko، "TPU Deep Dive".
-
HPCwire، "MLPerf Training v5.0 Benchmark Results Reflect Rapid Growth in the Field of AI"، يونيو 2025، https://www.hpcwire.com/off-the-wire/mlperf-training-v5-0-benchmark-results-reflect-rapid-growth-in-the-field-of-ai/.
-
MLCommons، "MLCommons Releases New MLPerf Inference v5.0 Benchmark Results"، أبريل 2025، https://mlcommons.org/2025/04/mlperf-inference-v5-0-results/.
-
Ko، "TPU Deep Dive".
-
Google Cloud Blog، "TPU v4 enables performance, energy and CO2e efficiency gains"، تم الوصول إليه ديسمبر 2025، https://cloud.google.com/blog/topics/systems/tpu-v4-enables-performance-energy-and-co2e-efficiency-gains.
-
TrendForce، "Google Unveils 7th-Gen TPU Ironwood".
-
Google Cloud Blog، "Quantifying the performance of the TPU".
-
Ko، "TPU Deep Dive".
-
Ko، "TPU Deep Dive".
-
Ko، "TPU Deep Dive".
-
Ko، "TPU Deep Dive".
-
Ko، "TPU Deep Dive".
-
Ko، "TPU Deep Dive".
-
Ko، "TPU Deep Dive".
-
Ko، "TPU Deep Dive".
-
Artech Digital، "Energy-Efficient GPU vs. TPU Allocation"، تم الوصول إليه ديسمبر 2025، https://www.artech-digital.com/blog/energy-efficient-gpu-vs-tpu-allocation.
-
Wikipedia، "Tensor Processing Unit".
-
XPU.pub، "Google Adds FP8 to Ironwood TPU".
-
Ko، "TPU Deep Dive".
-
Google Cloud Blog، "TPU v4 enables performance, energy and CO2e efficiency gains".
-
ByteBridge، "GPU and TPU Comparative Analysis Report"، Medium، تم الوصول إليه ديسمبر 2025، https://bytebridge.medium.com/gpu-and-tpu-comparative-analysis-report-a5268e4f0d2a.
-
ByteBridge، "GPU and TPU Comparative Analysis Report".
-
Anthropic، "Expanding our use of Google Cloud TPUs".
-
Ko، "TPU Deep Dive".
-
Ko، "TPU Deep Dive".
-
Ko، "TPU Deep Dive".
-
DataCamp، "Understanding TPUs vs GPUs in AI: A Comprehensive Guide"، تم الوصول إليه ديسمبر 2025، https://www.datacamp.com/blog/tpu-vs-gpu-ai.
-
Ko، "TPU Deep Dive".
-
DataCamp، "Understanding TPUs vs GPUs in AI".
-
Grigory Sapunov، "FP64, FP32, FP16, BFLOAT16, TF32, and other members of the ZOO"، Medium، تم الوصول إليه ديسمبر 2025، https://moocaholic.medium.com/fp64-fp32-fp16-bfloat16-tf32-and-other-members-of-the-zoo-a1ca7897d407.
-
Ko، "TPU Deep Dive".
-
Ko، "TPU Deep Dive".
-
Ko، "TPU Deep Dive".
-
Ko، "TPU Deep Dive".
-
Snider و Liang، "Operator Fusion in XLA".
-
APXML، "Memory-Aware Data Layout Transformations".
-
Google Cloud Blog، "How Lightricks trains video diffusion models at scale with JAX on TPU"، تم الوصول إليه ديسمبر 2025، https://cloud.google.com/blog/products/media-entertainment/how-lightricks-trains-video-diffusion-models-at-scale-with-jax-on-tpu.
-
CloudOptimo، "TPU vs GPU: What's the Difference in 2025?"، تم الوصول إليه ديسمبر 2025، https://www.cloudoptimo.com/blog/tpu-vs-gpu-what-is-the-difference-in-2025/.
-
Phoenix NAP، "TPU vs. GPU: Differences Explained"، تم الوصول إليه ديسمبر 2025، https://phoenixnap.com/kb/tpu-vs-gpu.
-
CloudOptimo، "TPU vs GPU".
-
DataCamp، "Understanding TPUs vs GPUs in AI".
-
Tailscale، "TPU vs GPU: Which Is Better for AI Infrastructure in 2025?"، تم الوصول إليه ديسمبر 2025، https://tailscale.com/learn/what-is-tpu-vs-gpu.
-
DataCamp، "Understanding TPUs vs GPUs in AI".
-
DataCamp، "Understanding TPUs vs GPUs in AI".
-
PyTorch Documentation، "Custom Kernels via Pallas".
-
Phoenix NAP، "TPU vs. GPU: Differences Explained".
-
Ko، "TPU Deep Dive".
-
OpenMetal، "TPU vs GPU: Pros and Cons"، تم الوصول إليه ديسمبر 2025، https://openmetal.io/docs/product-guides/private-cloud/tpu-vs-gpu-pros-and-cons/.
-
OpenMetal، "TPU vs GPU: Pros and Cons".
-
Phoenix NAP، "TPU vs. GPU: Differences Explained".
-
PRIMO.ai، "Processing Units - CPU, GPU, APU, TPU, VPU, FPGA, QPU"، تم الوصول إليه ديسمبر 2025، https://primo.ai/index.php?title=Processing_Units_-_CPU%2C_GPU%2C_APU%2C_TPU%2C_VPU%2C_FPGA%2C_QPU.
-
DataCamp، "Understanding TPUs vs GPUs in AI".
-
Google Cloud Documentation، "Profile your model on Cloud TPU VMs"، تم الوصول إليه ديسمبر 2025، https://cloud.google.com/tpu/docs/cloud-tpu-tools.
-
DataCamp، "Understanding TPUs vs GPUs in AI".
-
Ko، "TPU Deep Dive".
-
GitHub، "RFC: Evolving PyTorch/XLA".
-
Google Cloud Press Corner، "Anthropic to Expand Use".
-
TrendForce، "Google Unveils 7th-Gen TPU Ironwood".
-
Maginative، "Anthropic Secures 1M Google TPUs While Keeping Amazon as Primary Training Partner"، تم الوصول إليه ديسمبر 2025، https://www.maginative.com/article/anthropic-secures-1m-google-tpus-while-keeping-amazon-as-primary-training-partner/.
-
Anthropic، "A postmortem of three recent issues"، Engineering Blog، أغسطس 2025، https://www.anthropic.com/engineering/a-postmortem-of-three-recent-issues.
-
Anthropic، "A postmortem of three recent issues".
-
AI Magazine، "Why Anthropic Uses Google Cloud TPUs for AI Infrastructure"، تم الوصول إليه ديسمبر 2025، https://aimagazine.com/news/why-anthropic-uses-google-cloud-tpus-for-ai-infrastructure.
-
Google Cloud Blog، "Ironwood TPUs and new Axion-based VMs for your AI workloads"، نوفمبر 2025، https://cloud.google.com/blog/products/compute/ironwood-tpus-and-new-axion-based-vms-for-your-ai-workloads.
-
Ko، "TPU Deep Dive".
-
TrendForce، "Google Unveils 7th-Gen TPU Ironwood".
-
Ko، "TPU Deep Dive".
-
Ko، "TPU Deep Dive".
-
Ko، "TPU Deep Dive".
-
Ko، "TPU Deep Dive".
-
Ko، "TPU Deep Dive".
-
Google Cloud، "Tensor Processing Units (TPUs)"، تم الوصول إليه ديسمبر 2025، https://cloud.google.com/tpu.
-
TensorFlow Documentation، "Optimize TensorFlow performance using the Profiler"، تم الوصول إليه ديسمبر 2025، https://www.tensorflow.org/guide/profiler.
-
Google Cloud Documentation، "Profile your model on Cloud TPU VMs".
-
TensorFlow Documentation، "TensorFlow Profiler: Profile model performance"، تم الوصول إليه ديسمبر 2025، https://www.tensorflow.org/tensorboard/tensorboard_profiling_keras.
-
Google Cloud Documentation، "Profile your model on Cloud TPU VMs".
-
Google Cloud Blog، "PyTorch/XLA: Performance debugging on Cloud TPU VM: Part III"، تم الوصول إليه ديسمبر 2025، https://cloud.google.com/blog/topics/developers-practitioners/pytorchxla-performance-debugging-cloud-tpu-vm-part-iii.
-
Google Cloud Blog، "PyTorch/XLA: Performance debugging Part III".
-
Google Cloud Documentation، "Profile PyTorch XLA workloads"، تم الوصول إليه ديسمبر 2025، https://docs.cloud.google.com/tpu/docs/pytorch-xla-performance-profiling-tpu-vm.
-
TensorFlow Documentation، "Optimize TensorFlow performance using the Profiler".
-
TensorFlow Documentation، "Optimize TensorFlow performance using the Profiler".
-
Ko، "TPU Deep Dive".
-
Google Cloud Documentation، "Cloud TPU performance guide".
-
TensorFlow Documentation، "Optimize TensorFlow performance using the Profiler".
-
TensorFlow Documentation، "Optimize TensorFlow performance using the Profiler".
-
TensorFlow Documentation، "Optimize TensorFlow performance using the Profiler".
-
TrendForce، "Google Unveils 7th-Gen TPU Ironwood".
-
Tse، "Understanding the FP64, FP32, FP16, BFLOAT16, TF32, FP8 Formats".
-
Ko، "TPU Deep Dive".
-
Ko، "TPU Deep Dive".
-
Ko، "TPU Deep Dive".
-
Ko، "TPU Deep Dive".


