

Heb je het gevoel dat je praktisch het gezoem van GPU's kunt horen telkens als iemand "large language models" noemt? Er is een reden voor dat kosmische niveau van buzz: Transformer-architecturen. En als we dat fenomeen terugtraceren naar zijn Big Bang-moment, komen we vierkant uit bij een inmiddels legendarisch paper uit 2017 van een groep Google Brain en Google Research engineers: Attention Is All You Need.
Op het eerste gezicht zou de zin kunnen klinken als een zachte aansporing tot mindfulness, maar het luidde een revolutie in natural language processing (NLP) en daarbuiten in. Het Transformer-model gooide de AI-status quo in één snelle beweging omver: geen geleidelijke progressie meer van RNN's, LSTM's en convolutie-gebaseerde sequentiemodellen. In plaats daarvan kregen we een paralleliseerbaar, attention-gedreven systeem dat sneller traint, groter schaalt, en—dit is de kicker—betere resultaten behaalt.
1. Het Grote Idee: Hulde aan Self-Attention
Voordat Transformers ten tonele verschenen, was de goudstandaard voor sequentietransductie (denk aan taalvertaling, samenvatting, etc.) recurrente neurale netwerken met zorgvuldig ontworpen gatingsmechanismen of convolutionele neurale netwerken met ingewikkelde stapeling om lange-afstand afhankelijkheden aan te pakken. Effectief? Ja. Langzaam? Ook ja—vooral wanneer je echt massale datasets moet analyseren.
In eenvoudigste termen is self-attention een mechanisme waarmee elke token in een sequentie (bijv. een woord of subwoord) gelijktijdig naar elke andere token kan "kijken", contextrelaties kan ontdekken zonder gedwongen te worden stap-voor-stap door de data te kruipen. Deze benadering contrasteert met oudere modellen, zoals RNN's en LSTM's, die de sequentie grotendeels sequentieel moesten verwerken.
Transformers maken veel meer parallelisatie mogelijk door recurrentie (en de overhead die daarmee komt) weg te gooien. Je kunt een berg GPU's op het probleem gooien, trainen op massale datasets, en resultaten zien in dagen in plaats van weken.
[caption id="" align="alignnone" width="847"]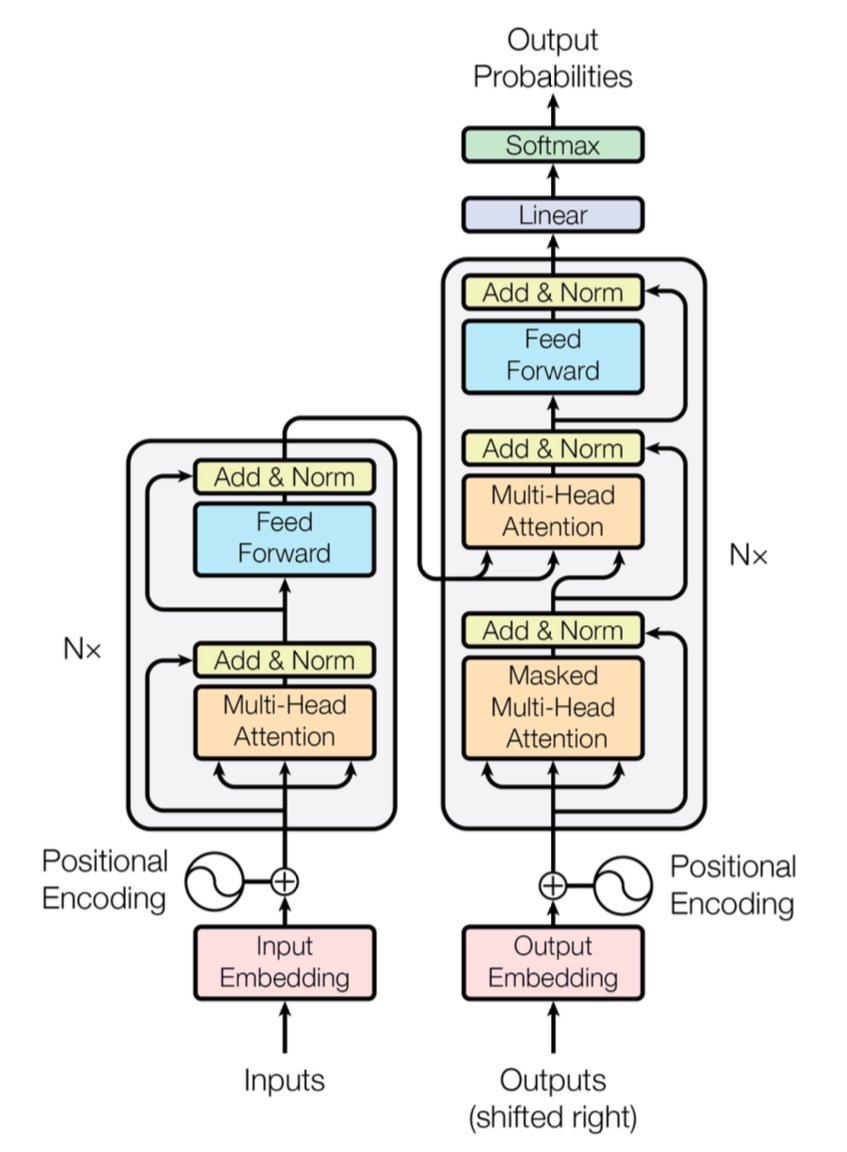 Figuur 1: De complete Transformer-architectuur met encoder (links) en decoder (rechts) met multi-head attention-lagen. Bron: Vaswani et al., "Attention Is All You Need" (2017). Afbeelding gereproduceerd voor educatieve doeleinden onder fair use. [/caption]
Figuur 1: De complete Transformer-architectuur met encoder (links) en decoder (rechts) met multi-head attention-lagen. Bron: Vaswani et al., "Attention Is All You Need" (2017). Afbeelding gereproduceerd voor educatieve doeleinden onder fair use. [/caption]
Korte Prestatie-opmerking: De oorspronkelijke Transformer toonde een 28,4 BLEU-score op de WMT 2014 Engels-naar-Duits taak—een stevige sprong over eerdere neurale machinevertaling-architecturen zoals CNN-gebaseerde en RNN-gebaseerde modellen, die rond de 25–26 BLEU op zijn best zweefden. Tegenwoordig gaan verbeterde Transformers (denk aan GPT-4 en zijn neven) nog verder, en pakken taken aan voorbij vertaling.
2. Onder de Motorkap: Multi-Head Attention en Positionele Coderingen
Multi-Head Attention
Binnen de self-attention van de Transformer bevinden zich deze magische wezens genaamd multi-head attention-modules. Ze laten het netwerk verschillende soorten relaties parallel leren. Denk eraan als het inzetten van meerdere schijnwerpers om verschillende delen van je data gelijktijdig te verlichten. Één attention-head zou lange-afstand afhankelijkheden kunnen volgen (zoals voornaamwoord-zelfstandig naamwoord referenties), terwijl een andere zich richt op lokale context (zoals de zin "op de mat" rond "kat"). Door deze gespecialiseerde sub-attentions te combineren, kan de Transformer genuanceerdere betekenis beter coderen.
[caption id="" align="alignnone" width="1220"]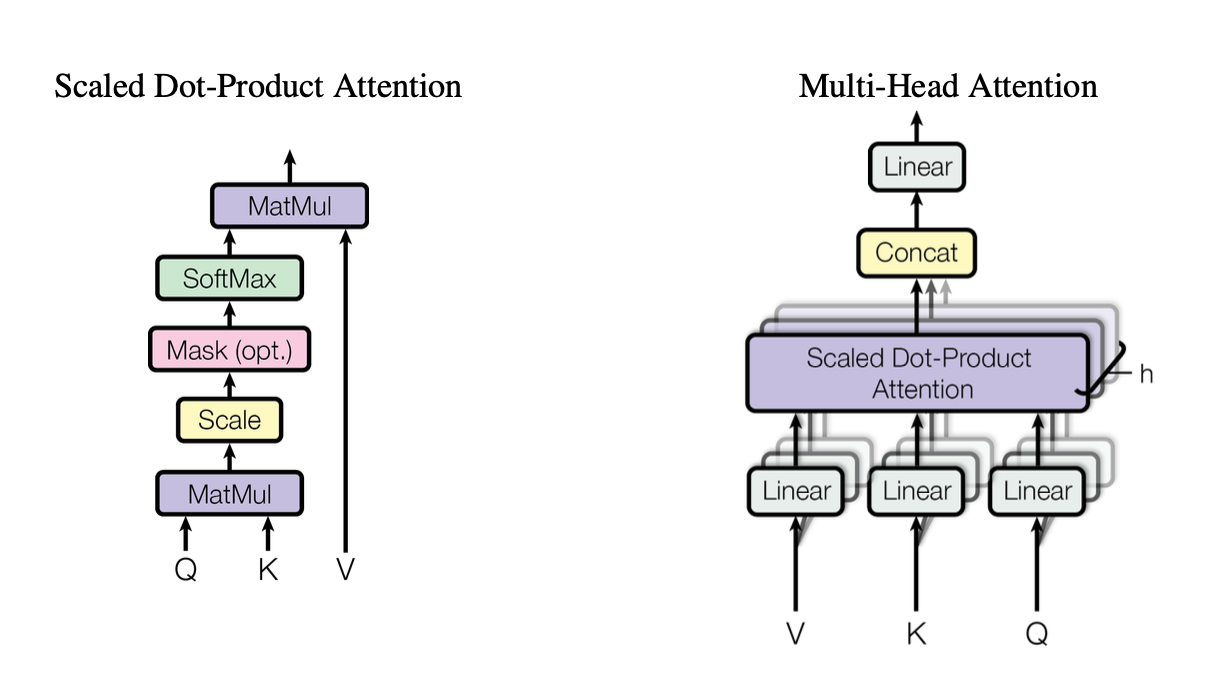 Figuur 2: Illustratie van het scaled dot-product attention-mechanisme dat toont hoe Query (Q), Key (K) en Value (V) vectoren interageren. Bron: Vaswani et al., "Attention Is All You Need" (2017). Afbeelding gereproduceerd voor educatieve doeleinden onder fair use. [/caption]
Figuur 2: Illustratie van het scaled dot-product attention-mechanisme dat toont hoe Query (Q), Key (K) en Value (V) vectoren interageren. Bron: Vaswani et al., "Attention Is All You Need" (2017). Afbeelding gereproduceerd voor educatieve doeleinden onder fair use. [/caption]
Deze heads gebruiken scaled dot-product attention als een standaard bouwsteen, die we in code kunnen samenvatten als:
import torchimport math def scaled_dot_product_attention(Q, K, V): # Q, K, V zijn [batch_size, heads, seq_len, d_k] d_k = Q.size(-1) scores = torch.matmul(Q, K.transpose(-2, -1)) / math.sqrt(d_k) weights = torch.softmax(scores, dim=-1) return torch.matmul(weights, V)
Elke head werkt op anders geprojecteerde versies van queries (Q), keys (K) en values (V), en voegt vervolgens de resultaten samen. Dit paralleliseerbare ontwerp is de sleutel tot de efficiëntie van de Transformer.
Positionele Coderingen
Geen recurrenties? Dat roept de vraag op: Hoe houdt het model de woordvolgorde bij? Betreed positionele coderingen—een sinusoïdaal of geleerd patroon toegevoegd aan elke token's embedding, wat de Transformer helpt een gevoel van sequentie te behouden. Het is alsof je elk woord een unieke tijdstempel geeft.
3. Snelle Prestatie-vergelijking
-
RNN's/LSTM's: Geweldig voor sequentietaken maar langzaam voor lange sequenties vanwege stap-voor-stap verwerking.
-
CNN's (bijv. ConvS2S): Sneller dan RNN's maar nog steeds niet volledig parallel voor lange-afstand afhankelijkheden.
-
Transformers:
Hogere Doorvoer: Kunnen hele sequenties parallel verwerken, wat training aanzienlijk sneller maakt.
-
Betere Resultaten: Transformers behaalden state-of-the-art scores in taken zoals machinevertaling (28,4 BLEU op WMT14 EN-DE) met minder trainingstijd.
-
Schaalbaar: Gooi meer GPU's op de data en kijk hoe het bijna lineair schaalt (binnen hardware- en geheugenlimieten).
4. De Complexiteitsoverweging: O(n²) en Waarom Het Belangrijk Is
Hoewel Transformers training versnellen door parallelisatie, draagt self-attention een O(n²) complexiteit wat betreft sequentielengte n. Met andere woorden, elke token let op elke andere token, wat duur kan zijn voor extreem lange sequenties. Onderzoekers verkennen actief efficiëntere attention-mechanismen (zoals sparse of blok-gewijze attention) om deze kosten te beperken.
Desondanks, voor typische NLP-taken waar token-aantallen in de duizenden liggen in plaats van miljoenen, wordt deze O(n²) overhead vaak opgewogen door de voordelen van parallelle berekening—vooral als je de juiste hardware hebt.
5. Waarom Het Belangrijk Is voor Large Language Models (LLM's)
Moderne LLM's—zoals GPT, BERT en T5—traceren hun afstamming direct naar de Transformer. Dat komt omdat de focus van het oorspronkelijke paper op parallelisme, self-attention en flexibele contextvensters het ideaal geschikt maakte voor taken voorbij vertaling, waaronder:
-
Tekstgeneratie & Samenvatting
-
Vraag-beantwoording
-
Code-aanvulling
-
Meertalige Chatbots
-
En ja, je nieuwe AI-schrijfassistent lijkt altijd een woordspeling in petto te hebben.
Kortom, "Attention Is All You Need" effende de weg voor deze grote modellen die miljarden tokens opnemen en bijna elke NLP-taak aankunnen die je hun kant op gooit.
6. We gaan meer compute nodig hebben: Waar Introl's Deployments Binnenkomen
Hier is de kink in de kabel: Transformers zijn hongerig—heel hongerig. Het trainen van een large language model kan betekenen dat je computerbronnen per vorkheftruck opzuigt. Om al die parallelisatie te benutten, heb je robuuste GPU-deployments nodig—soms in de duizenden (of tienduizenden). Daar komt high-performance computing (HPC) infrastructuur om de hoek kijken.
Bij Introl hebben we uit eerste hand gezien hoe massaal deze systemen kunnen worden. We hebben gewerkt aan builds met meer dan 100.000 GPU's op krappe tijdschema's—praat maar over logistieke bekwaamheid. Ons brood en boter zijn het deployen van GPU-servers, racks en geavanceerde stroom/koeling-opstellingen zodat alles efficiënt zoemt. Wanneer je gelijktijdig een Transformer-gebaseerd model traint op duizenden nodes, is elke hardware-bottleneck een energievortex voor zowel tijd als geld.
-
Grootschalige GPU-clusters: We hebben deployments uitgevoerd die voorbij 100K GPU's gingen, wat betekent dat we de complexiteiten begrijpen van rack-and-stack configuraties, bekabeling en stroom/koeling-strategieën om alles stabiel te houden.
-
Snelle Mobilisatie: Nog eens 2.000 GPU-nodes nodig in een paar dagen? Onze gespecialiseerde teams kunnen ter plaatse en operationeel zijn binnen 72 uur.
-
End-to-End Ondersteuning: Van firmware-updates en iDRAC-configuraties tot doorlopend onderhoud en prestatiecontroles, wij beheren de logistiek zodat je datawetenschappers zich kunnen blijven richten op innovatie.
7. Vooruitkijken: Grotere Modellen, Grotere Dromen
"Attention Is All You Need" is niet alleen een mijlpaal—het is de blauwdruk voor toekomstige uitbreidingen. Onderzoekers verkennen al langere-context Transformers, efficiënte attention-mechanismen en geavanceerde sparsity om enorme corpora aan te pakken (denk: hele bibliotheken, niet alleen je lokale boekwinkel). Je kunt erop rekenen dat de honger naar GPU-versnelde computing alleen maar zal toenemen.
En dat is de schoonheid van het Transformer-tijdperk. We hebben een model dat elegant kan schalen, mits we het matchen met de juiste hardware-strategie. Dus of je nu het volgende generatieve AI-fenomeen bouwt of de grenzen van universele vertaling verlegt, het hebben van een infrastructuurpartner die bedreven is in massale GPU-deployments is meer dan alleen leuk om te hebben; het is praktisch je concurrentievoordeel.
Laatste Gedachte: Transform Je AI-spel
Het paper Attention Is All You Need was meer dan een slimme titel—het was een seismische verschuiving. Transformers hebben alles getransformeerd van machinevertaling tot codegeneratie en daarbuiten. Als je die kracht op schaal wilt benutten, is de sleutel het matchen van briljante architectuur met even briljante infrastructuur.
Klaar om op te schalen? Ontdek hoe Introl's gespecialiseerde GPU Infrastructure Deployments je volgende grote Transformer-project kunnen versnellen—omdat de juiste hardware het verschil kan maken in AI.
De visualisaties in dit artikel zijn afkomstig uit het oorspronkelijke "Attention Is All You Need" paper (Vaswani et al., 2017) en zijn opgenomen met naamsvermelding onder fair use voor educatieve doeleinden. Het paper is beschikbaar op https://arxiv.org/abs/1706.03762 voor lezers die geïnteresseerd zijn in het complete onderzoek.


