

Você sente que pode praticamente ouvir o zumbido das GPUs toda vez que alguém menciona "large language models"? Há uma razão para esse buzz de nível cósmico: arquiteturas Transformer. E se estivermos rastreando esse fenômeno de volta ao seu momento Big Bang, chegamos diretamente em um paper agora lendário de 2017 de um grupo de engenheiros do Google Brain e Google Research: Attention Is All You Need.
À primeira vista, a frase pode soar como um lembrete gentil sobre mindfulness, mas anunciou uma revolução no processamento de linguagem natural (NLP) e além. O modelo Transformer revolucionou o status quo da AI de uma só vez: chega de progressão passo a passo de RNNs, LSTMs e modelos de sequência baseados em convolução. Em vez disso, obtivemos um sistema paralelizável, orientado por atenção, que treina mais rápido, escala maior e—aqui está o diferencial—alcança melhores resultados.
1. A Grande Ideia: Salve a Self-Attention
Antes dos Transformers surgirem na cena, o padrão ouro para transdução de sequências (pense tradução de idiomas, sumarização, etc.) envolvia redes neurais recorrentes com mecanismos de gate cuidadosamente projetados ou redes neurais convolucionais com empilhamento complicado para lidar com dependências de longo alcance. Eficaz? Sim. Lento? Também sim—especialmente quando você precisa analisar datasets verdadeiramente massivos.
Em termos mais simples, self-attention é um mecanismo pelo qual cada token em uma sequência (ex., uma palavra ou subpalavra) pode "olhar" para todos os outros tokens simultaneamente, descobrindo relações contextuais sem ser forçado a percorrer os dados passo a passo. Esta abordagem contrasta com modelos mais antigos, como RNNs e LSTMs, que tinham que processar a sequência amplamente de forma sequencial.
Transformers permitem muito mais paralelização ao descartar recorrência (e a sobrecarga que vem com ela). Você pode jogar uma abundância de GPUs no problema, treinar em datasets massivos e ver resultados em dias ao invés de semanas.
[caption id="" align="alignnone" width="847"]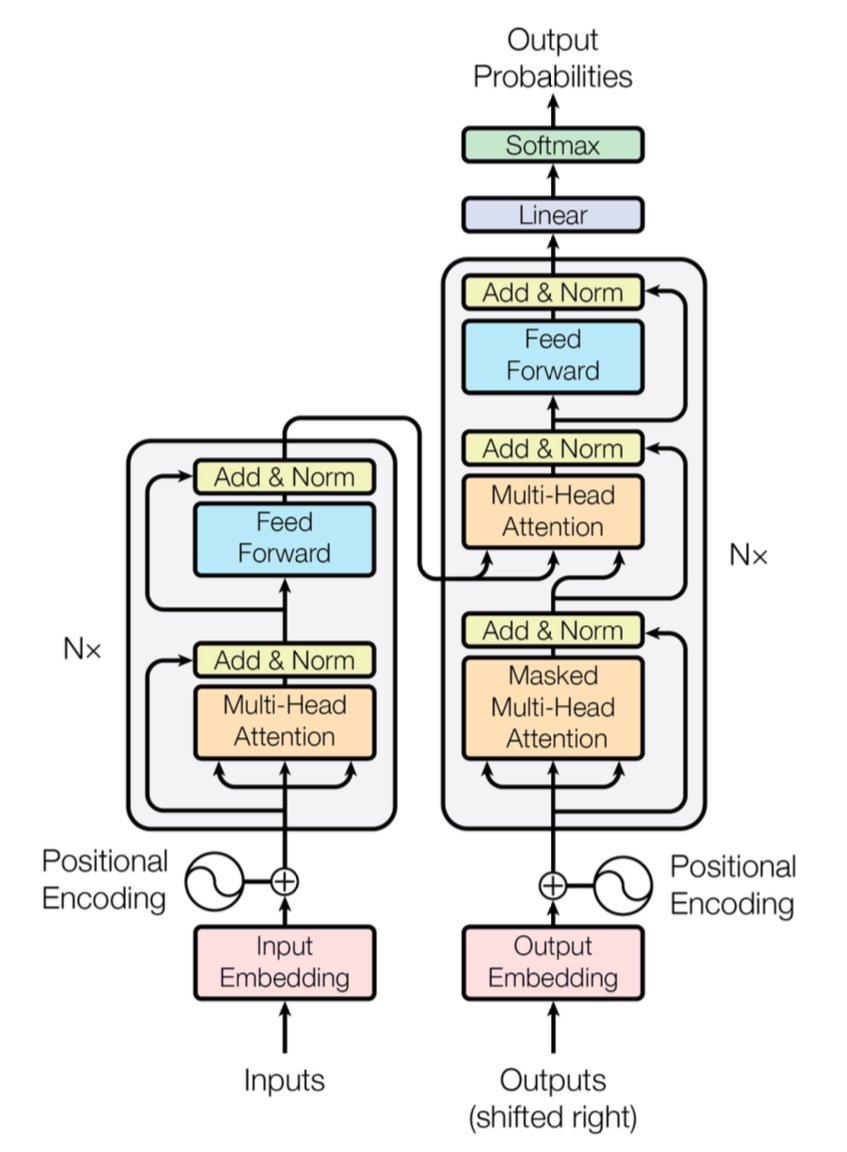 Figura 1: A arquitetura completa do Transformer mostrando encoder (esquerda) e decoder (direita) com camadas de multi-head attention. Fonte: Vaswani et al., "Attention Is All You Need" (2017). Imagem reproduzida para fins educacionais sob uso justo. [/caption]
Figura 1: A arquitetura completa do Transformer mostrando encoder (esquerda) e decoder (direita) com camadas de multi-head attention. Fonte: Vaswani et al., "Attention Is All You Need" (2017). Imagem reproduzida para fins educacionais sob uso justo. [/caption]
Nota Rápida de Performance: O Transformer original demonstrou um score BLEU de 28.4 na tarefa WMT 2014 English-to-German—um salto sólido sobre arquiteturas anteriores de tradução automática neural como modelos baseados em CNN e RNN, que ficavam em torno de 25–26 BLEU na melhor das hipóteses. Hoje em dia, Transformers aprimorados (pense GPT-4 e seus primos) vão ainda mais longe, lidando com tarefas além da tradução.
2. Por Dentro do Capô: Multi-Head Attention e Positional Encodings
Multi-Head Attention
Dentro da self-attention do Transformer estão essas criaturas mágicas chamadas módulos de multi-head attention. Eles permitem que a rede aprenda diferentes tipos de relacionamentos em paralelo. Pense nisso como implantar múltiplos holofotes para iluminar várias partes dos seus dados simultaneamente. Uma attention head pode rastrear dependências de longa distância (como referências pronome-substantivo), enquanto outra foca no contexto local (como a frase "no tapete" ao redor de "gato"). Combinando essas sub-attentions especializadas, o Transformer pode codificar melhor significado nuançado.
[caption id="" align="alignnone" width="1220"]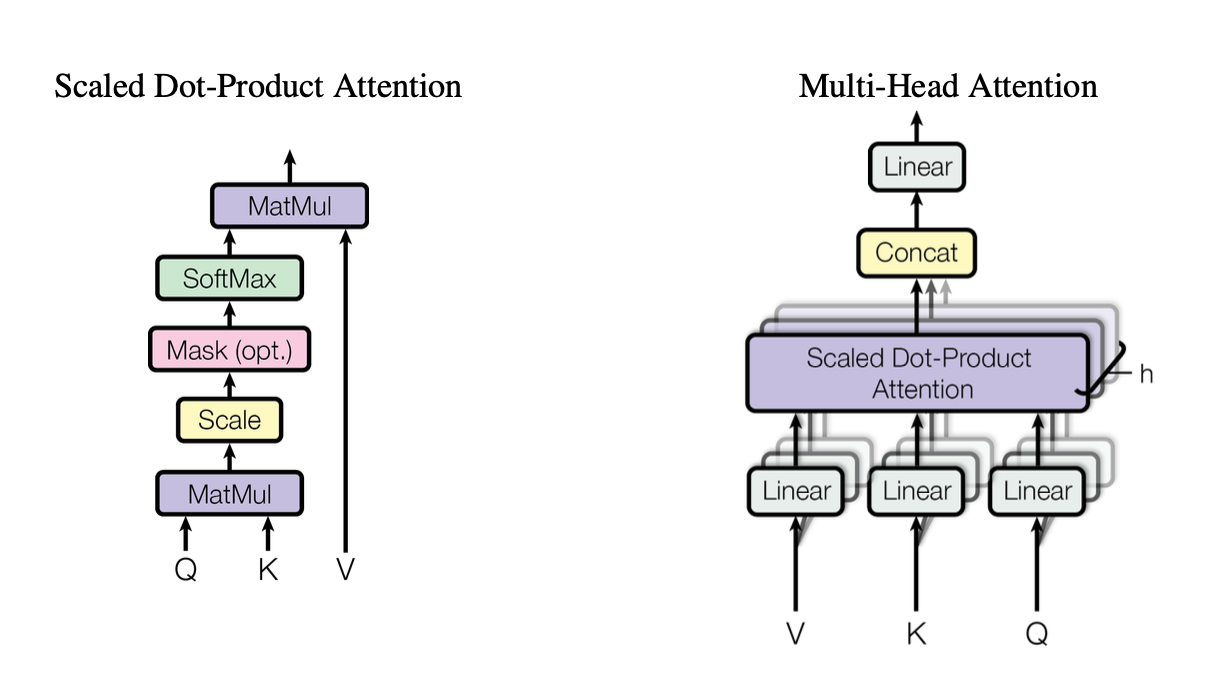 Figura 2: Ilustração do mecanismo de scaled dot-product attention mostrando como os vetores Query (Q), Key (K) e Value (V) interagem. Fonte: Vaswani et al., "Attention Is All You Need" (2017). Imagem reproduzida para fins educacionais sob uso justo. [/caption]
Figura 2: Ilustração do mecanismo de scaled dot-product attention mostrando como os vetores Query (Q), Key (K) e Value (V) interagem. Fonte: Vaswani et al., "Attention Is All You Need" (2017). Imagem reproduzida para fins educacionais sob uso justo. [/caption]
Essas heads usam scaled dot-product attention como bloco de construção padrão, que podemos resumir em código como:
import torchimport math def scaled_dot_product_attention(Q, K, V): # Q, K, V são [batch_size, heads, seq_len, d_k] d_k = Q.size(-1) scores = torch.matmul(Q, K.transpose(-2, -1)) / math.sqrt(d_k) weights = torch.softmax(scores, dim=-1) return torch.matmul(weights, V)
Cada head opera em versões projetadas de forma diferente de queries (Q), keys (K) e values (V), depois mescla os resultados. Este design paralelizável é fundamental para a eficiência do Transformer.
Positional Encodings
Sem recorrências? Isso levanta a questão: Como o modelo mantém controle da ordem das palavras? Entre os positional encodings—um padrão senoidal ou aprendido adicionado ao embedding de cada token, ajudando o Transformer a manter um senso de sequência. É como dar a cada palavra um timestamp único.
3. Comparação Rápida de Performance
-
RNNs/LSTMs: Ótimos para tarefas de sequência mas lentos para sequências longas devido ao processamento passo a passo.
-
CNNs (ex., ConvS2S): Mais rápidos que RNNs mas ainda não totalmente paralelos para dependências de longo alcance.
-
Transformers:
Maior Throughput: Podem processar sequências inteiras em paralelo, tornando o treinamento significativamente mais rápido.
-
Melhores Resultados: Transformers alcançaram scores estado da arte em tarefas como tradução automática (28.4 BLEU no WMT14 EN-DE) com menos tempo de treinamento.
-
Escaláveis: Jogue mais GPUs nos dados e veja escalar quase linearmente (dentro dos limites de hardware e memória).
4. A Consideração de Complexidade: O(n²) e Por Que Importa
Enquanto Transformers aceleram o treinamento através de paralelização, self-attention carrega uma complexidade O(n²) em relação ao comprimento da sequência n. Em outras palavras, cada token atende a todos os outros tokens, o que pode ser caro para sequências extremamente longas. Pesquisadores estão explorando ativamente mecanismos de atenção mais eficientes (como atenção esparsa ou por blocos) para mitigar esse custo.
Mesmo assim, para tarefas típicas de NLP onde contagens de tokens estão na casa dos milhares ao invés de milhões, essa sobrecarga O(n²) é frequentemente superada pelos benefícios da computação paralela—especialmente se você tem o hardware adequado.
5. Por Que Importa para Large Language Models (LLMs)
LLMs modernos—como GPT, BERT e T5—traçam sua linhagem diretamente ao Transformer. Isso porque o foco do paper original em paralelismo, self-attention e janelas de contexto flexíveis o tornou idealmente adequado para tarefas além da tradução, incluindo:
-
Geração de Texto & Sumarização
-
Question-Answering
-
Completação de Código
-
Chatbots Multilíngues
-
E sim, seu novo assistente de escrita AI sempre parece ter um trocadilho na manga.
Em resumo, "Attention Is All You Need" pavimentou o caminho para esses modelos grandes que ingerem bilhões de tokens e lidam com quase qualquer tarefa de NLP que você jogue para eles.
6. Vamos precisar de mais computação: Onde os Deployments da Introl Entram
Aqui está o problema: Transformers são famintos—muito famintos. Treinar um large language model pode significar sugar recursos computacionais às carradas. Para aproveitar todo esse paralelismo, você precisa de deployments robustos de GPU—às vezes numerando milhares (ou dezenas de milhares). É aí que a infraestrutura de computação de alto desempenho (HPC) entra.
Na Introl, vimos em primeira mão como esses sistemas podem ficar massivos. Trabalhamos em builds envolvendo mais de 100.000 GPUs em prazos apertados—isso sim é proeza logística. Nosso pão com manteiga são deploying servidores GPU, racks e configurações avançadas de energia/resfriamento para que tudo funcione eficientemente. Quando você está simultaneamente treinando um modelo baseado em Transformer em milhares de nós, qualquer gargalo de hardware é um vórtex de energia tanto para tempo quanto para dinheiro.
-
Clusters de GPU em Larga Escala: Executamos deployments que ultrapassaram 100K GPUs, significando que entendemos as complexidades de configurações rack-and-stack, cabeamento e estratégias de energia/resfriamento para manter tudo estável.
-
Mobilização Rápida: Precisa adicionar outros 2.000 nós de GPU em alguns dias? Nossas equipes especializadas podem estar no local e operacionais em 72 horas.
-
Suporte End-to-End: De atualizações de firmware e configurações iDRAC a manutenção contínua e verificações de performance, gerenciamos a logística para que seus cientistas de dados possam permanecer focados na inovação.
7. Olhando Adiante: Modelos Maiores, Sonhos Maiores
"Attention Is All You Need" não é apenas um marco—é o blueprint para expansões futuras. Pesquisadores já estão explorando Transformers de contexto mais longo, mecanismos de atenção eficientes e sparsity avançada para lidar com corpora enormes (pense: bibliotecas inteiras, não apenas sua livraria local). Tenha certeza, o apetite por computação acelerada por GPU só vai aumentar.
E essa é a beleza da era Transformer. Temos um modelo que pode escalar elegantemente, desde que o combinemos com a estratégia de hardware adequada. Então, seja você construindo o próximo fenômeno de AI generativa ou empurrando os limites da tradução universal, ter um parceiro de infraestrutura adepto em deployments massivos de GPU é mais que apenas um nice-to-have; é praticamente sua vantagem competitiva.
Pensamento Final: Transforme Seu Jogo de AI
O paper Attention Is All You Need foi mais que um título inteligente—foi uma mudança sísmica. Transformers transformaram tudo desde tradução automática até geração de código e além. Se você quer aproveitar esse poder em escala, a chave é combinar arquitetura brilhante com infraestrutura igualmente brilhante.
Pronto para escalar? Descubra como os Deployments de Infraestrutura GPU especializados da Introl podem acelerar seu próximo grande projeto Transformer—porque o hardware adequado pode fazer toda a diferença em AI.
As visualizações neste artigo são do paper original "Attention Is All You Need" (Vaswani et al., 2017) e estão incluídas com atribuição sob uso justo para fins educacionais. O paper está disponível em https://arxiv.org/abs/1706.03762 para leitores interessados na pesquisa completa.


