

Avez-vous l'impression d'entendre pratiquement le bourdonnement des GPU chaque fois que quelqu'un mentionne « grands modèles de langage » ? Il y a une raison à ce buzz d'ampleur cosmique : les architectures Transformer. Et si nous remontons ce phénomène à son moment Big Bang, nous atterrissons directement sur un article désormais légendaire de 2017, rédigé par un groupe d'ingénieurs de Google Brain et Google Research : Attention Is All You Need.
À première vue, la phrase pourrait ressembler à un doux encouragement vers la pleine conscience, mais elle a annoncé une révolution dans le traitement du langage naturel (NLP) et au-delà. Le modèle Transformer a bouleversé le statu quo de l'IA d'un seul coup : fini la progression centimètre par centimètre des RNN, LSTM et modèles de séquence basés sur la convolution. À la place, nous avons obtenu un système parallélisable, piloté par l'attention, qui s'entraîne plus vite, monte mieux en charge et — voici le plus important — obtient de meilleurs résultats.
1. La grande idée : Vive l'auto-attention
Avant que les Transformers n'arrivent sur scène, la référence pour la transduction de séquences (pensez à la traduction linguistique, au résumé, etc.) impliquait des réseaux de neurones récurrents avec des mécanismes de porte soigneusement conçus ou des réseaux de neurones convolutifs avec un empilement compliqué pour gérer les dépendances à longue portée. Efficace ? Oui. Lent ? Aussi, oui — surtout quand vous devez analyser des ensembles de données vraiment massifs.
En termes simples, l'auto-attention est un mécanisme par lequel chaque token dans une séquence (par exemple, un mot ou sous-mot) peut « regarder » tous les autres tokens simultanément, découvrant des relations contextuelles sans être forcé de ramper pas à pas à travers les données. Cette approche contraste avec les modèles plus anciens, comme les RNN et LSTM, qui devaient traiter la séquence largement de manière séquentielle.
Les Transformers permettent une parallélisation bien plus importante en abandonnant la récurrence (et les surcoûts qui l'accompagnent). Vous pouvez lancer une multitude de GPU sur le problème, entraîner sur des ensembles de données massifs et voir des résultats en jours plutôt qu'en semaines.
[caption id="" align="alignnone" width="847"]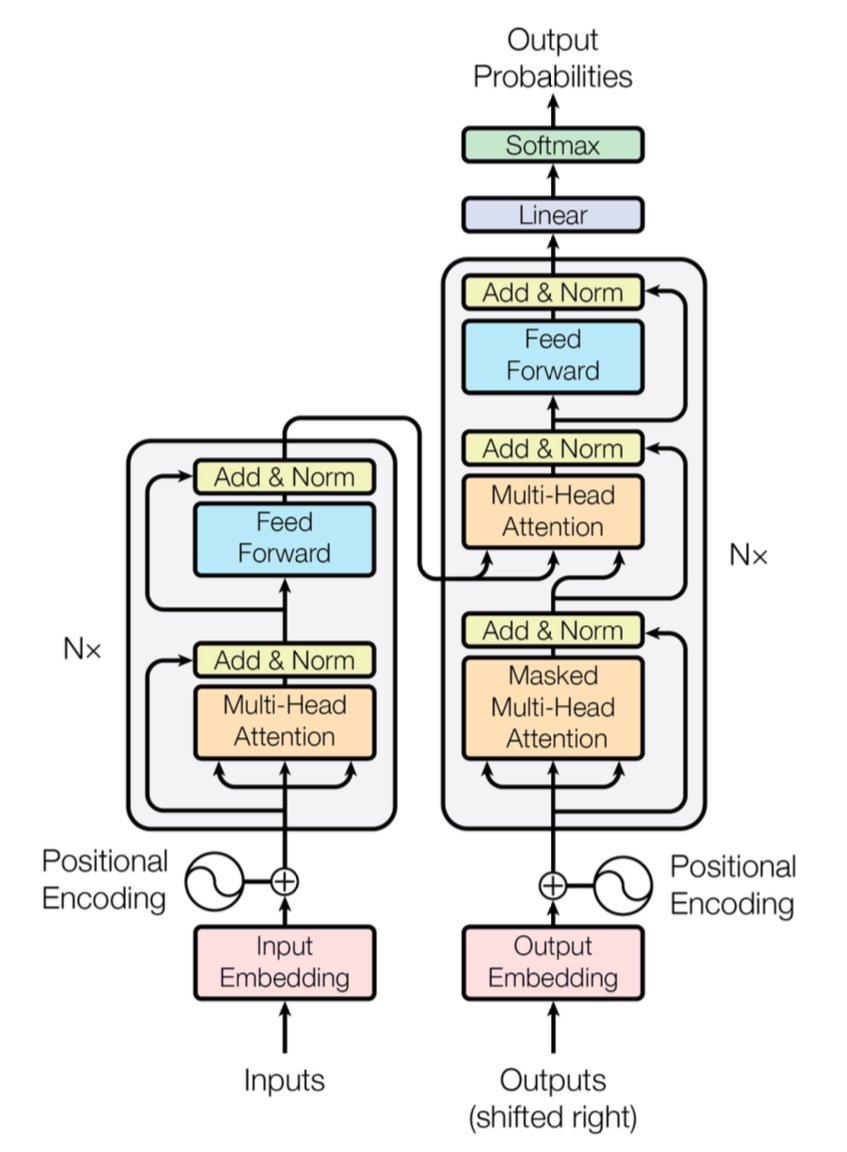 Figure 1 : L'architecture complète du Transformer montrant l'encodeur (gauche) et le décodeur (droite) avec les couches d'attention multi-têtes. Source : Vaswani et al., « Attention Is All You Need » (2017). Image reproduite à des fins éducatives sous usage équitable. [/caption]
Figure 1 : L'architecture complète du Transformer montrant l'encodeur (gauche) et le décodeur (droite) avec les couches d'attention multi-têtes. Source : Vaswani et al., « Attention Is All You Need » (2017). Image reproduite à des fins éducatives sous usage équitable. [/caption]
Note rapide sur les performances : Le Transformer original a démontré un score BLEU de 28,4 sur la tâche WMT 2014 anglais-allemand — un bond solide par rapport aux architectures antérieures de traduction automatique neuronale comme les modèles basés sur CNN et RNN, qui plafonnaient autour de 25-26 BLEU au mieux. De nos jours, les Transformers améliorés (pensez à GPT-4 et ses cousins) vont encore plus loin, gérant des tâches au-delà de la traduction.
2. Sous le capot : Attention multi-têtes et encodages positionnels
Attention multi-têtes
Au sein de l'auto-attention du Transformer se trouvent ces créatures magiques appelées modules d'attention multi-têtes. Ils permettent au réseau d'apprendre différents types de relations en parallèle. Imaginez cela comme déployer plusieurs projecteurs pour illuminer diverses parties de vos données simultanément. Une tête d'attention pourrait suivre les dépendances à longue distance (comme les références pronom-nom), tandis qu'une autre se concentre sur le contexte local (comme l'expression « sur le tapis » autour de « chat »). En combinant ces sous-attentions spécialisées, le Transformer peut mieux encoder des significations nuancées.
[caption id="" align="alignnone" width="1220"]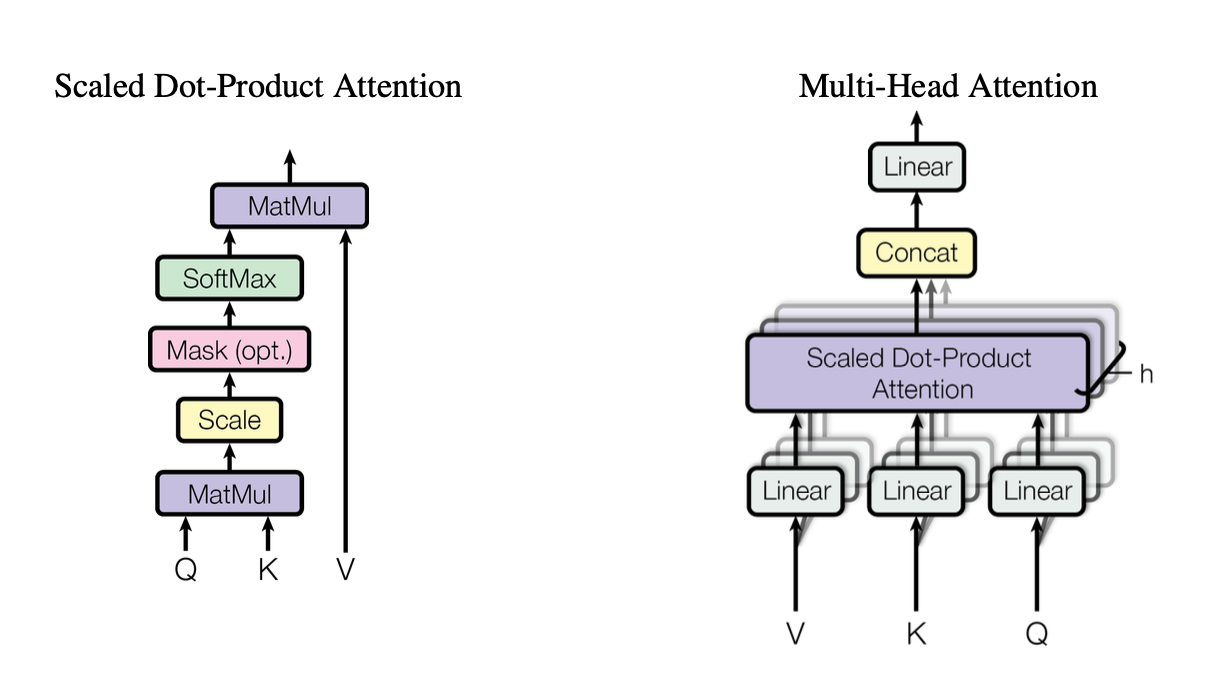 Figure 2 : Illustration du mécanisme d'attention par produit scalaire mis à l'échelle montrant comment les vecteurs Query (Q), Key (K) et Value (V) interagissent. Source : Vaswani et al., « Attention Is All You Need » (2017). Image reproduite à des fins éducatives sous usage équitable. [/caption]
Figure 2 : Illustration du mécanisme d'attention par produit scalaire mis à l'échelle montrant comment les vecteurs Query (Q), Key (K) et Value (V) interagissent. Source : Vaswani et al., « Attention Is All You Need » (2017). Image reproduite à des fins éducatives sous usage équitable. [/caption]
Ces têtes utilisent l'attention par produit scalaire mis à l'échelle comme bloc de construction standard, que nous pouvons résumer en code ainsi :
import torchimport math def scaled_dot_product_attention(Q, K, V): # Q, K, V sont [batch_size, heads, seq_len, d_k] d_k = Q.size(-1) scores = torch.matmul(Q, K.transpose(-2, -1)) / math.sqrt(d_k) weights = torch.softmax(scores, dim=-1) return torch.matmul(weights, V)
Chaque tête opère sur des versions différemment projetées des requêtes (Q), clés (K) et valeurs (V), puis fusionne les résultats. Cette conception parallélisable est la clé de l'efficacité du Transformer.
Encodages positionnels
Pas de récurrences ? Cela soulève la question : Comment le modèle garde-t-il la trace de l'ordre des mots ? Entrent en scène les encodages positionnels — un motif sinusoïdal ou appris ajouté à l'embedding de chaque token, aidant le Transformer à maintenir un sens de la séquence. C'est comme donner à chaque mot un horodatage unique.
3. Comparaison rapide des performances
-
RNN/LSTM : Excellents pour les tâches séquentielles mais lents pour les longues séquences en raison du traitement pas à pas.
-
CNN (par ex., ConvS2S) : Plus rapides que les RNN mais toujours pas entièrement parallèles pour les dépendances à longue portée.
-
Transformers :
Débit plus élevé : Peuvent traiter des séquences entières en parallèle, rendant l'entraînement significativement plus rapide.
-
Meilleurs résultats : Les Transformers ont atteint des scores à l'état de l'art dans des tâches comme la traduction automatique (28,4 BLEU sur WMT14 EN-DE) avec moins de temps d'entraînement.
-
Évolutif : Ajoutez plus de GPU aux données et regardez-le monter en charge de manière quasi linéaire (dans les limites du matériel et de la mémoire).
4. La considération de complexité : O(n²) et pourquoi c'est important
Bien que les Transformers accélèrent l'entraînement grâce à la parallélisation, l'auto-attention comporte une complexité O(n²) par rapport à la longueur de séquence n. En d'autres termes, chaque token prête attention à tous les autres tokens, ce qui peut être coûteux pour des séquences extrêmement longues. Les chercheurs explorent activement des mécanismes d'attention plus efficaces (comme l'attention sparse ou par blocs) pour atténuer ce coût.
Même ainsi, pour les tâches NLP typiques où le nombre de tokens se compte en milliers plutôt qu'en millions, cette surcharge O(n²) est souvent compensée par les avantages du calcul parallèle — surtout si vous disposez du matériel approprié.
5. Pourquoi c'est important pour les grands modèles de langage (LLM)
Les LLM modernes — comme GPT, BERT et T5 — tirent leur lignée directement du Transformer. C'est parce que l'accent mis par l'article original sur le parallélisme, l'auto-attention et les fenêtres de contexte flexibles l'a rendu idéalement adapté aux tâches au-delà de la traduction, notamment :
-
Génération de texte et résumé
-
Questions-réponses
-
Complétion de code
-
Chatbots multilingues
-
Et oui, votre nouvel assistant d'écriture IA qui semble toujours avoir un jeu de mots dans sa manche.
En bref, « Attention Is All You Need » a ouvert la voie à ces grands modèles qui ingèrent des milliards de tokens et gèrent presque n'importe quelle tâche NLP que vous leur soumettez.
6. Nous allons avoir besoin de plus de puissance de calcul : Où les déploiements d'Introl entrent en jeu
Voici le hic : Les Transformers sont affamés — très affamés. Entraîner un grand modèle de langage peut signifier aspirer des ressources de calcul par chariot élévateur. Pour exploiter toute cette parallélisation, vous avez besoin de déploiements GPU robustes — parfois comptés en milliers (ou dizaines de milliers). C'est là que l'infrastructure de calcul haute performance (HPC) entre en jeu.
Chez Introl, nous avons vu de première main à quel point ces systèmes peuvent devenir massifs. Nous avons travaillé sur des constructions impliquant plus de 100 000 GPU dans des délais serrés — parlons de prouesse logistique. Notre cœur de métier est le déploiement de serveurs GPU, de racks et de configurations avancées d'alimentation/refroidissement pour que tout fonctionne efficacement. Quand vous entraînez simultanément un modèle basé sur Transformer sur des milliers de nœuds, tout goulot d'étranglement matériel est un gouffre d'énergie en temps et en argent.
-
Clusters GPU à grande échelle : Nous avons exécuté des déploiements dépassant les 100K GPU, ce qui signifie que nous comprenons les subtilités des configurations rack-and-stack, du câblage et des stratégies d'alimentation/refroidissement pour garder tout stable.
-
Mobilisation rapide : Besoin d'ajouter 2 000 nœuds GPU supplémentaires en quelques jours ? Nos équipes spécialisées peuvent être sur site et opérationnelles dans les 72 heures.
-
Support de bout en bout : Des mises à jour de firmware et configurations iDRAC à la maintenance continue et aux vérifications de performance, nous gérons la logistique pour que vos data scientists puissent rester concentrés sur l'innovation.
7. Regard vers l'avenir : Des modèles plus grands, des rêves plus grands
« Attention Is All You Need » n'est pas qu'une étape importante — c'est le plan directeur pour les expansions futures. Les chercheurs explorent déjà des Transformers à contexte plus long, des mécanismes d'attention efficaces et une parcimonie avancée pour gérer d'énormes corpus (pensez : des bibliothèques entières, pas seulement votre librairie locale). Soyez assurés que l'appétit pour le calcul accéléré par GPU ne fera qu'augmenter.
Et c'est la beauté de l'ère Transformer. Nous avons un modèle qui peut élégamment monter en charge, à condition de l'associer à la bonne stratégie matérielle. Donc, que vous construisiez le prochain phénomène d'IA générative ou que vous repoussiez les limites de la traduction universelle, avoir un partenaire d'infrastructure expert en déploiements massifs de GPU est plus qu'un simple avantage — c'est pratiquement votre avantage compétitif.
Réflexion finale : Transformez votre stratégie IA
L'article Attention Is All You Need était plus qu'un titre accrocheur — c'était un séisme. Les Transformers ont transformé tout, de la traduction automatique à la génération de code et au-delà. Si vous voulez exploiter cette puissance à grande échelle, la clé est d'associer une architecture brillante à une infrastructure tout aussi brillante.
Prêt à passer à l'échelle supérieure ? Découvrez comment les déploiements d'infrastructure GPU spécialisés d'Introl peuvent accélérer votre prochain grand projet Transformer — car le bon matériel peut faire toute la différence en IA.
Les visualisations de cet article proviennent de l'article original « Attention Is All You Need » (Vaswani et al., 2017) et sont incluses avec attribution sous usage équitable à des fins éducatives. L'article est disponible sur https://arxiv.org/abs/1706.03762 pour les lecteurs intéressés par la recherche complète.


