

누군가 "대규모 언어 모델"을 언급할 때마다 GPU의 윙윙거리는 소리가 실제로 들리는 것 같은 느낌이 드나요? 그런 우주급 규모의 버즈에는 이유가 있습니다: Transformer 아키텍처. 이 현상을 빅뱅 순간까지 거슬러 올라가면, Google Brain과 Google Research 엔지니어 그룹이 2017년에 발표한 전설적인 논문에 도달합니다: Attention Is All You Need.
첫눈에 이 문구는 마음챙김에 대한 부드러운 권유처럼 들릴 수 있지만, 이는 자연어 처리(NLP)와 그 너머의 혁명을 예고했습니다. Transformer 모델은 한 번에 AI 현상 유지를 뒤흔들었습니다: RNN, LSTM, 그리고 합성곱 기반 시퀀스 모델의 조금씩 진행하는 방식은 더 이상 필요 없었습니다. 대신, 더 빠르게 훈련하고, 더 크게 확장하며, 그리고—여기가 핵심입니다—더 나은 결과를 달성하는 병렬화 가능한 어텐션 기반 시스템을 얻게 되었습니다.
1. 핵심 아이디어: 셀프 어텐션의 모든 것
Transformer가 등장하기 전, 시퀀스 변환(언어 번역, 요약 등)의 골드 스탠다드는 신중하게 설계된 게이팅 메커니즘을 가진 순환 신경망이나 장거리 의존성을 처리하기 위한 복잡한 스택을 가진 합성곱 신경망을 포함했습니다. 효과적인가? 그렇습니다. 느린가? 역시 그렇습니다—특히 정말 거대한 데이터셋을 분석해야 할 때는 더욱 그렇습니다.
가장 간단한 용어로 설명하면, 셀프 어텐션은 시퀀스의 모든 토큰(예: 단어 또는 부분단어)이 모든 다른 토큰을 동시에 "바라볼" 수 있게 하여, 데이터를 단계별로 천천히 크롤링하지 않고도 맥락적 관계를 발견할 수 있게 하는 메커니즘입니다. 이 접근법은 시퀀스를 대부분 순차적으로 처리해야 했던 RNN과 LSTM 같은 구형 모델과 대조됩니다.
Transformer는 순환(그리고 그에 따른 오버헤드)을 버림으로써 훨씬 더 많은 병렬화를 가능하게 합니다. 문제에 수많은 GPU를 투입하여 거대한 데이터셋으로 훈련하고 몇 주가 아닌 몇 일 만에 결과를 볼 수 있습니다.
[caption id="" align="alignnone" width="847"]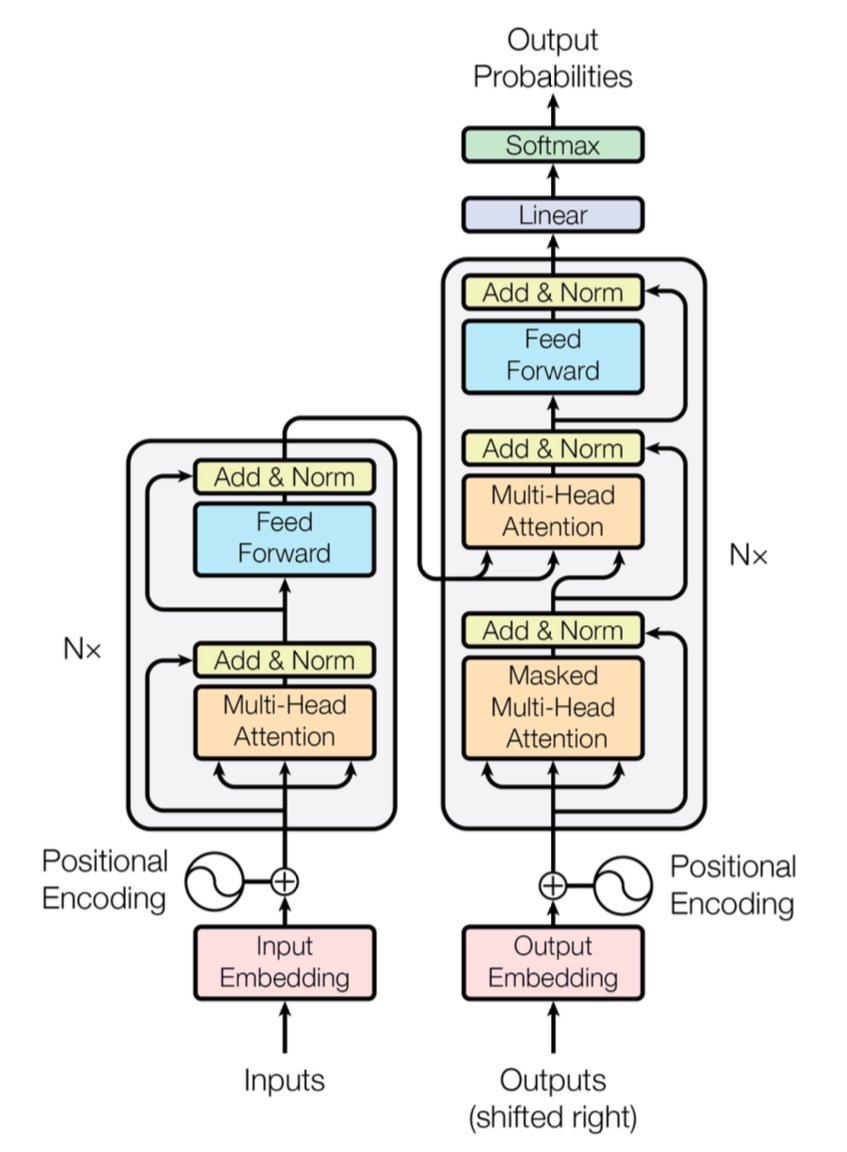 Figure 1: 멀티헤드 어텐션 레이어를 가진 인코더(왼쪽)와 디코더(오른쪽)를 보여주는 완전한 Transformer 아키텍처. 출처: Vaswani et al., "Attention Is All You Need" (2017). 교육 목적으로 공정 사용에 따라 복제된 이미지. [/caption]
Figure 1: 멀티헤드 어텐션 레이어를 가진 인코더(왼쪽)와 디코더(오른쪽)를 보여주는 완전한 Transformer 아키텍처. 출처: Vaswani et al., "Attention Is All You Need" (2017). 교육 목적으로 공정 사용에 따라 복제된 이미지. [/caption]
간단한 성능 참고사항: 원본 Transformer는 WMT 2014 영어-독일어 작업에서 28.4 BLEU 점수를 달성했습니다—이는 최대 25-26 BLEU 점수를 기록했던 CNN 기반 및 RNN 기반 모델 같은 이전 신경 기계 번역 아키텍처보다 상당한 도약이었습니다. 요즘에는 개선된 Transformer들(GPT-4와 그 변형들)이 번역을 넘어선 작업들을 처리하며 훨씬 더 나아갔습니다.
2. 내부 작동 원리: 멀티헤드 어텐션과 위치 인코딩
멀티헤드 어텐션
Transformer의 셀프 어텐션 안에는 멀티헤드 어텐션 모듈이라고 불리는 마법적인 존재들이 있습니다. 이들은 네트워크가 서로 다른 유형의 관계를 병렬로 학습할 수 있게 해줍니다. 데이터의 다양한 부분을 동시에 조명하는 여러 스포트라이트를 배치하는 것으로 생각해보세요. 하나의 어텐션 헤드는 장거리 의존성(대명사-명사 참조 같은)을 추적할 수 있고, 다른 하나는 로컬 컨텍스트("cat" 주변의 "on the mat" 같은 구문)에 집중할 수 있습니다. 이러한 특화된 서브 어텐션들을 결합하여, Transformer는 미묘한 의미를 더 잘 인코딩할 수 있습니다.
[caption id="" align="alignnone" width="1220"]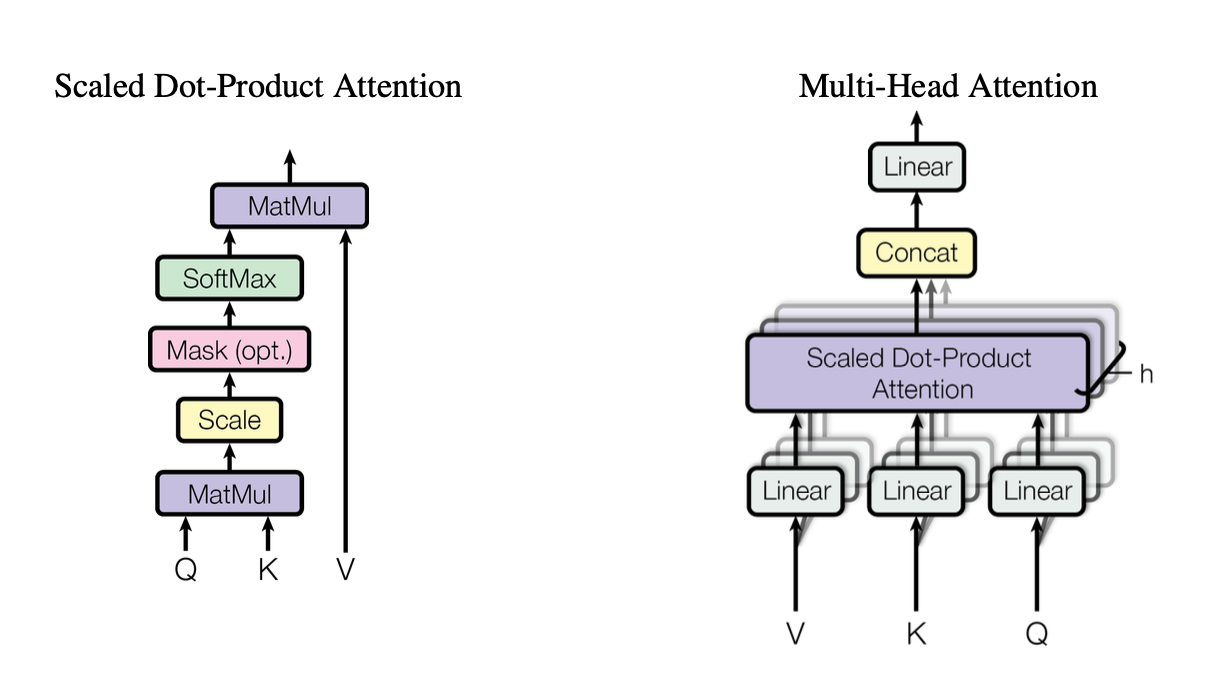 Figure 2: Query (Q), Key (K), Value (V) 벡터들이 상호작용하는 방식을 보여주는 스케일된 내적 어텐션 메커니즘의 그림. 출처: Vaswani et al., "Attention Is All You Need" (2017). 교육 목적으로 공정 사용에 따라 복제된 이미지. [/caption]
Figure 2: Query (Q), Key (K), Value (V) 벡터들이 상호작용하는 방식을 보여주는 스케일된 내적 어텐션 메커니즘의 그림. 출처: Vaswani et al., "Attention Is All You Need" (2017). 교육 목적으로 공정 사용에 따라 복제된 이미지. [/caption]
이러한 헤드들은 스케일된 내적 어텐션을 표준 빌딩 블록으로 사용하며, 이를 코드로 요약하면 다음과 같습니다:
import torch import math
def scaled_dot_product_attention(Q, K, V): # Q, K, V는 [batch_size, heads, seq_len, d_k] d_k = Q.size(-1) scores = torch.matmul(Q, K.transpose(-2, -1)) / math.sqrt(d_k) weights = torch.softmax(scores, dim=-1) return torch.matmul(weights, V)
각 헤드는 쿼리(Q), 키(K), 값(V)의 다르게 투영된 버전들을 처리한 다음 결과를 병합합니다. 이 병렬화 가능한 설계가 Transformer 효율성의 핵심입니다.
위치 인코딩
순환이 없다면 모델은 어떻게 단어 순서를 추적할까요? 여기서 위치 인코딩이 등장합니다—각 토큰의 임베딩에 추가되는 사인파 또는 학습된 패턴으로, Transformer가 시퀀스 감각을 유지하도록 도와줍니다. 각 단어에 고유한 타임스탬프를 주는 것과 같습니다.
3. 간단한 성능 대결
-
RNN/LSTM: 시퀀스 작업에는 훌륭하지만 단계별 처리로 인해 긴 시퀀스에서는 느림.
-
CNN (예: ConvS2S): RNN보다는 빠르지만 장거리 의존성에 대해서는 완전히 병렬이 아님.
-
Transformer:
높은 처리량: 전체 시퀀스를 병렬로 처리할 수 있어 훈련을 상당히 빠르게 만듦.
-
더 나은 결과: Transformer는 기계 번역 같은 작업에서 더 적은 훈련 시간으로 최첨단 점수(WMT14 EN-DE에서 28.4 BLEU)를 달성.
-
확장 가능: 데이터에 더 많은 GPU를 투입하면 거의 선형적으로 확장됨(하드웨어 및 메모리 한계 내에서).
4. 복잡성 고려사항: O(n²)과 그것이 중요한 이유
Transformer가 병렬화를 통해 훈련을 가속화하지만, 셀프 어텐션은 시퀀스 길이 n에 대해 O(n²) 복잡성을 가집니다. 즉, 모든 토큰이 다른 모든 토큰에 어텐션하므로 매우 긴 시퀀스에서는 비용이 클 수 있습니다. 연구자들은 이러한 비용을 완화하기 위해 더 효율적인 어텐션 메커니즘(스파스 또는 블록별 어텐션 같은)을 적극적으로 탐구하고 있습니다.
그럼에도 불구하고, 토큰 수가 수백만이 아닌 수천 단위인 일반적인 NLP 작업의 경우, 이 O(n²) 오버헤드는 종종 병렬 계산의 이점으로 상쇄됩니다—특히 적절한 하드웨어가 있다면 말입니다.
5. 대규모 언어 모델(LLM)에 대한 중요성
GPT, BERT, T5 같은 현대 LLM들은 그들의 계보를 Transformer로 직접 추적할 수 있습니다. 이는 원본 논문의 병렬성, 셀프 어텐션, 유연한 컨텍스트 윈도우에 대한 초점이 번역을 넘어선 작업들에 이상적으로 적합했기 때문입니다:
-
텍스트 생성 및 요약
-
질의응답
-
코드 완성
-
다국어 챗봇
-
그리고 네, 항상 소매에 언어유희를 숨겨둔 것 같은 새로운 AI 작성 어시스턴트.
간단히 말해, "Attention Is All You Need"는 수십억 개의 토큰을 섭취하고 당신이 던지는 거의 모든 NLP 작업을 처리할 수 있는 이러한 대규모 모델들의 길을 닦았습니다.
6. 더 많은 연산이 필요할 것입니다: Introl의 배포가 필요한 곳
여기에 함정이 있습니다: Transformer는 굶주려 있습니다—매우 굶주려 있습니다. 대규모 언어 모델을 훈련한다는 것은 지게차 단위로 컴퓨팅 리소스를 흡입한다는 의미일 수 있습니다. 그 모든 병렬성을 활용하려면 강력한 GPU 배포가 필요합니다—때로는 수천(또는 수만) 개 단위로. 여기서 고성능 컴퓨팅(HPC) 인프라가 개입합니다.
Introl에서는 이러한 시스템이 얼마나 거대해질 수 있는지 직접 경험했습니다. 우리는 빠듯한 일정에 100,000개 이상의 GPU를 포함하는 구축 작업을 해왔습니다—물류적 역량에 대해 말하자면 말이죠. 우리의 주력 사업은 모든 것이 효율적으로 윙윙거리도록 GPU 서버, 랙, 고급 전력/냉각 설정을 배포하는 것입니다. 수천 개의 노드에서 동시에 Transformer 기반 모델을 훈련할 때, 어떤 하드웨어 병목도 시간과 돈 모두에 대한 에너지 소용돌이가 됩니다.
-
대규모 GPU 클러스터: 우리는 100K GPU를 넘어선 배포를 실행했으며, 이는 모든 것을 안정적으로 유지하기 위한 랙 앤 스택 구성, 케이블링, 전력/냉각 전략의 복잡함을 이해한다는 의미입니다.
-
신속한 동원: 며칠 내에 2,000개의 GPU 노드를 추가해야 하나요? 우리의 전문 팀은 72시간 내에 현장에서 운영 가능합니다.
-
엔드투엔드 지원: 펌웨어 업데이트와 iDRAC 구성부터 지속적인 유지보수와 성능 점검까지, 우리는 데이터 과학자들이 혁신에 집중할 수 있도록 물류를 관리합니다.
7. 미래 전망: 더 큰 모델, 더 큰 꿈
"Attention Is All You Need"는 단순한 이정표가 아닙니다—그것은 미래 확장을 위한 청사진입니다. 연구자들은 이미 더 긴 컨텍스트 Transformer, 효율적인 어텐션 메커니즘, 그리고 거대한 코퍼스(생각해보세요: 지역 서점이 아닌 전체 도서관들)를 처리하기 위한 고급 희소성을 탐구하고 있습니다. GPU 가속 컴퓨팅에 대한 욕구는 계속 증가할 것임을 확신합니다.
그것이 Transformer 시대의 아름다움입니다. 적절한 하드웨어 전략과 매칭된다면 우아하게 확장할 수 있는 모델을 가지고 있습니다. 따라서 다음 생성형 AI 현상을 구축하든 범용 번역의 경계를 밀어내든, 거대한 GPU 배포에 능숙한 인프라 파트너를 두는 것은 단순히 있으면 좋은 것 이상입니다; 그것은 실질적으로 당신의 경쟁 우위입니다.
마지막 생각: AI 게임을 Transform하세요
Attention Is All You Need 논문은 영리한 제목 이상이었습니다—그것은 지각변동이었습니다. Transformer는 기계 번역부터 코드 생성과 그 너머까지 모든 것을 변화시켰습니다. 그 힘을 대규모로 활용하고 싶다면, 핵심은 뛰어난 아키텍처를 똑같이 뛰어난 인프라와 매칭시키는 것입니다.
규모를 확장할 준비가 되셨나요? Introl의 전문적인 GPU 인프라 배포가 어떻게 당신의 다음 대규모 Transformer 프로젝트를 가속화할 수 있는지 알아보세요—적절한 하드웨어는 AI에서 모든 차이를 만들 수 있기 때문입니다.
이 글의 시각화는 원본 "Attention Is All You Need" 논문(Vaswani et al., 2017)에서 가져온 것이며 교육 목적으로 공정 사용에 따라 출처 표시와 함께 포함되었습니다. 완전한 연구에 관심 있는 독자들은 https://arxiv.org/abs/1706.03762에서 논문을 이용할 수 있습니다.


