

誰かが「大規模言語モデル」について言及するたびに、GPUのハムノイズが実際に聞こえてくるような感覚を覚えませんか?その宇宙レベルの騒音には理由があります:Transformerアーキテクチャです。そして、この現象をビッグバン的な瞬間まで遡ると、Google BrainとGoogle Researchのエンジニアグループによる2017年の現在は伝説的な論文に行き着きます:Attention Is All You Need。
一見すると、このフレーズはマインドフルネスへの優しい誘いのように聞こえるかもしれませんが、これは自然言語処理(NLP)とその先の革命の前触れでした。Transformerモデルは一撃でAIの現状を覆しました:RNN、LSTM、畳み込みベースのシーケンスモデルの段階的な進歩はもう必要ありません。代わりに、並列化可能で注意機構駆動のシステムを手に入れました。これはより高速に訓練され、より大規模にスケールし、そして—ここが決め手ですが—より良い結果を達成します。
1. 大きなアイデア:セルフアテンションを讃えよ
Transformerが登場する前、シーケンス変換(言語翻訳、要約など)のゴールドスタンダードは、慎重に設計されたゲート機構を持つリカレントニューラルネットワークか、長距離依存性を処理するための複雑なスタッキングを持つ畳み込みニューラルネットワークでした。効果的?はい。遅い?これも、はい—特に本当に巨大なデータセットを分析する必要がある場合は。
最も簡単に言うと、セルフアテンションは、シーケンス内のすべてのトークン(例:単語やサブワード)が同時に他のすべてのトークンを「見る」ことができ、データを段階的に這って進むことを強制されることなく文脈的関係性を発見するメカニズムです。このアプローチは、シーケンスを主に順次処理する必要があったRNNやLSTMなどの古いモデルとは対照的です。
Transformerは再帰(とそれに付随するオーバーヘッド)を捨てることで、はるかに多くの並列化を可能にします。問題に大量のGPUを投入し、大規模なデータセットで訓練し、週ではなく日で結果を見ることができます。
[caption id="" align="alignnone" width="847"]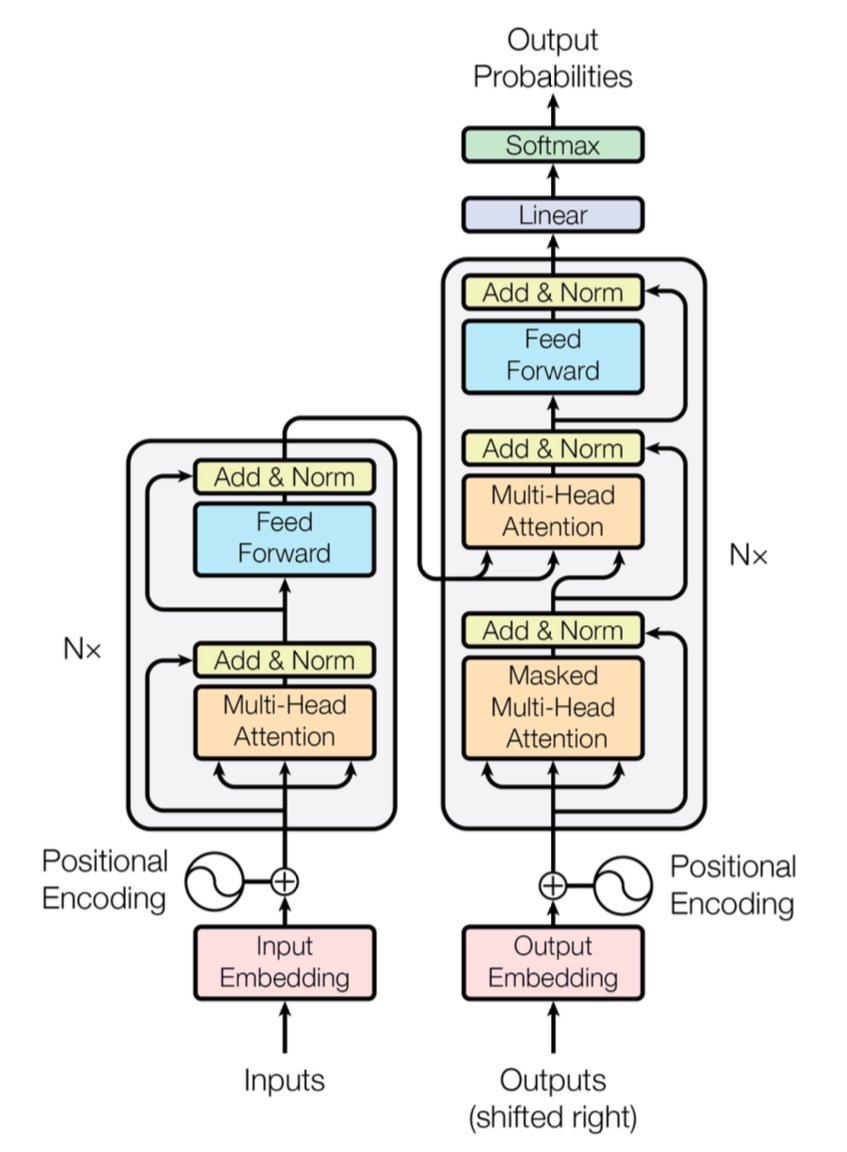 図1:マルチヘッドアテンション層を持つエンコーダー(左)とデコーダー(右)を示す完全なTransformerアーキテクチャ。出典:Vaswani et al., "Attention Is All You Need" (2017)。教育目的でのフェアユースの下で複製された画像。 [/caption]
図1:マルチヘッドアテンション層を持つエンコーダー(左)とデコーダー(右)を示す完全なTransformerアーキテクチャ。出典:Vaswani et al., "Attention Is All You Need" (2017)。教育目的でのフェアユースの下で複製された画像。 [/caption]
簡潔なパフォーマンス注記: オリジナルのTransformerは、WMT 2014英独翻訳タスクで28.4のBLEUスコアを実証しました—これは、せいぜい25-26 BLEU程度で停滞していたCNNベースやRNNベースのモデルなど、従来のニューラル機械翻訳アーキテクチャに対する着実な飛躍でした。現在では、改良されたTransformer(GPT-4とその仲間たちを考えてください)はさらに進歩し、翻訳を超えたタスクを処理しています。
2. 内部構造:マルチヘッドアテンションと位置エンコーディング
マルチヘッドアテンション
Transformerのセルフアテンションの中には、マルチヘッドアテンションモジュールと呼ばれる魔法の獣がいます。これらはネットワークが並列で異なるタイプの関係性を学習することを可能にします。データのさまざまな部分を同時に照らす複数のスポットライトを配備することと考えてください。一つのアテンションヘッドは長距離依存性(代名詞と名詞の参照など)を追跡し、もう一つは局所的文脈(「cat」周辺の「on the mat」のようなフレーズ)に焦点を当てるかもしれません。これらの専門化されたサブアテンションを組み合わせることで、Transformerはより微妙な意味をよりよくエンコードできます。
[caption id="" align="alignnone" width="1220"]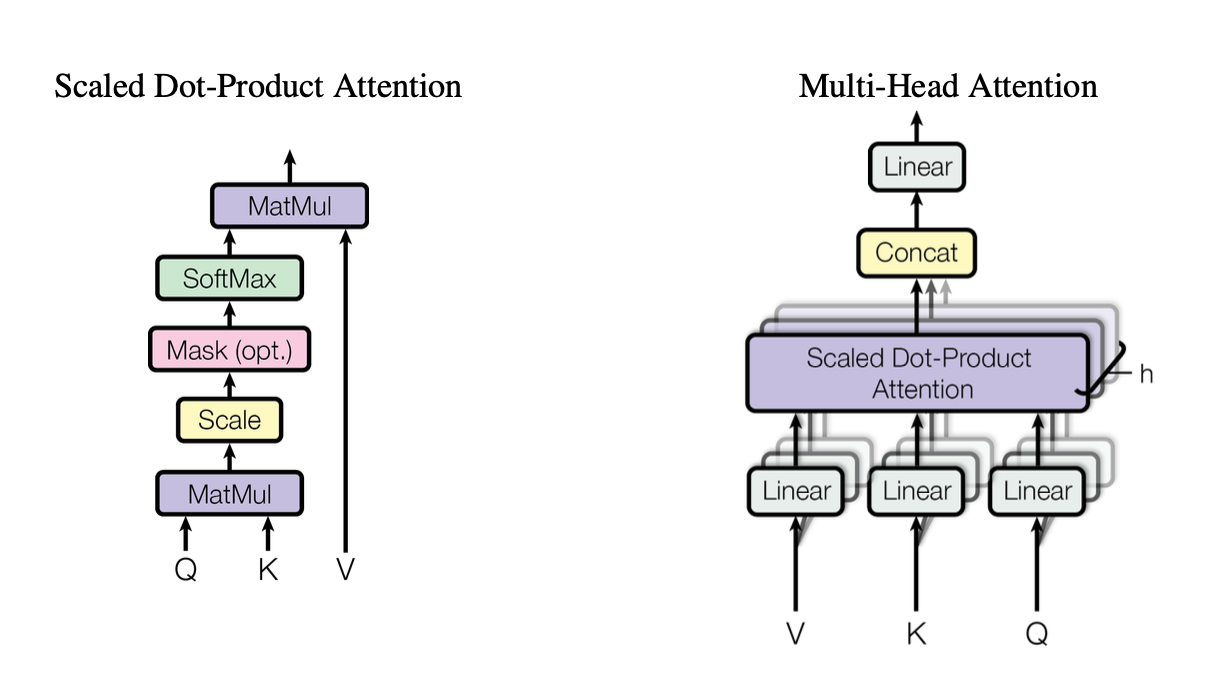 図2:Query(Q)、Key(K)、Value(V)ベクトルがどのように相互作用するかを示すスケール付きドット積アテンション機構の図解。出典:Vaswani et al., "Attention Is All You Need" (2017)。教育目的でのフェアユースの下で複製された画像。 [/caption]
図2:Query(Q)、Key(K)、Value(V)ベクトルがどのように相互作用するかを示すスケール付きドット積アテンション機構の図解。出典:Vaswani et al., "Attention Is All You Need" (2017)。教育目的でのフェアユースの下で複製された画像。 [/caption]
これらのヘッドは標準的な構成要素としてスケール付きドット積アテンションを使用し、これをコードで以下のように要約できます:
import torchimport math def scaled_dot_product_attention(Q, K, V): # Q, K, V are [batch_size, heads, seq_len, d_k] d_k = Q.size(-1) scores = torch.matmul(Q, K.transpose(-2, -1)) / math.sqrt(d_k) weights = torch.softmax(scores, dim=-1) return torch.matmul(weights, V)
各ヘッドはクエリ(Q)、キー(K)、値(V)の異なる投影バージョンで動作し、その後結果をマージします。この並列化可能な設計がTransformerの効率性の鍵です。
位置エンコーディング
再帰なし?それは疑問を呼び起こします:モデルはどうやって単語の順序を把握するのでしょうか?位置エンコーディングの登場です—各トークンの埋め込みに追加される正弦波または学習されたパターンで、Transformerがシーケンスの感覚を維持するのを助けます。これは各単語にユニークなタイムスタンプを与えるようなものです。
3. 簡潔なパフォーマンス対決
-
RNN/LSTM: シーケンスタスクには優れているが、段階的処理のため長いシーケンスでは遅い。
-
CNN(例:ConvS2S): RNNより高速だが、長距離依存性において完全には並列化されていない。
-
Transformer:
より高いスループット: 全体のシーケンスを並列で処理できるため、訓練を大幅に高速化。
-
より良い結果: Transformerは機械翻訳などのタスクでより少ない訓練時間で最先端スコア(WMT14 EN-DEで28.4 BLEU)を達成。
-
スケーラブル: データにより多くのGPUを投入し、(ハードウェアとメモリ制限内で)ほぼ線形にスケールするのを見る。
4. 複雑性の考慮:O(n²)とそれが重要な理由
Transformerは並列化により訓練を加速する一方で、セルフアテンションはシーケンス長nに関してO(n²)の複雑性を持ちます。言い換えると、すべてのトークンが他のすべてのトークンに注意を向けるため、極端に長いシーケンスでは高コストになる可能性があります。研究者たちは、このコストを軽減するためにより効率的なアテンション機構(スパースやブロック単位のアテンションなど)を積極的に探求しています。
それでも、トークン数が数百万ではなく数千の典型的なNLPタスクでは、このO(n²)のオーバーヘッドは並列計算の利益によってしばしば上回られます—特に適切なハードウェアがある場合は。
5. 大規模言語モデル(LLM)にとって重要な理由
現代のLLM—GPT、BERT、T5など—は直接Transformerにその系譜を遡ります。それは、オリジナル論文の並列性、セルフアテンション、柔軟な文脈ウィンドウへの焦点が、翻訳を超えたタスクに理想的に適合したためです:
-
テキスト生成と要約
-
質問応答
-
コード補完
-
多言語チャットボット
-
そして、はい、あなたの新しいAI執筆アシスタントは常に袖に駄洒落を隠し持っているようです。
簡単に言うと、「Attention Is All You Need」は、数十億のトークンを取り込み、あなたが投げかけるほぼすべてのNLPタスクを処理するこれらの大規模モデルの道を開いたのです。
6. より多くの計算が必要:IntrolのDeploymentの出番
ここに落とし穴があります: Transformerは貪欲—非常に貪欲です。大規模言語モデルを訓練することは、フォークリフト単位で計算資源を吸い上げることを意味する場合があります。すべての並列性を活用するには、堅牢なGPUデプロイメント—時には数千(または数万)の単位が必要です。そこで高性能コンピューティング(HPC)インフラが登場します。
Introlでは、これらのシステムがどれほど巨大になり得るかを直接見てきました。私たちは100,000台以上のGPUを含む構築に短期間で取り組んできました—物流の技量について話しましょう。私たちの専門は、すべてが効率的に動作するようにGPUサーバー、ラック、高度な電源/冷却セットアップをデプロイすることです。数千のノードでTransformerベースのモデルを同時に訓練している時、ハードウェアのボトルネックは時間とお金の両方にとってエネルギーの渦です。
-
大規模GPUクラスター: 私たちは100KGPUを超えるデプロイメントを実行してきたため、ラック・アンド・スタック構成、配線、すべてを安定させるための電源/冷却戦略の複雑さを理解しています。
-
迅速な動員: 数日で追加の2,000 GPUノードが必要?私たちの専門チームは72時間以内に現場で運用可能です。
-
エンドツーエンドサポート: ファームウェアアップデートとiDRAC構成から継続的なメンテナンスとパフォーマンスチェックまで、私たちはロジスティクスを管理し、データサイエンティストがイノベーションに集中できるようにします。
7. 先を見据えて:より大きなモデル、より大きな夢
「Attention Is All You Need」は単なるマイルストーンではありません—それは将来の拡張の青写真です。研究者たちはすでに、より長い文脈のTransformer、効率的なアテンション機構、巨大なコーパス(考えてみてください:地元の書店ではなく、図書館全体)を処理するための高度なスパース性を探求しています。GPU加速コンピューティングへの欲求は増大するばかりであることは確実です。
そして、それがTransformer時代の美しさです。適切なハードウェア戦略と組み合わせれば、エレガントにスケールできるモデルがあります。次の生成AI現象を構築している場合でも、普遍的翻訳の境界を押し広げている場合でも、大規模GPUデプロイメントに熟練したインフラパートナーを持つことは、単なる「あると良い」ものではありません;それは実質的にあなたの競争優位です。
最終的な考え:あなたのAIゲームを変革する
論文Attention Is All You Needは巧妙なタイトル以上のものでした—それは地殻変動的なシフトでした。Transformerは機械翻訳からコード生成まで、そしてその先のすべてを変革しました。その力を規模で活用したいなら、鍵は優れたアーキテクチャを同様に優れたインフラと組み合わせることです。
スケールアップの準備はできていますか? Introlの専門的なGPU Infrastructure Deploymentsが、あなたの次の大きなTransformerプロジェクトをどのように加速できるかをご覧ください—適切なハードウェアがAIにおいてすべての違いを生むからです。
この記事の視覚化は、オリジナルの「Attention Is All You Need」論文(Vaswani et al., 2017)からのもので、教育目的でのフェアユースの下で帰属とともに含まれています。完全な研究に興味のある読者のために、論文は https://arxiv.org/abs/1706.03762 で入手可能です。


