

¿Sientes que prácticamente puedes escuchar el zumbido de las GPUs cada vez que alguien menciona "modelos de lenguaje grande"? Hay una razón para ese revuelo a nivel cósmico: las arquitecturas Transformer. Y si rastreamos ese fenómeno hasta su momento del Big Bang, aterrizamos directamente en un artículo ahora legendario de 2017 de un grupo de ingenieros de Google Brain y Google Research: Attention Is All You Need.
A primera vista, la frase podría sonar como un suave empujón hacia la atención plena, pero anunció una revolución en el procesamiento del lenguaje natural (NLP) y más allá. El modelo Transformer derribó el statu quo de la IA de un solo golpe: no más progresión centímetro a centímetro de RNNs, LSTMs y modelos de secuencia basados en convolución. En su lugar, obtuvimos un sistema paralelizable, impulsado por atención, que entrena más rápido, escala más grande y —aquí está lo importante— logra mejores resultados.
1. La Gran Idea: Alabada Sea la Auto-Atención
Antes de que los Transformers irrumpieran en escena, el estándar de oro para la transducción de secuencias (piensa en traducción de idiomas, resumen, etc.) involucraba redes neuronales recurrentes con mecanismos de compuertas cuidadosamente diseñados o redes neuronales convolucionales con apilamiento complicado para manejar dependencias de largo alcance. ¿Efectivo? Sí. ¿Lento? También, sí—especialmente cuando necesitas analizar conjuntos de datos verdaderamente masivos.
En términos más simples, la auto-atención es un mecanismo mediante el cual cada token en una secuencia (por ejemplo, una palabra o subpalabra) puede "mirar" a todos los demás tokens simultáneamente, descubriendo relaciones contextuales sin verse obligado a rastrear paso a paso a través de los datos. Este enfoque contrasta con modelos más antiguos, como RNNs y LSTMs, que tenían que procesar la secuencia en gran parte secuencialmente.
Los Transformers permiten mucha más paralelización al descartar la recurrencia (y la sobrecarga que viene con ella). Puedes lanzar una multitud de GPUs al problema, entrenar con conjuntos de datos masivos y ver resultados en días en lugar de semanas.
[caption id="" align="alignnone" width="847"]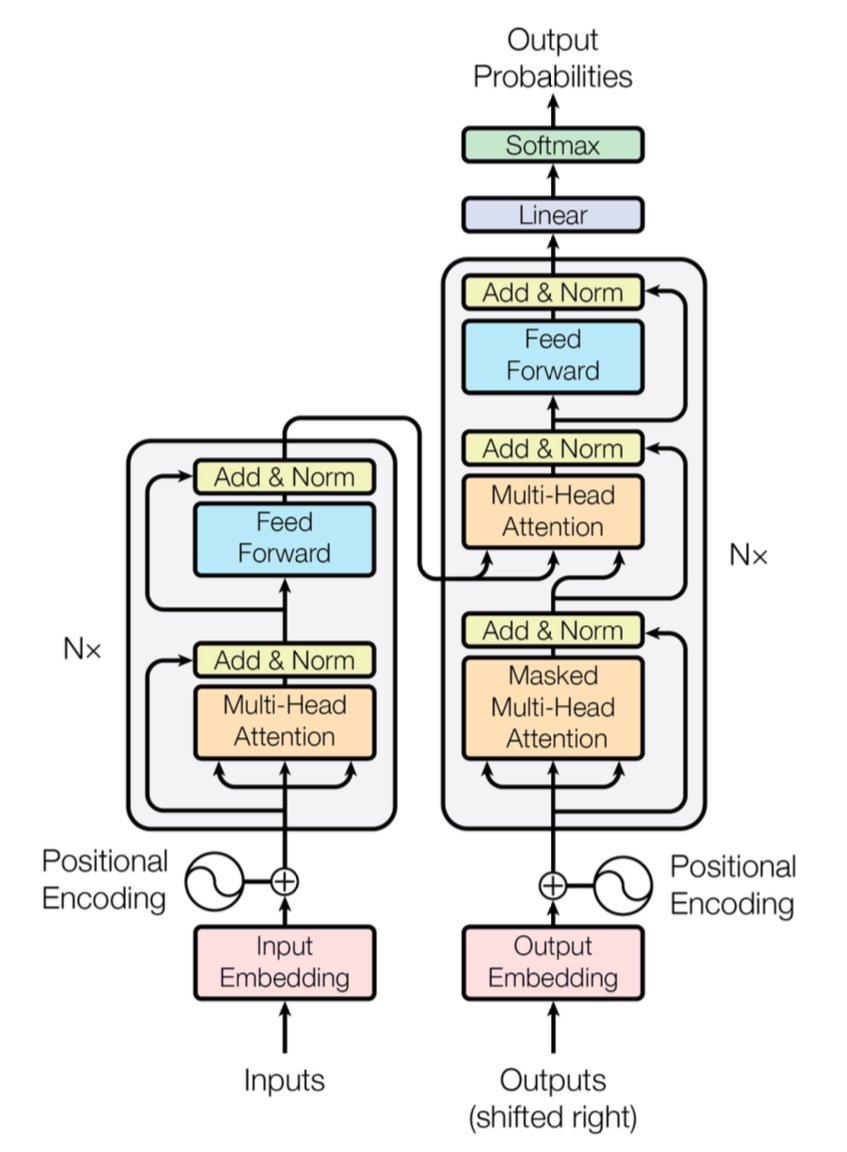 Figura 1: La arquitectura Transformer completa mostrando el codificador (izquierda) y el decodificador (derecha) con capas de atención multi-cabeza. Fuente: Vaswani et al., "Attention Is All You Need" (2017). Imagen reproducida con fines educativos bajo uso justo. [/caption]
Figura 1: La arquitectura Transformer completa mostrando el codificador (izquierda) y el decodificador (derecha) con capas de atención multi-cabeza. Fuente: Vaswani et al., "Attention Is All You Need" (2017). Imagen reproducida con fines educativos bajo uso justo. [/caption]
Nota Rápida de Rendimiento: El Transformer original demostró una puntuación BLEU de 28.4 en la tarea de inglés a alemán de WMT 2014—un salto sólido sobre arquitecturas previas de traducción automática neuronal como modelos basados en CNN y RNN, que rondaban alrededor de 25-26 BLEU en el mejor de los casos. Hoy en día, Transformers mejorados (piensa en GPT-4 y sus primos) van aún más allá, manejando tareas más allá de la traducción.
2. Bajo el Capó: Atención Multi-Cabeza y Codificaciones Posicionales
Atención Multi-Cabeza
Dentro de la auto-atención del Transformer están estas bestias mágicas llamadas módulos de atención multi-cabeza. Permiten que la red aprenda diferentes tipos de relaciones en paralelo. Piensa en ello como desplegar múltiples focos para iluminar varias partes de tus datos simultáneamente. Una cabeza de atención podría rastrear dependencias de larga distancia (como referencias pronombre-sustantivo), mientras otra se enfoca en el contexto local (como la frase "sobre la alfombra" alrededor de "gato"). Combinando estas sub-atenciones especializadas, el Transformer puede codificar mejor el significado matizado.
[caption id="" align="alignnone" width="1220"]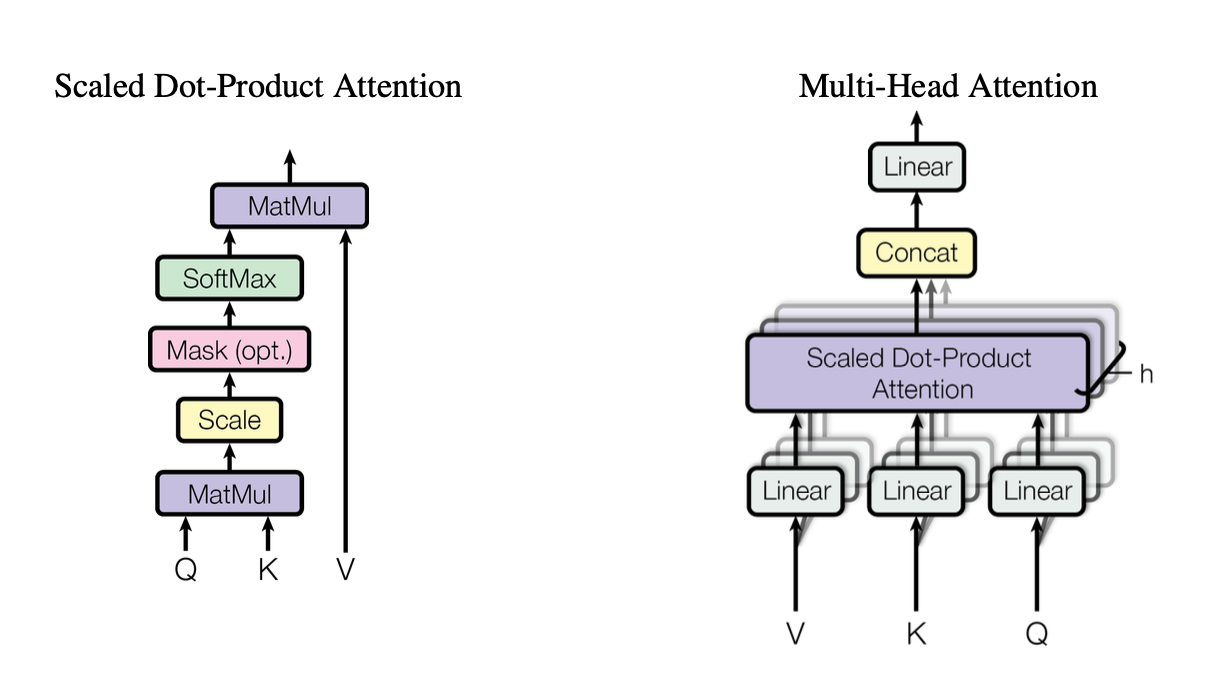 Figura 2: Ilustración del mecanismo de atención de producto punto escalado mostrando cómo interactúan los vectores Query (Q), Key (K) y Value (V). Fuente: Vaswani et al., "Attention Is All You Need" (2017). Imagen reproducida con fines educativos bajo uso justo. [/caption]
Figura 2: Ilustración del mecanismo de atención de producto punto escalado mostrando cómo interactúan los vectores Query (Q), Key (K) y Value (V). Fuente: Vaswani et al., "Attention Is All You Need" (2017). Imagen reproducida con fines educativos bajo uso justo. [/caption]
Estas cabezas usan atención de producto punto escalado como bloque de construcción estándar, que podemos resumir en código como:
import torchimport math def scaled_dot_product_attention(Q, K, V): # Q, K, V son [batch_size, heads, seq_len, d_k] d_k = Q.size(-1) scores = torch.matmul(Q, K.transpose(-2, -1)) / math.sqrt(d_k) weights = torch.softmax(scores, dim=-1) return torch.matmul(weights, V)
Cada cabeza opera en versiones proyectadas de forma diferente de queries (Q), keys (K) y values (V), luego fusiona los resultados. Este diseño paralelizable es clave para la eficiencia del Transformer.
Codificaciones Posicionales
¿Sin recurrencias? Eso plantea la pregunta: ¿Cómo hace el modelo para llevar un registro del orden de las palabras? Entran las codificaciones posicionales—un patrón sinusoidal o aprendido añadido a la incrustación de cada token, ayudando al Transformer a mantener un sentido de secuencia. Es como darle a cada palabra una marca de tiempo única.
3. Comparación Rápida de Rendimiento
-
RNNs/LSTMs: Excelentes para tareas de secuencia pero lentas para secuencias largas debido al procesamiento paso a paso.
-
CNNs (por ejemplo, ConvS2S): Más rápidas que las RNNs pero aún no completamente paralelas para dependencias de largo alcance.
-
Transformers:
Mayor Rendimiento: Pueden procesar secuencias enteras en paralelo, haciendo el entrenamiento significativamente más rápido.
-
Mejores Resultados: Los Transformers lograron puntuaciones de vanguardia en tareas como traducción automática (28.4 BLEU en WMT14 EN-DE) con menos tiempo de entrenamiento.
-
Escalables: Lanza más GPUs a los datos y míralo escalar casi linealmente (dentro de los límites de hardware y memoria).
4. La Consideración de Complejidad: O(n²) y Por Qué Importa
Mientras los Transformers aceleran el entrenamiento a través de la paralelización, la auto-atención conlleva una complejidad O(n²) con respecto a la longitud de secuencia n. En otras palabras, cada token atiende a todos los demás tokens, lo cual puede ser costoso para secuencias extremadamente largas. Los investigadores están explorando activamente mecanismos de atención más eficientes (como atención dispersa o por bloques) para mitigar este costo.
Aun así, para tareas típicas de NLP donde los conteos de tokens están en miles en lugar de millones, esta sobrecarga O(n²) a menudo se ve compensada por los beneficios del cálculo paralelo—especialmente si tienes el hardware adecuado.
5. Por Qué Importa para los Modelos de Lenguaje Grande (LLMs)
Los LLMs modernos—como GPT, BERT y T5—trazan su linaje directamente al Transformer. Eso es porque el enfoque del artículo original en paralelismo, auto-atención y ventanas de contexto flexibles lo hizo idealmente adecuado para tareas más allá de la traducción, incluyendo:
-
Generación de Texto y Resumen
-
Respuesta a Preguntas
-
Completado de Código
-
Chatbots Multilingües
-
Y sí, tu nuevo asistente de escritura de IA que siempre parece tener un juego de palabras bajo la manga.
En resumen, "Attention Is All You Need" allanó el camino para estos grandes modelos que ingieren miles de millones de tokens y manejan casi cualquier tarea de NLP que les lances.
6. Vamos a necesitar más cómputo: Donde Entran los Despliegues de Introl
Aquí está el detalle: Los Transformers son hambrientos—muy hambrientos. Entrenar un modelo de lenguaje grande puede significar devorar recursos de cómputo a montón. Para aprovechar todo ese paralelismo, necesitas despliegues robustos de GPU—a veces numerando en miles (o decenas de miles). Ahí es donde entra la infraestructura de computación de alto rendimiento (HPC).
En Introl, hemos visto de primera mano cuán masivos pueden llegar a ser estos sistemas. Hemos trabajado en construcciones que involucran más de 100,000 GPUs en plazos ajustados—hablamos de destreza logística. Nuestro pan de cada día es desplegar servidores GPU, racks y configuraciones avanzadas de energía/refrigeración para que todo funcione eficientemente. Cuando estás entrenando simultáneamente un modelo basado en Transformer en miles de nodos, cualquier cuello de botella de hardware es un vórtice de energía tanto para tiempo como para dinero.
-
Clústeres GPU a Gran Escala: Hemos ejecutado despliegues que superaron las 100K GPUs, lo que significa que entendemos las complejidades de las configuraciones de rack-and-stack, cableado y estrategias de energía/refrigeración para mantener todo estable.
-
Movilización Rápida: ¿Necesitas añadir otros 2,000 nodos GPU en unos días? Nuestros equipos especializados pueden estar en sitio y operativos en 72 horas.
-
Soporte de Extremo a Extremo: Desde actualizaciones de firmware y configuraciones de iDRAC hasta mantenimiento continuo y verificaciones de rendimiento, gestionamos la logística para que tus científicos de datos puedan mantenerse enfocados en la innovación.
7. Mirando Hacia Adelante: Modelos Más Grandes, Sueños Más Grandes
"Attention Is All You Need" no es solo un hito—es el plano para futuras expansiones. Los investigadores ya están explorando Transformers de contexto más largo, mecanismos de atención eficientes y dispersión avanzada para manejar corpus enormes (piensa: bibliotecas enteras, no solo tu librería local). Ten por seguro que el apetito por computación acelerada por GPU solo aumentará.
Y esa es la belleza de la era Transformer. Tenemos un modelo que puede escalar elegantemente, siempre que lo emparejemos con la estrategia de hardware adecuada. Así que ya sea que estés construyendo el próximo fenómeno de IA generativa o empujando los límites de la traducción universal, tener un socio de infraestructura experto en despliegues masivos de GPU es más que algo agradable de tener; es prácticamente tu ventaja competitiva.
Pensamiento Final: Transforma Tu Juego de IA
El artículo Attention Is All You Need fue más que un título ingenioso—fue un cambio sísmico. Los Transformers han transformado todo, desde la traducción automática hasta la generación de código y más allá. Si quieres aprovechar ese poder a escala, la clave es emparejar una arquitectura brillante con una infraestructura igualmente brillante.
¿Listo para escalar? Descubre cómo los Despliegues de Infraestructura GPU especializados de Introl pueden acelerar tu próximo gran proyecto Transformer—porque el hardware adecuado puede hacer toda la diferencia en IA.
Las visualizaciones en este artículo son del artículo original "Attention Is All You Need" (Vaswani et al., 2017) y se incluyen con atribución bajo uso justo con fines educativos. El artículo está disponible en https://arxiv.org/abs/1706.03762 para lectores interesados en la investigación completa.


