

每当有人提到"大语言模型"时,你是否感觉能够实实在在地听到GPU的嗡嗡声?这种宇宙级的嗡鸣声是有原因的:Transformer架构。如果我们追溯这一现象到其大爆炸时刻,我们会准确地定位到Google Brain和Google Research工程师团队在2017年发表的一篇如今已成为传奇的论文:Attention Is All You Need。
乍一看,这个短语可能听起来像是对正念的温和提示,但它预示着自然语言处理(NLP)及其他领域的一场革命。Transformer模型一举颠覆了AI现状:不再需要RNN、LSTM和基于卷积的序列模型的逐步推进。取而代之的是一个可并行化、注意力驱动的系统,训练更快、扩展性更强,而且——这是关键所在——取得更好的结果。
1. 核心理念:全能自注意力机制
在Transformer问世之前,序列转换任务(如语言翻译、摘要等)的黄金标准涉及具有精心设计门控机制的循环神经网络,或者具有复杂堆叠来处理长程依赖的卷积神经网络。有效吗?是的。慢吗?也是的——特别是当你需要分析真正海量的数据集时。
简单来说,自注意力机制是序列中每个token(如词或子词)可以同时"查看"每个其他token,发现上下文关系,而无需被迫逐步遍历数据。这种方法与旧模型(如RNN和LSTM)形成对比,后者必须主要按顺序处理序列。
Transformer通过摒弃循环(以及随之而来的开销)实现了更多的并行化。你可以投入大量GPU来解决问题,在海量数据集上训练,并在几天而非几周内看到结果。
[caption id="" align="alignnone" width="847"]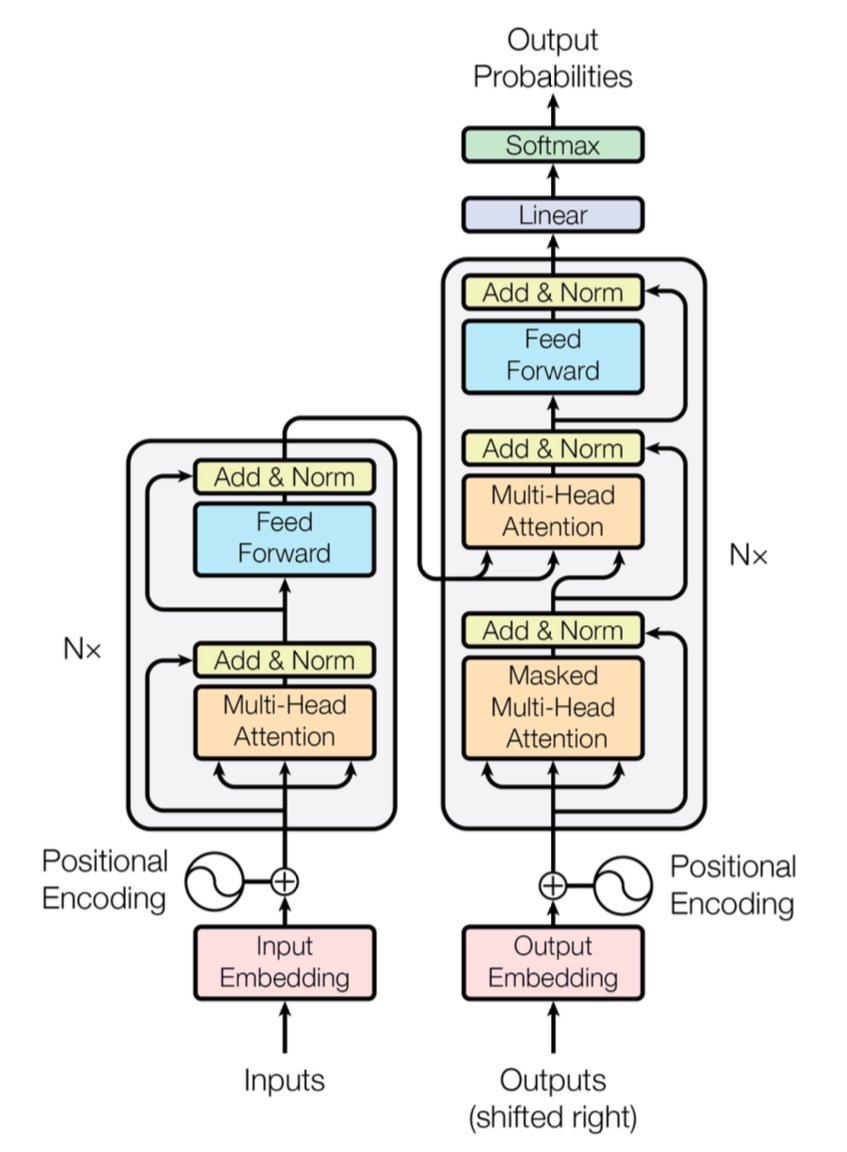 图1:完整的Transformer架构,显示编码器(左)和解码器(右)以及多头注意力层。来源:Vaswani等人,"Attention Is All You Need"(2017)。图像基于公平使用原则用于教育目的。[/caption]
图1:完整的Transformer架构,显示编码器(左)和解码器(右)以及多头注意力层。来源:Vaswani等人,"Attention Is All You Need"(2017)。图像基于公平使用原则用于教育目的。[/caption]
性能快速说明: 原始Transformer在WMT 2014英德翻译任务上实现了28.4 BLEU分数——相比之前的神经机器翻译架构(如基于CNN和RNN的模型,最好只能达到25-26 BLEU左右)有了显著飞跃。如今,改进的Transformer(如GPT-4及其同类)更进一步,处理超越翻译的任务。
2. 深入原理:多头注意力与位置编码
多头注意力
在Transformer的自注意力机制中,有这些被称为多头注意力模块的神奇组件。它们让网络能够并行学习不同类型的关系。可以把它想象成部署多个聚光灯同时照亮数据的各个部分。一个注意力头可能跟踪长距离依赖(如代词-名词引用),而另一个则专注于局部上下文(如围绕"cat"的短语"on the mat")。通过结合这些专门的子注意力,Transformer能够更好地编码细致的含义。
[caption id="" align="alignnone" width="1220"]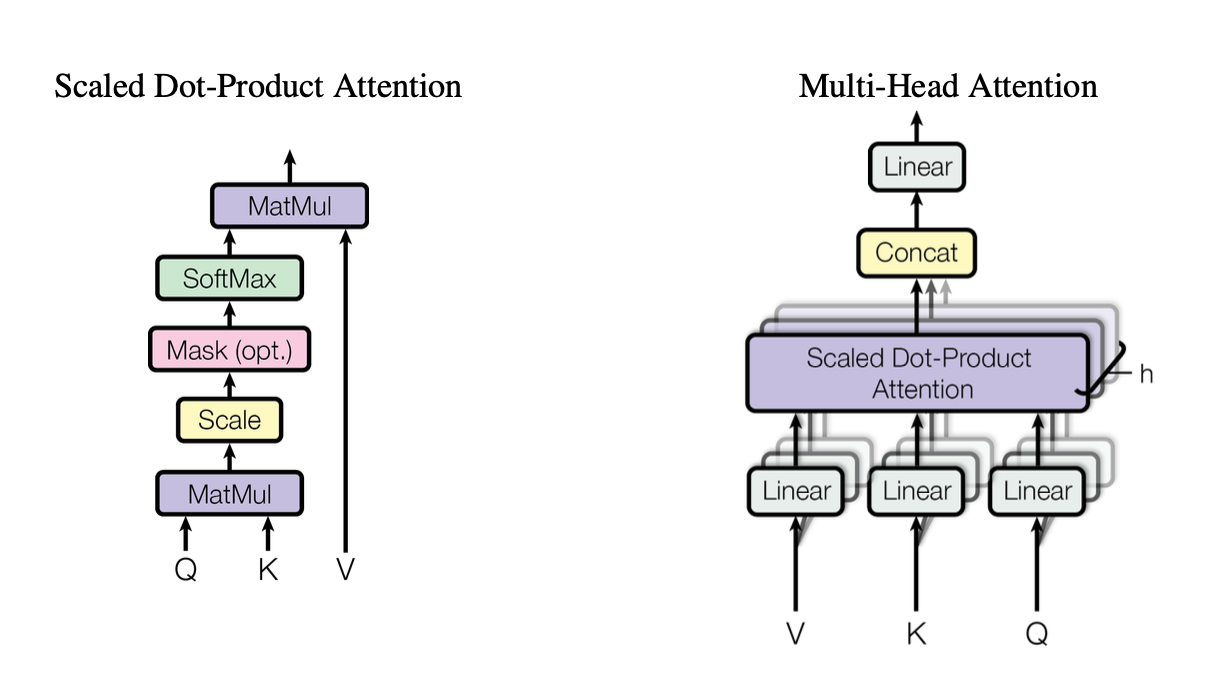 图2:缩放点积注意力机制的说明,显示查询(Q)、键(K)和值(V)向量如何交互。来源:Vaswani等人,"Attention Is All You Need"(2017)。图像基于公平使用原则用于教育目的。[/caption]
图2:缩放点积注意力机制的说明,显示查询(Q)、键(K)和值(V)向量如何交互。来源:Vaswani等人,"Attention Is All You Need"(2017)。图像基于公平使用原则用于教育目的。[/caption]
这些头使用缩放点积注意力作为标准构建块,我们可以用代码总结如下:
import torch import math
def scaled_dot_product_attention(Q, K, V): # Q, K, V are [batch_size, heads, seq_len, d_k] d_k = Q.size(-1) scores = torch.matmul(Q, K.transpose(-2, -1)) / math.sqrt(d_k) weights = torch.softmax(scores, dim=-1) return torch.matmul(weights, V)
每个头在查询(Q)、键(K)和值(V)的不同投影版本上操作,然后合并结果。这种可并行化的设计是Transformer效率的关键。
位置编码
没有循环?这就引出了一个问题:模型如何保持词序跟踪?位置编码登场——一种添加到每个token嵌入的正弦或学习模式,帮助Transformer保持序列感知。这就像给每个词一个唯一的时间戳。
3. 性能对比速览
-
RNN/LSTM: 擅长序列任务,但由于逐步处理,对长序列处理较慢。
-
CNN(如ConvS2S): 比RNN更快,但对长程依赖仍不能完全并行。
-
Transformer:
更高吞吐量: 可以并行处理整个序列,使训练显著加快。
-
更好结果: Transformer在机器翻译等任务中实现了最先进的分数(WMT14 EN-DE上28.4 BLEU),训练时间更短。
-
可扩展: 投入更多GPU处理数据,几乎线性扩展(在硬件和内存限制范围内)。
4. 复杂度考虑:O(n²)及其重要性
虽然Transformer通过并行化加速训练,但自注意力机制相对于序列长度n具有O(n²)复杂度。换句话说,每个token都要关注其他每个token,这对极长序列可能很昂贵。研究人员正在积极探索更高效的注意力机制(如稀疏或分块注意力)来缓解这种成本。
即便如此,对于token数量在数千而非数百万的典型NLP任务,这种O(n²)开销通常被并行计算的优势所抵消——特别是如果你有合适的硬件。
5. 对大语言模型(LLM)的重要意义
现代LLM——如GPT、BERT和T5——直接追溯到Transformer血统。这是因为原始论文对并行性、自注意力和灵活上下文窗口的关注使其非常适合超越翻译的任务,包括:
-
文本生成和摘要
-
问答
-
代码补全
-
多语言聊天机器人
-
是的,你的新AI写作助手似乎总是有妙语连珠。
简而言之,"Attention Is All You Need"为这些摄取数十亿token并处理你抛给它们的几乎任何NLP任务的大模型铺平了道路。
6. 我们需要更多算力:Introl部署的用武之地
问题在于: Transformer非常贪婪——极其贪婪。训练一个大语言模型可能意味着大量消耗计算资源。要利用所有并行性,你需要强大的GPU部署——有时数量达到数千(或数万)。这就是高性能计算(HPC)基础设施发挥作用的地方。
在Introl,我们亲身体验了这些系统能有多庞大。我们曾在紧张的时间表内参与涉及超过100,000个GPU的构建——谈论后勤能力。我们的专长是部署GPU服务器、机架和先进的电力/冷却设置,使一切高效运转。当你同时在数千个节点上训练基于Transformer的模型时,任何硬件瓶颈都是时间和金钱的能量漩涡。
-
大规模GPU集群: 我们执行了超过10万GPU的部署,这意味着我们理解机架堆叠配置、布线和电力/冷却策略的复杂性,以保持一切稳定。
-
快速动员: 需要在几天内增加另外2,000个GPU节点?我们的专业团队可以在72小时内到场并投入运行。
-
端到端支持: 从固件更新和iDRAC配置到持续维护和性能检查,我们管理后勤工作,让你的数据科学家专注于创新。
7. 展望未来:更大模型,更大梦想
"Attention Is All You Need"不仅仅是一个里程碑——它是未来扩展的蓝图。研究人员已在探索更长上下文的Transformer、高效注意力机制和高级稀疏性,以处理庞大语料(想想:整个图书馆,而非当地书店)。可以确定,对GPU加速计算的需求只会增加。
这就是Transformer时代的美妙之处。我们有一个可以优雅扩展的模型,前提是我们用合适的硬件策略来匹配它。因此,无论你是在构建下一个生成式AI现象还是推动通用翻译的边界,拥有一个在大规模GPU部署方面经验丰富的基础设施合作伙伴不仅仅是锦上添花;它实际上就是你的竞争优势。
最后思考:变革你的AI游戏
论文Attention Is All You Need不仅仅是一个巧妙的标题——它是一次地震式转变。Transformer已经变革了从机器翻译到代码生成及其他方面的一切。如果你想大规模利用这种力量,关键是将出色的架构与同样出色的基础设施相匹配。
准备扩展? 了解Introl专业的GPU基础设施部署如何加速你下一个大型Transformer项目——因为合适的硬件能在AI中产生巨大差异。
本文中的可视化图表来自原始论文"Attention Is All You Need"(Vaswani等人,2017),基于公平使用原则用于教育目的并注明出处。有兴趣了解完整研究的读者可在https://arxiv.org/abs/1706.03762查阅该论文。


