

هل تشعر وكأنك تسمع طنين GPU عملياً في أي وقت يذكر أحدهم "نماذج اللغة الكبيرة"؟ هناك سبب لهذا الطنين الكوني: معماريات Transformer. وإذا كنا نتتبع هذه الظاهرة إلى لحظة الانفجار الكبير الخاصة بها، فإننا نصل مباشرة إلى ورقة بحثية أسطورية الآن من عام 2017 من مجموعة مهندسي Google Brain و Google Research: Attention Is All You Need.
من النظرة الأولى، قد تبدو العبارة وكأنها دفعة لطيفة نحو اليقظة الذهنية، لكنها بشّرت بثورة في معالجة اللغات الطبيعية (NLP) وما هو أبعد من ذلك. لقد قلب نموذج Transformer الوضع الراهن في AI في ضربة واحدة سريعة: لا مزيد من التقدم البطيء لـ RNNs وLSTMs ونماذج التسلسل القائمة على الالتفاف. بدلاً من ذلك، حصلنا على نظام قابل للمعالجة المتوازية ومُحرك بالانتباه يتدرب بشكل أسرع، ويتوسع بشكل أكبر، وإليك المفاجأة—يحقق نتائج أفضل.
1. الفكرة الكبيرة: تحية للانتباه الذاتي
قبل أن تنفجر Transformers على المشهد، كان المعيار الذهبي لتحويل التسلسل (فكر في ترجمة اللغة، التلخيص، إلخ) يتضمن الشبكات العصبية المتكررة مع آليات تحكم مُصممة بعناية أو الشبكات العصبية الالتفافية مع تكديس معقد للتعامل مع التبعيات طويلة المدى. فعال؟ نعم. بطيء؟ أيضاً، نعم—خاصة عندما تحتاج إلى تحليل مجموعات بيانات ضخمة حقاً.
بأبسط العبارات، الانتباه الذاتي هو آلية يمكن من خلالها لكل رمز في تسلسل (مثل كلمة أو كلمة فرعية) أن "ينظر" إلى كل رمز آخر في نفس الوقت، مكتشفاً العلاقات السياقية دون أن يُجبر على الزحف خطوة بخطوة عبر البيانات. هذا المنهج يتناقض مع النماذج الأقدم، مثل RNNs وLSTMs، التي كان عليها معالجة التسلسل بشكل متسلسل إلى حد كبير.
تمكّن Transformers من مزيد من المعالجة المتوازية عبر التخلص من التكرار (والعبء الذي يأتي معه). يمكنك إلقاء مجموعة من GPU على المشكلة، والتدرب على مجموعات بيانات ضخمة، ورؤية النتائج في أيام بدلاً من أسابيع.
[caption id="" align="alignnone" width="847"]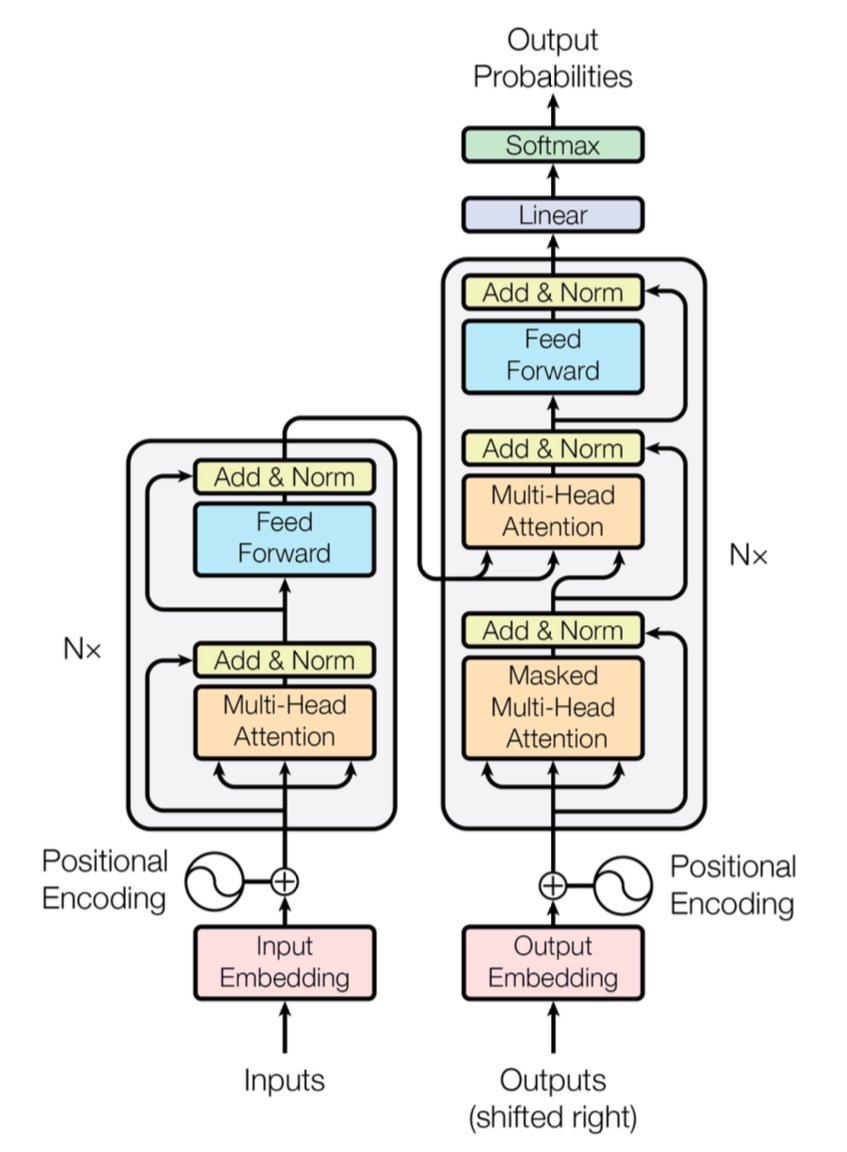 الشكل 1: معمارية Transformer الكاملة تُظهر المُرمز (يسار) وفك التشفير (يمين) مع طبقات الانتباه متعدد الرؤوس. المصدر: Vaswani وآخرون، "Attention Is All You Need" (2017). الصورة مُعاد إنتاجها لأغراض تعليمية تحت الاستخدام العادل. [/caption]
الشكل 1: معمارية Transformer الكاملة تُظهر المُرمز (يسار) وفك التشفير (يمين) مع طبقات الانتباه متعدد الرؤوس. المصدر: Vaswani وآخرون، "Attention Is All You Need" (2017). الصورة مُعاد إنتاجها لأغراض تعليمية تحت الاستخدام العادل. [/caption]
ملاحظة أداء سريعة: أظهر Transformer الأصلي درجة 28.4 BLEU على مهمة WMT 2014 للترجمة من الإنجليزية إلى الألمانية—قفزة صلبة عن معماريات الترجمة الآلية العصبية السابقة مثل النماذج القائمة على CNN وRNN، والتي تراوحت حول 25-26 BLEU في أحسن الأحوال. هذه الأيام، Transformers المحسنة (فكر في GPT-4 وأقرانها) تذهب أبعد، معالجة مهام تتجاوز الترجمة.
2. تحت الغطاء: الانتباه متعدد الرؤوس والترميزات الموضعية
الانتباه متعدد الرؤوس
داخل الانتباه الذاتي لـ Transformer توجد هذه الوحوش السحرية التي تُدعى وحدات الانتباه متعدد الرؤوس. إنها تتيح للشبكة تعلم أنواع مختلفة من العلاقات بالتوازي. فكر فيها كنشر أضواء كاشفة متعددة لإنارة أجزاء مختلفة من بياناتك في نفس الوقت. قد يتتبع رأس انتباه واحد التبعيات بعيدة المدى (مثل مراجع الضمير-الاسم)، بينما يركز آخر على السياق المحلي (مثل العبارة "على الحصيرة" حول "القطة"). من خلال دمج هذه الانتباهات الفرعية المتخصصة، يمكن لـ Transformer ترميز معنى أكثر دقة بشكل أفضل.
[caption id="" align="alignnone" width="1220"]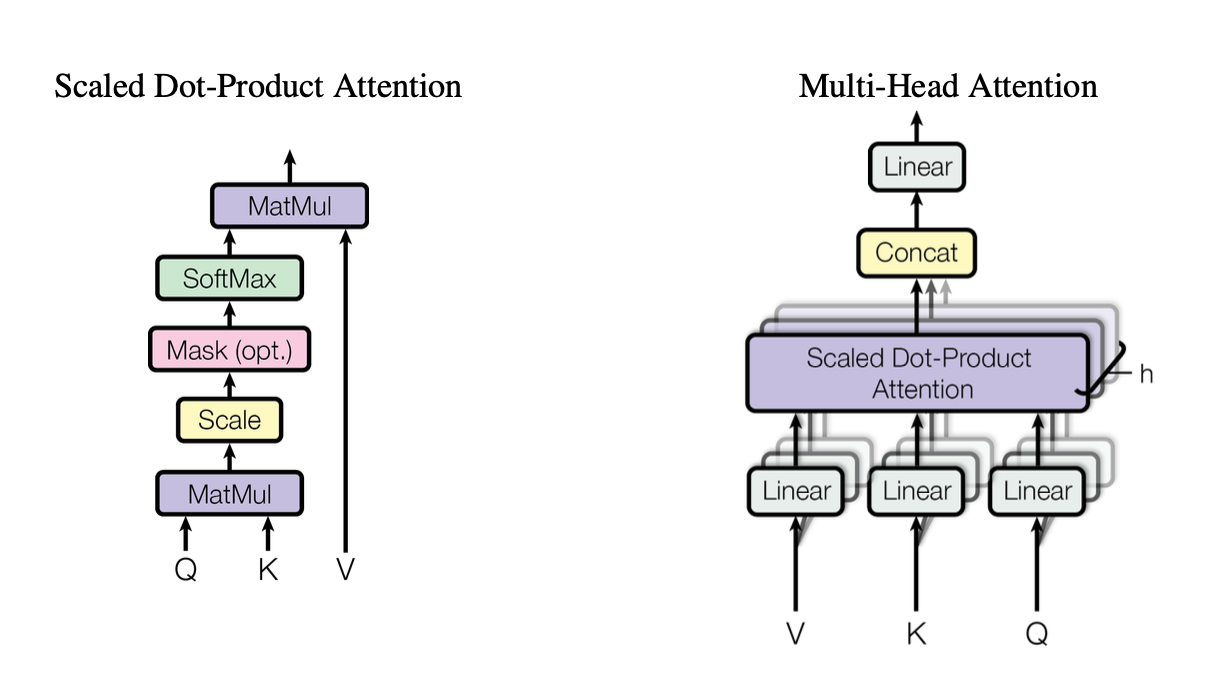 الشكل 2: توضيح آلية الانتباه للمنتج النقطي المُتدرج يُظهر كيف تتفاعل متجهات الاستعلام (Q) والمفتاح (K) والقيمة (V). المصدر: Vaswani وآخرون، "Attention Is All You Need" (2017). الصورة مُعاد إنتاجها لأغراض تعليمية تحت الاستخدام العادل. [/caption]
الشكل 2: توضيح آلية الانتباه للمنتج النقطي المُتدرج يُظهر كيف تتفاعل متجهات الاستعلام (Q) والمفتاح (K) والقيمة (V). المصدر: Vaswani وآخرون، "Attention Is All You Need" (2017). الصورة مُعاد إنتاجها لأغراض تعليمية تحت الاستخدام العادل. [/caption]
تستخدم هذه الرؤوس الانتباه للمنتج النقطي المتدرج كلبنة بناء أساسية، والذي يمكننا تلخيصه في الكود كالتالي:
import torchimport math def scaled_dot_product_attention(Q, K, V): # Q, K, V are [batch_size, heads, seq_len, d_k] d_k = Q.size(-1) scores = torch.matmul(Q, K.transpose(-2, -1)) / math.sqrt(d_k) weights = torch.softmax(scores, dim=-1) return torch.matmul(weights, V)
كل رأس يعمل على نسخ مُسقطة بشكل مختلف من الاستعلامات (Q) والمفاتيح (K) والقيم (V)، ثم يدمج النتائج. هذا التصميم القابل للمعالجة المتوازية هو المفتاح لكفاءة Transformer.
الترميزات الموضعية
لا تكرارات؟ هذا يثير السؤال: كيف يحتفظ النموذج بتتبع ترتيب الكلمات؟ ادخل الترميزات الموضعية—نمط جيبي أو مُتعلم يُضاف إلى تضمين كل رمز، مما يساعد Transformer على الحفاظ على إحساس بالتسلسل. إنه مثل إعطاء كل كلمة طابع زمني فريد.
3. مواجهة أداء سريعة
-
RNNs/LSTMs: ممتازة لمهام التسلسل لكنها بطيئة للتسلسلات الطويلة بسبب المعالجة خطوة بخطوة.
-
CNNs (مثل ConvS2S): أسرع من RNNs لكن ليست متوازية بالكامل للتبعيات طويلة المدى.
-
Transformers:
معدل نقل أعلى: يمكنها معالجة تسلسلات كاملة بالتوازي، مما يجعل التدريب أسرع بشكل كبير.
-
نتائج أفضل: حقق Transformers درجات متطورة في مهام مثل الترجمة الآلية (28.4 BLEU على WMT14 EN-DE) مع وقت تدريب أقل.
-
قابل للتوسع: ألق المزيد من GPU على البيانات وشاهدها تتوسع بشكل خطي تقريباً (ضمن حدود الأجهزة والذاكرة).
4. اعتبار التعقيد: O(n²) ولماذا يهم
بينما تُسرع Transformers التدريب من خلال المعالجة المتوازية، الانتباه الذاتي يحمل تعقيد O(n²) فيما يتعلق بطول التسلسل n. بمعنى آخر، كل رمز ينتبه إلى كل رمز آخر، مما قد يكون مكلفاً للتسلسلات الطويلة جداً. الباحثون يستكشفون بنشاط آليات انتباه أكثر كفاءة (مثل الانتباه المُتناثر أو القائم على الكتل) لتخفيف هذه التكلفة.
ومع ذلك، للمهام النموذجية في NLP حيث تكون أعداد الرموز في الآلاف بدلاً من الملايين، هذا العبء O(n²) غالباً ما يُقابل بفوائد الحوسبة المتوازية—خاصة إذا كان لديك الأجهزة المناسبة.
5. لماذا يهم لنماذج اللغة الكبيرة (LLMs)
نماذج LLM الحديثة—مثل GPT وBERT وT5—تتتبع نسبها مباشرة إلى Transformer. هذا لأن تركيز الورقة الأصلية على المعالجة المتوازية والانتباه الذاتي ونوافذ السياق المرنة جعلها مناسبة بشكل مثالي للمهام خارج الترجمة، بما في ذلك:
-
توليد النصوص والتلخيص
-
الإجابة على الأسئلة
-
إكمال الأكواد
-
روبوتات الدردشة متعددة اللغات
-
ونعم، مساعد الكتابة AI الجديد الذي يبدو وكأنه دائماً لديه تورية في جعبته.
باختصار، "Attention Is All You Need" مهدت الطريق لهذه النماذج الكبيرة التي تستوعب مليارات الرموز وتتعامل مع أي مهمة NLP تُلقيها عليها تقريباً.
6. سنحتاج إلى مزيد من الحوسبة: حيث تأتي عمليات نشر Introl
إليك المشكلة: Transformers جائعة—جائعة جداً. تدريب نموذج لغة كبير يمكن أن يعني استهلاك موارد الحوسبة بحمولات الرافعة الشوكية. لاستغلال كل هذا التوازي، تحتاج إلى عمليات نشر GPU قوية—أحياناً تُرقم بالآلاف (أو عشرات الآلاف). هنا تتدخل بنية الحوسبة عالية الأداء (HPC).
في Introl، شهدنا بشكل مباشر كيف يمكن أن تصبح هذه الأنظمة ضخمة. عملنا على بناءات تضمنت أكثر من 100,000 GPU في جداول زمنية ضيقة—تحدث عن البراعة اللوجستية. خبزنا وزبدتنا هو نشر خوادم GPU والرفوف وإعدادات الطاقة/التبريد المتقدمة حتى يعمل كل شيء بكفاءة. عندما تدرب نموذجاً قائماً على Transformer بشكل متزامن على آلاف العقد، أي عنق زجاجة في الأجهزة هو دوامة طاقة للوقت والمال.
-
مجموعات GPU واسعة النطاق: لقد نفذنا عمليات نشر تجاوزت 100K GPU، مما يعني أننا نفهم تعقيدات تكوينات الرف والتكديس، والكابلات، واستراتيجيات الطاقة/التبريد للحفاظ على استقرار كل شيء.
-
التعبئة السريعة: تحتاج إلى إضافة 2,000 عقدة GPU أخرى في بضعة أيام؟ فرقنا المتخصصة يمكن أن تكون في الموقع وتعمل خلال 72 ساعة.
-
الدعم الشامل: من تحديثات البرامج الثابتة وتكوينات iDRAC إلى الصيانة المستمرة وفحوصات الأداء، نحن ندير اللوجستيات حتى يتمكن علماء البيانات لديك من التركيز على الابتكار.
7. النظر إلى الأمام: نماذج أكبر، أحلام أكبر
"Attention Is All You Need" ليست مجرد معلم—إنها مخطط للتوسعات المستقبلية. الباحثون يستكشفون بالفعل Transformers ذات سياق أطول، وآليات انتباه فعالة، وتناثر متقدم للتعامل مع مجموعات ضخمة (فكر: مكتبات كاملة، ليس فقط متجر الكتب المحلي). كن مطمئناً، الشهية للحوسبة المُسرعة بـ GPU ستتزايد فقط.
وهذا جمال عصر Transformer. لدينا نموذج يمكن أن يتوسع بأناقة، بشرط أن نطابقه مع استراتيجية الأجهزة المناسبة. لذا سواء كنت تبني الظاهرة التوليدية AI القادمة أو تدفع حدود الترجمة العالمية، وجود شريك بنية تحتية بارع في عمليات نشر GPU الضخمة أكثر من مجرد أمر جميل؛ إنه عملياً ميزتك التنافسية.
الفكرة الأخيرة: حوّل لعبة AI الخاصة بك
الورقة Attention Is All You Need كانت أكثر من عنوان ذكي—كانت تحولاً زلزالياً. لقد حولت Transformers كل شيء من الترجمة الآلية إلى توليد الأكواد وما هو أبعد من ذلك. إذا كنت تريد استغلال هذه القوة على نطاق واسع، المفتاح هو مطابقة المعمارية الرائعة مع بنية تحتية رائعة بنفس القدر.
مستعد للتوسع؟ اكتشف كيف يمكن لـ عمليات نشر البنية التحتية GPU المتخصصة من Introl أن تُسرع مشروع Transformer الكبير التالي—لأن الأجهزة المناسبة يمكن أن تُحدث كل الفرق في AI.
الرسوم التوضيحية في هذا المقال من الورقة الأصلية "Attention Is All You Need" (Vaswani وآخرون، 2017) ومُدرجة مع الإسناد تحت الاستخدام العادل لأغراض تعليمية. الورقة متاحة في https://arxiv.org/abs/1706.03762 للقراء المهتمين بالبحث الكامل.


