

क्या आपको लगता है कि जब भी कोई "large language models" का जिक्र करता है तो आप व्यावहारिक रूप से GPUs की गुंजाइश सुन सकते हैं? इस ब्रह्मांडीय स्तर की गूंज का एक कारण है: Transformer architectures। और अगर हम इस घटना को उसके Big Bang के क्षण तक ट्रेस करें, तो हम Google Brain और Google Research इंजीनियरों के एक समूह के अब-प्रसिद्ध 2017 पेपर पर पहुंचते हैं: Attention Is All You Need।
पहली नज़र में, यह वाक्यांश mindfulness की दिशा में एक नम्र संकेत लग सकता है, लेकिन इसने natural language processing (NLP) और इससे आगे एक क्रांति की घोषणा की। Transformer मॉडल ने एक ही झटके में AI की स्थिति को उलट दिया: अब RNNs, LSTMs, और convolution-based sequence models की इंच-दर-इंच प्रगति की जरूरत नहीं। इसके बजाय, हमें एक parallelizable, attention-driven सिस्टम मिला जो तेजी से train करता है, बड़े पैमाने पर scale करता है, और—यहाँ है असली बात—बेहतर परिणाम प्राप्त करता है।
1. बड़ा विचार: Self-Attention की जय-जयकार
Transformers के scene पर आने से पहले, sequence transduction (जैसे भाषा अनुवाद, सारांश, आदि) के लिए gold standard में सावधानीपूर्वक engineered gating mechanisms के साथ recurrent neural networks या long-range dependencies को handle करने के लिए जटिल stacking के साथ convolutional neural networks शामिल थे। प्रभावी? हाँ। धीमे? भी, हाँ—खासकर जब आपको सच में विशाल datasets का विश्लेषण करने की जरूरत हो।
सबसे सरल शब्दों में, self-attention एक mechanism है जिसके द्वारा एक sequence में हर token (जैसे, एक word या subword) एक साथ हर दूसरे token को "देख" सकता है, contextual relationships की खोज करते हुए data के through step-by-step crawl करने के लिए मजबूर हुए बिना। यह approach पुराने models जैसे RNNs और LSTMs के विपरीत है, जिन्हें sequence को काफी हद तक sequentially process करना पड़ता था।
Transformers recurrence (और इसके साथ आने वाले overhead) को छोड़कर कहीं अधिक parallelization को सक्षम बनाते हैं। आप problem पर GPUs की एक फौज फेंक सकते हैं, massive datasets पर train कर सकते हैं, और हफ्तों के बजाय दिनों में परिणाम देख सकते हैं।
[caption id="" align="alignnone" width="847"]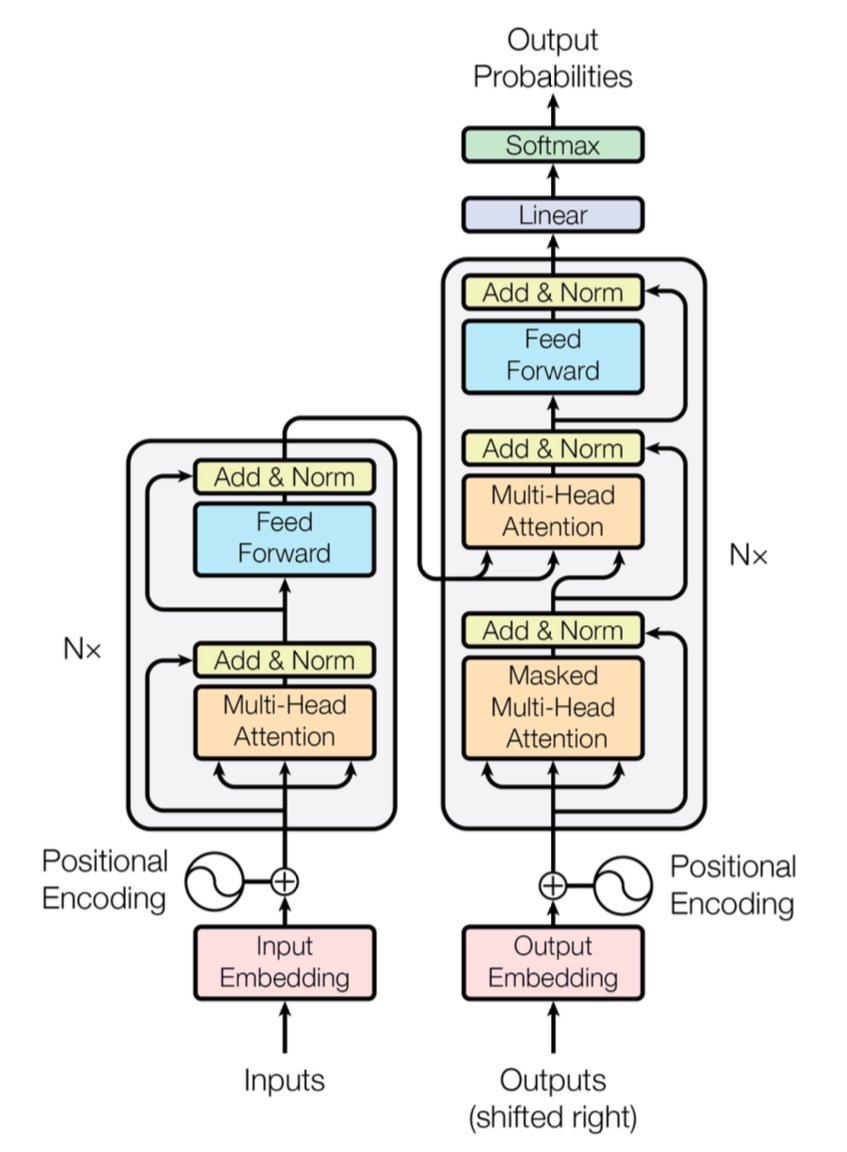 Figure 1: The complete Transformer architecture showing encoder (left) and decoder (right) with multi-head attention layers. Source: Vaswani et al., "Attention Is All You Need" (2017). Image reproduced for educational purposes under fair use. [/caption]
Figure 1: The complete Transformer architecture showing encoder (left) and decoder (right) with multi-head attention layers. Source: Vaswani et al., "Attention Is All You Need" (2017). Image reproduced for educational purposes under fair use. [/caption]
त्वरित प्रदर्शन नोट: मूल Transformer ने WMT 2014 English-to-German task पर 28.4 BLEU score प्रदर्शित किया—CNN-based और RNN-based models जैसे पूर्व neural machine translation architectures पर एक ठोस छलांग, जो बेहतर से बेहतर 25-26 BLEU के आसपास मंडराते थे। आजकल, सुधारे गए Transformers (GPT-4 और इसके cousins के बारे में सोचें) और भी आगे जाते हैं, translation से आगे के tasks को handle करते हुए।
2. हुड के नीचे: Multi-Head Attention और Positional Encodings
Multi-Head Attention
Transformer के self-attention के भीतर ये जादुई जीव हैं जिन्हें multi-head attention modules कहा जाता है। ये network को parallel में विभिन्न प्रकार के relationships सीखने देते हैं। इसे अपने data के विभिन्न हिस्सों को एक साथ illuminate करने के लिए कई spotlights तैनात करने के रूप में सोचें। एक attention head long-distance dependencies को track कर सकता है (जैसे pronoun-noun references), जबकि दूसरा local context पर focus करता है (जैसे "cat" के आसपास "on the mat" वाक्यांश)। इन specialized sub-attentions को combine करते हुए, Transformer बेहतर nuanced meaning को encode कर सकता है।
[caption id="" align="alignnone" width="1220"]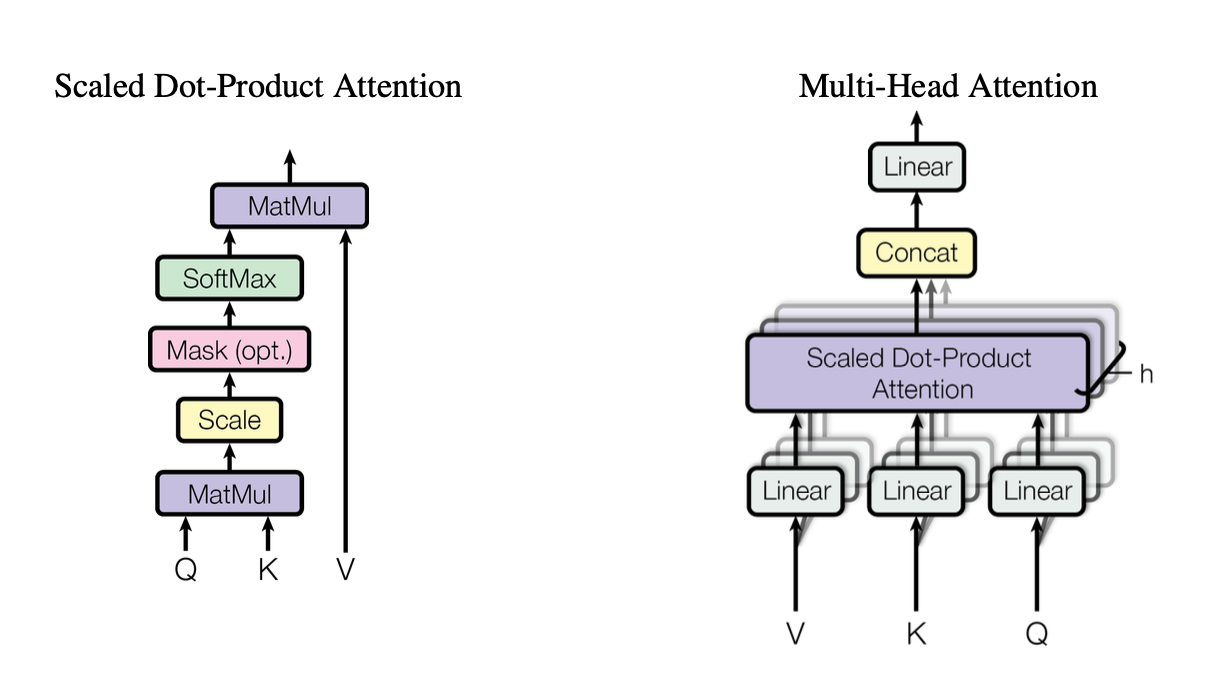 Figure 2: Illustration of the scaled dot-product attention mechanism showing how Query (Q), Key (K), and Value (V) vectors interact. Source: Vaswani et al., "Attention Is All You Need" (2017). Image reproduced for educational purposes under fair use. [/caption]
Figure 2: Illustration of the scaled dot-product attention mechanism showing how Query (Q), Key (K), and Value (V) vectors interact. Source: Vaswani et al., "Attention Is All You Need" (2017). Image reproduced for educational purposes under fair use. [/caption]
ये heads scaled dot-product attention को standard building block के रूप में उपयोग करते हैं, जिसे हम code में इस प्रकार summarize कर सकते हैं:
import torchimport math def scaled_dot_product_attention(Q, K, V): # Q, K, V are [batch_size, heads, seq_len, d_k] d_k = Q.size(-1) scores = torch.matmul(Q, K.transpose(-2, -1)) / math.sqrt(d_k) weights = torch.softmax(scores, dim=-1) return torch.matmul(weights, V)
हर head queries (Q), keys (K), और values (V) के अलग-अलग projected versions पर operate करता है, फिर results को merge करता है। यह parallelizable design Transformer की efficiency की key है।
Positional Encodings
कोई recurrences नहीं? यह सवाल उठाता है: model word order का track कैसे रखता है? यहाँ आते हैं positional encodings—हर token की embedding में जोड़ा गया एक sinusoidal या learned pattern, जो Transformer को sequence की sense बनाए रखने में मदद करता है। यह हर word को unique timestamp देने जैसा है।
3. त्वरित प्रदर्शन तुलना
-
RNNs/LSTMs: sequence tasks के लिए बेहतरीन लेकिन step-by-step processing के कारण long sequences के लिए धीमे।
-
CNNs (जैसे ConvS2S): RNNs से तेज लेकिन long-range dependencies के लिए अभी भी पूर्णतः parallel नहीं।
-
Transformers:
Higher Throughput: पूरे sequences को parallel में process कर सकते हैं, जिससे training काफी तेज हो जाता है।
-
Better Results: Transformers ने machine translation जैसे tasks में state-of-the-art scores हासिल किए (WMT14 EN-DE पर 28.4 BLEU) कम training time के साथ।
-
Scalable: data पर अधिक GPUs फेंकें और इसे लगभग linearly scale होते देखें (hardware और memory limits के भीतर)।
4. Complexity का विचार: O(n²) और यह क्यों महत्वपूर्ण है
जबकि Transformers parallelization के माध्यम से training को accelerate करते हैं, self-attention sequence length n के संबंध में O(n²) complexity रखता है। दूसरे शब्दों में, हर token हर दूसरे token को attend करता है, जो extremely long sequences के लिए expensive हो सकता है। Researchers सक्रिय रूप से अधिक efficient attention mechanisms (जैसे sparse या block-wise attention) की खोज कर रहे हैं इस cost को कम करने के लिए।
फिर भी, typical NLP tasks के लिए जहाँ token counts हजारों में हैं लाखों के बजाय, यह O(n²) overhead अक्सर parallel computation के benefits से कम हो जाता है—खासकर अगर आपके पास उचित hardware है।
5. Large Language Models (LLMs) के लिए यह क्यों महत्वपूर्ण है
Modern LLMs—जैसे GPT, BERT, और T5—अपनी lineage सीधे Transformer से trace करते हैं। ऐसा इसलिए है क्योंकि original paper का parallelism, self-attention, और flexible context windows पर focus ने इसे translation से आगे के tasks के लिए ideally suited बनाया, जिनमें शामिल हैं:
-
Text Generation & Summarization
-
Question-Answering
-
Code Completion
-
Multi-lingual Chatbots
-
और हाँ, आपका नया AI writing assistant हमेशा अपनी sleeve में एक pun रखता लगता है।
संक्षेप में, "Attention Is All You Need" ने इन large models के लिए रास्ता बनाया जो billions tokens को ingest करते हैं और आपके द्वारा फेंके जाने वाले लगभग किसी भी NLP task को handle करते हैं।
6. हमें अधिक compute की जरूरत होगी: जहाँ Introl की Deployments आती हैं
यहाँ है catch: Transformers भूखे हैं—बहुत भूखे। एक large language model को train करने का मतलब forklift load से computing resources को hoover up करना हो सकता है। उस सभी parallelism का उपयोग करने के लिए, आपको robust GPU deployments की जरूरत है—कभी-कभी हजारों (या दस हजारों) की संख्या में। वहीं high-performance computing (HPC) infrastructure कदम रखता है।
Introl में, हमने firsthand देखा है कि ये systems कितने massive हो सकते हैं। हमने 100,000 से अधिक GPUs वाले builds पर tight timelines पर काम किया है—logistical prowess की बात करें। हमारी bread and butter GPU servers, racks, और advanced power/cooling setups को deploy करना है ताकि सब कुछ efficiently hum करे। जब आप एक साथ thousands nodes पर Transformer-based model को train कर रहे हों, कोई भी hardware bottleneck time और money दोनों के लिए energy vortex है।
-
Large-Scale GPU Clusters: हमने 100K GPUs से आगे push करने वाली deployments execute की हैं, मतलब हम rack-and-stack configurations, cabling, और power/cooling strategies की जटिलताओं को समझते हैं ताकि सब कुछ stable रहे।
-
Rapid Mobilization: कुछ दिनों में अन्य 2,000 GPU nodes जोड़ने की जरूरत है? हमारी specialized teams 72 घंटों के भीतर on-site और operational हो सकती हैं।
-
End-to-End Support: Firmware updates और iDRAC configurations से लेकर ongoing maintenance और performance checks तक, हम logistics को manage करते हैं ताकि आपके data scientists innovation पर focused रह सकें।
7. आगे देखते हुए: बड़े Models, बड़े सपने
"Attention Is All You Need" सिर्फ एक milestone नहीं है—यह future expansions के लिए blueprint है। Researchers पहले से ही longer-context Transformers, efficient attention mechanisms, और enormous corpora (सोचें: पूरी libraries, सिर्फ आपकी local bookstore नहीं) को handle करने के लिए advanced sparsity की खोज कर रहे हैं। निश्चित रहें, GPU-accelerated computing की appetite केवल ramp up होगी।
और यही Transformer era की सुंदरता है। हमारे पास एक model है जो elegantly scale कर सकता है, बशर्ते हम इसे उचित hardware strategy के साथ match करें। तो चाहे आप अगला generative AI phenomenon build कर रहे हों या universal translation की boundaries push कर रहे हों, massive GPU deployments में adept infrastructure partner का होना सिर्फ nice-to-have से अधिक है; यह व्यावहारिक रूप से आपका competitive edge है।
अंतिम विचार: अपना AI Game Transform करें
Paper Attention Is All You Need एक clever title से अधिक था—यह एक seismic shift था। Transformers ने machine translation से code generation और इससे आगे सब कुछ transform कर दिया है। अगर आप उस power को scale पर harness करना चाहते हैं, तो key brilliant architecture को equally brilliant infrastructure के साथ match करना है।
Scale up करने के लिए तैयार? जानें कि कैसे Introl के specialized GPU Infrastructure Deployments आपके अगले बड़े Transformer project को accelerate कर सकते हैं—क्योंकि उचित hardware AI में सारा अंतर ला सकता है।
इस article में visualizations original "Attention Is All You Need" paper (Vaswani et al., 2017) से हैं और educational purposes के लिए fair use के तहत attribution के साथ शामिल किए गए हैं। पूरी research में interested readers के लिए paper https://arxiv.org/abs/1706.03762 पर उपलब्ध है।


