

Bạn có cảm thấy như có thể thực sự nghe thấy tiếng ồn của GPU mỗi khi ai đó nhắc đến "large language models" không? Có một lý do cho sự rung chuyển ở quy mô vũ trụ đó: kiến trúc Transformer. Và nếu chúng ta truy ngược hiện tượng này về thời điểm Big Bang của nó, chúng ta sẽ đến thẳng một bài báo huyền thoại năm 2017 từ nhóm các kỹ sư Google Brain và Google Research: Attention Is All You Need.
Thoạt nhìn, cụm từ này có thể nghe như một lời khuyên nhẹ nhàng về thiền định, nhưng nó đã báo hiệu một cuộc cách mạng trong xử lý ngôn ngữ tự nhiên (NLP) và hơn thế nữa. Mô hình Transformer đã lật đổ hiện trạng AI trong một nhát: không còn tiến bộ từng inch của RNN, LSTM, và các mô hình sequence dựa trên convolution. Thay vào đó, chúng ta có một hệ thống có thể song song hóa, dựa trên attention, huấn luyện nhanh hơn, mở rộng lớn hơn, và—điều quan trọng nhất—đạt kết quả tốt hơn.
1. Ý Tưởng Lớn: Hoan Hô Self-Attention
Trước khi Transformer xuất hiện, tiêu chuẩn vàng cho sequence transduction (như dịch máy, tóm tắt, v.v.) bao gồm các mạng neural tái diễn với cơ chế gating được thiết kế cẩn thận hoặc mạng neural tích chập với việc xếp chồng phức tạp để xử lý các dependency xa. Hiệu quả? Có. Chậm? Cũng có—đặc biệt khi bạn cần phân tích các bộ dữ liệu thực sự lớn.
Nói một cách đơn giản nhất, self-attention là một cơ chế mà mỗi token trong một chuỗi (ví dụ: một từ hoặc subword) có thể "nhìn" vào mọi token khác đồng thời, khám phá các mối quan hệ ngữ cảnh mà không bị buộc phải bò từng bước qua dữ liệu. Cách tiếp cận này tương phản với các mô hình cũ hơn, như RNN và LSTM, phải xử lý chuỗi phần lớn theo tuần tự.
Transformer cho phép song song hóa nhiều hơn bằng cách loại bỏ recurrence (và overhead đi kèm với nó). Bạn có thể ném một đống GPU vào vấn đề, huấn luyện trên các bộ dữ liệu lớn, và thấy kết quả trong vài ngày thay vì vài tuần.
[caption id="" align="alignnone" width="847"]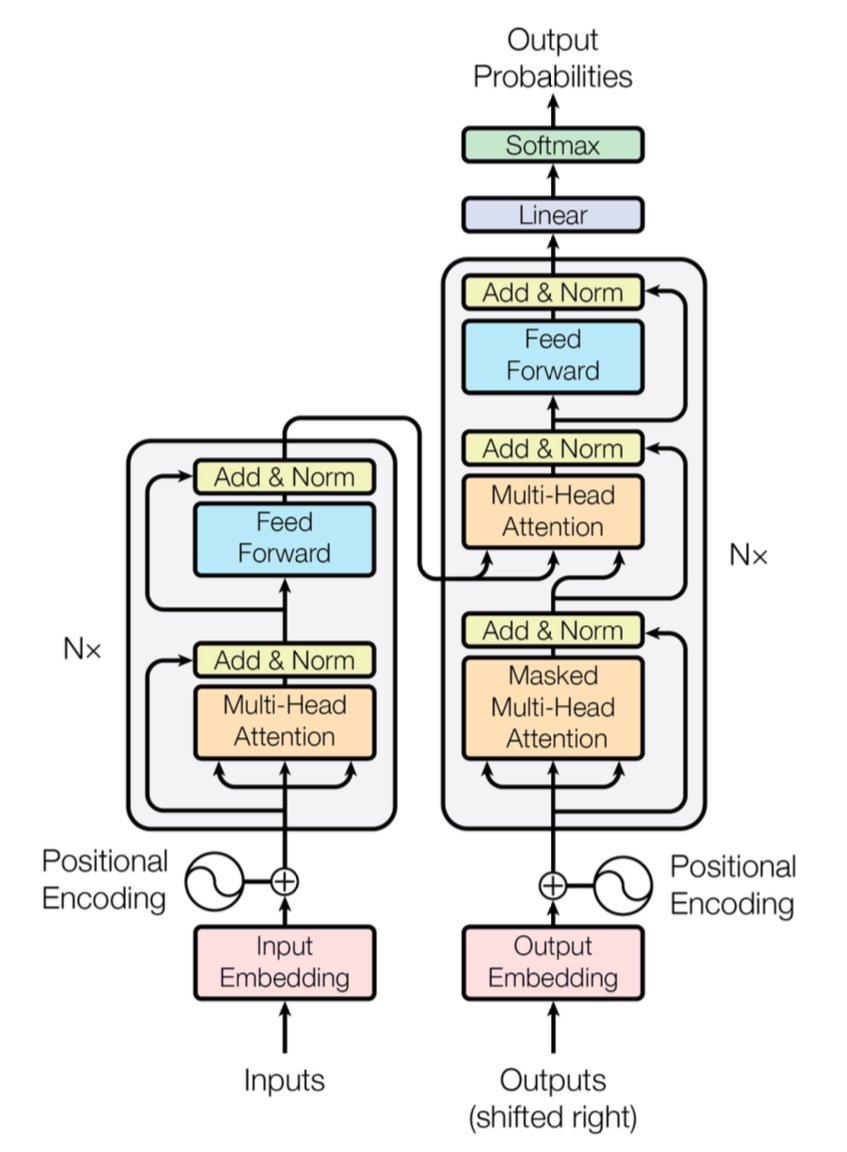 Hình 1: Kiến trúc Transformer hoàn chỉnh hiển thị encoder (trái) và decoder (phải) với các lớp multi-head attention. Nguồn: Vaswani et al., "Attention Is All You Need" (2017). Hình ảnh được tái sản xuất cho mục đích giáo dục dưới fair use. [/caption]
Hình 1: Kiến trúc Transformer hoàn chỉnh hiển thị encoder (trái) và decoder (phải) với các lớp multi-head attention. Nguồn: Vaswani et al., "Attention Is All You Need" (2017). Hình ảnh được tái sản xuất cho mục đích giáo dục dưới fair use. [/caption]
Ghi Chú Hiệu Suất Nhanh: Transformer gốc đã chứng minh điểm BLEU 28.4 trên tác vụ WMT 2014 English-to-German—một bước nhảy vững chắc so với các kiến trúc dịch máy neural trước đó như mô hình dựa trên CNN và RNN, dao động khoảng 25–26 BLEU tối đa. Ngày nay, các Transformer được cải tiến (như GPT-4 và các mô hình tương tự) đi xa hơn nữa, xử lý các tác vụ ngoài dịch thuật.
2. Bên Trong: Multi-Head Attention và Positional Encodings
Multi-Head Attention
Trong self-attention của Transformer có những con quái vật kỳ diệu gọi là các module multi-head attention. Chúng cho phép mạng học các loại mối quan hệ khác nhau song song. Hãy nghĩ về nó như triển khai nhiều đèn pha để chiếu sáng các phần khác nhau của dữ liệu đồng thời. Một attention head có thể theo dõi các dependency xa (như tham chiếu đại từ-danh từ), trong khi head khác tập trung vào ngữ cảnh local (như cụm từ "on the mat" xung quanh "cat"). Kết hợp các sub-attention chuyên biệt này, Transformer có thể mã hóa ý nghĩa tinh tế tốt hơn.
[caption id="" align="alignnone" width="1220"]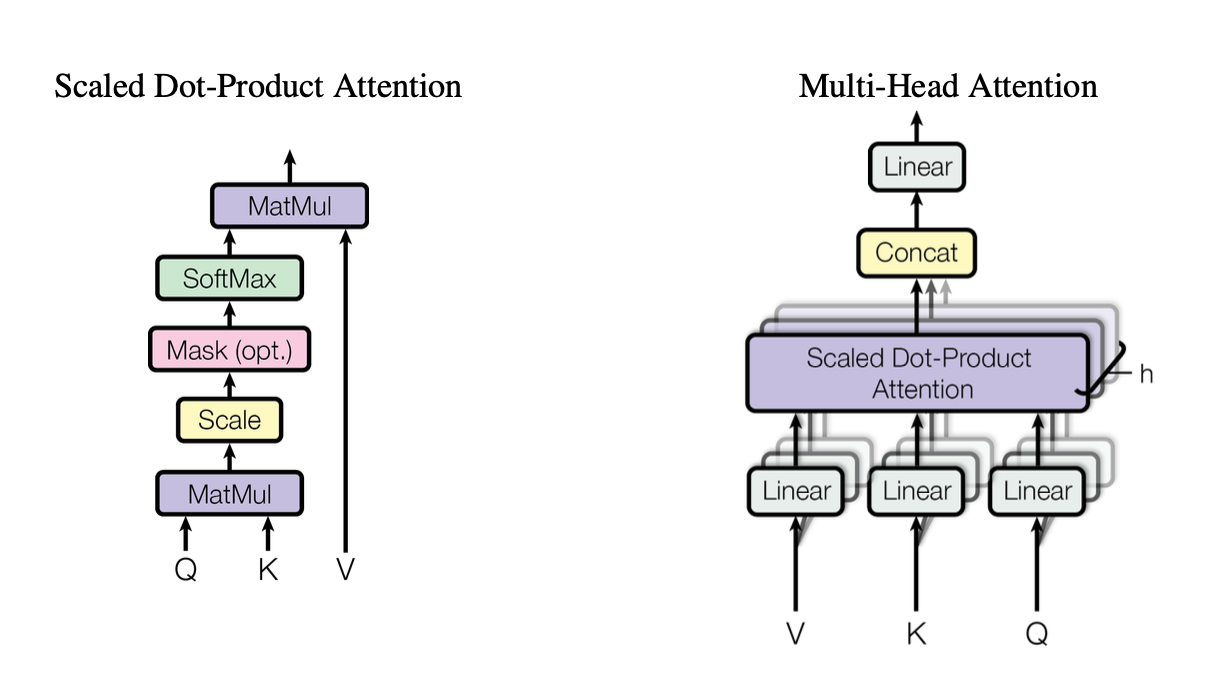 Hình 2: Minh họa cơ chế scaled dot-product attention cho thấy cách các vector Query (Q), Key (K), và Value (V) tương tác. Nguồn: Vaswani et al., "Attention Is All You Need" (2017). Hình ảnh được tái sản xuất cho mục đích giáo dục dưới fair use. [/caption]
Hình 2: Minh họa cơ chế scaled dot-product attention cho thấy cách các vector Query (Q), Key (K), và Value (V) tương tác. Nguồn: Vaswani et al., "Attention Is All You Need" (2017). Hình ảnh được tái sản xuất cho mục đích giáo dục dưới fair use. [/caption]
Các head này sử dụng scaled dot-product attention làm khối xây dựng chuẩn, mà chúng ta có thể tóm tắt trong code như sau:
import torch import math def scaled_dot_product_attention(Q, K, V): # Q, K, V are [batch_size, heads, seq_len, d_k] d_k = Q.size(-1) scores = torch.matmul(Q, K.transpose(-2, -1)) / math.sqrt(d_k) weights = torch.softmax(scores, dim=-1) return torch.matmul(weights, V)
Mỗi head hoạt động trên các phiên bản được chiếu khác nhau của queries (Q), keys (K), và values (V), sau đó hợp nhất kết quả. Thiết kế có thể song song hóa này là chìa khóa cho hiệu quả của Transformer.
Positional Encodings
Không có recurrence? Điều đó đặt ra câu hỏi: Mô hình theo dõi thứ tự từ như thế nào? Đó là lúc positional encodings xuất hiện—một pattern sinusoidal hoặc được học thêm vào embedding của mỗi token, giúp Transformer duy trì cảm giác về sequence. Giống như cho mỗi từ một timestamp duy nhất.
3. So Sánh Hiệu Suất Nhanh
-
RNN/LSTM: Tuyệt vời cho các tác vụ sequence nhưng chậm cho các chuỗi dài do xử lý từng bước.
-
CNN (ví dụ: ConvS2S): Nhanh hơn RNN nhưng vẫn chưa hoàn toàn song song cho các dependency xa.
-
Transformer:
Throughput Cao Hơn: Có thể xử lý toàn bộ chuỗi song song, làm cho việc huấn luyện nhanh hơn đáng kể.
-
Kết Quả Tốt Hơn: Transformer đạt điểm số tốt nhất trong các tác vụ như dịch máy (28.4 BLEU trên WMT14 EN-DE) với ít thời gian huấn luyện hơn.
-
Có Thể Mở Rộng: Ném thêm GPU vào dữ liệu và xem nó mở rộng gần như tuyến tính (trong giới hạn phần cứng và bộ nhớ).
4. Cân Nhắc Về Độ Phức Tạp: O(n²) và Tại Sao Nó Quan Trọng
Trong khi Transformer tăng tốc huấn luyện thông qua song song hóa, self-attention mang theo độ phức tạp O(n²) liên quan đến độ dài chuỗi n. Nói cách khác, mọi token attend to mọi token khác, có thể tốn kém cho các chuỗi cực dài. Các nhà nghiên cứu đang tích cực khám phá các cơ chế attention hiệu quả hơn (như sparse hoặc block-wise attention) để giảm thiểu chi phí này.
Tuy vậy, đối với các tác vụ NLP điển hình nơi số lượng token tính bằng hàng nghìn thay vì hàng triệu, overhead O(n²) này thường bị vượt qua bởi lợi ích của tính toán song song—đặc biệt nếu bạn có phần cứng phù hợp.
5. Tại Sao Nó Quan Trọng Với Large Language Models (LLMs)
Các LLM hiện đại—như GPT, BERT, và T5—truy nguyên gốc rễ trực tiếp từ Transformer. Đó là bởi vì sự tập trung của bài báo gốc vào song song hóa, self-attention, và context windows linh hoạt khiến nó lý tưởng cho các tác vụ ngoài dịch thuật, bao gồm:
-
Text Generation & Summarization
-
Question-Answering
-
Code Completion
-
Multi-lingual Chatbots
-
Và vâng, trợ lý viết AI mới của bạn luôn dường như có một lời chơi chữ trong tay áo.
Tóm lại, "Attention Is All You Need" đã mở đường cho những mô hình lớn này tiêu thụ hàng tỷ token và xử lý hầu như bất kỳ tác vụ NLP nào bạn ném vào.
6. Chúng ta sẽ cần thêm compute: Nơi Triển Khai của Introl Xuất Hiện
Đây là vấn đề: Transformer rất tham ăn—rất, rất tham ăn. Huấn luyện một large language model có thể có nghĩa là hút tài nguyên tính toán theo xe nâng. Để khai thác tất cả sự song song hóa đó, bạn cần triển khai GPU mạnh mẽ—đôi khi đếm bằng hàng nghìn (hoặc hàng chục nghìn). Đó là lúc hạ tầng high-performance computing (HPC) bước vào.
Tại Introl, chúng tôi đã chứng kiến tận mắt những hệ thống này có thể lớn như thế nào. Chúng tôi đã làm việc trên các build liên quan đến hơn 100,000 GPU trong thời gian chặt—thực sự là năng lực logistics. Bread and butter của chúng tôi là triển khai GPU servers, racks, và thiết lập power/cooling tiên tiến để mọi thứ chạy hiệu quả. Khi bạn đồng thời huấn luyện mô hình dựa trên Transformer trên hàng nghìn node, bất kỳ bottleneck phần cứng nào cũng là vortex năng lượng cho cả thời gian và tiền bạc.
-
GPU Clusters Quy Mô Lớn: Chúng tôi đã thực hiện các triển khai vượt quá 100K GPU, có nghĩa là chúng tôi hiểu các phức tạp của cấu hình rack-and-stack, cabling, và chiến lược power/cooling để giữ mọi thứ ổn định.
-
Mobilization Nhanh: Cần thêm 2,000 GPU nodes trong vài ngày? Các team chuyên biệt của chúng tôi có thể có mặt tại chỗ và hoạt động trong vòng 72 giờ.
-
Hỗ Trợ End-to-End: Từ cập nhật firmware và cấu hình iDRAC đến bảo trì liên tục và kiểm tra hiệu suất, chúng tôi quản lý logistics để các data scientist có thể tập trung vào đổi mới.
7. Nhìn Về Phía Trước: Mô Hình Lớn Hơn, Giấc Mơ Lớn Hơn
"Attention Is All You Need" không chỉ là một cột mốc—nó là blueprint cho các mở rộng tương lai. Các nhà nghiên cứu đã khám phá Transformer ngữ cảnh dài hơn, cơ chế attention hiệu quả, và sparsity tiên tiến để xử lý corpora khổng lồ (nghĩ: toàn bộ thư viện, không chỉ hiệu sách địa phương của bạn). Hãy yên tâm, sự thèm muốn cho tính toán được tăng tốc GPU sẽ chỉ tăng lên.
Và đó là vẻ đẹp của kỷ nguyên Transformer. Chúng ta có một mô hình có thể mở rộng một cách thanh lịch, miễn là chúng ta kết hợp nó với chiến lược phần cứng phù hợp. Vì vậy, dù bạn đang xây dựng hiện tượng generative AI tiếp theo hay đẩy ranh giới của dịch thuật universal, có một đối tác hạ tầng thạo trong triển khai GPU lớn không chỉ là nice-to-have; nó thực tế là lợi thế cạnh tranh của bạn.
Suy Nghĩ Cuối: Transform AI Game Của Bạn
Bài báo Attention Is All You Need không chỉ là một tiêu đề thông minh—nó là một sự thay đổi địa chấn. Transformer đã biến đổi mọi thứ từ dịch máy đến tạo code và hơn thế nữa. Nếu bạn muốn khai thác sức mạnh đó ở quy mô lớn, chìa khóa là kết hợp kiến trúc xuất sắc với hạ tầng cũng xuất sắc không kém.
Sẵn sàng mở rộng? Tìm hiểu cách GPU Infrastructure Deployments chuyên biệt của Introl có thể tăng tốc dự án Transformer lớn tiếp theo của bạn—bởi vì phần cứng phù hợp có thể tạo ra tất cả sự khác biệt trong AI.
Các visualization trong bài viết này từ bài báo "Attention Is All You Need" gốc (Vaswani et al., 2017) và được bao gồm với attribution dưới fair use cho mục đích giáo dục. Bài báo có sẵn tại https://arxiv.org/abs/1706.03762 cho độc giả quan tâm đến nghiên cứu hoàn chỉnh.


