

Haben Sie das Gefühl, dass Sie praktisch das Summen von GPUs hören können, sobald jemand "Large Language Models" erwähnt? Dafür gibt es einen Grund für dieses kosmische Brummen: Transformer-Architekturen. Und wenn wir dieses Phänomen zu seinem Big Bang-Moment zurückverfolgen, landen wir direkt bei einem mittlerweile legendären Paper aus dem Jahr 2017 von einer Gruppe von Google Brain und Google Research Ingenieuren: Attention Is All You Need.
Auf den ersten Blick mag der Satz wie ein sanfter Schubs in Richtung Achtsamkeit klingen, aber er läutete eine Revolution im Natural Language Processing (NLP) und darüber hinaus ein. Das Transformer-Modell stürzte den AI-Status quo in einem einzigen schnellen Schlag um: kein zentimeterweises Voranschreiten mehr von RNNs, LSTMs und faltungsbasierten Sequenzmodellen. Stattdessen bekamen wir ein parallelisierbares, aufmerksamkeitsgetriebenes System, das schneller trainiert, größer skaliert und—hier ist der Clou—bessere Ergebnisse erzielt.
1. Die große Idee: Es lebe die Self-Attention
Bevor Transformer auf die Bühne traten, war der Goldstandard für Sequenztransduktion (denken Sie an Sprachübersetzung, Zusammenfassung, etc.) rekurrente neuronale Netzwerke mit sorgfältig entwickelten Gating-Mechanismen oder Convolutional Neural Networks mit komplizierten Schichtungen zur Behandlung von Langstreckenabhängigkeiten. Effektiv? Ja. Langsam? Auch ja—besonders wenn Sie wirklich massive Datensätze analysieren müssen.
In einfachsten Begriffen ist Self-Attention ein Mechanismus, durch den jeder Token in einer Sequenz (z.B. ein Wort oder Teilwort) gleichzeitig auf jeden anderen Token "schauen" kann und kontextuelle Beziehungen entdeckt, ohne gezwungen zu sein, Schritt-für-Schritt durch die Daten zu kriechen. Dieser Ansatz kontrastiert mit älteren Modellen wie RNNs und LSTMs, die die Sequenz größtenteils sequenziell verarbeiten mussten.
Transformer ermöglichen weit mehr Parallelisierung, indem sie Rekurrenz (und den damit verbundenen Overhead) verwerfen. Sie können eine Vielzahl von GPUs auf das Problem loslassen, auf massiven Datensätzen trainieren und Ergebnisse in Tagen statt Wochen sehen.
[caption id="" align="alignnone" width="847"]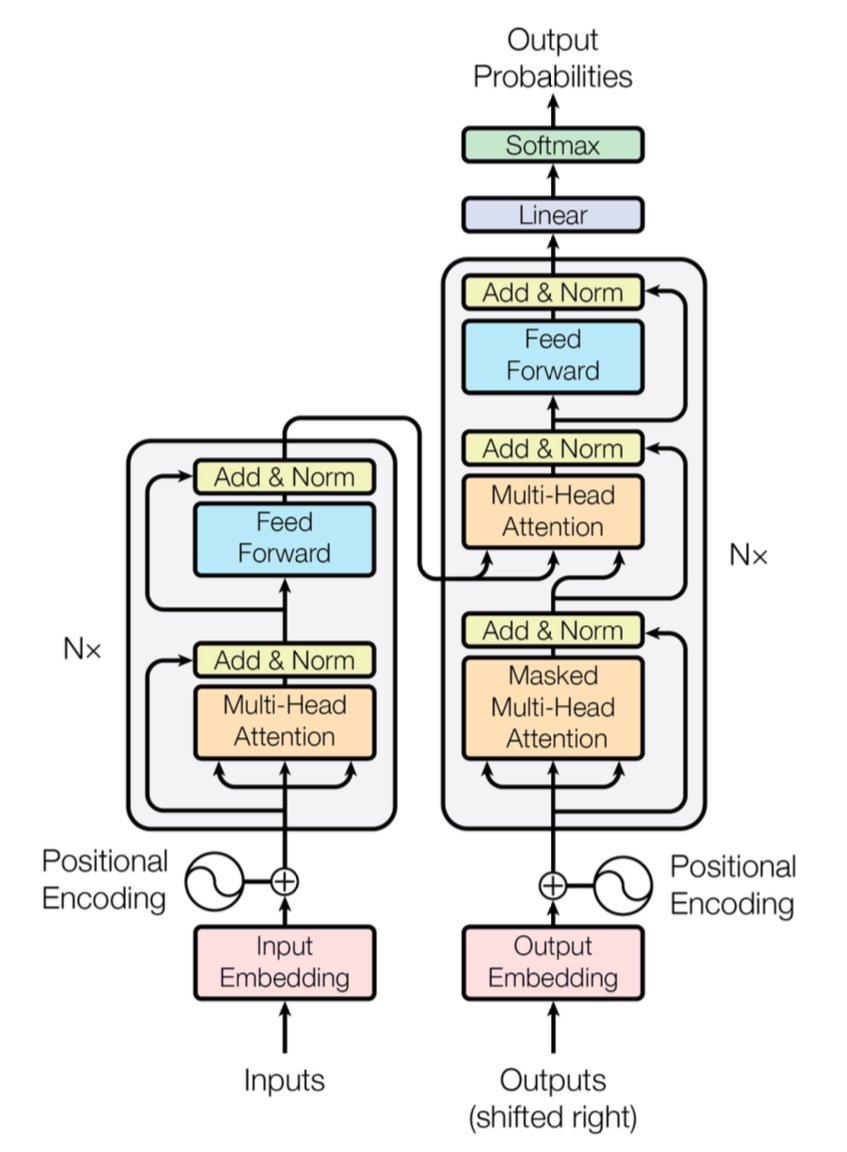 Abbildung 1: Die vollständige Transformer-Architektur zeigt Encoder (links) und Decoder (rechts) mit Multi-Head Attention-Schichten. Quelle: Vaswani et al., "Attention Is All You Need" (2017). Bild reproduziert für Bildungszwecke unter Fair Use. [/caption]
Abbildung 1: Die vollständige Transformer-Architektur zeigt Encoder (links) und Decoder (rechts) mit Multi-Head Attention-Schichten. Quelle: Vaswani et al., "Attention Is All You Need" (2017). Bild reproduziert für Bildungszwecke unter Fair Use. [/caption]
Kurze Leistungsnotiz: Der ursprüngliche Transformer demonstrierte einen 28.4 BLEU-Score bei der WMT 2014 English-to-German-Aufgabe—ein solider Sprung über frühere neuronale Maschinenübersetzungsarchitekturen wie CNN-basierte und RNN-basierte Modelle, die bestenfalls um 25–26 BLEU pendelten. Heutzutage gehen verbesserte Transformer (denken Sie an GPT-4 und seine Cousins) noch weiter und bewältigen Aufgaben jenseits der Übersetzung.
2. Unter der Haube: Multi-Head Attention und Positional Encodings
Multi-Head Attention
Innerhalb der Self-Attention des Transformers befinden sich diese magischen Bestien namens Multi-Head Attention-Module. Sie lassen das Netzwerk verschiedene Arten von Beziehungen parallel lernen. Stellen Sie es sich vor wie den Einsatz mehrerer Scheinwerfer, um verschiedene Teile Ihrer Daten gleichzeitig zu beleuchten. Ein Attention-Head könnte Langstreckenabhängigkeiten verfolgen (wie Pronomen-Nomen-Referenzen), während ein anderer sich auf lokalen Kontext konzentriert (wie die Phrase "auf der Matte" um "Katze"). Durch die Kombination dieser spezialisierten Sub-Attentions kann der Transformer nuancierte Bedeutungen besser kodieren.
[caption id="" align="alignnone" width="1220"]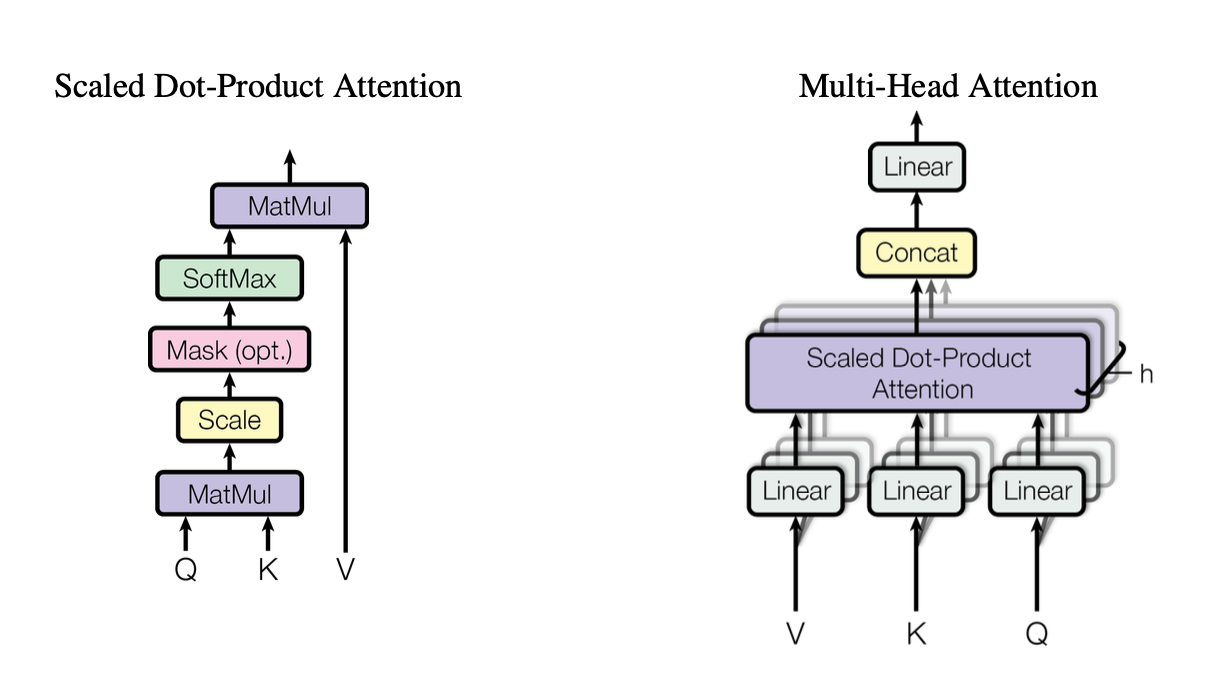 Abbildung 2: Darstellung des skalierten Dot-Product Attention-Mechanismus zeigt, wie Query (Q), Key (K) und Value (V) Vektoren interagieren. Quelle: Vaswani et al., "Attention Is All You Need" (2017). Bild reproduziert für Bildungszwecke unter Fair Use. [/caption]
Abbildung 2: Darstellung des skalierten Dot-Product Attention-Mechanismus zeigt, wie Query (Q), Key (K) und Value (V) Vektoren interagieren. Quelle: Vaswani et al., "Attention Is All You Need" (2017). Bild reproduziert für Bildungszwecke unter Fair Use. [/caption]
Diese Heads verwenden skalierte Dot-Product Attention als Standard-Baustein, den wir im Code so zusammenfassen können:
import torch import math
def scaled_dot_product_attention(Q, K, V): # Q, K, V sind [batch_size, heads, seq_len, d_k] d_k = Q.size(-1) scores = torch.matmul(Q, K.transpose(-2, -1)) / math.sqrt(d_k) weights = torch.softmax(scores, dim=-1) return torch.matmul(weights, V)
Jeder Head arbeitet mit unterschiedlich projizierten Versionen von Queries (Q), Keys (K) und Values (V) und führt dann die Ergebnisse zusammen. Dieses parallelisierbare Design ist der Schlüssel zur Effizienz des Transformers.
Positional Encodings
Keine Rekurrenzen? Das wirft die Frage auf: Wie behält das Modell die Wortreihenfolge im Auge? Hier kommen Positional Encodings ins Spiel—ein sinusoidales oder gelerntes Muster, das zu jedem Token-Embedding hinzugefügt wird und dem Transformer hilft, ein Gefühl für die Sequenz zu behalten. Es ist wie jedem Wort einen einzigartigen Zeitstempel zu geben.
3. Schneller Leistungsvergleich
-
RNNs/LSTMs: Großartig für Sequenzaufgaben, aber langsam für lange Sequenzen aufgrund der schrittweisen Verarbeitung.
-
CNNs (z.B. ConvS2S): Schneller als RNNs, aber immer noch nicht vollständig parallel für Langstreckenabhängigkeiten.
-
Transformer:
Höherer Durchsatz: Können ganze Sequenzen parallel verarbeiten, was das Training erheblich beschleunigt.
-
Bessere Ergebnisse: Transformer erzielten state-of-the-art Scores bei Aufgaben wie Maschinenübersetzung (28.4 BLEU auf WMT14 EN-DE) mit weniger Trainingszeit.
-
Skalierbar: Werfen Sie mehr GPUs auf die Daten und beobachten Sie, wie sie nahezu linear skalieren (innerhalb der Hardware- und Speichergrenzen).
4. Die Komplexitätsüberlegung: O(n²) und warum es wichtig ist
Während Transformer das Training durch Parallelisierung beschleunigen, bringt Self-Attention eine O(n²)-Komplexität bezüglich der Sequenzlänge n mit sich. Mit anderen Worten, jeder Token beachtet jeden anderen Token, was bei extrem langen Sequenzen teuer werden kann. Forscher erforschen aktiv effizientere Attention-Mechanismen (wie spärliche oder blockweise Attention), um diese Kosten zu mindern.
Dennoch überwiegen bei typischen NLP-Aufgaben, wo Token-Zählungen in den Tausenden statt Millionen liegen, oft die Vorteile der parallelen Berechnung diesen O(n²)-Overhead—besonders wenn Sie die richtige Hardware haben.
5. Warum es für Large Language Models (LLMs) wichtig ist
Moderne LLMs—wie GPT, BERT und T5—führen ihre Abstammung direkt auf den Transformer zurück. Das liegt daran, dass der Fokus des ursprünglichen Papers auf Parallelismus, Self-Attention und flexible Kontextfenster es ideal für Aufgaben jenseits der Übersetzung machte, einschließlich:
-
Textgenerierung & Zusammenfassung
-
Frage-Antwort-Systeme
-
Code-Vervollständigung
-
Mehrsprachige Chatbots
-
Und ja, Ihr neuer AI-Schreibassistent scheint immer einen Wortwitz im Ärmel zu haben.
Kurz gesagt, "Attention Is All You Need" ebnete den Weg für diese großen Modelle, die Milliarden von Token aufnehmen und fast jede NLP-Aufgabe bewältigen, die Sie ihnen vorwerfen.
6. Wir werden mehr Computing brauchen: Wo Introls Deployments ins Spiel kommen
Hier ist der Haken: Transformer sind hungrig—sehr hungrig. Das Training eines Large Language Models kann bedeuten, dass Computing-Ressourcen gabelstaplerweise verschlungen werden. Um all diese Parallelisierung zu nutzen, brauchen Sie robuste GPU-Deployments—manchmal in den Tausenden (oder Zehntausenden). Hier kommt High-Performance Computing (HPC)-Infrastruktur ins Spiel.
Bei Introl haben wir aus erster Hand gesehen, wie massiv diese Systeme werden können. Wir haben an Builds gearbeitet, die über 100.000 GPUs in knappen Zeitrahmen umfassten—das nennt man logistische Meisterleistung. Unser täglich Brot ist das Deployment von GPU-Servern, Racks und fortgeschrittenen Power/Cooling-Setups, damit alles effizient summt. Wenn Sie gleichzeitig ein Transformer-basiertes Modell auf Tausenden von Knoten trainieren, ist jeder Hardware-Engpass ein Energiestrudel für Zeit und Geld.
-
Großflächige GPU-Cluster: Wir haben Deployments ausgeführt, die über 100K GPUs hinausgingen, was bedeutet, dass wir die Feinheiten von Rack-and-Stack-Konfigurationen, Verkabelung und Power/Cooling-Strategien verstehen, um alles stabil zu halten.
-
Schnelle Mobilisierung: Müssen Sie weitere 2.000 GPU-Knoten in ein paar Tagen hinzufügen? Unsere spezialisierten Teams können vor Ort und betriebsbereit innerhalb von 72 Stunden sein.
-
End-to-End Support: Von Firmware-Updates und iDRAC-Konfigurationen bis hin zu laufender Wartung und Leistungsprüfungen verwalten wir die Logistik, damit sich Ihre Data Scientists auf Innovation konzentrieren können.
7. Blick nach vorn: Größere Modelle, größere Träume
"Attention Is All You Need" ist nicht nur ein Meilenstein—es ist der Blueprint für zukünftige Erweiterungen. Forscher erkunden bereits Transformer mit längerem Kontext, effiziente Attention-Mechanismen und fortgeschrittene Sparsity zur Behandlung enormer Corpora (denken Sie: ganze Bibliotheken, nicht nur Ihre örtliche Buchhandlung). Seien Sie versichert, der Appetit auf GPU-beschleunigte Berechnung wird nur zunehmen.
Und das ist die Schönheit der Transformer-Ära. Wir haben ein Modell, das elegant skalieren kann, vorausgesetzt, wir passen es mit der richtigen Hardware-Strategie zusammen. Ob Sie also das nächste generative AI-Phänomen bauen oder die Grenzen der universellen Übersetzung verschieben, einen Infrastruktur-Partner zu haben, der in massiven GPU-Deployments versiert ist, ist mehr als nur nice-to-have; es ist praktisch Ihr Wettbewerbsvorteil.
Abschließender Gedanke: Transformieren Sie Ihr AI-Spiel
Das Paper Attention Is All You Need war mehr als ein cleverer Titel—es war ein seismischer Wandel. Transformer haben alles von Maschinenübersetzung bis Code-Generierung und darüber hinaus transformiert. Wenn Sie diese Macht im großen Maßstab nutzen wollen, ist der Schlüssel, brillante Architektur mit ebenso brillanter Infrastruktur zu verbinden.
Bereit zum Hochskalieren? Finden Sie heraus, wie Introls spezialisierte GPU Infrastructure Deployments Ihr nächstes großes Transformer-Projekt beschleunigen können—denn die richtige Hardware kann den entscheidenden Unterschied in der AI machen.
Die Visualisierungen in diesem Artikel stammen aus dem ursprünglichen "Attention Is All You Need" Paper (Vaswani et al., 2017) und sind mit Quellenangabe unter Fair Use für Bildungszwecke enthalten. Das Paper ist verfügbar unter https://arxiv.org/abs/1706.03762 für Leser, die an der vollständigen Forschung interessiert sind.


