

คุณรู้สึกเหมือนได้ยินเสียงหึ่งของ GPU ทุกครั้งที่มีคนพูดถึง "large language models" หรือไม่? มีเหตุผลที่ทำให้เกิดเสียงหึ่งระดับจักรวาลนั้น: Transformer architectures และหากเราย้อนกลับไปหาจุดเริ่มต้น Big Bang ของปรากฏการณ์นี้ เราจะมาถึงงานวิจัยตำนานจากปี 2017 ของทีมงาน Google Brain และ Google Research engineers: Attention Is All You Need
ผิวเผินแล้วประโยคนี้อาจฟังดูเหมือนการเตือนใจให้มี mindfulness แต่มันกลับประกาศการปฏิวัติใน natural language processing (NLP) และอื่นๆ โมเดล Transformer ได้พลิกโฉมสถานการณ์ AI ในเพียงครั้งเดียว: ไม่ต้องใช้ RNNs, LSTMs และ convolution-based sequence models ที่เดินทางทีละนิดทีละหน่อยอีกต่อไป แต่เราได้ระบบที่ parallelizable และขับเคลื่อนด้วย attention ที่เทรนได้เร็วกว่า scale ได้ใหญ่กว่า และที่สำคัญคือ—ได้ผลลัพธ์ที่ดีกว่า
1. แนวคิดใหญ่: All Hail Self-Attention
ก่อนที่ Transformers จะปรากฏตัวขึ้นมา มาตรฐานทองคำสำหรับ sequence transduction (เช่น การแปลภาษา การสรุป ฯลฯ) เกี่ยวข้องกับ recurrent neural networks ที่มี gating mechanisms ที่ออกแบบอย่างพิถีพิถัน หรือ convolutional neural networks ที่มีการ stacking ซับซ้อนเพื่อจัดการกับ long-range dependencies มีประสิทธิภาพหรือไม่? ใช่ ช้าหรือไม่? เช่นกัน—โดยเฉพาะเมื่อคุณต้องวิเคราะห์ datasets ที่ใหญ่มากจริงๆ
อธิบายให้ง่าย self-attention เป็นกลไกที่ทุก token ในลำดับ (เช่น คำหรือ subword) สามารถ "มอง" ไปที่ token อื่นๆ ทุกตัวพร้อมกัน เพื่อค้นหาความสัมพันธ์เชิงบริบทโดยไม่ถูกบังคับให้คลานผ่านข้อมูลทีละขั้นตอน วิธีนี้ตรงข้ามกับโมเดลเก่าๆ เช่น RNNs และ LSTMs ที่ต้องประมวลผลลำดับส่วนใหญ่แบบ sequential
Transformers ทำให้สามารถ parallelization ได้มากกว่าโดยการทิ้ง recurrence (และ overhead ที่มาพร้อมกับมัน) คุณสามารถใช้ GPU จำนวนมากมายกับปัญหา เทรนบน datasets ขนาดใหญ่ และเห็นผลลัพธ์ในหลายวันแทนที่จะเป็นหลายสัปดาห์
[caption id="" align="alignnone" width="847"]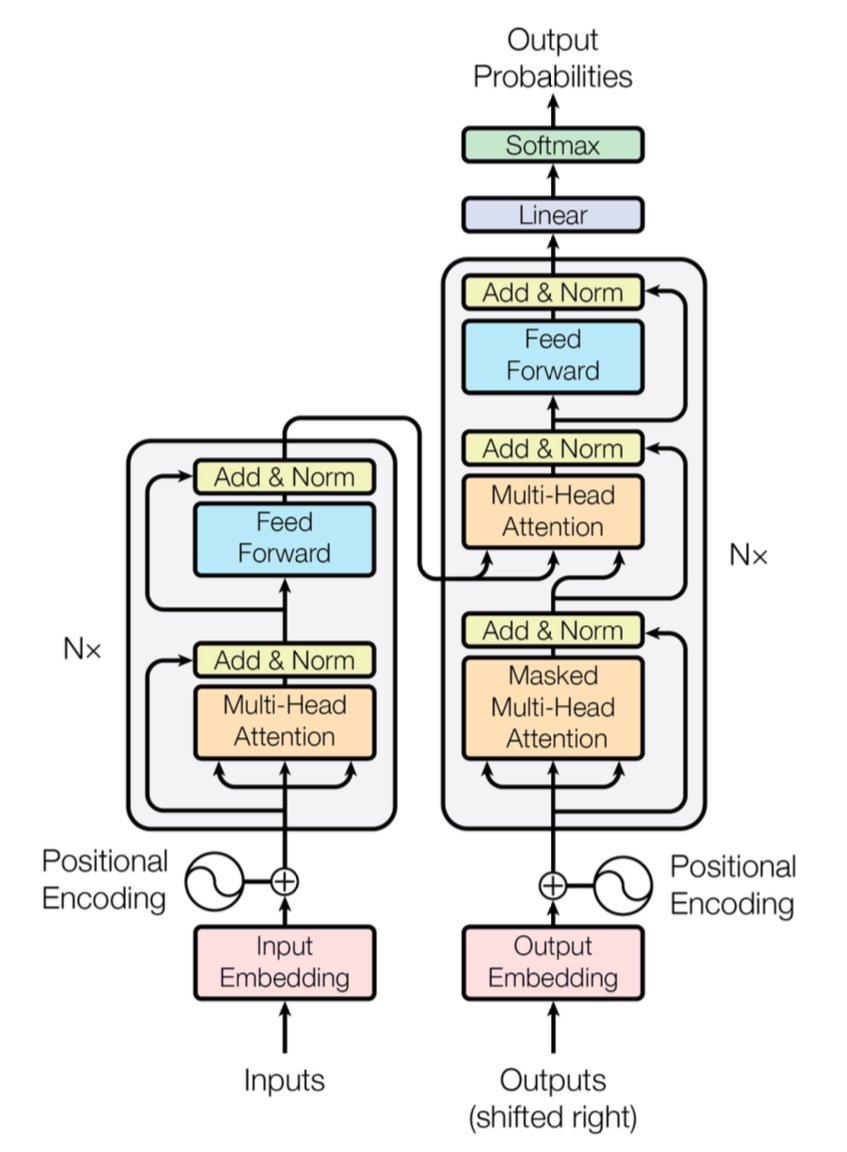 Figure 1: The complete Transformer architecture showing encoder (left) and decoder (right) with multi-head attention layers. Source: Vaswani et al., "Attention Is All You Need" (2017). Image reproduced for educational purposes under fair use. [/caption]
Figure 1: The complete Transformer architecture showing encoder (left) and decoder (right) with multi-head attention layers. Source: Vaswani et al., "Attention Is All You Need" (2017). Image reproduced for educational purposes under fair use. [/caption]
Quick Performance Note: Transformer ตัวแรกแสดงคะแนน BLEU 28.4 ในงาน WMT 2014 English-to-German—ก้าวกระโดดที่แข็งแกร่งจาก neural machine translation architectures ก่อนหน้าเช่น CNN-based และ RNN-based models ที่วนเวียนอยู่ที่ 25–26 BLEU ที่ดีที่สุด ปัจจุบัน Transformers ที่ปรับปรุงแล้ว (เช่น GPT-4 และพวกพ้อง) ไปได้ไกลกว่านั้น โดยจัดการงานเกินกว่าการแปล
2. ใต้ฝากระโปรง: Multi-Head Attention และ Positional Encodings
Multi-Head Attention
ภายใน self-attention ของ Transformer มีสัตว์วิเศษเรียกว่า multi-head attention modules พวกมันให้เครือข่ายเรียนรู้ความสัมพันธ์ประเภทต่างๆ แบบ parallel คิดว่าเป็นการใช้สปอตไลท์หลายตัวเพื่อส่องส่วนต่างๆ ของข้อมูลพร้อมกัน attention head หนึ่งอาจติดตาม long-distance dependencies (เช่น การอ้างอิง pronoun-noun) ในขณะที่อีกตัวโฟกัสที่ local context (เช่น วลี "on the mat" รอบๆ "cat") การรวม sub-attentions เฉพาะทางเหล่านี้ Transformer สามารถ encode ความหมายที่ละเอียดอ่อนได้ดีกว่า
[caption id="" align="alignnone" width="1220"]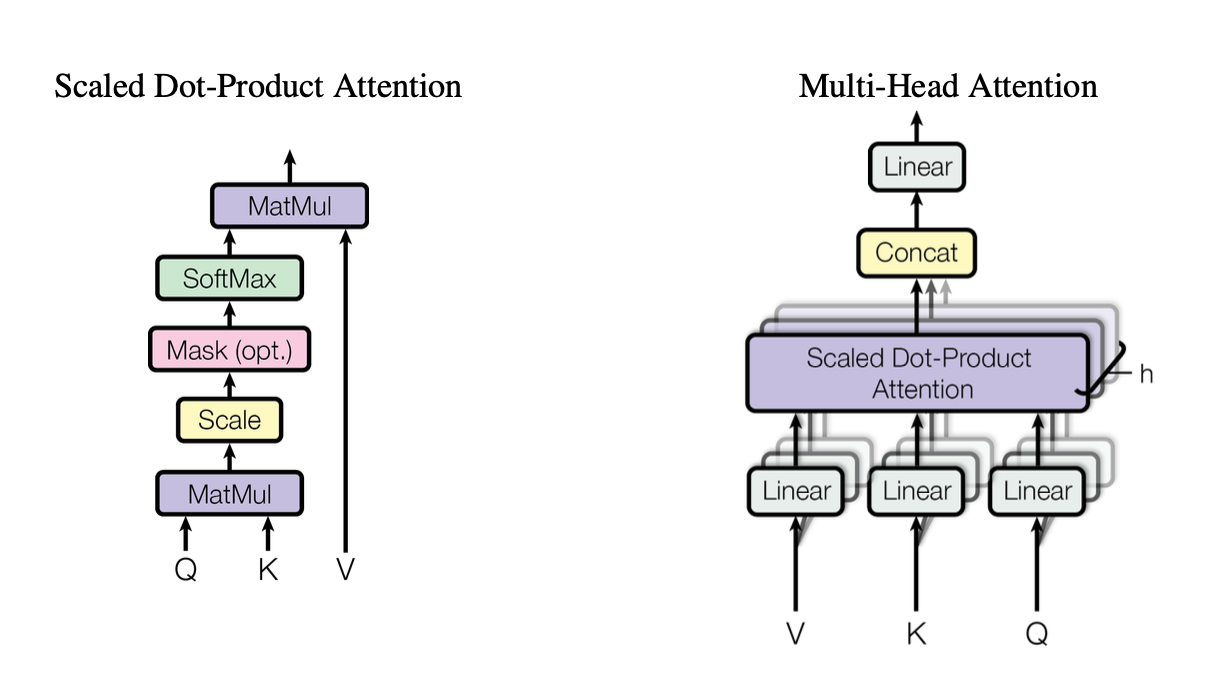 Figure 2: Illustration of the scaled dot-product attention mechanism showing how Query (Q), Key (K), and Value (V) vectors interact. Source: Vaswani et al., "Attention Is All You Need" (2017). Image reproduced for educational purposes under fair use. [/caption]
Figure 2: Illustration of the scaled dot-product attention mechanism showing how Query (Q), Key (K), and Value (V) vectors interact. Source: Vaswani et al., "Attention Is All You Need" (2017). Image reproduced for educational purposes under fair use. [/caption]
heads เหล่านี้ใช้ scaled dot-product attention เป็น building block มาตรฐาน ซึ่งเราสามารถสรุปในโค้ดเป็น:
import torchimport math def scaled_dot_product_attention(Q, K, V): # Q, K, V are [batch_size, heads, seq_len, d_k] d_k = Q.size(-1) scores = torch.matmul(Q, K.transpose(-2, -1)) / math.sqrt(d_k) weights = torch.softmax(scores, dim=-1) return torch.matmul(weights, V)
แต่ละ head ทำงานกับ queries (Q), keys (K) และ values (V) ที่ projected แตกต่างกัน จากนั้นรวมผลลัพธ์ การออกแบบที่ parallelizable นี้เป็นกุญแจสู่ประสิทธิภาพของ Transformer
Positional Encodings
ไม่มี recurrences? นั่นทำให้เกิดคำถาม: โมเดลติดตามลำดับคำได้อย่างไร? เข้าสู่ positional encodings—รูปแบบ sinusoidal หรือ learned pattern ที่เพิ่มเข้าไปใน embedding ของแต่ละ token ช่วยให้ Transformer รักษาความรู้สึกของลำดับ เหมือนการให้ timestamp เฉพาะแก่แต่ละคำ
3. การเปรียบเทียบประสิทธิภาพอย่างรวดเร็ว
-
RNNs/LSTMs: เหมาะสำหรับ sequence tasks แต่ช้าสำหรับลำดับยาวเนื่องจากการประมวลผลทีละขั้นตอน
-
CNNs (เช่น ConvS2S): เร็วกว่า RNNs แต่ยังไม่ parallel อย่างเต็มที่สำหรับ long-range dependencies
-
Transformers:
Higher Throughput: สามารถประมวลผลลำดับทั้งหมดแบบ parallel ทำให้การเทรนเร็วกว่าอย่างมาก
-
ผลลัพธ์ดีกว่า: Transformers ทำคะแนน state-of-the-art ในงานเช่น machine translation (28.4 BLEU บน WMT14 EN-DE) ด้วยเวลาเทรนน้อยกว่า
-
Scalable: โยน GPU เพิ่มเติมใส่ข้อมูลและดู scale เกือบ linear (ภายในขีดจำกัดของ hardware และ memory)
4. ข้อพิจารณาความซับซ้อน: O(n²) และเหตุผลที่สำคัญ
ในขณะที่ Transformers เร่งการเทรนผ่าน parallelization แต่ self-attention มี O(n²) complexity เกี่ยวกับความยาวลำดับ n กล่าวอีกนัยหนึ่ง ทุก token attend กับ token อื่นๆ ทุกตัว ซึ่งอาจมีค่าใช้จ่ายสูงสำหรับลำดับที่ยาวมาก นักวิจัยกำลังสำรวจกลไก attention ที่มีประสิทธิภาพมากขึ้น (เช่น sparse หรือ block-wise attention) เพื่อลดค่าใช้จ่ายนี้
ถึงกระนั้น สำหรับงาน NLP ทั่วไปที่มีจำนวน token อยู่ในระดับพันแทนที่จะเป็นล้าน overhead O(n²) นี้มักถูกชดเชยด้วยประโยชน์ของ parallel computation—โดยเฉพาะถ้าคุณมี hardware ที่เหมาะสม
5. เหตุผลที่สำคัญสำหรับ Large Language Models (LLMs)
LLMs สมัยใหม่—เช่น GPT, BERT และ T5—สืบทอดเชื้อสายมาจาก Transformer โดยตรง เพราะการโฟกัสของงานวิจัยต้นฉบับใน parallelism, self-attention และ flexible context windows ทำให้เหมาะอย่างยิ่งสำหรับงานเกินกว่าการแปล รวมถึง:
-
Text Generation & Summarization
-
Question-Answering
-
Code Completion
-
Multi-lingual Chatbots
-
และใช่ AI writing assistant ใหม่ของคุณดูเหมือนจะมี pun อยู่ในแขนเสมอ
สั้นๆ คือ "Attention Is All You Need" ปูทางสำหรับโมเดลใหญ่เหล่านี้ที่รับประทาน tokens หลายพันล้านตัวและจัดการกับงาน NLP เกือบทุกอย่างที่คุณโยนมาให้
6. เราต้องการ compute มากกว่านี้: ที่ซึ่ง Deployments ของ Introl เข้ามา
นี่คือข้อติด: Transformers หิวโหย—หิวโหยมาก การเทรน large language model อาจหมายถึงการดูดดูดทรัพยากรคอมพิวติ้งด้วยรถยก เพื่อใช้ประโยชน์จาก parallelism ทั้งหมดนั้น คุณต้องการ GPU deployments ที่แข็งแกร่ง—บางครั้งเป็นพันหรือหมื่นตัว นั่นคือจุดที่ high-performance computing (HPC) infrastructure เข้ามา
ที่ Introl เราได้เห็นโดยตรงว่าระบบเหล่านี้ใหญ่แค่ไหน เราทำงานในโครงการที่เกี่ยวข้องกับ GPU กว่า 100,000 ตัวในระยะเวลาสั้น—พูดถึงความเชี่ยวชาญด้านโลจิสติกส์ ขนมปังและเนยของเราคือการ deploy GPU servers, racks และการติดตั้ง power/cooling ขั้นสูงเพื่อให้ทุกอย่างทำงานอย่างมีประสิทธิภาพ เมื่อคุณเทรน Transformer-based model พร้อมกันบน nodes หลายพัน bottleneck ด้าน hardware ใดๆ คือ energy vortex สำหรับทั้งเวลาและเงิน
-
Large-Scale GPU Clusters: เราได้ปฏิบัติ deployments ที่ผลักดันเกิน 100K GPUs หมายความว่าเราเข้าใจความซับซ้อนของ rack-and-stack configurations, cabling และกลยุทธ์ power/cooling เพื่อให้ทุกอย่างเสถียร
-
Rapid Mobilization: ต้องการเพิ่ม GPU nodes อีก 2,000 ตัวในไม่กี่วัน? ทีมเฉพาะของเราสามารถไปที่ location และทำงานได้ภายใน 72 ชั่วโมง
-
End-to-End Support: ตั้งแต่ firmware updates และ iDRAC configurations ไปจนถึง ongoing maintenance และ performance checks เราจัดการโลจิสติกส์เพื่อให้ data scientists ของคุณสามารถโฟกัสที่นวัตกรรม
7. มองไปข้างหน้า: โมเดลใหญ่กว่า ความฝันใหญ่กว่า
"Attention Is All You Need" ไม่ใช่แค่ milestone—มันเป็น blueprint สำหรับการขยายตัวในอนาคต นักวิจัยกำลังสำรวจ longer-context Transformers, efficient attention mechanisms และ advanced sparsity เพื่อจัดการกับ corpora ขนาดใหญ่ (คิด: ห้องสมุดทั้งหมด ไม่ใช่แค่ร้านหนังสือในละแวกบ้าน) มั่นใจได้ว่าความอยากสำหรับ GPU-accelerated computing จะเพิ่มขึ้นเท่านั้น
และนั่นคือความงามของยุค Transformer เรามีโมเดลที่สามารถ scale อย่างงดงาม ให้เราจับคู่กับกลยุทธ์ hardware ที่เหมาะสม ดังนั้นไม่ว่าคุณจะสร้าง generative AI phenomenon ตัวต่อไปหรือผลักดันขอบเขตของ universal translation การมี infrastructure partner ที่เชี่ยวชาญใน massive GPU deployments เป็นมากกว่าแค่ nice-to-have มันเป็น competitive edge ของคุณจริงๆ
Final Thought: Transform Your AI Game
งานวิจัย Attention Is All You Need เป็นมากกว่าแค่ชื่อเรื่องฉลาด—มันเป็นการเปลี่ยนแปลงครั้งใหญ่ Transformers ได้เปลี่ยนทุกอย่างตั้งแต่ machine translation ไปจนถึง code generation และอื่นๆ หากคุณต้องการใช้พลังนั้นในระดับใหญ่ กุญแจคือการจับคู่ architecture ที่ยอดเยี่ยมกับ infrastructure ที่ยอดเยี่ยมเท่าๆ กัน
พร้อมที่จะ scale up หรือยัง? ค้นหาว่า GPU Infrastructure Deployments เฉพาะทางของ Introl สามารถเร่งโครงการ Transformer ครั้งใหญ่ต่อไปของคุณได้อย่างไร—เพราะ hardware ที่เหมาะสมสามารถสร้างความแตกต่างทั้งหมดใน AI
ภาพประกอบในบทความนี้มาจากงานวิจัยต้นฉบับ "Attention Is All You Need" (Vaswani et al., 2017) และถูกรวมไว้พร้อมการระบุแหล่งที่มาภายใต้ fair use สำหรับวัตถุประสงค์เชิงการศึกษา งานวิจัยมีให้ที่ https://arxiv.org/abs/1706.03762 สำหรับผู้อ่านที่สนใจงานวิจัยฉบับสมบูรณ์


