

Apakah Anda merasa bisa mendengar dengungan GPU setiap kali seseorang menyebut "large language models?" Ada alasan untuk buzz tingkat kosmik ini: arsitektur Transformer. Dan jika kita menelusuri fenomena tersebut kembali ke momen Big Bang-nya, kita akan mendarat tepat pada paper legendaris 2017 dari sekelompok insinyur Google Brain dan Google Research: Attention Is All You Need.
Pada pandangan pertama, frase tersebut mungkin terdengar seperti dorongan lembut menuju mindfulness, tetapi ini menandakan revolusi dalam natural language processing (NLP) dan seterusnya. Model Transformer mengubah status quo AI dalam satu gerakan cepat: tidak ada lagi kemajuan inci demi inci dari RNN, LSTM, dan model sequence berbasis convolutional. Sebaliknya, kita mendapatkan sistem yang dapat diparalelkan, didorong oleh attention yang melatih lebih cepat, menskalakan lebih besar, dan—inilah intinya—mencapai hasil yang lebih baik.
1. Ide Besar: Hidup Self-Attention
Sebelum Transformer muncul ke panggung, standar emas untuk sequence transduction (pikirkan terjemahan bahasa, summarization, dll.) melibatkan recurrent neural networks dengan mekanisme gating yang direkayasa dengan hati-hati atau convolutional neural networks dengan stacking rumit untuk menangani long-range dependencies. Efektif? Ya. Lambat? Juga ya—terutama ketika Anda perlu menganalisis dataset yang benar-benar masif.
Dalam istilah paling sederhana, self-attention adalah mekanisme di mana setiap token dalam sequence (misalnya, kata atau subword) dapat "melihat" setiap token lain secara bersamaan, menemukan hubungan kontekstual tanpa dipaksa merangkak langkah demi langkah melalui data. Pendekatan ini kontras dengan model lama, seperti RNN dan LSTM, yang harus memproses sequence sebagian besar secara berurutan.
Transformer memungkinkan paralelisasi yang jauh lebih banyak dengan membuang recurrence (dan overhead yang menyertainya). Anda dapat melemparkan banyak GPU pada masalah, melatih pada dataset masif, dan melihat hasil dalam hitungan hari alih-alih minggu.
[caption id="" align="alignnone" width="847"]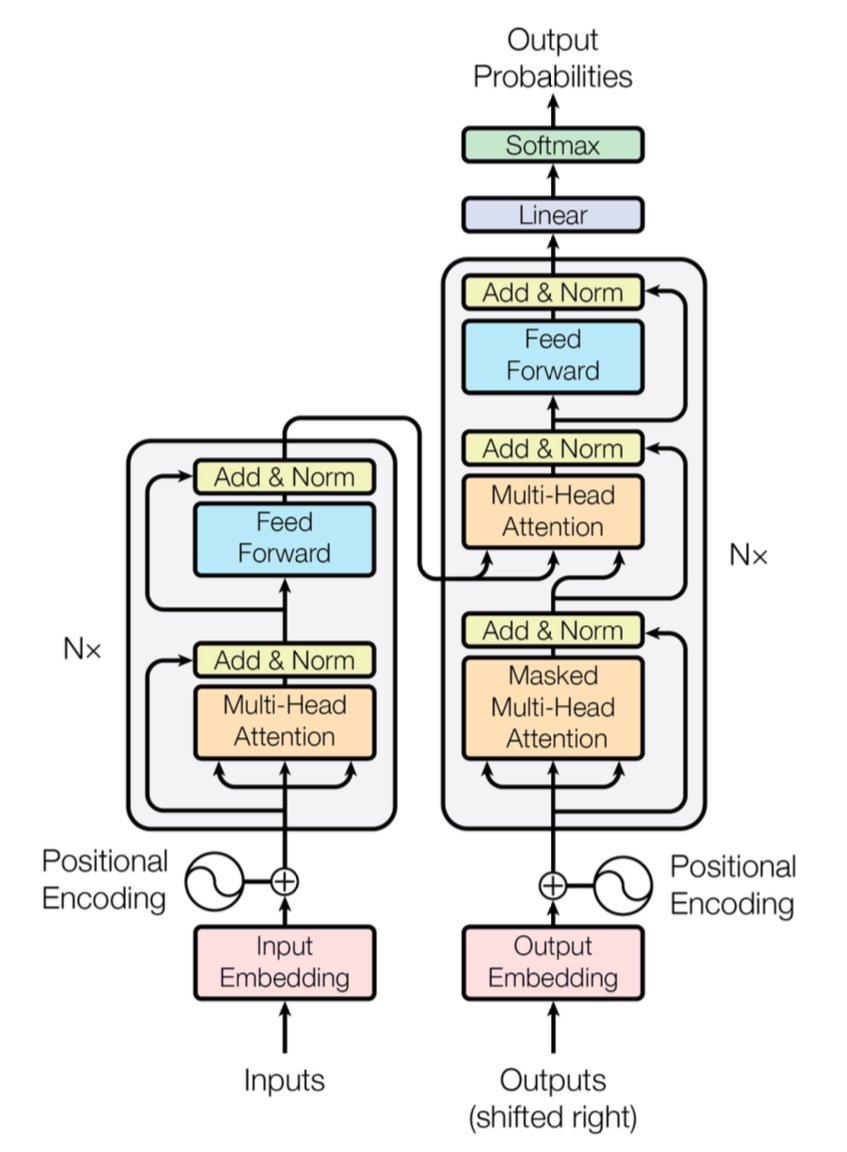 Figure 1: Arsitektur Transformer lengkap menunjukkan encoder (kiri) dan decoder (kanan) dengan layer multi-head attention. Sumber: Vaswani et al., "Attention Is All You Need" (2017). Gambar direproduksi untuk tujuan edukasi di bawah fair use. [/caption]
Figure 1: Arsitektur Transformer lengkap menunjukkan encoder (kiri) dan decoder (kanan) dengan layer multi-head attention. Sumber: Vaswani et al., "Attention Is All You Need" (2017). Gambar direproduksi untuk tujuan edukasi di bawah fair use. [/caption]
Catatan Performa Cepat: Transformer asli mendemonstrasikan skor BLEU 28.4 pada tugas WMT 2014 English-to-German—lompatan solid dibandingkan arsitektur neural machine translation sebelumnya seperti model berbasis CNN dan RNN, yang melayang sekitar 25–26 BLEU paling baik. Hari-hari ini, Transformer yang ditingkatkan (pikirkan GPT-4 dan sepupunya) melangkah lebih jauh, menangani tugas melampaui terjemahan.
2. Di Balik Layar: Multi-Head Attention dan Positional Encodings
Multi-Head Attention
Dalam self-attention Transformer terdapat makhluk ajaib yang disebut modul multi-head attention. Mereka memungkinkan network mempelajari berbagai jenis hubungan secara paralel. Pikirkan ini sebagai menggunakan beberapa sorotan untuk menerangi berbagai bagian data Anda secara bersamaan. Satu attention head mungkin melacak long-distance dependencies (seperti referensi pronoun-noun), sementara yang lain fokus pada konteks lokal (seperti frasa "on the mat" di sekitar "cat"). Menggabungkan sub-attention khusus ini, Transformer dapat mengkode makna yang lebih bernuansa dengan lebih baik.
[caption id="" align="alignnone" width="1220"]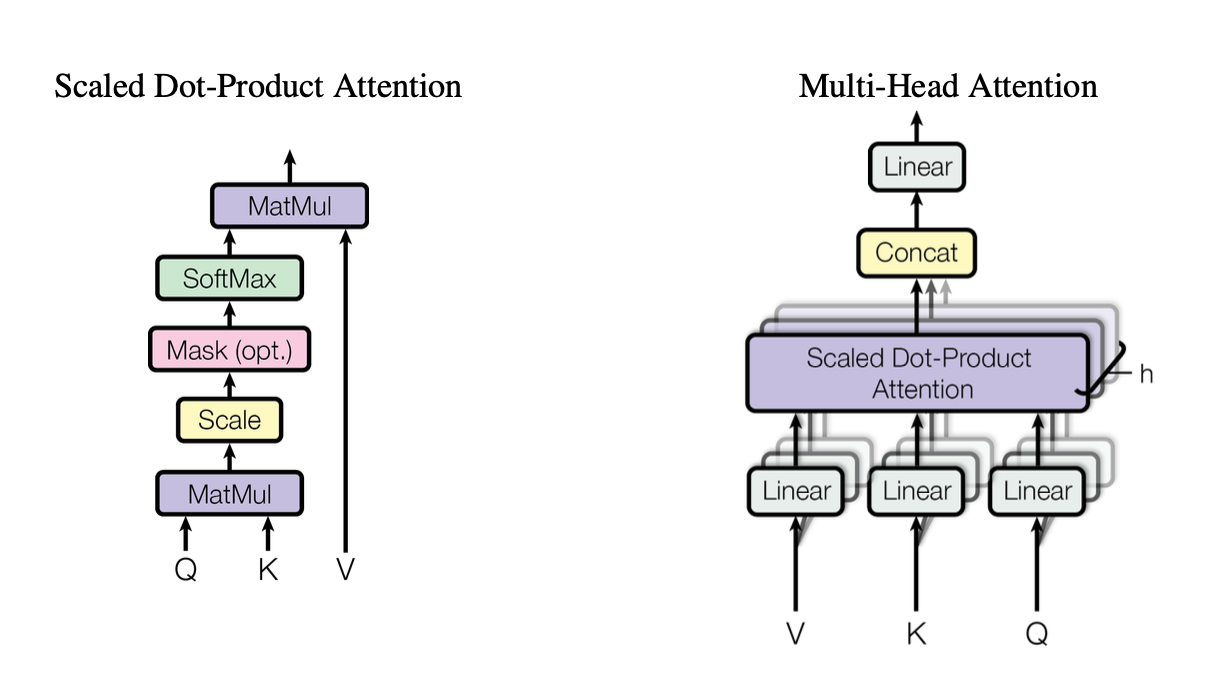 Figure 2: Ilustrasi mekanisme scaled dot-product attention menunjukkan bagaimana vektor Query (Q), Key (K), dan Value (V) berinteraksi. Sumber: Vaswani et al., "Attention Is All You Need" (2017). Gambar direproduksi untuk tujuan edukasi di bawah fair use. [/caption]
Figure 2: Ilustrasi mekanisme scaled dot-product attention menunjukkan bagaimana vektor Query (Q), Key (K), dan Value (V) berinteraksi. Sumber: Vaswani et al., "Attention Is All You Need" (2017). Gambar direproduksi untuk tujuan edukasi di bawah fair use. [/caption]
Head-head ini menggunakan scaled dot-product attention sebagai blok bangunan standar, yang dapat kita ringkas dalam kode sebagai:
import torchimport math def scaled_dot_product_attention(Q, K, V): # Q, K, V adalah [batch_size, heads, seq_len, d_k] d_k = Q.size(-1) scores = torch.matmul(Q, K.transpose(-2, -1)) / math.sqrt(d_k) weights = torch.softmax(scores, dim=-1) return torch.matmul(weights, V)
Setiap head beroperasi pada versi yang diproyeksikan secara berbeda dari queries (Q), keys (K), dan values (V), kemudian menggabungkan hasilnya. Desain yang dapat diparalelkan ini adalah kunci efisiensi Transformer.
Positional Encodings
Tidak ada recurrence? Itu memunculkan pertanyaan: Bagaimana model melacak urutan kata? Masuk positional encodings—pola sinusoidal atau yang dipelajari ditambahkan ke embedding setiap token, membantu Transformer mempertahankan rasa sequence. Ini seperti memberi setiap kata timestamp unik.
3. Perbandingan Performa Cepat
-
RNN/LSTM: Bagus untuk tugas sequence tetapi lambat untuk sequence panjang karena pemrosesan langkah demi langkah.
-
CNN (misalnya, ConvS2S): Lebih cepat dari RNN tetapi masih tidak sepenuhnya paralel untuk long-range dependencies.
-
Transformer:
Throughput Lebih Tinggi: Dapat memproses seluruh sequence secara paralel, membuat training jauh lebih cepat.
-
Hasil Lebih Baik: Transformer mencapai skor state-of-the-art dalam tugas seperti machine translation (28.4 BLEU pada WMT14 EN-DE) dengan waktu training lebih sedikit.
-
Scalable: Lemparkan lebih banyak GPU pada data dan lihat penskalaan hampir linear (dalam batas hardware dan memori).
4. Pertimbangan Kompleksitas: O(n²) dan Mengapa Penting
Meskipun Transformer mempercepat training melalui paralelisasi, self-attention membawa kompleksitas O(n²) terkait panjang sequence n. Dengan kata lain, setiap token memperhatikan setiap token lain, yang bisa mahal untuk sequence yang sangat panjang. Peneliti secara aktif mengeksplorasi mekanisme attention yang lebih efisien (seperti sparse atau block-wise attention) untuk mengurangi biaya ini.
Meski demikian, untuk tugas NLP tipikal di mana jumlah token dalam ribuan daripada jutaan, overhead O(n²) ini sering diimbangi oleh manfaat komputasi paralel—terutama jika Anda memiliki hardware yang tepat.
5. Mengapa Penting untuk Large Language Models (LLM)
LLM modern—seperti GPT, BERT, dan T5—menelusuri garis keturunan mereka langsung ke Transformer. Itu karena fokus paper asli pada paralelisme, self-attention, dan context windows fleksibel membuatnya sangat cocok untuk tugas melampaui terjemahan, termasuk:
-
Text Generation & Summarization
-
Question-Answering
-
Code Completion
-
Multi-lingual Chatbots
-
Dan ya, asisten menulis AI baru Anda sepertinya selalu memiliki permainan kata di lengan bajunya.
Singkatnya, "Attention Is All You Need" membuka jalan untuk model besar ini yang menelan miliaran token dan menangani hampir semua tugas NLP yang Anda lemparkan pada mereka.
6. Kita akan membutuhkan lebih banyak compute: Di Mana Deployment Introl Masuk
Ini masalahnya: Transformer haus—sangat haus. Melatih large language model dapat berarti menyedot sumber daya komputasi dalam muatan forklift. Untuk memanfaatkan semua paralelisme itu, Anda memerlukan deployment GPU yang kuat—kadang berjumlah ribuan (atau puluhan ribu). Di situlah infrastruktur high-performance computing (HPC) masuk.
Di Introl, kami telah melihat secara langsung seberapa besar sistem ini bisa menjadi. Kami telah bekerja pada build yang melibatkan lebih dari 100.000 GPU dalam timeline ketat—bicara tentang kehebatan logistik. Roti dan mentega kami adalah menggunakan server GPU, rack, dan setup power/cooling canggih sehingga semuanya beroperasi secara efisien. Ketika Anda secara bersamaan melatih model berbasis Transformer pada ribuan node, bottleneck hardware apa pun adalah pusaran energi untuk waktu dan uang.
-
Cluster GPU Skala Besar: Kami telah mengeksekusi deployment yang mendorong melampaui 100K GPU, berarti kami memahami seluk-beluk konfigurasi rack-and-stack, cabling, dan strategi power/cooling untuk menjaga semuanya stabil.
-
Mobilisasi Cepat: Perlu menambahkan 2.000 node GPU lagi dalam beberapa hari? Tim khusus kami dapat on-site dan operasional dalam 72 jam.
-
Dukungan End-to-End: Dari update firmware dan konfigurasi iDRAC hingga maintenance berkelanjutan dan pemeriksaan performa, kami mengelola logistik sehingga data scientist Anda dapat tetap fokus pada inovasi.
7. Melihat ke Depan: Model Lebih Besar, Impian Lebih Besar
"Attention Is All You Need" bukan hanya milestone—ini adalah blueprint untuk ekspansi masa depan. Peneliti sudah mengeksplorasi Transformer konteks-lebih-panjang, mekanisme attention efisien, dan sparsity canggih untuk menangani corpora besar (pikirkan: seluruh perpustakaan, bukan hanya toko buku lokal Anda). Yakinlah, nafsu makan untuk komputasi yang dipercepat GPU hanya akan meningkat.
Dan itulah keindahan era Transformer. Kita memiliki model yang dapat menskalakan dengan elegan, asalkan kita mencocokkannya dengan strategi hardware yang tepat. Jadi apakah Anda membangun fenomena generative AI berikutnya atau mendorong batas terjemahan universal, memiliki mitra infrastruktur yang mahir dalam deployment GPU masif lebih dari sekadar nice-to-have; itu praktis keunggulan kompetitif Anda.
Pemikiran Akhir: Transform Game AI Anda
Paper Attention Is All You Need lebih dari judul yang cerdas—itu adalah pergeseran seismik. Transformer telah mengubah segalanya dari machine translation hingga code generation dan seterusnya. Jika Anda ingin memanfaatkan kekuatan itu dalam skala besar, kuncinya adalah mencocokkan arsitektur brilian dengan infrastruktur yang sama brilliannya.
Siap untuk scale up? Cari tahu bagaimana GPU Infrastructure Deployments khusus Introl dapat mempercepat proyek Transformer besar berikutnya—karena hardware yang tepat dapat membuat semua perbedaan dalam AI.
Visualisasi dalam artikel ini berasal dari paper asli "Attention Is All You Need" (Vaswani et al., 2017) dan disertakan dengan atribusi di bawah fair use untuk tujuan edukasi. Paper tersebut tersedia di https://arxiv.org/abs/1706.03762 untuk pembaca yang tertarik dengan penelitian lengkap.


