

Чи відчуваєте ви, що практично можете почути гудіння GPU щоразу, коли хтось згадує "великі мовні моделі?" На це є причина такого космічного рівня гулу: архітектури Transformer. І якщо ми відстежуватимемо цей феномен до його моменту Великого вибуху, то потрапимо прямо на тепер уже легендарну статтю 2017 року від групи інженерів Google Brain та Google Research: Attention Is All You Need.
На перший погляд, ця фраза може звучати як м'який поштовх до усвідомленості, але вона знаменувала революцію в обробці природної мови (NLP) та за її межами. Модель Transformer перевернула статус-кво AI одним швидким ударом: більше ніяких повільних покрокових прогресій RNN, LSTM та конволюційних моделей послідовностей. Натомість ми отримали систему, що підлягає паралелізації, керовану увагою, яка тренується швидше, масштабується краще і—ось головний козир—досягає кращих результатів.
1. Велика ідея: Слава самоувазі
До того, як Transformer'и з'явилися на сцені, золотим стандартом для трансдукції послідовностей (подумайте про переклад мов, узагальнення тощо) були рекурентні нейронні мережі з ретельно розробленими механізмами воротування або конволюційні нейронні мережі зі складним укладанням для обробки далекосяжних залежностей. Ефективні? Так. Повільні? Також так—особливо коли потрібно аналізувати справді масивні набори даних.
Найпростіше кажучи, самоувага—це механізм, за допомогою якого кожен токен у послідовності (наприклад, слово або підслово) може "дивитися" на кожен інший токен одночасно, виявляючи контекстні зв'язки без необхідності повільно крокувати через дані крок за кроком. Цей підхід контрастує зі старшими моделями, такими як RNN та LSTM, які повинні були обробляти послідовність переважно послідовно.
Transformer'и забезпечують набагато більшу паралелізацію, відкидаючи рекурентність (та накладні витрати, що з нею пов'язані). Ви можете кинути зграю GPU на проблему, тренувати на масивних наборах даних і бачити результати за дні, а не тижні.
[caption id="" align="alignnone" width="847"]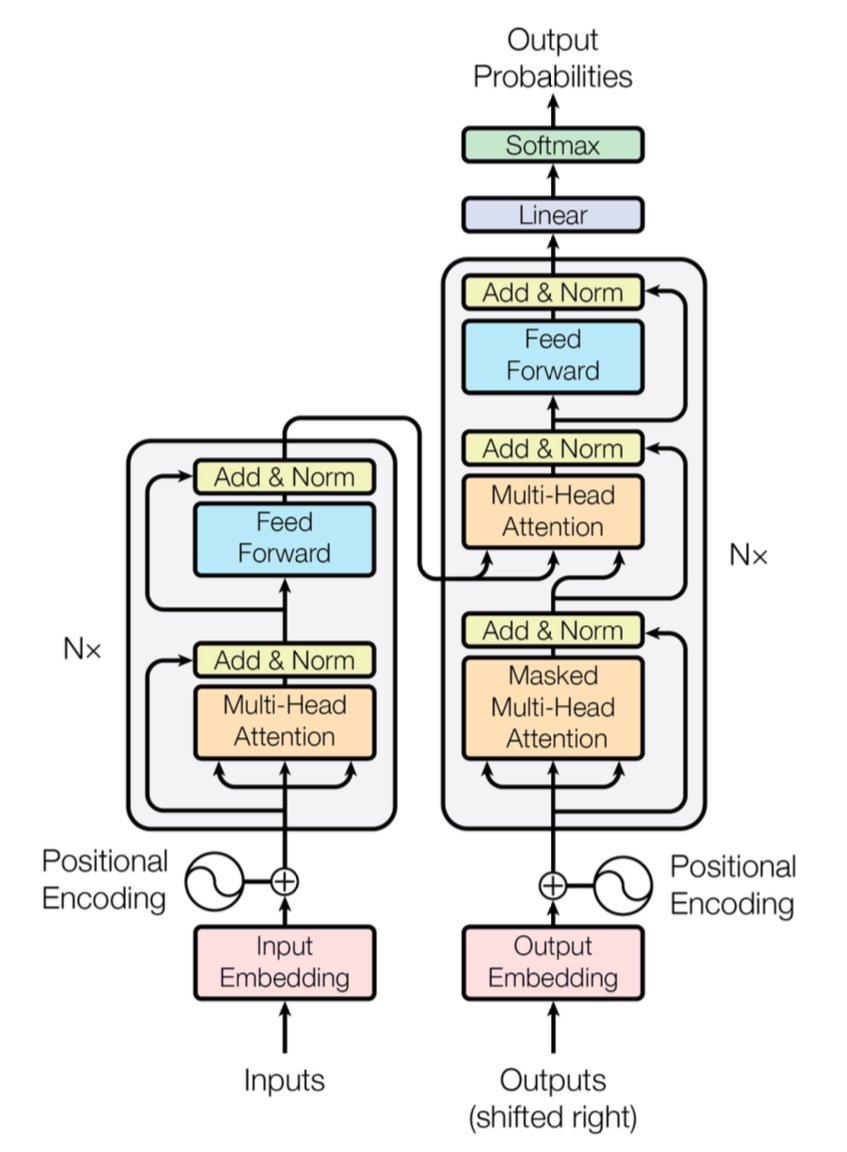 Рисунок 1: Повна архітектура Transformer, що показує кодувальник (ліворуч) і декодувальник (праворуч) з багатоголовими шарами уваги. Джерело: Vaswani et al., "Attention Is All You Need" (2017). Зображення відтворено в освітніх цілях згідно з принципами добросовісного використання. [/caption]
Рисунок 1: Повна архітектура Transformer, що показує кодувальник (ліворуч) і декодувальник (праворуч) з багатоголовими шарами уваги. Джерело: Vaswani et al., "Attention Is All You Need" (2017). Зображення відтворено в освітніх цілях згідно з принципами добросовісного використання. [/caption]
Коротка нотатка про продуктивність: Оригінальний Transformer продемонстрував оцінку BLEU 28.4 на завданні WMT 2014 English-to-German—солідний стрибок над попередніми архітектурами нейронного машинного перекладу, такими як моделі на основі CNN та RNN, які коливалися навколо 25–26 BLEU у кращому випадку. Сьогодні покращені Transformer'и (думайте про GPT-4 та його побратимів) йдуть ще далі, обробляючи завдання поза межами перекладу.
2. Під капотом: Багатоголова увага та позиційні кодування
Багатоголова увага
Всередині самоуваги Transformer'а є ці магічні звірі, які називаються модулями багатоголової уваги. Вони дозволяють мережі вивчати різні типи зв'язків паралельно. Подумайте про це як про розгортання кількох прожекторів для одночасного освітлення різних частин ваших даних. Одна голова уваги може відстежувати далекосяжні залежності (як посилання займенник-іменник), тоді як інша фокусується на локальному контексті (як фраза "на килимку" навколо "кіт"). Поєднуючи ці спеціалізовані під-уваги, Transformer може краще кодувати нюансований зміст.
[caption id="" align="alignnone" width="1220"]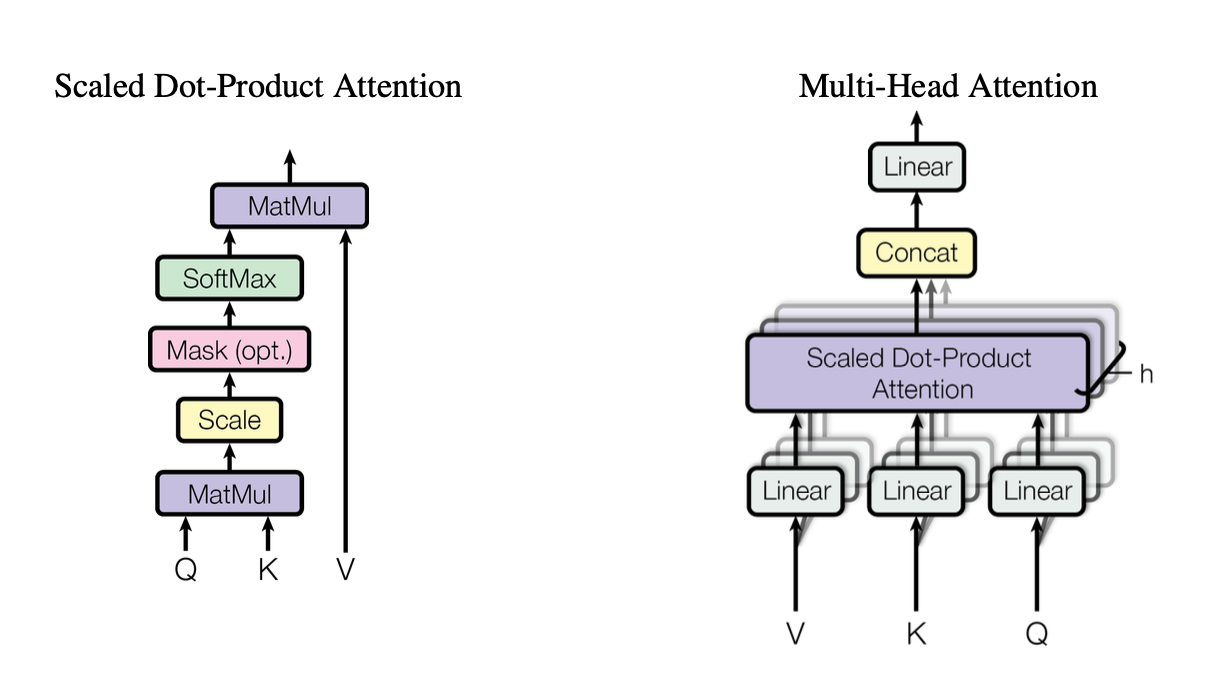 Рисунок 2: Ілюстрація масштабованого механізму уваги скалярного добутку, що показує, як взаємодіють вектори запиту (Q), ключа (K) та значення (V). Джерело: Vaswani et al., "Attention Is All You Need" (2017). Зображення відтворено в освітніх цілях згідно з принципами добросовісного використання. [/caption]
Рисунок 2: Ілюстрація масштабованого механізму уваги скалярного добутку, що показує, як взаємодіють вектори запиту (Q), ключа (K) та значення (V). Джерело: Vaswani et al., "Attention Is All You Need" (2017). Зображення відтворено в освітніх цілях згідно з принципами добросовісного використання. [/caption]
Ці голови використовують масштабовану увагу скалярного добутку як стандартний будівельний блок, що можна узагальнити в коді як:
import torch import math def scaled_dot_product_attention(Q, K, V): # Q, K, V are [batch_size, heads, seq_len, d_k] d_k = Q.size(-1) scores = torch.matmul(Q, K.transpose(-2, -1)) / math.sqrt(d_k) weights = torch.softmax(scores, dim=-1) return torch.matmul(weights, V)
Кожна голова працює з по-різному проектованими версіями запитів (Q), ключів (K) та значень (V), а потім об'єднує результати. Цей дизайн, що підлягає паралелізації, є ключовим для ефективності Transformer'а.
Позиційні кодування
Немає рекурентності? Це породжує питання: Як модель відстежує порядок слів? Увійдіть позиційні кодування—синусоїдальний або вивчений патерн, доданий до вбудовування кожного токена, допомагаючи Transformer'у зберігати відчуття послідовності. Це як надати кожному слову унікальну позначку часу.
3. Швидке порівняння продуктивності
-
RNN/LSTM: Чудово для завдань послідовностей, але повільні для довгих послідовностей через покрокову обробку.
-
CNN (наприклад, ConvS2S): Швидші за RNN, але все ще не повністю паралельні для далекосяжних залежностей.
-
Transformer'и:
Вища пропускна здатність: Можуть обробляти цілі послідовності паралельно, роблячи тренування значно швидшим.
-
Кращі результати: Transformer'и досягли найсучасніших оцінок у завданнях, таких як машинний переклад (28.4 BLEU на WMT14 EN-DE) з меншим часом тренування.
-
Масштабовані: Кидайте більше GPU на дані і дивіться, як це масштабується майже лінійно (в межах апаратних обмежень та пам'яті).
4. Врахування складності: O(n²) і чому це важливо
Хоча Transformer'и прискорюють тренування через паралелізацію, самоувага несе складність O(n²) щодо довжини послідовності n. Іншими словами, кожен токен звертає увагу на кожен інший токен, що може бути дорого для надзвичайно довгих послідовностей. Дослідники активно досліджують більш ефективні механізми уваги (як розріджену або блокову увагу) для пом'якшення цієї вартості.
Навіть так, для типових завдань NLP, де кількість токенів вимірюється тисячами, а не мільйонами, ця накладна вартість O(n²) часто переважується перевагами паралельного обчислення—особливо якщо у вас є відповідне апаратне забезпечення.
5. Чому це важливо для великих мовних моделей (LLM)
Сучасні LLM—як GPT, BERT та T5—ведуть своє походження безпосередньо від Transformer'а. Це тому, що фокус оригінальної статті на паралелізмі, самоувазі та гнучких контекстних вікнах зробив її ідеально підходящою для завдань поза межами перекладу, включаючи:
-
Генерація тексту та узагальнення
-
Питання-відповіді
-
Завершення коду
-
Багатомовні чатботи
-
І так, ваш новий AI-асистент для написання завжди має каламбур у рукаві.
Коротше кажучи, "Attention Is All You Need" проклала шлях для цих великих моделей, які поглинають мільярди токенів і обробляють майже будь-яке завдання NLP, яке ви на них кидаєте.
6. Нам знадобиться більше обчислень: Де з'являються розгортання Introl
Ось підвох: Transformer'и голодні—дуже голодні. Тренування великої мовної моделі може означати поглинання обчислювальних ресурсів навантаженнями автонавантажувача. Щоб використати всю цю паралелізацію, вам потрібні потужні розгортання GPU—іноді їх кількість вимірюється тисячами (або десятками тисяч). Саме тут вступає інфраструктура високопродуктивних обчислень (HPC).
В Introl ми на власному досвіді бачили, наскільки масивними можуть стати ці системи. Ми працювали над збірками, що включали понад 100,000 GPU в жорсткі терміни—от це логістична майстерність. Наш хліб з маслом—це розгортання GPU-серверів, стійок та передових установок живлення/охолодження, щоб все працювало ефективно. Коли ви одночасно тренуєте модель на основі Transformer на тисячах вузлів, будь-яке апаратне вузьке місце є енергетичним вихором як для часу, так і для грошей.
-
Великомасштабні GPU-кластери: Ми виконували розгортання, що перевищували 100K GPU, що означає, що ми розуміємо складнощі конфігурацій стійок і стеків, кабельних з'єднань та стратегій живлення/охолодження для підтримки всього стабільного.
-
Швидка мобілізація: Потрібно додати ще 2,000 GPU-вузлів за кілька днів? Наші спеціалізовані команди можуть бути на місці та працювати протягом 72 годин.
-
Підтримка від кінця до кінця: Від оновлень прошивки та конфігурацій iDRAC до поточного обслуговування та перевірок продуктивності, ми керуємо логістикою, щоб ваші дата-сайентисти могли залишатися зосередженими на інноваціях.
7. Погляд у майбутнє: Більші моделі, більші мрії
"Attention Is All You Need" не просто віха—це план для майбутніх розширень. Дослідники вже досліджують Transformer'и з довшим контекстом, ефективні механізми уваги та передову розрідженість для обробки величезних корпусів (думайте: цілі бібліотеки, а не лише ваш місцевий книжковий магазин). Будьте впевнені, апетит до обчислень, прискорених GPU, тільки зростатиме.
І в цьому краса ери Transformer'ів. У нас є модель, яка може елегантно масштабуватися, за умови, що ми підберемо її з правильною апаратною стратегією. Тож чи будуєте ви наступний феномен генеративного AI, чи розширюєте межі універсального перекладу, мати партнера з інфраструктури, досвідченого в масивних розгортаннях GPU, це більше ніж просто приємно мати; це практично ваша конкурентна перевага.
Заключна думка: Трансформуйте свою AI-гру
Стаття Attention Is All You Need була більше ніж просто розумною назвою—це був сейсмічний зсув. Transformer'и трансформували все від машинного перекладу до генерації коду і далі. Якщо ви хочете використати цю силу в масштабі, ключ у поєднанні блискучої архітектури з такою ж блискучою інфраструктурою.
Готові масштабувати? Дізнайтеся, як спеціалізовані розгортання GPU-інфраструктури Introl можуть прискорити ваш наступний великий проект Transformer—тому що правильне апаратне забезпечення може зробити всю різницю в AI.
Візуалізації в цій статті з оригінальної статті "Attention Is All You Need" (Vaswani et al., 2017) і включені з атрибуцією згідно з принципами добросовісного використання в освітніх цілях. Стаття доступна за адресою https://arxiv.org/abs/1706.03762 для читачів, зацікавлених у повному дослідженні.


